
Implementing Delay Guard to Solve the Problem of Increasing Processing Delays in Twilio Media Streams
This page has been translated by machine translation. View original
Introduction
With Twilio Media Streams, you can receive voice during calls in real-time via WebSocket. However, when downstream processing (e.g., voice analysis or AI inference) becomes heavy, unprocessed audio accumulates in the queue, causing you to process increasingly older audio, with delays snowballing. As a result, a situation can occur where the server handles audio that a user just spoke with a delay of several seconds to tens of seconds.

In this article, we will implement a "delay guard" as one solution to this problem and verify its effectiveness. A delay guard refers to a mechanism that thins out old audio when exceeding a latency budget (e.g., 200 ms). As an existing concept, it is similar to load shedding (thinning) to maintain latency targets. The aim of this article is to compare how latency changes with and without this mechanism.
Target Audience
- Those who want to try Media Streams but are concerned about handling latency
- Those who want to understand how latency increases in real-time voice processing and potential countermeasures
Prerequisites
- One-way only (Twilio → server)
- Processing to return received audio to the Twilio side is out of scope
- "Delay guard" suppresses latency by discarding audio
- There is a trade-off in "reducing latency at the cost of reduced information"
Terminology
- Backlog
How much unprocessed audio has accumulated in terms of time, expressed in ms
backlog = latest received timestamp − processed timestamp - Latency Budget
An upper guideline beyond which user experience deteriorates - Delay Guard
A mechanism that thins out old audio to keep up with the latest when about to exceed the latency budget
References
- Media Streams WebSocket messages | Twilio Docs
- Consume real-time Media Streams using WebSockets | Twilio Docs
Architecture
- Receive audio events from Twilio via WebSocket
- Queue the received
media - Workers take items from the queue for processing (fixed sleep in this case)
- If delay guard is enabled, discard old items when backlog exceeds the threshold
Implementation
Operations in Twilio Console
Create a Function for the Incoming Webhook in Twilio Functions.
/media-stream-incoming Function
exports.handler = function (context, event, callback) {
const WSS_URL = context.WSS_URL; // This is an environment variable on Twilio side
const twiml = new Twilio.twiml.VoiceResponse();
// Start stream from Twilio → WebSocket server
twiml.start().stream({
url: WSS_URL,
track: 'inbound_track',
});
// Minimal response to keep the call from ending immediately (for testing)
twiml.say('Media stream started. Please speak.');
twiml.pause({ length: 60 });
callback(null, twiml);
};
Set the environment variables as follows:
| Variable Name | Example | Meaning |
|---|---|---|
WSS_URL |
wss://****.com/twilio |
Connection destination obtained in the procedure described later |
Enter the URL of the above Function in the Voice Configuration Incoming Webhook of the Twilio purchased number, and set POST as the request type.
Building a WebSocket Server
For this purpose, we used Render.com since "it's fine as long as it can be published externally and receive WSS."
The environment variables on the Render side are as follows:
| Variable Name | Example | Meaning |
|---|---|---|
SLEEP_MS |
60 | Simulated processing time (ms) |
L1_MS |
200 | Latency budget (ms) |
ENABLE_GOVERNOR |
0 / 1 | Disable/Enable delay guard |
The server.js for testing is as follows:
server.js
const http = require('http');
const express = require('express');
const { WebSocketServer } = require('ws');
const app = express();
const port = process.env.PORT || 3000;
app.get('/', (req, res) => {
res.status(200).send('ok');
});
const server = http.createServer(app);
const wss = new WebSocketServer({ server, path: '/twilio' });
// Environment variables controlled on Render side
const SLEEP_MS = Number(process.env.SLEEP_MS || 60);
const ENABLE_GOVERNOR = String(process.env.ENABLE_GOVERNOR || '0') === '1';
const L1_MS = Number(process.env.L1_MS || 200);
// monotonic elapsed time (ms)
const t0 = process.hrtime.bigint();
function nowMs() {
return Number((process.hrtime.bigint() - t0) / 1000000n);
}
function sleep(ms) {
return new Promise((resolve) => setTimeout(resolve, ms));
}
wss.on('connection', (ws, req) => {
console.log('[ws] connected', { path: req.url });
const state = {
streamSid: null,
mediaFormat: null,
tsLatest: null,
tsDone: null,
lastSeq: null,
droppedChunks: 0,
queue: [], // { ts, seq }[]
closed: false,
};
function backlogMs() {
if (state.tsLatest == null || state.tsDone == null) return null;
return state.tsLatest - state.tsDone;
}
// Delay guard: Discard items "older than L1_MS from latest" (drop-head)
function applyGovernor() {
if (!ENABLE_GOVERNOR) return;
if (state.tsLatest == null) return;
const cutoff = state.tsLatest - L1_MS;
while (state.queue.length > 0) {
const head = state.queue[0];
if (head.ts >= cutoff) break;
state.queue.shift();
state.droppedChunks += 1;
}
}
async function workerLoop() {
for (;;) {
if (state.closed) return;
if (state.queue.length === 0) {
await sleep(5);
continue;
}
const item = state.queue.shift();
// Simulated downstream (fixed sleep)
await sleep(SLEEP_MS);
state.tsDone = item.ts;
// Check if we're keeping up with each processing
applyGovernor();
}
}
// Output only one line of CSV per second (to prevent log inflation)
const metricTimer = setInterval(() => {
const b = backlogMs();
if (b == null) return;
// metric,t_wall_ms,ts_latest,ts_done,backlog_ms,queue_len,dropped_chunks,governor,sleep_ms,l1_ms
console.log(
[
'metric',
nowMs(),
state.tsLatest,
state.tsDone,
b,
state.queue.length,
state.droppedChunks,
ENABLE_GOVERNOR ? 1 : 0,
SLEEP_MS,
L1_MS,
].join(',')
);
}, 1000);
workerLoop().catch((e) => {
console.log('[worker] error', { message: e?.message });
});
ws.on('message', (message) => {
const text = Buffer.isBuffer(message) ? message.toString('utf8') : String(message);
let data;
try {
data = JSON.parse(text);
} catch (e) {
return;
}
const ev = data.event;
if (ev === 'connected') {
console.log('[twilio] connected');
return;
}
if (ev === 'start') {
state.streamSid = data.start?.streamSid ?? null;
state.mediaFormat = data.start?.mediaFormat ?? null;
state.tsLatest = null;
state.tsDone = null;
state.lastSeq = null;
state.droppedChunks = 0;
state.queue.length = 0;
console.log('[twilio] start', {
streamSid: state.streamSid,
mediaFormat: state.mediaFormat,
governor: ENABLE_GOVERNOR ? 1 : 0,
sleepMs: SLEEP_MS,
l1Ms: L1_MS,
});
return;
}
if (ev === 'media') {
const ts = Number(data.media?.timestamp);
const seq = Number(data.sequenceNumber);
if (!Number.isFinite(ts) || !Number.isFinite(seq)) return;
if (state.lastSeq != null && seq !== state.lastSeq + 1) {
console.log('[warn] seq gap', { prev: state.lastSeq, current: seq, delta: seq - state.lastSeq });
}
state.lastSeq = seq;
state.tsLatest = ts;
state.queue.push({ ts, seq });
// Check catch-up at receipt time as well
applyGovernor();
return;
}
if (ev === 'stop') {
console.log('[twilio] stop', { streamSid: state.streamSid ?? data.streamSid });
return;
}
});
ws.on('close', () => {
state.closed = true;
clearInterval(metricTimer);
console.log('[ws] closed');
});
ws.on('error', (err) => {
console.log('[ws] error', { message: err?.message });
});
});
server.listen(port, '0.0.0.0', () => {
console.log('[http] listening', { port: String(port) });
});
Deploy it with the following steps:
- Push to GitHub
- Create a Web Service on Render.com and connect the repository
- Set Start Command to
node server.js - Set Environment Variables for
SLEEP_MS,L1_MS,ENABLE_GOVERNOR - After deployment, confirm that
https://<service>.onrender.com/returnsok
Testing
Under the same conditions, make approximately 60-second voice calls to the Twilio number and compare these two patterns:
- Pattern A: No delay guard (
ENABLE_GOVERNOR=0) - Pattern B: With delay guard (
ENABLE_GOVERNOR=1,L1_MS=200)
The simulated processing is fixed at SLEEP_MS=60. This is to ensure a situation where "processing cannot keep up."
On Render.com, we set the log mode to Live tail and collected logs.
Results
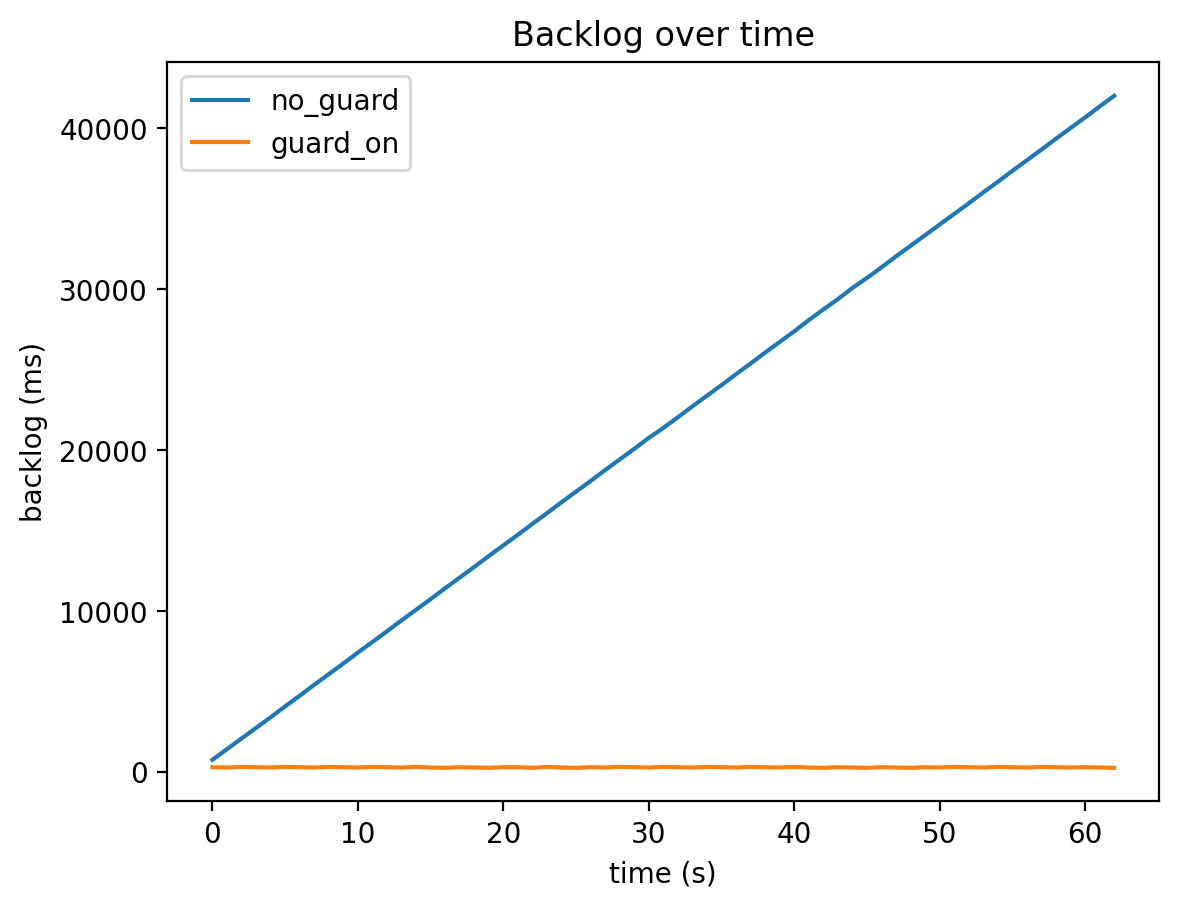
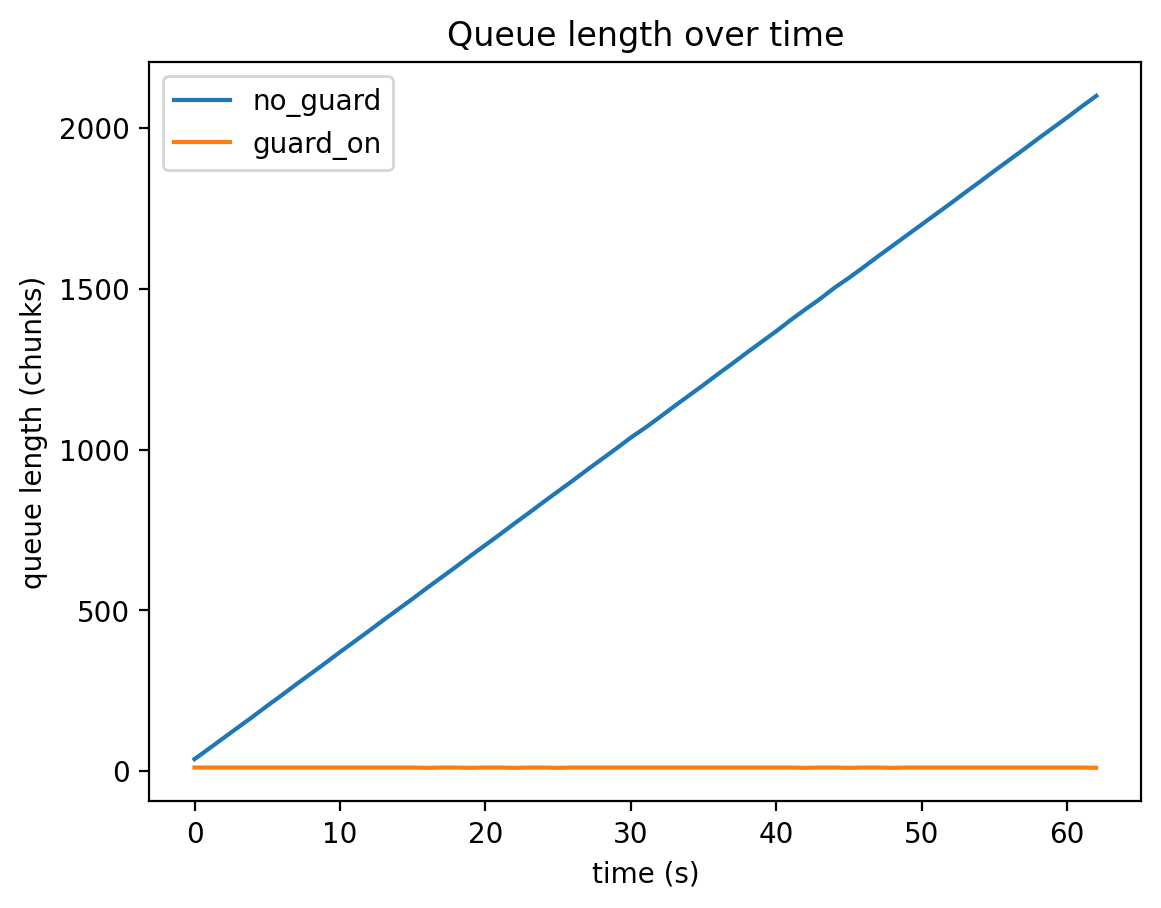
Aggregating the logs from this test (63 samples each, about 62 seconds) resulted in the following:
| Condition | Max Backlog | Median Backlog | 95th Percentile Backlog | Max Queue | Total Dropped |
|---|---|---|---|---|---|
| No delay guard | 42020 ms | 21380 ms | 39954 ms | 2100 | 0 |
| With delay guard | 320 ms | 300 ms | 320 ms | 11 | 2089 |
-
Pattern A: No delay guard
The backlog expanded to about 42 seconds at maximum. This is a state where the server might handle "what was just spoken" with a delay of tens of seconds. -
Pattern B: With delay guard
The backlog was kept to around 320 ms maximum. In exchange, thinning occurred for the portion that couldn't be processed in time.
Backlog Progression
Queue Length Progression
Cumulative Dropping with Delay Guard Enabled

Pattern A Detailed Data
metric,t_wall_ms,ts_latest,ts_done,backlog_ms,queue_len,dropped_chunks,governor,sleep_ms,l1_ms
metric,127053,1227,467,760,37,0,0,60,200
metric,128053,2227,807,1420,70,0,0,60,200
metric,129053,3207,1127,2080,103,0,0,60,200
metric,130053,4207,1467,2740,136,0,0,60,200
metric,131053,5207,1807,3400,169,0,0,60,200
metric,132053,6207,2127,4080,203,0,0,60,200
metric,133053,7207,2467,4740,236,0,0,60,200
metric,134053,8207,2787,5420,270,0,0,60,200
metric,135053,9207,3127,6080,303,0,0,60,200
metric,136053,10207,3467,6740,336,0,0,60,200
metric,137053,11207,3787,7420,370,0,0,60,200
metric,138053,12207,4127,8080,403,0,0,60,200
metric,139053,13207,4467,8740,436,0,0,60,200
metric,140053,14207,4787,9420,470,0,0,60,200
metric,141053,15207,5127,10080,503,0,0,60,200
metric,142053,16207,5467,10740,536,0,0,60,200
metric,143053,17207,5787,11420,570,0,0,60,200
metric,144053,18207,6127,12080,603,0,0,60,200
metric,145053,19207,6467,12740,636,0,0,60,200
metric,146053,20207,6787,13420,670,0,0,60,200
metric,147053,21207,7127,14080,703,0,0,60,200
metric,148053,22207,7467,14740,736,0,0,60,200
metric,149053,23207,7787,15420,770,0,0,60,200
metric,150053,24207,8127,16080,803,0,0,60,200
metric,151053,25207,8447,16760,837,0,0,60,200
metric,152053,26207,8787,17420,870,0,0,60,200
metric,153054,27207,9127,18080,903,0,0,60,200
metric,154054,28207,9447,18760,937,0,0,60,200
metric,155054,29207,9787,19420,970,0,0,60,200
metric,156054,30207,10127,20080,1003,0,0,60,200
metric,157054,31207,10447,20760,1037,0,0,60,200
metric,158054,32167,10787,21380,1068,0,0,60,200
metric,159054,33167,11127,22040,1101,0,0,60,200
metric,160054,34167,11447,22720,1135,0,0,60,200
metric,161054,35167,11787,23380,1168,0,0,60,200
metric,162054,36167,12127,24040,1201,0,0,60,200
metric,163054,37167,12447,24720,1235,0,0,60,200
metric,164054,38167,12787,25380,1268,0,0,60,200
metric,165054,39167,13107,26060,1302,0,0,60,200
metric,166054,40167,13447,26720,1335,0,0,60,200
metric,167054,41167,13787,27380,1368,0,0,60,200
metric,168055,42187,14107,28080,1403,0,0,60,200
metric,169055,43187,14447,28740,1436,0,0,60,200
metric,170056,44167,14787,29380,1468,0,0,60,200
metric,171057,45187,15107,30080,1503,0,0,60,200
metric,172057,46147,15447,30700,1534,0,0,60,200
metric,173057,47147,15787,31360,1567,0,0,60,200
metric,174057,48147,16107,32040,1601,0,0,60,200
metric,175058,49147,16447,32700,1634,0,0,60,200
metric,176058,50147,16787,33360,1667,0,0,60,200
metric,177058,51127,17107,34020,1700,0,0,60,200
metric,178058,52127,17447,34680,1733,0,0,60,200
metric,179062,53127,17787,35340,1766,0,0,60,200
metric,180063,54127,18107,36020,1800,0,0,60,200
metric,181063,55127,18447,36680,1833,0,0,60,200
metric,182063,56127,18767,37360,1867,0,0,60,200
metric,183064,57127,19107,38020,1900,0,0,60,200
metric,184064,58127,19447,38680,1933,0,0,60,200
metric,185065,59127,19767,39360,1967,0,0,60,200
metric,186065,60127,20107,40020,2000,0,0,60,200
metric,187065,61127,20447,40680,2033,0,0,60,200
metric,188065,62127,20767,41360,2067,0,0,60,200
metric,189065,63127,21107,42020,2100,0,0,60,200
Pattern B Detailed Data
metric,t_wall_ms,ts_latest,ts_done,backlog_ms,queue_len,dropped_chunks,governor,sleep_ms,l1_ms
metric,24066,1187,887,300,11,29,1,60,200
metric,25065,2187,1907,280,11,62,1,60,200
metric,26065,3187,2867,320,11,96,1,60,200
metric,27065,4167,3867,300,11,128,1,60,200
metric,28066,5167,4887,280,11,161,1,60,200
metric,29066,6167,5847,320,11,195,1,60,200
metric,30066,7167,6867,300,11,228,1,60,200
metric,31066,8167,7887,280,11,261,1,60,200
metric,32067,9167,8847,320,11,295,1,60,200
metric,33066,10167,9867,300,11,328,1,60,200
metric,34066,11167,10887,280,11,361,1,60,200
metric,35066,12167,11847,320,11,395,1,60,200
metric,36066,13167,12867,300,11,428,1,60,200
metric,37066,14147,13867,280,11,460,1,60,200
metric,38066,15147,14827,320,11,494,1,60,200
metric,39066,16147,15867,280,11,527,1,60,200
metric,40067,17147,16887,260,10,561,1,60,200
metric,41066,18147,17847,300,11,594,1,60,200
metric,42066,19147,18867,280,11,627,1,60,200
metric,43066,20147,19887,260,10,661,1,60,200
metric,44066,21147,20847,300,11,694,1,60,200
metric,45067,22147,21847,300,11,727,1,60,200
metric,46066,23147,22887,260,10,761,1,60,200
metric,47066,24147,23827,320,11,794,1,60,200
metric,48066,25107,24827,280,11,825,1,60,200
metric,49067,26087,25827,260,10,858,1,60,200
metric,50066,27087,26787,300,11,891,1,60,200
metric,51066,28087,27807,280,11,924,1,60,200
metric,52066,29087,28767,320,11,958,1,60,200
metric,53066,30087,29787,300,11,991,1,60,200
metric,54067,31087,30807,280,11,1024,1,60,200
metric,55067,32087,31767,320,11,1058,1,60,200
metric,56067,33087,32787,300,11,1091,1,60,200
metric,57067,34067,33787,280,11,1123,1,60,200
metric,58067,35067,34747,320,11,1157,1,60,200
metric,59067,36067,35767,300,11,1190,1,60,200
metric,60067,37067,36787,280,11,1223,1,60,200
metric,61067,38067,37747,320,11,1257,1,60,200
metric,62068,39067,38767,300,11,1290,1,60,200
metric,63067,40067,39787,280,11,1323,1,60,200
metric,64067,41067,40747,320,11,1357,1,60,200
metric,65067,42067,41787,280,11,1390,1,60,200
metric,66067,43067,42807,260,10,1424,1,60,200
metric,67067,44067,43767,300,11,1457,1,60,200
metric,68067,45067,44787,280,11,1490,1,60,200
metric,69068,46067,45807,260,10,1524,1,60,200
metric,70067,47067,46767,300,11,1557,1,60,200
metric,71067,48067,47787,280,11,1590,1,60,200
metric,72067,49067,48807,260,10,1624,1,60,200
metric,73067,50067,49767,300,11,1657,1,60,200
metric,74067,51067,50787,280,11,1690,1,60,200
metric,75067,52067,51747,320,11,1724,1,60,200
metric,76068,53067,52767,300,11,1757,1,60,200
metric,77067,54027,53747,280,11,1788,1,60,200
metric,78067,55027,54707,320,11,1822,1,60,200
metric,79067,56027,55727,300,11,1855,1,60,200
metric,80067,57027,56747,280,11,1888,1,60,200
metric,81066,58027,57707,320,11,1922,1,60,200
metric,82068,59027,58727,300,11,1955,1,60,200
metric,83068,60027,59747,280,11,1988,1,60,200
metric,84067,61027,60727,300,11,2022,1,60,200
metric,85067,62027,61747,280,11,2055,1,60,200
metric,86068,63027,62767,260,10,2089,1,60,200
Discussion
It's a Trade-off with Information Loss
The dropped_chunks=2089 in the delay guard enabled case calculates to approximately 41.78 seconds of discarded audio frames. In this experiment, since we intentionally created a state where processing is slower than arrival with SLEEP_MS=60, it's natural that the thinning is substantial.
What's important is that the system's characteristics change when delay guard is introduced. Without delay guard, the backlog will theoretically continue to grow as long as processing can't keep up. With delay guard, the system keeps the backlog near the latency budget at the cost of manifesting the inability to process everything as data loss. In other words, delay guard transforms an overloaded system from "infinitely delayed" to "finite delay with data loss."
This design is suitable for use cases that prioritize immediacy over completeness, such as keyword detection or live caption tracking. However, it is not suitable for use cases where data loss is unacceptable, such as audit storage or downstream transcription requiring absolute precision. When data loss is unacceptable, priority should be given to increasing processing capacity, lightening processing, asynchronous processing, or separation of storage and real-time systems rather than using delay guard.
Refining Discard Logic
The implementation in this article is a simple drop-head approach that discards the oldest items first when backlog exceeds the latency budget. While this implementation is straightforward and reliably suppresses latency, there are ways to discard more intelligently that might preserve more information value while still meeting the latency budget.
For example, preferentially discarding silence or low-energy segments could be one strategy. In human conversation or caption generation, missing silent periods often has relatively little impact on understanding meaning. This would tend to preserve speech-dense sections better than simple drop-head.
Another approach would be to shift from continuous discarding to temporal sampling. For instance, during overload, only passing one chunk at regular intervals to provide coarse temporal resolution tracking. While completeness is reduced, this might be advantageous compared to continuous discarding for use cases focused on tracking topic changes or content outlines. With the conditions in this test, where processing can only keep up with 1/3 of the incoming data, a natural design would be to process only 1 out of every 3 chunks during overload. While drop-head results in a similar loss rate, its discarding tends to be more continuous, which may make sampling-based approaches more stable in quality for certain applications.
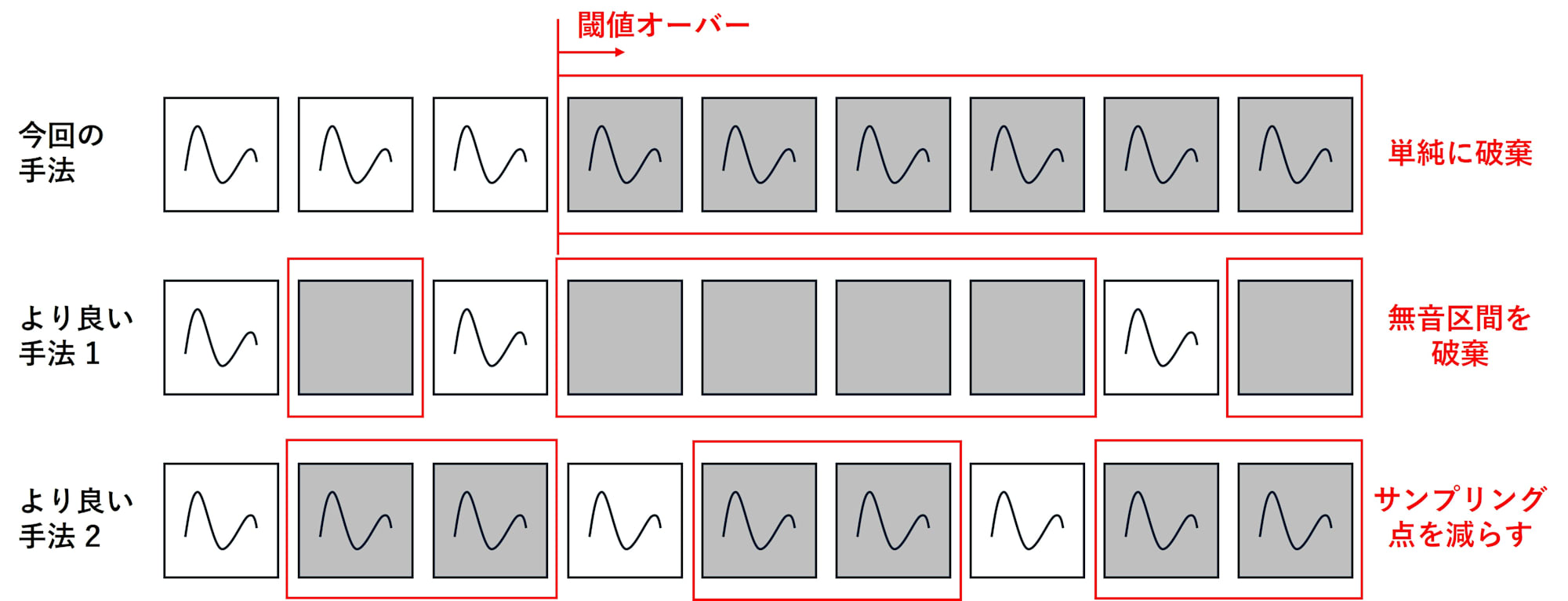
Thus, delay guard is not just about discarding old items but is also a quality design problem of how to structure data loss during overload. By selecting a specific use case and evaluating how downstream quality metrics (e.g., keyword detection rate, caption tracking delay, transcription error rate) change when altering the discard pattern, the application decision for delay guard can be better quantified.
Conclusion
In Twilio Media Streams, when downstream processing of received audio cannot keep up with the arrival rate, the backlog can continue to grow, potentially resulting in audio processing delays of tens of seconds. Implementing a delay guard can keep latency near the latency budget (e.g., 200 ms), but unprocessed data is lost through load shedding, creating a trade-off with completeness. In production, selecting discard logic tailored to use cases, such as silence-prioritized discarding or sampling-based thinning, and evaluating with downstream quality metrics, helps make more informed application decisions.