
Understanding intention with Nova, stability with Titan. Comparing search accuracy of 4 Embedding models using LLM-as-a-Judge
This page has been translated by machine translation. View original
In the previous article, we registered about 60,000 blog posts from DevelopersIO in Amazon S3 Vectors and built a serverless semantic search environment.
This time, we compared the search accuracy of four Embedding models using this environment. We'll explain how we reached the conclusion to "use Nova Embed and Titan V2 in combination according to their strengths" by having LLM-as-a-Judge automatically score search results for identical queries.
Comparison Target Models
| Model | Provider | Dimensions | Execution Environment |
|---|---|---|---|
| Amazon Nova Embed | AWS (Bedrock) | 1024 | Bedrock API |
| Amazon Titan Embed V2 | AWS (Bedrock) | 1024 | Bedrock API |
| multilingual-e5-large | Microsoft (OSS) | 1024 | EC2 |
| ruri-base | Hugging Face (OSS) | 768 | EC2 |
We compared two Bedrock managed models and two OSS models.
For the approximately 60,000 blog posts mentioned above, we vectorized Japanese summaries of about 165 characters and English summaries of about 60 words with each model, and registered them as separate indices in S3 Vectors (4 models × 2 languages = 8 indices).
Evaluation Method
Search Queries (33 types × 12 patterns)
Assuming actual use cases, we prepared the following 12 patterns. These are broadly divided into "same-language search," where the query and search target are in the same language, and "cross-lingual search," which searches across different languages.
Same-Language Search:
| # | Test Pattern | Query Example | Purpose |
|---|---|---|---|
| 1 | Japanese→Japanese | "Lambda コールドスタート 対策" | Basic performance |
| 3 | English→English | "RAG hallucination prevention" | English basic performance |
| 4 | Single word→Japanese | "React" "Lambda" | Noise resistance |
| 5 | Single word→English | "S3" "CDK" | Noise resistance (English) |
| 6 | Synonym→Japanese | "サーバーレス関数 タイムアウト 変更" | Synonym understanding |
| 8 | Intent/Issue→Japanese | "コンテナが勝手に再起動を繰り返す" | Intent understanding |
| 10 | Niche tech→Japanese | "Projen を使ったプロジェクト管理" | Low-frequency topics |
Cross-Lingual Search:
| # | Test Pattern | Query Example | Purpose |
|---|---|---|---|
| 2 | English→Japanese | "Lambda cold start mitigation" | Cross-lingual basic |
| 7 | Synonym (EN→JP) | "Increase Lambda execution time" | Cross-lingual synonyms |
| 9 | Intent/Issue (EN→JP) | "ECS Fargate tasks restarting loop" | Cross-lingual intent understanding |
| 11 | Niche tech (EN→JP) | "Benefits of using IAM Roles Anywhere" | Cross-lingual low-frequency |
| 12 | Japanese→English | "Lambda コールドスタート 対策" | Reverse cross-lingual |
Evaluation Metric: nDCG@10 × LLM-as-a-Judge
We passed the Top-10 results of each search to an LLM for scoring on a scale of 0-100. To improve judgment accuracy, we had the LLM read not just the article titles but also the RAG summaries in both Japanese and English.
| Score | Meaning |
|---|---|
| 100 | Contains a direct answer/solution to the query |
| 80 | Closely related and very useful |
| 50 | Topic is correct but falls short of addressing the intent |
| 20 | Contains the same words but different content |
| 0 | Unrelated |
We calculated nDCG (Normalized Discounted Cumulative Gain) from the scores. This metric is higher when better results appear at the top, with 1.0 being ideal.
We used Gemini 3.0 Pro as the Judge. For reference, we also scored the same data with Claude Sonnet 4.5 (Amazon Bedrock) to compare between Judges.
Test Environment
| Item | Value |
|---|---|
| S3 Vectors indices | 8 (4 models × 2 languages) |
| Number of articles | About 60,000 / index |
| Search queries | 33 types |
| Test patterns | 12 types (7 same-language + 5 cross-lingual) |
| Search count | 180 times |
| Judge | Gemini 3.0 Pro (main) / Claude Sonnet 4.5 (reference) |
| Region | Bedrock: us-east-1 / S3 Vectors: us-west-2 |
Results
Overall Ranking
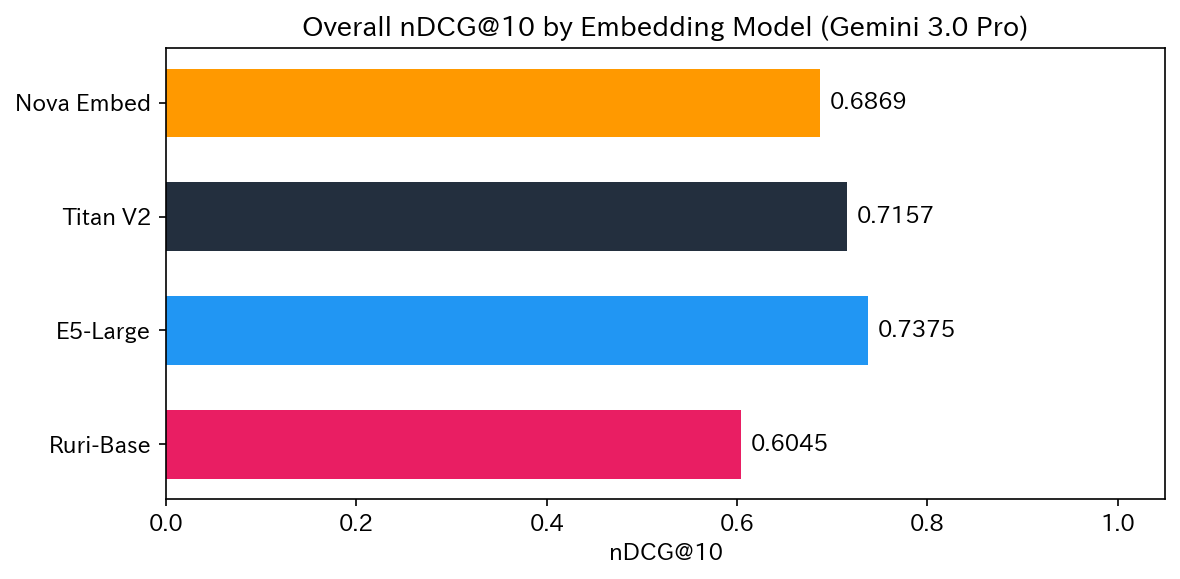
| Rank | Model | nDCG@3 | nDCG@10 |
|---|---|---|---|
| 1 | E5-Large | 0.7922 | 0.7375 |
| 2 | Titan V2 | 0.7826 | 0.7157 |
| 3 | Nova Embed | 0.7438 | 0.6869 |
| 4 | Ruri-Base | 0.6600 | 0.6045 |
Overall, E5-Large ranked 1st, but the picture changes significantly when looking at individual test patterns.
Same-Language Search
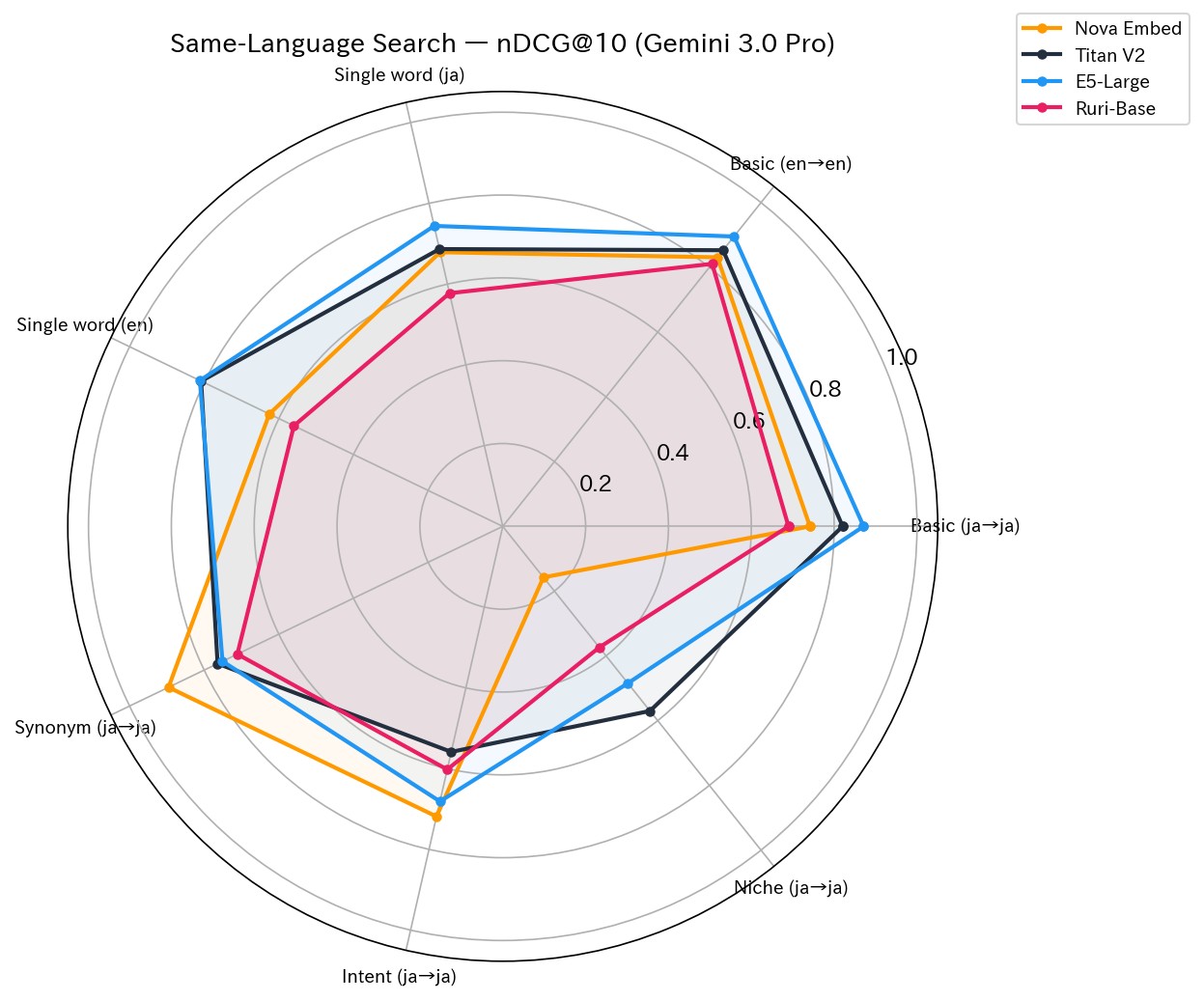
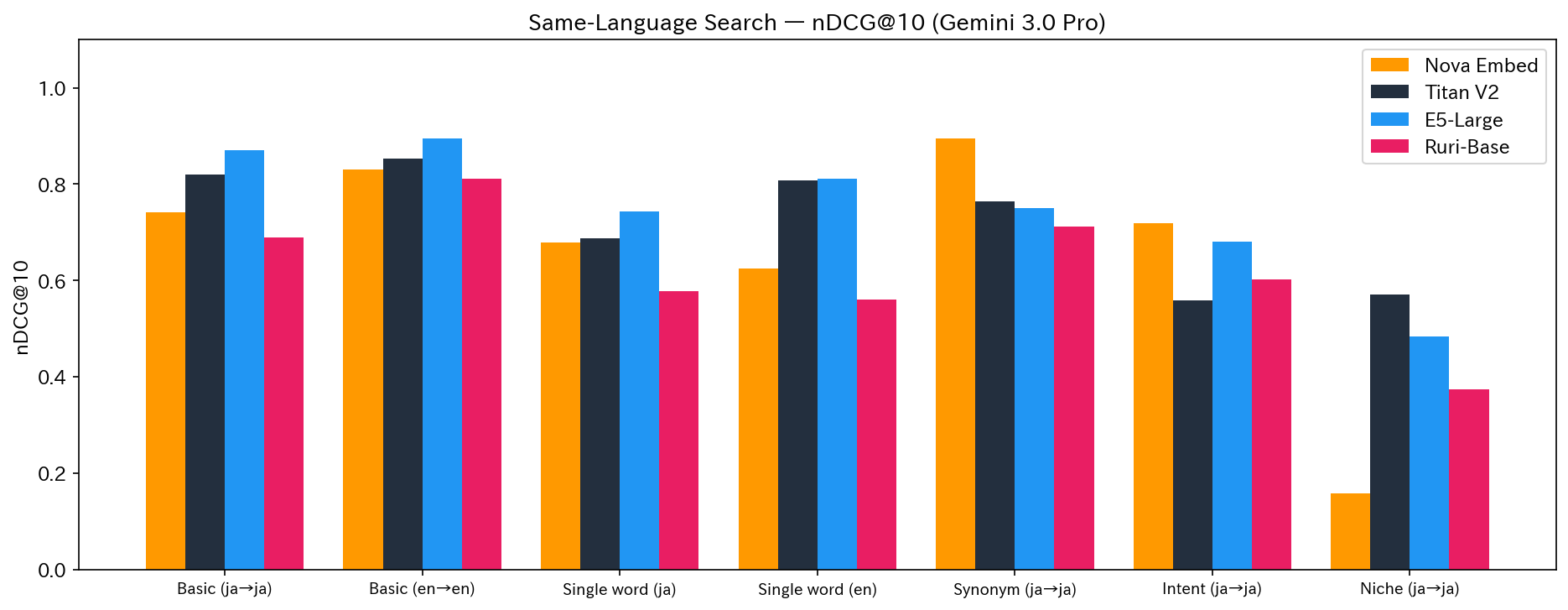
| Test | Content | Nova | Titan | E5 | Ruri | 1st Place |
|---|---|---|---|---|---|---|
| test1 | Basic (ja→ja) | 0.7415 | 0.8205 | 0.8711 | 0.6898 | E5 |
| test3 | Basic (en→en) | 0.8310 | 0.8529 | 0.8953 | 0.8108 | E5 |
| test4 | Single word (ja) | 0.6790 | 0.6868 | 0.7441 | 0.5775 | E5 |
| test5 | Single word (en) | 0.6254 | 0.8082 | 0.8116 | 0.5596 | E5 |
| test6 | Synonym (ja→ja) | 0.8956 | 0.7640 | 0.7510 | 0.7111 | Nova |
| test8 | Intent (ja→ja) | 0.7187 | 0.5586 | 0.6813 | 0.6022 | Nova |
| test10 | Niche (ja→ja) | 0.1576 | 0.5701 | 0.4846 | 0.3738 | Titan |
For basic keyword searches (tests 1, 3, 4, 5), E5-Large won across the board. Meanwhile, Nova dominated in synonym recognition (test6) and intent understanding (test8).
Cross-Lingual Search
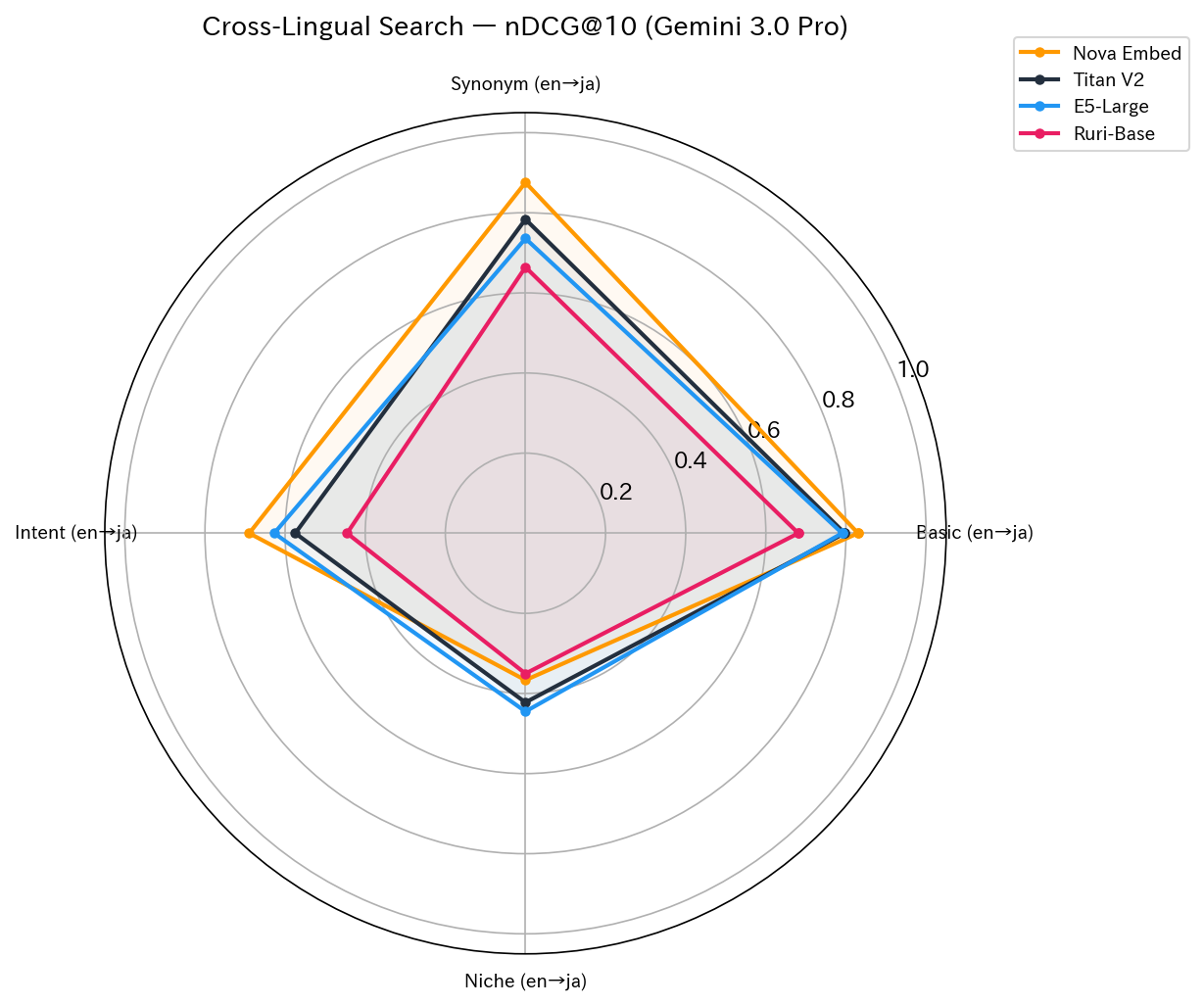
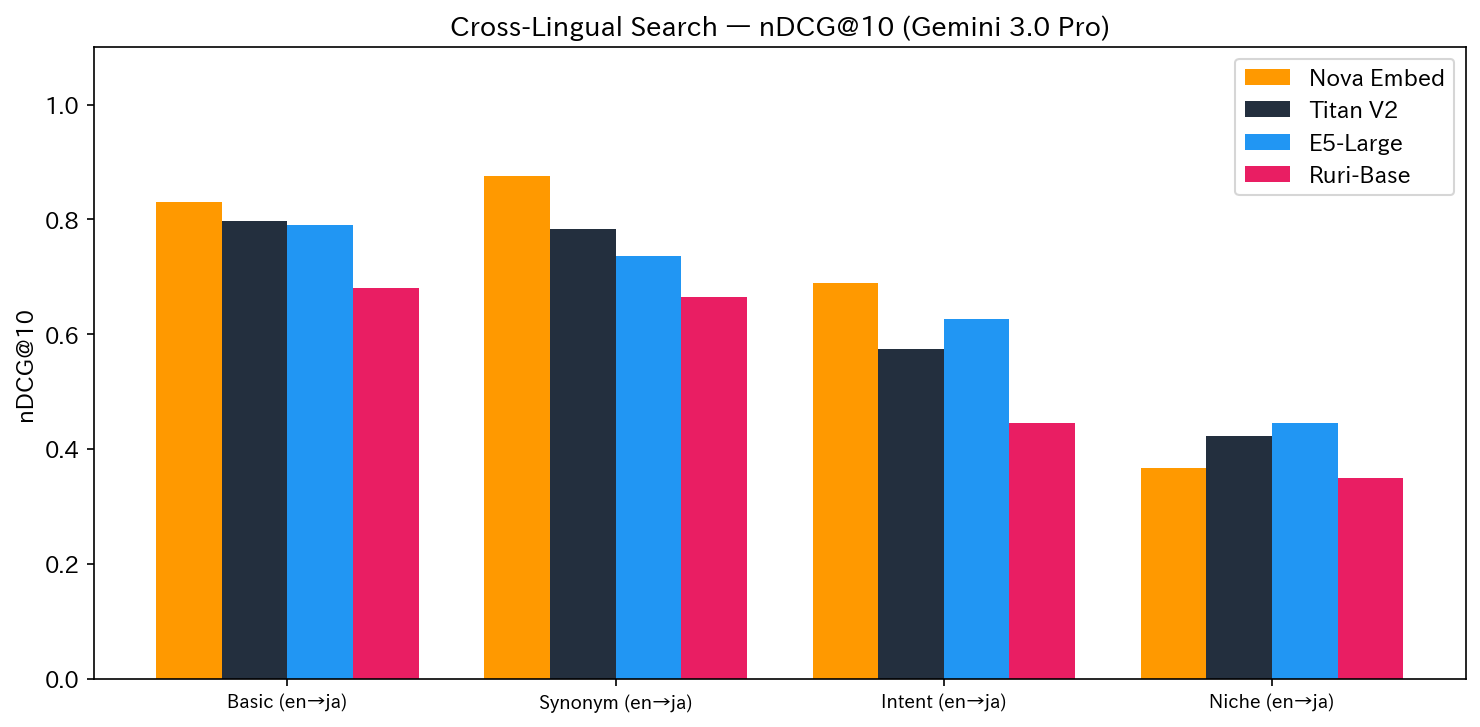
| Test | Content | Nova | Titan | E5 | Ruri | 1st Place |
|---|---|---|---|---|---|---|
| test2 | Basic (en→ja) | 0.8302 | 0.7969 | 0.7904 | 0.6810 | Nova |
| test7 | Synonym (en→ja) | 0.8755 | 0.7837 | 0.7358 | 0.6642 | Nova |
| test9 | Intent (en→ja) | 0.6895 | 0.5746 | 0.6271 | 0.4453 | Nova |
| test11 | Niche (en→ja) | 0.3667 | 0.4224 | 0.4451 | 0.3504 | E5 |
| test12 | Basic (ja→en) | 0.7250 | 0.9511 | 0.9603 | 0.6529 | E5 |
For en→ja, Nova ranked 1st in 3 out of 4 patterns, showing outstanding ability to find Japanese articles from English queries.
However, in our additional ja→en test (test12: Japanese query → English index), the results were reversed. With the query "RAG ハルシネーション 対策" (RAG hallucination countermeasures), Nova's Top-6 were all unrelated articles (conference reports, anime introductions, etc.) resulting in nDCG@10 = 0.33, while Titan (0.95) and E5 (0.96) maintained stable accuracy. We discovered that Nova's cross-lingual capability has asymmetry between en→ja and ja→en.
Same-Language vs Cross-Lingual
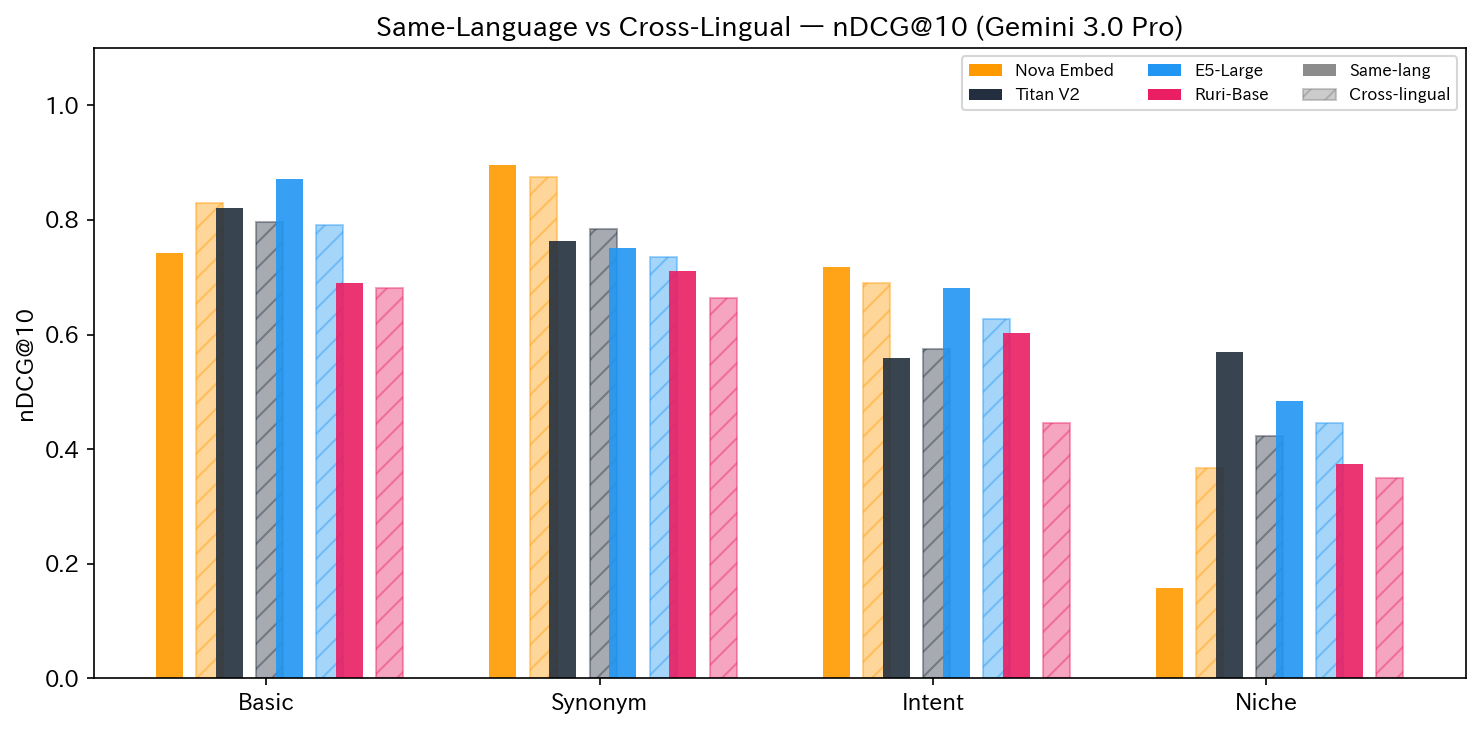
Comparing same-language and cross-lingual searches in the same category revealed interesting trends.
- Nova: Showed almost no drop in accuracy for en→ja (Basic: 0.74→0.83, Synonym: 0.90→0.88). However, it collapsed on some ja→en queries, showing asymmetry in cross-lingual capabilities
- Titan / E5: Maintained stable accuracy for ja→en. Due to the higher information content in English summaries, ja→en sometimes scored higher than ja→ja
- Ruri: Showed significant accuracy decline in cross-lingual searches (Intent: 0.60→0.45, react_hooks ja→en: nDCG=0.0)
- Niche: All models struggled with both same-language and cross-lingual searches
Heatmap (All Patterns)
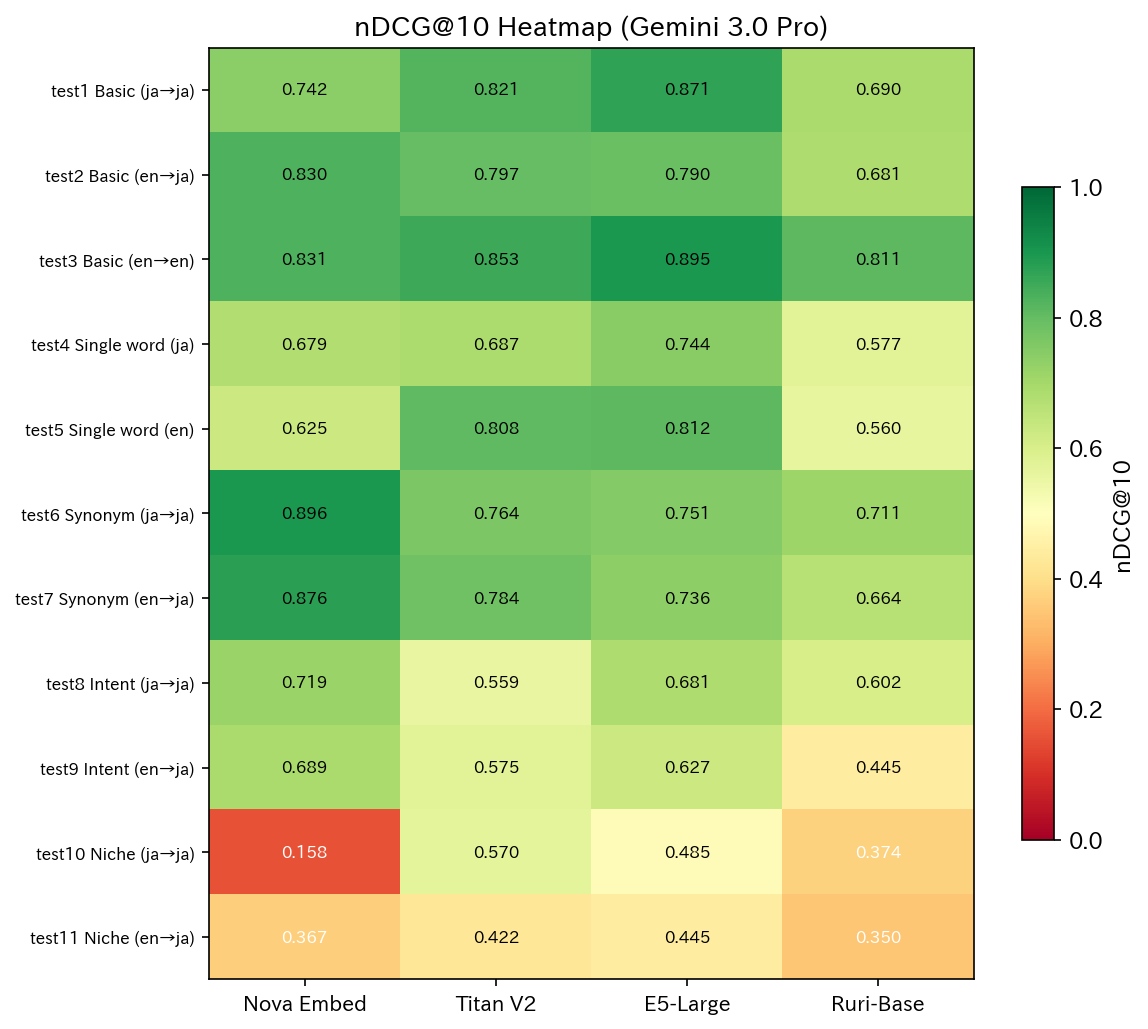
Model Characteristics
Nova Embed: Strong in Intent Understanding and Synonyms, Weak in Niche Topics
Nova excelled in synonym recognition (test6: 0.8956) and intent understanding (test8: 0.7187), outperforming other models.
Here's a specific example of a synonym-type query (test6). We searched for "サーバーレス関数 タイムアウト 変更" (serverless function timeout change), which doesn't use AWS's official terminology.
Nova Embed (Top-3):
- Fixed an issue where Lambda functions execute multiple times by setting timeout and retry count → score: 100 ✅
- How to check if a Lambda function has timed out from its logs → score: 75
- Created a Lambda to recover Lambda functions that failed due to timeout → score: 65
Titan V2 (Top-3):
- How to change the execution timeout time of AWS Systems Manager RunCommand? → score: 75
- How to change the integration timeout in API Gateway → score: 95
- [New Feature] Changing timeout values for AWS Elastic Load Balancing (ELB) → score: 40
Nova understood that "serverless function" = "Lambda" semantically, with all Top-3 results being Lambda-related. Titan was literal with "timeout change" as keywords, mixing in non-Lambda services like SSM and API Gateway.
Here's an example of intent understanding (test8). We input the natural language description of a problem situation: "コンテナが勝手に再起動を繰り返す" (containers repeatedly restart on their own).
Nova Embed (Top-3):
- Unintended restarts during AMI creation → score: 20
- Auto-restart with systemd during exceptions → score: 75
- ECS tasks with CannotPullContainerError during ECR image updates → score: 95 ✅
Titan V2 (Top-3):
- Unintended restarts during AMI creation → score: 30
- Handling EC2 maintenance requiring restart → score: 35
- How to keep Windows containers running in ECS → score: 75
Nova successfully included a high-scoring ECS-related article (score: 95) in its Top-3. Titan only matched on the words "restart" and "container," failing to bring articles that matched the intent to the top positions.
Conversely, for niche technology (test10: 0.1576), the positions were reversed. For the query "Projen を使ったプロジェクト管理" (Project management using Projen):
Nova Embed (Top-3):
- Backlog management using GitHub Projects (product/sprint) → score: 20
- How to manage Issues and sub-Issues appropriately using Project → score: 20
- Introducing project management to (non-engineer) staff work → score: 15
Titan V2 (Top-3):
- Regular AWS CDK App development became comfortable using projen → score: 95 ✅
- [Report + Try] projen – a CDK for software project configuration #CDK Day → score: 95 ✅
- Project Management #1 → score: 15
Nova was drawn to the general meaning of "project management" and failed to find any Projen-related articles. Titan accurately captured the proper noun "Projen" and successfully hit related articles in its Top-2. This is a good example where Nova's semantic understanding worked against it, and Titan complemented it.
Titan Embed V2: Stable Second Place
While Titan doesn't have outstanding strengths, it consistently ranked 2nd-3rd across all patterns. It took 1st place for niche technology (test10: 0.5701) where Nova failed, showing it has few weaknesses and is a balanced model.
OSS Models (E5-Large / Ruri-Base): High Basic Performance but Operational Challenges
E5-Large ranked 1st in Japanese basic search (test1: 0.8711), English basic search (test3: 0.8953), and single-word searches (test4/5). It's the most accurate model for textbook search queries. However, it fell behind Nova in synonym recognition and intent understanding.
Ruri-Base ranked last in all 12 patterns, but considering its handicap of having fewer dimensions (768) than other models (1024), it performed reasonably well.
However, OSS models presented operational challenges. Real-time vectorization of search terms requires model loading and inference. It's difficult to achieve practical latency in CPU-only environments like Lambda, and keeping GPU instances running constantly isn't cost-effective.
While there was potential for using these models for similar article searches with pre-vectorized data, we decided against adopting OSS models since we had no plans for model fine-tuning or custom optimization, and instead focused on Bedrock's managed models.
Vectorization Speed
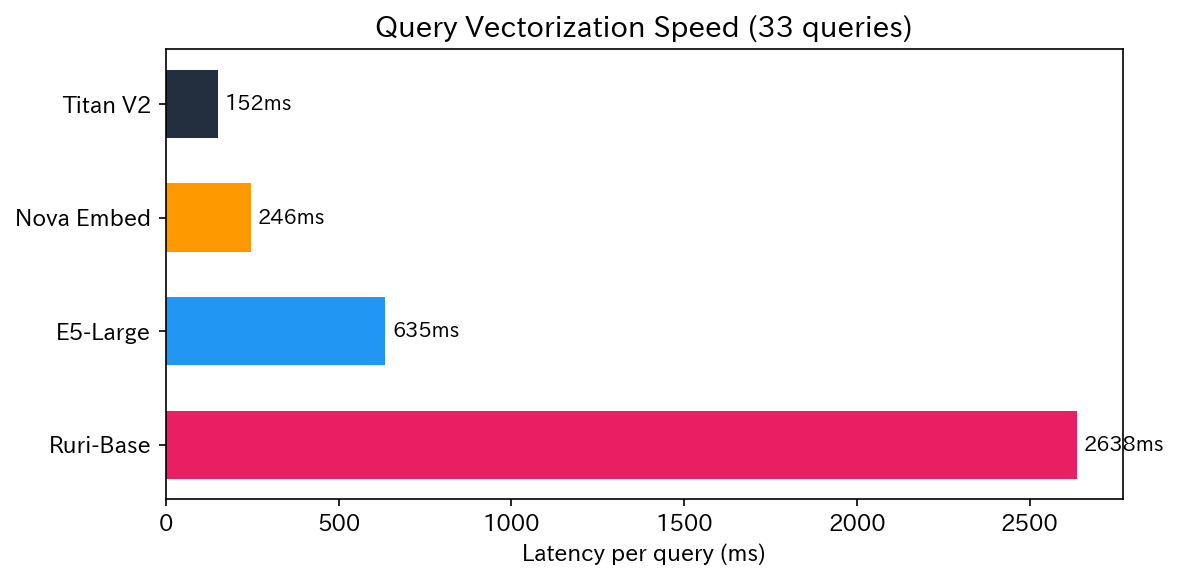
| Model | Initialization | Inference (33 items) | Per item | Execution Environment |
|---|---|---|---|---|
| Titan V2 | 0.1s | 5.0s | 152ms | Bedrock API |
| Nova Embed | 0.1s | 8.1s | 246ms | Bedrock API |
| E5-Large | 57.8s | 21.0s | 635ms | EC2 |
| Ruri-Base | 4.9s | 87.0s | 2,638ms | EC2 |
Models via Bedrock API were fast with no initialization needed. OSS models required Docker container startup and model loading, with E5-Large taking about a minute for initialization, which was a drawback.
Reference: Sonnet's Second Opinion
To verify Judge bias, we also had Claude Sonnet 4.5 (Amazon Bedrock) score the same data.
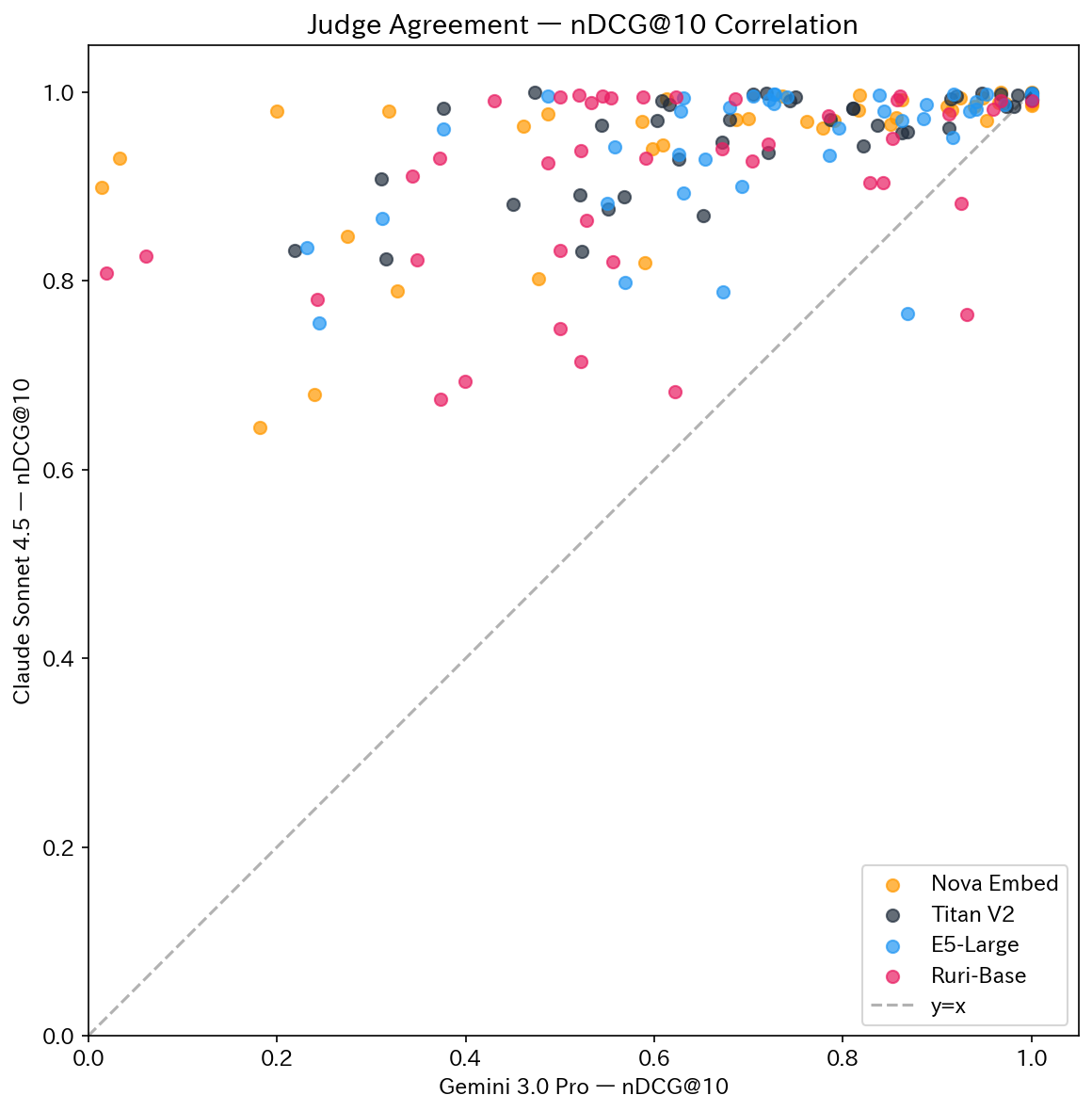
Gemini used the 5-level scale (0/20/50/80/100) as instructed, which clearly differentiated between models. Sonnet, however, used continuous values from 0-100 (69% of 1,640 evaluations used non-specified values), resulting in all models clustering between nDCG@10 = 0.90-0.95 with little differentiation.
| Test | Gemini 1st | Sonnet 1st | Match |
|---|---|---|---|
| test2 Cross-lingual basic | Nova | Nova | ✓ |
| test6 Synonyms | Nova | Nova | ✓ |
| test7 Synonyms (EN→JP) | Nova | Nova | ✓ |
| test8 Intent understanding | Nova | Nova | ✓ |
| test9 Intent (EN→JP) | Nova | Nova | ✓ |
| test10 Niche technology | Titan | Titan | ✓ |
| test1 Basic (JP→JP) | E5 | Titan | ✗ |
| test3 Basic (EN→EN) | E5 | Titan | ✗ |
| test4 Single word (JP) | E5 | Ruri | ✗ |
| test5 Single word (EN) | E5 | Titan | ✗ |
| test11 Niche (EN→JP) | E5 | Nova | ✗ |
The top-ranked models matched in 6/11 cases (55%). Patterns where Nova excelled (cross-lingual, synonyms, intent understanding) and where Titan excelled (niche technology) were consistent across both Judges, but basic searches and single-word searches varied between E5 and Titan. Since LLM-as-a-Judge rankings can change depending on the Judge selected, please consider these results as relative trends.
Conclusion
Bedrock Model Selection Guidelines
| Use Case | Recommended Model | Reason |
|---|---|---|
| Cross-lingual search (EN→JP) | Nova Embed | Highest accuracy for English query → Japanese content |
| Handling variants and synonyms | Nova Embed | Understands "serverless function" → "Lambda" |
| Natural language problem searches | Nova Embed | Highest intent understanding capability |
| Keyword search & niche technology | Titan V2 | Stable with few weaknesses, complements Nova's weak areas |
Overall Assessment
This comparison clearly revealed each model's strengths and weaknesses.
In terms of "overall score," the OSS model E5-Large ranked 1st, but for our semantic search platform, we prioritize use cases where users input their "problems" vaguely in natural language, rather than searches with clear keywords.
Therefore, instead of focusing on overall score, we valued strengths in "intent understanding (test8)" and "synonym recognition (test6)," and decided to adopt Nova Embed as our main model, as it's a Bedrock managed model that doesn't require infrastructure management like GPUs.
However, through testing, we also identified areas where Nova struggles, such as niche technologies and single-word keyword searches. For these areas, we're considering using Titan V2, which has few weaknesses and is stable, to complement Nova in a combined approach that leverages the strengths of each model.