![[Session Report] Revealing the Secret of 40% Cost Reduction! Best Practices for Large-scale Model Training Proven in Amazon Nova Development (AWS-56) #AWSSummit](https://images.ctfassets.net/ct0aopd36mqt/IpyxwdJt9befE2LRbgxQg/028ee4834e885c77086d6c53a87f1c10/eyecatch_awssummitjapan2025_sessionj_1200x630.jpg?w=3840&fm=webp)
[Session Report] Revealing the Secret of 40% Cost Reduction! Best Practices for Large-scale Model Training Proven in Amazon Nova Development (AWS-56) #AWSSummit
This page has been translated by machine translation. View original
June 26, 2025 (Thu) 15:50 - 16:30
Speaker: Keita Watanabe
Sr. World Wide Specialist Solutions Architect, Frameworks WWSO
Amazon Web Services Japan G.K.
Overview
The combination of Amazon SageMaker HyperPod and EC2 UltraClusters has achieved high fault tolerance and efficiency in large-scale foundation model training. By leveraging these best practices, which were proven during the development of Amazon Nova, it is possible to reduce costs and shorten training time. Particularly, the optimal combination of 3D parallelism (data parallel, tensor parallel, pipeline parallel) in distributed training and technologies such as asynchronous checkpoint generation played crucial roles.

Evolution and Challenges of Distributed Learning
Machine learning has evolved from being completed on a single GPU to requiring distributed learning due to the emergence of large-scale foundation models.

There are three main parallelization methods in distributed learning:
- Data Parallelism
Processing different data across multiple model replicas - Tensor Parallelism
Distributing processing at the MLP and Attention block level - Pipeline Parallelism
Distributing each layer of the model
However, distributed learning has tightly coupled states, with the vulnerability that a single node failure can stop the entire learning process.
Innovative Features of Amazon SageMaker HyperPod
AWS provides insights gained from developing its own generative AI Amazon Nova to overcome the drawbacks of distributed learning in the form of Amazon SageMaker HyperPod. HyperPod is a foundation model development environment that reflects best practices in large-scale distributed learning.
- Resiliency Feature
Automatic recovery during node failures - HyperPod Observability
Visualization of system issues - Asynchronous Checkpoint Generation
Creating checkpoints without interrupting training
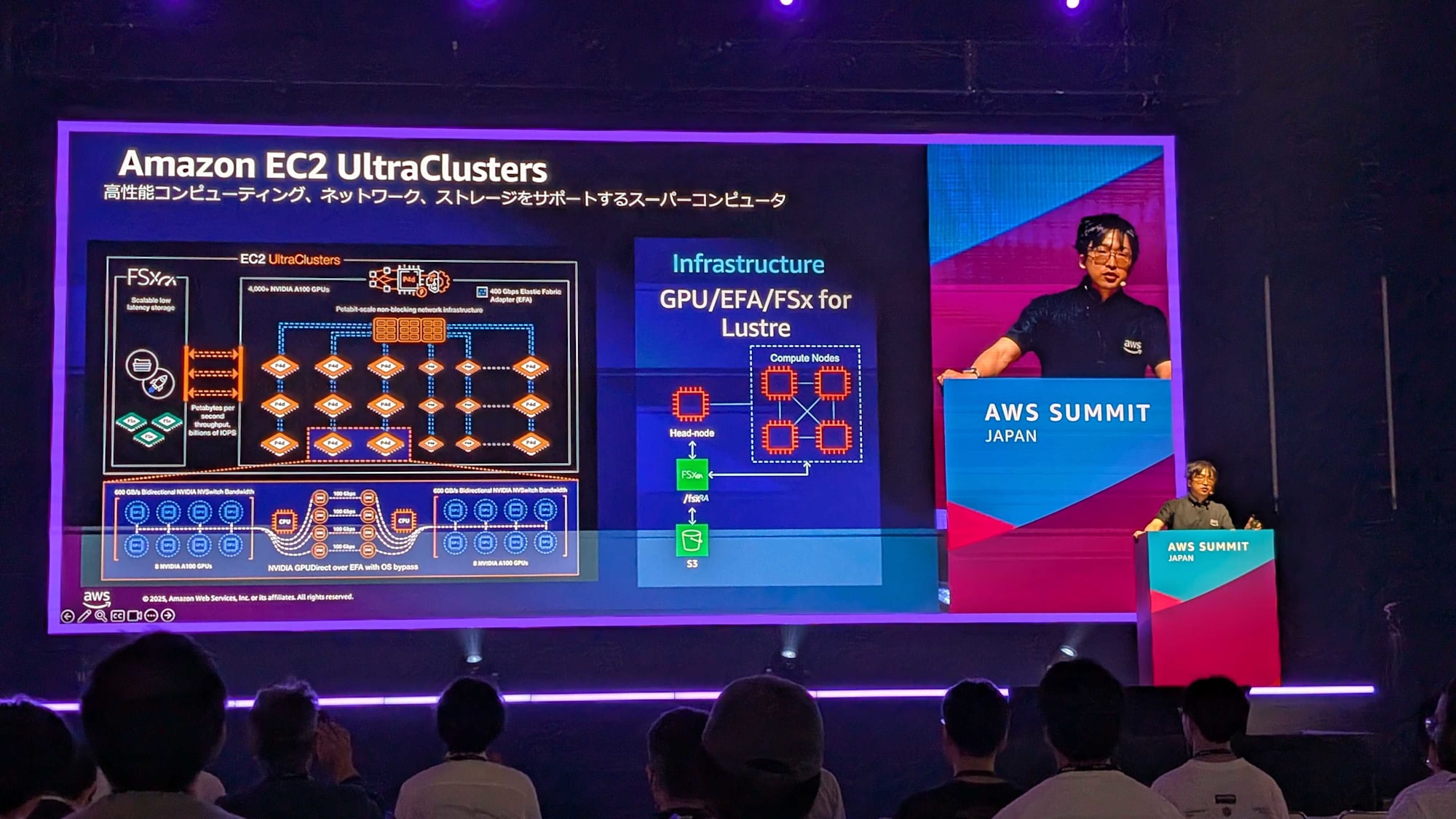
Leveraging Amazon EC2 UltraClusters
UltraClusters function as a supercomputer foundation integrating high-performance computing, networking, and storage.
- High-speed accelerators and large-capacity device memory
- High-bandwidth interconnect
- Scalable distributed file storage
AWS Deep Learning Software Stack
Providing machine images with all necessary libraries for model development in the form of Deep Learning AMI (DLAMI).
- ML Frameworks
PyTorch, JAX, DDP, FSDP, MegatronLM, DeepSpeed, torch-neuronx - Communication Libraries & SDKs
NCCL (important for GPU communication), AWS OFI NCCL, SMP, SMDDP - Hardware & Kernels
Accelerator drivers, EFA kernel drivers
Proven Case Studies
- Llama 3.3 Swallow
Adopted best practices for distributed learning using HyperPod
Impression
I was impressed by the innovation in large-scale model training brought about by AWS's advanced distributed computing architecture. In particular, the improved fault tolerance and efficiency achieved by combining Amazon SageMaker HyperPod and EC2 UltraClusters is expected to provide a significant competitive advantage in future AI development.