![[Update] Amazon Bedrock Knowledge Bases multimodal search is now generally available #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/33a7q65plkoztFWVfWxPWl/a718447bea0d93a2d461000926d65428/reinvent2025_devio_update_w1200h630.png?w=3840&fm=webp)
[Update] Amazon Bedrock Knowledge Bases multimodal search is now generally available #AWSreInvent
This page has been translated by machine translation. View original
Hello! I am Takakuni (@takakuni_) from the Consulting Department of the Cloud Business Division.
Amazon Bedrock Knowledge Bases has launched general availability of multimodal search.
It's finally here! Let's take a look at this update.
Update Content
To repeat, literally, "Multimodal search is now generally available for Amazon Bedrock Knowledge bases."
At re:Invent 2024, the multimodal search feature for Amazon Bedrock Knowledge bases was released as a public preview.
=At re:Invent 2025, this feature including multimodal search has started general availability! (Hooray)
Support for Amazon Nova Multimodal Embeddings
With this update, "Amazon Nova Multimodal Embeddings" can now be used as an embedding model for Amazon Bedrock Knowledge Bases.
Therefore, for multimodal embedding methods, you can now choose between two patterns: using Amazon Bedrock Data Automation (hereafter, BDA) as a parser, or using Amazon Nova Multimodal Embeddings as an embedding model.
Different Approaches
As mentioned earlier regarding multimodal embedding methods, "using Amazon Bedrock Data Automation as a parser" or "using Amazon Nova Multimodal Embeddings as an embedding model" each have different approaches.
As a refresher, the embedding process in Amazon Bedrock Knowledge bases goes through parsing before embedding processing, as shown below.

The previously supported BDA is used as a parser to convert audio and images to text.
Therefore, the final data format for embedding is text data.

In contrast, Amazon Nova Multimodal Embeddings is a model capable of embedding audio and images.
Therefore, it stores data directly in the vector database without the parsing process performed by BDA.

First, let's remember this difference.
Search Methods Have Also Increased
With Amazon Bedrock Knowledge Bases supporting Amazon Nova Multimodal Embeddings as an embedding model, it's now possible to perform similarity searches using images.
Until this update, the BDA-only mechanism only supported text search. It's very helpful that images can now be embedded with Amazon Nova Multimodal Embeddings.
Image-based queries allow users to upload images and find visually similar content
However, this image search is currently only supported by the Retrieve API, and it still seems difficult to generate responses with images as input using the RetrieveAndGenerate API. [1] [2]
Is Amazon Nova Multimodal Embeddings Better?
While Amazon Nova Multimodal Embeddings seems better because it enables image search with the Retrieve API [3], the recommended approach depends on your search use case.
Specifically, the guidance is as follows. It's helpful to have such guidance:
| Content Type | Amazon Nova Multimodal Embeddings | Amazon Bedrock Data Automation |
|---|---|---|
| Product catalogs/images | (Recommended) Enables visual similarity matching and image-based queries | (Limited) Effective only for cases extracting text through OCR |
| Meeting recordings and calls | (Recommended) Cannot process speech content in a meaningful way | (Recommended) Can provide full speech-to-text transcription and searchable text |
| Training and educational videos | (Partial) Can process visual content but not audio | (Recommended) Captures both audio transcripts and visual descriptions |
| Customer support recordings | (Not recommended) Cannot effectively process audio content | (Recommended) Creates searchable complete conversation records |
| Technical diagrams | (Recommended) Optimal for visual similarity and pattern matching | (Limited) Can extract text labels but not visual relationships |
Feature Differences
Here are some other noteworthy differences.
Regions
First, regarding regions, Amazon Nova Multimodal Embeddings is currently only supported in the Northern Virginia region.
In contrast, BDA is supported in the following regions:
- US West (Oregon)
- US East (N. Virginia)
- Europe (Frankfurt)
- Europe (London)
- Europe (Ireland)
- Asia Pacific (Mumbai)
- Asia Pacific (Sydney)
- AWS GovCloud (US-West)
Japanese Language Support
Both seem to support Japanese.
Amazon Nova Multimodal Embeddings
Looking at the AWS AI Service Cards, it states "We curated data from over 200 languages for Amazon Nova Multimodal Embeddings," though it doesn't explicitly mention Japanese support.
However, following the "see Amazon Nova User Guide" direction and checking the Amazon Nova User Guide, it indicates that Japanese is supported in the general Nova world, so it's likely supported.
1: Optimized for these 15 languages: English, German, Spanish, French, Italian, Japanese, Korean, Arabic, Simplified Chinese, Russian, Hindi, Portuguese, Dutch, Turkish, and Hebrew.
Amazon Bedrock Data Automation
Japanese is supported. However, vertical text is not supported, so be careful. (A common issue)
Text can be text aligned horizontally within the document. Horizontally arrayed text can be read regardless of the degree of rotation of a document. BDA does not support vertical text (text written vertically, as is common in languages like Japanese and Chinese) alignment within the document.
By the way, Japanese support was added recently. Very grateful...
Differences in Supported Extensions
The supported file extensions differ slightly.
Amazon Nova Multimodal Embeddings seems slightly more advantageous:
| File Type | Nova Multimodal Embeddings | Bedrock Data Automation (BDA) |
|---|---|---|
| Images | .png, .jpg, .jpeg, .gif, .webp | .png, .jpg, .jpeg |
| Audio | .mp3, .ogg, .wav | .amr, .flac, .m4a, .mp3, .ogg, .wav |
| Video | .mp4, .mov, .mkv, .webm, .flv, .mpeg, .mpg, .wmv, .3gp | .mp4, .mov |
| Documents | Processes as text | .pdf (also extracts text from images) |
However, for audio searches (raw audio files or audio in video files), the BDA approach is recommended.
Nova Multimodal Embeddings cannot effectively process speech content in audio or video files. If your multimedia content contains important spoken information that users need to search, choose the BDA approach to ensure full transcription and searchability.
Let's Try It
Let's create knowledge bases and test the differences.
This time, I'll register zodiac animal images in the knowledge base and search through them.
List of zodiac images
Mouse

Cow

Tiger

Rabbit

Dragon

Snake

Horse

Sheep

Monkey

Rooster

Dog

Boar

Thank you as always, Irasutoya...
BDA Parser Only
Let's start with the traditional BDA. I named the knowledge base "kb-bda".
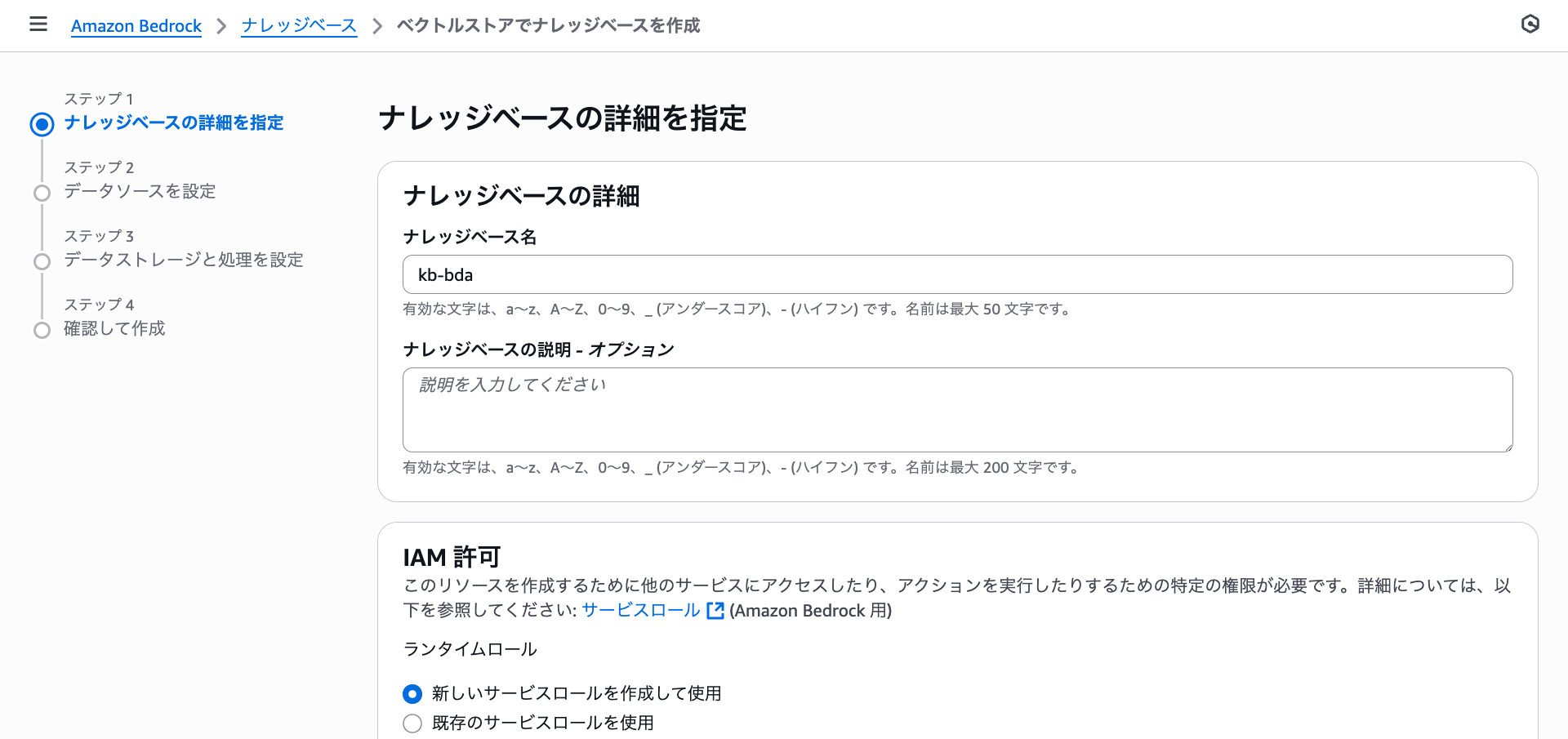
For data sources, I chose S3 and parser processing. There are three options displayed: default parser, BDA, and foundation model.
I'll select BDA for this case.
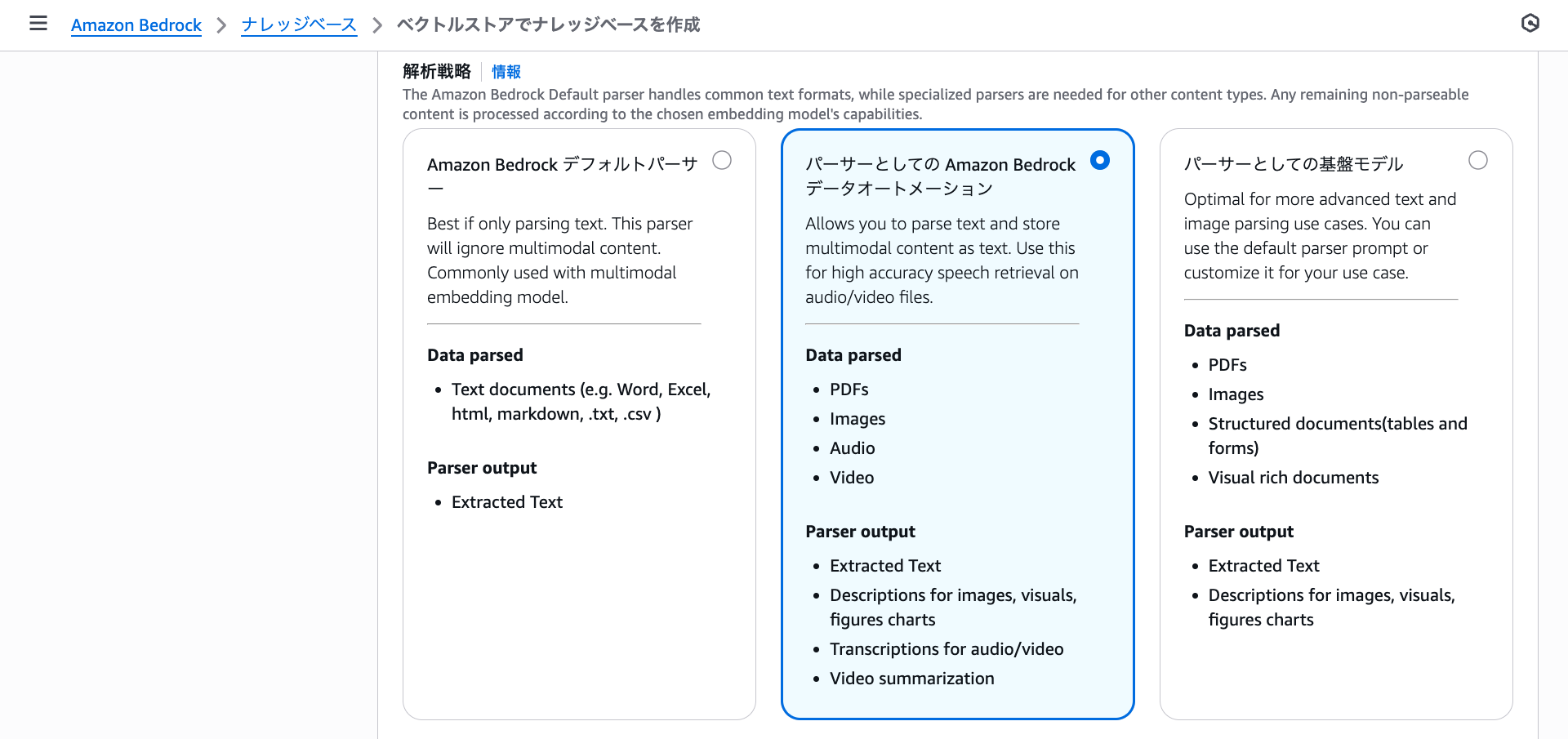
For the embedding model, I'll select Titan Text Embeddings V2 since BDA ultimately embeds text.
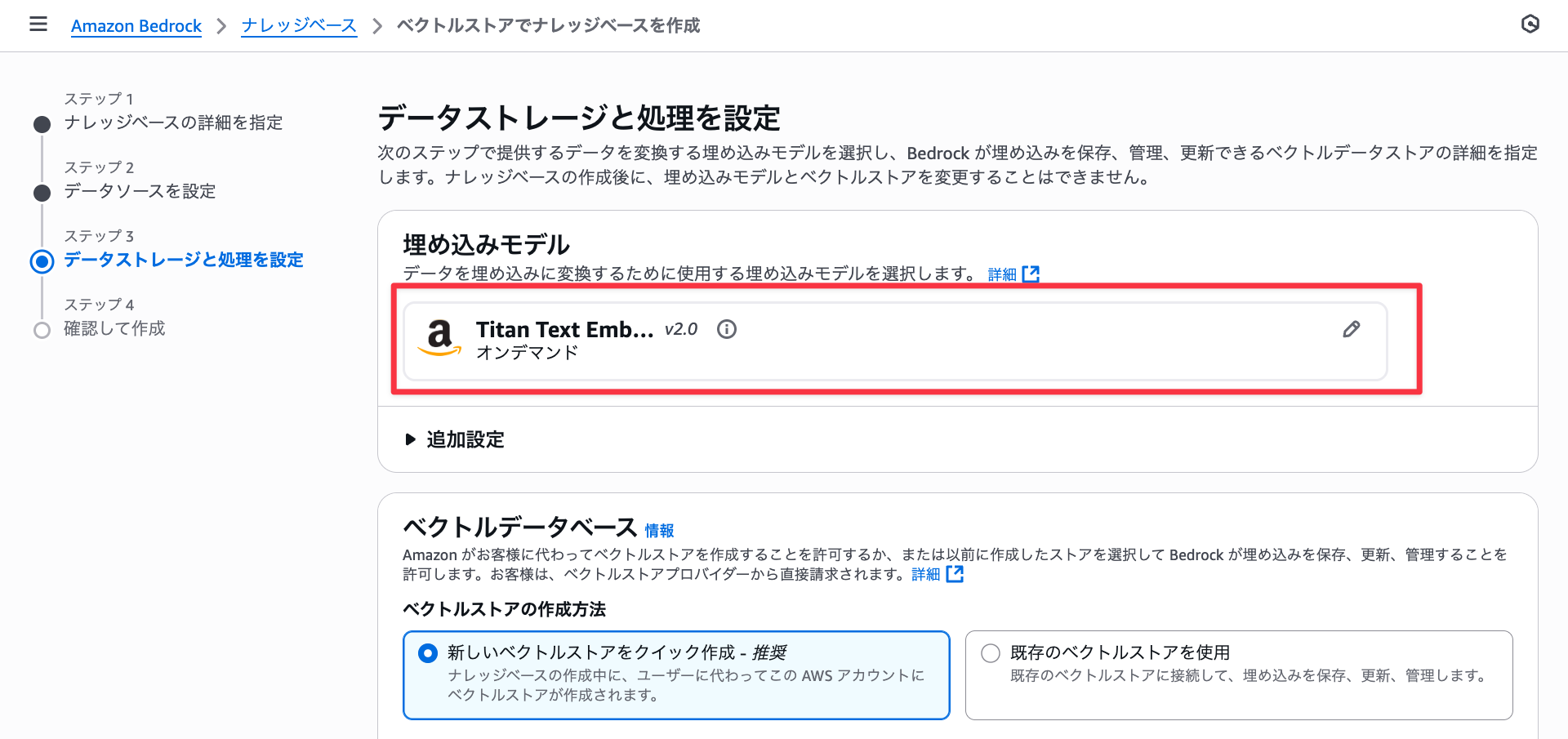
I chose S3 Vectors as the vector data store and created it.
I ran the synchronization process. It took about 5 minutes for 12 files.
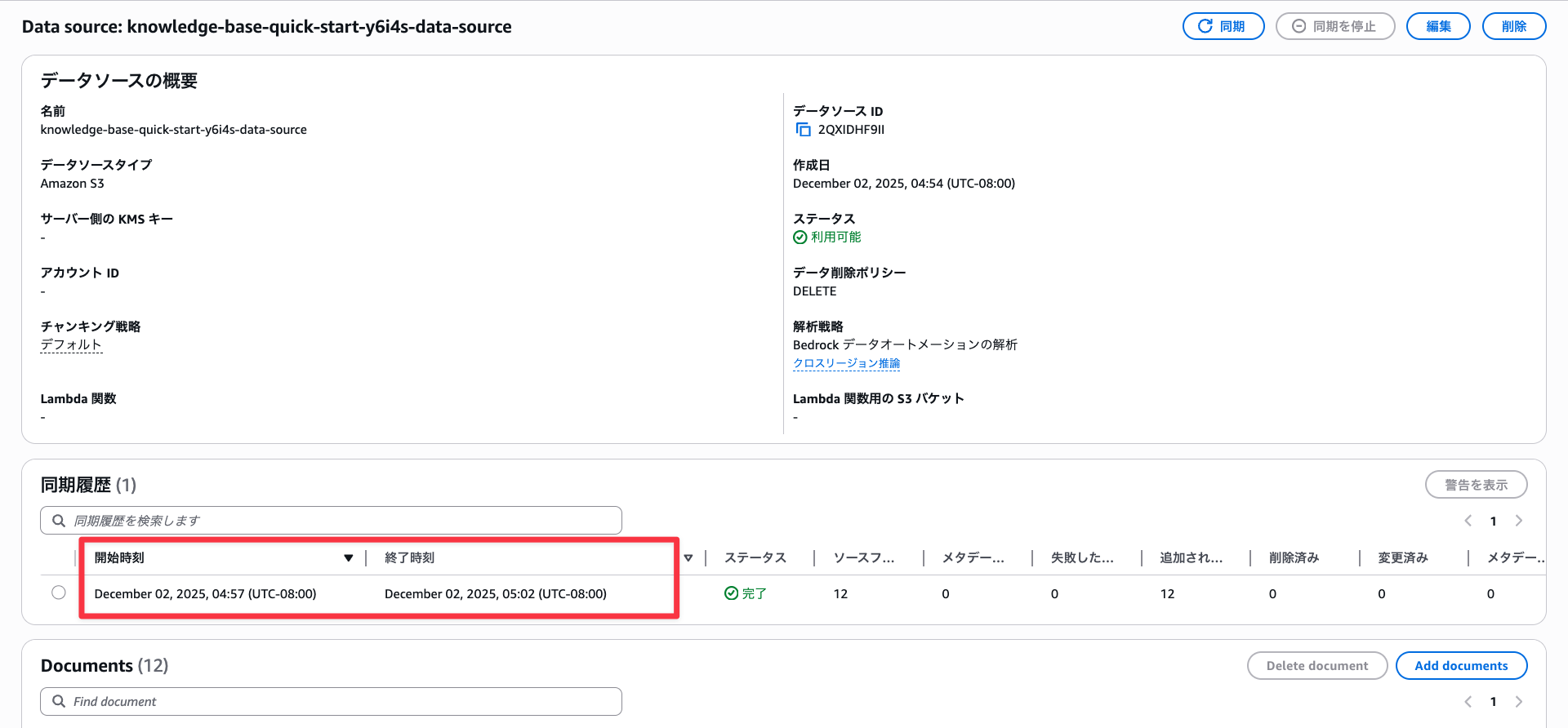
Let's perform a vector search. Since Amazon Titan Text Embedding v2 (the chosen embedding model) has standard support for English and preview support for Japanese, I'll first search in English. Searching for "cow" correctly returns a cow.
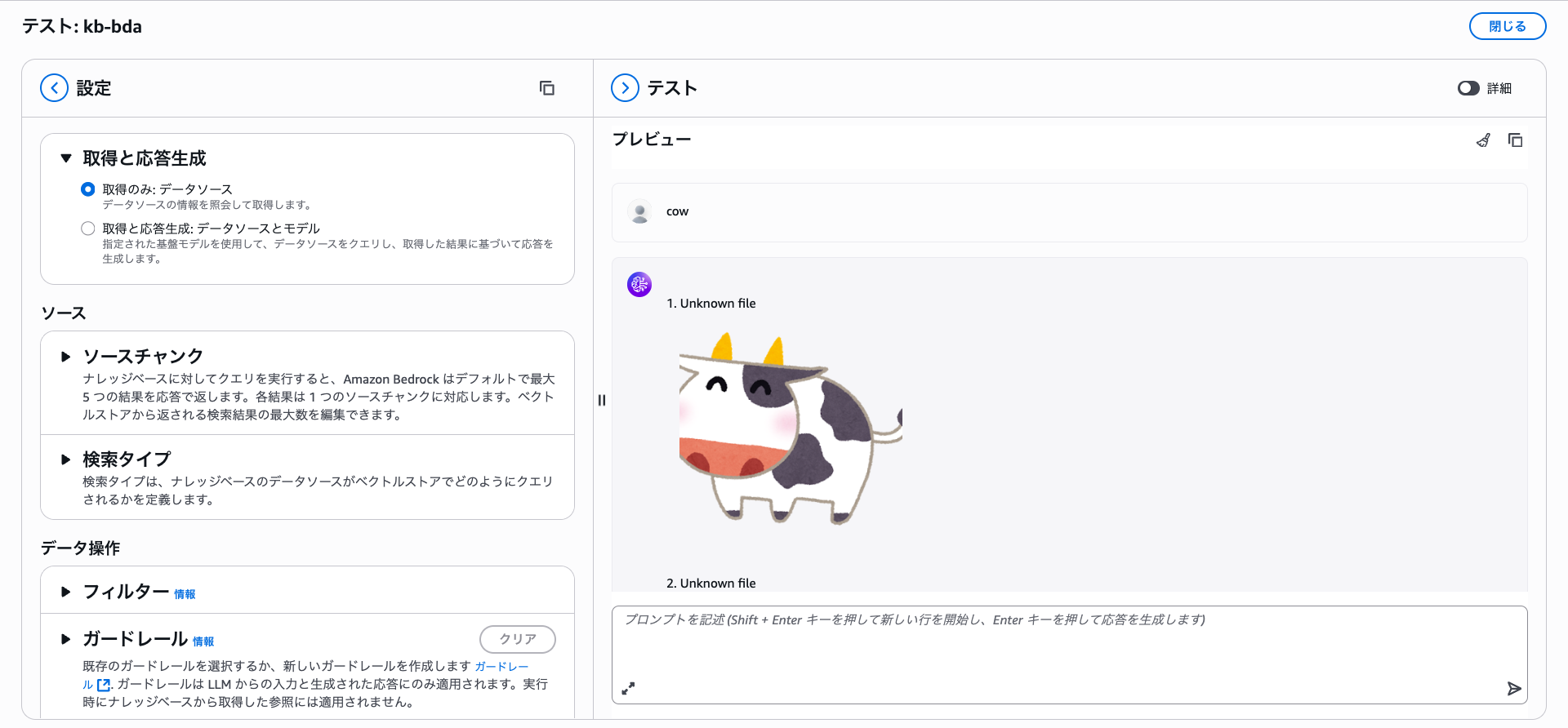
When searching for "牛" in Japanese, it returns a dog.
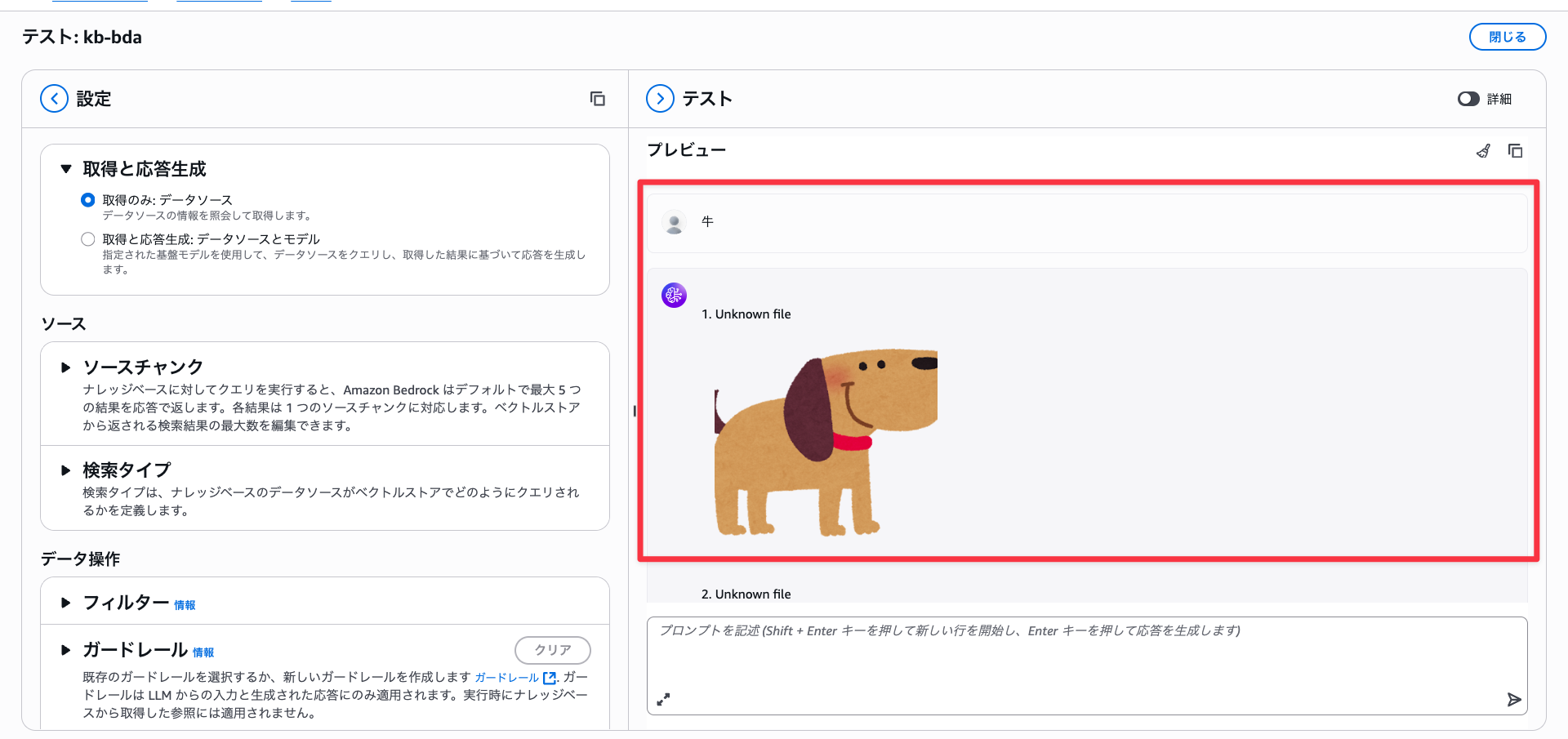
With reranking applied, it correctly returns a cow.
Let's examine the contents of S3 Vectors.
※If you want to try this yourself, change VECTOR_BUCKET_NAME and VECTOR_INDEX_NAME.
import base64
import json
import sys
import boto3
REGION = "us-east-1"
MODEL_ID = "amazon.titan-embed-text-v2:0"
DIMENSION = 1024
VECTOR_BUCKET_NAME = "bedrock-knowledge-base-s7yi88"
VECTOR_INDEX_NAME = "bedrock-knowledge-base-default-index"
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
s3vectors = boto3.client("s3vectors", region_name=REGION)
query = sys.argv[1]
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(
{
"inputText": query,
"dimensions": DIMENSION,
}
),
)
response_body = json.loads(response["body"].read())
embedding = response_body["embedding"]
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
queryVector={"float32": embedding},
topK=3,
returnDistance=True,
returnMetadata=True,
)
print(json.dumps(response["vectors"], indent=2))
Looking at the vector bucket contents, we can see that AMAZON_BEDROCK_TEXT contains the text converted by BDA.
takakuni@ multimodal % uv run main.py cow
[
{
"key": "979900bc-b2dc-4a02-aceb-18b04e0a2c69",
"metadata": {
"AMAZON_BEDROCK_TEXT": "This image shows a cartoon illustration of a cow with a black and white body, a red nose, and yellow horns. The cow is depicted in a simple, stylized manner with exaggerated features, such as large eyes and a wide mouth. The cow is standing on a black background, and its tail is visible on the right side of the image. The overall style of the illustration is playful and whimsical, suggesting it might be part of a children's book or educational material.",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:35Z\",\"modifiedDate\":\"2025-12-02T12:46:35Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_ushi.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/99IHDPO2PQ/2QXIDHF9II/b5bf39af-0b7e-4fa1-977a-183f33eae8f2.png\"}}],\"sourceDocumentId\":\"FJyBQGITnOIBecEs/buuYGwErC5w/ryaLjLiNBexU+bPOIF7OyF7LthUNzTvZIn5\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"x-amz-bedrock-kb-data-source-id": "2QXIDHF9II",
"x-amz-bedrock-kb-document-page-number": 0.0
},
"distance": 1.2734625339508057
},
{
"key": "897ebcae-bc2d-4119-adc3-aaa6735ac68b",
"metadata": {
"x-amz-bedrock-kb-document-page-number": 0.0,
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:30Z\",\"modifiedDate\":\"2025-12-02T12:46:30Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_hitsuji_kagamimochi.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/99IHDPO2PQ/2QXIDHF9II/cecc2b2a-0241-44a0-a509-d41a40cc90ca.png\"}}],\"sourceDocumentId\":\"OKgT9G3/dgz7rBIuH6WKHYt32sYYf/oLOYnB3TPRYRjHawMLEtyGgXlrmGFeJG0A\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_TEXT": "This image shows a cute, cartoonish character sitting on a wooden pedestal. The character has a fluffy white body resembling a sheep or a cloud, with a cheerful expression. It is wearing a blue bow tie and has orange hair on both sides of its head. There is a small orange with a green leaf on top of its head. The background is solid black, making the character stand out prominently. The character appears to be in a playful and whimsical setting.",
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"x-amz-bedrock-kb-data-source-id": "2QXIDHF9II"
},
"distance": 1.7209044694900513
},
{
"key": "8c7aab78-fb5a-4dec-b525-72df60e229b2",
"metadata": {
"x-amz-bedrock-kb-document-page-number": 0.0,
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:27Z\",\"modifiedDate\":\"2025-12-02T12:46:27Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_inu.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/99IHDPO2PQ/2QXIDHF9II/ed0965ec-9a12-47f7-bd93-5b778a455a9f.png\"}}],\"sourceDocumentId\":\"o625brHQZKEzo/1Ym/sZhMLXdEsjVaJnxgR5BFl/57RIxm4JkV4eiZJb2KUl96PG\",\"additionalMetadata\":null}",
"AMAZON_BEDROCK_TEXT": "This image shows a cartoon illustration of a dog with a smiling face. The dog has a brown body and dark brown ears. It is wearing a red collar around its neck. The dog's tail is curved upwards and is also dark brown. The background of the image is black, making the dog stand out prominently. The illustration appears to be simple and stylized, likely aimed at conveying a friendly and cheerful demeanor.",
"x-amz-bedrock-kb-data-source-id": "2QXIDHF9II",
"x-amz-bedrock-kb-source-file-mime-type": "image/png"
},
"distance": 1.7683148384094238
}
]
Amazon Nova Multimodal Embeddings Default Parser
Next, let's look at Amazon Nova Multimodal Embeddings.
To examine each parser's processing, I'll create separate knowledge bases. First, let's try the default parser. I named it "kb-nova-def".
I selected S3 as the data source and moved to the parser section.
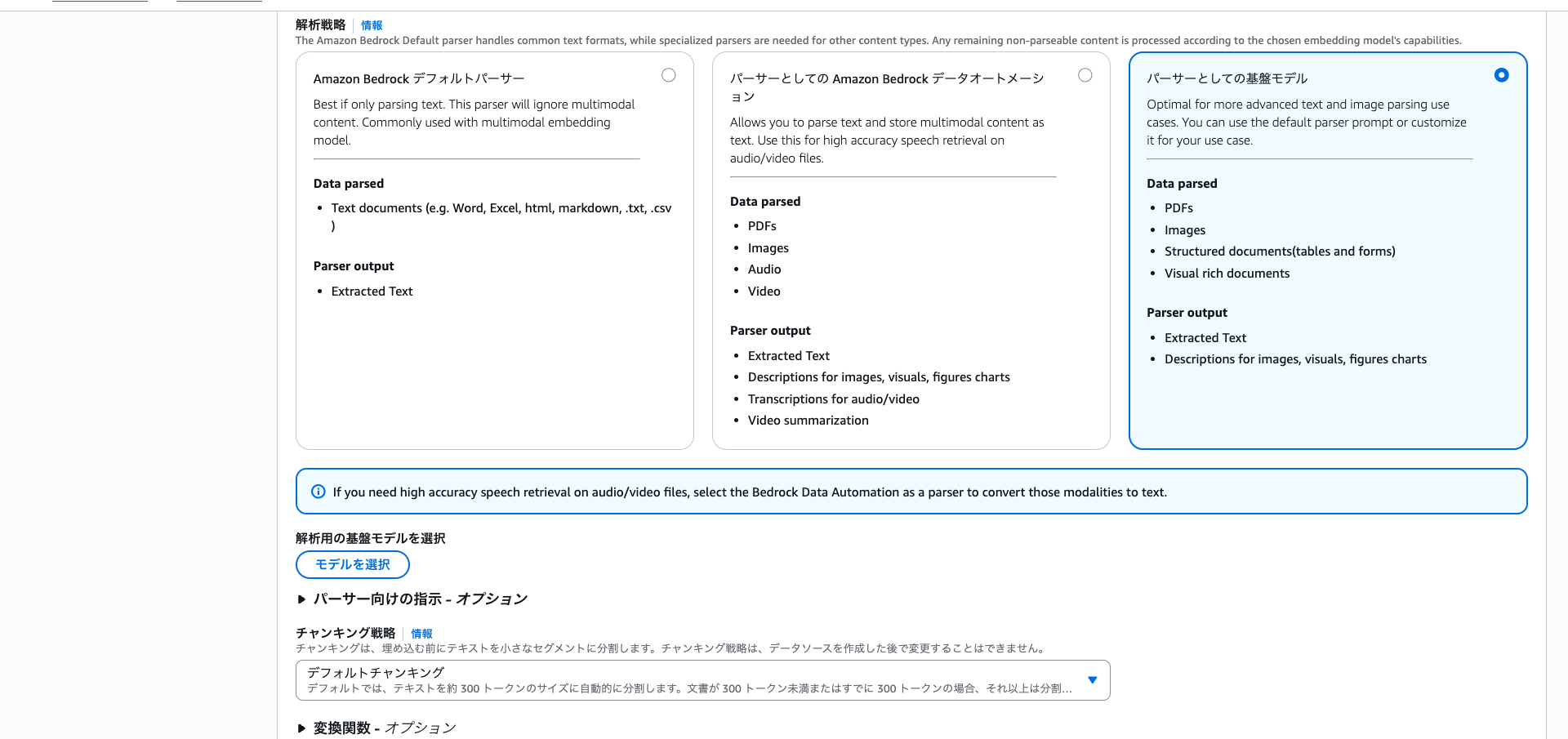
When choosing the default parser, parsing is limited to text content.
Bedrock default parser: Recommended for text-only content processing. This parser processes common text formats while ignoring multimodal files. Supports text documents including Word, Excel, HTML, Markdown, TXT, and CSV files.
With the default parser, it doesn't mean "Amazon Nova Multimodal Embeddings (multimodal embedding) can't be used." It just means "parsing (adding supplementary information) won't be performed," so don't worry.
After creating the knowledge base, I ran synchronization. The processing time was about 3 minutes.
Let's search. Both "cow" and "牛" correctly return results.
cow
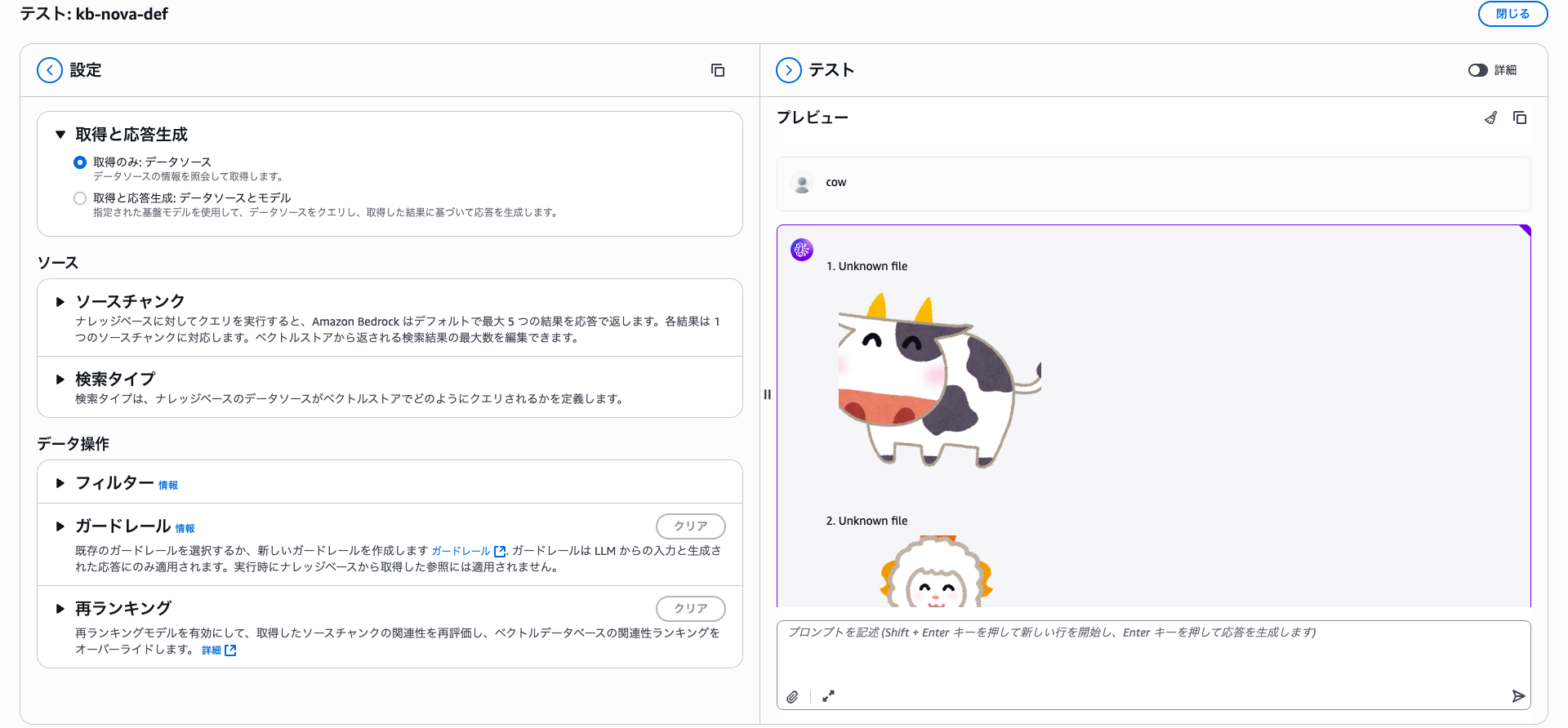
牛
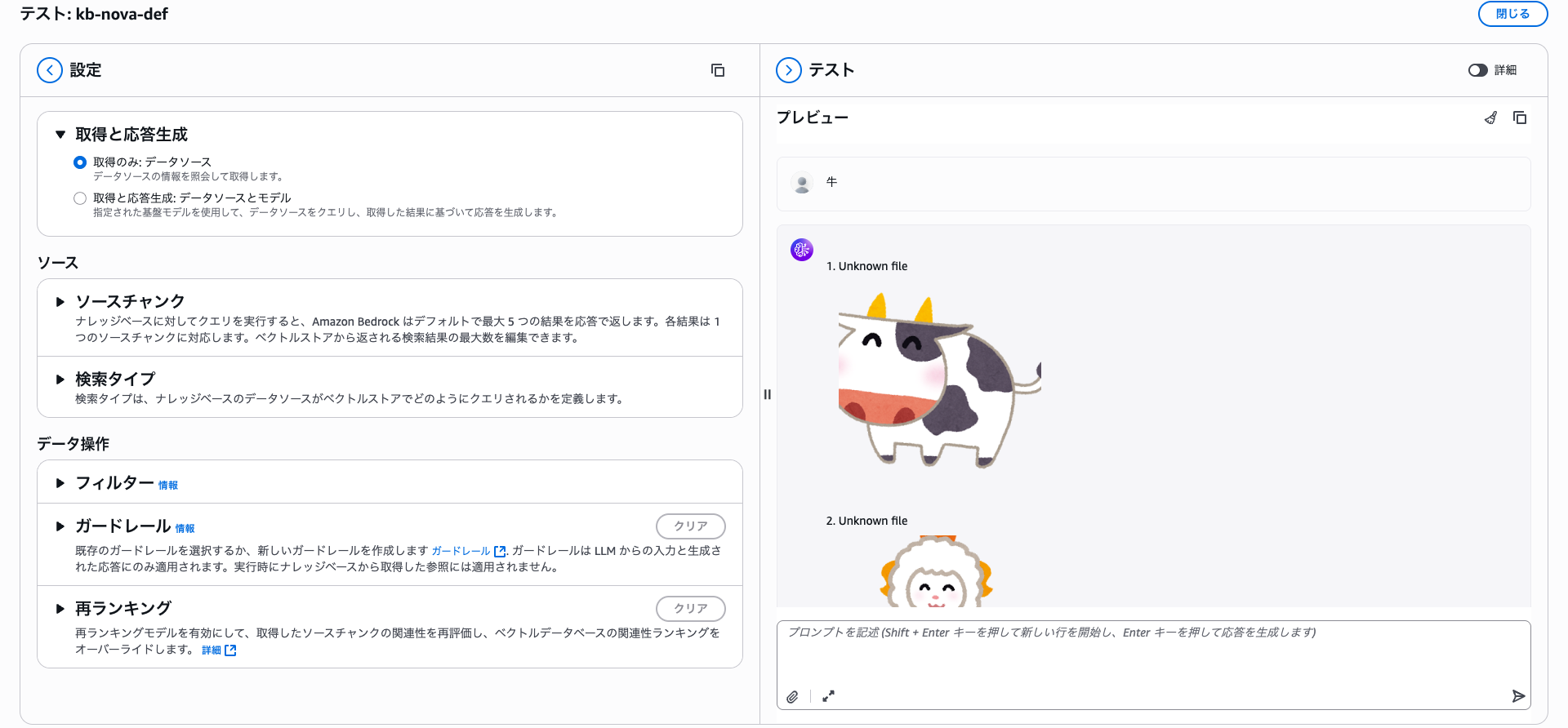
Image Search
Let's try the image search, which is the highlight of this feature. We'll search by attaching a file.
I performed a similarity search for images close to a wild boar. The image similarity search is working successfully.
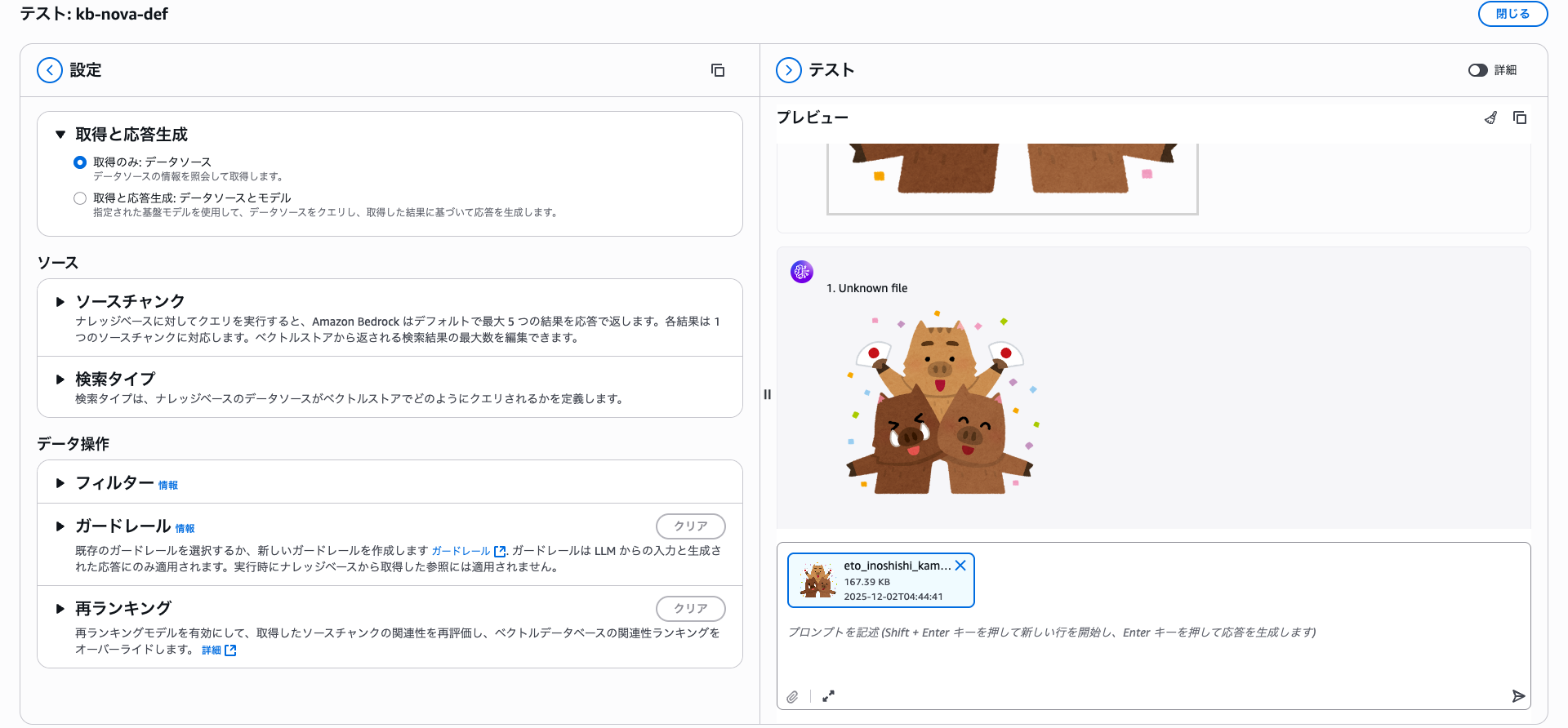
Searches combining images + text are currently not supported.
By the way, the next most similar match after the wild boar was a mouse.
Let's look at the contents of the vector database.
import base64
import json
import sys
import boto3
REGION = "us-east-1"
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
DIMENSION = 3072
VECTOR_BUCKET_NAME = "bedrock-knowledge-base-uvyqtx"
VECTOR_INDEX_NAME = "bedrock-knowledge-base-default-index"
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
s3vectors = boto3.client("s3vectors", region_name=REGION)
query = sys.argv[1]
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(
{
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": DIMENSION,
"text": {
"truncationMode": "END",
"value": query,
},
},
}
),
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
queryVector={"float32": embedding},
topK=3,
returnDistance=True,
returnMetadata=True,
)
print(json.dumps(response["vectors"], indent=2))
We can see that AMAZON_BEDROCK_TEXT doesn't exist, and the images are directly embedded.
takakuni.shinnosuke@HL01556 multimodal % uv run nova-def.py 牛
[
{
"key": "079ac1b2-3634-4d9f-a25c-95085ea11da3",
"metadata": {
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:35Z\",\"modifiedDate\":\"2025-12-02T12:46:35Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_ushi.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/AIVOBLTWS2/2QXBLQPSXV/08099c71-1d3e-4a87-b122-867979ba137e.png\"}}],\"sourceDocumentId\":\"FJyBQGITnOIBecEs/buuYGwErC5w/ryaLjLiNBexU+bPOIF7OyF7LthUNzTvZIn5\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"x-amz-bedrock-kb-data-source-id": "2QXBLQPSXV",
"x-amz-bedrock-kb-source-file-mime-type": "image/png"
},
"distance": 1.4934920072555542
},
{
"key": "de6dc4ba-ae8c-4dd6-b180-e705b5b15c18",
"metadata": {
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:37Z\",\"modifiedDate\":\"2025-12-02T12:46:37Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/uchidenokoduchi_eto01_nedumi.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/AIVOBLTWS2/2QXBLQPSXV/193dd3fd-fda8-4487-b31a-1e68eaaeceda.png\"}}],\"sourceDocumentId\":\"ecQmm41S02ySLchT7ffYQwit0z6NWGMJBVgp3ZWJucVnuRrclVAt5ngmuSA+yPd+\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-data-source-id": "2QXBLQPSXV"
},
"distance": 1.8008359670639038
},
{
"key": "cd107461-8bff-4dfb-aa7d-4ebb966f8dc2",
"metadata": {
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:29Z\",\"modifiedDate\":\"2025-12-02T12:46:29Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_saru_fukubukuro.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/AIVOBLTWS2/2QXBLQPSXV/7569266e-0972-4553-8e57-f42b858d2c3a.png\"}}],\"sourceDocumentId\":\"TLSB8hCikGymA/N9a9YEJZxolakUocVEpk23lB86XGzIEolP729JpJJ9iIDn50Y4\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"x-amz-bedrock-kb-data-source-id": "2QXBLQPSXV"
},
"distance": 1.8240646123886108
}
]
Amazon Nova Multimodal Embeddings Foundation Model Parser
In addition to Amazon Nova Multimodal Embeddings, we'll use the Foundation Model for parsing.
By using the Foundation Model for parsing, we can add supplementary information to non-text files such as images. I named it "kb-nova-foundation". The synchronization time was about 3 minutes for this process as well.
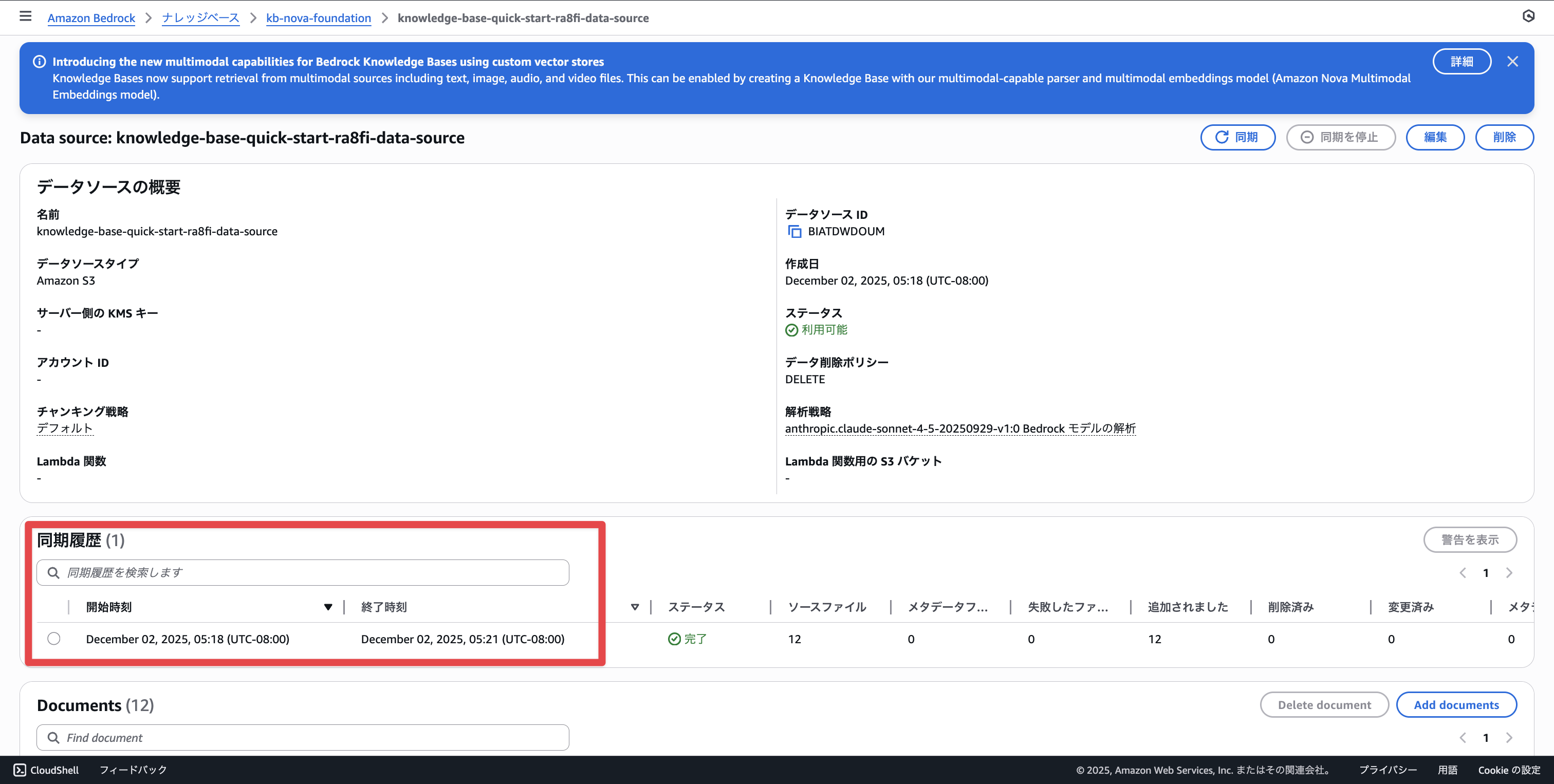
Let's try searching. When we search for "cow" and "牛", we can see the searches are working well.
cow
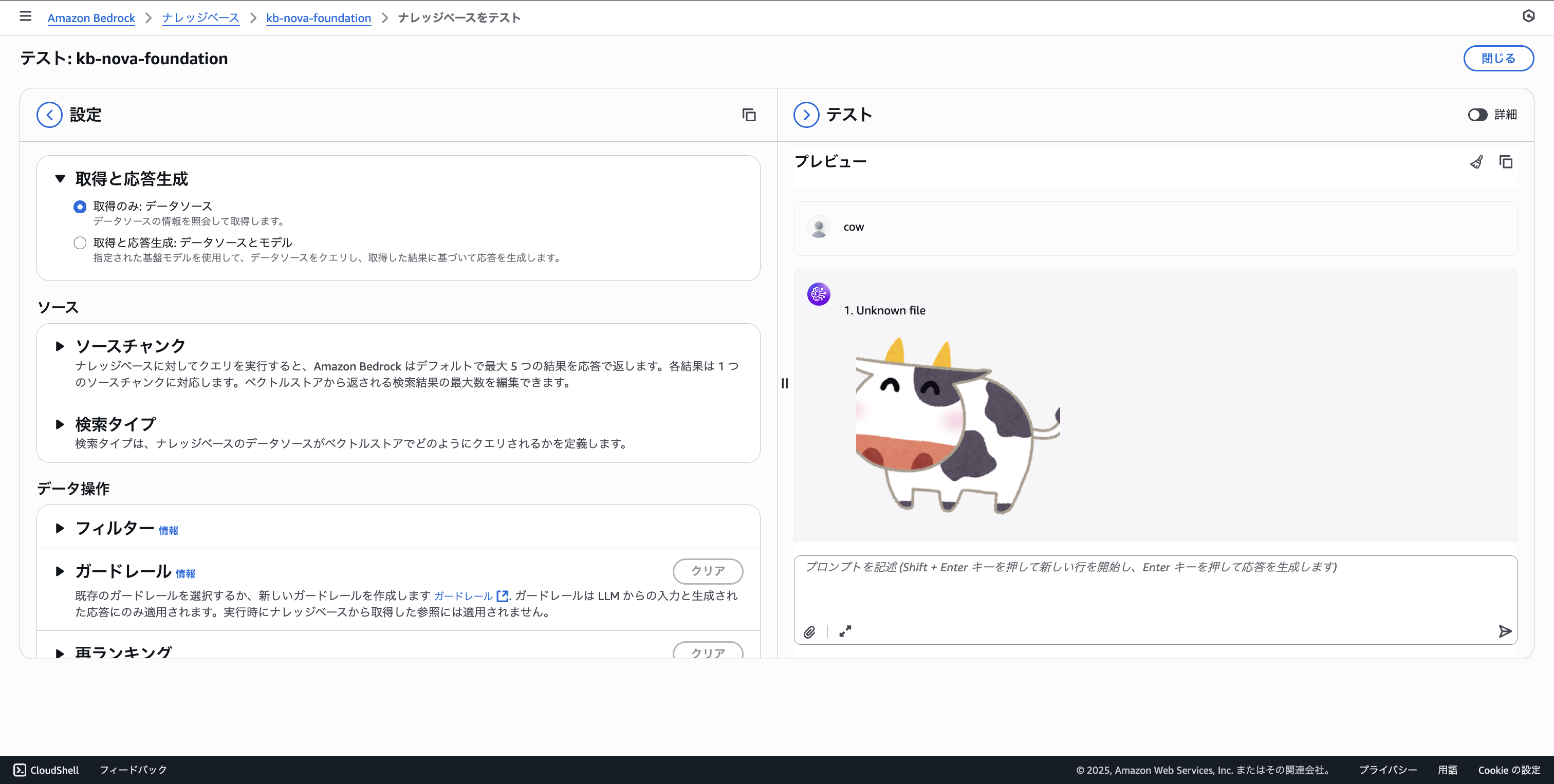
牛
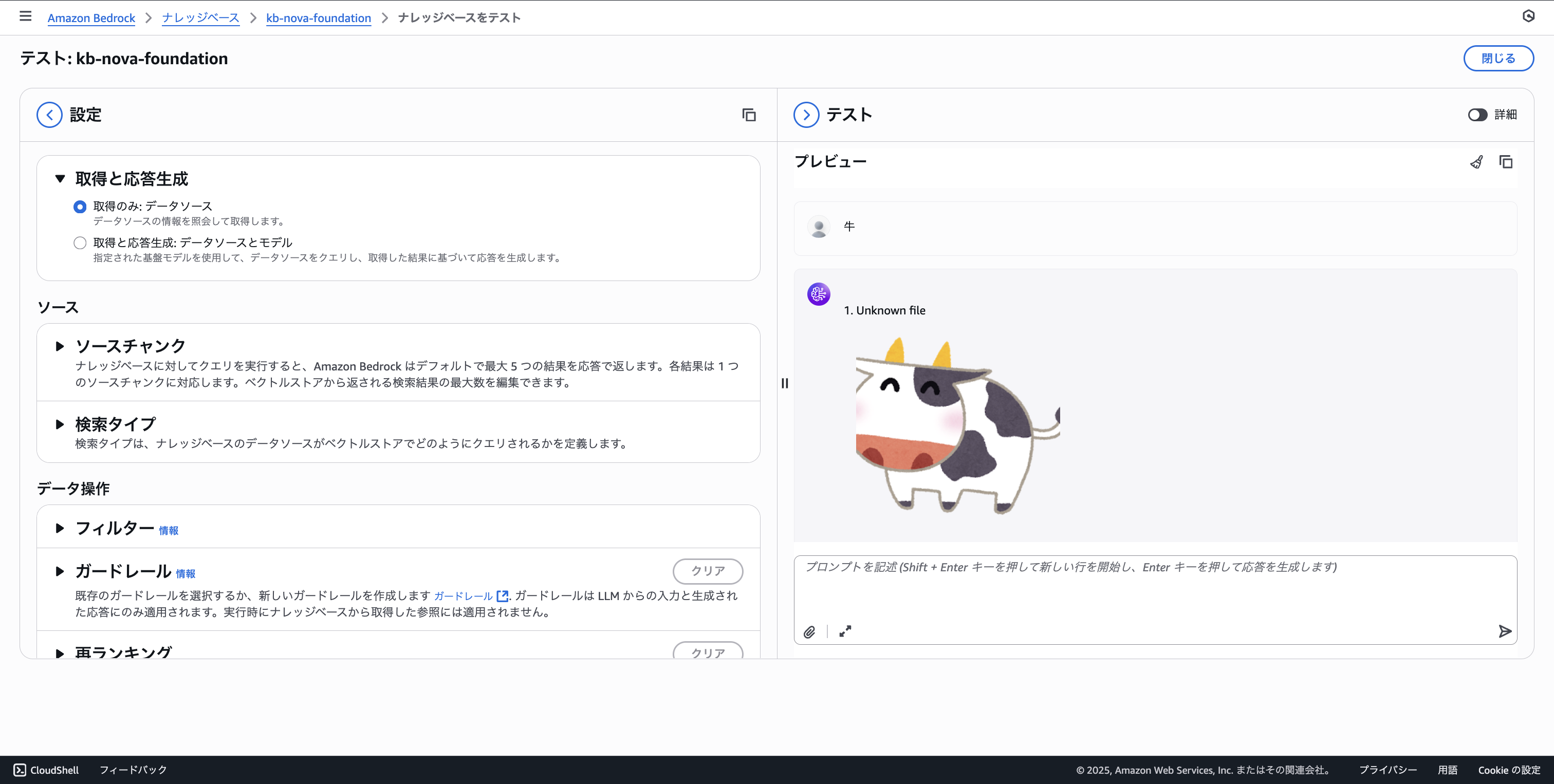
Let's check the vector database as usual.
import base64
import json
import sys
import boto3
REGION = "us-east-1"
MODEL_ID = "amazon.nova-2-multimodal-embeddings-v1:0"
DIMENSION = 3072
VECTOR_BUCKET_NAME = "bedrock-knowledge-base-e4sne0"
VECTOR_INDEX_NAME = "bedrock-knowledge-base-default-index"
bedrock = boto3.client("bedrock-runtime", region_name=REGION)
s3vectors = boto3.client("s3vectors", region_name=REGION)
query = sys.argv[1]
response = bedrock.invoke_model(
modelId=MODEL_ID,
body=json.dumps(
{
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": DIMENSION,
"text": {
"truncationMode": "END",
"value": query,
},
},
}
),
)
response_body = json.loads(response["body"].read())
embedding = response_body["embeddings"][0]["embedding"]
response = s3vectors.query_vectors(
vectorBucketName=VECTOR_BUCKET_NAME,
indexName=VECTOR_INDEX_NAME,
queryVector={"float32": embedding},
topK=3,
returnDistance=True,
returnMetadata=True,
)
print(json.dumps(response["vectors"], indent=2))
We can see that AMAZON_BEDROCK_METADATA contains additional information generated by the Foundation Model.
takakuni.shinnosuke@ multimodal % uv run nova-found.py 牛
[
{
"key": "50205e85-8c81-48f6-a180-11031fc5eb46",
"metadata": {
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:35Z\",\"modifiedDate\":\"2025-12-02T12:46:35Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_ushi.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/CMWY2SJUEQ/BIATDWDOUM/53867e2a-0e00-4a8a-8c3b-0054d9a3ddef.png\"}}],\"sourceDocumentId\":\"FJyBQGITnOIBecEs/buuYGwErC5w/ryaLjLiNBexU+bPOIF7OyF7LthUNzTvZIn5\",\"additionalMetadata\":null}",
"AMAZON_BEDROCK_TEXT": "<markdown> <figure> A cute cartoon illustration of a cow in a simple, childlike art style. The cow is depicted in a side view with a white body and black spots. It has yellow horns, closed happy eyes (shown as curved lines), pink blush on its cheeks, and an orange/coral colored snout. The cow has a gray tail with a tuft at the end. The illustration has a watercolor or painted texture with soft edges and appears to be designed in a kawaii or cute Japanese style. </figure> </markdown>",
"x-amz-bedrock-kb-document-page-number": 0.0,
"x-amz-bedrock-kb-data-source-id": "BIATDWDOUM"
},
"distance": 0.7612391114234924
},
{
"key": "780874cb-6bf7-47f3-a34e-9fbd65fbe51a",
"metadata": {
"x-amz-bedrock-kb-data-source-id": "BIATDWDOUM",
"AMAZON_BEDROCK_TEXT": "<markdown> <figure> An illustration of a stylized green and yellow dragon character in an Asian art style. The dragon has a serpentine body colored in shades of green with darker green patches, orange/yellow antlers or horns on its head, and a yellow belly. The dragon has a friendly, smiling expression with simple facial features and appears to be in a playful, curled pose with its tail visible. The art style is simple and flat with solid colors, suggesting it may be used for children's content or as a mascot. </figure> </markdown>",
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:32Z\",\"modifiedDate\":\"2025-12-02T12:46:32Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/dragon_good.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/CMWY2SJUEQ/BIATDWDOUM/99540a18-3b68-42e1-8b0d-6fc68b0fb467.png\"}}],\"sourceDocumentId\":\"jzPCh68DR2F354chjKbAEaHGfFRyDVRGW3IzjNsY9tMA8BLpUrHLQpnwGvkdOuYM\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-document-page-number": 0.0
},
"distance": 0.8840569257736206
},
{
"key": "8b1fef2e-2012-49b6-b72e-31764ad48a8d",
"metadata": {
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:31Z\",\"modifiedDate\":\"2025-12-02T12:46:31Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/uchidenokoduchi_eto07_uma.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/CMWY2SJUEQ/BIATDWDOUM/8a7b4b5c-0b01-4ea6-b438-c6a5e2b72106.png\"}}],\"sourceDocumentId\":\"AqnYnvijJIoMtA8bscRaLoGfOIa0Odewo3MO9AdDMM6eMtO2TFYJbuVGTyKJJ009\",\"additionalMetadata\":null}",
"AMAZON_BEDROCK_TEXT": "<markdown> <figure> An illustration showing a brown horse standing on its hind legs in a celebratory pose with one front leg raised. The horse is holding what appears to be a yellow lucky cat (maneki-neko) figurine with red and green decorations. Around them are several gold coins with oval patterns and sparkle effects, suggesting good fortune or financial success. </figure> </markdown>",
"x-amz-bedrock-kb-data-source-id": "BIATDWDOUM",
"x-amz-bedrock-kb-document-page-number": 0.0
},
"distance": 0.9140208959579468
}
]
Since we're using Amazon Nova Multimodal Embeddings as the embedding model, image search is also possible.
BDA + Amazon Nova Multimodal Embeddings
What happens when we combine BDA with Amazon Nova Multimodal Embeddings?
As we reviewed earlier, embedding happens after parsing is complete. Therefore, this means that the text data extracted by BDA will be embedded using Amazon Nova Multimodal Embeddings.
If you use the BDA parser with the Amazon Nova Multimodal Embeddings model, the embeddings model will act like a text embeddings model. When working with multimodal content, use one of the processing approaches for best results depending on your use case.
The synchronization time was affected by BDA and took about 5 minutes as well.
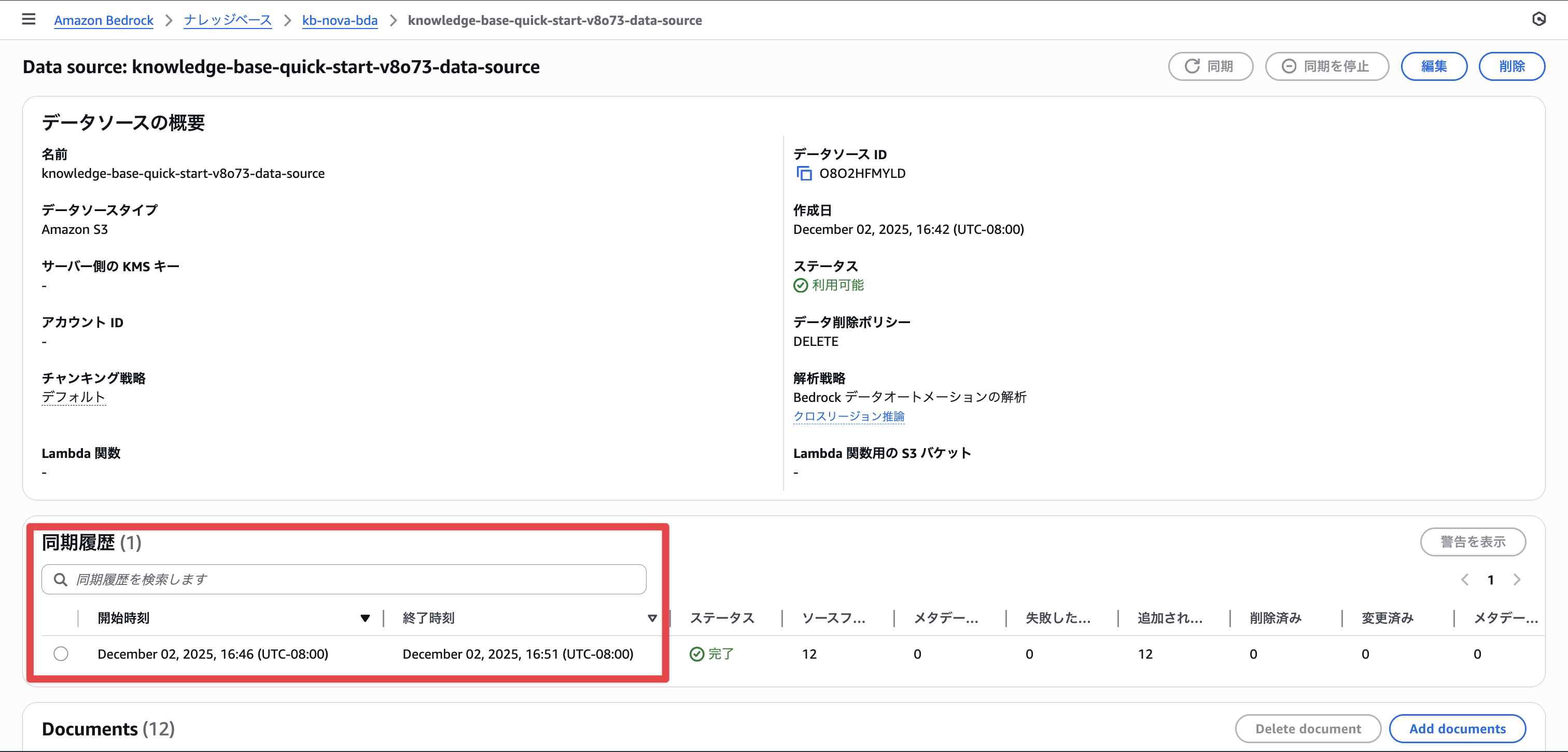
As usual, searches for "cow", "牛", and image search are all working well.
cow
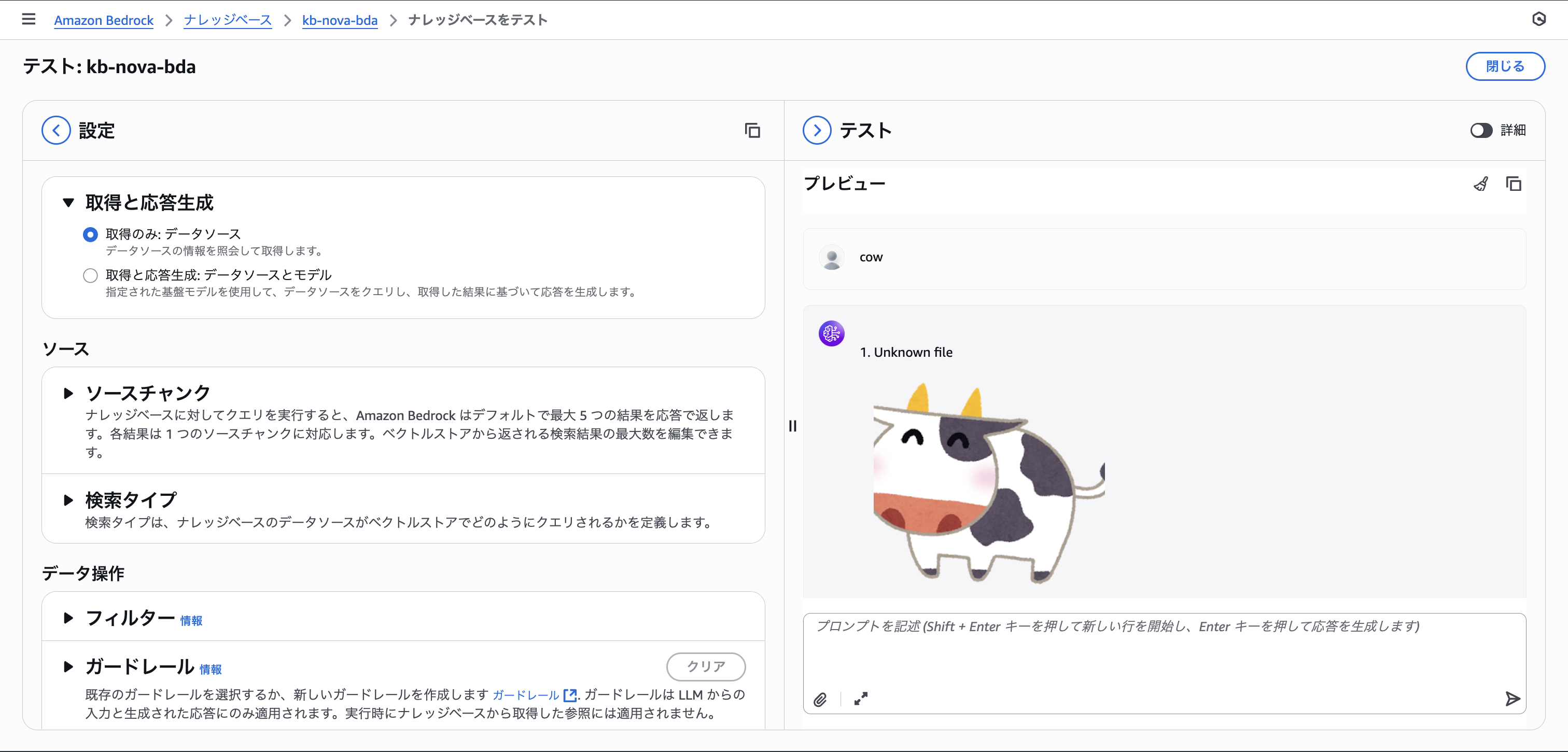
牛
Image Search
Let's check the vector database contents as well.
As mentioned in the documentation, AMAZON_BEDROCK_TEXT is included. It's not clear from this whether the embedded data format is an image or text.
takakuni@ multimodal % python nova-bda.py cow
[
{
"key": "6e29b014-2115-4297-8995-425896f4d0cf",
"metadata": {
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_TEXT": "This image shows a cartoon illustration of a cow with a black and white body, a red nose, and yellow horns. The cow is depicted in a simple, stylized manner with exaggerated features such as large eyes and a wide mouth. The background of the image is solid black, making the cow stand out prominently. The cow appears to be standing with its tail visible on the right side. There are no logos, scene texts, or identified persons in this image.",
"x-amz-bedrock-kb-document-page-number": 0.0,
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:35Z\",\"modifiedDate\":\"2025-12-02T12:46:35Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_ushi.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/KF4GCYJUM4/O8O2HFMYLD/41d81e04-c46e-4e01-a21e-d2188bc099bd.png\"}}],\"sourceDocumentId\":\"FJyBQGITnOIBecEs/buuYGwErC5w/ryaLjLiNBexU+bPOIF7OyF7LthUNzTvZIn5\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"x-amz-bedrock-kb-data-source-id": "O8O2HFMYLD"
},
"distance": 0.6646683812141418
},
{
"key": "a9eccf72-85ed-4435-ad82-eba8efc2bd0e",
"metadata": {
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:27Z\",\"modifiedDate\":\"2025-12-02T12:46:27Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_inu.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/KF4GCYJUM4/O8O2HFMYLD/1ca0a9d2-e577-4ce0-af65-dfb34e81f7ec.png\"}}],\"sourceDocumentId\":\"o625brHQZKEzo/1Ym/sZhMLXdEsjVaJnxgR5BFl/57RIxm4JkV4eiZJb2KUl96PG\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"x-amz-bedrock-kb-data-source-id": "O8O2HFMYLD",
"x-amz-bedrock-kb-document-page-number": 0.0,
"AMAZON_BEDROCK_TEXT": "This image shows a cartoon illustration of a dog with a smiling face. The dog has a brown body and dark brown ears. It is wearing a red collar around its neck. The dog's tail is curved upwards and is also dark brown. The background of the image is black, making the dog stand out prominently. The dog appears to be in a cheerful and friendly pose.",
"x-amz-bedrock-kb-source-file-modality": "IMAGE"
},
"distance": 0.825368344783783
},
{
"key": "c9016068-e612-4b95-8982-ee1d452c8687",
"metadata": {
"AMAZON_BEDROCK_TEXT": "This image shows a cartoon illustration of a tiger with a joyful expression. The tiger has a yellow body with black stripes, a pink nose, and white whiskers. Its mouth is open, showing its teeth, and it appears to be in a playful or happy mood. The tiger's tail is curved upwards, and its paws are positioned as if it is running or leaping. The background of the image is solid black, making the tiger stand out prominently. There are no logos, scene texts, or detected persons in this image.",
"x-amz-bedrock-kb-source-file-mime-type": "image/png",
"x-amz-bedrock-kb-document-page-number": 0.0,
"x-amz-bedrock-kb-source-file-modality": "IMAGE",
"AMAZON_BEDROCK_METADATA": "{\"text\":null,\"author\":null,\"createDate\":\"2025-12-02T12:46:34Z\",\"modifiedDate\":\"2025-12-02T12:46:34Z\",\"source\":{\"sourceLocation\":\"s3://multimodal-2025-12-01-123456789012/contents/eto_remake_tora.png\",\"sourceType\":null},\"descriptionText\":null,\"pageNumber\":null,\"pageSizes\":null,\"graphDocument\":{\"entities\":[]},\"parentText\":null,\"relatedContents\":[{\"locationType\":\"S3\",\"s3Location\":{\"uri\":\"s3://multimodal-out-2025-12-01-123456789012/aws/bedrock/knowledge_bases/KF4GCYJUM4/O8O2HFMYLD/17b55c33-bb63-4f23-bbdd-efc228fefa73.png\"}}],\"sourceDocumentId\":\"SRrW6U/eGeN3KpO54xp2YMstlQT4I+5+tBq4yP1cX9m6qzEsijWVC3fFeBVH/owK\",\"additionalMetadata\":null}",
"x-amz-bedrock-kb-data-source-id": "O8O2HFMYLD"
},
"distance": 0.8383215665817261
}
]
Looking at the Amazon Bedrock logs, we can confirm that embedding is being applied to the text data, as expected.
{
"timestamp": "2025-12-03T00:51:26Z",
"accountId": "123456789012",
"identity": {
"arn": "arn:aws:sts::123456789012:assumed-role/AmazonBedrockExecutionRoleForKnowledgeBase_8jxmm/EmbeddingTask-ZQEJWEU5LT"
},
"region": "us-east-1",
"requestId": "8797bbe2-4d90-4290-bd5b-eeb2a729e661",
"operation": "InvokeModel",
"modelId": "arn:aws:bedrock:us-east-1::foundation-model/amazon.nova-2-multimodal-embeddings-v1:0",
"input": {
"inputContentType": "application/json",
"inputBodyJson": {
"taskType": "SINGLE_EMBEDDING",
"singleEmbeddingParams": {
"embeddingPurpose": "GENERIC_INDEX",
"embeddingDimension": 3072,
"text": {
"truncationMode": "END",
"value": "This image shows a cartoon illustration of a cow with a black and white body, a red nose, and yellow horns. The cow is depicted in a simple, stylized manner with exaggerated features such as large eyes and a wide mouth. The background of the image is solid black, making the cow stand out prominently. The cow appears to be standing with its tail visible on the right side. There are no logos, scene texts, or identified persons in this image."
}
}
},
"inputTokenCount": 94
},
"output": {
"outputContentType": "application/json",
"outputBodyJson": {
"embeddings": [
{
"embeddingType": "TEXT",
"embedding": [
]
}
]
}
},
"schemaType": "ModelInvocationLog",
"schemaVersion": "1.0"
}
Summary
That concludes "Amazon Bedrock Knowledge Bases multimodal search is now generally available."
I hope you now have a better understanding of the differences between Amazon Nova format and BDA format.
I hope this blog has been helpful to you. This was Takakuni from the Cloud Business Division Consulting Department (@takakuni_)!
The
RAG functionalitycontent in Multimodal processing approach is probably referring to this. ↩︎The statement
No support for image-based queries when used without Nova Multimodal Embeddings - all searches must use text inputin Capabilities and limitations is probably referring to the pattern of using BDA + Nova Multimodal Embeddings. I believe it means that while content in the vector database is embedded as text, it's still possible to search using images as input. ↩︎Since Strands Agents only uses the Retrieve API, the impact is minimal ↩︎