![[Report] Integrating HR Data Using MCP for Decision Making #ISV319 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[Report] Integrating HR Data Using MCP for Decision Making #ISV319 #AWSreInvent
This page has been translated by machine translation. View original
Hello, I'm Kamino from the Consulting Department, and I love supermarkets.
In this article, I'll be sharing a session report from the Lightning Talk "No More Orphans: Bringing Work and People Data Into Decisions with MCP (ISV319)" that I attended at re:Invent 2025.
I was interested in this session because it introduced a case study of utilizing MCP in the HR field, which directly connects to practical business. I wanted to learn how companies are integrating data at the enterprise level to achieve this.
Session Overview
- Session Title: No More Orphans: Bringing Work and People Data Into Decisions with MCP (ISV319)
- Speakers:
- Kinman (Sr. Solutions Architect, AWS)
- Ike Benion (VP of Product Management, Platform, Visier)
- Date & Time: Wednesday, Dec 3, 12:30 PM - 12:50 PM PST
- Venue: Mandalay Bay | Level 2 South | Oceanside C | Content Hub | Lightning Theater
- Level: 300 – Advanced
- Format: Lightning Talk
Session Description (Official)
Managers make dozens of high-impact decisions every week — but too often, work and people data is missing from the table especially in ad hoc decisions. The result? Strategy built on partial context, disconnected systems, and underused insights. In this session, we'll explore how Visier's Model Context Protocol (MCP) server changes that. By transforming fragmented HR and workforce data into a unified, AI-ready semantic layer, MCP lets organizations combine people data with critical business data, automate context delivery, and surface insights where decisions happen.
Session Content
What is the "Orphan Data" Problem?
The session began with an impressive question from moderator Kinman.
"You've been tasked with forming a team from existing employees for an important project. Who's interested? Who has the capacity? Who has the skills to make this project successful?"
Many managers and leaders make decisions without complete information because data is scattered across multiple systems. This is the "Orphan Data problem," which takes away the ability to make better decisions.
I had never heard the term "Orphan Data" before, but I learned that it refers to isolated data as described above.
Three Fundamental Challenges

Ike Benion highlighted three problems that prevent data-driven decision making:
1. Data Challenge
Data is scattered throughout the enterprise ecosystem, and trying to integrate it in one place over decades still remains a significant challenge. This presents a major opportunity that can be addressed with technology stacks like MCP.
2. Time Challenge
While pre-built processes incorporate data for decision-making, ad hoc decisions (many HR-related decisions made daily) don't have data available when needed.
3. Data Literacy Challenge
Many organizations struggle with data literacy itself, such as how to use available data, understanding different metric definitions, and the relationships between data.
It was explained that all three challenges can be addressed by implementing MCP and agents within enterprises to achieve data integration.
I found these three challenges quite relatable. It's not straightforward to make data-driven decisions when you need to organize the data itself and prepare infrastructure for immediate use.
Visier's MCP Server Architecture

Visier's architecture consists of the following components:
Data Sources and Ingest Layer
Ingests data from various sources throughout the enterprise ecosystem, such as HCM (Human Capital Management), ERP, VMS (Vendor Management System), and performs data cleansing and preparation.
Semantic Layer
Designed with thousands of ready-to-use metrics, concepts, and dimensions that answer questions across the entire employee lifecycle. Since these are pre-designed, organizations can start using this data immediately.
Caching and Delivery Layer
Analytics processing in large databases requires significant computational resources and tends to cause delays. Visier employs caching and other techniques to speed up data retrieval.
MCP Deployment
MCP is stacked on top of existing APIs in the caching and delivery layer.
There was an explanation of the specific implementation of the MCP server built with AWS support:
- Amazon ECR (Elastic Container Registry): Release management for MCP server containers
- Amazon EC2: Container deployment to global regions and availability zones
- Elastic Load Balancer & Auto Scaling Group: Scaling EC2 instances according to demand changes
- Amazon Route 53: Domain name matching for multi-tenant hierarchy (as each organization has its own environment)
- Amazon CloudWatch: Monitoring performance and uptime
They built the server based on open-source MCP code with modifications for Visier's specific use cases. It's a standard AWS configuration using Claude as the MCP client. With many users, it's also important to use caching to keep costs down.
Demo: Engineer Attrition Risk Analysis
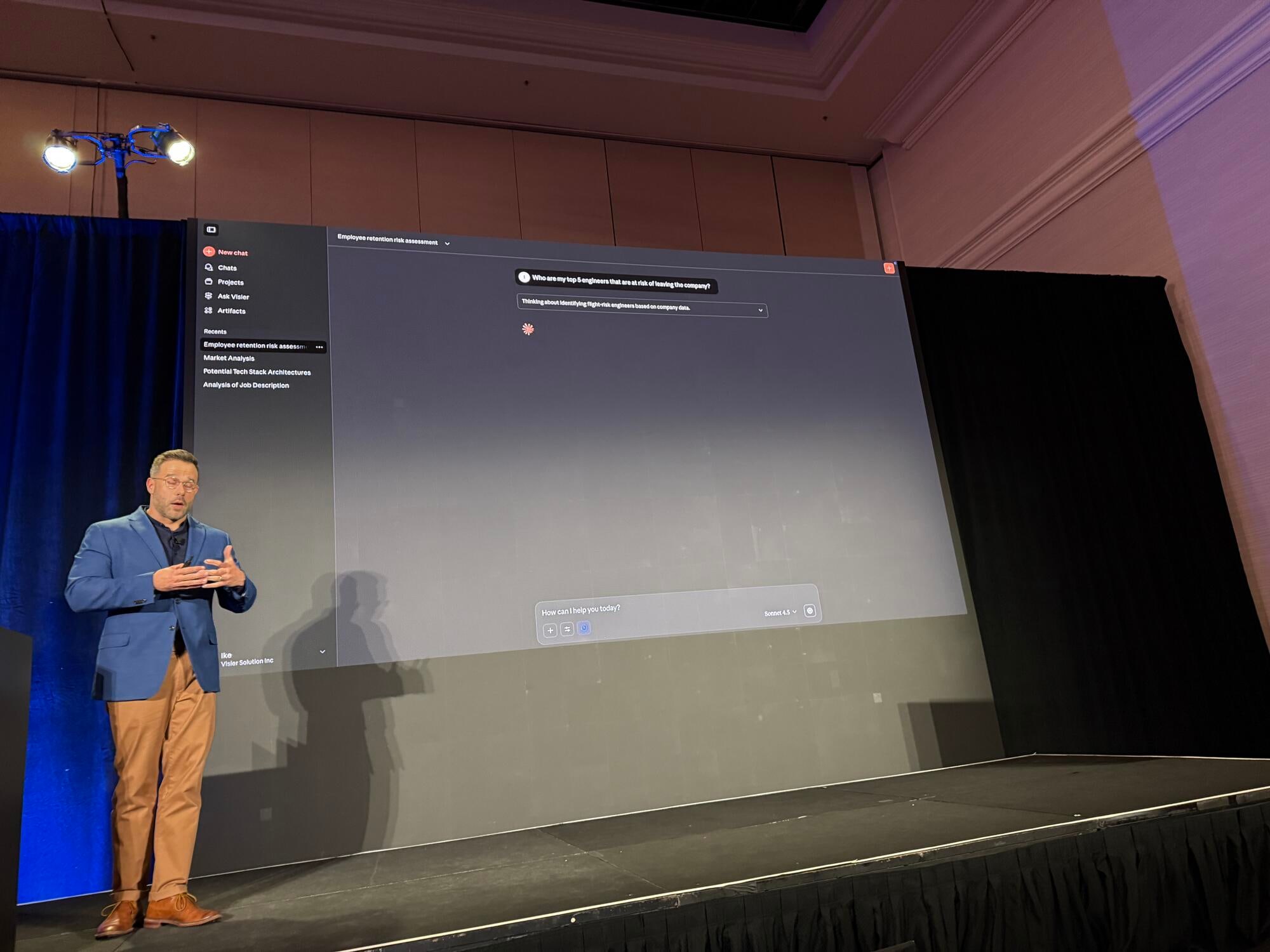

The actual demo showcased a use case using Claude. They showed an example of querying the MCP Server. The demo and scenarios were easy to understand because they used familiar examples. Here are the specifics:
Scenario Setting
As a leader of an engineering development team, you've experienced the shocking event of a high performer resigning. You want to know what can be done to keep the remaining key members.
This scenario feels like a common situation, which makes it interesting.
Initial Prompt to Claude
Claude connects to Visier's MCP server and begins retrieving various tools. It performs analysis object searches, object filtering, organizational level information retrieval, and outputs results like "who are the top 5 employees" and "what is the resignation risk for next year."
Difference Between MCP and API
Ike emphasized how MCP is superior to APIs. MCP can provide additional context about the purpose of tools and how agents should use them. This enables better operation with many APIs and becomes scalable over time. Once integrated with MCP, you don't need to change settings for all connected systems when improving the API side.
Analysis of Resignation Risk Factors
Knowing is not enough; it's important to know "what should be done" as a result. So, they ask about the factors contributing to resignation risk.
The agent takes the five high-risk engineers and analyzes each factor. As a result, issues with compensation, career stagnation, poor relationships with managers, and performance concerns were identified.
I found this interesting while listening - connecting HR data for such use cases is fascinating. If you can retrieve data through an MCP server, it would be valuable to have something that can bounce ideas off or generate hypotheses for us in our daily work. At the same time, I felt that a lot of data would be needed for analysis, which could pose challenges, but it's impressive that they've organized it to this extent.
Lessons Learned

Ike shared important lessons learned from implementing MCP:
API Restructuring is Necessary
Wrapping existing APIs is a common approach, but APIs are built for specific use cases and fundamentally differ from how agents approach them. Some work will be necessary, such as providing additional tools, integrating endpoints, and splitting MCPs according to use cases.
This is helpful reference. While they tried to reuse as much as possible, there are challenging areas like authentication, so it's important to consider options like splitting or recreating if it's lightweight.
Difficulty in Agent Error Handling
Agents don't kindly tell you what went wrong. If you think you'll find it in a typical interface, you won't. Having observability on the API side is more effective. Ensure proper behavior and provide predictable, high-quality results over time.
I often feel the difficulty of debugging when creating AI agents myself. Since AI agents don't always behave the same way, it's important to be able to see input, output, and tool results in detail and consistently.
For AWS's AI agent service AgentCore, it seems important to check observability with application logs and dashboards provided by Observability, and to evaluate the agent itself using the recently added Evaluation feature.
Tool Descriptions are Critical
The errors seen in the demo were caused by dependencies between two APIs. The best solution is to provide better instructions for tools. However, in multi-agent environments, it's observed that agents use tools in different ways, inconsistently. Think strategically about both implementation methods and how customers implement them.
I felt that Anthropic's article on creating good tools for agents is relevant to this topic.
Cost Considerations
Potential costs are a major consideration. As preventive measures, they mitigated costs with typical measures like caps and rate limits. For example, preventing agents with errors from causing performance issues on the server. You don't know what use cases for APIs will actually look like until you try. In corporate initiatives, many are still in the pilot stage.
Future Outlook

Visier's future direction was explained around three questions:
Expanding Returns to Agents
Agents often seek very limited and direct information from systems, which may restrict end-user value compared to UI interactions. Visier is considering using their proprietary LLM (which is very knowledgeable about data, user context, what users are looking for, and what they should ask) to provide broader value propositions and give agents the right context to deliver better stories about data that helps managers.
It's important to consider the attributes of users themselves. I got the impression that we could provide more user-appropriate responses by giving them memory or sharing attributes from master data.
Predicting Scaled Use Cases
With many pilot use cases with enterprise partners, they're considering what the number and diversity of customers will look like, and what will happen when MCP provides services to a wider user base in production environments.
Impact of Additional Tools
What impact would there be if new tools such as visualization capabilities were added to the basic query tools currently provided? Also, to what extent will users trust and utilize the results generated by agents using these additional tools for decision-making?
Conclusion
In this session, I learned about Visier's approach to solving HR data integration problems using MCP.
Although it was a 20-minute Lightning Talk, I felt it was filled with practical MCP use cases and valuable lessons. It was interesting to think about how I would design it myself. I want to reflect on what I learned today when designing and building MCP Servers in the future.
While it wasn't very visible in this talk, I felt that their success despite various challenges in preparing data and implementing MCP Server could be a good case study for other companies.
That concludes my session report. Thank you for reading to the end!