
I tried a method to dynamically change source loading per environment using the target variable in dbt Cloud

I'm Kawabata.
When developing with large datasets, I believe there are the following challenges:
- Long query execution times
- Concerns about executing high-cost queries
In such cases, by dynamically changing query content according to production and development environments, efficient development becomes possible in the development environment, such as "targeting only the last month's data to avoid full scans."
This time, I'll verify a method to dynamically change source loading by environment using the target variable in dbt Cloud.
Target Audience
- People interested in how to dynamically change queries by environment in dbt Cloud
- People handling large-scale data who face productivity challenges in development
Test Environment
Snowflake account: Enterprise edition trial account
dbt Cloud account: Enterprise edition
Environment and target
As mentioned earlier, dbt allows you to explicitly separate production and development environments, and you can configure information about the warehouse to connect to.
Please refer to the following documentation for details.
That information is stored in the target variable.
The target variable contains various attributes to identify the environment.
The following table summarizes particularly useful attributes for building dynamic logic.
| Attribute | Description | Use Case |
|---|---|---|
| target.name | dev,prod,ci | The active target name defined in profiles.yml or dbt Cloud job settings. The primary flag for distinguishing environments |
| target.schema | dbt_name,analytics | The target schema name where dbt materializes models in the current execution |
| target.database | DEV_DB,PROD_DB | The target database name in the current execution |
| target.warehouse | COMPUTE_XS,COMPUTE_L | The name of the Snowflake virtual warehouse being used for execution |
| target.user | name,dbt_cloud_service_account | The user account name used to connect to the data warehouse |
| target.role | ANALYTICS_ENGINEER,DBT_PROD_ROLE | The Snowflake role name used for execution |
Please refer to the following documentation for details.
Verifying Dynamic Query Changes
We'll verify how to dynamically execute queries in a development environment using the concepts above.
Data Used
This time, we'll use the ORDERS table from the TPCH_SF1000 schema in the shared database SNOWFLAKE_SAMPLE_DATA provided by Snowflake as sample data.
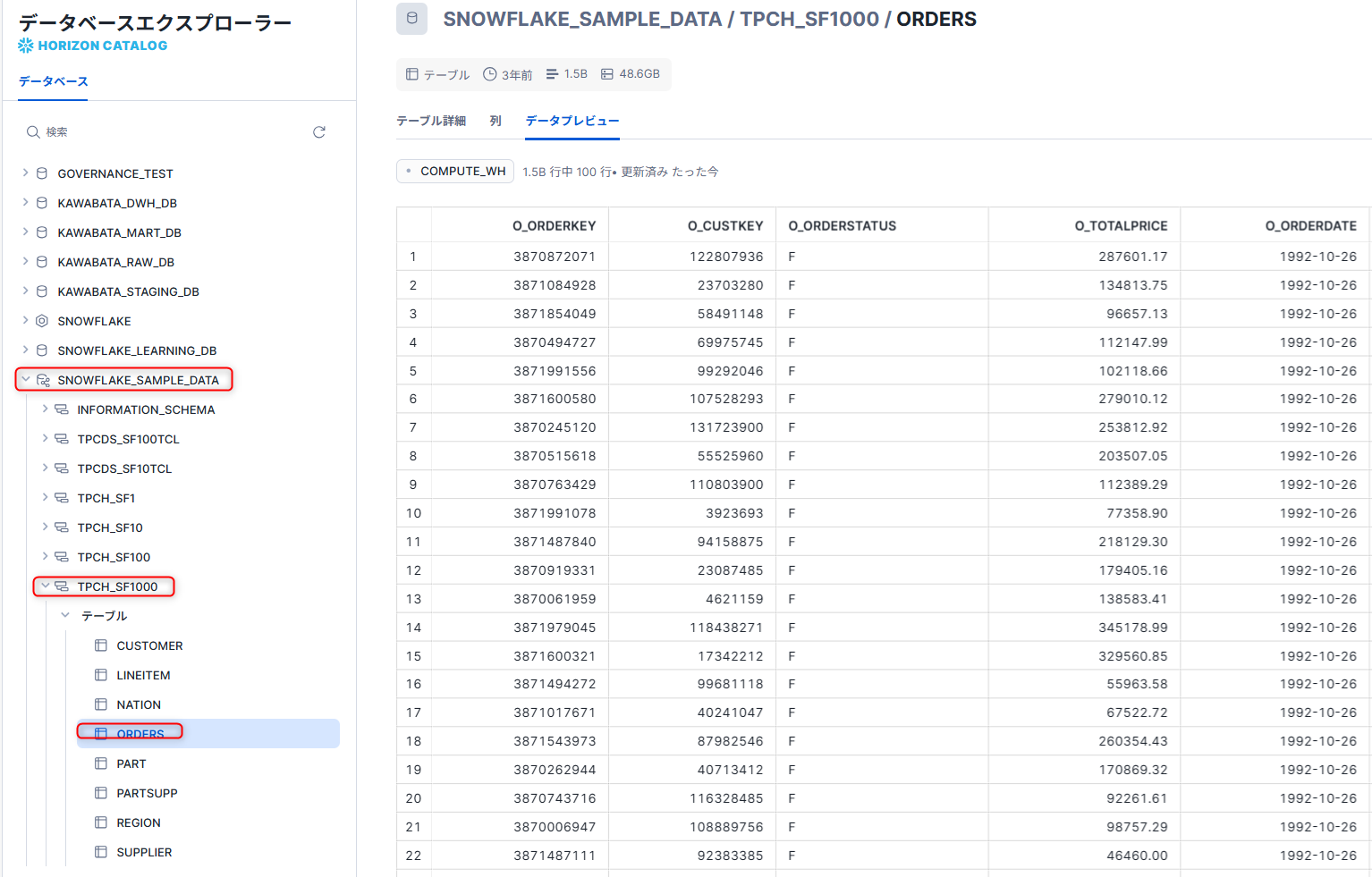
Defining sources in dbt Cloud
Create a sources.yml in the models directory of your dbt project and define the data source as follows:
version: 2
sources:
- name: tpch_sf1000
database: snowflake_sample_data
schema: tpch_sf1000
tables:
- name: orders
```### Defining Target Name in dbt Cloud
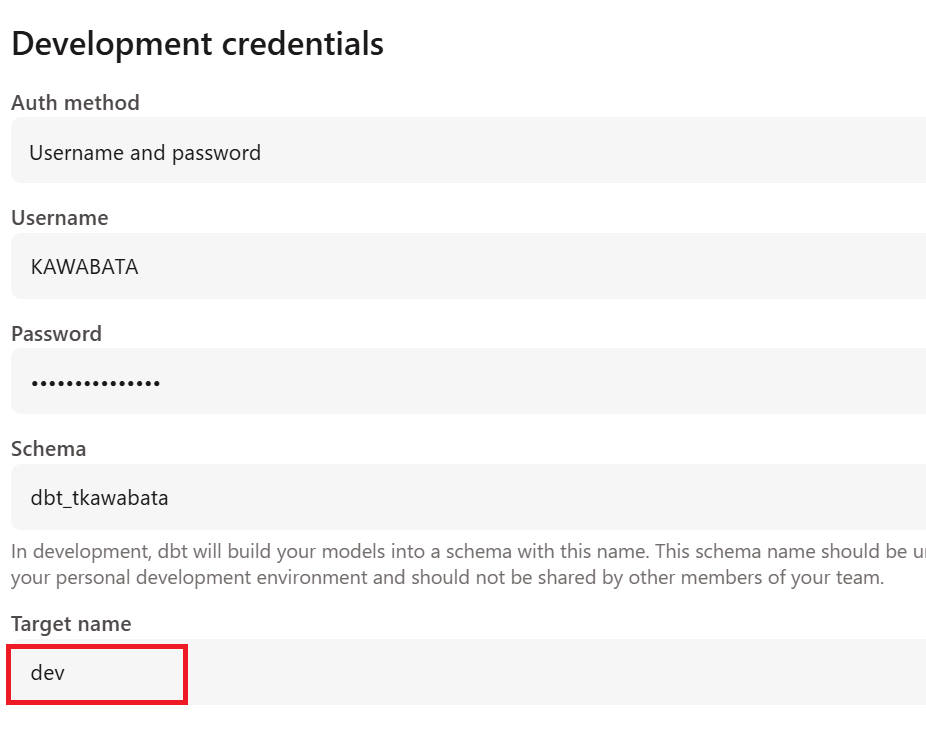
In dbt Cloud, you can set the `Target name` in `Development credentials`.
In this case, I set it to `dev` as shown below.
### Creating an SQL Model
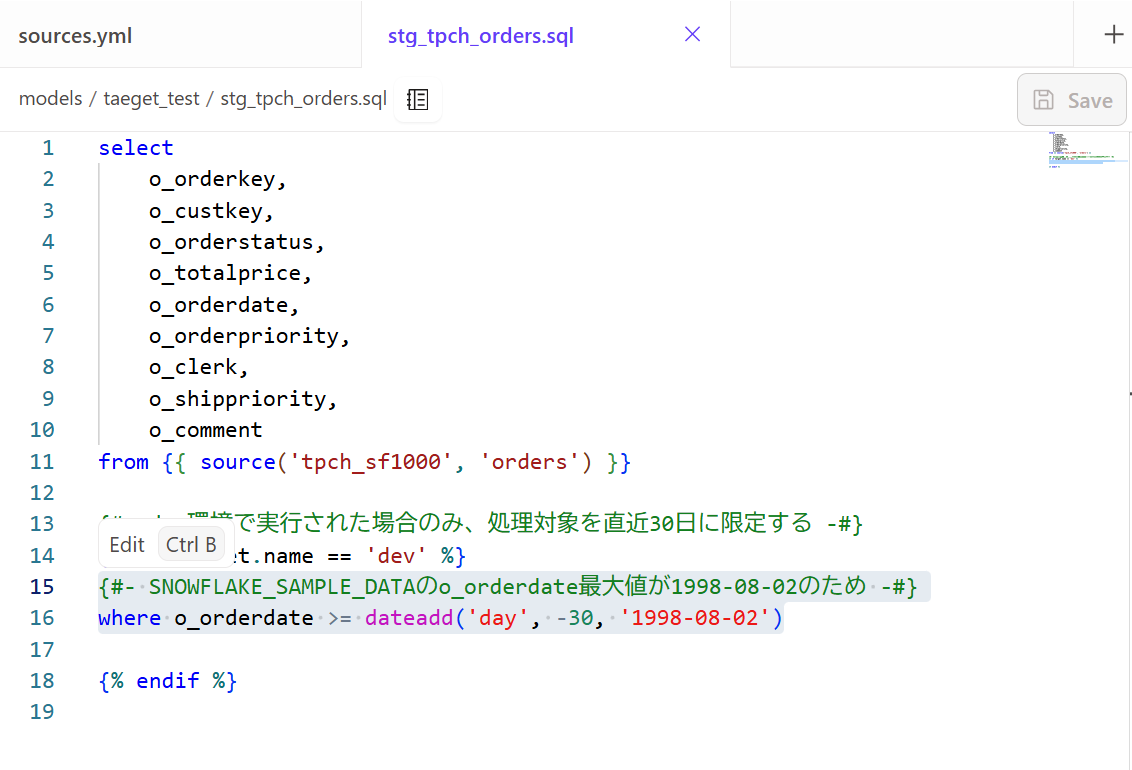
I created a new SQL file named `stg_tpch_orders.sql` and wrote the following SQL:
```sql
select
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_shippriority,
o_comment
from {{ source('tpch_sf1000', 'orders') }}
{#- Only limit processing to the last 30 days when run in dev environment -#}
{% if target.name == 'dev' %}
where o_orderdate >= dateadd('day', -30, '1998-08-02')
{% endif %}
{#- Max o_orderdate value in SNOWFLAKE_SAMPLE_DATA is 1998-08-02 -#}
-- Retrieving 30 days of data
Execution and Performance Check
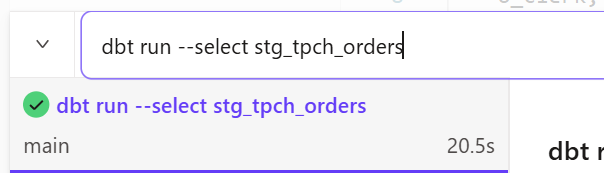
Now I'll run the model we just created in the development environment.
-- Run only the stg_tpch_orders model we just created
dbt run --select stg_tpch_orders
We stored the results in a table, and checking the results shows it took about 20 seconds.
I also checked the Snowflake side.
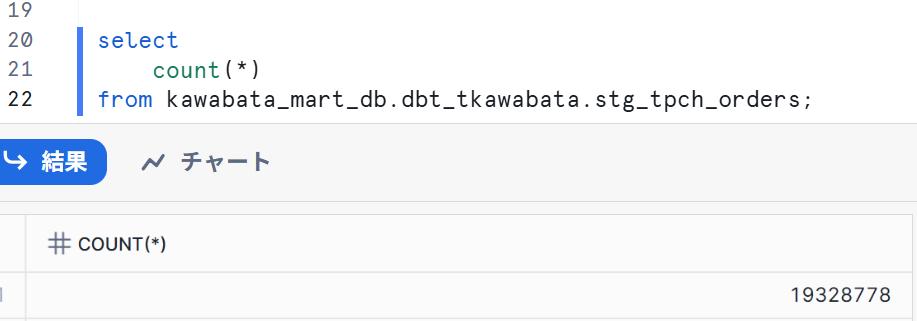
Since it's data for 30 days, it behaved as expected.
Let's also try it in the production environment.
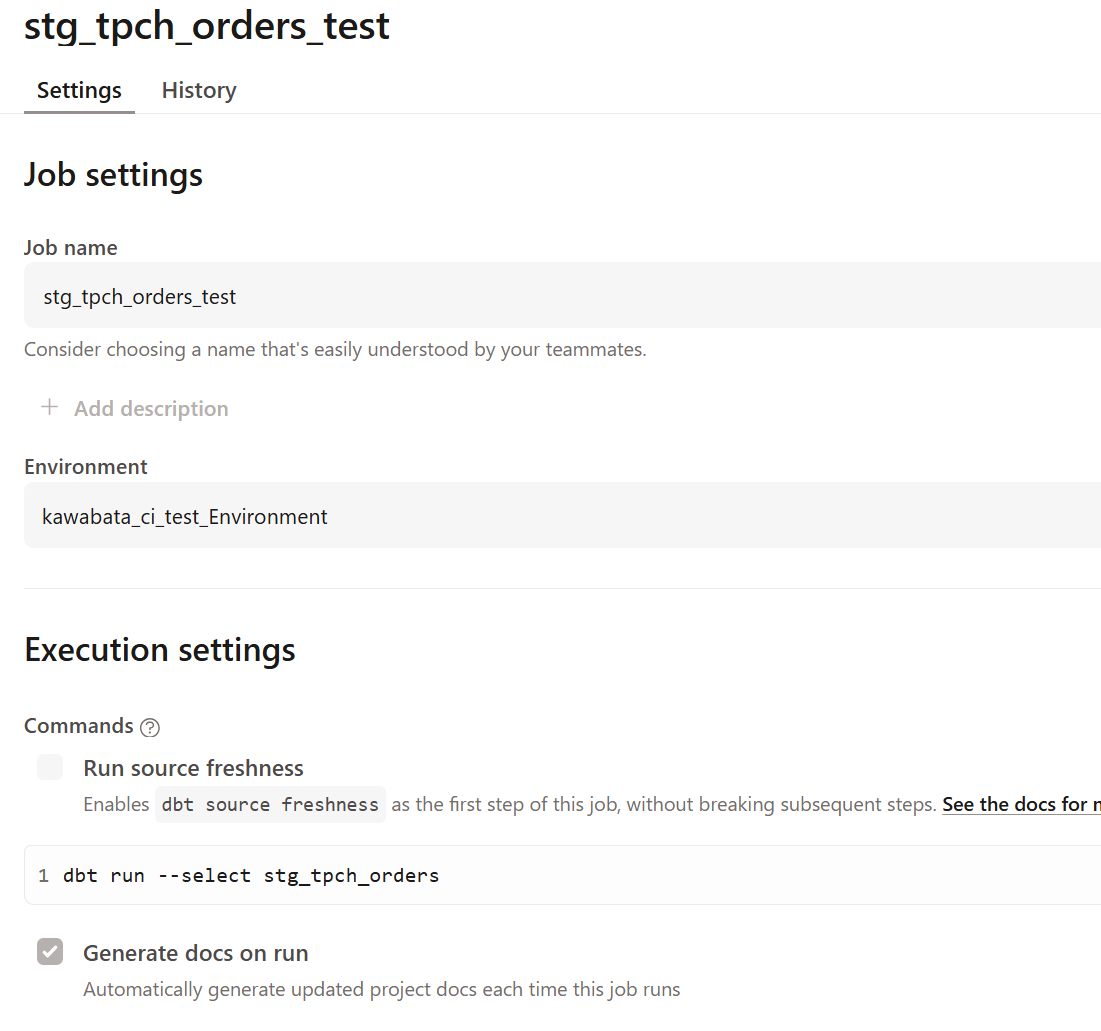
I created and ran a new job as shown below.
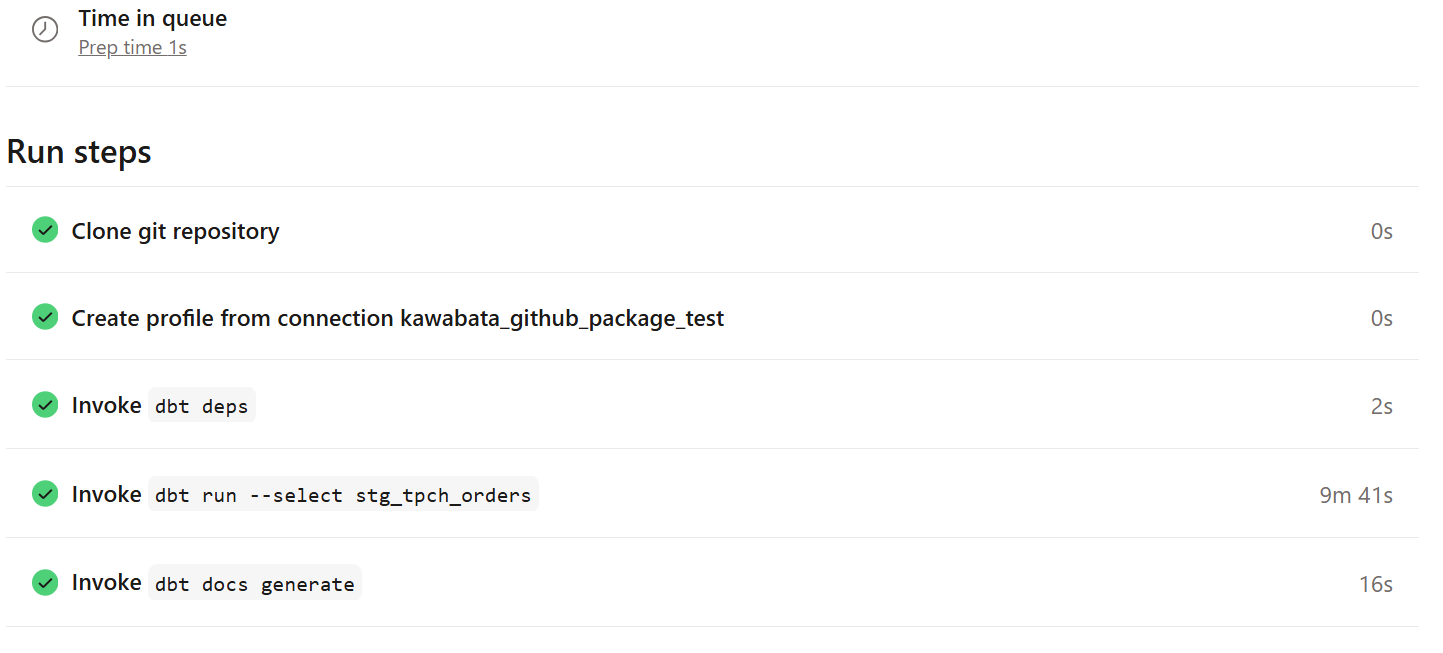
The processing time took about 10 minutes.
I also checked the Snowflake side, and it looked like this:
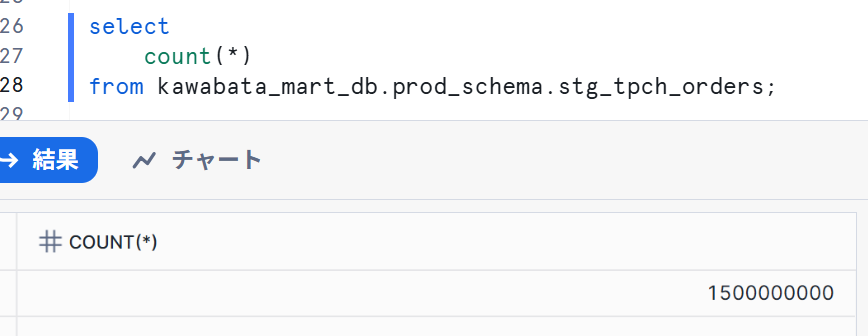
As expected, I was able to change the query that runs in development and production environments.
This approach can be useful when dealing with large amounts of data that can be filtered by date!
Testing Dynamic Source Changes
Previously we did this at the query level, but now I'll test a method to dynamically specify which source to read from when production and development environments are separated in the data warehouse.### Environment Preparation
We will store the previously created 30-day data in DEV_RAW_DB and the data executed in the production environment in PRD_RAW_DB.
-- Create test databases
CREATE DATABASE IF NOT EXISTS PRD_RAW_DB;
CREATE DATABASE IF NOT EXISTS DEV_RAW_DB;
-- Create schemas in the databases
CREATE SCHEMA IF NOT EXISTS PRD_RAW_DB.CONFIRM;
CREATE SCHEMA IF NOT EXISTS DEV_RAW_DB.CONFIRM;
-- 6 years of data to production environment
CREATE TRANSIENT TABLE PRD_RAW_DB.CONFIRM.STG_TPCH_ORDERS
CLONE KAWABATA_MART_DB.PROD_SCHEMA.STG_TPCH_ORDERS;
-- 30 days of data to development environment
CREATE TRANSIENT TABLE DEV_RAW_DB.CONFIRM.STG_TPCH_ORDERS
CLONE KAWABATA_MART_DB.DBT_TKAWABATA.STG_TPCH_ORDERS;
Define sources in dbt Cloud
Create a sources.yml file in the models directory of your dbt project and define the data sources as follows.
As mentioned earlier, we defined Target name as dev in Development credentials.
Also, we defined Target name as prod in the Deploy Job settings screen.
*The job configuration screen will be described later.
version: 2
sources:
- name: Environment_switching_test
database: |
{%- if target.name == 'prod' -%}
prd_raw_db
{%- else -%}
dev_raw_db
{%- endif -%}
schema: confirm
tables:
- name: STG_TPCH_ORDERS
```### Creating the Model
I created a `test_orders` model as follows:
```sql
select
o_orderkey,
o_custkey,
o_orderstatus,
o_totalprice,
o_orderdate,
o_orderpriority,
o_clerk,
o_shippriority,
o_comment
from {{ source('Environment_switching_test', 'STG_TPCH_ORDERS') }}
I executed it with the following command:
dbt run --select test_orders
When checking the Snowflake interface, I confirmed that data was being loaded from DEV_RAW_DB's STG_TPCH_ORDERS.
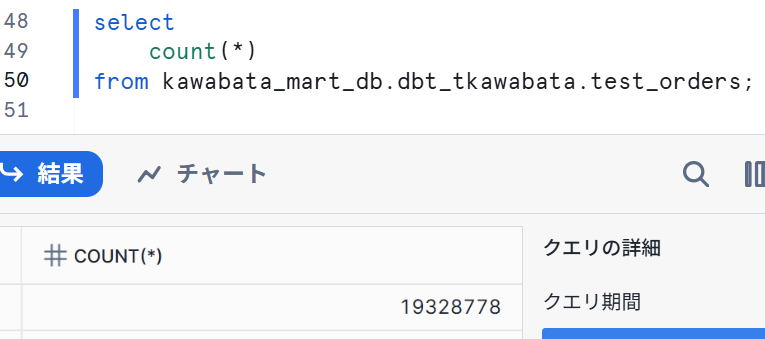
Let's check the production environment as well. I set up the job as follows, specifying prod in the Target name under Advanced settings.
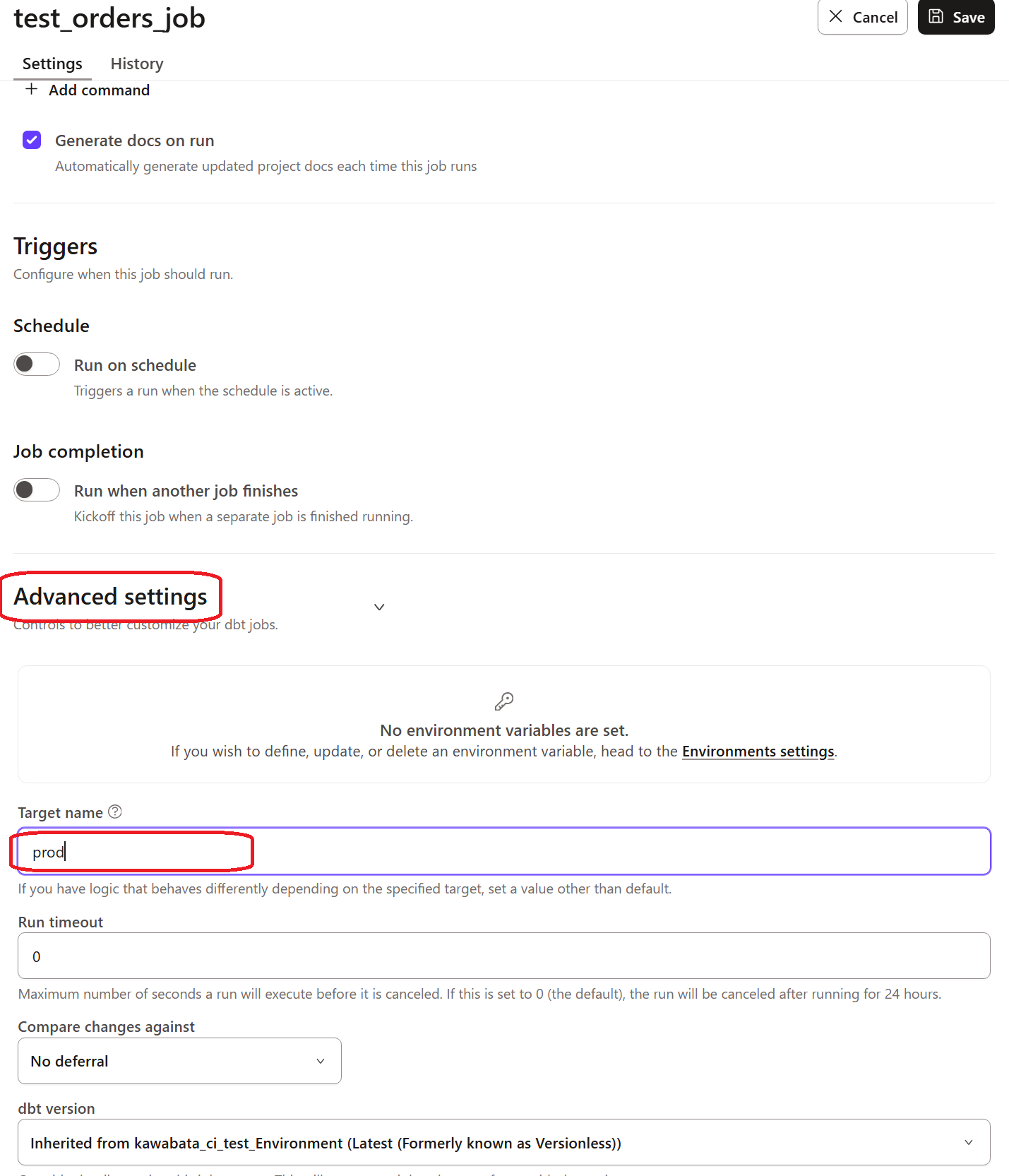
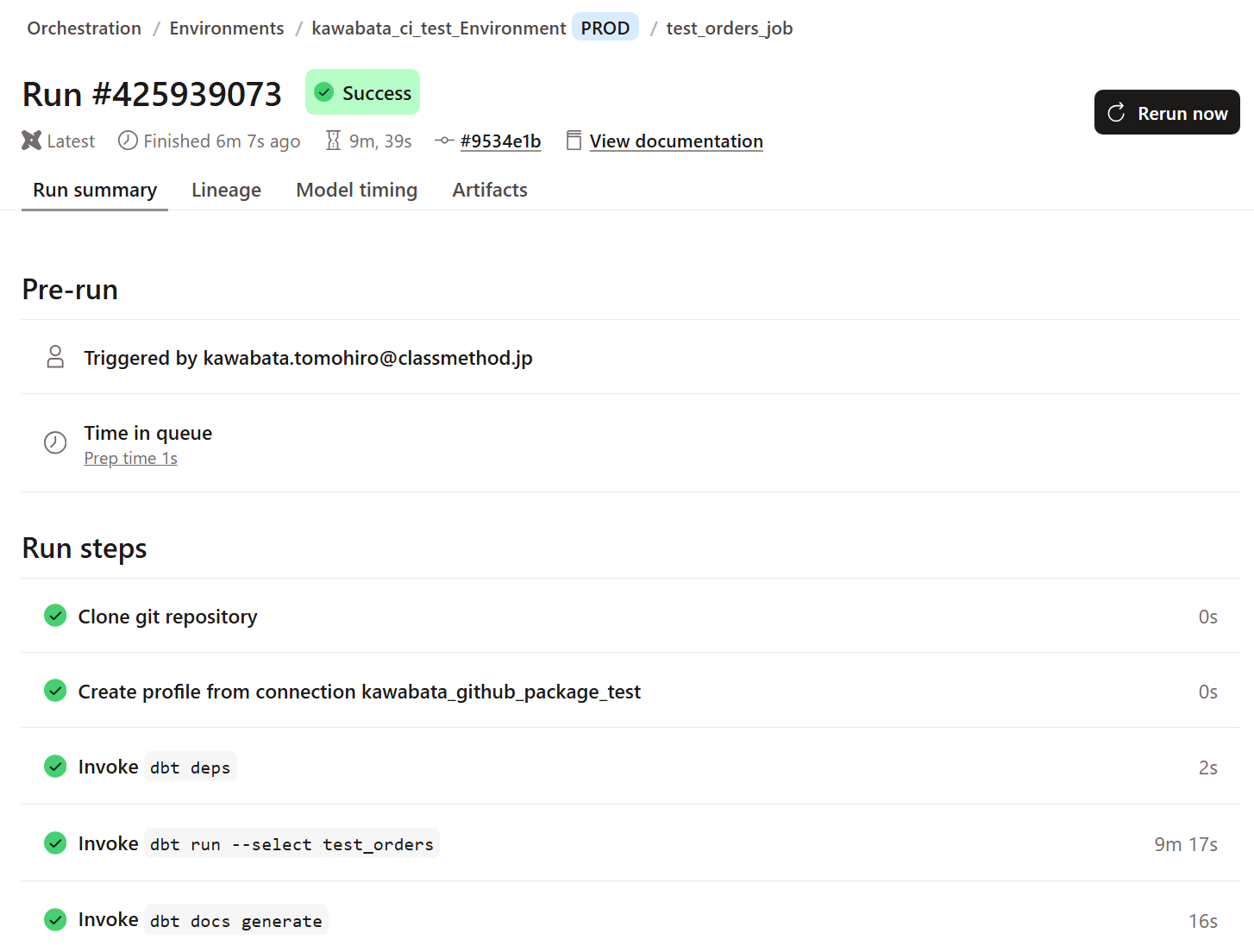
After execution, I noticed the runtime increased, suggesting it's working as expected.
I also confirmed in Snowflake, and it looked like this:
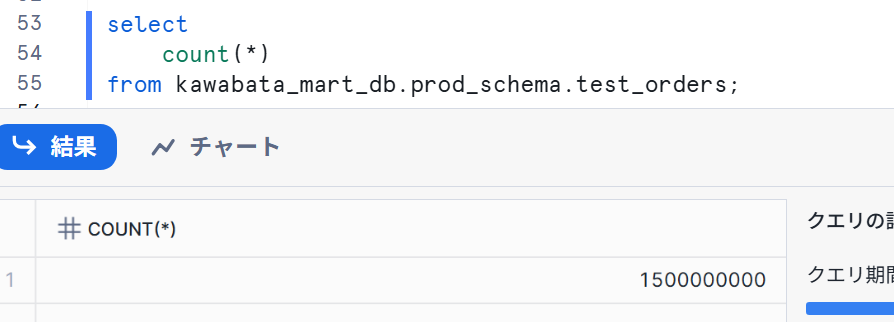
This demonstrates how we can dynamically change the source based on the environment!
Summary
After trying these two patterns, which one should be used depends on the situation.
I asked an AI to organize the considerations as follows:
| Consideration | When Dynamic WHERE Clause is Suitable | When Dynamic Source Selection is Suitable |
|---|---|---|
| Top Priority | Development speed and cost efficiency | Security and strict environment separation |
| Data Access | When developers can have read access to production data | When developers should have no access to production data (e.g., contains PII or confidential information) |
| Dataset | When the source is huge and creating a copy for development is difficult or costly | When mechanisms are in place to easily prepare development datasets (e.g., Snowflake zero-copy clone) |
| Testing Requirements | When most test cases can be covered with recent data | When testing with specific historical data or deliberately created data is essential |
| Team Maturity | When wanting to implement dbt quickly or maintain a simple configuration | When data governance is established and operational processes for environment management can be built |
Conclusion
How was this approach?
I tried two patterns for changing the source based on environment, but each has different characteristics that should be selected according to your situation.
I hope this article can be of some reference to you!
![[新機能]dbt CloudでホストされたRemote MCP Serverがパブリックベータとしてリリースされました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-f846b6052d1f7b983172226c6b1ed44b/6b4729aabfb5b7a3359acc27dc6b5453/dbt-1200x630-1.jpg)
