
BigQuery Sharing Features and Key Points to Remember
This page has been translated by machine translation. View original
Introduction
Hello, this is Kodaka from the Data Business Division.
Recently, I had the opportunity to consider the design for BigQuery data sharing across projects, so I compiled information about BigQuery Sharing (formerly known as: Analytics Hub).
The basic usage of BigQuery Sharing is introduced in a hands-on format in the article below. In this blog, I will organize the characteristics and constraints/points to note about BigQuery Sharing that emerged during actual testing, providing information that can serve as a reference for adoption decisions.
Overview of BigQuery Sharing
BigQuery Sharing is a service that allows you to share BigQuery datasets within and outside your organization.
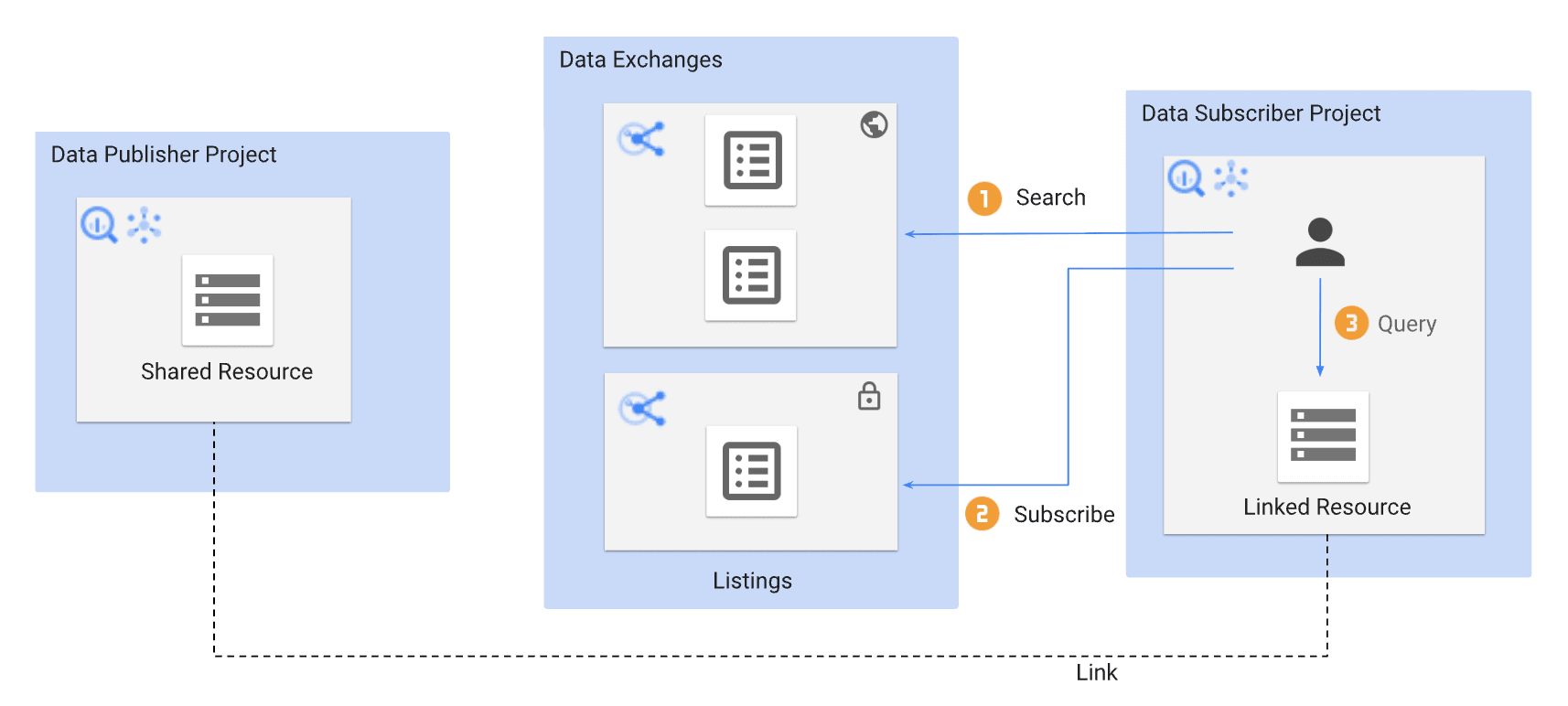
Source: Introduction to BigQuery sharing | Google Cloud
Let me briefly organize the key terminology.
| Term | Description |
|---|---|
| Exchange | A logical group that bundles Listings. Can be set as private/public |
| Listing | A sharing unit that corresponds one-to-one with a shared dataset |
| Linked dataset | A read-only dataset created in the Subscriber's project when they subscribe |
| Publisher | The party providing the data |
| Subscriber | The party receiving the data |
The basic flow is that the Publisher registers and publishes Listings in an Exchange, and when a Subscriber subscribes, a linked dataset is automatically created in their own project. Data is not copied but directly referenced from the Publisher's side.
Characteristics of BigQuery Sharing
1. No need to grant IAM roles to the Publisher's side
One of the major features of BigQuery Sharing is that there is no need to grant BigQuery IAM roles on the Publisher's project to users on the Subscriber side.
Normally, when referencing BigQuery data across projects, you need to grant some IAM role (such as bigquery.dataViewer) to the source project. With BigQuery Sharing, sharing is completed simply by granting the subscriber permission on the Exchange/Listing, making IAM management on the Publisher side simpler.
2. Management of subscriber permissions and subscriptions
subscriber permissions
The subscriber permission for Exchange/Listing controls the ability to subscribe.
When subscriber role is granted
State where the subscriber role is granted on the Exchange permissions screen
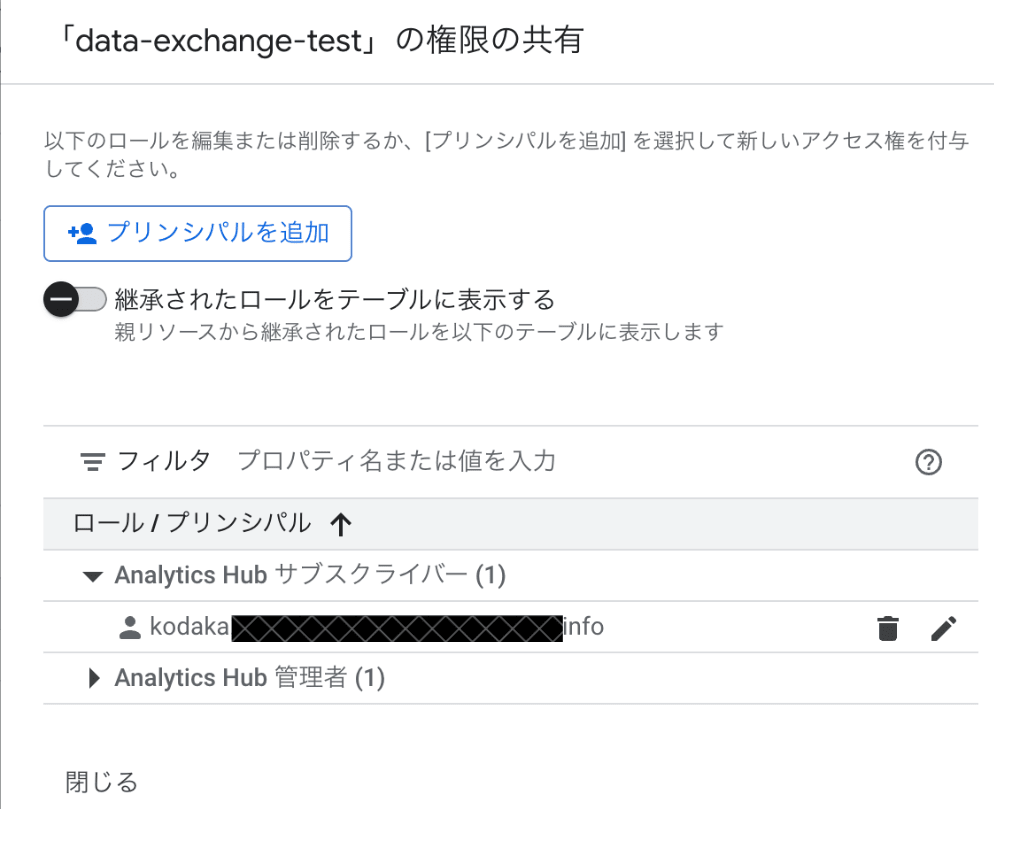
Listings are displayed in the list and subscribable
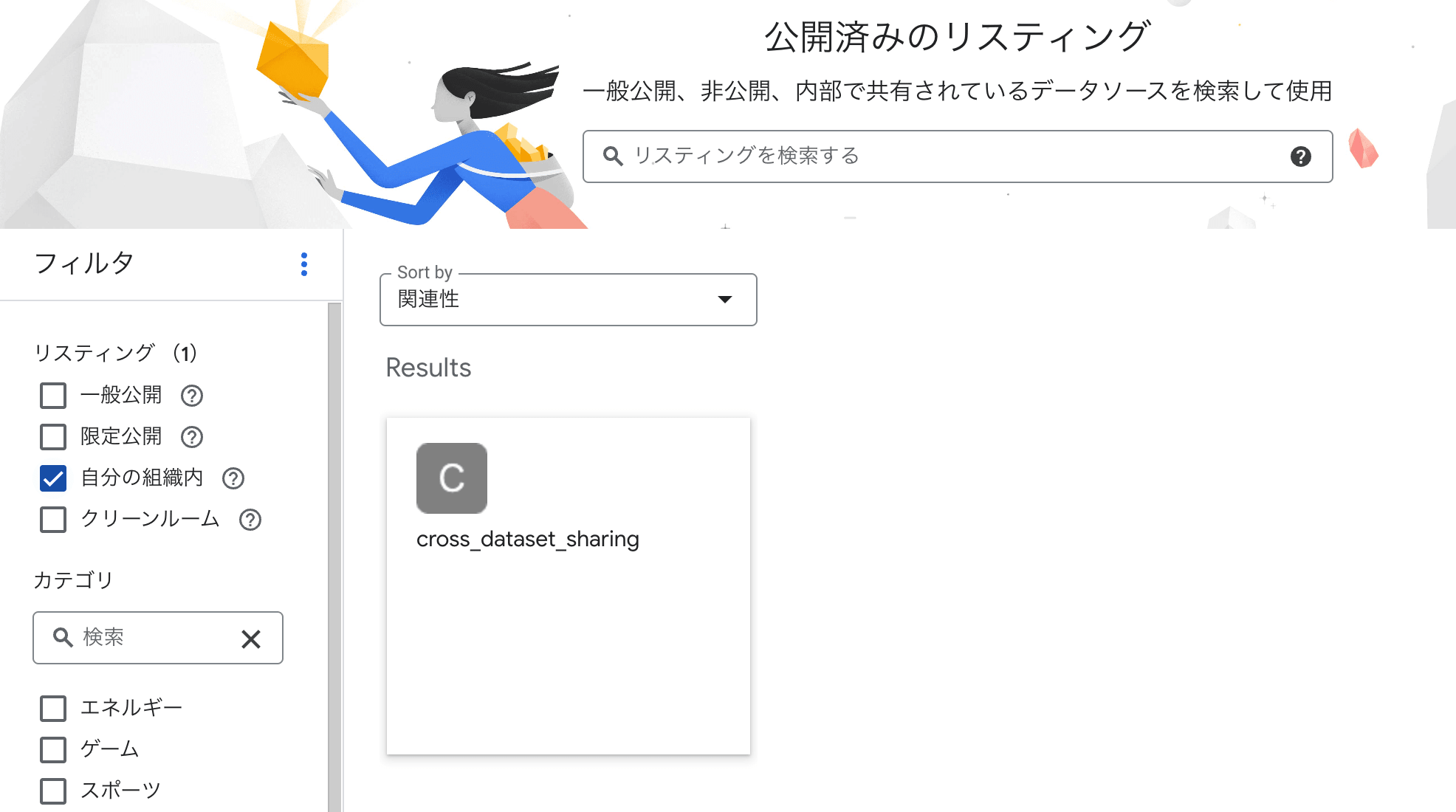
When subscriber role is removed
State where the subscriber role is removed from the Exchange
Screen where Listings are not displayed in the list and cannot be selected
Without permission, not only can't you subscribe, but the Listing itself becomes invisible, preventing unintended exposure of information.
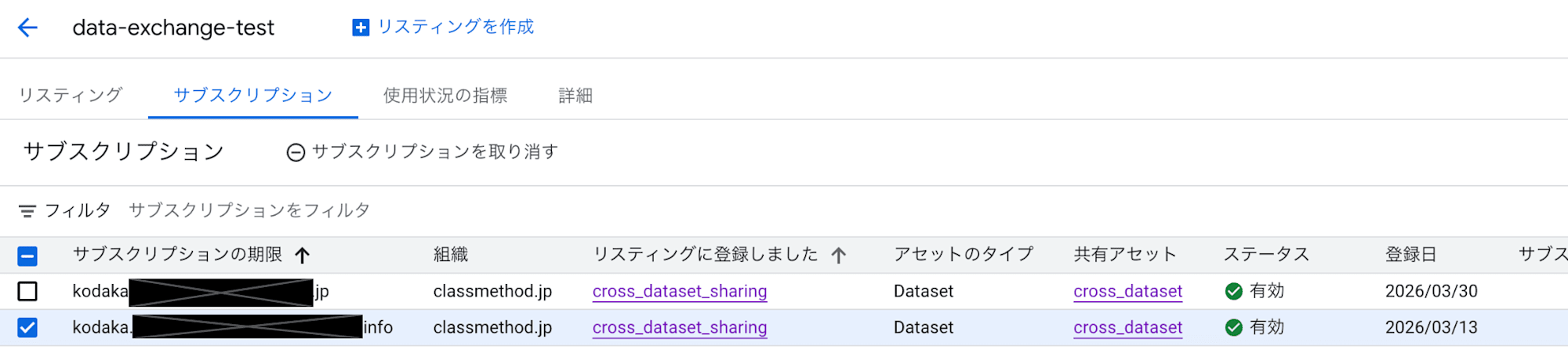
Subscription management
Revoking the subscriber permission prevents new subscriptions but does not stop access to already subscribed linked datasets. To stop existing access, you need to revoke the subscription from the "Subscriptions" tab in the Exchange.
Screen for revoking subscriptions from the Exchange's "Subscriptions" tab
Summary
| Action | Effect |
|---|---|
Revoking subscriber permission |
Stops new subscriptions and discovery of Listings. Access to existing linked datasets continues |
| Revoking subscription | Stops data access to the linked dataset. The linked dataset itself remains on the Subscriber side and must be manually deleted |
3. Permission control at Exchange/Listing level
The subscriber permission can be granted at both Exchange and Listing levels.
| Grant level | Behavior |
|---|---|
| Exchange level | Allows subscription to all Listings under that Exchange |
| Listing level | Allows subscription to specific Listings only |
This allows you to use Exchanges as grouping units and control access more finely at the Listing level.
4. Automatic reflection of added tables
When tables are added to the Publisher's dataset, they are automatically reflected in the linked dataset. The same applies to schema changes and data updates.
No follow-up work is required on the Subscriber side, so there is no increase in operational load even if the number of shared tables increases.
5. Query costs are charged to the Subscriber
The cost of queries against linked datasets is charged to the Subscriber's project. There is no cost burden on the Publisher side.
There is a clear separation where storage fees are only charged to the Publisher, and query scan fees are only charged to the Subscriber.
6. Linked datasets are read-only
INSERT/UPDATE/DELETE operations on linked datasets will result in errors. There is no risk of unintended data changes, allowing data providers to publish datasets with confidence.
Constraints and points to note
1. Listing registration granularity is dataset-level only
Listings can only be registered at the dataset level. It is not possible to register and publish only specific tables or views in a Listing.
If you want to publish only specific tables, you can address this by creating a separate dataset for publication and placing views of the target tables there.
┌─── Publisher side ────────────────────────────────┐
│ │
│ Original dataset (private) │
│ ├─ Table A │
│ ├─ Table B (to be published) │
│ └─ Table C (to be published) │
│ │ │
│ ▼ │
│ Publication dataset ← Registered in Listing │
│ ├─ View_Table B → References Table B │
│ └─ View_Table C → References Table C │
│ │
└───────────────────────────────────────────────────┘
However, this view-based approach has caveats explained in the next section.
2. Publisher-side viewing permissions needed for view references
While tables in linked datasets can be referenced with Subscriber-side permissions only, views require Publisher-side viewing permissions for the source table's dataset.
This means that with the "place views in a publication dataset" approach mentioned earlier, you would need to grant Publisher-side viewing permissions to users on the Subscriber side. This undermines the benefit of "no need for Publisher-side IAM grants" offered by BigQuery Sharing.
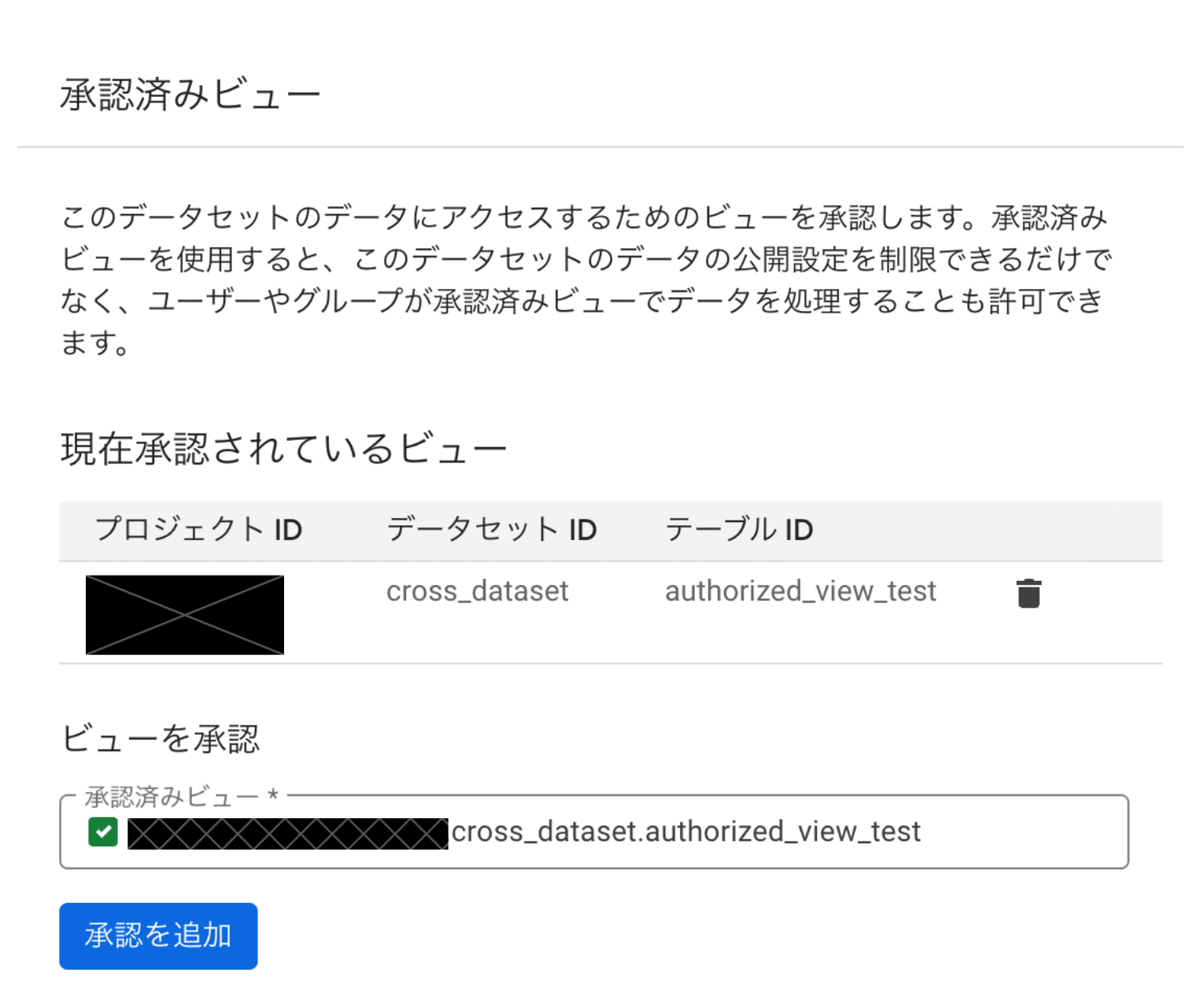
This problem can be avoided by using authorized views. With authorized views, the view itself holds data access permissions, eliminating the need to grant Publisher-side viewing permissions to Subscriber-side users.
| View type | Publisher-side viewing permission |
|---|---|
| Regular view | Viewing permission for the source table's dataset is required |
| Authorized view | Not required |
When using authorized views, you don't need to create a separate publication dataset; you can place authorized views in the original dataset and register it in a Listing.
Making a view authorized
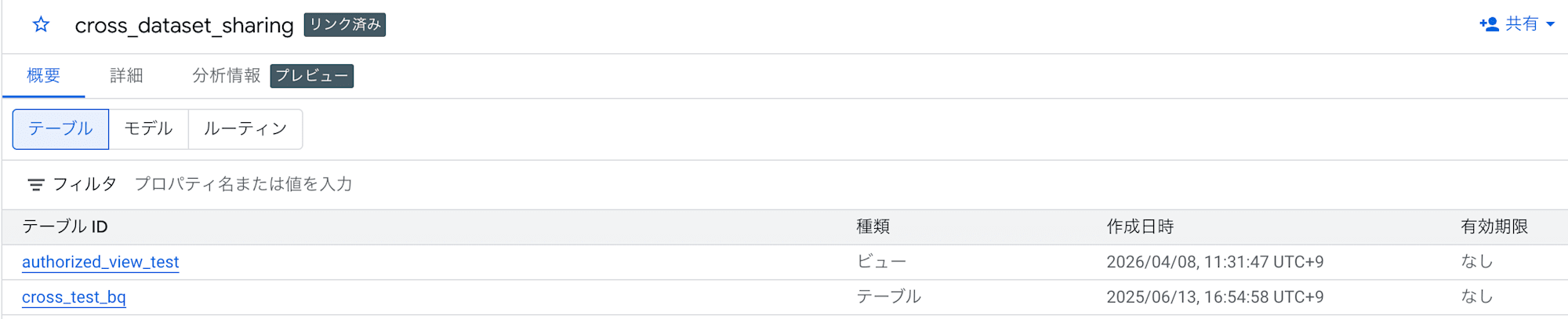
Confirming that the view exists in the linked dataset
Successful SELECT statement on the authorized view
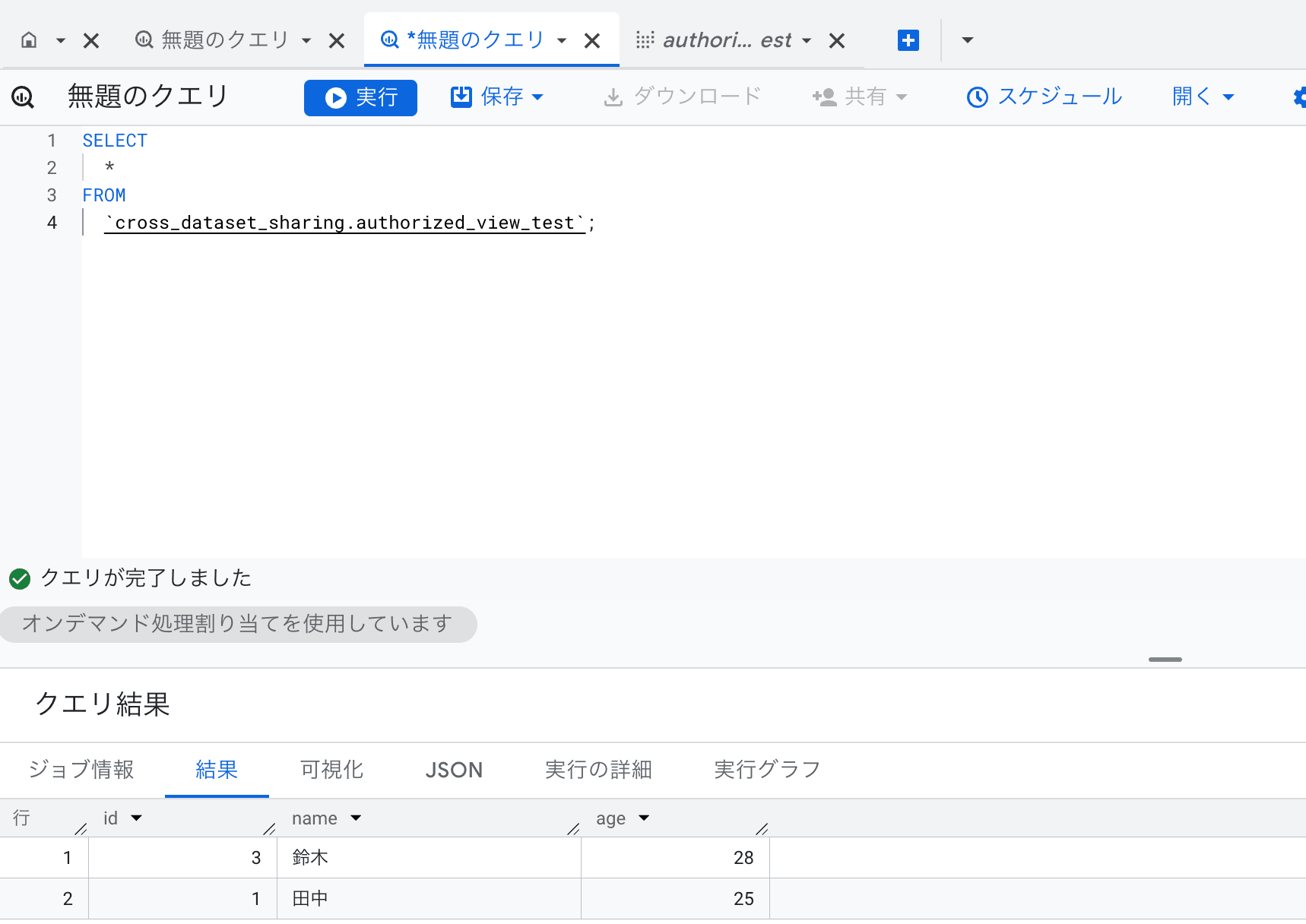
3. Other limitations
| Constraint | Details |
|---|---|
| Maximum number of subscriptions | Maximum 1,000 per Listing |
| IAM settings for individual tables | IAM role settings for individual tables in linked datasets are not possible (dataset level only) |
| Table-level tag settings | Tag settings for tables in linked datasets are not possible |
| Materialized views | Materialized views referencing tables in linked datasets are not supported |
| Table snapshots | Taking snapshots of tables in linked datasets is not possible |
| Irreversibility of logging settings | Once enabled, subscriber email logging cannot be disabled (Exchange must be recreated) |
Summary
In this article, I organized the characteristics and constraints/points to note about BigQuery Sharing. When considering adoption, I recommend organizing the granularity of sharing targets and permission design in advance.
Reference materials