![[Small Talk] Converting CSV files with many columns to JSON and loading them #SnowflakeDB](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-37f4322e7cca0bb66380be0a31ceace4/0886455fd66594d3e7d8947c9c7c844d/eyecatch_snowflake)
[Small Talk] Converting CSV files with many columns to JSON and loading them #SnowflakeDB

Introduction
I had an opportunity to load data files with many columns in Snowflake, and I'm sharing what I tried in this article.
Conclusion of this article
If you can convert data files beforehand, transforming them into semi-structured formats like JSON before loading and loading them into a single VARIANT type column can be expected to improve loading performance.
What I'll try in this article
I'll try the following approaches for loading data files with many columns:
- Create data files (CSV) with many columns
- Maximum number of columns set to 20,000
- Load the data files (execute COPY command)
- Loading in CSV format
- Define a table with maximum 20,000 columns
- Convert data files to JSON format and load into 1 column with VARIANT type
- Expand vertically within Snowflake after loading
- Expand horizontally within Snowflake after loading## Preparation
- Loading in CSV format
Sample data creation and CSV to JSON file conversion were done using Python.
The various Python functions used during verification are as follows. The creation of these functions was handled by generative AI.
Function to create sample data
import pandas as pd
import numpy as np
import sys
def generate_survey_data(rows: int, cols: int):
"""
Function that generates a sample of survey response data with the number of rows and columns
specified in the arguments and outputs it as a CSV
Args:
rows (int): Number of rows (number of respondents)
cols (int): Number of columns (USERID + number of questions)
"""
if cols < 1:
print("Please specify 1 or more for the number of columns.")
return
# Generate column names
columns = ['USERID']
for i in range(1, cols):
columns.append(f'Q-{i}')
# Create data excluding USERID column (randomly generate 0, 1)
data = np.random.randint(0, 2, size=(rows, cols - 1))
# Create DataFrame
df = pd.DataFrame(data, columns=columns[1:])
# Add USERID column
df.insert(0, 'USERID', range(1, rows + 1))
# Output as CSV file
file_name = f'survey_data_{rows}x{cols}.csv'
df.to_csv(file_name, index=False)
print(f'CSV file generated: {file_name}')
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: python generate_survey_data.py <rows> <columns>")
else:
try:
rows = int(sys.argv[1])
cols = int(sys.argv[2])
generate_survey_data(rows, cols)
except ValueError:
print("Please specify integers as arguments.")
Function to create DDL statements for tables with many columns
import sys
def generate_ddl_to_file(table_name: str, num_questions: int, output_file: str):
"""
Function that generates Snowflake CREATE TABLE DDL for the specified table name
and number of questions, and writes it to a file.
Args:
table_name (str): Name of the table to create.
num_questions (int): Number of question columns (Q-1, Q-2...).
output_file (str): Filename to write the DDL statement to.
"""
if num_questions < 1:
print("Error: Please specify an integer of 1 or greater for the number of questions.")
return
columns = ['\t"USERID" NUMBER(2,0)']
for i in range(1, num_questions + 1):
columns.append(f'\t"Q-{i}" NUMBER(1,0)')
columns_str = ",\n".join(columns)
ddl = f"create or replace TABLE {table_name} (\n{columns_str}\n);"
try:
with open(output_file, 'w') as f:
f.write(ddl)
print(f"DDL successfully written to '{output_file}'.")
except Exception as e:
print(f"Error: Failed to write to file. Details: {e}")
if __name__ == "__main__":
# Check number of arguments (script name + number of questions = 2)
if len(sys.argv) != 2:
print("Usage: python generate_snowflake_ddl.py <number of questions>")
sys.exit(1)
num_questions_str = sys.argv[1]
try:
num_questions = int(num_questions_str)
if num_questions < 1:
raise ValueError("Please specify an integer of 1 or greater for the number of questions.")
# Auto-generate table name and output filename
total_columns = num_questions + 1
table_name = f'MY_SURVEY_TABLE_{total_columns}'
output_file = f'{table_name}.sql'
generate_ddl_to_file(table_name, num_questions, output_file)
except ValueError as e:
print(f"Error: {e}")
```:::details Function to Convert CSV Files to JSON Format
```python
import csv
import json
import sys
def csv_to_json(csv_file_path, json_file_path):
"""
Function that reads a specified CSV file and outputs it as a JSON file.
Args:
csv_file_path (str): Path to the CSV file to read.
json_file_path (str): Path to the JSON file to output.
"""
data = []
try:
with open(csv_file_path, 'r') as csv_file:
csv_reader = csv.DictReader(csv_file)
for row in csv_reader:
data.append(row)
except FileNotFoundError:
print(f"Error: File '{csv_file_path}' not found.")
return
except Exception as e:
print(f"Error: Failed to read CSV file. Details: {e}")
return
try:
with open(json_file_path, 'w', encoding='utf-8') as json_file:
json.dump(data, json_file, indent=4, ensure_ascii=False)
print(f"Read '{csv_file_path}' and converted it to JSON file as '{json_file_path}'.")
except Exception as e:
print(f"Error: Failed to write JSON file. Details: {e}")
if __name__ == '__main__':
if len(sys.argv) != 3:
print("Usage: python csv_to_json_converter.py <input CSV filename> <output JSON filename>")
sys.exit(1)
input_csv = sys.argv[1]
output_json = sys.argv[2]
csv_to_json(input_csv, output_json)
Sample Data
Using the above function, I created the following data files:
# 1000 columns
$ python generate_sample_data.py 10 1000
CSV file generated: survey_data_10x1000.csv
# 10,000 columns
$ python generate_sample_data.py 10 10000
CSV file generated: survey_data_10x10000.csv
# 20,000 columns
$ python generate_sample_data.py 10 20000
CSV file generated: survey_data_10x20000.csv
The content has 10 records in each file, while the number of columns is 1000, 10,000, and 20,000 respectively. Here is a partial view of the data file:
USERID,Q-1,Q-2,...,Q-997,Q-998,Q-999
1,0,1,...,1,0,1
2,0,1,...,1,0,1
3,1,1,...,0,0,1
.
.
.
8,1,1,...,1,0,1
9,1,1,...,0,0,1
10,1,1,...,1,1,1
```### Snowflake Side: Creating Various Objects
Let's create database, schema, internal stage and other objects for verification.
```sql
CREATE DATABASE IF NOT EXISTS test_db;
USE SCHEMA PUBLIC;
--Create internal stage
CREATE STAGE my_int_stage;
I created two file formats. The one with PARSE_HEADER = TRUE will be used when defining tables through schema detection.
--Create file formats
CREATE OR REPLACE FILE FORMAT my_csv_format_parse_header
TYPE = CSV
FIELD_DELIMITER = ','
PARSE_HEADER = TRUE
EMPTY_FIELD_AS_NULL = true
COMPRESSION = NONE;
CREATE OR REPLACE FILE FORMAT my_csv_format
TYPE = CSV
FIELD_DELIMITER = ','
SKIP_HEADER = 1
EMPTY_FIELD_AS_NULL = true
COMPRESSION = NONE;
Let's create virtual warehouses for verification. I've prepared two different sizes here.
--Virtual warehouse
USE ROLE SYSADMIN;
CREATE WAREHOUSE xs_wh
WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
CREATE WAREHOUSE large_wh
WAREHOUSE_SIZE = LARGE
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;
I've also disabled caching.
ALTER ACCOUNT SET USE_CACHED_RESULT = false;
The sample data files that we created have been placed in the internal stage.
>ls @my_int_stage;
+---------------------------------------+--------+----------------------------------+-------------------------------+
| name | size | md5 | last_modified |
|---------------------------------------+--------+----------------------------------+-------------------------------|
| my_int_stage/survey_data_10x1000.csv | 25904 | 6c12874310c2c463e72cf8b541f69a60 | Sun, 31 Aug 2025 06:10:26 GMT |
| my_int_stage/survey_data_10x10000.csv | 268896 | d206836f0772efaa56cd121058528c08 | Sun, 31 Aug 2025 06:10:26 GMT |
| my_int_stage/survey_data_10x20000.csv | 548896 | 106958550d2deb822149657d885cabe3 | Sun, 31 Aug 2025 06:10:26 GMT |
+---------------------------------------+--------+----------------------------------+-------------------------------+
Let's Try It
Let's load the CSV data files with different numbers of columns.### 1000 Columns
Due to the large number of columns, I defined the table using the schema detection feature.
--Define table using schema detection feature: 1000 columns
CREATE OR REPLACE TABLE MY_SURVEY_TABLE_1000
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x1000.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
--Confirm the number of columns
>DESC TABLE MY_SURVEY_TABLE_1000
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 1000 |
+----------+
--Check USERID and 1000 columns
>DESC TABLE MY_SURVEY_TABLE_1000
->> SELECT "name" FROM $1 LIMIT 3;
+--------+
| name |
|--------|
| USERID |
| Q-1 |
| Q-2 |
+--------+
>DESC TABLE MY_SURVEY_TABLE_1000
->> SELECT "name" FROM $1 LIMIT 3 OFFSET 997;
+-------+
| name |
|-------|
| Q-997 |
| Q-998 |
| Q-999 |
+-------+
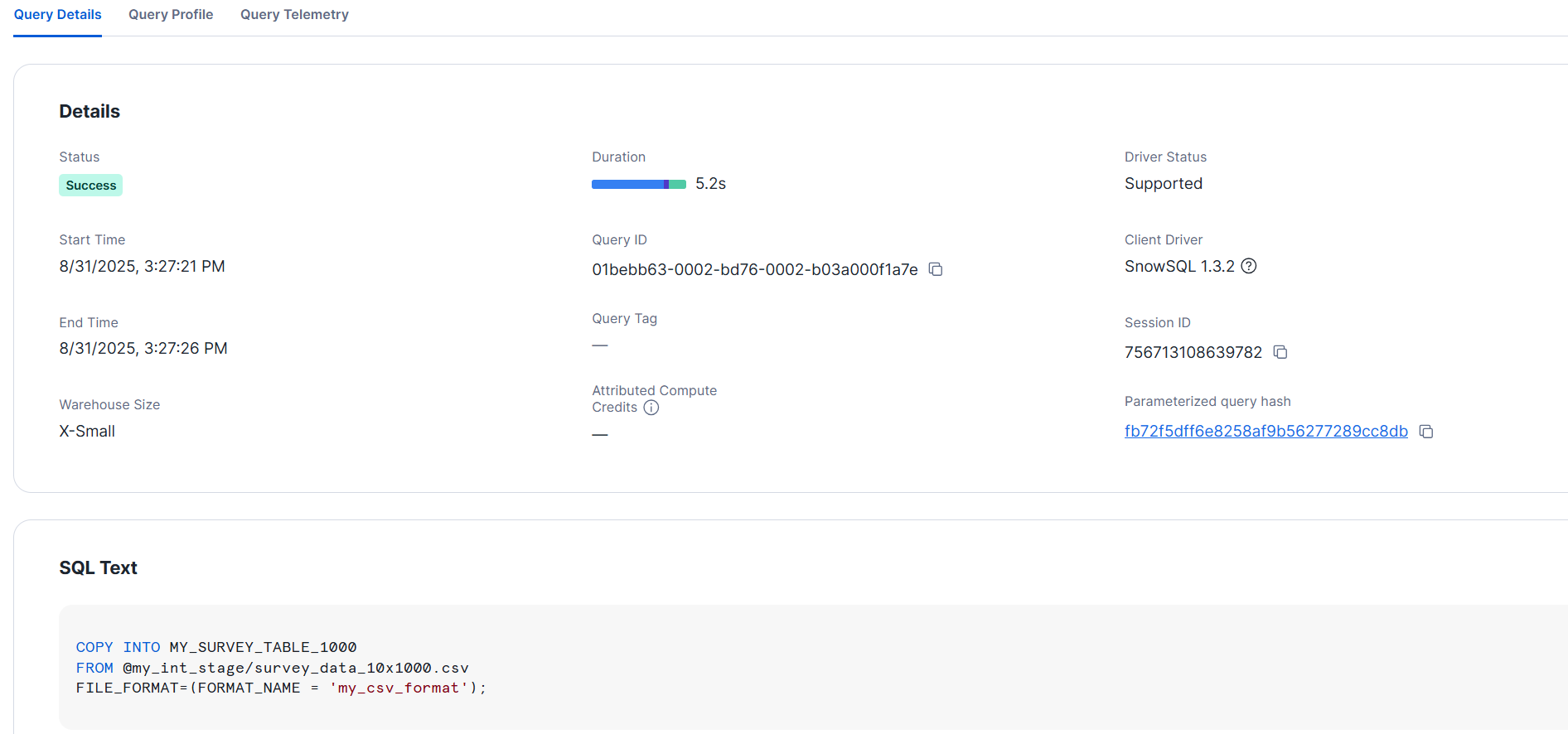
Let's load the data. In this case with this number of columns, I only tested with XS size. Here, the data loaded in about 5 seconds.
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_1000
FROM @my_int_stage/survey_data_10x1000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
+--------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|--------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x1000.csv | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+--------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
```### 10000 Columns CSV
Next, we'll try a CSV data file with 10000 columns. Since there are many columns, we similarly defined the table using the schema detection feature.
```sql
--Define table using schema detection feature: 10000 columns
CREATE OR REPLACE TABLE MY_SURVEY_TABLE_10000
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x10000.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
--Check the number of columns
>DESC TABLE MY_SURVEY_TABLE_10000
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 10000 |
+----------+
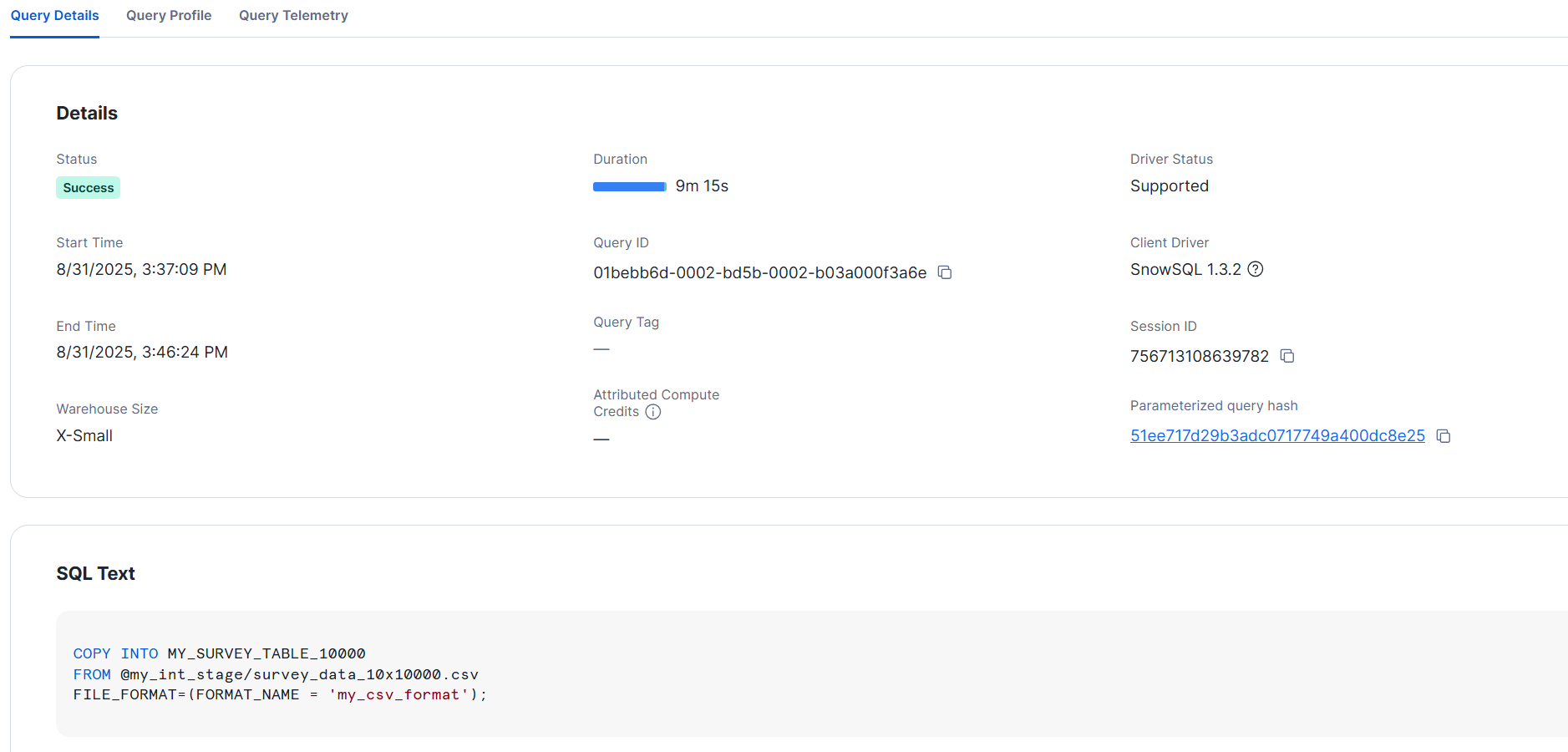
From here, we'll try loading with each warehouse size.
- XS size
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_10000
FROM @my_int_stage/survey_data_10x10000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| my_int_stage/survey_data_10x10000.csv | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
```
- L size
```sql
TRUNCATE TABLE MY_SURVEY_TABLE_10000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_10000
FROM @my_int_stage/survey_data_10x10000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| my_int_stage/survey_data_10x10000.csv | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+---------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
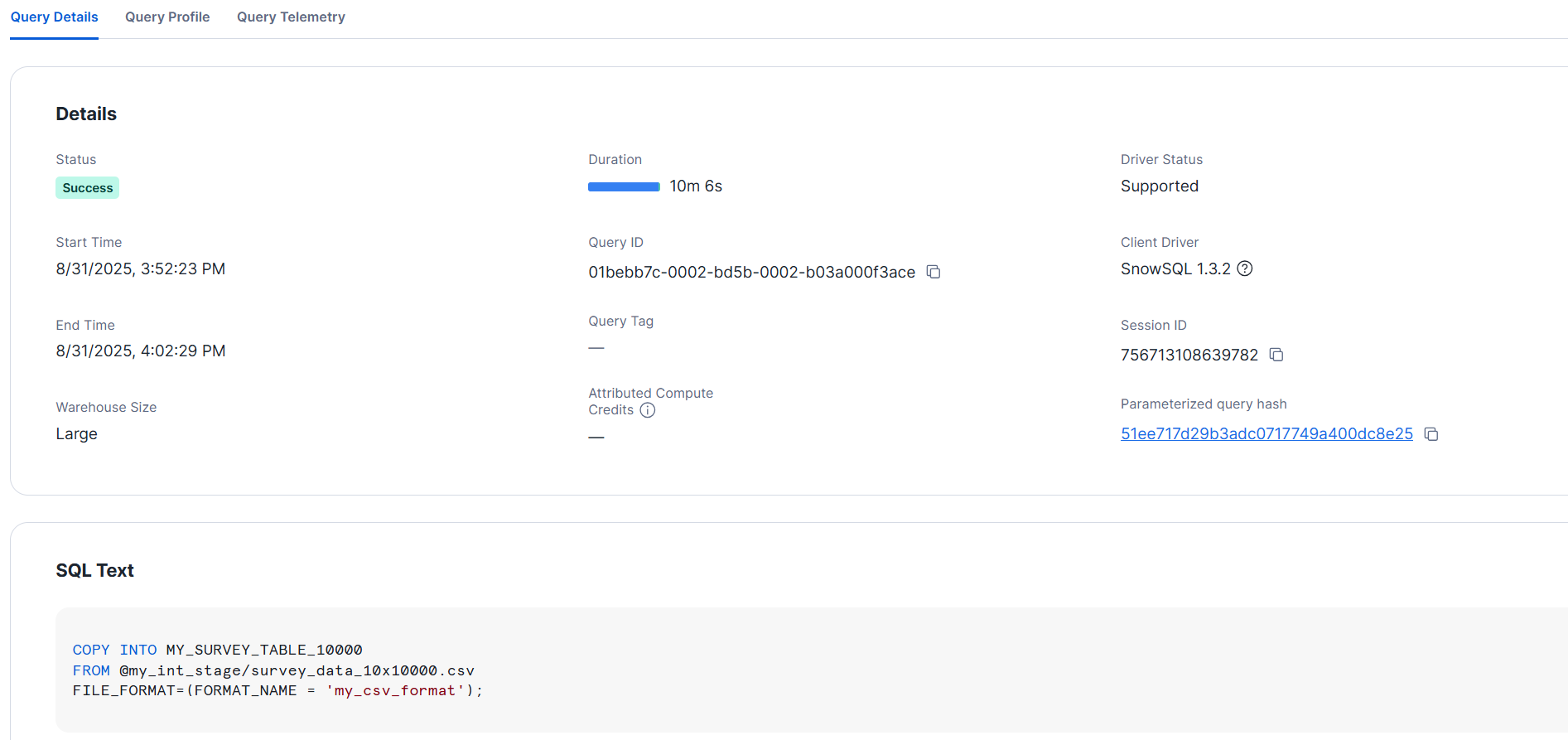
The above shows the results of each single trial, and each took approximately 10 minutes to load. During testing, since we are loading a single file, there is no visible benefit to changing the size.
*Details will be explained later.### 2000 Columns CSV
Let's try loading a CSV file with an increased number of columns - 20000 columns. When attempting to define a table using schema detection in this case, an error occurred.
>CREATE OR REPLACE TABLE MY_SURVEY_TABLE_20000
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x20000.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
100316 (22000): Column position is 10000 but max column position allowed is 9999
According to the error message, the maximum number of columns appears to be 9,999. Since we were able to define a table with 10,000 columns in the previous step, I tried with a data file containing 10,001 columns, which resulted in an error.
$ python generate_sample_data.py 10 10001
This produces an error:
>CREATE OR REPLACE TABLE MY_SURVEY_TABLE_10001
USING TEMPLATE (
SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@my_int_stage/survey_data_10x10001.csv',
FILE_FORMAT=>'my_csv_format_parse_header'
)
)
);
100316 (22000): Column position is 10000 but max column position allowed is 9999
Although the schema detection feature gives an error, Snowflake still allows us to define the table directly. I generated a DDL statement using the function prepared in advance, and defined the table by executing this file.
$ python generate_ddl.py 19999
DDL has been successfully written to 'MY_SURVEY_TABLE_20000.sql'.
Part of the defined DDL statement:
create or replace TABLE MY_SURVEY_TABLE_20000 (
"USERID" NUMBER(2,0),
"Q-1" NUMBER(1,0),
"Q-2" NUMBER(1,0),
・
・
・
"Q-19997" NUMBER(1,0),
"Q-19998" NUMBER(1,0),
"Q-19999" NUMBER(1,0)
);
I placed the SQL file in the stage and executed it:
--Define the table
>EXECUTE IMMEDIATE FROM @my_int_stage/MY_SURVEY_TABLE_20000.sql;
+---------------------------------------------------+
| status |
|---------------------------------------------------|
| Table MY_SURVEY_TABLE_20000 successfully created. |
+---------------------------------------------------+
--Confirm the number of columns
>DESC TABLE MY_SURVEY_TABLE_20000
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 20000 |
+----------+
Let's try loading with different warehouse sizes.
- XS size
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_20000
FROM @my_int_stage/survey_data_10x20000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
>SELECT COUNT(*) FROM MY_SURVEY_TABLE_20000;
+----------+
| COUNT(*) |
|----------|
| 10 |
+----------+
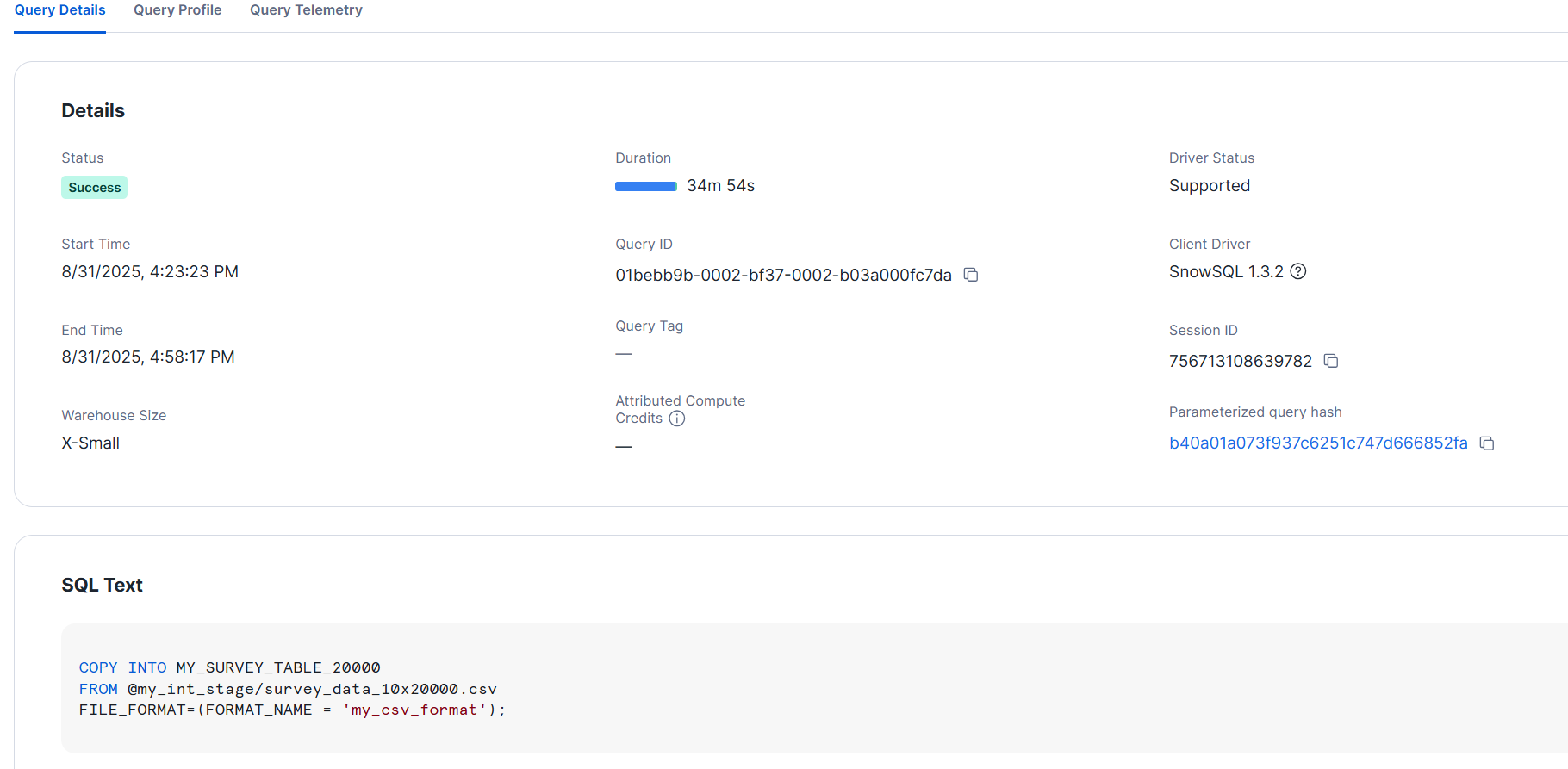
- L size
TRUNCATE TABLE MY_SURVEY_TABLE_20000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO MY_SURVEY_TABLE_20000
FROM @my_int_stage/survey_data_10x20000.csv
FILE_FORMAT=(FORMAT_NAME = 'my_csv_format');
>SELECT COUNT(*) FROM MY_SURVEY_TABLE_20000;
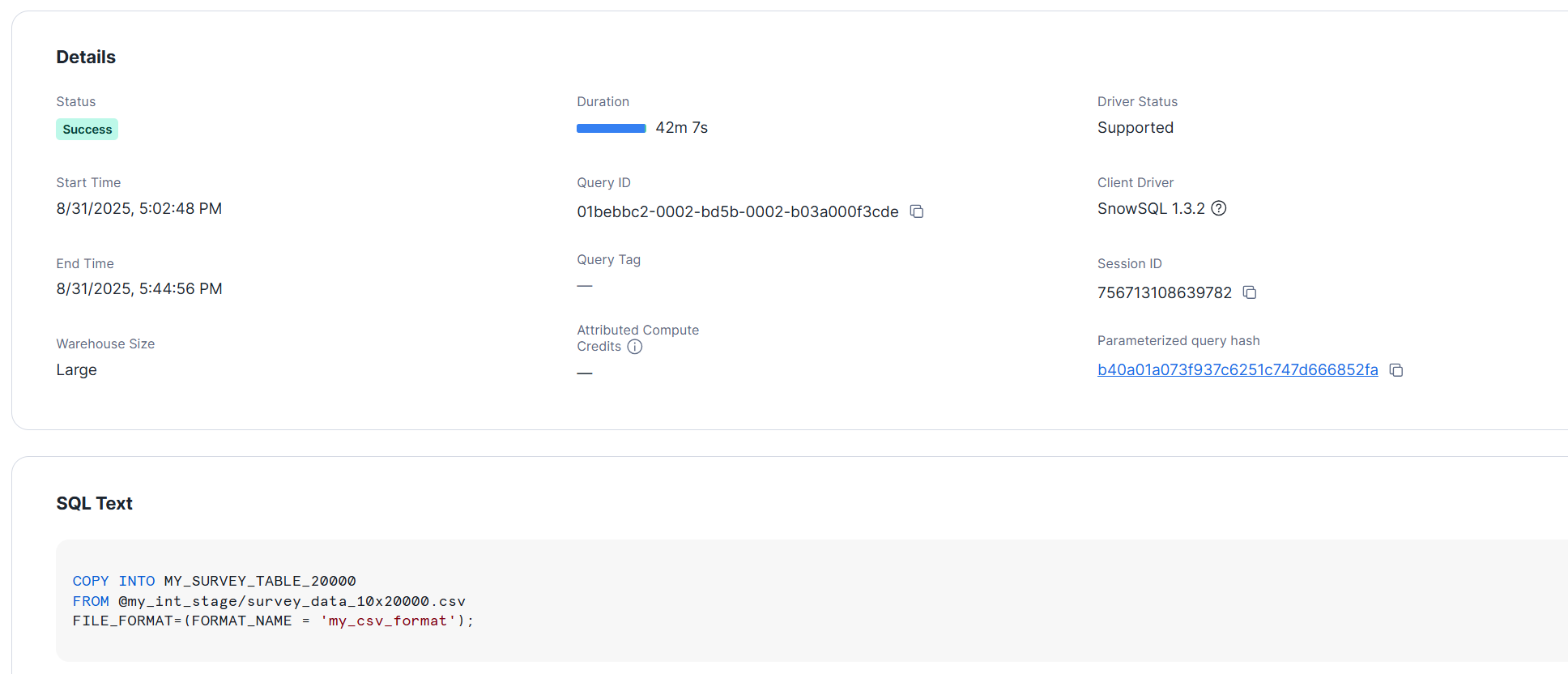
Both took more than 30 minutes to complete. Similarly, no benefits were observed from increasing the warehouse size.### Converting to JSON Format and Loading
Let's convert CSV to JSON and load it as a single column of VARIANT type. We'll try this with original column counts of 10000 and 20000 columns.
First, we'll convert our data files to JSON format.
$ python csv_to_json.py survey_data_10x10000.csv survey_data_10x10000.json
Successfully read 'survey_data_10x10000.csv' and converted it to JSON file 'survey_data_10x10000.json'.
$ python csv_to_json.py survey_data_10x20000.csv survey_data_10x20000.json
Successfully read 'survey_data_10x20000.csv' and converted it to JSON file 'survey_data_10x20000.json'.
The contents of the JSON file look like this:
[
{
"USERID": "1",
"Q-1": "1",
"Q-2": "0",
・
・
・
"Q-9998": "1",
"Q-9999": "1"
},
{
"USERID": "2",
"Q-1": "1",
"Q-2": "0",
・
・
・
"Q-9998": "0",
"Q-9999": "0"
}
]
We'll place the created JSON files in the internal stage.### Converting 10000-column CSV to JSON format and loading
I will try this with various sizes as well.
- XS size
--Define the table
CREATE OR REPLACE TABLE test_10000 (v VARIANT);
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_10000
FROM @my_int_stage/survey_data_10x10000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x10000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
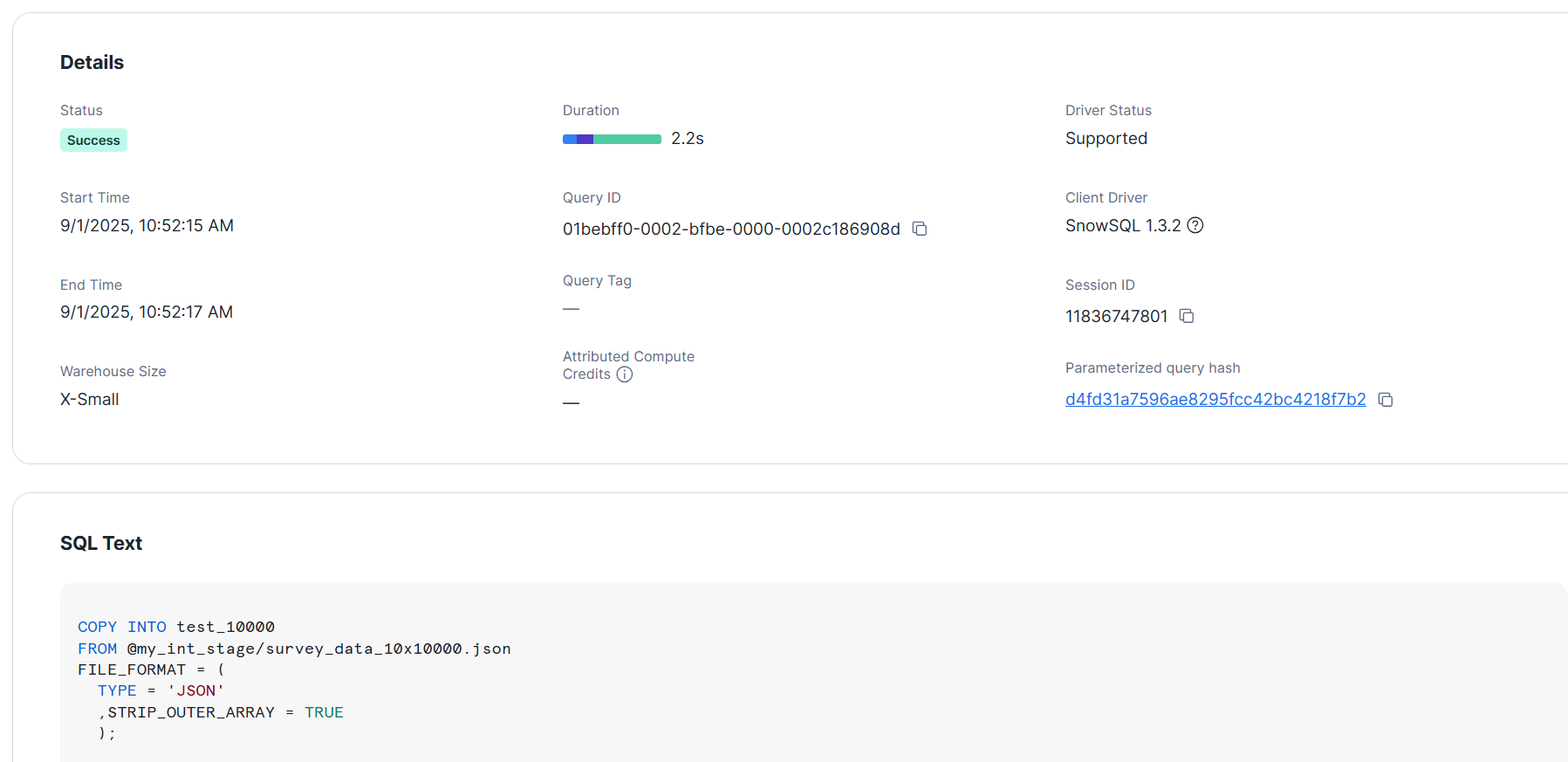
- L size
TRUNCATE TABLE test_10000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_10000
FROM @my_int_stage/survey_data_10x10000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x10000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
```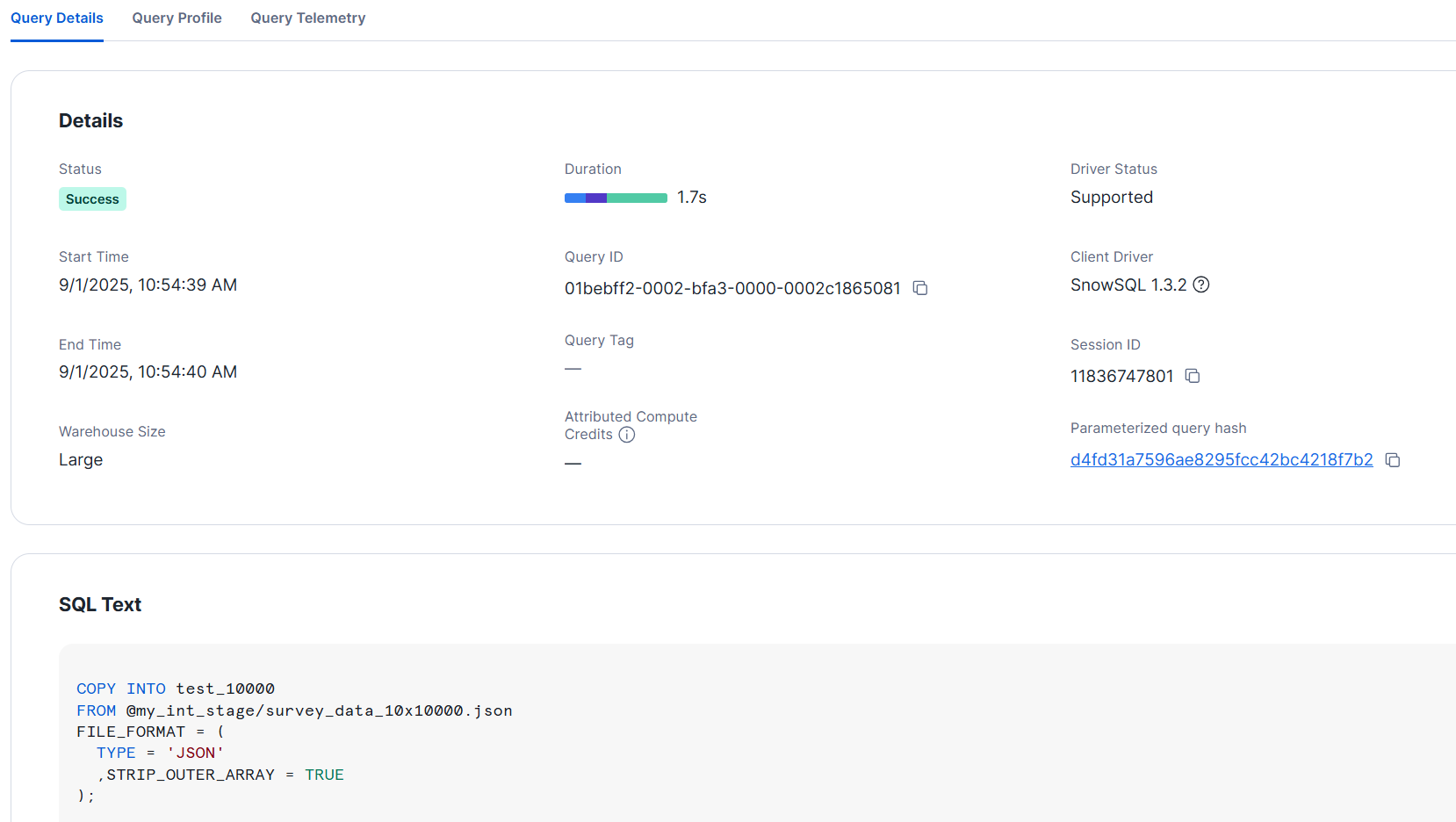
In this case, even with XS size, it loaded in about 2 seconds. After loading, it looks like the image below.
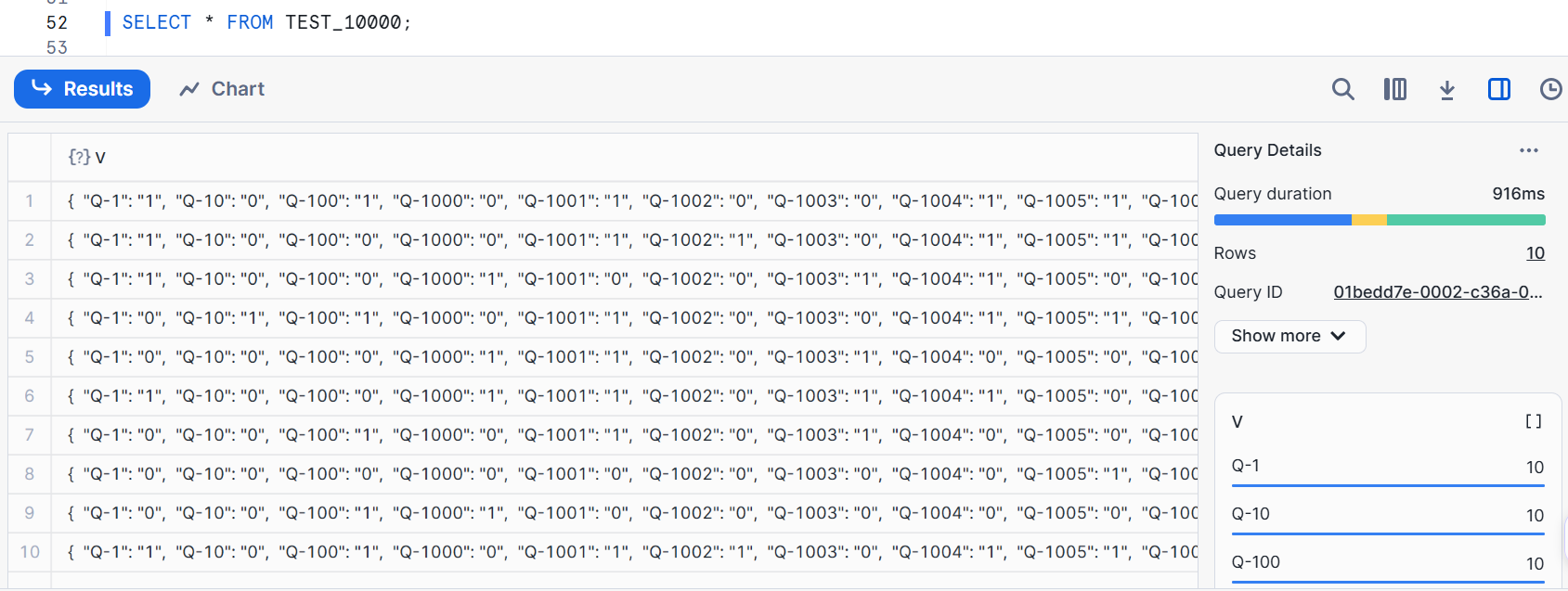### Converting 20000-column CSV to JSON format and loading
I tried this with different sizes as well.
- XS size
```sql
--Define the table
CREATE OR REPLACE TABLE test_20000 (v VARIANT);
>ALTER WAREHOUSE xs_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE xs_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_20000
FROM @my_int_stage/survey_data_10x20000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x20000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
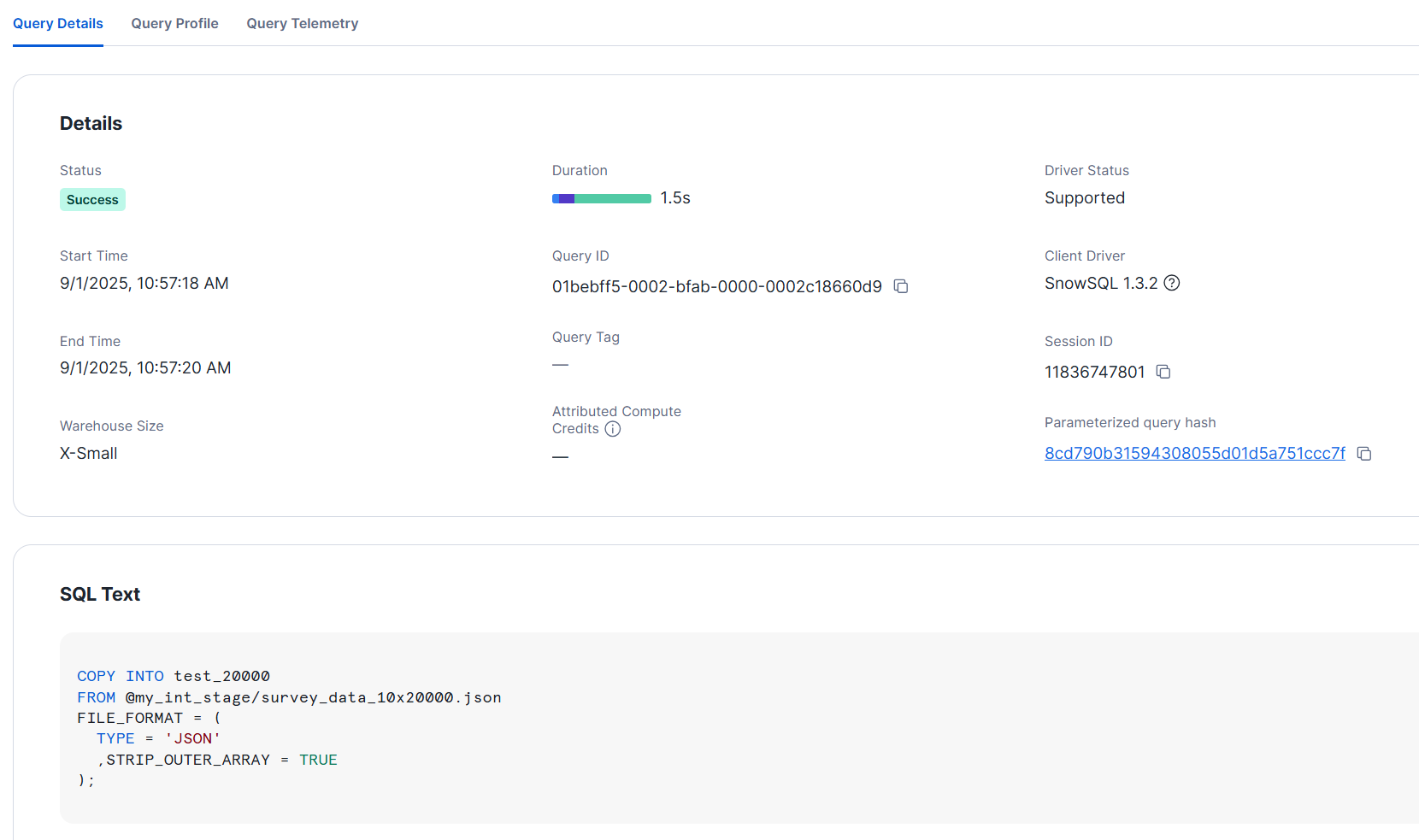
- L size
TRUNCATE TABLE test_20000;
>ALTER WAREHOUSE large_wh RESUME;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>USE WAREHOUSE large_wh;
+----------------------------------+
| status |
|----------------------------------|
| Statement executed successfully. |
+----------------------------------+
>COPY INTO test_20000
FROM @my_int_stage/survey_data_10x20000.json
FILE_FORMAT = (
TYPE = 'JSON'
,STRIP_OUTER_ARRAY = TRUE
);
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
| file | status | rows_parsed | rows_loaded | error_limit | errors_seen | first_error | first_error_line | first_error_character | first_error_column_name |
|----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------|
| my_int_stage/survey_data_10x20000.json | LOADED | 10 | 10 | 1 | 0 | NULL | NULL | NULL | NULL |
+----------------------------------------+--------+-------------+-------------+-------------+-------------+-------------+------------------+-----------------------+-------------------------+
```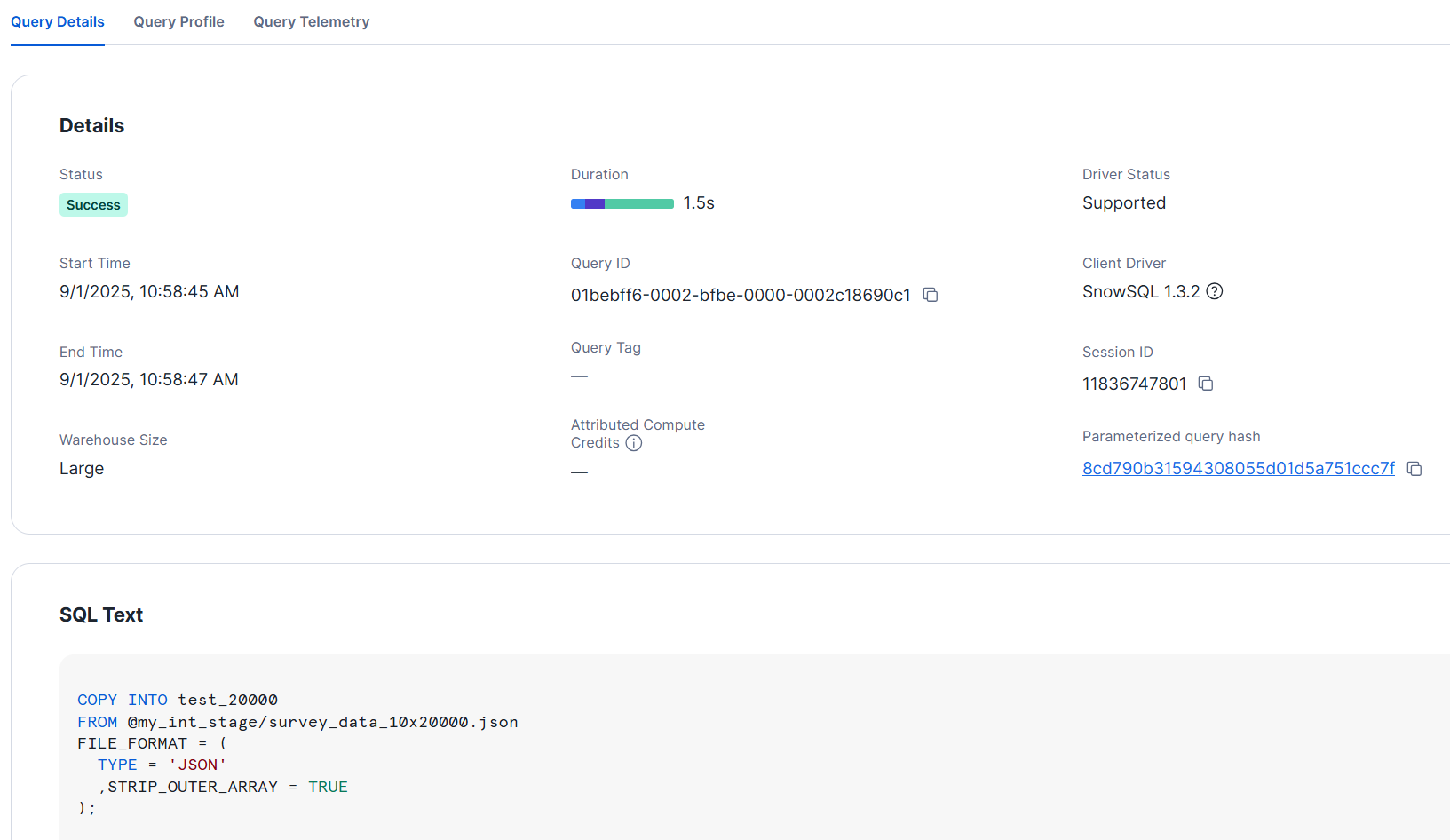
It loaded within 2 seconds even with XS size.
### Let's try transformation processing after loading
Since we loaded data into a VARIANT type column, the loaded data looks as shown in the figure below. Each record stores survey responses for each user in a key-value format.
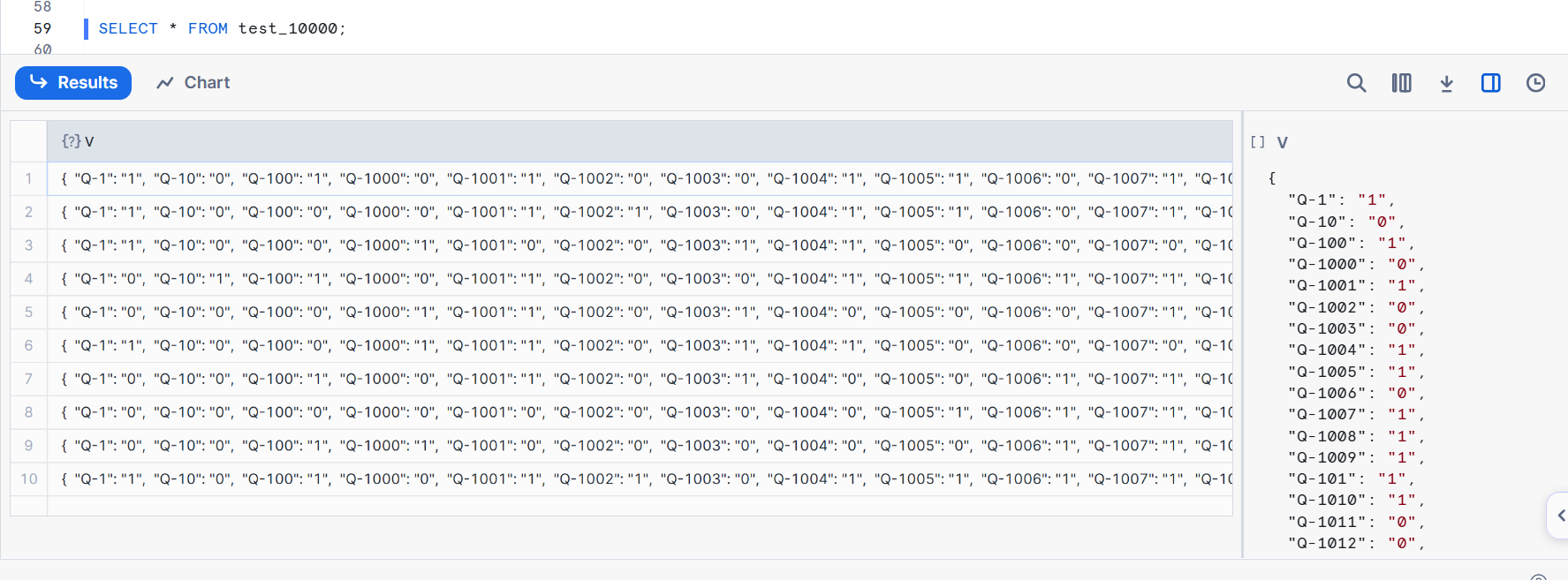
We can convert it to a vertical format with the following query. First, let's try with data originally from a CSV file with 10,000 columns that was loaded in JSON format.
- XS size
```sql
ALTER WAREHOUSE xs_wh RESUME;
USE WAREHOUSE xs_wh;
SELECT
t.v:"USERID"::NUMBER AS userid,
f.key::VARCHAR AS key,
f.value::VARCHAR AS value
FROM
test_10000 AS t,
LATERAL FLATTEN(input => t.v) AS f
WHERE
f.key <> 'USERID'
ORDER BY
userid,
key;
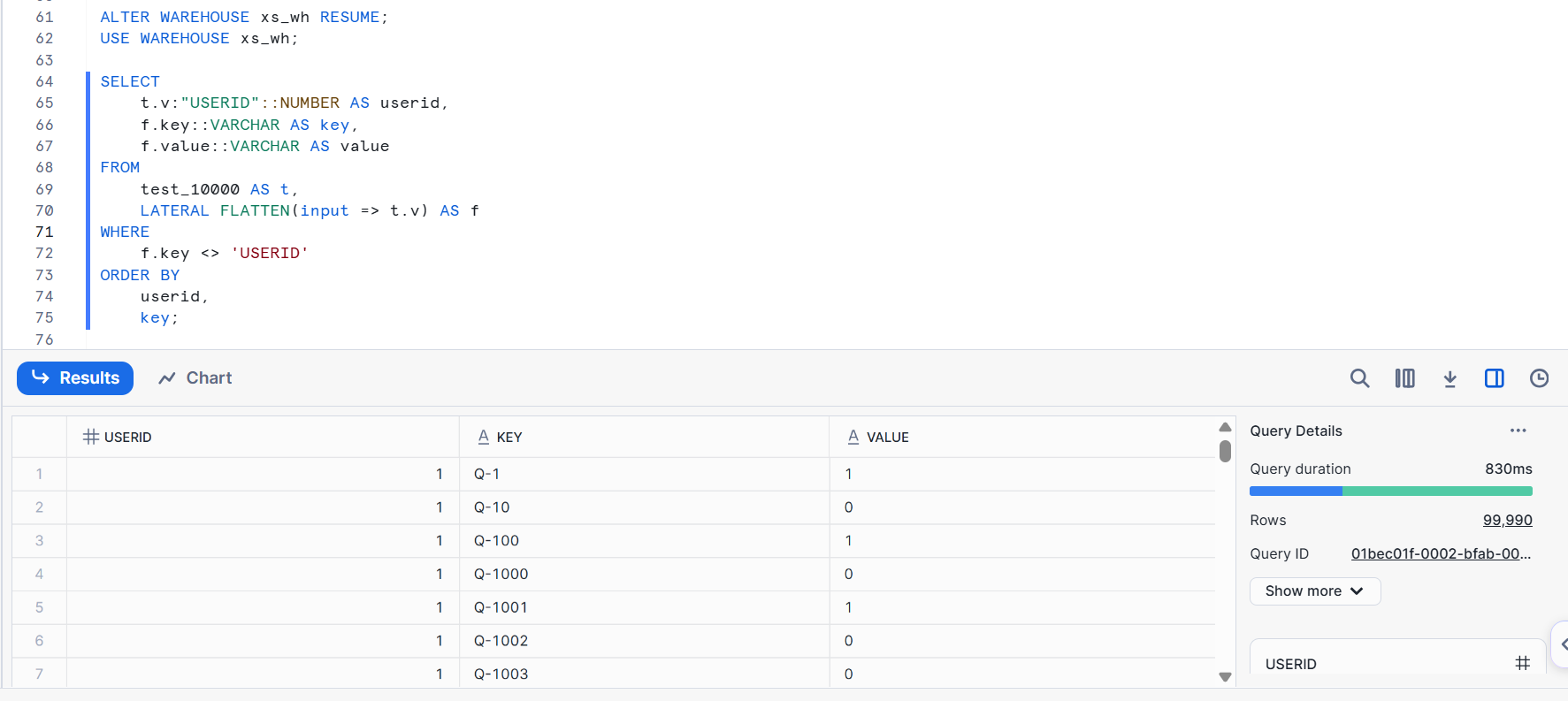
The query details are as shown below. It completed in less than a second.
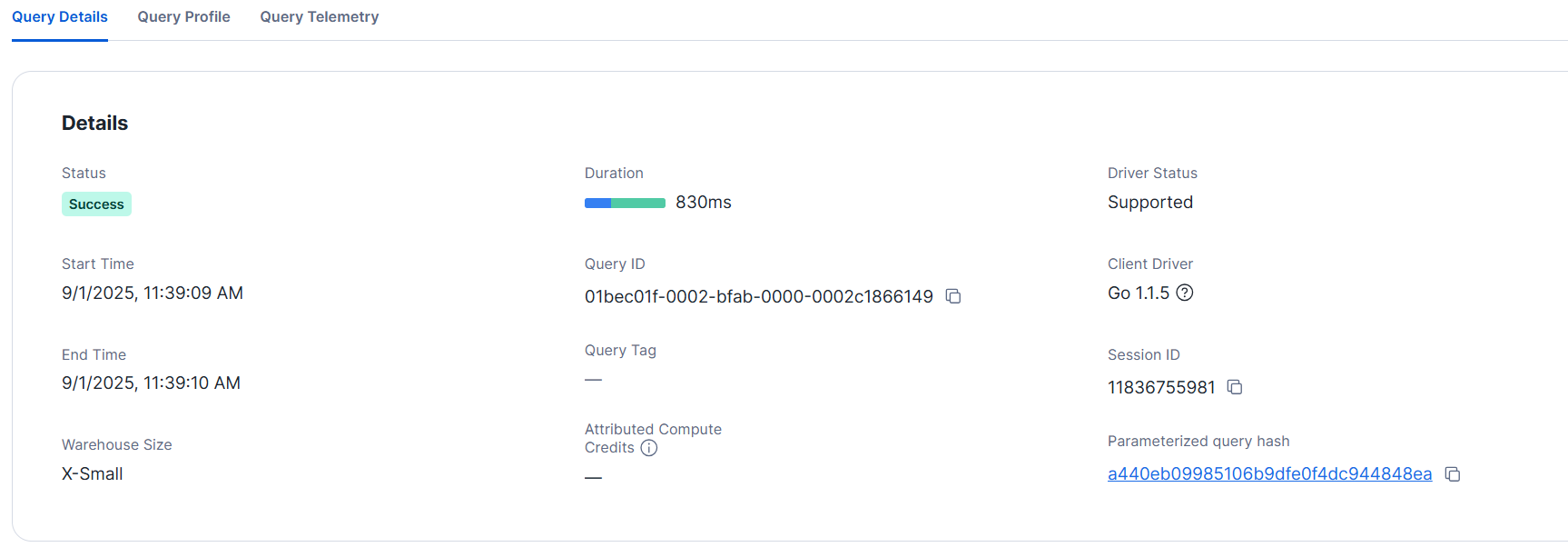
- L size
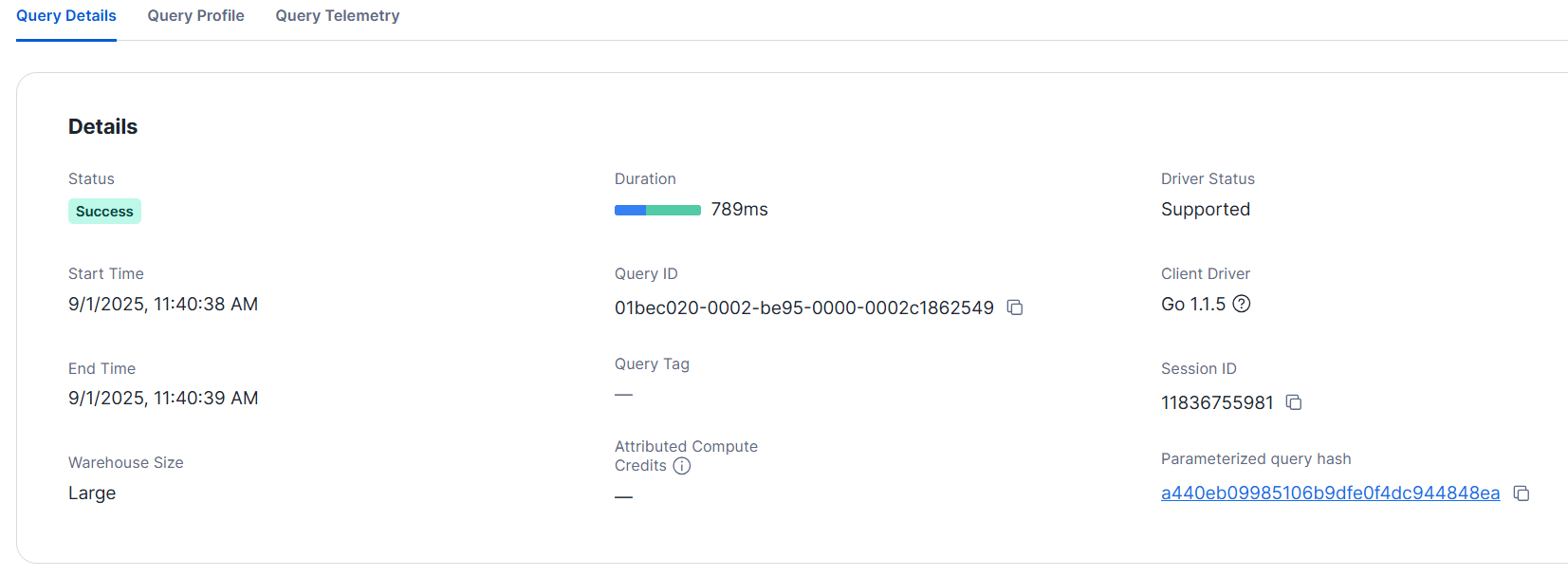
The query details are as shown below. Similarly, it completed in less than a second.
Next, let's try with data originally from a CSV file with 20,000 columns that was loaded in JSON format.
- XS size
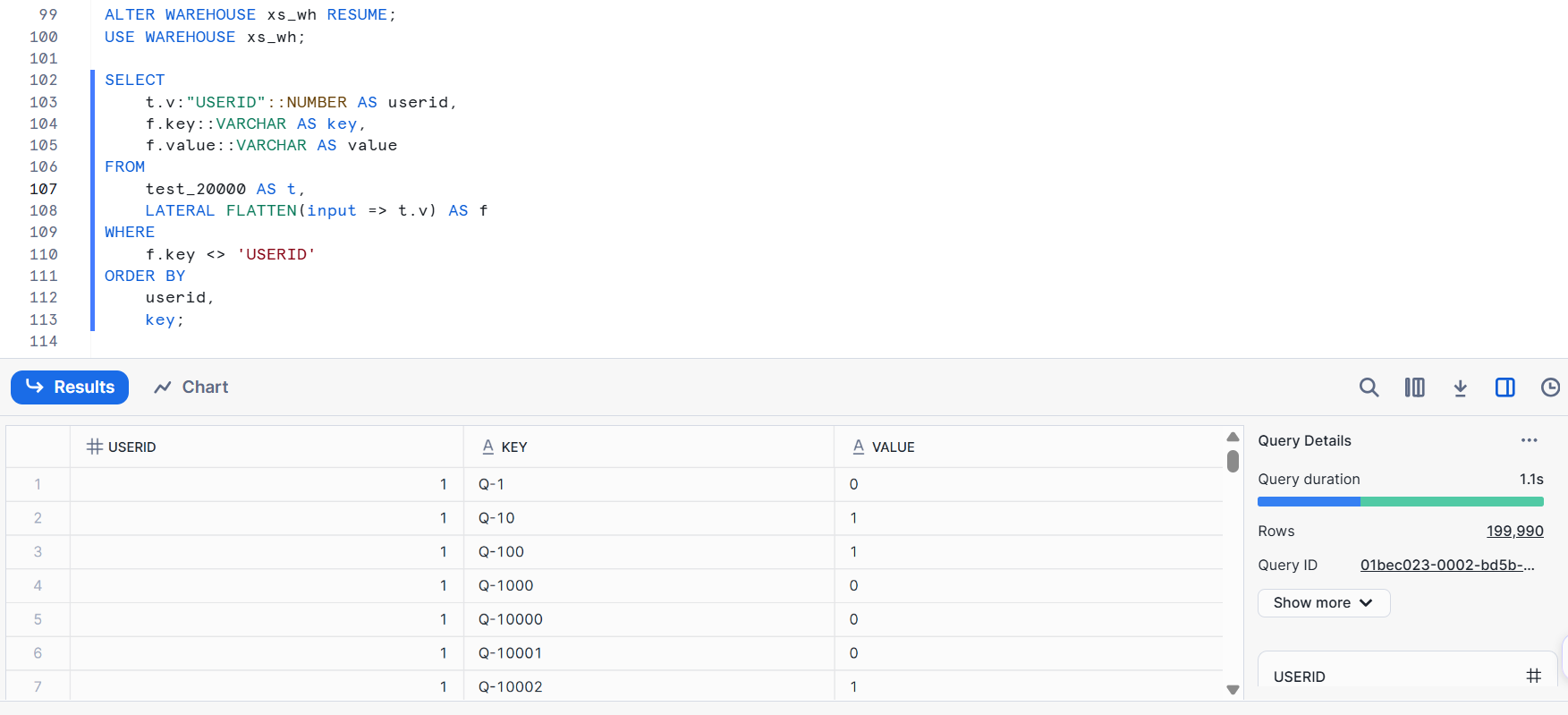
Query details
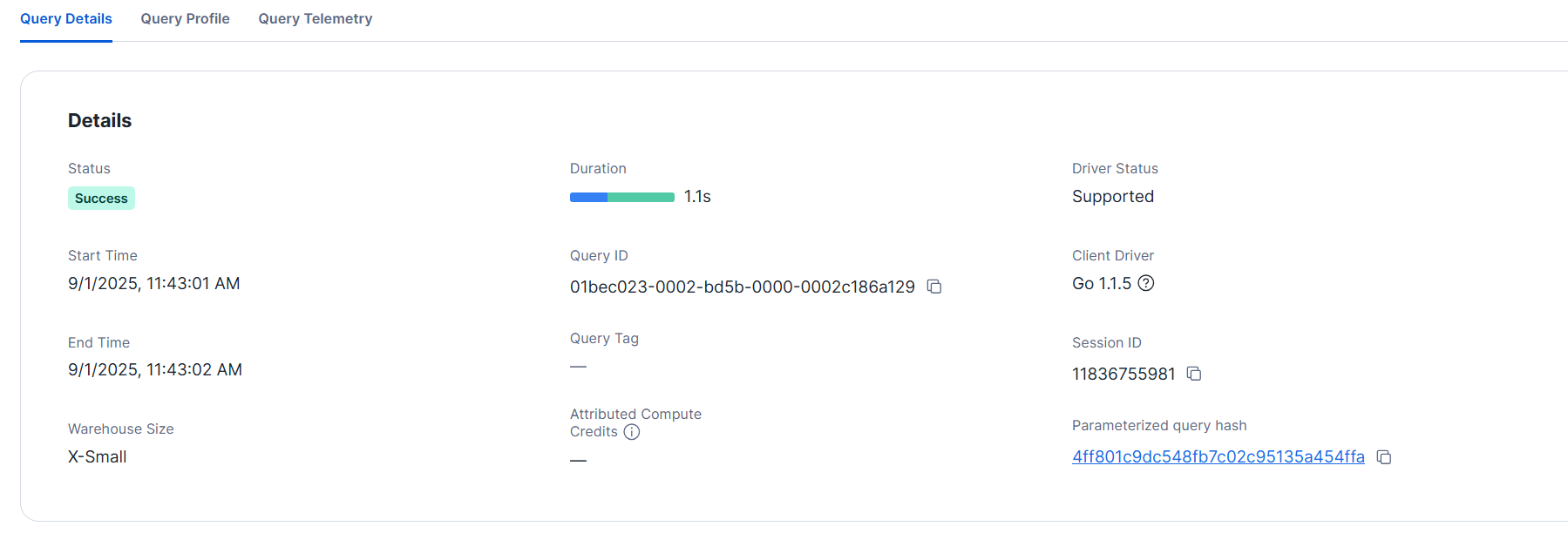
- L size
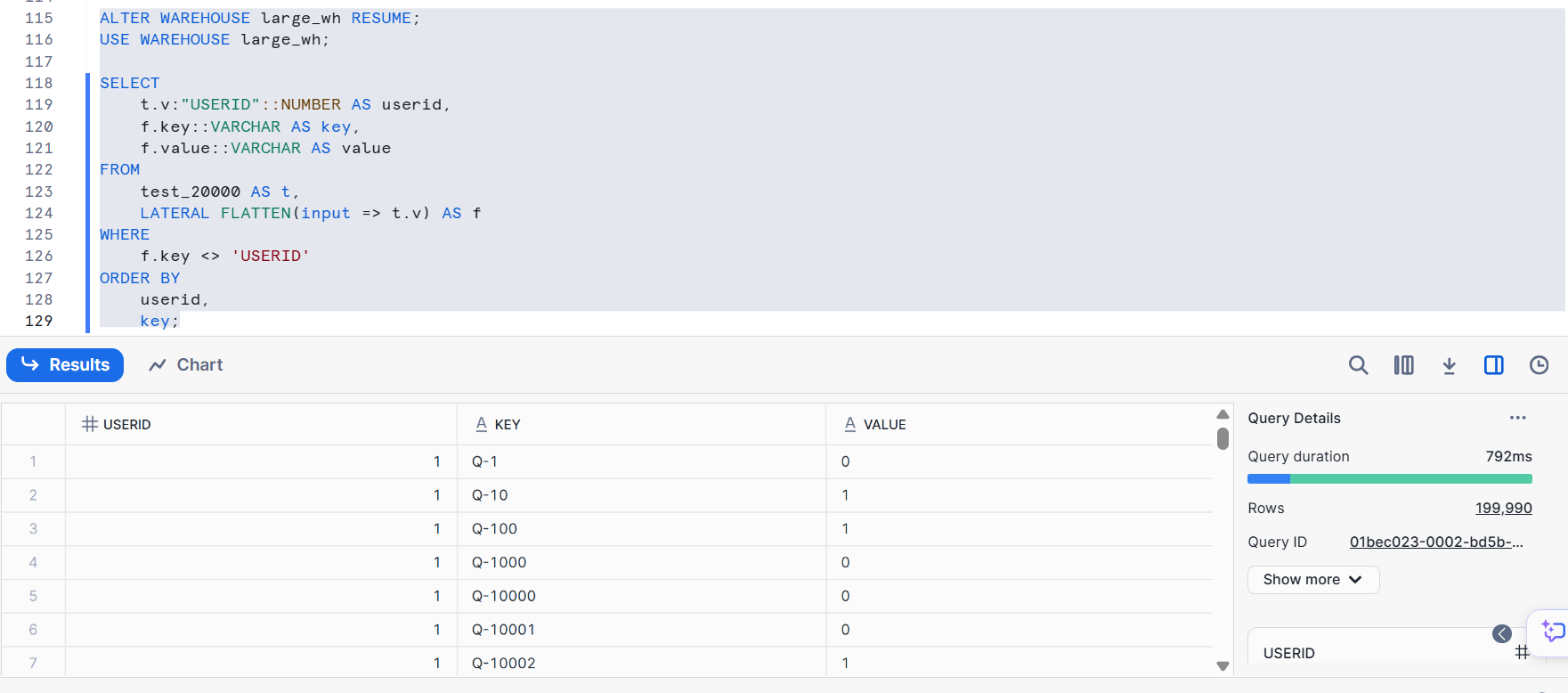
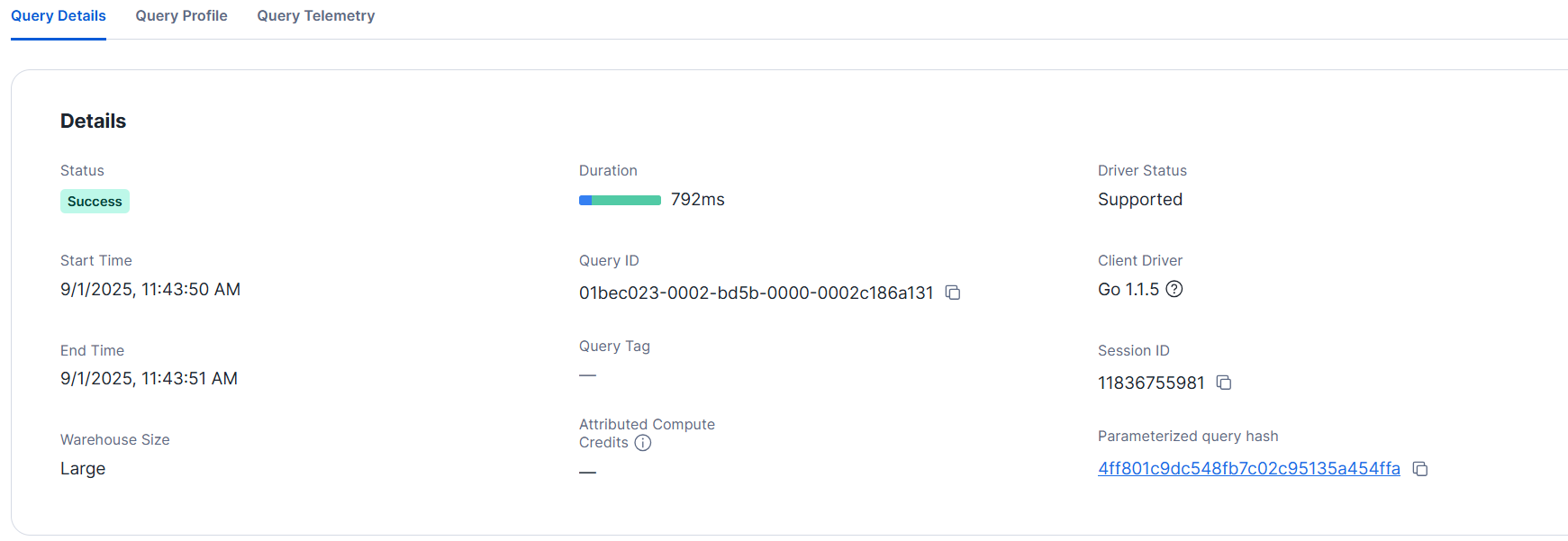
This also completed in about 1 second. If it's not essential to maintain over 10,000 columns simultaneously, the vertical format is likely to improve both performance and ease of analysis.### Expand Columns
Finally, after importing a CSV with 10,000 columns into Snowflake in JSON format, I tried expanding it back to 10,000 columns within Snowflake.
Below is an example tested with an L-size warehouse, which resulted in a processing time of over 10 minutes, similar to the initial loading time.
CREATE OR REPLACE TABLE test_10000_flat AS
SELECT
*
FROM
(
SELECT
t.v:"USERID"::NUMBER AS userid,
f.key::VARCHAR AS key,
f.value::VARCHAR AS value
FROM
test_10000 AS t,
LATERAL FLATTEN(input => t.v) AS f
WHERE
f.key <> 'USERID'
) AS source_data
PIVOT(
MAX(value) FOR key IN (ANY)
) AS pivoted_data
ORDER BY
userid;
--Check the number of columns
DESC TABLE test_10000_flat
->> SELECT count(*) FROM $1;
+----------+
| COUNT(*) |
|----------|
| 10000 |
+----------+
Query details
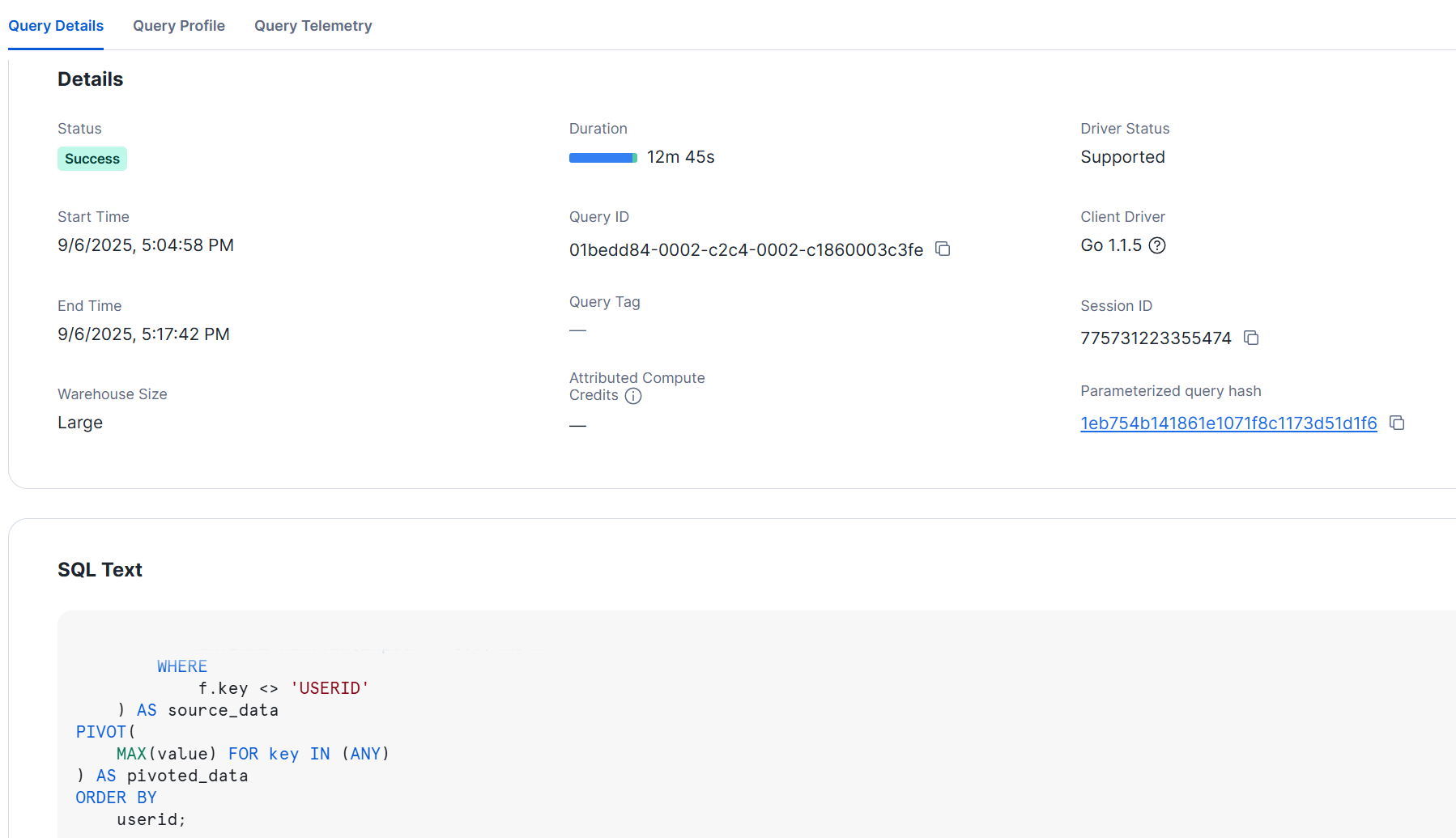 ## Considerations for Tables with Many Columns
## Considerations for Tables with Many Columns
First, regarding the number of data files related to the current configuration during data loading, the following relevant information is available:
Snowflake virtual warehouses have each thread ingesting a single file at a time.
An XS size warehouse provides 8 threads, and the number of available threads doubles with each increase in warehouse size. Therefore, you can benefit from scaling up when loading a large number of files.
On the other hand, in cases like this one where the number of files is small, increasing the size won't change the processing speed, as each thread processes a single file.
Additionally, the relationship between number of columns and performance is explained in detail here:
Tables with many columns experience decreased performance due to reduced compression rates and increased metadata processing during compilation. In particular, compilation time significantly affects query execution speed.
For reference, below is a comparison of compilation times for relevant queries. There are three records, with the query content from top to bottom as follows:
- SELECT from a table storing a 10,000-column CSV converted to JSON in a single VARIANT type column
- SELECT from a table where a single VARIANT column was expanded to 10,000 columns within Snowflake
- Creating a 10,000-column table within Snowflake from a table with a single VARIANT column (CTAS)
>SELECT
QUERY_TEXT
,QUERY_TYPE
,TOTAL_ELAPSED_TIME
,BYTES_SCANNED,COMPILATION_TIME
,EXECUTION_TIME
FROM SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY
WHERE QUERY_ID IN ('01beddb4-0002-c33c-0002-c186000471da','01beddae-0002-c2d9-0002-c186000442aa','01bedd84-0002-c2c4-0002-c1860003c3fe')
ORDER BY start_time DESC;
+------------------------------------------------+------------------------+--------------------+---------------+------------------+----------------+
| QUERY_TEXT | QUERY_TYPE | TOTAL_ELAPSED_TIME | BYTES_SCANNED | COMPILATION_TIME | EXECUTION_TIME |
|------------------------------------------------+------------------------+--------------------+---------------+------------------+----------------|
| select * from test_10000; | SELECT | 831 | 403488 | 184 | 508 |
| select * from test_10000_flat; | SELECT | 108843 | 3183136 | 107624 | 1082 |
| CREATE OR REPLACE TABLE test_10000_flat AS | CREATE_TABLE_AS_SELECT | 764722 | 403488 | 709523 | 54311 |
| SELECT | | | | | |
| * | | | | | |
| FROM | | | | | |
| ( | | | | | |
| SELECT | | | | | |
| t.v:"USERID"::NUMBER AS userid, | | | | | |
| f.key::VARCHAR AS key, | | | | | |
| f.value::VARCHAR AS value | | | | | |
| FROM | | | | | |
| test_10000 AS t, | | | | | |
| LATERAL FLATTEN(input => t.v) AS f | | | | | |
| WHERE | | | | | |
| f.key <> 'USERID' | | | | | |
| ) AS source_data | | | | | |
| PIVOT( | | | | | |
| MAX(value) FOR key IN (ANY) | | | | | |
| ) AS pivoted_data | | | | | |
| ORDER BY | | | | | |
| userid; | | | | | |
+------------------------------------------------+------------------------+--------------------+---------------+------------------+----------------+
```Compared to the first query that directly references JSON (184ms), the query that expands columns before referencing them in Snowflake has an overwhelmingly longer compilation time. Particularly when creating a table using CREATE TABLE AS SELECT, the compilation time exceeded 700,000ms, possibly due to the massive metadata processing that occurs.
## Conclusion
I tried loading a CSV file with many columns.
I hope this information will be useful as a reference.


