![[Presentation Report] JAWS-UG Osaka re:Invent re:Cap Lightning Talk Event - I gave a presentation titled "Let's evaluate AI agents with Amazon Bedrock AgentCore Evaluations!" (The session was forcibly ended when a UFO arrived)](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1769409184/user-gen-eyecatch/qiaqfegwamdjfuah1jsw.png)
[Presentation Report] JAWS-UG Osaka re:Invent re:Cap Lightning Talk Event - I gave a presentation titled "Let's evaluate AI agents with Amazon Bedrock AgentCore Evaluations!" (The session was forcibly ended when a UFO arrived)
This page has been translated by machine translation. View original
Introduction
Hello, I'm Kannno from the Consulting Department, a big fan of La Moo supermarket.
I gave a presentation titled "Let's evaluate AI agents using Amazon Bedrock AgentCore Evaluations!" at the JAWS-UG Osaka re:Invent re:Cap LT Conference held on Monday, January 26, 2026!
This event was a recap LT conference for re:Invent 2025, with presentation slots of 1, 3, or 5 minutes to choose from. I presented in the 5-minute slot. There was a unique rule that if the UFO squad appeared, you would be forcibly stopped (but finishing too early was also not allowed), so I was nervous about keeping within the time limit...!
Actually, last year's re:Invent 2025 was my first time attending! Good memories include watching The Wizard of Oz at the Sphere, and when I dropped my earphones on the plane but a kind foreigner picked them up for me.
Among the announcements, I personally wanted to talk about Amazon Bedrock AgentCore Evaluations, which is why I introduced it in this LT.
Presentation Materials
What is Amazon Bedrock AgentCore?
Before discussing Amazon Bedrock AgentCore Evaluations, let me briefly touch on Amazon Bedrock AgentCore.
Amazon Bedrock AgentCore is a managed service that allows you to easily create AI agents.

For example, if you want to create an AI agent with supermarket knowledge, you can host the AI agent on Runtime and implement it with the following structure.
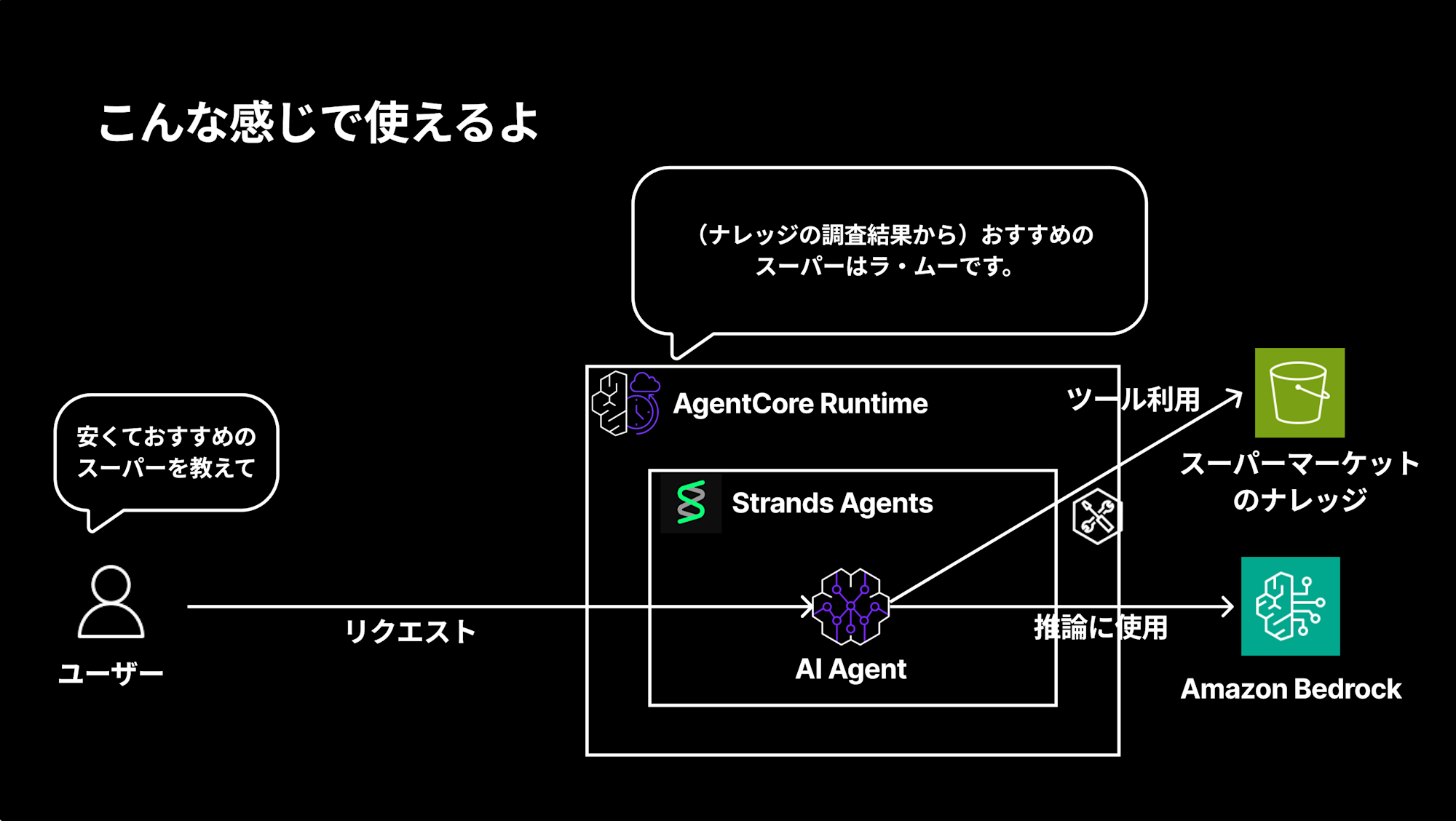
For a question like "Tell me about an affordable recommended supermarket," the agent uses tools to research the knowledge and responds with "The recommended supermarket is La Moo."
Are you evaluating your AI agents?
You've created AI agents, but are you evaluating them?
Not doing it... seems difficult... but you want to evaluate if they're working properly and improve the AI agents you've created...
Of course, you don't want to just create it and be done; you want to analyze and continuously update it, right?
Good news for those with such concerns!
There was a welcome update at re:Invent 2025. It's Amazon Bedrock AgentCore Evaluations (Preview).
Amazon Bedrock AgentCore Evaluations
Amazon Bedrock AgentCore Evaluations is a feature that allows you to evaluate AI agents you're developing and operating directly from the console.
You can easily check from the dashboard, and it uses LLM-as-a-Judge for evaluations.
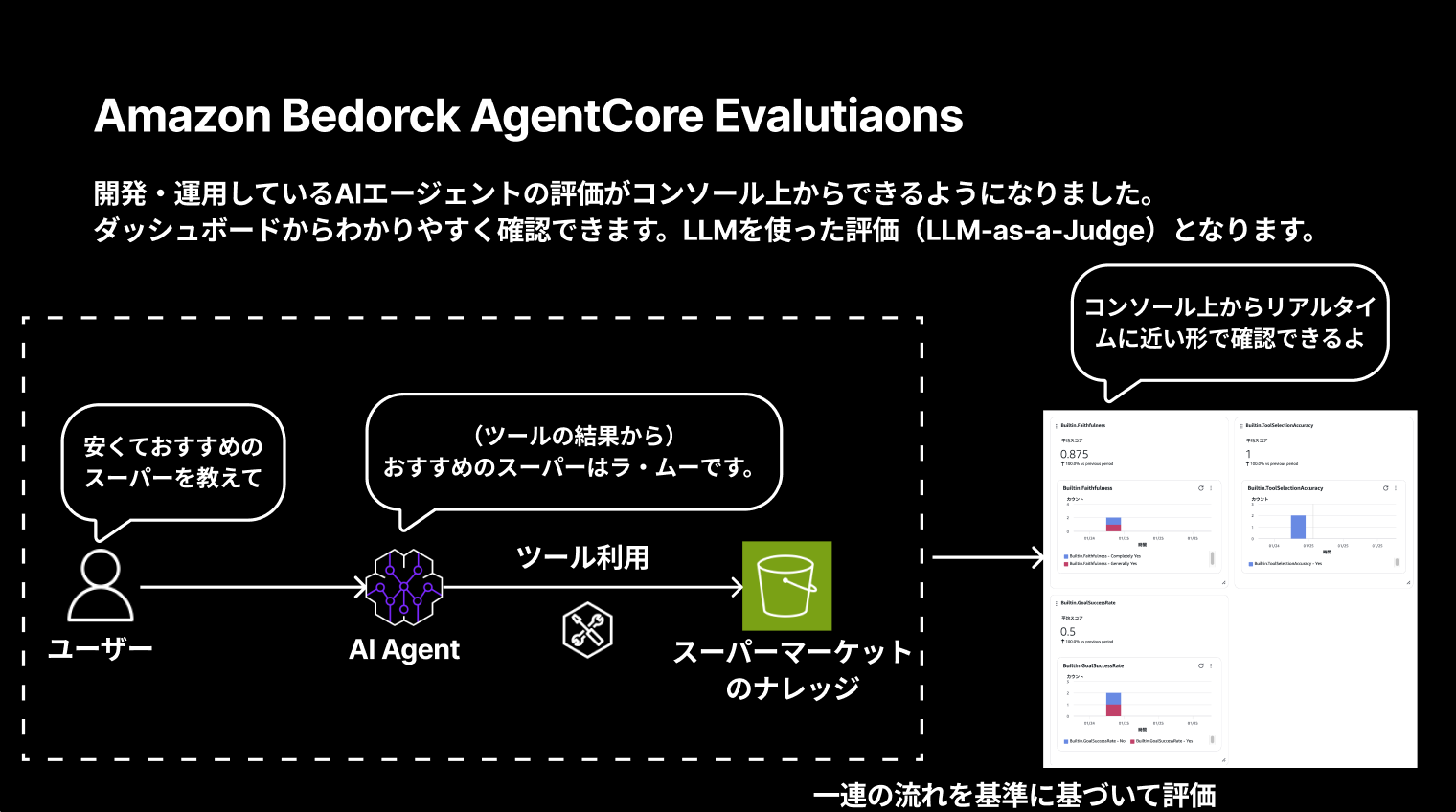
It's great that you can evaluate the interaction between users and AI agents, as well as tool usage based on criteria, and check it in near real-time from the console!
Evaluation Methods
Since evaluation is done based on logs, it doesn't affect running agents and can be checked in near real-time on the console.
There are two evaluation methods:
| Evaluation Method | Overview |
|---|---|
| Online Evaluation | Continuously monitor agent quality in real-time, can specify sampling rate and filter conditions. Evaluation results can be checked from the Observability dashboard |
| On-demand evaluation | Can evaluate on-demand by specifying a specific session ID, etc. Easily implemented with Starter Toolkit |
It's great that neither method affects agents in production.
I'll actually try Online Evaluation this time!
For on-demand evaluation, there's a blog post that tried it, so please refer to it if needed!
Let's Try It Out
Prerequisites
The source code used is available in the repository below:
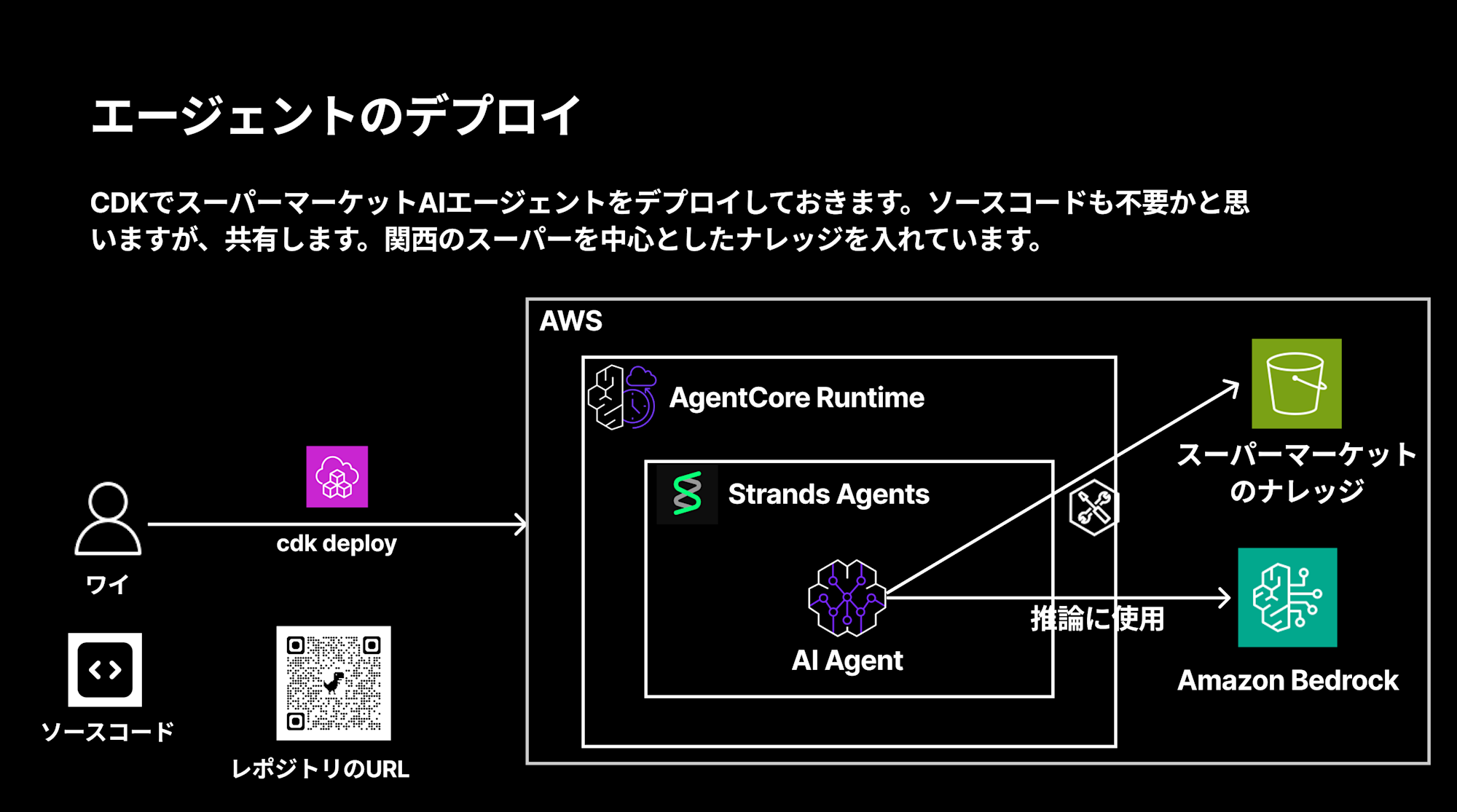
It's configured to deploy an AI agent with knowledge focused on supermarkets in the Kansai region using CDK.
Deploying the Agent
First, let's deploy the AI agent.
git clone https://github.com/yuu551/supermarket-agent-cdk.git
cd supermarket-agent-cdk
Install the necessary dependencies and deploy with CDK:
pnpm install
pnpm dlx cdk deploy
Once deployment is complete, a supermarket AI agent will be built on Amazon Bedrock AgentCore.
The configuration is as follows:
The supermarket knowledge documents are uploaded and the knowledge base is created, but it's not synchronized, so we'll synchronize it manually.
Configuring Evaluation from the Console
We'll configure settings from the Amazon Bedrock AgentCore console. I selected the following three evaluation metrics:
| Evaluation Metric | Overview |
|---|---|
| Faithfulness | Evaluates whether the information in the response is supported by the provided context/sources |
| Goal success rate | Evaluates whether the conversation successfully achieved the user's goal |
| Tool selection accuracy | Evaluates whether the agent selected the appropriate tools for the task |
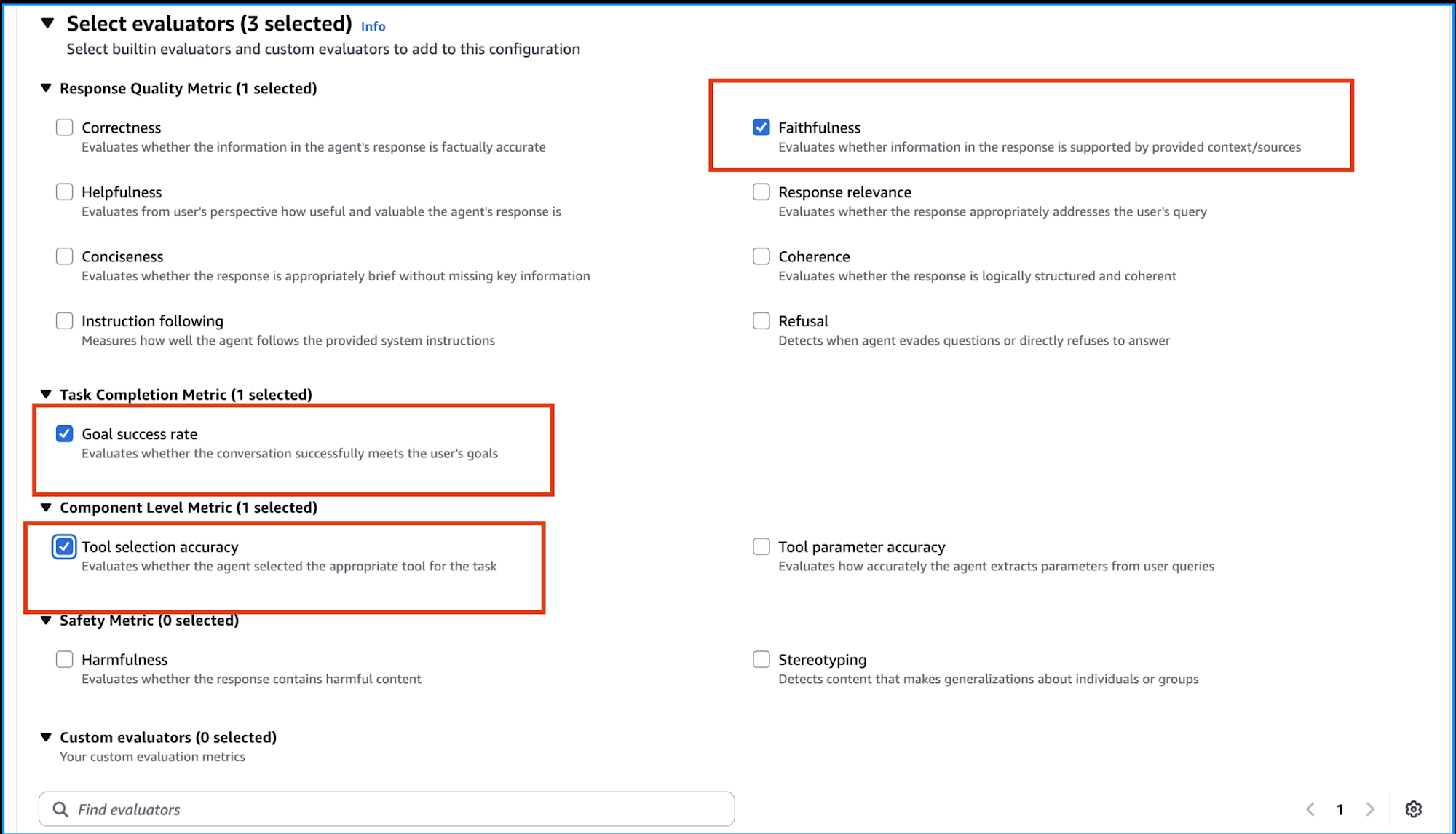
From the Select evaluators section in the console, just check the above three metrics and save the settings!
Let's Ask the AI Agent Some Questions
Once the settings are complete, let's ask the AI agent some questions.
You can test from the Agent sandbox in the console.
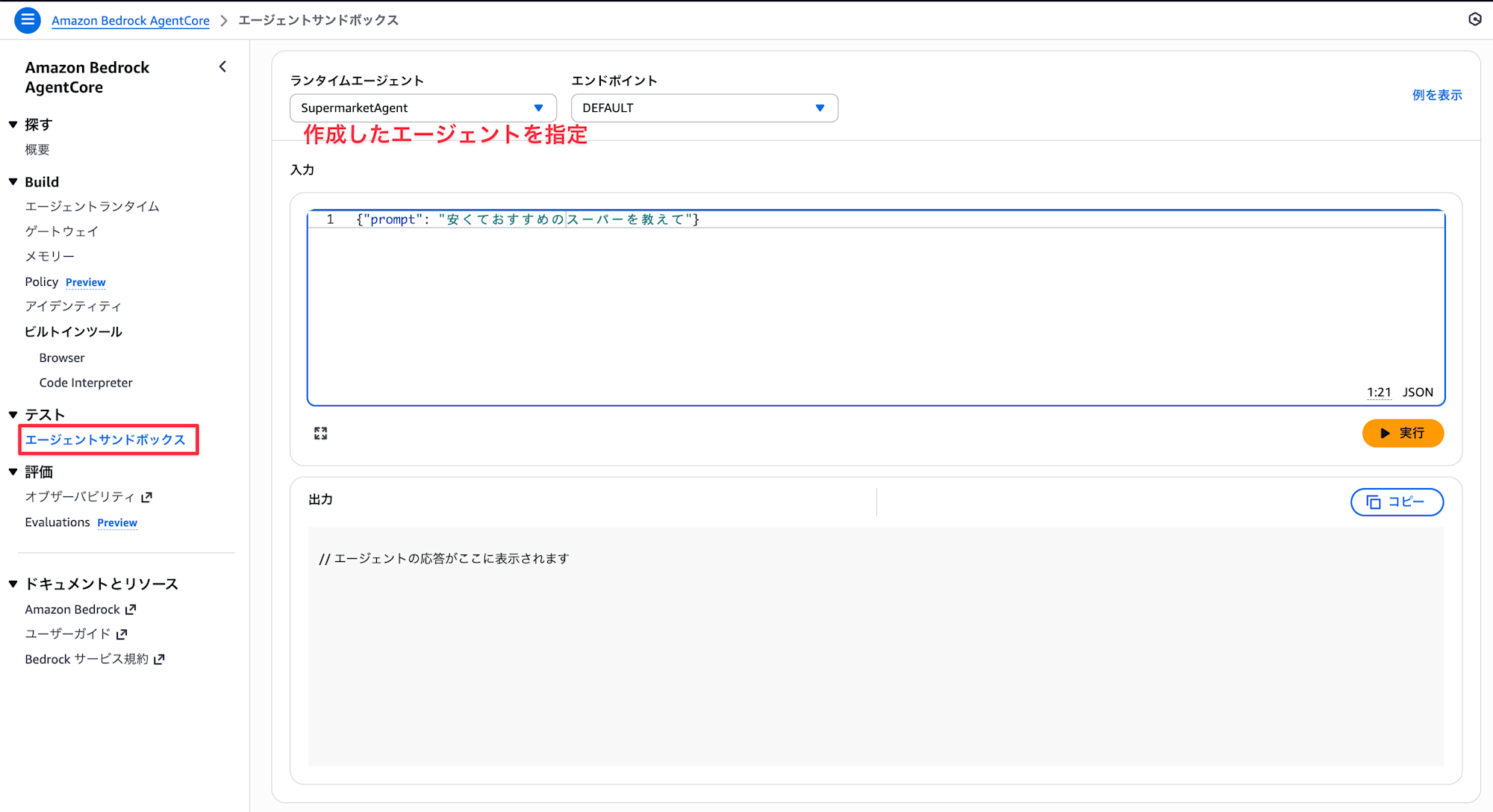
I tried asking questions that are likely to be answered correctly and some that are likely to be incorrect.
Question 1: Tell me about affordable recommended supermarkets
Question 2: Tell me about Costco
Question 1 can be answered because there's information in the knowledge base, but Question 2 about Costco shouldn't be answerable since that information isn't in the knowledge base.
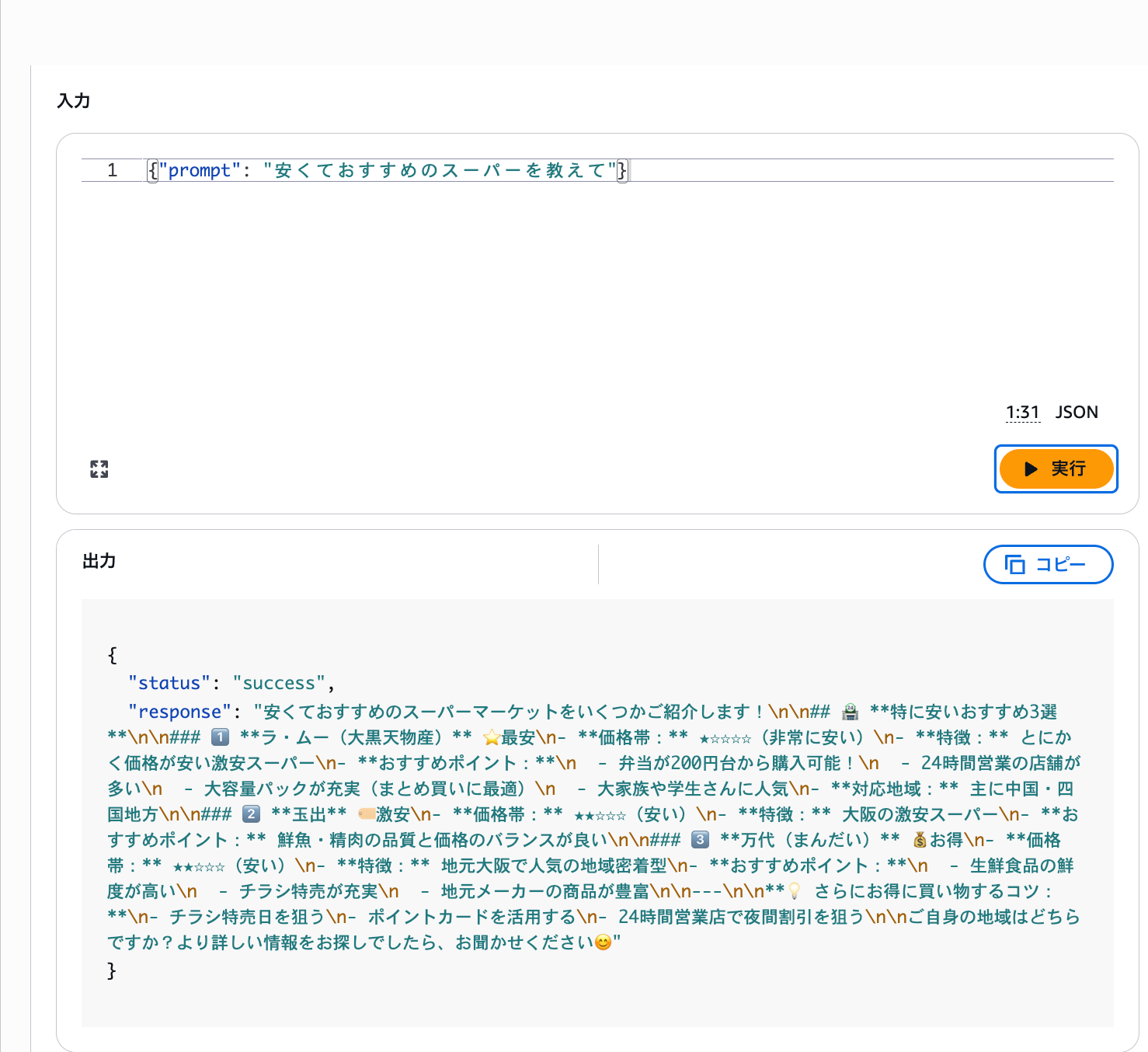
It's properly giving me recommended supermarkets based on the knowledge.
Looking at the actual response to Question 2, the Costco question received a response like "I'm sorry, no information about Costco was found in the search results." It couldn't answer as expected.
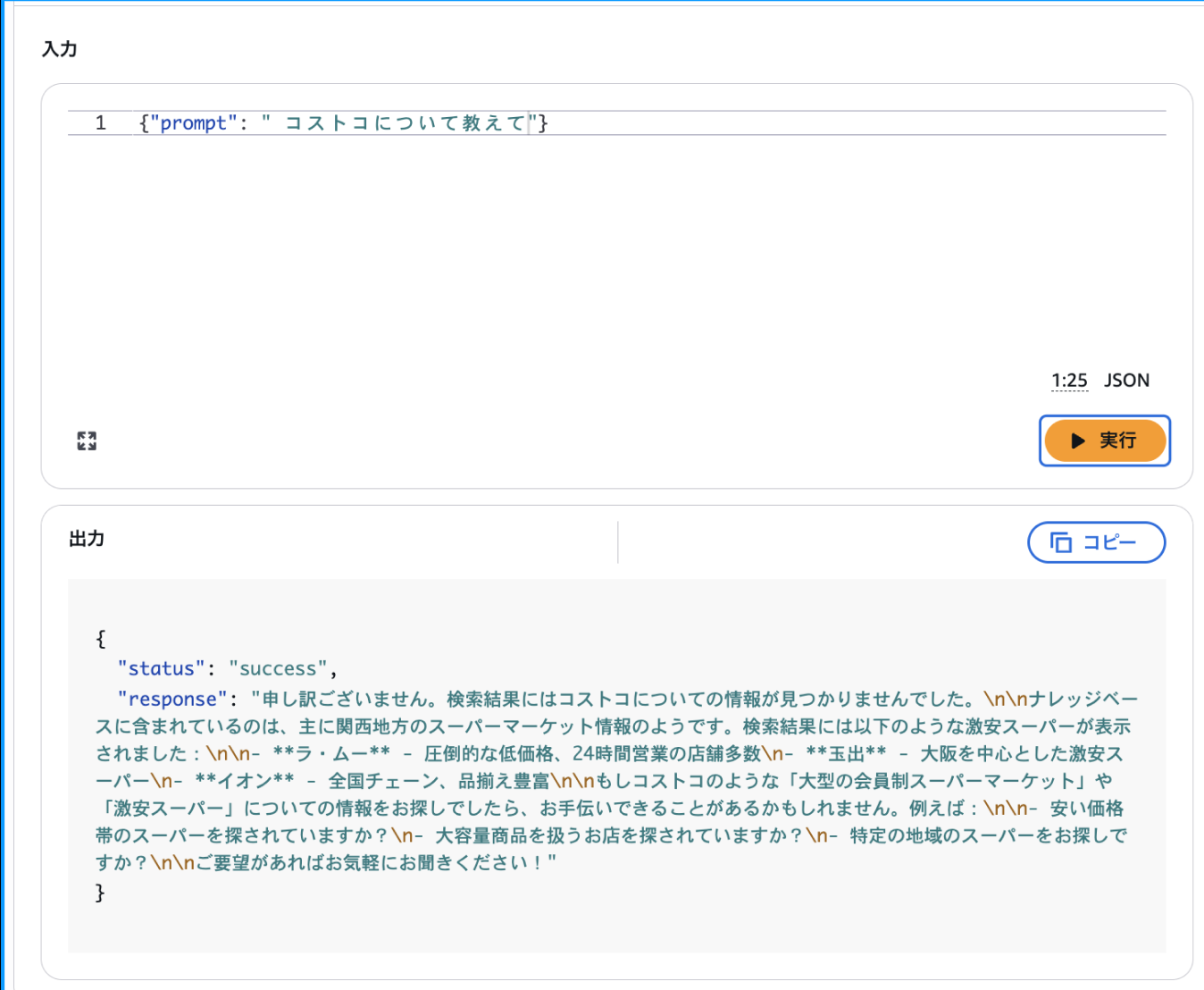
Viewing Evaluation Results
The evaluation summary for several questions can be viewed from the Gen AI Observability dashboard. Looking at the dashboard, you can see the average scores for each evaluation metric.
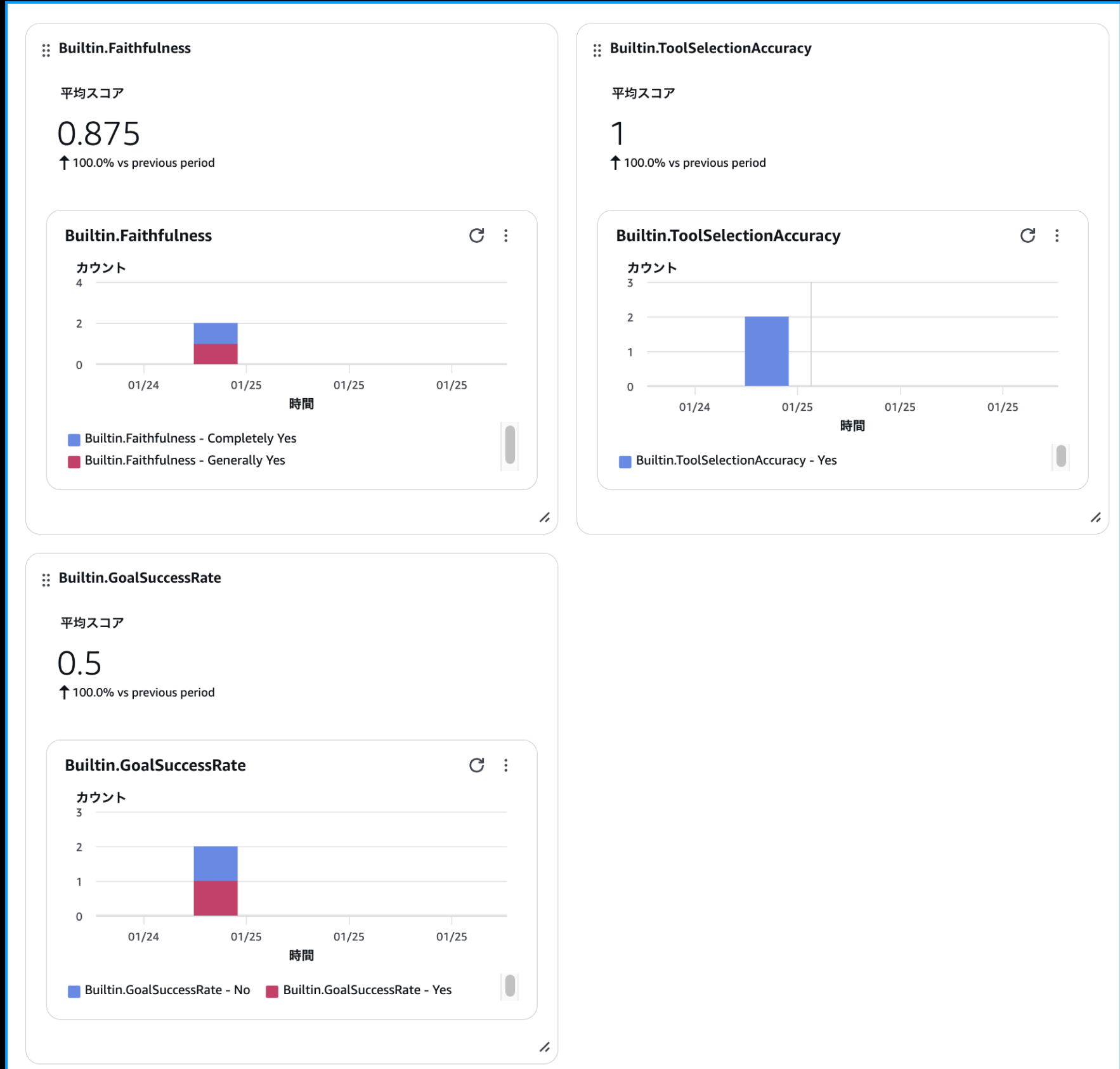
It's nice to be able to see at a glance how well it meets the criteria!
Digging Deeper into Evaluation Results
Let's break it down a bit more and see specifically how the Costco question was evaluated. The evaluation results are stored in CloudWatch Logs, so let's take GoalSuccessRate as an example.
You can check the log group from the link in the settings screen.
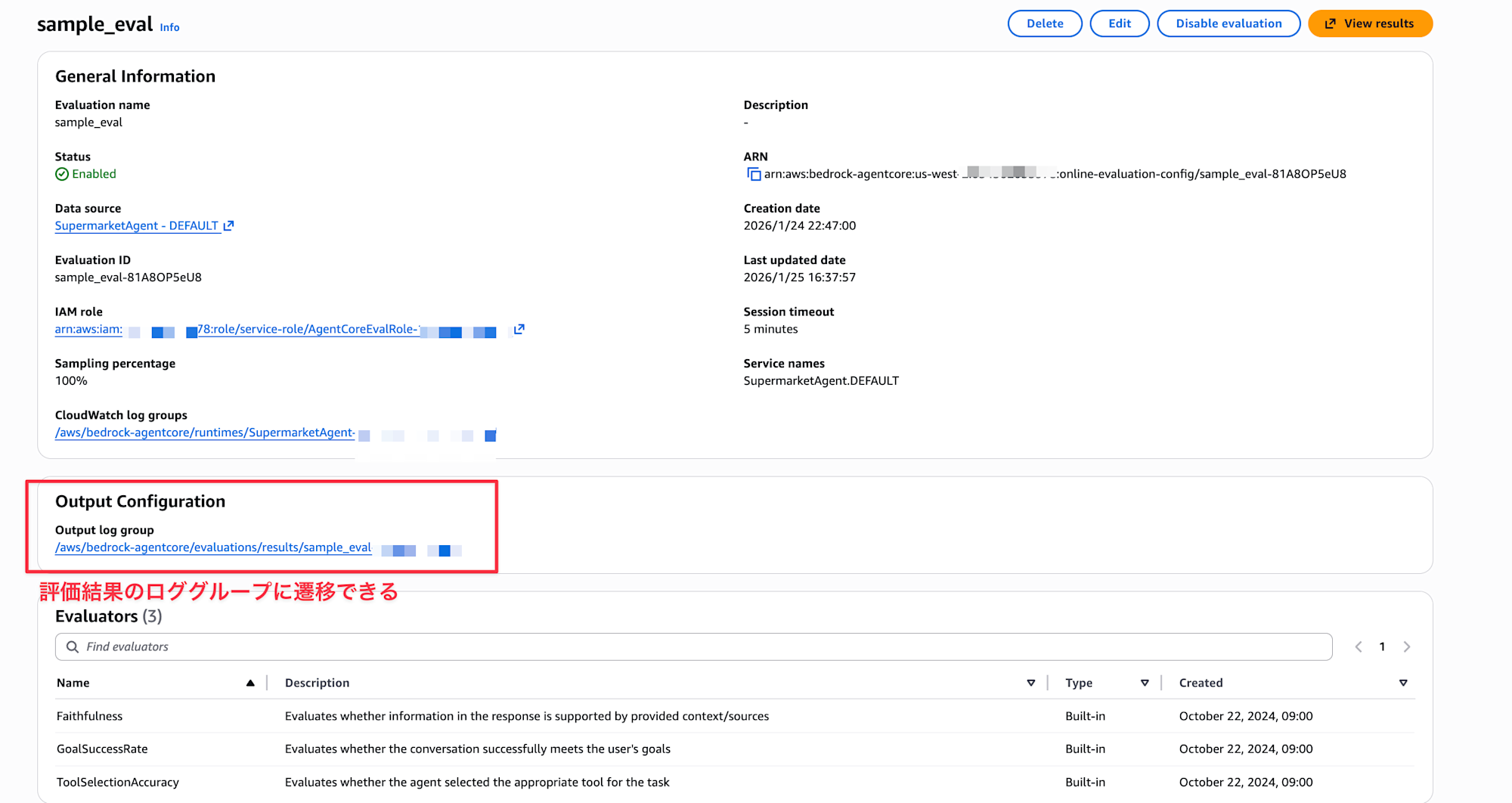
The logs were recorded as follows:

The evaluation log translates to:
The user asked about Costco in Japanese.
The AI assistant appropriately used the "retrieve" tool to search for information about Costco in the knowledge base.
The search returned 5 documents with scores above 0.4, but none of them contained specific information about Costco. Instead, information about various supermarkets in the Kansai region (La Moo, Tamade, Hankyu Oasis, Life, AEON, Konan) was displayed.
The AI assistant correctly interpreted the tool's output and honestly informed the user that no direct information about Costco was found in the knowledge base.
The user's goal was to learn about Costco, but as confirmed by the tool output, that information is not included in the knowledge base, so the assistant cannot directly fulfill that request.
The assistant responded professionally to this limitation by maintaining transparency while suggesting alternatives.
This question scored 0 on GoalSuccessRate.
The goal of providing information about Costco wasn't achieved. In this case, we would simply want to add Costco knowledge.
On the other hand, it scored 1 point for Faithfulness.

The user asked about "Costco". The assistant performed a search with the keyword "Costco", but the results returned were 5 pieces of information about various supermarkets in the Kansai region (La Moo, Life, AEON, Tamade, Konan, etc.) and contained no information about Costco at all.
The assistant's response accurately reflects this situation in the following ways:
It acknowledges that the search results did not include direct information about Costco.
It correctly identifies the information that was actually found (information about supermarkets in Kansai such as La Moo, Tamade, Hankyu Oasis, Life, and AEON).
It explicitly states that Costco information is not available in the current knowledge base.
It suggests that if there are specific questions about Costco, it can provide support again.
The assistant's response is completely faithful to the conversation history.
It doesn't fabricate information about Costco, correctly conveys the output of the search tool, and appropriately acknowledges the limitations of the available data. There are no contradictions between the assistant's response and the conversation history.
From the perspective of faithfulness, it's passing the criteria.
Insights from Evaluation Results
It's important to check not just the scores, but also what criteria the AI used to make its judgment...!!
There might be gaps between human evaluation criteria. Combine with visual checks as needed to make judgments! Analyze to identify bottlenecks and make your AI agent behavior better!
Additional Note: Strands Agents Eval Feature
Strands Agents also has an Eval feature, so
I recommend trying it for cases where you want more sophisticated evaluation than AgentCore Evaluations!
You can implement it like this:
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import OutputEvaluator
# Define test cases
test_cases = [
Case(name="knowledge-1", input="What is the capital of France?", expected_output="Paris"),
Case(name="math-1", input="What is 5 × 12 × 1.08?", expected_output="64.8"),
Case(
name="knowledge-2",
input="Who is Yudai Kannno?",
expected_output="I don't know",
),
]
# Task function
def get_response(case: Case) -> str:
agent = Agent(system_prompt="An assistant that provides accurate information")
return str(agent(case.input))
# LLM Judge evaluator
evaluator = OutputEvaluator(rubric="Evaluate accuracy and completeness on a scale of 1.0-0.0")
# Run test
experiment = Experiment(cases=test_cases, evaluators=[evaluator])
reports = experiment.run_evaluations(get_response)
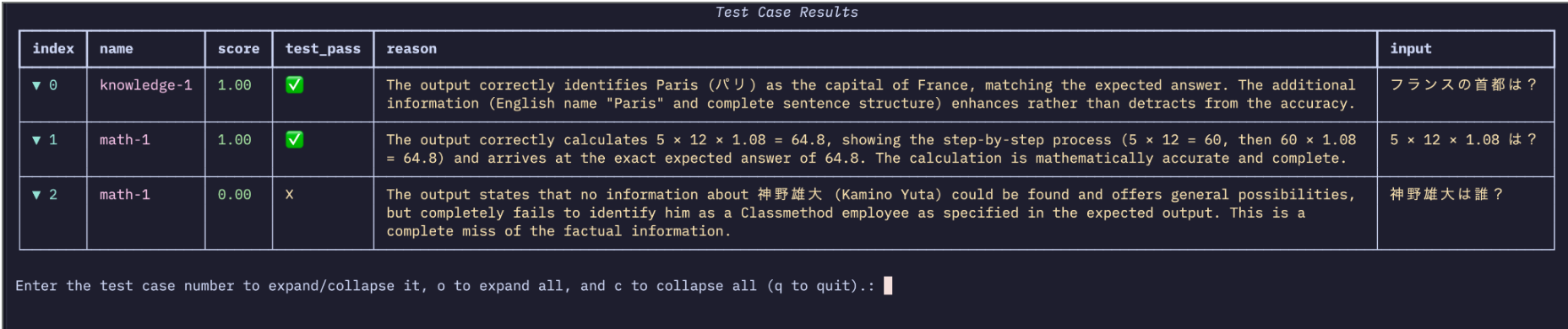
reports[0].run_display()
When you run it, the evaluation results are displayed like test code, which is easy to understand.
Conclusion
AI agents aren't just create-and-forget; this is a very welcome update for accumulating feedback and evaluations to improve them and bring them closer to ideal behavior!
Let's use Evaluations to continuously improve our AI agents!
At this JAWS-UG Osaka re:Invent re:Cap LT Conference, I finished with 7 seconds to spare, just barely finishing early without being taken away by the UFO squad, and that's how it ended! w
Just 2 more seconds... frustrating...
Thank you to the organizers and everyone who listened!
If this presentation has made you want to learn more about AgentCore, I would be very happy if you also read the following article!
I hope this article was helpful to you. Thank you for reading to the end!