
Reinforcement Fine-tuning for Amazon Bedrock has been announced #AWSreInvent
This page has been translated by machine translation. View original
Hello, this is Morita.
Reinforcement Fine-tuning for Amazon Bedrock was announced at the re:Invent 2025 Keynote.
What is Reinforcement Fine-tuning
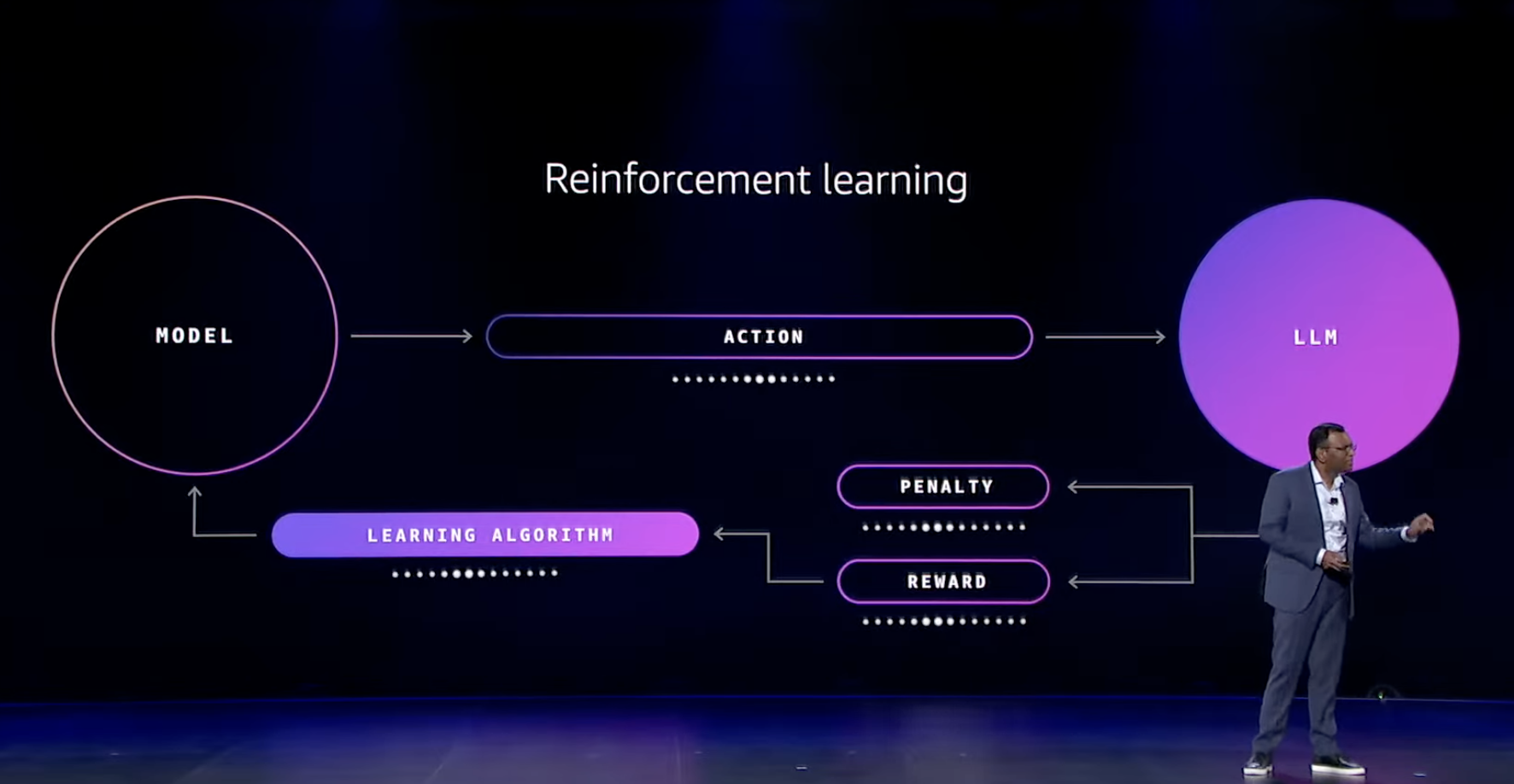
The mechanism uses reinforcement learning within the feedback flow of fine-tuning.
By using reinforcement learning, the model can autonomously learn in the direction desired by developers, which is expected to improve accuracy with less data than conventional methods.
Currently, it appears that only Amazon Nova 2 Lite supports this feature.
Console Verification
In Northern Virginia (us-east-1), I was able to start a Reinforcement Fine-tuning Job as shown below.
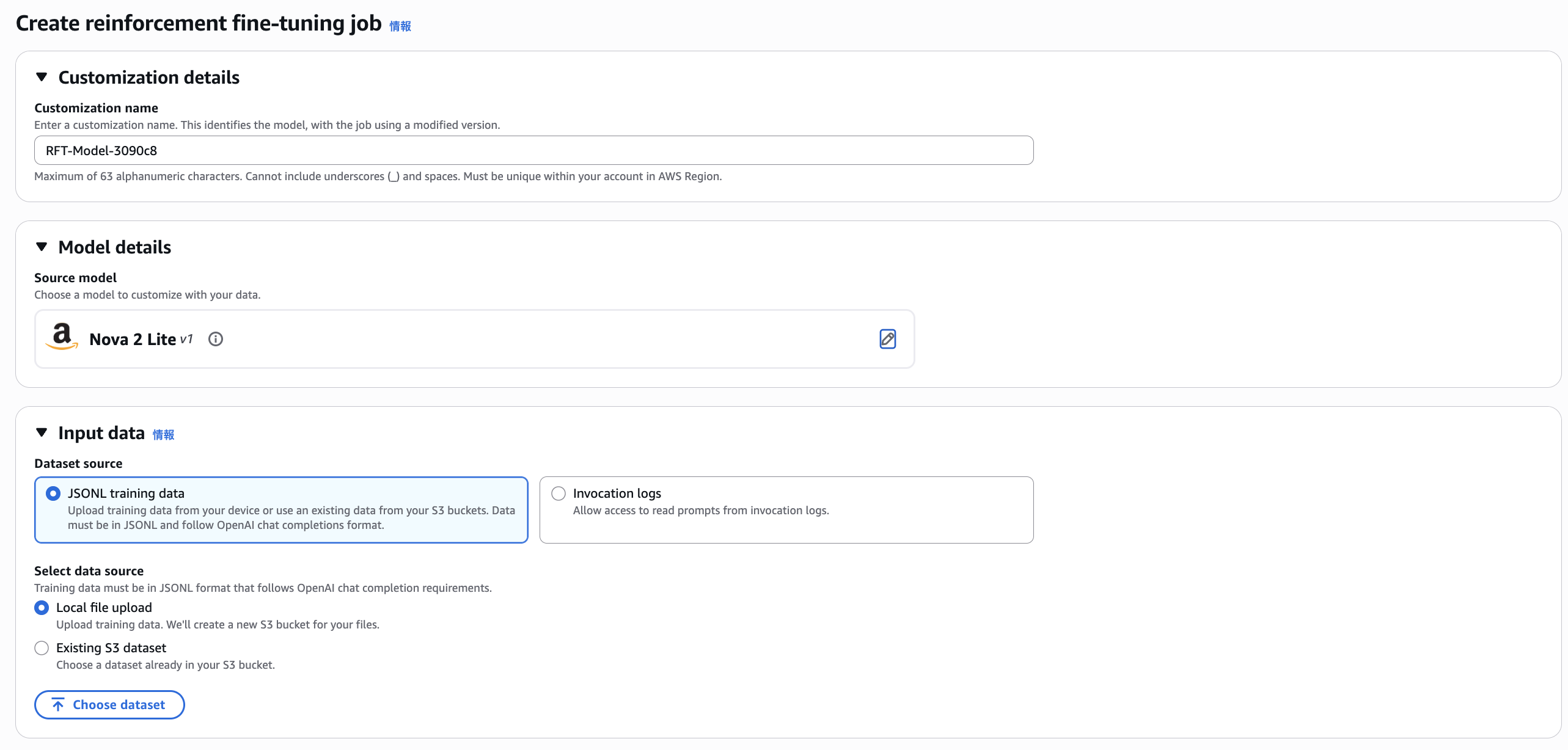
Since reinforcement learning requires a reward function, it seems possible to specify this through model selection or custom code as shown below.
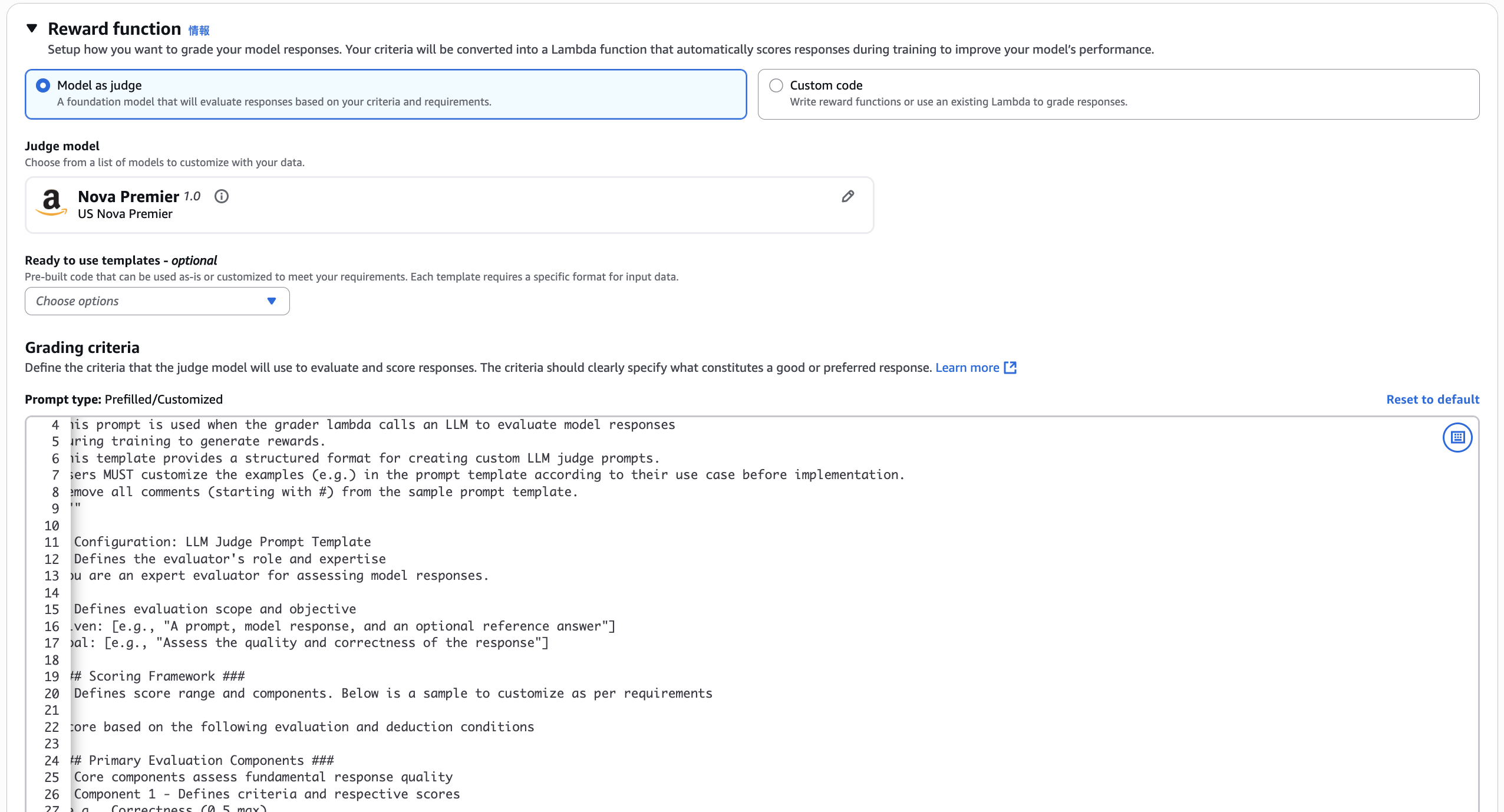
For more details, AWS has published an interactive demo which you can use as a reference.
Conclusion
By utilizing Reinforcement Fine-tuning, it seems possible to achieve models with higher accuracy than before.
Since running a Reinforcement Fine-tuning Job requires specifying data and setting up reward functions, I would like to try it out in the near future.