
I tried out OpenAI's gpt-oss-120b and gpt-oss-20b which became available on Amazon Bedrock
This page has been translated by machine translation. View original
On August 5, 2025, OpenAI released open-weight language models "gpt-oss-120b" and "gpt-oss-20b". On the same day, it was announced that these models became available on AWS's Amazon Bedrock and Amazon SageMaker.
In this article, I'll introduce the results of enabling access to these models on Amazon Bedrock in the North America Oregon region (us-west-2) and verifying their operation in the chat playground.
Model Access Settings
First, I selected "OpenAI" as the provider in the Bedrock dashboard for the Oregon region (us-west-2) and requested access to use "gpt-oss-120b" and "gpt-oss-20b".
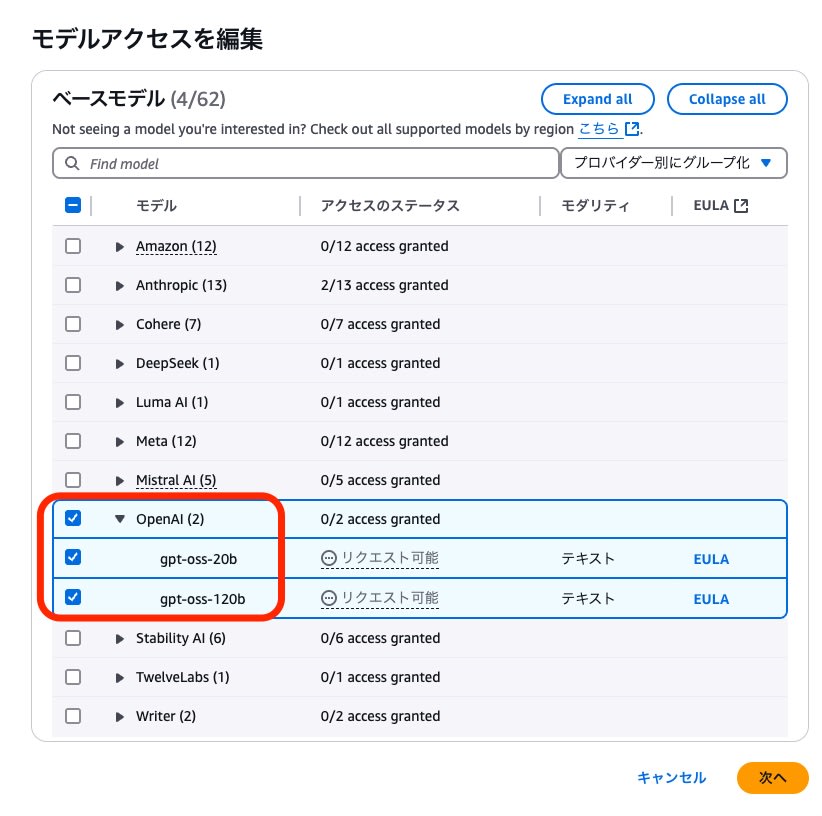
I requested these models on the edit model access screen.
Using AWS CLI to search for models containing gpt-oss in the us-west-2 region, I obtained the following information:
$ aws bedrock list-foundation-models --region us-west-2 --query "modelSummaries[?contains(modelName, 'gpt-oss')]"
[
{
"modelArn": "arn:aws:bedrock:us-west-2::foundation-model/openai.gpt-oss-120b-1:0",
"modelId": "openai.gpt-oss-120b-1:0",
"modelName": "gpt-oss-120b",
"providerName": "OpenAI",
"inputModalities": [
"TEXT"
],
"outputModalities": [
"TEXT"
],
"responseStreamingSupported": false,
"customizationsSupported": [],
"inferenceTypesSupported": [
"ON_DEMAND"
],
"modelLifecycle": {
"status": "ACTIVE"
}
},
{
"modelArn": "arn:aws:bedrock:us-west-2::foundation-model/openai.gpt-oss-20b-1:0",
"modelId": "openai.gpt-oss-20b-1:0",
"modelName": "gpt-oss-20b",
"providerName": "OpenAI",
"inputModalities": [
"TEXT"
],
"outputModalities": [
"TEXT"
],
"responseStreamingSupported": false,
"customizationsSupported": [],
"inferenceTypesSupported": [
"ON_DEMAND"
],
"modelLifecycle": {
"status": "ACTIVE"
}
}
]
From the CLI execution results, I found that at this point, the input and output are TEXT only, and "responseStreamingSupported": false indicates that streaming responses are not supported.
Operation Verification
I verified the operation of both models in the Bedrock chat playground.
I set the maximum output tokens to 8192 and ran in comparison mode with other settings at their default values.
I used the following prompt and compared the response content and processing time:
Create a simple explanation of the AWS shared responsibility model in Japanese that executives can intuitively understand.
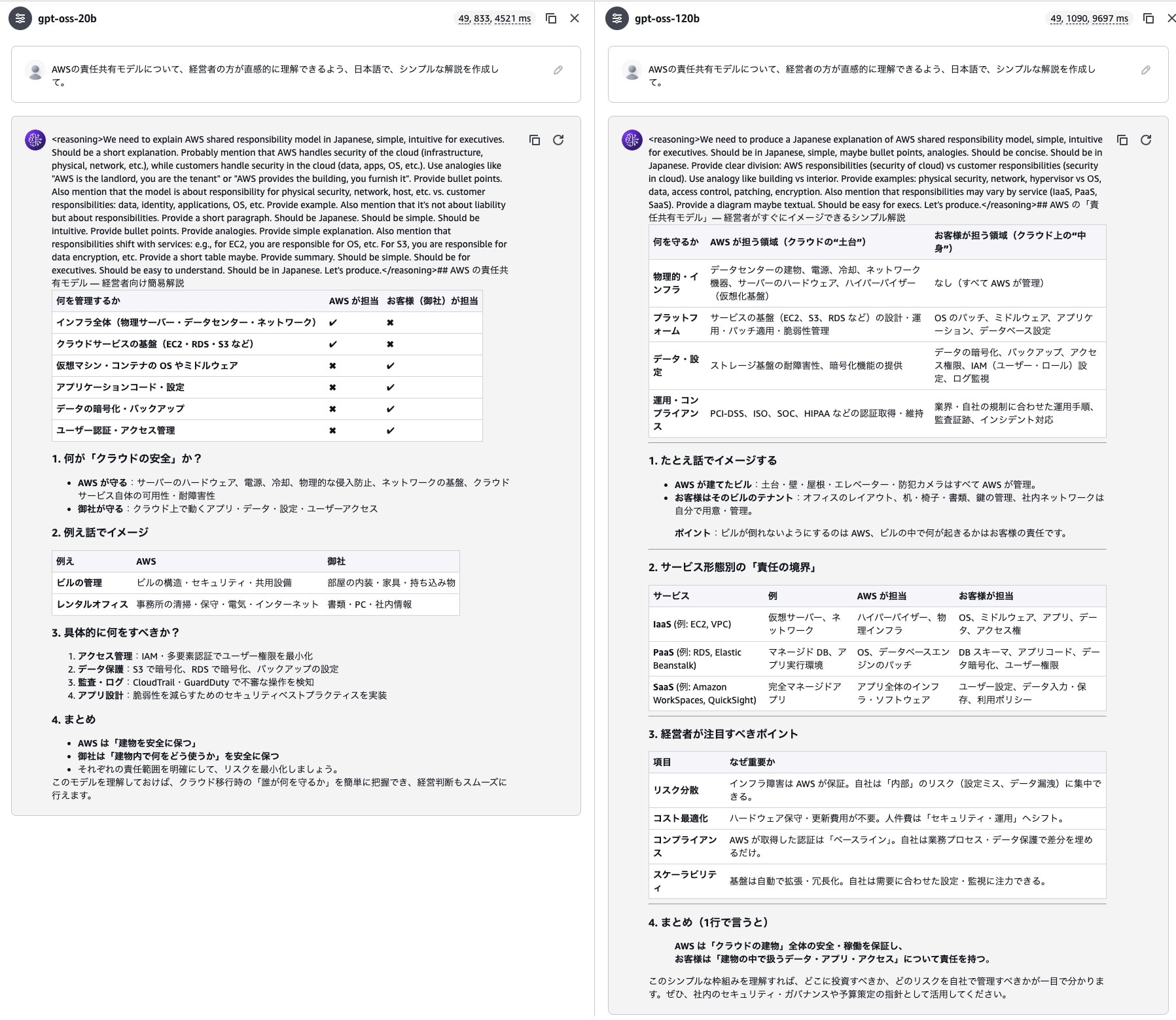
As a result, although there was some distortion in the first heading (H2 element), I was able to get an appropriate response in Japanese Markdown format.
Price Comparison
I compared the billing unit price per output token between the main models available on Bedrock and the gpt-oss series.
- Unit price when using Bedrock in Oregon region on-demand
| Provider | Models | Price per 1,000 output tokens | Comparison to Sonnet4 |
|---|---|---|---|
| Amazon | Amazon Nova Micro | 0.00014 | 1% |
| Amazon | Amazon Nova Lite | 0.00024 | 2% |
| OpenAI | gpt-oss-20b | 0.00030 | 2% |
| OpenAI | gpt-oss-120b | 0.00060 | 4% |
| Anthropic | Claude 3 Haiku | 0.00125 | 8% |
| Amazon | Amazon Nova Pro | 0.00320 | 21% |
| Anthropic | Claude 3.5 Haiku | 0.00400 | 27% |
| Amazon | Amazon Nova Premier | 0.01250 | 83% |
| Anthropic | Claude Sonnet 4 | 0.01500 | 100% |
| Anthropic | Claude Opus 4.1 | 0.07500 | 500% |
From this comparison, I found that gpt-oss-20b is priced almost the same as "Amazon Nova Lite," and the higher-end model gpt-oss-120b can be used at about half the price of "Claude 3 Haiku." These appear to be very strong options for cost-conscious use cases.
Throughput Performance Comparison
I also executed the AWS responsibility model prompt on other major models to measure the number of tokens and processing time. I compared the number of tokens that can be output per second (throughput).
| Models | Output tokens | Latency (ms) | Output tokens/sec |
|---|---|---|---|
| gpt-oss-20b | 833 | 4521 | 184.3 |
| gpt-oss-120b | 1090 | 9697 | 112.4 |
| Amazon Nova Micro | 494 | 2646 | 186.7 |
| Amazon Nova Lite | 756 | 4744 | 159.4 |
| Amazon Nova Pro | 550 | 5640 | 97.5 |
| Amazon Nova Premier | 220 | 4407 | 49.9 |
| Claude 3 Haiku | 344 | 4972 | 69.2 |
| Claude 3.5 Haiku | 319 | 6410 | 49.8 |
| Claude Sonnet 4 | 580 | 13968 | 41.5 |
| Claude Opus 4.1 | 627 | 32731 | 19.2 |
I confirmed that gpt-oss-20b has throughput performance comparable to the fastest "Amazon Nova Micro," and gpt-oss-120b exceeds "Amazon Nova Pro." High performance can be expected not only in terms of price but also in response speed.
Comparison with Local LLM
For reference, I compared the throughput when running "gpt-oss-20b" on Amazon Bedrock versus a local environment (LM Studio on an M4 Pro Mac).
| Models | Output tokens | Latency (sec) | Output tokens/sec |
|---|---|---|---|
| Bedrock | 833 | 4521 | 184.3 |
| Local (M4 Mac) | 813 | 36172 | 22.4 |
While there may be insufficient optimization settings in the local environment, I found that Amazon Bedrock provides excellent performance as an execution environment for gpt-oss-20b.
Summary
The newly released open-weight models "gpt-oss-20b" and "gpt-oss-120b" have been confirmed to be excellent choices in terms of both cost and performance.
These models could be effective candidates, particularly for tasks requiring low-cost and high-speed processing.
Currently, OpenAI models provided on Bedrock have limitations in regions and available functions, but I look forward to future service expansions.