
Amazon QuickにXX日以上ログインしていないユーザーをAmazon Quickのダッシュボードで可視化してみる
こんにちは。クラウド事業本部の木村です。
Amazon Quickはユーザー数に応じた従量課金のため、不要なユーザーが残っているとコストが発生し続けます。定期的に棚卸しをして、長期間ログインしていないユーザーを削除することでコスト最適化を行うことができます。
以前、IAM Identity Center の未使用ユーザーを Amazon Quick で可視化する記事を書きました。
・AWS IAM Identity CenterにXX日以上ログインしていないユーザーをQuick Suiteで可視化してみる
今回はこの仕組みを流用して、Amazon Quick のユーザーを対象に、XX日以上ログインしていないユーザーを抽出して Amazon Quick のダッシュボードで可視化します。
Amazon Quick の料金体系
Amazon Quick はユーザーのロールに応じて以下の料金が発生します(2026/03時点)。
最新の価格は公式サイトを参照するようにしてください。
https://aws.amazon.com/jp/quick/quicksight/pricing/
| プラン | ユーザータイプ | 月額 | 主な用途・利用可能機能 |
|---|---|---|---|
| Quick Sight(BI) | Author | $24 / ユーザー | ダッシュボード作成・編集 |
| Quick Sight(BI) | Reader | $3 / ユーザー | ダッシュボード閲覧のみ |
| Q in Quick Suite / Quick Suite Enterprise | Author Pro | $40 / ユーザー | BI 機能 + 生成 AI 機能 |
| Q in Quick Suite / Quick Suite Professional | Reader Pro | $20 / ユーザー | BI 閲覧 + 生成 AI 機能 |
※Proユーザーが存在していてAI機能を有効化する場合、上記に加えてインフラストラクチャ料金として月額 $250 が別途発生します。
上記ユーザーがどのような権限を持つのかについては以下の記事にて大変わかりやすくまとまっておりますので、詳細はこちらをご参照ください。 https://dev.classmethod.jp/articles/amazon-quick-suite-quicksight-perspective/
前提条件
今回は以下の前提で構築しております。
- CloudTrail の証跡が有効
- AWS Organizations 利用中
- IAM Identity Center を利用してQuickのユーザを管理している
基本的には以前執筆した内容と重複する点が多いですが、本記事のみで構築が完結できるように以前と同じような内容についても記載しております。
AWS IAM Identity CenterにXX日以上ログインしていないユーザーをQuick Suiteで可視化してみる
仕組み
基本的に前回のIAM Identity Centerのユーザーを可視化した際と同じ仕組みを流用しており、一覧の取得元だけが異なる形になります。
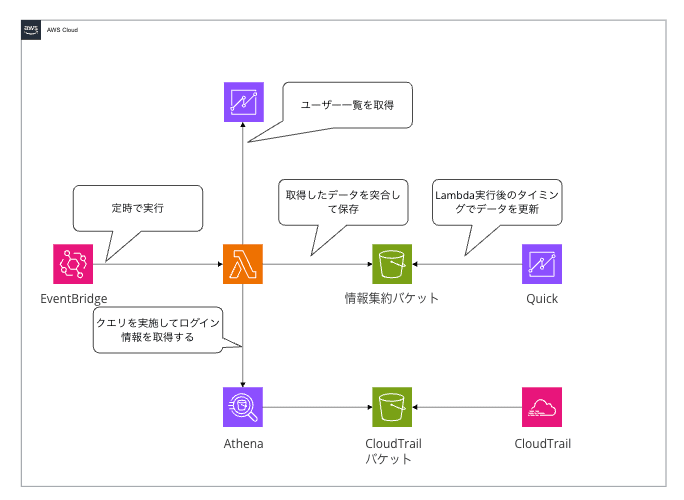
LambdaにてAthenaのクエリの実施とIAM Identity Centerのユーザーの一覧を取得して突合を行いデータの加工をすることで、Quick Suiteではダッシュボードを作成すれば良いだけにしています。
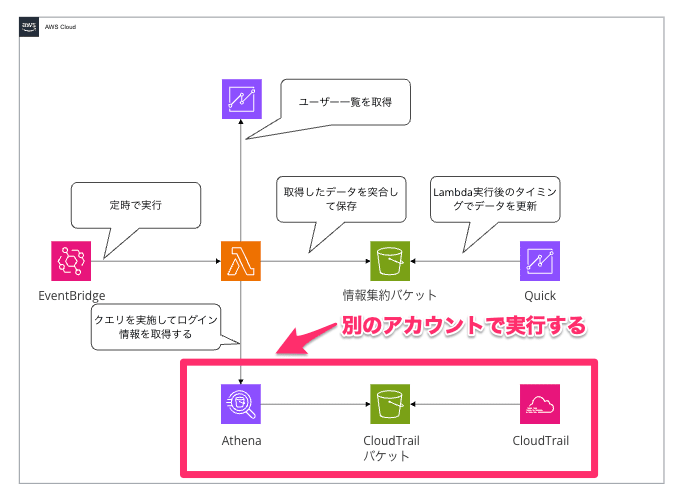
Quickを利用しているアカウントとCloudTrailを集約しているアカウントは別であることが多いかと思います。今回もQuickを利用しているアカウントとLambdaを実行するアカウントとAthenaを実行するアカウントを分けて実行する想定して進めていきます。
やってみた
では実際に構築していきます。
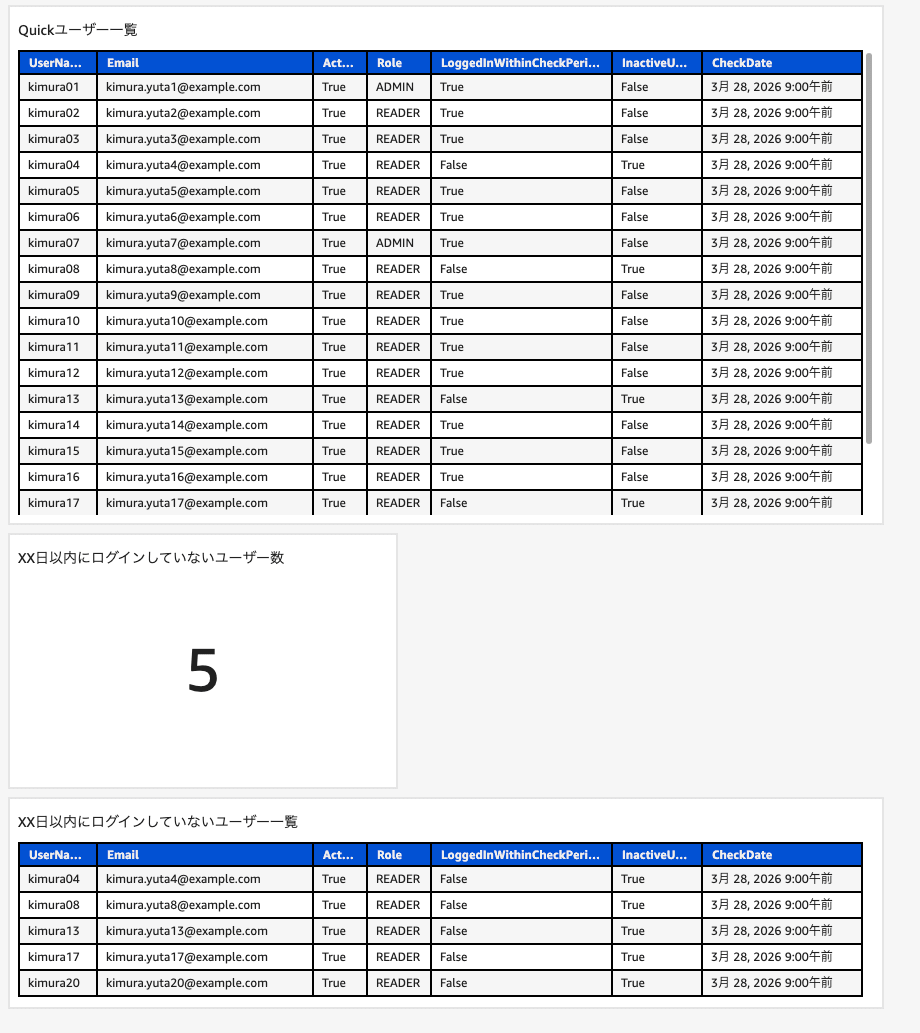
最終的なイメージとしてはIAM Identity Centerのユーザーを可視化した際と同様にシンプルにユーザー全員の情報、XX日以内にログインしていないユーザー数、XX日以内にログインしていないユーザー一覧を表示するように作成していきます。
CloudTrailアカウントにLambdaが引き受けるロールを作成する(CloudTrailアカウントでの作業)
AthenaでのクエリをCloudTrailアカウントで実行するので、Lambdaが引き受けるためのロールの作成が必要になります。
必要な権限は以下になります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AthenaQueryExecution",
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults",
"athena:StopQueryExecution",
"athena:GetWorkGroup"
],
"Resource": [
"arn:aws:athena:ap-northeast-1:XXXXXXXXXXXX:workgroup/primary",
"arn:aws:athena:ap-northeast-1:XXXXXXXXXXXX:workgroup/*"
]
},
{
"Sid": "GlueCatalogAccess",
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetPartitions"
],
"Resource": [
"arn:aws:glue:ap-northeast-1:XXXXXXXXXXXX:catalog",
"arn:aws:glue:ap-northeast-1:XXXXXXXXXXXX:database/default",
"arn:aws:glue:ap-northeast-1:XXXXXXXXXXXX:table/default/cloudtrail_quick"
]
},
{
"Sid": "S3CloudTrailReadAccess",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::{CloudTrail保管先バケット}",
"arn:aws:s3:::{CloudTrail保管先バケット}/*"
]
},
{
"Sid": "S3AthenaOutputAccess",
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::{Athena結果保存用バケット}",
"arn:aws:s3:::{Athena結果保存用バケット}/*"
]
}
]
}
{CloudTrail保管先バケット}と{Athena結果保存用バケット}部分およびXXXXXXXXXXXXにしているアカウントIDの箇所はそれぞれの値に置き換えてください。
Athenaテーブルを作成する(CloudTrailアカウントでの作業)
Athenaでクエリする前段の作業として、テーブルを作成が必要になります。こちらは初回のみ実施すれば問題ないです。
以下のDDLにて、テーブルを作成してください。
CREATE EXTERNAL TABLE `cloudtrail_quick`(
`eventversion` string,
`useridentity` string,
`eventtime` string,
`eventsource` string,
`eventname` string,
`awsregion` string,
`sourceipaddress` string,
`useragent` string,
`errorcode` string,
`errormessage` string,
`requestparameters` string,
`responseelements` string,
`additionaleventdata` string,
`requestid` string,
`eventid` string,
`resources` string,
`eventtype` string,
`apiversion` string,
`readonly` string,
`recipientaccountid` string,
`serviceeventdetails` string,
`sharedeventid` string,
`vpcendpointid` string
)
PARTITIONED BY (
`region` string,
`date` string
)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'ignore.malformed.json' = 'true'
)
STORED AS INPUTFORMAT
'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'{CloudTrailログを格納しているS3 URI}'
TBLPROPERTIES (
'classification'='cloudtrail',
'compressionType'='gzip',
'projection.date.format'='yyyy/MM/dd',
'projection.date.interval'='1',
'projection.date.interval.unit'='DAYS',
'projection.date.range'='NOW-1YEARS,NOW',
'projection.date.type'='date',
'projection.enabled'='true',
'projection.region.type'='enum',
'projection.region.values'='us-east-1,us-east-2,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1',
'storage.location.template'='{CloudTrailログを格納しているS3 URI}/${region}/${date}'
);
{CloudTrailログを格納しているS3 URI}としている部分については、それぞれの環境のS3 URIに置き換えてクエリを実行してください。
Lambdaを作成する
ここからはAmazon Quickを利用しているアカウントで作業を行います。
以下のようなコードで作成します。
import boto3
import datetime
import csv
import io
import time
import os
from botocore.exceptions import ClientError
CLOUDTRAIL_ROLE_ARN = os.environ['CLOUDTRAIL_ROLE_ARN']
ATHENA_OUTPUT_LOCATION = os.environ['ATHENA_OUTPUT_LOCATION']
OUTPUT_BUCKET = os.environ['OUTPUT_BUCKET']
ATHENA_DATABASE = os.environ.get('ATHENA_DATABASE', 'default')
ATHENA_TABLE = os.environ.get('ATHENA_TABLE', 'cloudtrail_quick')
OUTPUT_PREFIX = os.environ.get('OUTPUT_PREFIX', 'quick-users')
CHECK_PERIOD_DAYS = int(os.environ.get('CHECK_PERIOD_DAYS', '30'))
def assume_cross_account_role(role_arn, session_name):
"""クロスアカウントロールを引き受けて Session を返す"""
try:
sts_client = boto3.client('sts')
print(f"Assuming role: {role_arn}")
assumed_role = sts_client.assume_role(
RoleArn=role_arn,
RoleSessionName=session_name,
DurationSeconds=3600
)
session = boto3.Session(
aws_access_key_id=assumed_role['Credentials']['AccessKeyId'],
aws_secret_access_key=assumed_role['Credentials']['SecretAccessKey'],
aws_session_token=assumed_role['Credentials']['SessionToken']
)
print("Successfully assumed role")
return session
except ClientError as e:
print(f"Failed to assume role: {e.response['Error']['Message']}")
raise
except Exception as e:
print(f"Unexpected error assuming role: {str(e)}")
raise
def get_quicksight_users():
"""QuickSight のユーザー一覧を取得する"""
account_id = boto3.client('sts').get_caller_identity()['Account']
client = boto3.client('quicksight')
users = []
next_token = None
try:
print("Fetching QuickSight users...")
while True:
kwargs = {'AwsAccountId': account_id, 'Namespace': 'default'}
if next_token:
kwargs['NextToken'] = next_token
response = client.list_users(**kwargs)
users.extend(response.get('UserList', []))
next_token = response.get('NextToken')
if not next_token:
break
print(f"Retrieved {len(users)} QuickSight users")
return users
except ClientError as e:
print(f"Error retrieving QuickSight users: {e.response['Error']['Message']}")
raise
except Exception as e:
print(f"Unexpected error retrieving users: {str(e)}")
raise
def execute_athena_query(athena_client, query, database, output_location, max_wait_seconds=300):
"""Athena クエリを実行して結果を返す(ヘッダー行を除く)"""
try:
print("Executing Athena query...")
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={'Database': database},
ResultConfiguration={'OutputLocation': output_location}
)
query_execution_id = response['QueryExecutionId']
print(f"Query execution ID: {query_execution_id}")
max_attempts = max_wait_seconds // 5
for _ in range(max_attempts):
response = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
status = response['QueryExecution']['Status']['State']
if status == 'SUCCEEDED':
print("Query completed successfully")
break
elif status in ['FAILED', 'CANCELLED']:
error_msg = response['QueryExecution']['Status'].get('StateChangeReason', 'Unknown error')
print(f"Query failed: {error_msg}")
raise Exception(f"Athena query failed: {error_msg}")
time.sleep(5)
else:
raise Exception(f"Query timeout after {max_wait_seconds} seconds")
results = []
paginator = athena_client.get_paginator('get_query_results')
for page_num, page in enumerate(paginator.paginate(QueryExecutionId=query_execution_id)):
rows = page['ResultSet']['Rows']
if page_num == 0:
rows = rows[1:] # ヘッダー行をスキップ
for row in rows:
results.append([col.get('VarCharValue', '') for col in row['Data']])
return results
except ClientError as e:
print(f"Error executing Athena query: {e.response['Error']['Message']}")
raise
except Exception as e:
print(f"Unexpected error executing query: {str(e)}")
raise
def get_logged_in_usernames(athena_session, database, table, output_location, days=30):
"""
CloudTrail から直近 N 日以内に IAM Identity Center 経由でログインした
ユーザー名のセットを返す
"""
try:
print(f"Querying CloudTrail for logins in the last {days} days...")
print(f"Athena database: {database}, table: {table}")
athena_client = athena_session.client('athena', region_name='ap-northeast-1')
query = f"""
SELECT DISTINCT
regexp_extract(
json_extract_scalar(responseelements, '$.assumedRoleUser.arn'),
'[^/]+$'
) AS username
FROM "{database}"."{table}"
WHERE
eventsource = 'sts.amazonaws.com'
AND eventname = 'AssumeRoleWithSAML'
AND from_iso8601_timestamp(eventtime) >= current_timestamp - interval '{days}' day
AND json_extract_scalar(requestparameters, '$.roleArn') LIKE '%AWSReservedSSO%'
AND region = 'ap-northeast-1'
AND date >= date_format(current_date - interval '{days}' day, '%Y/%m/%d')
"""
results = execute_athena_query(
athena_client=athena_client,
query=query,
database=database,
output_location=output_location
)
logged_in = {row[0] for row in results if row and row[0]}
print(f"Found {len(logged_in)} unique users who logged in within the last {days} days")
return logged_in
except Exception as e:
print(f"Error querying CloudTrail: {str(e)}")
return set()
def save_to_s3(s3_client, bucket, key, content):
"""S3 にコンテンツを保存する"""
try:
s3_client.put_object(
Bucket=bucket,
Key=key,
Body=content,
ContentType='text/csv'
)
print(f"Saved to s3://{bucket}/{key}")
except ClientError as e:
print(f"Error saving to S3: {e.response['Error']['Message']}")
raise
def lambda_handler(event, context):
"""Lambda メインハンドラー:QuickSight ユーザーの棚卸しを実行する"""
start_time = time.time()
now = datetime.datetime.now()
latest_key = f"{OUTPUT_PREFIX}/latest.csv"
archive_key = (
f"{OUTPUT_PREFIX}/archives"
f"/year={now.strftime('%Y')}"
f"/month={now.strftime('%m')}"
f"/day={now.strftime('%d')}/data.csv"
)
print("=" * 60)
print("QuickSight User Inventory")
print("=" * 60)
s3_client = boto3.client('s3')
try:
print("\n[Step 1] Fetching QuickSight users...")
qs_users = get_quicksight_users()
if not qs_users:
print("No users found in QuickSight")
return {'statusCode': 200, 'body': 'No users found in QuickSight'}
print("\n[Step 2] Querying CloudTrail via Athena...")
logged_in_usernames = set()
try:
athena_session = assume_cross_account_role(
role_arn=CLOUDTRAIL_ROLE_ARN,
session_name=f"QuickUserInventory-{now.strftime('%Y%m%d%H%M%S')}"
)
logged_in_usernames = get_logged_in_usernames(
athena_session=athena_session,
database=ATHENA_DATABASE,
table=ATHENA_TABLE,
output_location=ATHENA_OUTPUT_LOCATION,
days=CHECK_PERIOD_DAYS
)
except Exception as e:
print(f"Warning: Could not query CloudTrail: {str(e)}")
print("Continuing without CloudTrail data...")
print("\n[Step 3] Processing user login status...")
user_records = []
for user in qs_users:
username = user.get('UserName', '')
logged_in = username in logged_in_usernames
user_records.append({
'UserName': username,
'Email': user.get('Email', ''),
'Role': user.get('Role', ''),
'Active': user.get('Active', False),
'LoggedInWithinCheckPeriod': logged_in,
'InactiveUser': not logged_in,
'CheckDate': now.strftime('%Y-%m-%d %H:%M:%S'),
})
active_users = [u for u in user_records if u['LoggedInWithinCheckPeriod']]
inactive_users = [u for u in user_records if u['InactiveUser']]
print(f"Total users: {len(user_records)}")
print(f"Active users (logged in within {CHECK_PERIOD_DAYS} days): {len(active_users)}")
print(f"Inactive users (no login in {CHECK_PERIOD_DAYS} days): {len(inactive_users)}")
print("\n[Step 4] Generating CSV output...")
output = io.StringIO()
fieldnames = ['UserName', 'Email', 'Role', 'Active', 'LoggedInWithinCheckPeriod', 'InactiveUser', 'CheckDate']
csv_writer = csv.DictWriter(output, fieldnames=fieldnames, quoting=csv.QUOTE_NONNUMERIC)
csv_writer.writeheader()
csv_writer.writerows(user_records)
csv_content = output.getvalue()
print("\n[Step 5] Saving results to S3...")
save_to_s3(s3_client, OUTPUT_BUCKET, latest_key, csv_content)
save_to_s3(s3_client, OUTPUT_BUCKET, archive_key, csv_content)
elapsed_time = time.time() - start_time
print(f"\n{'=' * 60}")
print("QuickSight User Inventory Summary")
print(f"{'=' * 60}")
print(f"Total users: {len(user_records)}")
print(f"Active users (logged in within {CHECK_PERIOD_DAYS} days): {len(active_users)}")
print(f"Inactive users (no login in {CHECK_PERIOD_DAYS} days): {len(inactive_users)}")
print(f"Processing time: {int(elapsed_time // 60)}m {int(elapsed_time % 60)}s")
print(f"{'=' * 60}\n")
return {
'statusCode': 200,
'body': {
'message': 'QuickSight user inventory completed successfully',
'total_users': len(user_records),
'active_users': len(active_users),
'inactive_users': len(inactive_users),
'check_period_days': CHECK_PERIOD_DAYS,
'processing_time_seconds': int(elapsed_time),
'latest_file': f"s3://{OUTPUT_BUCKET}/{latest_key}",
'archive_file': f"s3://{OUTPUT_BUCKET}/{archive_key}",
}
}
except Exception as e:
error_message = f"Unexpected error: {str(e)}"
print(f"\n{error_message}")
return {
'statusCode': 500,
'body': {'error': error_message}
}
環境変数
- 必須の環境変数
実行するためにそれぞれの環境に合わせた環境変数の設定が必要になります。
| 環境変数名 | 説明 | 設定例 |
|---|---|---|
| CLOUDTRAIL_ROLE_ARN | CloudTrail側のアカウントで作成したクロスアカウントロールのARN | arn:aws:iam::XXXXXXXXXXXX:role/ロール名 |
| ATHENA_OUTPUT_LOCATION | CloudTrail側のアカウントにあるAthenaクエリ結果の出力先S3パス | s3://バケット名/ |
| OUTPUT_BUCKET | Lambda実行アカウント側にある最終結果CSVを保存するS3バケット名 | バケット名 |
- オプションの環境変数
デフォルト値が設定されているため、必要に応じて変更してください。
| 環境変数名 | 説明 | デフォルト値 |
|---|---|---|
| ATHENA_DATABASE | CloudTrailログのAthenaデータベース名 | default |
| ATHENA_TABLE | CloudTrailログのAthenaテーブル名 | cloudtrail_quick |
| OUTPUT_PREFIX | S3に保存する結果ファイルのプレフィックス | quick-users |
| CHECK_PERIOD_DAYS | ログインチェック期間(日数) | 30 |
Lambdaの実行ロール
Lambdaの実行にあたっては以下権限を付与してください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:ap-northeast-1:XXXXXXXXXXXX:*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:ap-northeast-1:XXXXXXXXXXXX:log-group:/aws/lambda/{Lambda名}:*"
]
},
{
"Sid": "S3WriteAccess",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:PutObjectAcl"
],
"Resource": [
"arn:aws:s3:::{OUTPUT_BUCKET}/*"
]
},
{
"Sid": "QuickSightReadAccess",
"Effect": "Allow",
"Action": [
"quicksight:ListUsers"
],
"Resource": "arn:aws:quicksight:ap-northeast-1:XXXXXXXXXXXX:user/default/*"
},
{
"Sid": "STSGetCallerIdentity",
"Effect": "Allow",
"Action": [
"sts:GetCallerIdentity"
],
"Resource": "*"
},
{
"Sid": "AssumeRoleForCloudTrail",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "{CLOUDTRAIL_ROLE_ARN}"
}
]
}
{Lambda名}と{OUTPUT_BUCKET}と{CLOUDTRAIL_ROLE_ARN}部分およびXXXXXXXXXXXXにしているアカウントIDの箇所はそれぞれの値に置き換えてください。
EventBridgeを設定する
Lambdaを定時実行できるように、EventBridgeを設定します。
今回は月次での棚卸しをイメージし、下記では月末に1度実行されるように設定しています。
cron(0 0 28 * ? *)
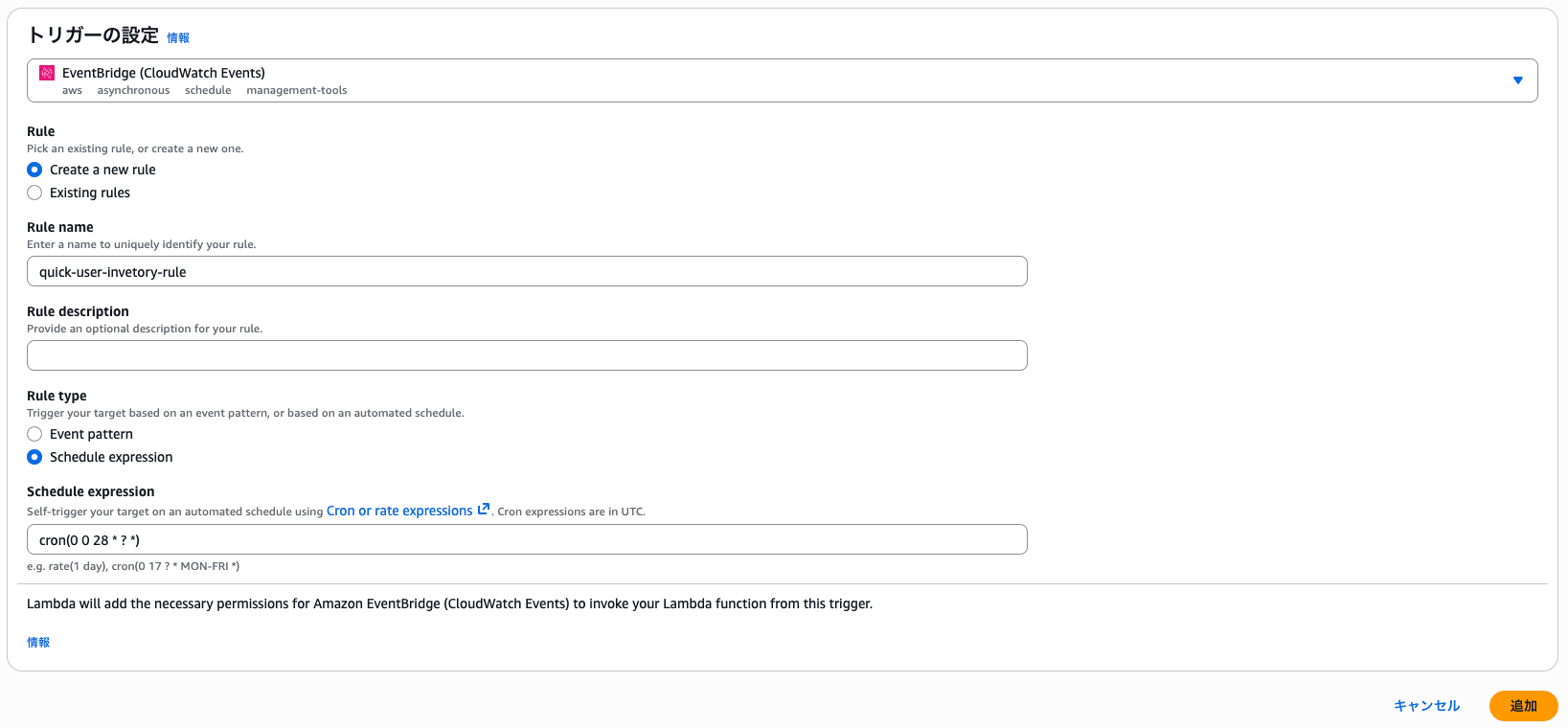
実行タイミングはcronを調整して任意の実行タイミングに変更いただければと思います。
データセットを作成する
ここからはAmazon Quickでの作業になります。まず作成した情報をダッシュボードで表示するためのデータを取り込みます。
今回はそのまま表示できるようにLambda側で調整しておりますので、S3に配置しているファイルを読み取るようにするだけです。
Quick Suiteの画面から「データセット」を選択して、データソースのタブから「データソースを作成」を選択してください。
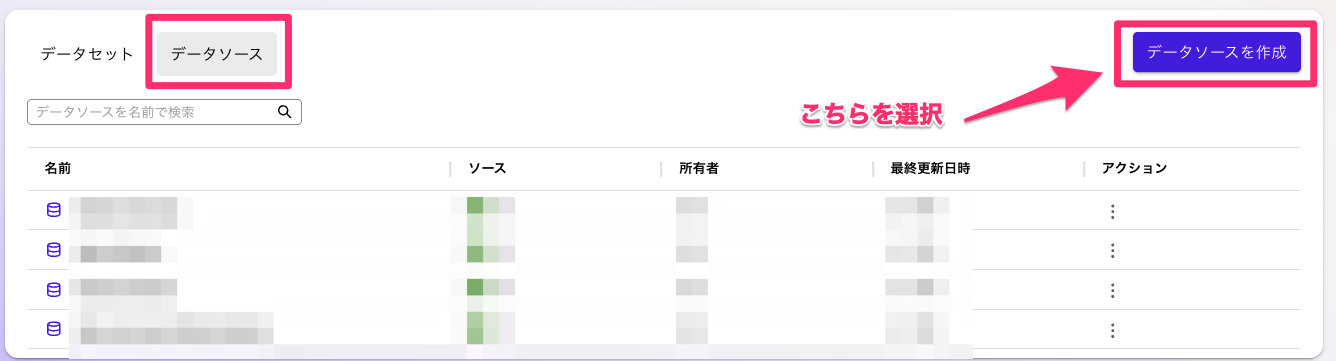
データソースとしてS3を選択します。
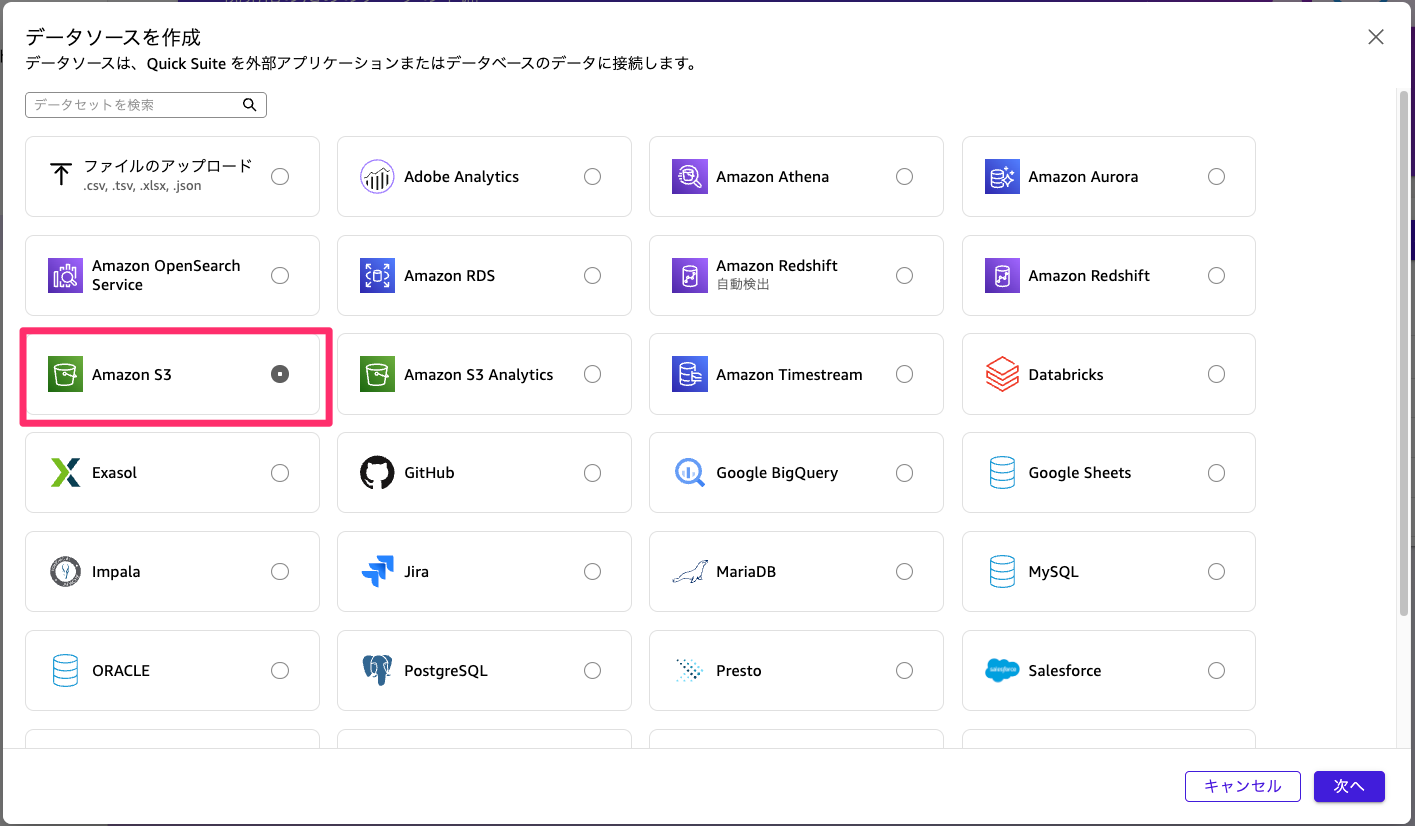
特定のS3バケットに格納しているファイルを読み取るようにマニュフェストファイルを以下のように作成してアップロードします。
{
"fileLocations": [
{
"URIs": [
"s3://{実行結果格納先バケット}/quick-users/latest.csv"
]
}
],
"globalUploadSettings": {
"format": "CSV",
"delimiter": ",",
"textqualifier": "\"",
"containsHeader": "true"
}
}
こちらもバケット名を適宜置き換えてください。(プレフィックス等をデフォルトから変更している場合はそちらも書き換えてください)
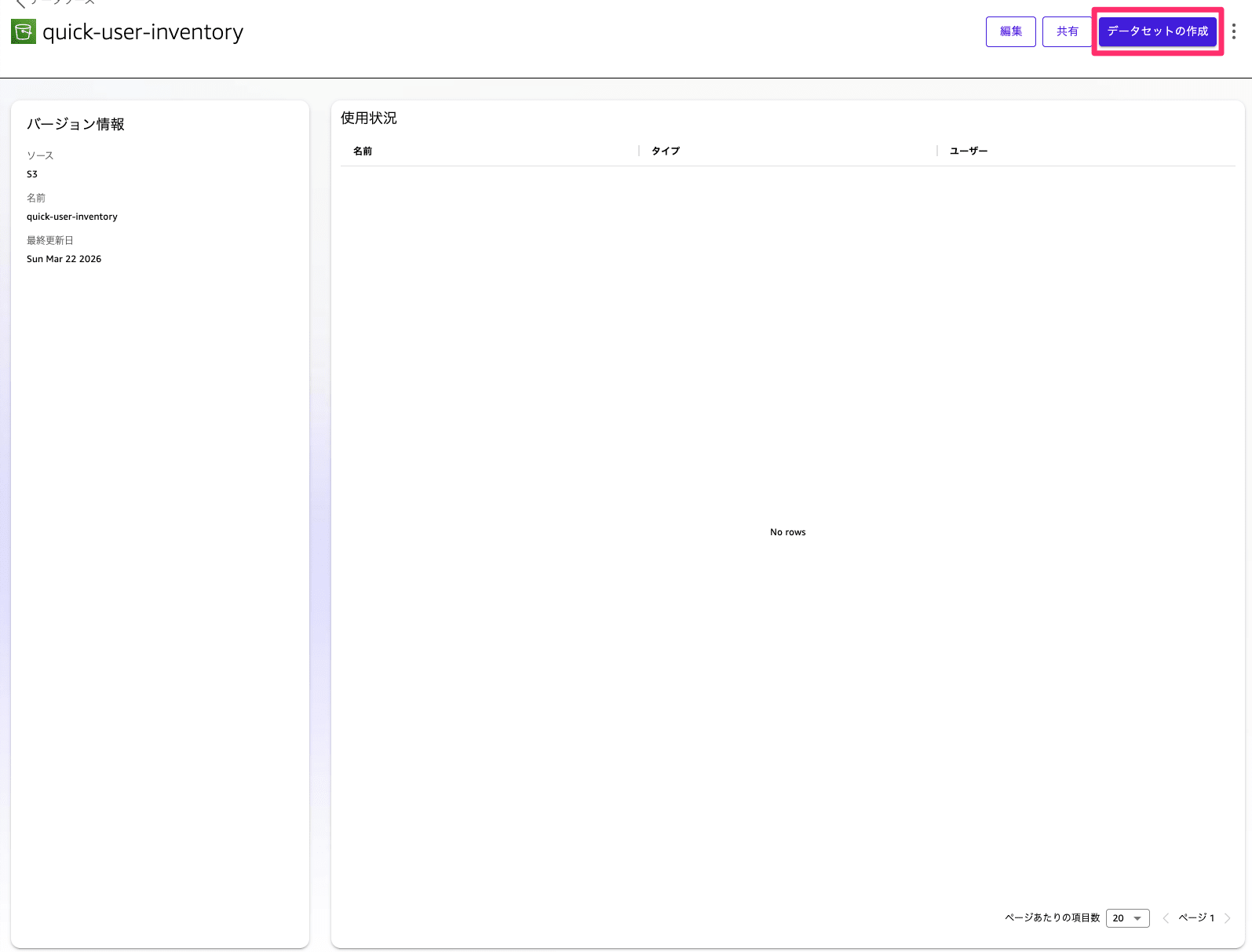
成功すると以下のようにデータソースが追加されます。続いて「データセットの作成」を選択してください。
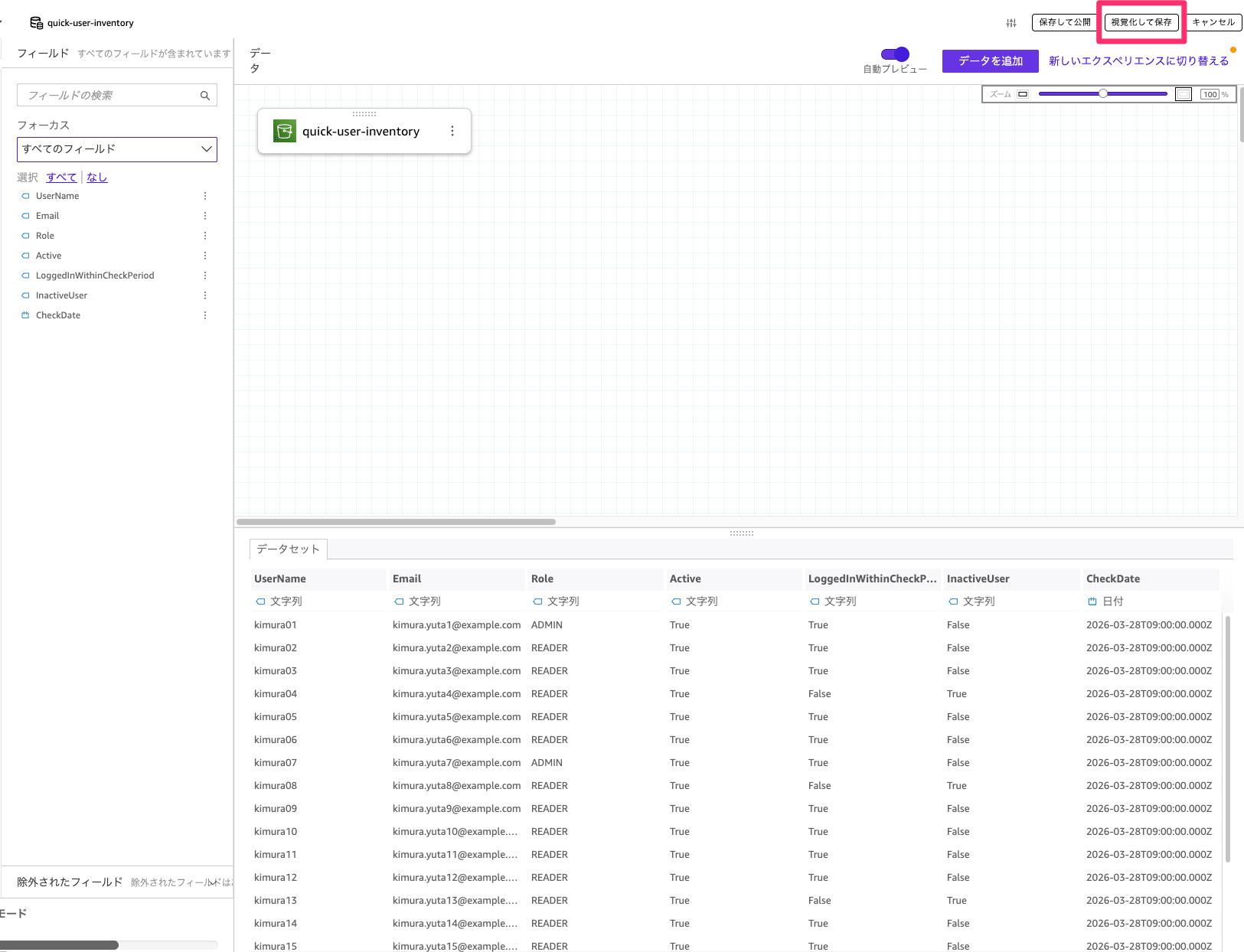
データ編集を選択して、取り込んでいる内容が問題なければ「視覚化して保存」を選択してください。
📝 注意
今回もキャプチャ取得にあたって検証環境で取得したデータが少なく参考にならないので、ダッシュボードの表示内容を確認していただきやすいようにダミーで作成したデータを使用しています。
データセットを更新するように設定する
ここまででデータセットの取り込みができました。ただこのままでは作成時のデータの内容を取得し続けることになってしまいます。
ですのでLambdaの実行された後のタイミングのデータを取り込む様に自動更新を設定していきます。
作成したデータセットを選択して、更新のタブを選択し新しいスケジュールの追加を選択してください。
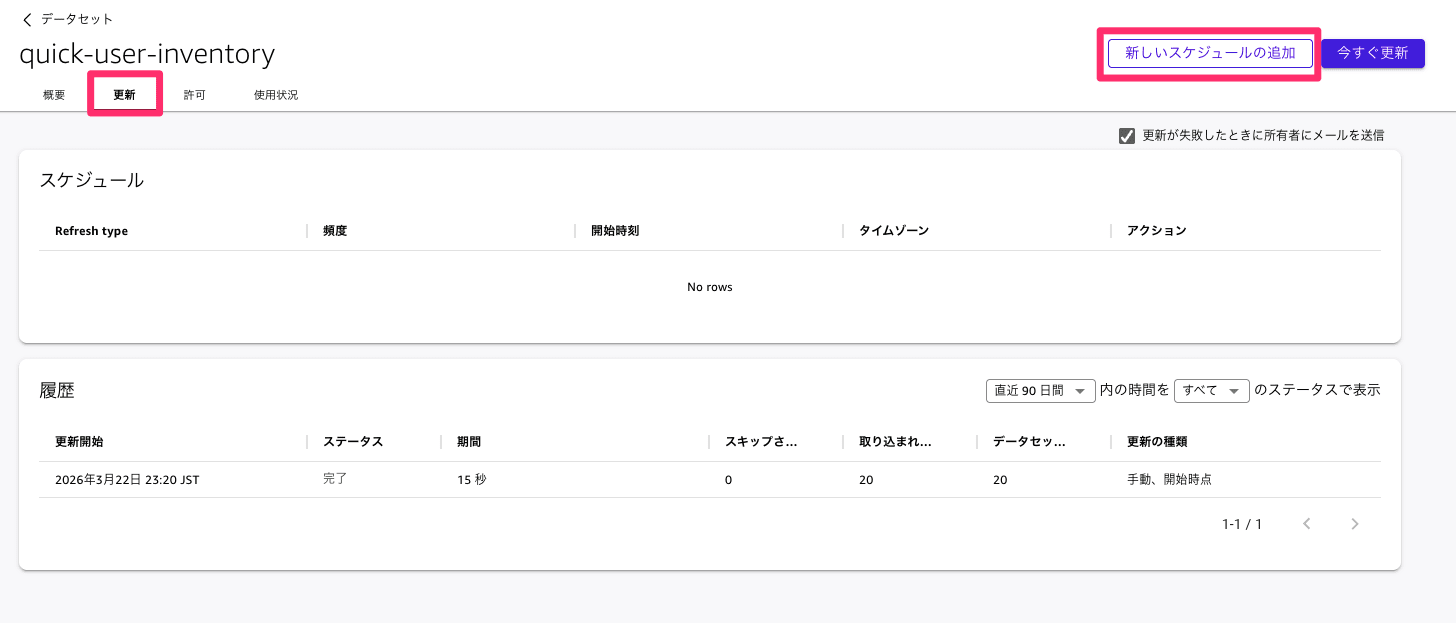
Lambdaの処理が終わるタイミングで更新されるようにスケジュールを設定します。こちらはLambdaの実行完了後のタイミングに合わせて時刻を設定してください。

このようにスケジュールを設定しておくと、取り込むデータが自動で更新されその時の最新のデータを取り込むことが可能です。
ダッシュボードを整備する
ダッシュボードを整備してユーザー全員の情報、XX日以内にログインしていないユーザー数、XX日以内にログインしていないユーザー一覧を表示するように設定していきます。今回はLambda側でデータを整えているので対応する内容としてはかなり簡単です。
まずユーザー全員の情報を表示します。表形式で表示したいのでテーブルを選択してください。
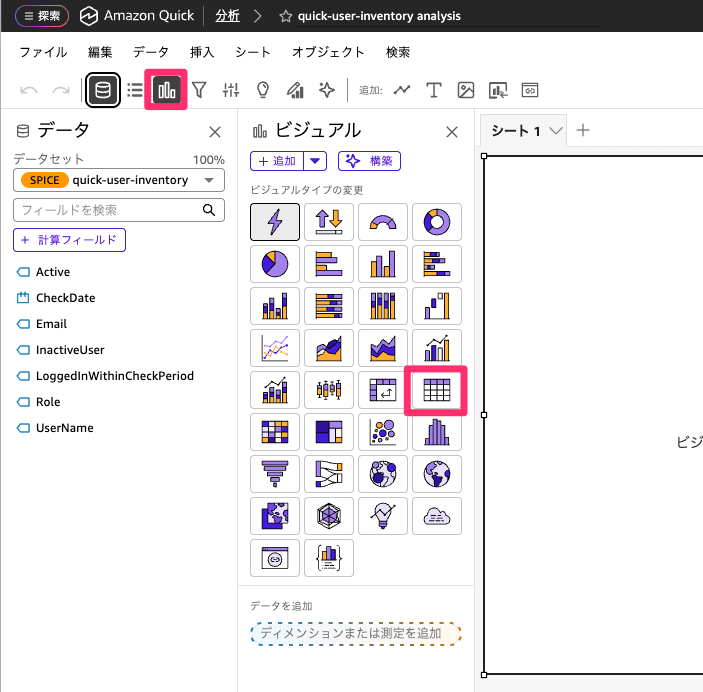
テーブルが追加できたら値に行の項目を全て追加してください。

列を追加すると以下のようにLambdaで取得した内容を全て表示させることができます。
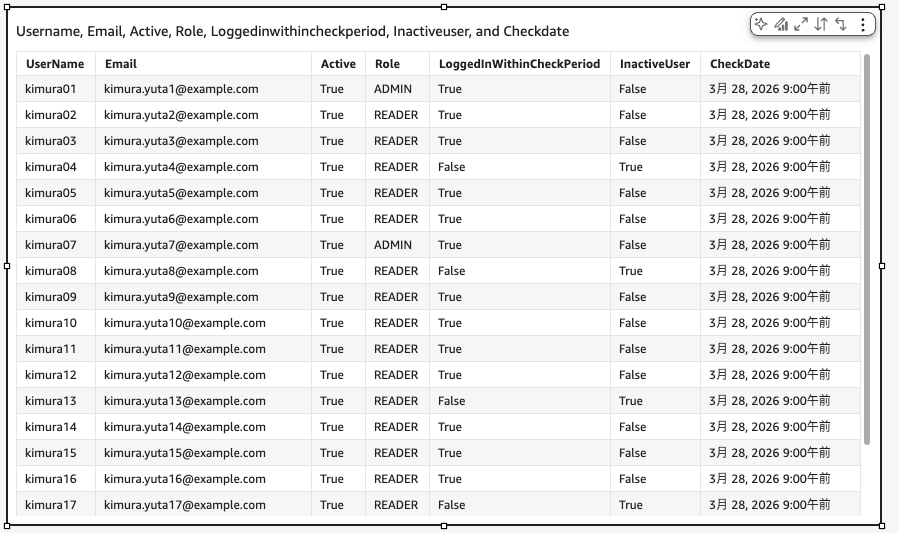
続いてXX日以内にログインしていないユーザー数を表示させます。
まずInactiveUserがTrueとなっている件数をカウントする必要がありますので。計算フィールドを作成します。
データから計算フィールドを選択してください。
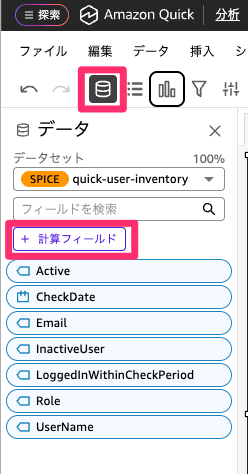
以下の様に計算式を設定して保存します。

ifelse(InactiveUser = "True", 1, 0)
計算フィールドが作成できたら先ほどと同様にビジュアルを追加します。今度はデフォルトのビジュアルタイプのままで先ほど作成した計算フィールドを追加されたフィールドにドラッグアンドドロップします。

すると先ほどのカウントされた数を表示することができます。
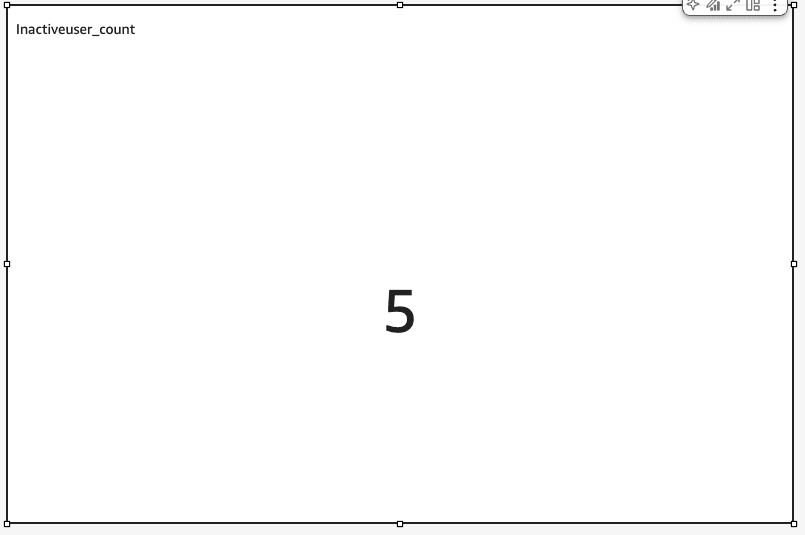
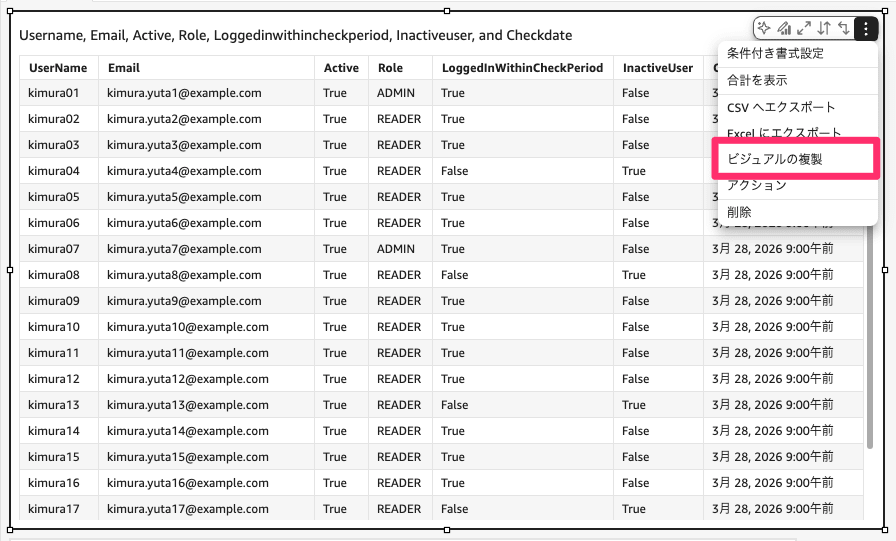
最後にXX日以内にログインしていないユーザー一覧を表示するように設定します。
まず先ほど作ったテーブルを複製します。
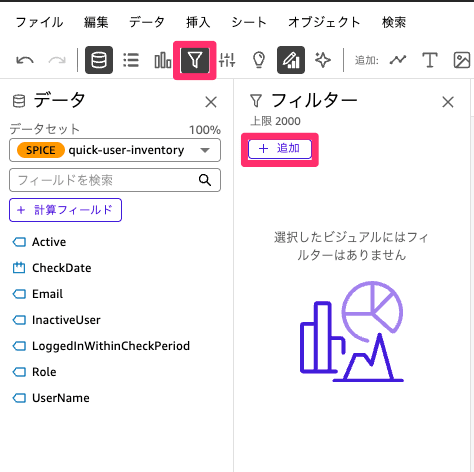
複製ができたら、テーブルに対してフィルターを設定します。テーブルを選択したままフィルターを選択して追加からInactiveUserを選択してください。
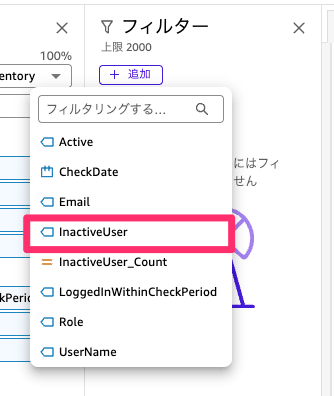
続いて編集を選択して、Trueのみにチェックして適用を選択します。
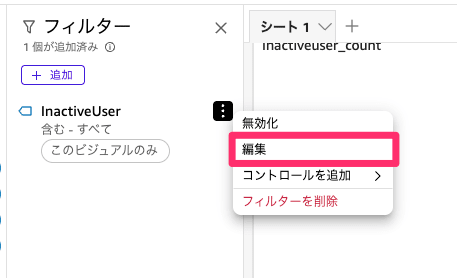
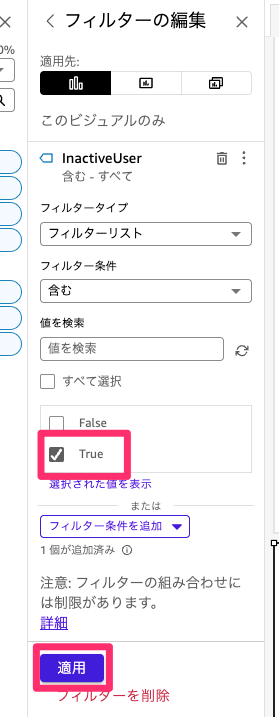
このようにフィルターを適用することで、ログインされていないユーザーのみ絞り込むことが可能です。
上記の設定ができたら、画面右上の公開ボタンからダッシュボードとして公開することでダッシュボードの作成が完了します。
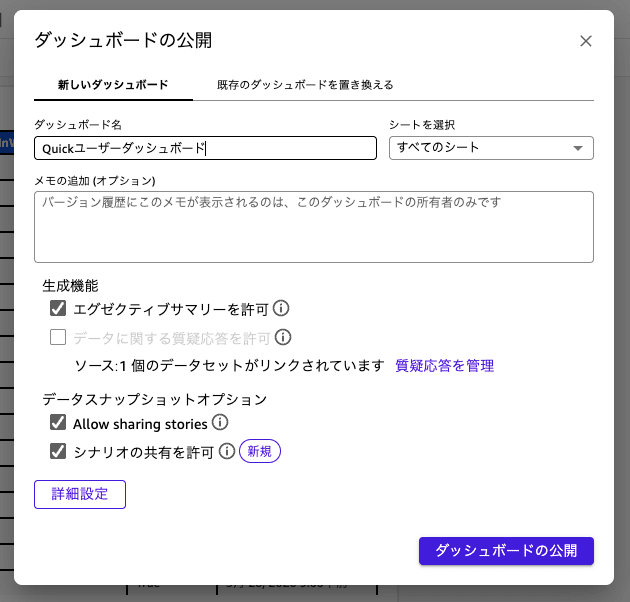
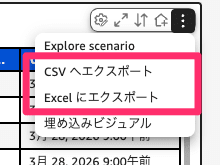
この内容をダッシュボードからでもcsvやExcelで出力することもできますので棚卸し対象をこちらで取得して共有することができます。
まとめ
今回はAmazon Quick 自体のユーザー棚卸し方法を整理しました。
前回の記事と構成はほぼ同じで、データ取得部分(Lambda の Amazon Quick API 呼び出し + Athena クエリの対象イベント)を変更することで棚卸しをできるようにしております。
その他の棚卸しにも今回の構築を流用してどんどん情報をAmazon Quickに集約していけると効率的に作業できそうかなと思っております。
今回の記事が参考になれば幸いです。
以上、クラウド事業本部の木村がお届けしました。