![[レポート] あなたの時系列予測データをアーキテクトする!!Amazon ForecastのChalk Talkセッションを聴講してきました #reinvent #AIM327](https://devio2023-media.developers.io/wp-content/uploads/2022/11/eyecatch_reinvent2022_session-report.png)
[レポート] あなたの時系列予測データをアーキテクトする!!Amazon ForecastのChalk Talkセッションを聴講してきました #reinvent #AIM327
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
こんちには。
データアナリティクス事業本部 機械学習チームの中村です。
現在、re:Invent 2022に現地で参加しております。
本記事では「Data preparation tips for highly accurate time-series forecasts」というセッションに参加しましたので、そのレポートをします。
セッションについて
- タイトル
- Data preparation tips for highly accurate time-series forecasts
- 登壇者
- Adarsh Singh, Sr. Software Developer Engineer, Amazon
- Charles Laughlin, Principal AI/ML Specialist Solution Architect, AWS
- セッション情報
- 日時: 2022-11-28 (Mon) 10:00-11:00
- 形式: Chalk Talk
- 番号: AIM327
- 会場: Caesars Forum (Level 1, Alliance 311, Caesars Forum)
- レベル: 300 - Advanced
内容は、Amazon Forecastを使用して、大規模なMLベースの時系列予測のためにデータをアーキテクトする方法を学ぶものなります。
セッション概要
事前の案内としては以下の通りです。
Accurate forecasting helps you make more informed decisions that directly impact financial results. In this chalk talk, learn how to architect your data for large-scale, ML-based time-series forecasting using Amazon Forecast. Review key data tenets, including collating data from different sources, building an initial base model, and selecting the most impactful features. Get tips on how to handle missing, sparse, and outlier data. Also, learn how to use related time-series and item metadata to “featurize” your data to get better results, especially for items with little history.
(日本語訳)
正確な予測は、財務結果に直接影響を与える、より多くの情報に基づいた意思決定を行うのに役立ちます。このトークセッションでは、Amazon Forecastを使用して、大規模なMLベースの時系列予測のためにデータをアーキテクトする方法を学びます。異なるソースからのデータの照合、最初の基本モデルの構築、最も影響力のある機能の選択など、主要なデータの基本を確認します。欠損、疎、異常値のデータをどのように扱うかのヒントも得られます。また、関連する時系列やアイテムのメタデータを使用してデータを「特徴づけ」し、特に履歴の少ないアイテムについて、より良い結果を得る方法を学びます。
セッション聴講内容
アジェンダ

- Amazon Forecastの紹介
- 入力データをどのように準備するか
- モデル改善のためのプロセス
- より発展したデータ準備の戦略
- Q&A
- 追加のリソースについて
Amazon Forecastの紹介

ここでは、Amazon Forecastの概要が紹介されていました。
以下のような特徴が説明されていました。
- Forecastが全てのインフラを管理するフルマネージドサービス
- 単純な予測以外にも、入力(RTS)が仮に変わったと仮定した場合にどのように結果が変化するかなどの分析も可能
ForecastのMLライフサイクル
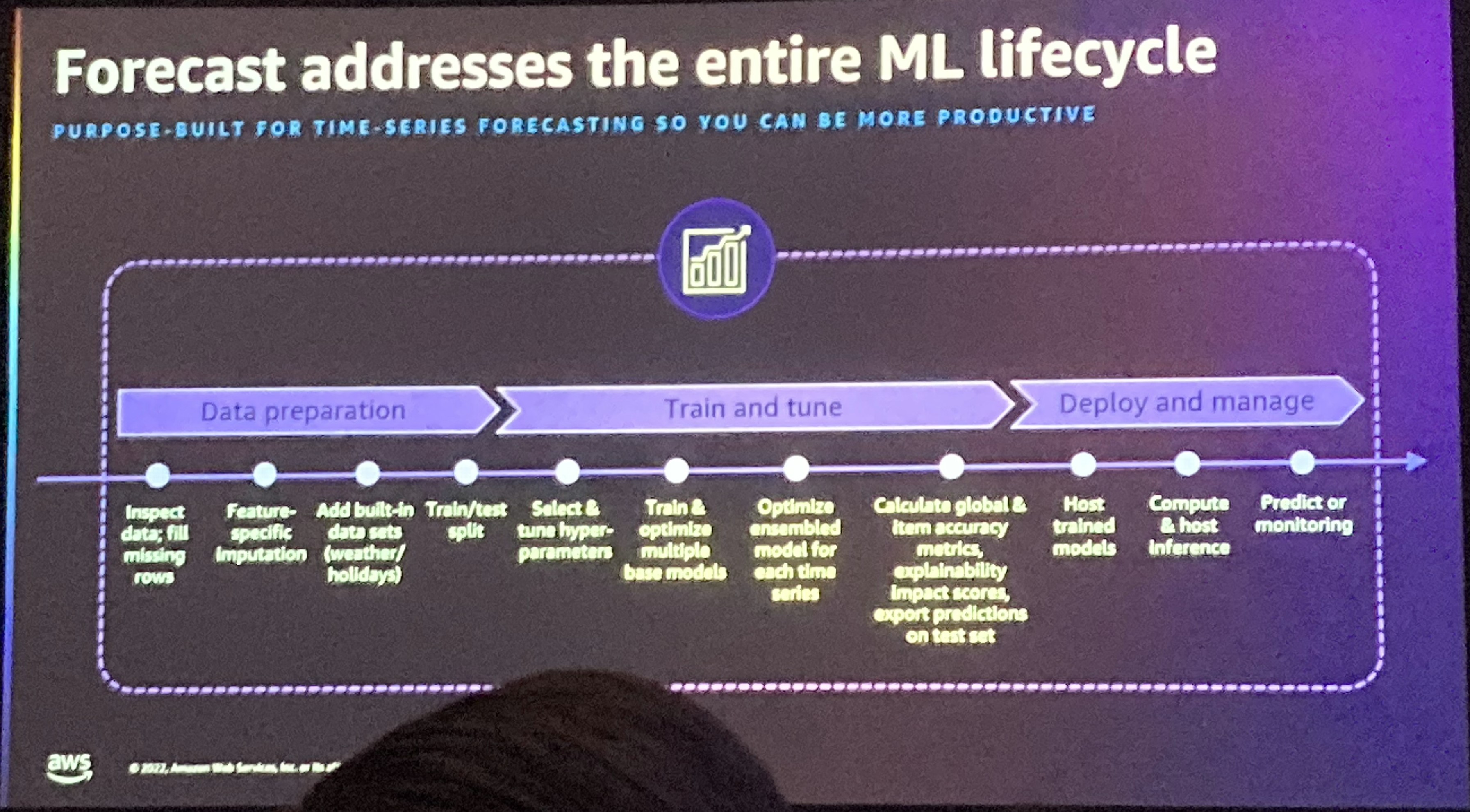
主に3つの部分に分かれています。
- Data preparation
- Train and tune
- Deploy and manage
「Data preparation」では、データの欠損値の対応や、頻度(サンプリング周期の変換)などを必要に応じて実施します。
「Train and tune」では、一つのモデルではなくて様々なモデルのアンサンブルで構成することができます。これらを最適化するプロセスが組み込まれているようです。 もちろん一つ一つのモデルに対してもHPO(ハイパーパラメータ最適化)がきちんと行われるということでした。
入力データについて
入力データは以下の3つが使用されます。
- Target time series (TTS)
- Related time Series (RTS)
- Item metadata

必須となるデータは、公式ドキュメントにも記載されている通りですが、TTSのアイテムID、タイムスタンプ、予測したい時系列データ(セッションの場合、需要データ)となります。 データに周期性がある場合は、その周期が含まれるデータを十分に得られれば、その周期性もモデルに組み込むことができます。

RTSは、モデルを改善したり予測結果を説明するために使用されるデータです。 RTSを使用する場合は、TTSと同様にアイテムIDとタイムスタンプをデータに含める必要があります。データとしては、スライドのように連続値やバイナリ値を13個まで与えることが可能です。ほとんどのケースでは、5、6列のRTSのカラムがあれば、良い精度が得られる傾向にあるとの目安を聞くこともできました。
またバイナリ値などの量子化するデータについては、補足の説明が多くありました。こういったデータは静的なデータであり、時系列データではないことに注意が必要そうです。これらのデータはどのようなカテゴライズでカラムとしてデータを与えるのか、設計の余地が多くありそうな印象を受けました。

Item metadtaはこのようなものを例に挙げられていました。
より発展したデータ準備の戦略
より発展したデータ準備の話として以下のような図が例示されていました。

これは、正解の時系列と、予測した時系列の誤差をマッピングしたもので、縦軸をMAPE、横軸をRMSEとなっています。
この双方が外れているような場所のポイントにフォーカスしてデータを確認することで、新しいカラムを入れる必要があるなどの手がかりを得ることができると説明されていました。

また改善を検討する中で、どのカラムをすると結果が改善、もしくは悪くなるのか分析することも必要のようです。
ここで、参加者から質問があったのは、「予測モデルを構築する前段階で、データにある問題を早い段階で発見する方法はあるか?」という内容でした。これは、外れ値を使うアプローチは、予測モデルを構築した後にしか実施できないため、それを実施する前にできないかという意図です。その回答としては、RやPythonのツールを使って分析するという回答となっていました。
また外れ値が、本当にエラーによって起きたものなのか、必然的に発生したのか(例えば祝日が突然発生したなど)、その外れ値は再発するのか、もう二度と発生しないのか、など外れ値自体の分析も非常に重要とのコメントが追加でありました。
また欠損値についてもホワイトボードを用いて追加の説明がありましたが、詳しいニュアンスは聞き取ることができませんでした。図のみ貼っておきます。
締めのスライド


まとめ
いかがでしたでしょうか。基礎的な部分も説明しつつ、具体的な問題に踏み込んで、解決策を例示されているのが印象的な良いセッションでした。 参加者の質問も、実際にここで困るよなと同意できるようなものが多く、回答も学びがありました。 これを機会に、Amazon Forecastをもっと活用していこうと思います。










