![[For Beginners] Getting Started with Personal Knowledge Management Using Claude Code × Obsidian × Vertex AI](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-75c24212db08a605cf51b1578f9a040c/f14b12b1b1cf9b5ed2427490ff86734d/eyecatch_anthropic?w=3840&fm=webp)
[For Beginners] Getting Started with Personal Knowledge Management Using Claude Code × Obsidian × Vertex AI
This page has been translated by machine translation. View original
Introduction
I'm Kasama from the Data Business Division.
After reading the following article, I thought the idea was really good, so I customized the settings myself and have been using it for a week. I'd like to document that experience.
(I'm a beginner with both Obsidian and Claude Code, so please let me know if there are better, simpler methods...)
Prerequisites
I wanted to transcribe my personal English lesson mp3/mp4 videos into text to get feedback, and to transcribe regular meeting videos into minutes, so I created a system that uses Vertex AI for transcription and summarization. The diagram is as follows:
Implementation
The implementation code for this project is stored on Github, so please check it there.
@obsidian-claude-feedback-sample % tree
.
├── .claude
│ ├── format-md.sh
│ ├── prompt
│ │ ├── english_lesson.md
│ │ └── meeting.md
│ └── settings.json
├── 00_Configs
│ ├── Extra
│ └── Templates
│ └── Daily.md
├── 01_Daily
├── 02_Inbox
│ └── 雑メモ.md
├── 03_eng_study
├── 04_Meetings
├── audio_video_to_text
│ ├── audio_video_to_text.py
│ ├── input
│ ├── output
│ └── requirements.txt
├── .prettierrc
├── CLAUDE.md
├── package-lock.json
├── package.json
└── README.md
.claude/format-md.sh runs with Claude Code's hooks functionality. It formats .md files with prettier.
#!/bin/bash
FILE_PATH=$(jq -r '.tool_input.file_path')
if [[ "$FILE_PATH" == *.md ]]; then
echo "📝 Formatting markdown file: $FILE_PATH"
if [ -f node_modules/.bin/prettier ]; then
npx prettier --write "$FILE_PATH" && echo "✅ Prettier formatting completed for $FILE_PATH" || echo "❌ Prettier formatting failed for $FILE_PATH"
elif command -v prettier >/dev/null 2>&1; then
prettier --write "$FILE_PATH" && echo "✅ Prettier formatting completed for $FILE_PATH" || echo "❌ Prettier formatting failed for $FILE_PATH"
else
echo "⚠️ Warning: prettier not found, skipping formatting for $FILE_PATH"
fi
fi
In .claude/settings.json, I've configured basic allow/deny commands, hook settings to call scripts, and notification sounds.
{
"env": {
"TF_LOG": "WARN",
"CLAUDE_CODE_ENABLE_TELEMETRY": "0",
"BASH_DEFAULT_TIMEOUT_MS": "600000"
},
"permissions": {
"allow": [
"Bash(ls ./)",
"Bash(ls ./*)",
"Bash(cat ./*)",
"Bash(grep:*)",
"Bash(rg:*)",
"Bash(find ./)",
"Bash(tree ./)",
"Bash(head ./*)",
"Bash(tail ./*)",
"Bash(echo:*)",
"Bash(pwd)",
"Bash(cd ./)",
"Bash(mkdir ./)",
"Bash(cp ./* ./)",
"Bash(mv ./* ./)",
"Bash(touch ./)",
"Bash(which:*)",
"Bash(env)",
"Bash(whoami)",
"Bash(date)",
"Bash(uv run:*)",
"Read(./**)",
"Edit(./**)",
"Grep(./**)",
"Glob(./**)",
"LS(./**)",
"LS(..)",
"Write(./**)",
"MultiEdit(./**)",
"TodoRead(**)",
"TodoWrite(**)",
"Task(**)",
"Bash(uv run:*)"
],
"deny": [
"Bash(rm -rf:*)",
"Bash(rm /*)",
"Bash(cp /* *)",
"Bash(cp:*)",
"Bash(mv /* *)",
"Bash(mv:*)",
"Bash(mkdir /*)",
"Bash(sudo:*)",
"Write(.git/**)"
]
},
"enabledMcpjsonServers": [
],
"disabledMcpjsonServers": [],
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": ".claude/format-md.sh"
}
]
}
],
"Notification": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "afplay /System/Library/Sounds/Funk.aiff"
}
]
}
],
"Stop": [
{
"matcher": "",
"hooks": [
{
"type": "command",
"command": "afplay /System/Library/Sounds/Funk.aiff"
}
]
}
]
}
}
I created the Obsidian folder structure with reference to the following article.
The folder structure is quite general, so I'll likely change it as I use it more.
├── 00_Configs
│ ├── Extra → Image file storage
│ └── Templates → Template file storage
│ └── Daily.md
├── 01_Daily → Daily Note storage
├── 02_Inbox → Memo storage
│ └── 雑メモ.md
├── 03_eng_study → English study note storage
├── 04_Meetings → Meeting minutes storage
The following Python script transcribes mp4/mp3 files:
audio_video_to_text/audio_video_to_text.py
import os
import logging
import vertexai
from vertexai.generative_models import GenerativeModel, Part
from dotenv import load_dotenv
import ffmpeg
# Load .env file
load_dotenv()
# ---------- Environment variables ----------
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
FILE_NAME = os.getenv("FILE_NAME") # Example: "meeting_audio.mp4" or "meeting_audio.mp3"
OUTPUT_DIR = "output" # Output destination
MODEL_NAME = "gemini-2.5-pro"
GOOGLE_APPLICATION_CREDENTIALS = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = GOOGLE_APPLICATION_CREDENTIALS
# ---------- Logging ----------
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(message)s")
logger = logging.getLogger(__name__)
# Initialize Vertex AI
vertexai.init(project=PROJECT_ID, location=REGION)
def convert_mp4_to_mp3(mp4_path: str, mp3_path: str) -> None:
"""Convert MP4 file to MP3"""
logger.info("Starting MP4 to MP3 conversion: %s -> %s", mp4_path, mp3_path)
try:
(
ffmpeg.input(mp4_path)
.output(mp3_path)
.global_args("-loglevel", "quiet")
.run(overwrite_output=True)
)
logger.info("MP4 to MP3 conversion completed")
except Exception as e:
logger.error("Error occurred during MP4 conversion: %s", e)
raise
def transcribe_audio(audio_path: str) -> str:
"""Transcribe audio file to text"""
logger.info("Starting transcription: %s", audio_path)
model = GenerativeModel(MODEL_NAME)
# Determine MIME type based on file extension
if audio_path.lower().endswith('.mp4'):
mime_type = "video/mp4"
elif audio_path.lower().endswith('.mp3'):
mime_type = "audio/mp3"
else:
raise ValueError(f"Unsupported file format: {audio_path}")
with open(audio_path, "rb") as f:
audio_part = Part.from_data(f.read(), mime_type=mime_type)
prompt = (
"Please transcribe the following audio.\n"
"1. Start a new line when the speaker changes.\n"
"2. Add punctuation where possible.\n"
)
response = model.generate_content([audio_part, prompt])
logger.info("Transcription completed")
return response.text
if __name__ == "__main__":
try:
# Separate file name and extension
input_file_path = os.path.join("input", FILE_NAME)
file_name_without_ext, file_extension = os.path.splitext(FILE_NAME)
# Check if input file exists
if not os.path.exists(input_file_path):
raise FileNotFoundError(f"Input file not found: {input_file_path}")
audio_file = None
temp_mp3_file = None
if file_extension.lower() == ".mp4":
# For MP4 files, convert to MP3
temp_mp3_file = os.path.join("input", f"{file_name_without_ext}_converted.mp3")
convert_mp4_to_mp3(input_file_path, temp_mp3_file)
audio_file = temp_mp3_file
elif file_extension.lower() == ".mp3":
# For MP3 files, use directly
audio_file = input_file_path
else:
raise ValueError(f"Unsupported file format: {file_extension}")
# Execute transcription
transcript = transcribe_audio(audio_file)
# Save output (using filename without extension)
os.makedirs(OUTPUT_DIR, exist_ok=True)
out_path = os.path.join(OUTPUT_DIR, f"{file_name_without_ext}_transcript.txt")
with open(out_path, "w", encoding="utf-8") as f:
f.write(transcript)
logger.info("Saved transcription text: %s", out_path)
# Delete temporary file
if temp_mp3_file and os.path.exists(temp_mp3_file):
os.remove(temp_mp3_file)
logger.info("Deleted temporary file: %s", temp_mp3_file)
except Exception as e:
logger.exception("Error occurred during processing: %s", e)
raise
In .prettierrc, I've configured automatic formatting settings for markdown files.
{
"tabWidth": 4,
"useTabs": false,
"proseWrap": "preserve",
"printWidth": 120,
"endOfLine": "lf"
}
Setup
Obsidian
Now let's set up everything.
First, download the repository locally with git clone.
Next, if you haven't set up Obsidian yet, please install it. There are many installation guides for Obsidian online, so I'll skip that here.
Once installed, launch Obsidian and select "Open folder as vault" to open the folder you just cloned.
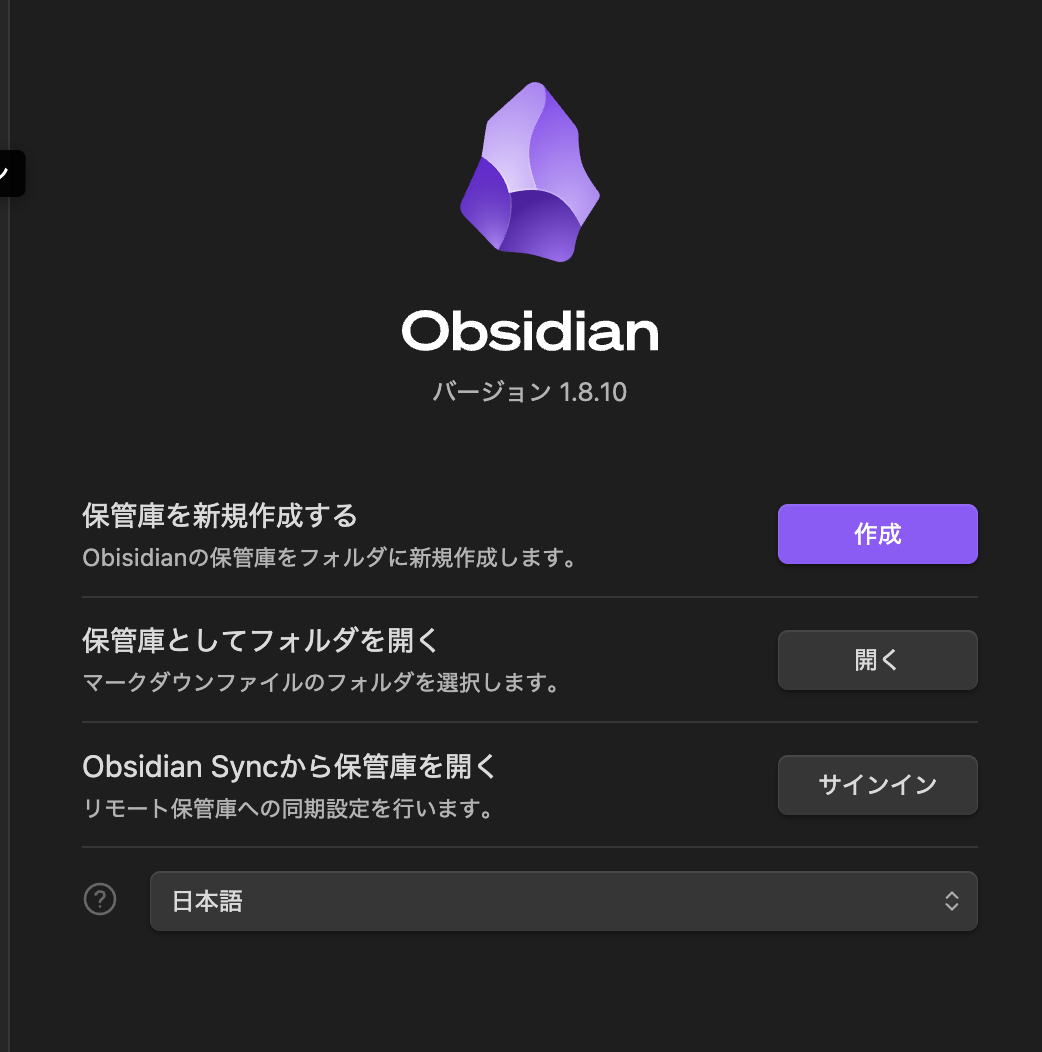
After opening, specify the template and note creation locations in the settings screen (highlighted in red).
Files & Links
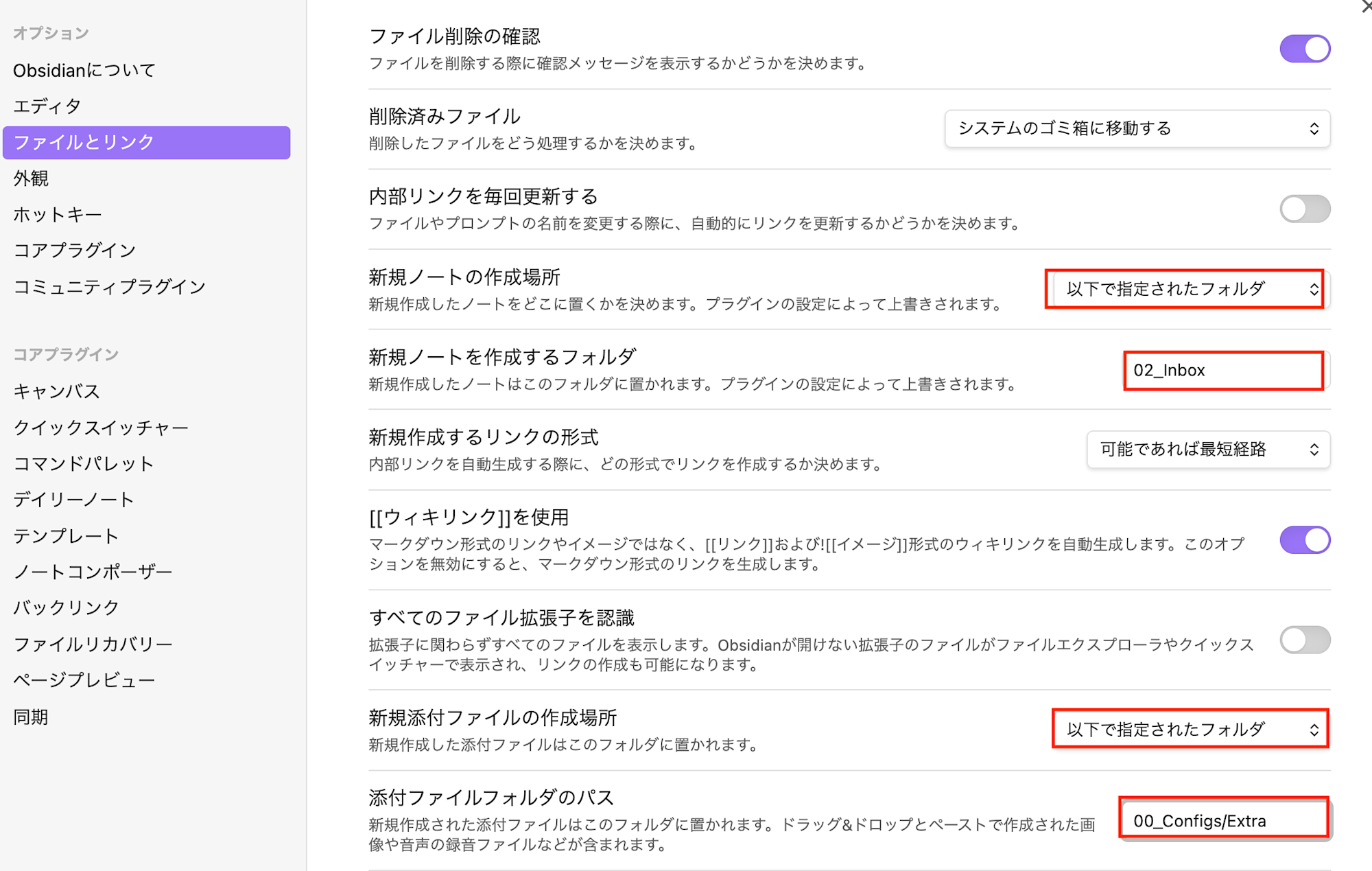
Daily Notes
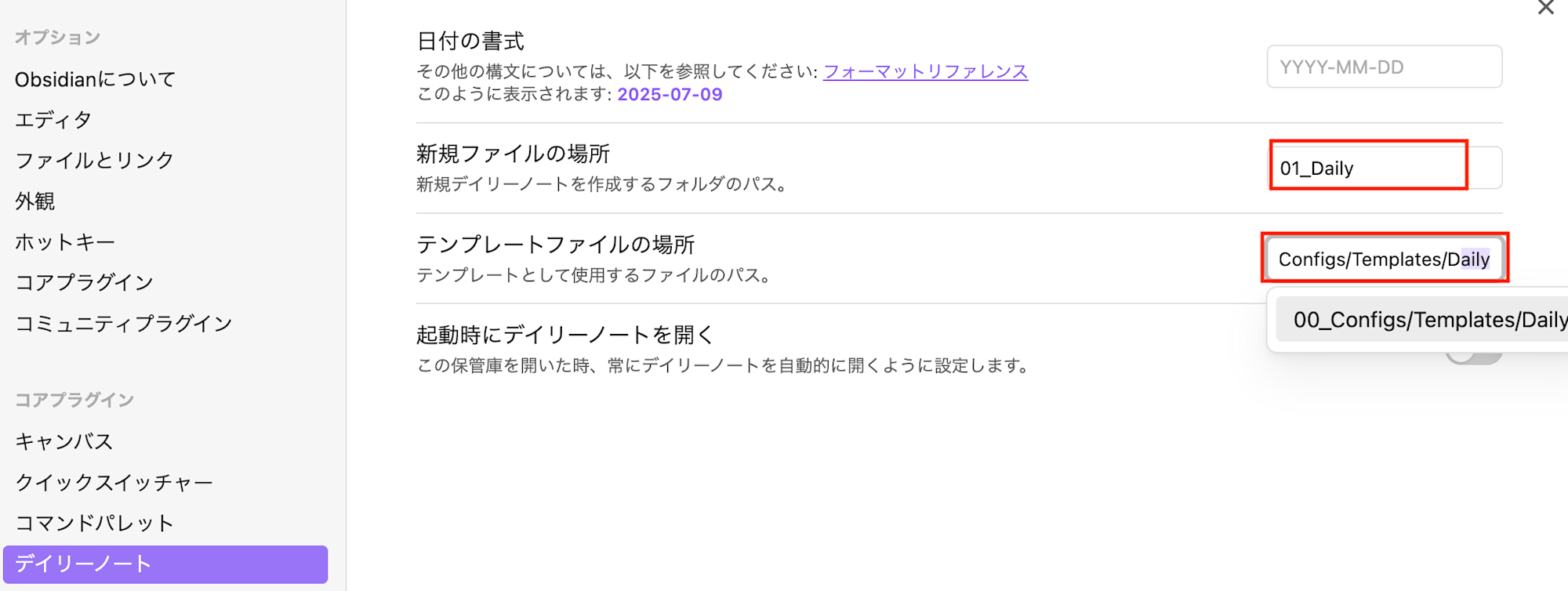
Templates
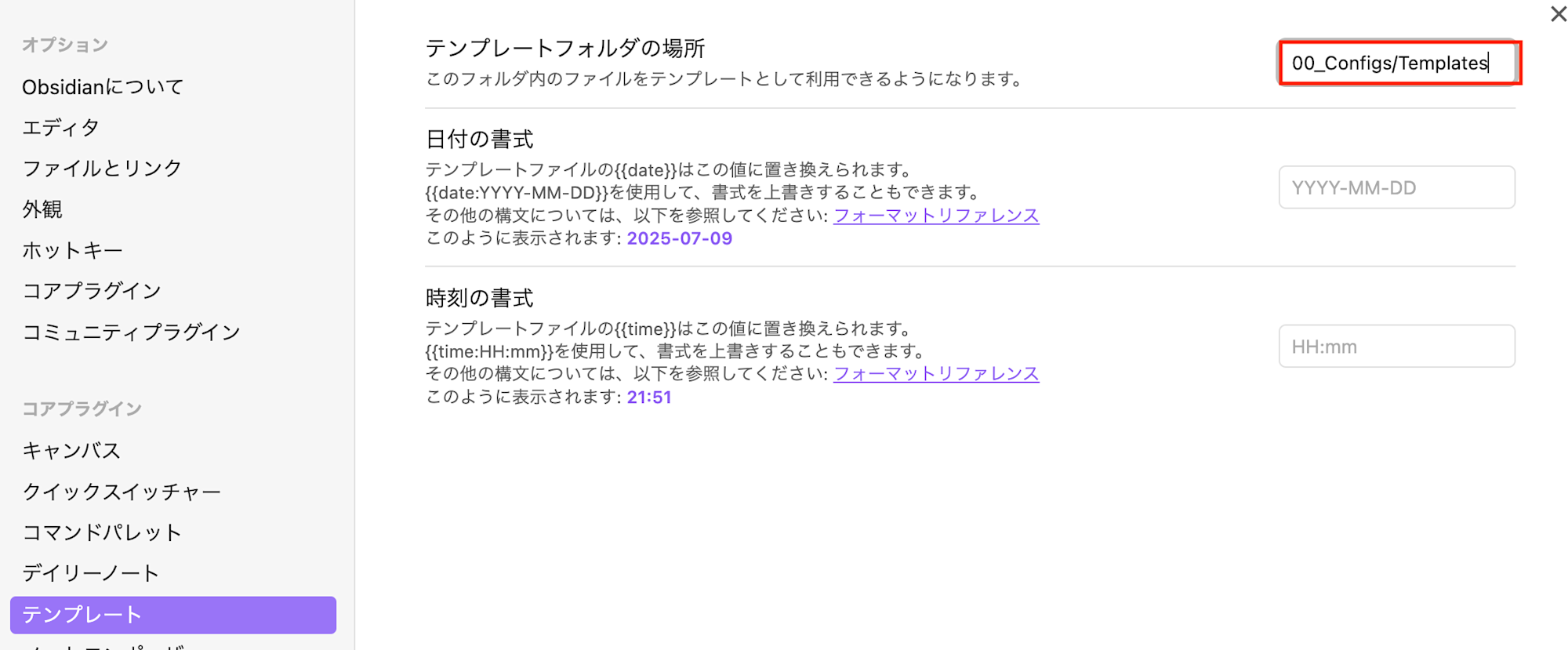
Currently, I'm proceeding with these minimal settings. I do want to explore and add more features later.
Vertex AI
Next, let's set up Vertex AI to run our scripts.
For enabling Vertex AI, please refer to the "Google Cloud Setup" section of the following blog:
Python Environment
Next, let's install uv for Python version management, virtual environment, and package management.
# macOS/Linux
curl -LsSf https://astral.sh/uv/install.sh | sh
# Windows
powershell -c "irm https://astral.sh/uv/install.ps1 | iex"
After installation, navigate to the project directory, create a uv virtual environment, and install dependencies.
# Navigate to project directory
cd audio_video_to_text
# Create virtual environment (automatically installs Python 3.13)
uv venv --python 3.13
# Activate virtual environment
# macOS/Linux
source .venv/bin/activate
# Windows
.venv\Scripts\activate
# Install dependencies
uv pip install -r requirements.txt
Create a .env file in the audio_video_to_text/ directory. Specify the input file name with extension in FILE_NAME. Also include your Google Cloud configuration values.
PROJECT_ID=your-gcp-project-id
REGION=your-region
GOOGLE_APPLICATION_CREDENTIALS=path/to/your/service-account-key.json
FILE_NAME=eng_record.mp3
Claude Code
For Claude Code setup, please refer to the official documentation:
Once setup is complete, since we'll be using Prettier with hooks, install it from package.json using npm install.
@obsidian-claude-feedback-sample % npm install
added 1 package, and audited 2 packages in 706ms
1 package is looking for funding
run `npm fund` for details
found 0 vulnerabilities
You can confirm the installation with npm list.
@obsidian-claude-feedback-sample % npm list
obsidian-claude-feedback-sample@1.0.0 /git/obsidian-claude-feedback-sample
└── prettier@3.6.2
For hooks, you can verify that the settings have been applied using the Claude command /hooks.
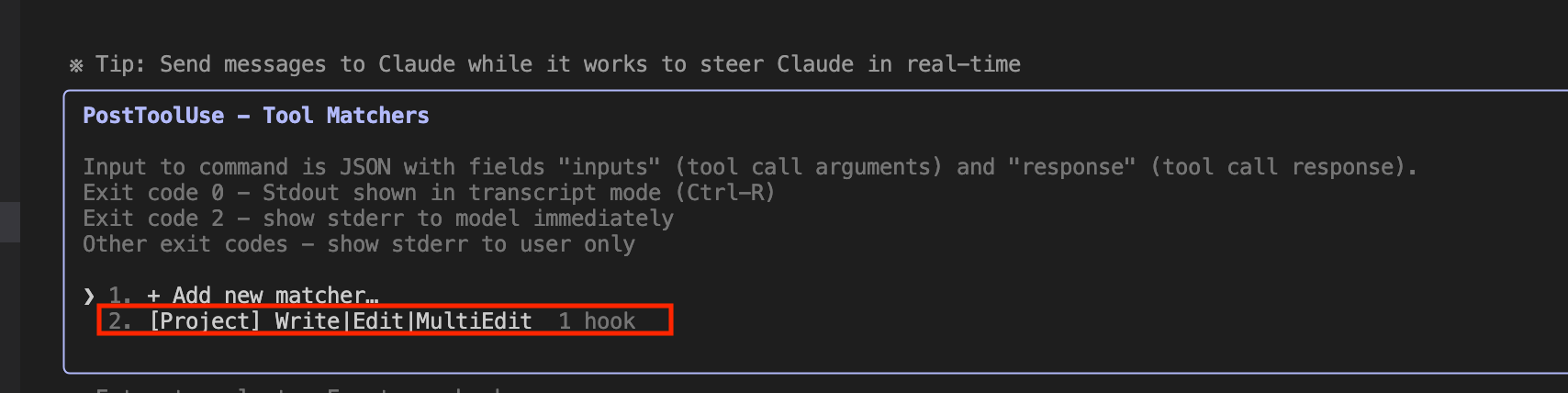
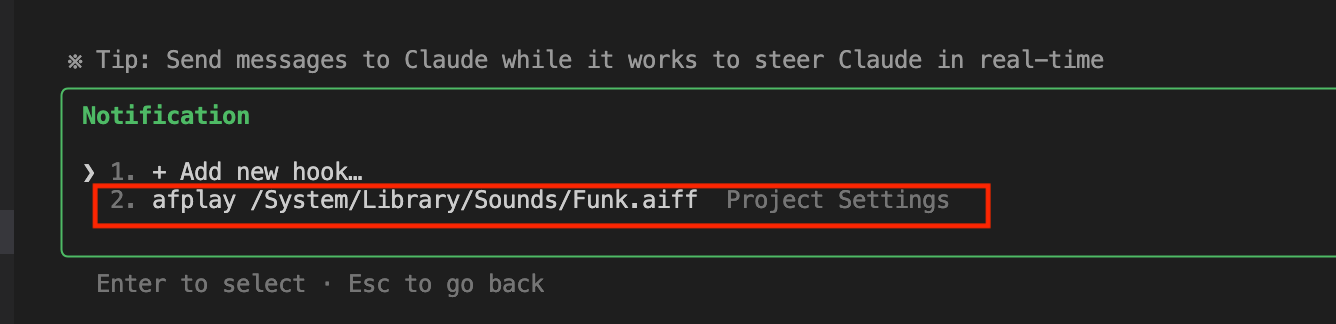
Trying It Out
Now let's actually try using it.
Place the MP3 or MP4 file you want to convert in the audio_video_to_text/input/ folder and set the FILE_NAME in the .env file to the file name (with extension).
Make sure the virtual environment we created earlier is activated and run the script.
cd audio_video_to_text
python audio_video_to_text.py
The file was about 30 minutes long but finished in just over a minute.
@audio_video_to_text % python audio_video_to_text.py
2025-07-09 22:41:02,151 - 文字起こし開始: input/eng_record.mp3
2025-07-09 22:42:15,686 - 文字起こし完了
2025-07-09 22:42:15,688 - 書き起こしテキストを保存しました: output/eng_record_transcript.txt
Now let's use Claude to create feedback based on the generated txt file.
To confirm that Prettier runs, I'll execute in debug mode with claude --debug.
Paste the path to the transcribed file in the recording text section of .claude/prompt/english_lesson.md and pass it to Claude Code.
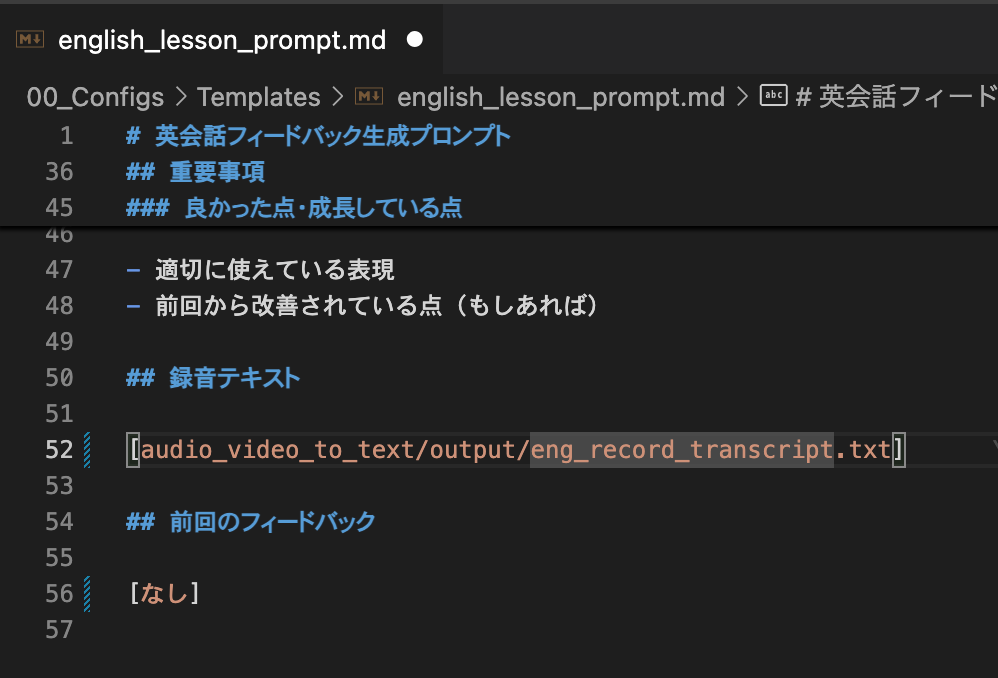

I confirmed in the DEBUG logs that the hooks ran and Prettier started.

It's complete.
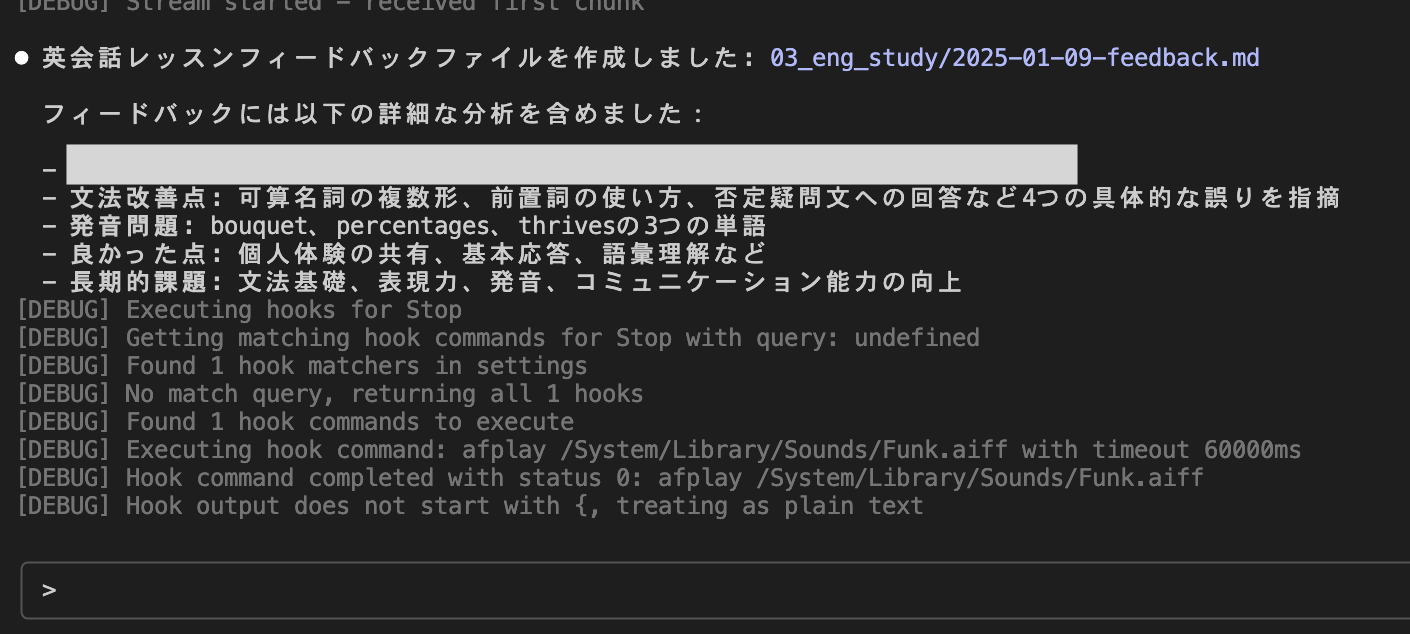
Though the date in the feedback file shows January for some reason, I received appropriate feedback.

For meeting minutes, the process is almost identical except for the prompt, so please try it yourself.
For mp4 files, you could also use Gemini Web for transcription (I implemented the script because mp3 wasn't supported there...).
Conclusion
Since I've only been managing personal knowledge for a week, I plan to improve the configuration daily, so please consider this as a reference.