
Amazon Bedrock Evaluations入門:関連性とカバレッジから始めるRAG検索の精度評価

はじめに
RAG(Retrieval Augmented Generation)システムを導入する際に、重要でありながら難しいのが検索精度の評価です。
2025年3月に一般提供されたAmazon Bedrock Evaluationsを使うと、RAGを汎用的かつシステマティックに評価できます。
本記事では、Amazon Bedrock Evaluationsを用い、RAGの検索フェーズに特化し、 「関連性」と「カバレッジ」から検索精度を評価 する方法を紹介します。
狙いは2つあります。
RAGの検索フェーズの重要性を考慮
RAGは名前の通り、検索(Retrieval)のあとで生成(Generation)を行います。
関連性の低い文書を検索していては、期待するような生成結果は得られません。
最初の検索フェーズの精度は非常に重要なため、その評価も然りです。
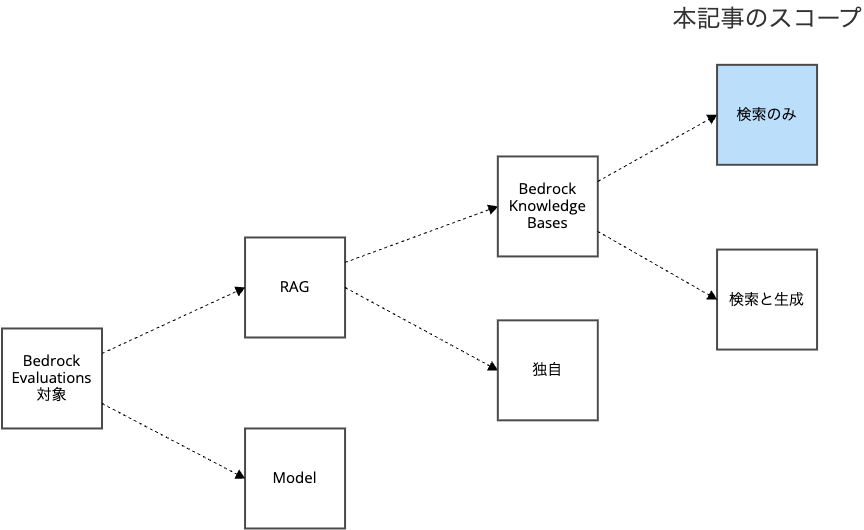
汎用的で高機能なAmazon Bedrock Evaluationsをシンプルに始める
Amazon Bedrock Evaluationsは、汎用的で高機能です。
RAGだけでなくLLMモデルの評価もでき、Bedrock Knowledge Bases以外のRAG一般も評価できます。
RAGに限定しても、検索だけの評価は2軸(メトリクス)、検索から生成までの評価は10軸(メトリクス)と情報量が多いです。
RAGの検索フェーズに限定して評価することで、覚える手順も確認すべきメトリクスも大幅に減るため、導入の敷居が下がります。
システム構成について
今回は、RAGシステムとしてS3 VectorsをBedrock Knowledge Basesと連携して利用します。
2025年7月にプレビュー公開されたばかりの機能であり、リージョン制限がある、ベクトル検索しかできない、といった制約もありますが、今回のようにBedrock Evaluationsを手を動かしながら覚えるという意味では、OpenSearchやPostgreSQLと比べて利用費を大幅に抑えられます。
今回はプレビュー中の S3 Vectorsを利用するため、 バージニア北部リージョン を利用します。
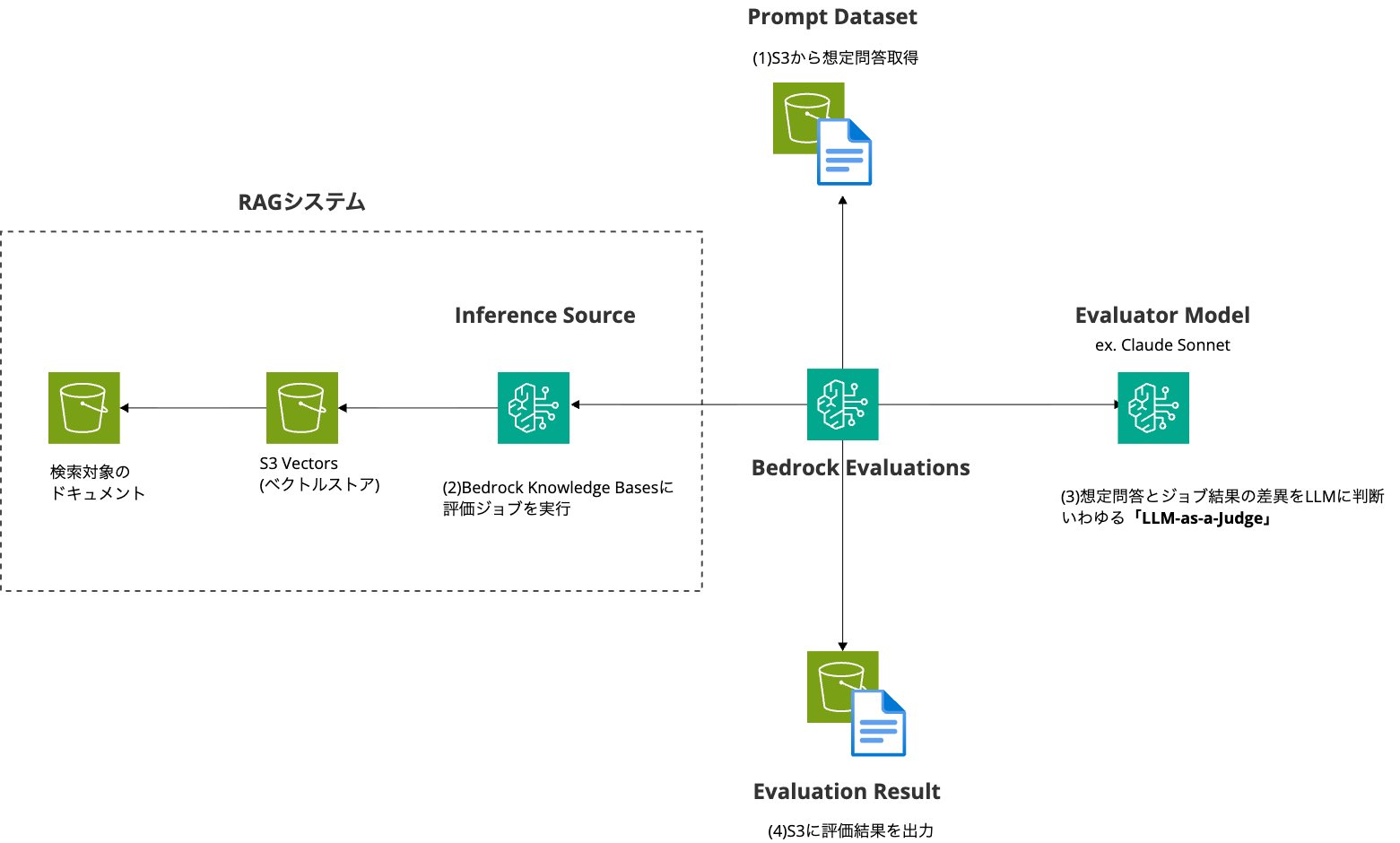
作業の流れ
- 検索ドキュメント管理用S3バケットの作成
- 検索精度評価用データ管理用S3バケットの作成
- RAG(Bedrock Knowledge BasesとS3 Vectors)の作成
- 検索対象のデータの投入
- 検索精度評価用のデータ(プロンプトデータセット)の投入
- 評価ジョブの実行
- 評価ジョブレポートの確認
- 評価ジョブの再実行
利用するサービスの制限から「バージニア北部」リージョンにリソースを作成して下さい。
1. 検索ドキュメント管理用S3バケットの作成
次のバケットを作成してください。
- 検索ドキュメント管理用S3バケット
本記事末尾にある、S3 FAQから取得した検索対象ドキュメントをアップロードして下さい。
2. 検索精度評価用データ管理用S3バケットの作成
次のバケットを作成してください。
- 検索精度評価用データ管理用S3バケット
Bedrock EvaluationsがこのS3バケットにアクセスできるように、バケットの「アクセス許可」→「Cross-Origin Resource Sharing (CORS)」から次のCORS設定を追加してください
[
{
"AllowedHeaders": [
"*"
],
"AllowedMethods": [
"GET",
"PUT",
"POST",
"DELETE"
],
"AllowedOrigins": [
"*"
],
"ExposeHeaders": [
"Access-Control-Allow-Origin"
]
}
]
CORS参考 : https://docs.aws.amazon.com/bedrock/latest/userguide/model-evaluation-security-cors.html
RAG(Bedrock Knowledge BasesとS3 Vectors)の作成
今回は利用費を抑えられるように、Bedrock Knowledge BasesとS3 VectorsでRAGを構築します。
Bedrockコンソールのサイドメニュー「ナレッジベース」からBedrock Knowledge Basesのサービスページに移動します。
次に「作成」ボタンの 「ベクトルストアを含むナレッジベース」 を選択し、ナレッジベース(Bedrock Knowledge Bases)とデータベース(S3 Vectors)の作成画面に移動します。

ステップ1「ナレッジベースの詳細を指定」
デフォルトのままで大丈夫です。
「データソースを選択」で「Amazon S3」が選択されていることを確認してください。
ステップ2「データソースを設定」
データソースの場所に作成した 検索ドキュメント管理用S3バケット を指定してください。
ステップ 3「データストレージと処理を設定」
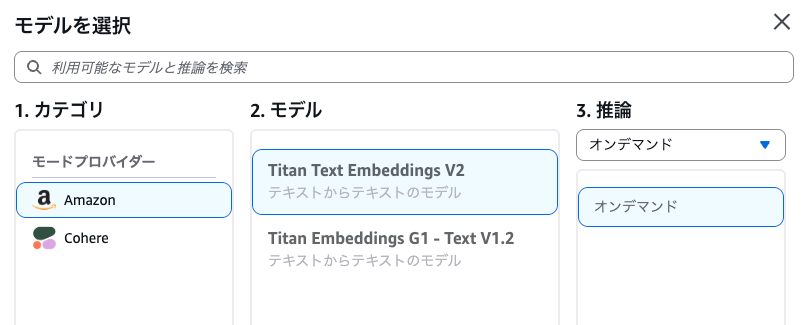
「埋め込みモデル」
- Amazonの「Titan Text Embeddings V2」を指定
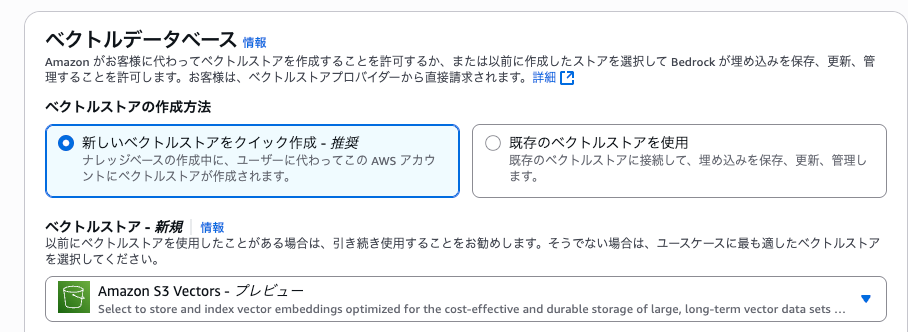
「ベクトルデータベース」
- 「新しいベクトルストアをクイック作成」をチェック
- 「ベクトルストア」に「Amazon S3 Vectors」を指定
検索ドキュメントを同期
ナレッジ検索できるように、Bedrock Knowledge Baseの「データソース」エリアから、「データソース」をチェックして 「同期」 ボタンをクリックします。
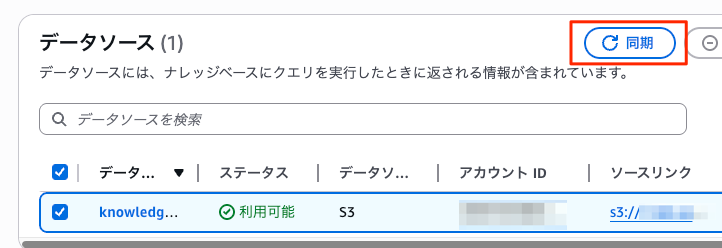
データソースをクリックし、同期履歴から、同期が成功し、登録したドキュメントが追加されていることを確認してください。
ナレッジベースをテスト
「ナレッジベースをテスト」のリンクから実際に検索してみましょう。
左ペインの「設定」で「取得のみ: データソース」を選択し、右ペインの質問欄で「Amazon S3 イベント通知とは?」を入力しましょう。
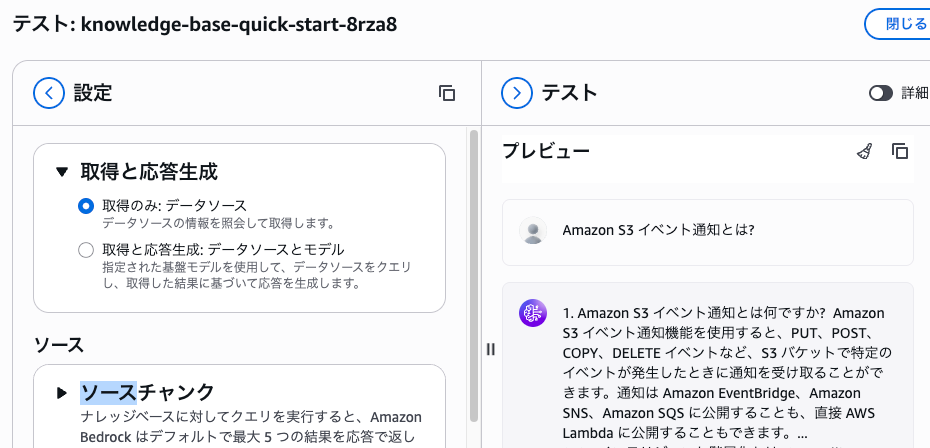
期待通りのドキュメントが検索できていますか?
今回は 生成(generate) ではなく 取得(retrieve) のみを行っているので、データソースにあるマッチしたテキスト範囲(チャンク)がそのまま表示されます。
1. 検索精度評価用のデータ(プロンプトデータセット)の投入
検索精度の評価にあたり、評価用のデータ(プロンプトデータセット)を用意します。
このデータは次の2項目を用意します
prompt: RAGシステムへの質問referenceResponses: RAG の検索結果に含まれるべき正解(グラウントゥルース)です。カバレッジに利用するため、参照してほしいチャンク(ドキュメントの該当部分)をそのまま記載するのではなく、検索結果に含まれるべき「正解」を網羅的に記載します。
この2つのデータを JSONL形式 で記述します。
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Provide the prompt you want to use during inference"}]},"referenceResponses":[{"content":[{"text":"Specify a ground-truth response"}]}]}]}
1行に圧縮されているので、見やすくしたのが次のものです。
{
"conversationTurns": [
{
"prompt": {
"content": [
{
"text": "What is the recommended service interval for your product?"
}
]
},
"referenceResponses": [
{
"content": [
{
"text": "The recommended service interval for our product is two years."
}
]
}
]
}
]
}
今回は、次のような プロンプトデータセット を用意しました。
{"conversationTurns":[{"prompt":{"content":[{"text":"Amazon S3 にはどれくらいの量のデータを保存できますか?"}]},"referenceResponses":[{"content":[{"text":"データの総量とオブジェクト数に制限はありません。個別のオブジェクトサイズは最大5TBです。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Amazon S3 はどの程度信頼できますか?"}]},"referenceResponses":[{"content":[{"text":"S3 Standardは99.99%のアベイラビリティーで設計されており、ストレージクラスによって99.5%から99.99%のアベイラビリティーを提供します。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Amazon S3 イベント通知とは何ですか?"}]},"referenceResponses":[{"content":[{"text":"S3バケットでPUT、POST、COPY、DELETEなどの特定イベントが発生した際に、EventBridge、SNS、SQS、Lambdaへ通知を送信できる機能です。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"S3 インテリジェント階層化とは"}]},"referenceResponses":[{"content":[{"text":"アクセス頻度に基づいてデータを自動的に最も費用効果の高いアクセス階層に移動し、ストレージコストを削減するストレージクラスです。"}]}]}]}
{"conversationTurns":[{"prompt":{"content":[{"text":"Amazon S3 の耐久性はどれくらいですか?"}]},"referenceResponses":[{"content":[{"text":"99.999999999%(イレブンナイン)のデータ耐久性を実現し、デフォルトで最低3つのAZにデータを冗長保存します。"}]}]}]}
検索精度評価用データ管理用S3バケットに投入してください。
検索評価ジョブの実行
Bedrock Evaluations で検索評価ジョブを実行します。
AWSコンソールのBedrockのサイドメニューから「評価」→「評価」とたどり、タブメニューで「Models」ではなく「RAG」を選択します。
「Create」ボタンから評価ジョブを作成します
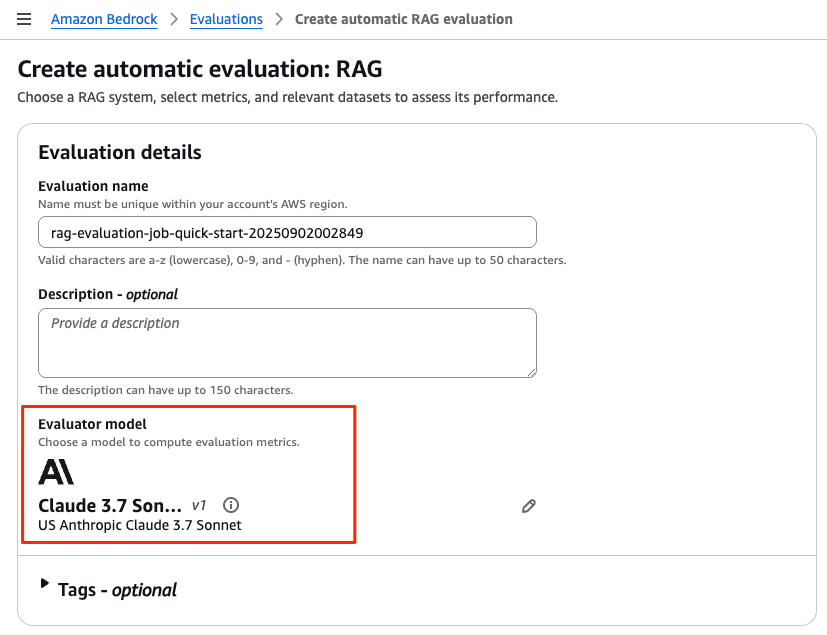
Evaluation detailsでLLM-as-a-judgeのモデルを選択
Bedrock Evaluations の最大の特徴は、評価を LLMが行うことであり、一般に 「LLM-as-a-judge」 と呼ばれます。
この評価に利用するモデルを Evaluator model と呼び、「モデルを選択」からAnthropicのClaude Sonnetなど、お気に入りのモデルを指定してください。
RAGシステムの指定
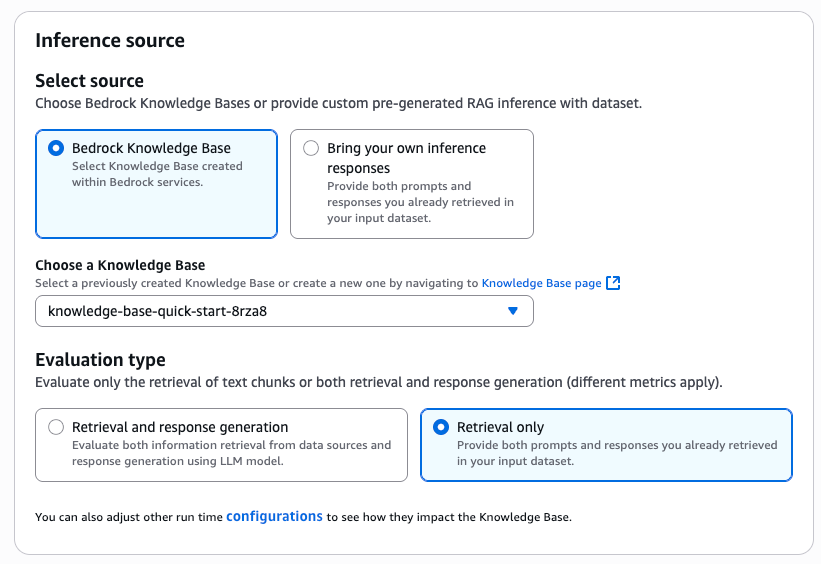
「Inference source」エリアでは、評価対象のRAGシステムを指定します。
「Bedrock Knowledge Base」 をチェックし、 「Choose a Knowledge Base」 のプルダウンから先ほど作成した S3 Vectors のリソースを指定してください。
評価対象が検索だけなのか生成も含めるのか指定
Bedrock EvaluationsはRAGの以下のどちらの評価も可能です
- 検索のみ:Retrieval only
- 検索と生成:Retrieval and response generation
今回は、シンプルに 「検索のみ(Retrieval only)」 を選択します。
評価メトリクスを指定
評価タイプは
- 検索のみ
- 検索と生成
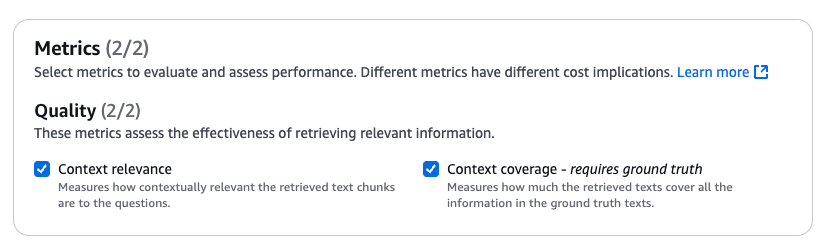
で異なります。今回は検索のみのため、次の2メトリクスを利用できます。どちらもチェックしましょう。
- Context relevance
- Context coverage
これらのメトリクスの意味は後述します。
データセットと評価レポートの指定
「Dataset and evaluation results S3 location」セクションから以下を指定します。
- 評価用データセットをアップロードしたパス(Dataset for evaluation)
- 評価結果の出力先S3プリフィックス(Results for evaluation)
評価メトリクス
評価タイプ(検索のみか生成も含めるのか)によって評価メトリクスも異なります。
検索のみのメトリクス は Context relevance と Context coverage のわずか2つです。
情報検索(Information Retrieval)の世界では、検索性を評価する精度(precision:質問に適合しないドキュメントをどれだけ避けられたか)と再現率(recall:質問に適合するドキュメントをどれだけ網羅できたか) という2大指標が存在します。
RelevanceとCoverageはIRの世界のPrecisionとRecallのRAG版とみなすと理解しやすいと思います。
PrecisionとRecallの詳細は、次のリンクから学びましょう。
コンテキストの関連性(Context relevance)
取得した情報が、質問の文脈にどれだけ関連しているかを示す指標です。
この指標は、取得したテキストが質問と直接関係ない、あるいは質問の文脈や意図を汲み取れていない、といった問題を特定するために不可欠です。
スコアが低い場合は、これらの関連性に課題があることを示唆します。
コンテキストの網羅性(Context coverage)
取得した情報が、あらかじめ用意した正解データ(ground truth)をどれだけ網羅できているかを示す指標です。
この指標は、取得したテキストが、質問に対して本来提供すべき情報を十分にカバーできていない、という問題を特定するために不可欠です。
スコアが低い場合は、情報の網羅性に課題があることを示唆します。
評価ジョブレポートの確認
評価ジョブは 非同期 に実行されます。
情報量が多いため、重要なポイントをかいつまんで紹介します。
なお、2025/09/10 時点では、 評価レポートはすべて英語 です。
概要を把握
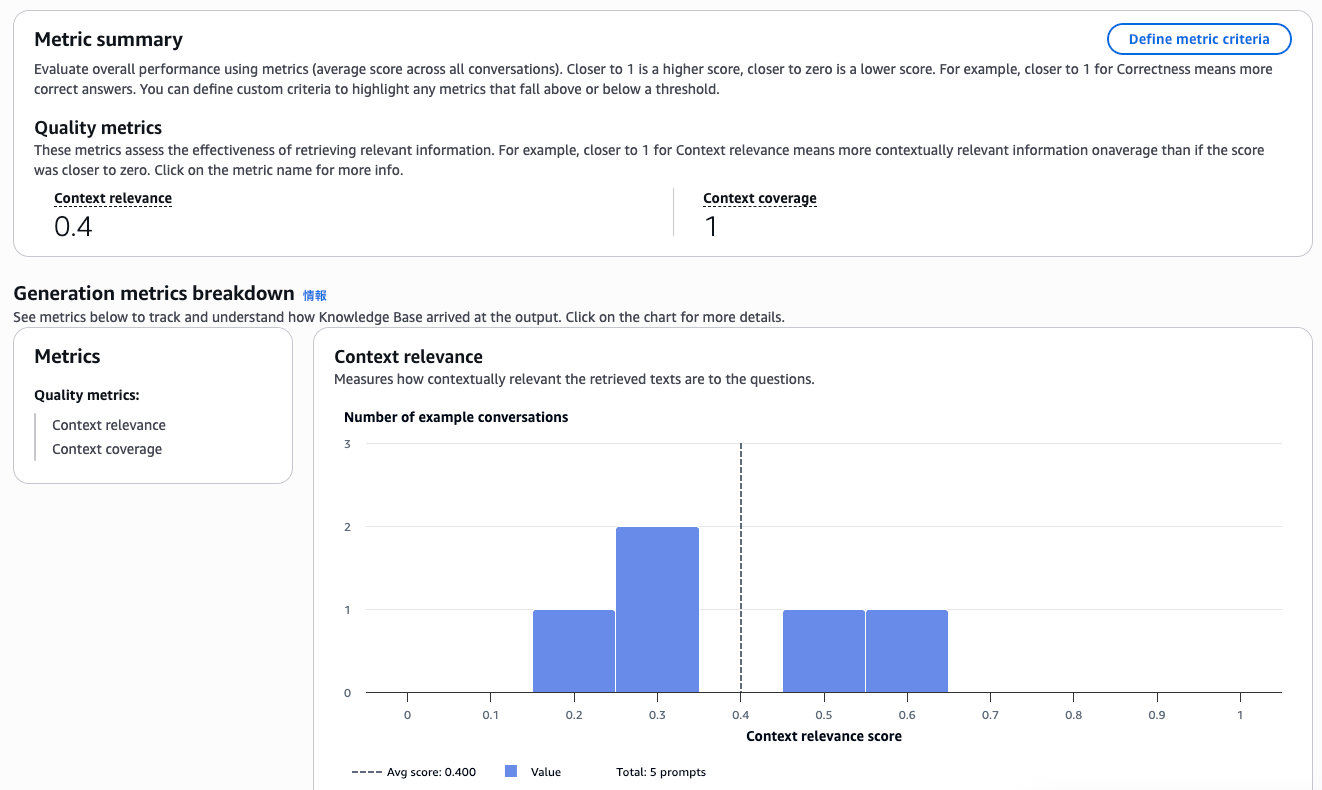
メトリックサマリーページで、次のメトリクスが0(品質が低い)から1(品質が高い)でスコアリングされます。
- コンテキストの関連性(Context relevance)
- コンテキストの網羅性(Context coverage)
高いスコアを目指してRAGのパラメーターやデータソースを改善しましょう。
メトリックをブレイクダウン
スコアが想定より低かった場合、原因の調査が必要です。
スコアが 0.4 だった コンテキストの関連性(Context relevance) をブレイクダウンしてみましょう。
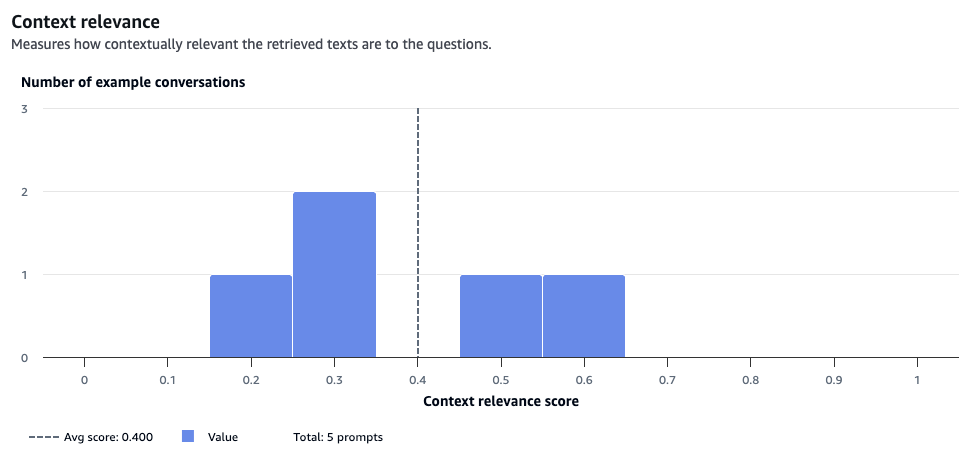
5件のプロンプトデータセットは 0.4 前後に分布しています。
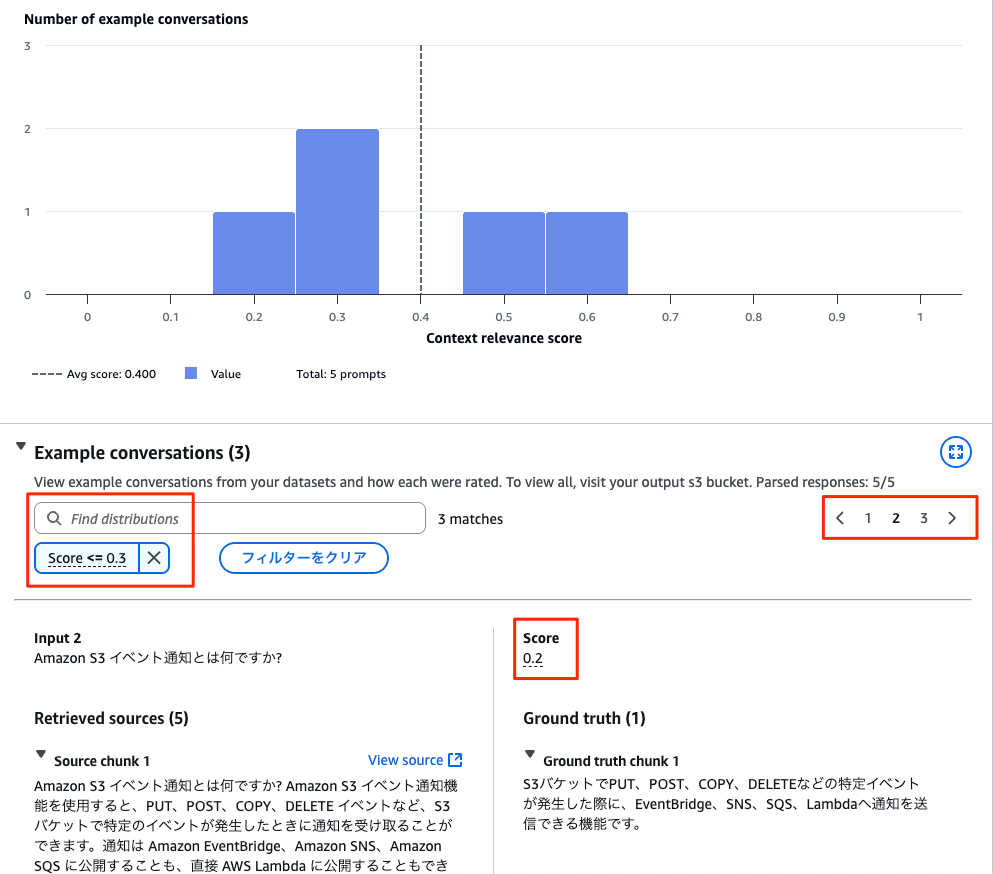
ヒストグラム下の「Example conversations」のエリアで、評価結果を確認できます。
検索ボックス("Find distributions")に「 Score <= 0.3」と入力し、評価の悪かった検索だけをフィルターします。
関連性が 0.2 と一番悪かった検索を確認すると、「Amazon S3 イベント通知とは何ですか?」という質問だったことがわかります。
スコアをクリックすると、ポップアップ画面でその評価を確認できます。
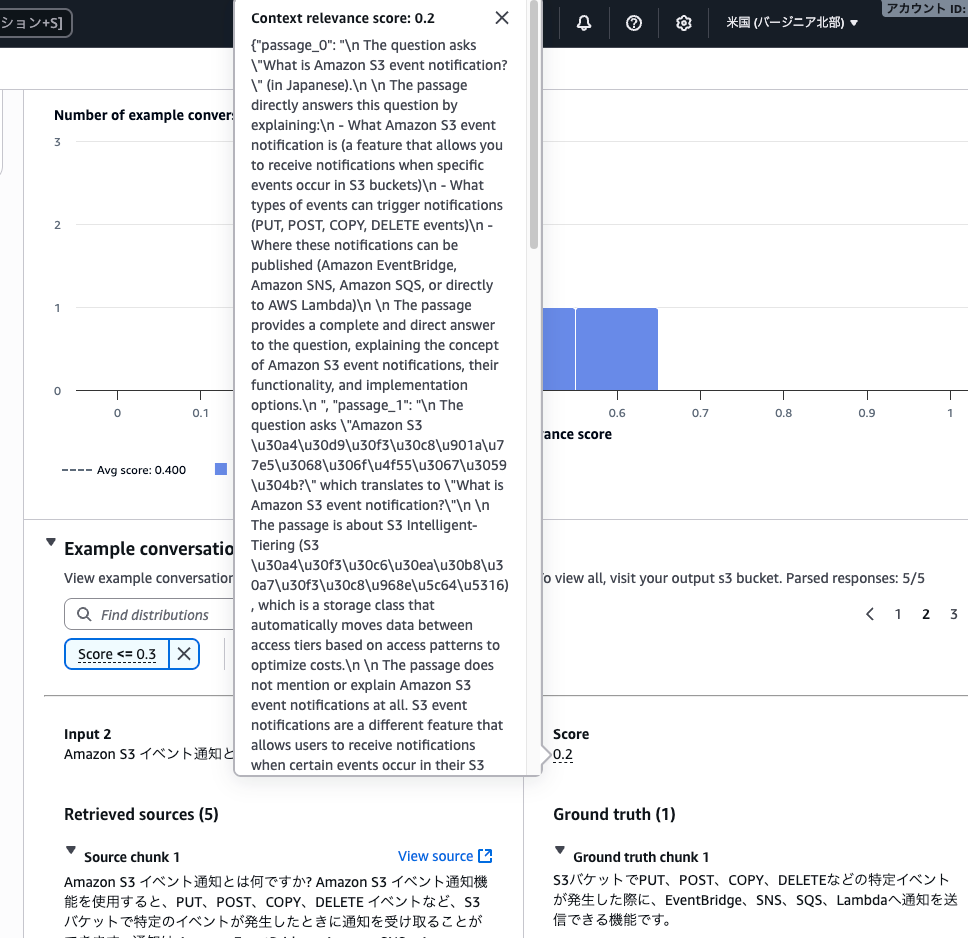
評価コメントによると、「Amazon S3 イベント通知とは何ですか?」という検索結果が5件あったが、そのうち4件がS3のイベント通知と関係ないというものでした。
今回の検証では、RAGに1チャンクで収まる文章量の5ドキュメントのみを登録し、検索ではデフォルトで5チャンク、つまり、すべてのドキュメントを返却しています。登録した5件のドキュメントは、S3という共通点はあるものの、それぞれ異なるトピックを扱っています。
そのため、全般的に網羅性は高いものの、関連性が低いという評価になっています。
検索パラメーターを変えて検索評価ジョブを再実行
検索ドキュメント数と検索チャンク数が一致していることが、関連性のメトリクスに悪い評価を与えているため、チャンク数を2に変えてジョブを再実行してみましょう。
ジョブ作成画面の「Inference source」エリアに 「configurations」というリンク があります。
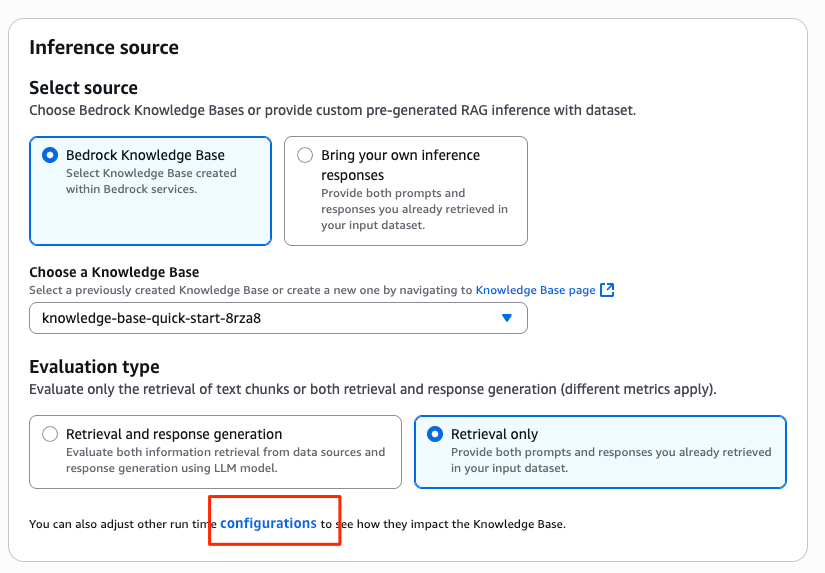
単なるリンクに見えて、Bedrock Knowledge Basesに検索する際のパラメーターを指定する、非常に重要な設定画面です。
設定項目の 最大ソースチャンク数(Source chunks) を 2 に変更 しましょう。
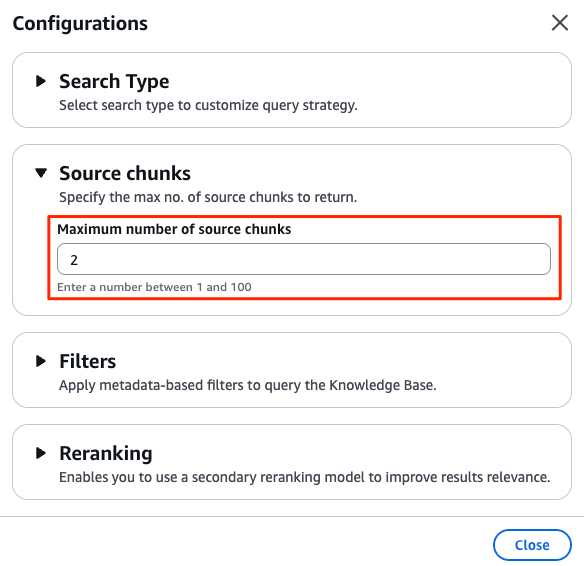
残りの設定は、前回と一緒で問題ありません。
この設定で再度ジョブを実行してレポートを確認すると、 Context relevanceのスコアが 0.4 から 0.75 に大きく改善 しました。
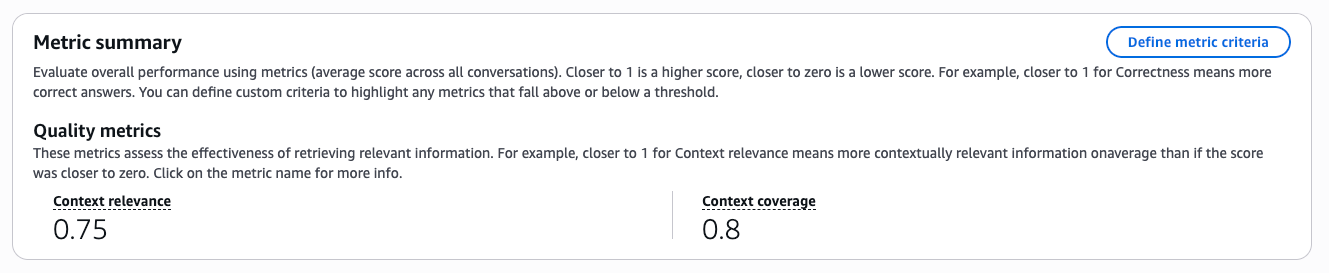
内訳は以下です
- 0.5が2件
- 0.75が1件
- 1.0 が2件
関連性の最低スコアの0.5は2件で発生しており、その片方は前回ワーストだった「Amazon S3 イベント通知とは何ですか?」です。
スコアをクリックし、その理由を確認してみましょう。
passage_0とpassage_1の2チャンク(ドキュメント)を取得passage_0は 質問に直接的に回答しているため 関連性あり- "The passage directly answers this question by explaining..."
passage_1は S3 Intelligent-Tiering についてのチャンク(ドキュメント)で関連性なし- "The passage explains how S3 Intelligent-Tiering works... However, the passage does not contain any information about S3 event notifications..."
1件だけあった 関連性スコア 0.75 は「Amazon S3 の耐久性はどれくらいですか?」に関する検索であり、同様に理由を確認すると、以下の通りでした。
passage_0とpassage_1の2チャンク(ドキュメント)を取得passage_0は 質問に直接的に回答しているため 関連性あり- "The passage directly answers this question by stating.."
passage_1は 「耐久性」ではなく「信頼性」についてのチャンク(ドキュメント)で関連はするけれども、直接的ではないということで Maybe として加点扱い- "Since the passage is about Amazon S3 and its reliability features but doesn't specifically address the durability metrics requested in the question, I would rate this as "Maybe" - it's related to the topic but doesn't directly provide the specific information asked for."
評価ジョブ間の比較分析
ジョブを複数選んで「Compare」を実行すると、ジョブ間で 評価メトリクスを比較できます。
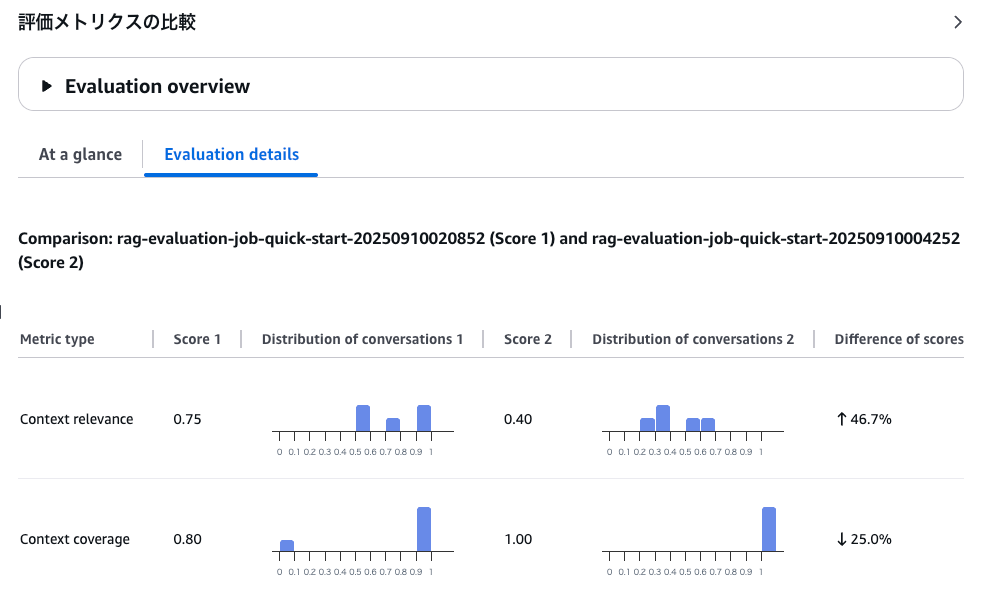
一貫した手法・メトリクスで評価することで、イテレーションの差分を評価しましょう。
まとめ
本記事では、Amazon Bedrock Evaluationsを使ってRAGの検索精度を評価する方法を解説しました。
Amazon Bedrock Evaluations は汎用的で高機能ですが、まずはRAGの検索フェーズに限定すると導入すると、覚える操作が少なくて済み、評価メトリクスも2個だけなので理解も容易です。
慣れてきたら、評価用データ(プロンプトデータ)を増やしたり、「検索と生成」フェーズの評価も検討しましょう。後者は設定項目が増え、評価メトリクスも10個と複雑さが増します。
詳細は次の記事をご確認ください
参考
付録:検索対象のデータ
以下はAmazon S3のFAQから引用した文章です。
01.txt
Amazon S3 にはどれくらいの量のデータを保存できますか?
Amazon S3 に格納可能なデータの総量とオブジェクトの数には制限はありません。個別の Amazon S3 オブジェクトのサイズは、最低 0 バイトから最大 5 TB までさまざまです。1 つの PUT にアップロード可能なオブジェクトの最大サイズは 5 GB です。100 MB を超えるオブジェクトの場合は、マルチパートアップロード機能を使うことをお考えください。
02.txt
Amazon S3 はどの程度信頼できますか?
Amazon S3 によって、高度にスケーラブルで可用性も高く、かつ高速で安価なデータストレージインフラストラクチャを利用できるようになります。このインフラストラクチャは、Amazon が使用しているウェブサイトのグローバルネットワークと同じものです。S3 Standard ストレージクラスは 99.99% のアベイラビリティー、S3 標準 – IA ストレージクラス、S3 Intelligent-Tiering ストレージクラスおよび S3 Glacier Instant Retrieval ストレージクラスは 99.9% のアベイラビリティー、S3 1 ゾーン – IA ストレージクラスは 99.5% のアベイラビリティー、S3 Glacier Flexible Retrieval および S3 Glacier Deep Archive クラスは 99.99% のアベイラビリティーおよび 99.9% の SLA に設計されています。これらのストレージクラスはすべて Amazon S3 サービスレベルアグリーメントによって裏付けられています。
03.txt
Amazon S3 イベント通知とは何ですか?
Amazon S3 イベント通知機能を使用すると、PUT、POST、COPY、DELETE イベントなど、S3 バケットで特定のイベントが発生したときに通知を受け取ることができます。通知は Amazon EventBridge、Amazon SNS、Amazon SQS に公開することも、直接 AWS Lambda に公開することもできます。
04.txt
S3 インテリジェント階層化とは
S3 Intelligent-Tiering は、パフォーマンスへの影響、取得費用、運用上のオーバーヘッドなしに、アクセス頻度に基づいてデータを最も費用効果の高いアクセスティアに自動的に移動することにより、きめ細かいオブジェクトレベルでストレージコストを自動的に削減できる初めてのクラウドストレージです。S3 Intelligent-Tiering は、高頻度、低頻度、およびアーカイブインスタントアクセス階層で、頻繁に、稀に、そしてめったにアクセスされないデータに対して、ミリ秒単位でのレイテンシーと高スループットのパフォーマンスを提供します。オブジェクトモニタリングとオートメーションに対する少額の月額料金で、S3 Intelligent-Tiering はアクセスパターンをモニタリングし、オブジェクトをある階層から別の階層へ自動的に移動させることができます。S3 Intelligent-Tiering では取得に料金はかからないため、アクセスパターンを変更しても、ストレージの請求が予想外に増えることはありません。これで、S3 Intelligent-Tiering を、事実上すべてのワークロード、特にデータレイク、データ分析、機械学習、新しいアプリケーション、およびユーザー生成コンテンツのデフォルトのストレージクラスとして使用できます。
05.txt
Amazon S3 の耐久性はどれくらいですか?
Amazon S3 は、クラウドで最も耐久性の高いストレージを提供します。S3 は、独自のアーキテクチャに基づいて、99.999999999% (イレブンナイン) のデータ耐久性を実現できるように設計されています。さらに、S3 はデフォルトで最低 3 つのアベイラビリティーゾーン (AZ) にデータを冗長的に保存するため、広範囲に及ぶ災害に対する回復力が組み込みで備わっています。お客様は、データを 1 つの AZ に保存してストレージコストやレイテンシーを最小限に抑えたり、データセンター全体が永久に失われても回復できるように複数の AZ に保存したり、地理的な耐障害性要件を満たすために複数の AWS リージョンに保存したりできます。




