
Report "Grafana Labs' Development Organization Where All Engineers Are On-Call, and Open Source Standards" #grafanaJP
This page has been translated by machine translation. View original
"This is amazing... The Grafana Lab's development organization is being this open and honest with us..."
On March 18, 2026, I participated in "Grafana Meetup Japan #8" as part of the organizing team. The theme this time was "Grafana's Development Organization and Open Standards." Guest speakers included Dee Kitchen, VP of Engineering at Grafana Labs, and Ted Young, co-founder of OpenTelemetry and Developer Programs Director at Grafana Labs, who spoke following the recently held ObservabilityCon on the Road Tokyo. They shared insights about Grafana Labs' internal development organization and the philosophy behind OSS projects—information that's rarely disclosed.
Dee Kitchen is the VPoE overseeing Grafana Labs' database teams working on Loki, Mimir, Tempo, and Pyroscope, while Ted Young is a co-founder of OpenTelemetry and a member of its Governance Committee—both are key figures in the observability industry.
Having these two individuals together discussing Grafana Labs' engineering organization and how to start OSS projects made for an incredibly valuable event, which I'll summarize here.
This article is compiled from transcriptions of the event. While the talks were in English with Japanese interpretation, I've structured the content to preserve the presenters' original nuances as much as possible.
Session 1: How Grafana Builds Software — How Grafana Develops Their Products

Session 1 featured Dee Kitchen (Grafana Labs VP of Engineering) introducing Grafana Labs' engineering organization and development process.
Engineering Principles: Autonomy and Ownership
We place great emphasis on autonomy and ownership. Managers don't make top-down decisions. We expect engineers to teach us bottom-up about "what's right" and "which tools to use."
By the way, look at the right side. We don't use Jira.
Taking any of these principles to extremes would be disastrous. What we aim for is harmony and balance across all principles. The engineering environment must be a place where engineers can perform at their best. Not for managers.
Globally Distributed Organizational Structure
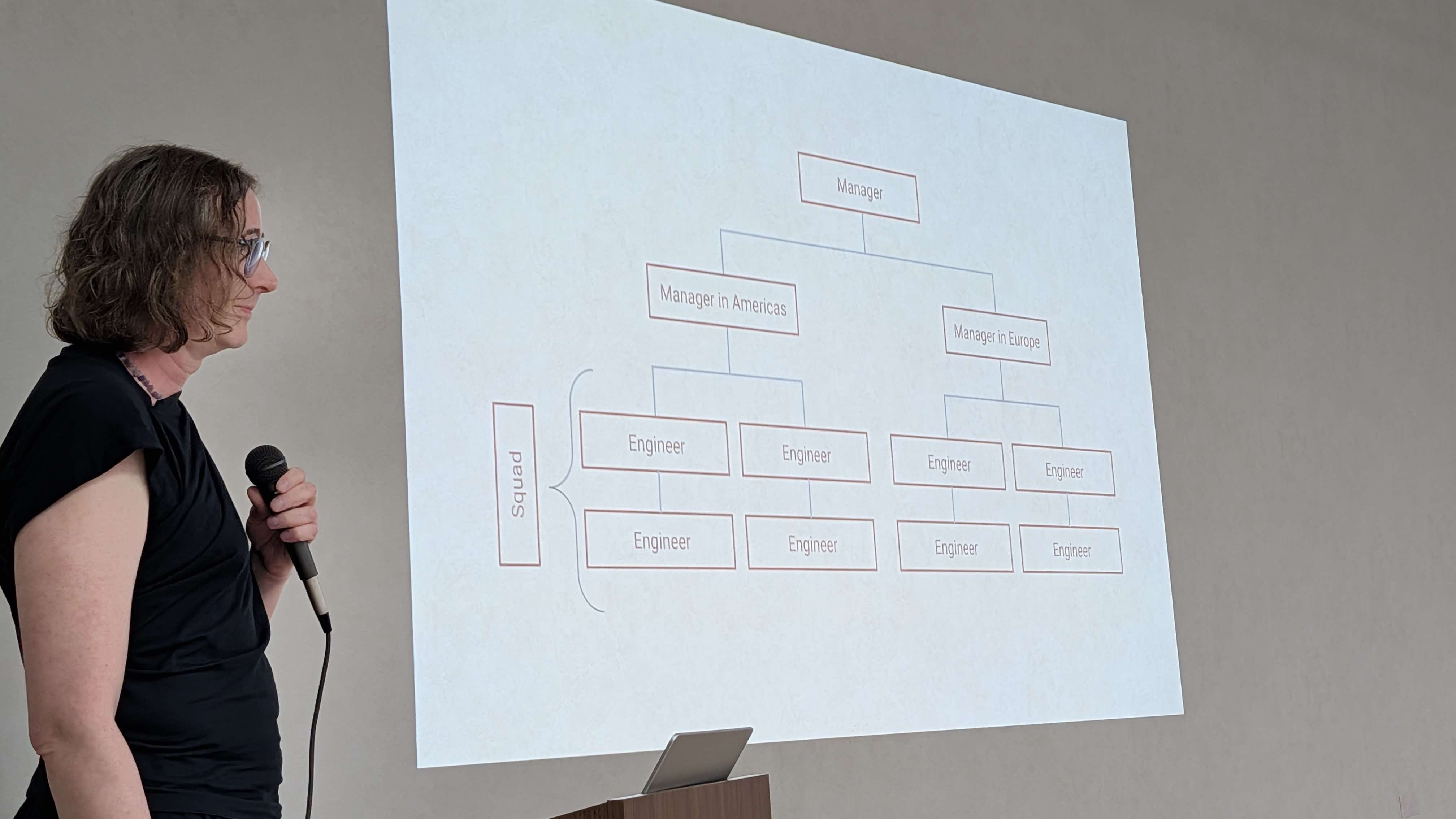
Let me show you concrete examples of how these principles manifest in our organizational structure.
Imagine we have a squad (team). We distribute that team across the globe. Sometimes we only have 3-4 people in one region, which might cover the entire Americas.
However, we operate on-call with a "Follow the Sun" approach. To have engineers on-call only during daytime hours, we need at least two regions. Since everyone needs to be on-call at least once a month, we need at least 4 people per region. So a squad must have at least 6-8 people across a minimum of 2 regions.
Furthermore, our principles state that every engineer must have a manager in their region. This means each squad has multiple managers. That's interesting! Many managers were used to being the only manager in a squad. New managers initially wonder, "What do you mean I have to share leadership?"
To prevent managers from centralizing power, we set the average number of direct reports at 8-10 per manager. Even when it looks like they only have 4 subordinates, we intentionally assign more people to prevent managers from micromanaging.
By now you should understand: Managers don't have power. They only have influence.
Deployment via a Monorepo
Next, let me talk about our deployment system as another element to understand this environment.
We use a single GitHub repository. Internally, we call it "Deployment Tools." Engineers will immediately notice there are 26,500 branches and 720,000 commits. This single repository essentially defines one thing: "What Grafana Cloud should be."
We deploy Grafana Cloud on AWS, GCP, and Azure. That's 25 physical regions with 50 logical regions. Engineers don't need to think about cloud service providers.

Deployment Tools consists of two technologies. The first is Jsonnet, a project from Google that extends JSON. We're probably its largest user as a major OSS. It allows formal descriptions of JSON, making it clear what you've written.
The second is Tanka, a tool that converts Jsonnet definitions into something cloud providers can actually execute. It can also handle Kubernetes configurations, control scheduling, and generate readable diffs of changes.
80% of changes are executed by bots. To be clear, this is not AI. Take tenant limit updates, for example. Instead of issuing support tickets and making physical configuration changes, bots safely implement changes.
The purpose of this system is simple: to allow engineers to focus on engineering. Not operations. This makes engineers happy. Because they are on-call and responsible for all the code they write.
Hackathons: Half of Our Product Features Come From Here
When you give engineers this much authority, interesting things happen.
We hold hackathons internally at Grafana Labs. About half of all engineers participate, four times a year, one week each time. Many companies do hackathons, but we're a bit extreme. About half of what gets built during hackathons is released as actual product features.
We want this to feel like a one-week startup. Participants make video pitches presenting their projects and results. Rankings are determined by company-wide voting, and winners receive prize money.
We want engineers to feel the pain of the problems they face. If you want to build tools for engineers, the engineers themselves should use those tools and feel the problems. We run this cycle monthly, not yearly.
Open Source and Licensing
We're an open source company. We have guidelines on which licenses to apply and when. Our basic philosophy is to provide appropriate licensing structures for software that gets installed in user environments—in other words, software that goes onto your machine.
On-Call: Four Responsibilities for All Engineers
As mentioned earlier, all engineers take on-call duties. At least one week per month, at least 12 hours per week. Engineers on-call must monitor multiple things.
First, SLOs (Service Level Objectives). This is most important. We must have reliable systems. No one will buy unreliable systems.
But it's easy to create a reliable system by scaling up and spending money. So second is TCO (Total Cost of Ownership). You have the responsibility to maintain balanced service costs.
Third, vulnerabilities and security. You must apply patches. A reliable and cost-efficient service is meaningless if it's not secure.
And fourth, resilience. The responsibility to ensure the service can withstand attacks and failures.
Q&A: How Engineers Are Evaluated
Questioner: "You mentioned there's a clear distinction between engineers and managers, and that managers have no power. So how are engineers evaluated?"
"We evaluate engineers based on business outcomes. You can work on whatever you want. However, if it doesn't generate valuable business outcomes for us, that work effectively isn't recognized. Engineers themselves must choose the right work. In other words, a business mindset is required."
Questioner: "So even if engineers want to work on something new, they need to consider how it contributes to Grafana Cloud's business. Proposals require a business mindset, and unless they clearly understand how their deliverables contribute to the company's overall business, they won't be recognized. So engineering plus business perspective, plus on-call duties. Is that what's expected of Grafana Labs engineers?"
"Correct."
Session 2: How to Start an Open Source Project — How Open Source Projects Are Born

Session 2 featured a talk by Ted Young (OpenTelemetry co-founder, Grafana Labs Developer Programs Director).
Hello everyone. I'm Ted Young on the internet. I was asked to talk about how to start an open source project. It's really simple. Just create a new project on GitHub.

But in reality, I have some advice. I've been involved with open source for a long time. Probably too long. So long that I don't even look like my GitHub avatar anymore. I keep trying to take new photos, but somehow they all turn out worse. I've worked on various projects including Apache projects, Node.js, Ruby on Rails, and Cloud Foundry.
What I'm going to talk about is what I consider "keys to harmony." There's no right or wrong. However, when starting a project, it's important to have clarity and agreement on these things.
Three Motivations for Individuals to Start OSS
There are three reasons individuals create OSS projects: Fun, Passion, and Professional.
Fun. This is the best reason, right? Creating software for yourself. In a way, this is the purest form of open source. You do it because you want to. That's it.
The next most common reason is Passion. What I mean is that you care about whether the software works correctly. Not for money, not because you're maintaining it as a job. But it's important to you that the software works. In other words, this software is no longer just for you.
And the third is of course Professional. Cases where you create software as a job. It's done to generate economic activity, and people generally receive salaries or some form of compensation.
"Support is No Fun"
My one piece of advice for individuals is this:
Support is no fun.

When your project needs support, when people come to you for support, it means your project has become important. But it also means it's no longer fun. Because it's no longer for you. It's for the people you're supporting.
Here you have a choice. Either you're passionate about the people using this software and why they use it, so you continue providing support for free. Or this software has entered the Professional realm, and you should receive some form of compensation.
You're providing support, but you're neither passionate about these people nor receiving compensation. This is your ego trapping you. Don't be fooled by your ego. Tell people: "I created this for fun, and there are no guarantees."
This is the most important thing for individuals.
Success Conditions for Large-Scale OSS
Now if you want advice about large-scale professional OSS projects, I have some. If for some reason you're trying to start one.
When thinking of large-scale open source, you probably imagine the Linux Foundation, Linux, Kubernetes, OpenTelemetry—shared infrastructure. But don't forget the largest open source project in history: The Internet. It's much bigger. Because it's not about shared infrastructure, it's about communication.
There are four factors for large-scale software to succeed.
First, protocols. The largest OSS projects related to communication aren't built on top of applications. They're built on top of protocols. Applications are built on top of protocols. The true application is the protocol itself. That's how everything on the internet works, right? HTTP, FTP, BitTorrent, even email.
Second, modularity. Large-scale projects must be useful even when not complete. In fact, they never will be complete. Even the internet isn't a single protocol but a stack of protocols developed one by one.
Third, redundancy. Not just software redundancy. The organizations creating the software must not have single points of failure.
And finally, of course, money. Large-scale projects require a lot of engineering time, which requires funding.
Practices at OpenTelemetry
Let me show you concrete examples of how we've addressed these issues at OpenTelemetry.
Most importantly, OpenTelemetry is actually a protocol. Implementation requires a lot of effort, so it might seem like implementation is most important. But implementation is completely optional. What's important is the protocol.
Of course, those familiar with OpenTelemetry have heard of OTLP. This is our main protocol. But in fact, we're developing several other protocols. One based on Apache Arrow, and STEP, a more efficient metrics protocol.
But actually, the most important part of OpenTelemetry is also the most boring part. That's Semantic Conventions. They define what an HTTP request is, what an SQL database call is, and everything we report. To ensure it's reported the same way every time, regardless of where it's reported from.
This is true open source. Sending data. Whether using OTLP or other protocols. If the data follows semantic conventions, it's OpenTelemetry. It doesn't matter how the data was created or how it was sent.
About modularity. We keep all parts of OpenTelemetry loosely coupled. This is actually a difficult design challenge. We often hear: "Why not put this feature in the Collector, assuming everyone uses the Collector, which would be simpler than putting it in all SDKs." But if we coupled all implementations together and made it so you had to use all our implementations to use OpenTelemetry, we would be providing a hairball, not a protocol.
Regarding vendor-neutral governance. To eliminate single points of failure, we have a rule that no more than 2 people from the same organization can occupy key positions like the Governance Committee or Technical Committee.
And the monetization model. We're explicit about how to make money with OpenTelemetry. Share data. Standardize data. Compete on analysis. Data is standard, analysis is a green field.
This is a lesson learned from early Kubernetes. In the early days of Kubernetes, it wasn't clear how to make money. It wasn't clear who owned the software. Startups like Coros and Heptio seemed to own the software, and when someone submitted a proposal, it wasn't clear if it was a good proposal or a clever proposal from a startup trying to make money. Engineering could be stressful.
OpenTelemetry has few such problems. Because everyone agrees on the rules of the game.
Among projects people try to donate to OpenTelemetry, some look interesting and useful but don't match our motivational model. We can't accept them because we can't guarantee they'll be maintained after the original maintainers retire. These are typically projects built on top of OpenTelemetry, like DevTools, CLIs, and data visualizations.
But I actually think we're saving people by saying "No" to these projects. Because things built on top of OpenTelemetry should be Fun.
So my request to everyone here: Think about what you can do with observability and OpenTelemetry. But think of it as a fun journey. Create projects and share them with people. Don't worry about support. I'm really looking forward to seeing what you all create.
Ask Me Anything (AMA)
After a break, Dee Kitchen and Ted Young held an AMA session. They answered questions from participants in real-time. Here are the highlights from the most engaging topics.
Code Security Measures
Question: Regarding the goal of keeping code secure, what specific challenges do you face and what countermeasures do you implement, to the extent you can share?
Dee Kitchen: We face supply chain risks. Our projects have over a million installations and are used in almost every country.
Under a very talented CISO (Chief Information Security Officer), we conduct vulnerability scanning of all repositories, including those we don't ship. We set requirements for patching within very short timeframes, all secrets are encrypted and only available in accessible environments. We place canary tokens in all environments and immediately rotate and disable all related secrets if a secret is leaked.
Engineer incentive design is also important. We design so that contributing to security leads to promotion and compensation. Almost all major financial institutions in the US and Europe are our customers. They hold us accountable.
Why All Engineers Are On-Call
Question: Having all engineers on call is quite unusual. Could you share the background on why this rule was established?
Dee Kitchen: When you have a separate SRE (Site Reliability Engineering) team, software creators don't feel the pain of the problems. They externalize the pain of unreliable, noisy software to the SRE.
Our approach is to align incentives. If you create reliable software, you'll have a quiet time when on-call. Conversely, if you create noisy software, you'll suffer during on-call. This design naturally makes engineers take responsibility for the quality of their code.
Multi-Cloud Deployment
Question: Learning that you deploy on multiple clouds (AWS, GCP, Azure) was new information for me. Do you use different public clouds differently for Grafana Cloud deployments? Please share to the extent possible.
Dee Kitchen: It's completely homogeneous. The purpose is to provide a cellular architecture. Think of AWS regions. When you move to a different region, all services are available. We're exactly the same. Users typically choose regions close to where their applications are hosted to minimize egress costs.
External Contributors and Product Roadmap
Question: For things published as OSS, I imagine there are PRs for feature additions from external contributors. Are there any techniques you use to successfully match these with your product roadmap?
Dee Kitchen: Not particularly.
(The answer to this question was simple, indicating they don't have special mechanisms in place.)
Examples of Bot Automation
Question: You mentioned using bots for automation. How far does this automation extend specifically?
Dee Kitchen: One concrete example: when a service is under load and an alert occurs, that data is automatically passed to automation, which scales up to resolve the load. However, this is limited to scenarios where we can accurately measure the situation. It's essentially runbook automation.
Balancing Vendor Neutrality and Revenue
Question: Balancing OSS vendor neutrality and making money seems difficult. Could you share methods and techniques from OpenTelemetry?
Ted Young: If everyone is open and agrees on how to make money, funding itself doesn't create problems. Most importantly, people need to be honest about their motivations, and the project structure needs to be such that people don't have to lie.
In early Kubernetes, this wasn't achieved. It wasn't clear who owned the software or how to monetize it, making it difficult to judge whether proposals were purely technical or startups plotting to monetize, making engineering stressful. OpenTelemetry has few such problems because everyone agrees on the rules of the game.
Dee Kitchen: End users value vendor neutrality highly. Trust me, they keep us honest.
Current State of AI Utilization
Question: Are you incorporating AI into development?
Dee Kitchen: 98% of our engineers use AI. We give no instructions on which AI tools to use. Claude, Codex, ChatGPT, Gemini, create your own model on Hugging Face. It's up to you.
Top engineers spend most of their daytime defining problems. Then during the night's 16 hours, a team of 20-30 AI agents actually codes the solutions. Typical engineers use Copilot or Codex, consuming about 300 million tokens monthly on average.
There are challenges too. With AI increasing code production, PR reviews have become much more difficult.
We won't release Grafana Assistant until it reaches a level where our internal engineers choose to use it. What we wouldn't use ourselves isn't good enough for users.
That's an incredibly clear standard for dogfooding, and I really resonated with this approach.
Conclusion: "I'm amazed they spoke this openly..."
That was my one-word impression. This meetup was held the day after ObservabilityCon on the Road Tokyo, a large-scale Grafana Labs event, and the contrast with the business-like tone there made this refreshingly enjoyable to listen to throughout.
Personally, these points left the strongest impression:
- Grafana Labs' engineer-centric organizational philosophy that "Managers don't have power. They only have influence"
- The culture where half of hackathon results are released as product features
- Ted Young's candid advice about OSS: "Support is no fun. Beware the ego trap"
- OpenTelemetry's clear monetization model: "Share data. Compete on analysis"
It's rare for internal engineering organizational structures and OSS operational philosophies that usually stay behind the scenes to be discussed this openly. The frankness and honesty of Dee Kitchen and Ted Young really stood out in this meetup.
Grafana Meetup Japan will continue to be held regularly, so please join if you're interested.
That's all for today. This has been Takaharu Hamada (Hamako).