
"The Accumulation of Failures" Gave Birth to LLMs (Part 1) — From the Limits of Mathematics to the Geometry of Meaning
This page has been translated by machine translation. View original
Introduction
ChatGPT and Claude, large language models (LLMs), were not born from a goal of "let's build an LLM."
Someone trying to prove the limits of mathematics, someone trying to reduce noise on telephone lines, someone trying to fix precision bugs in machine translation——the byproducts of each solving completely different problems accumulated over 80 years to become LLMs.
This article traces "how those unintended connections came to be" in order. No prior knowledge of ML or mathematics is assumed.
The spark was Fireship's YouTube video. Inspired by its compact summary of LLM history, I wanted to dig deeper into "what problem each invention was really trying to solve," which led me to write this article.
Part One (this article) covers the birth of the computer concept, information theory, neural network training, and the technology for turning words into numbers. Part Two will follow the birth of Attention for handling context, through the Transformer, the scaling revolution of GPT-3, and the current era of alignment and efficiency.
Chapter 1 — What Does It Mean to "Compute"? — Alan Turing (1936)
The Problem He Was Trying to Solve
In the 1930s, the mathematics community harbored a dream:
"Every mathematical proposition should be decidable as 'true or false' by an algorithm."
This was called the Entscheidungsproblem (Decision Problem), proposed by the giant of mathematics, Hilbert. In short, it was the question: "Can mathematics be completely mechanized?"
British mathematician Alan Turing set out to prove whether this was actually true.
Turing's Translation: Turning a Mathematical Question into a Programming Question
Turing's brilliant insight was translating the question into a different question.
If an algorithm existed that could decide mathematical propositions, it would work like this:
Keep searching for a proof → Stop when a proof is found → Loop forever if none is found
In other words, the question "Can mathematics be mechanized?" becomes the same as the question "Can we determine whether a program will halt or loop?"
So if he could prove that the halting problem was unsolvable, he could prove that mechanizing mathematics was also impossible. That was Turing's target.
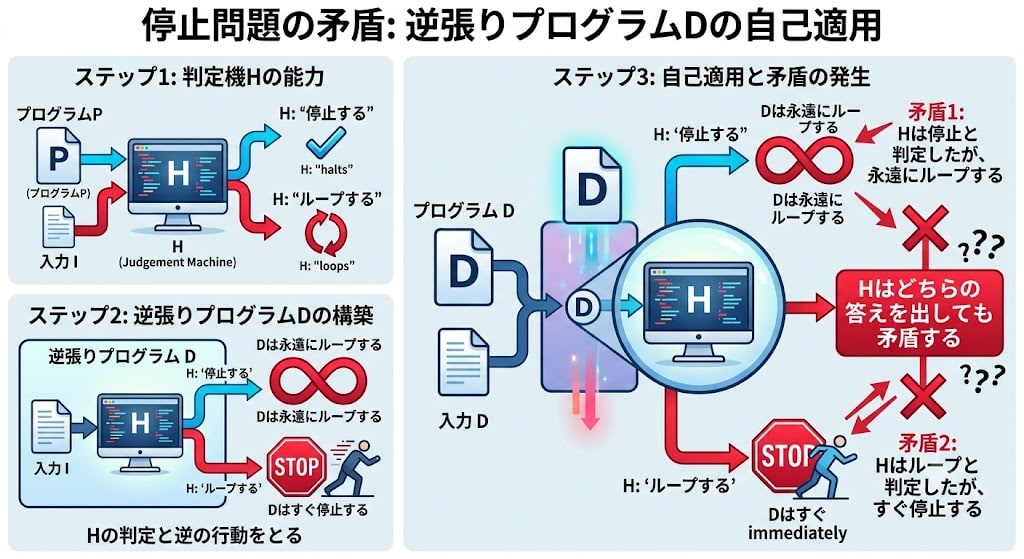
The "Halting Problem": The Contradiction Born from Self-Reference
"Can a universal program (Judge H) be built that determines whether any program will halt or loop before running it?"
The answer is No. The reason has the same structure as the "liar's paradox."
"This statement is false."
→ If true, it's false. If false, it's true. Either way, a contradiction.
The same trap can be built with Judge H:
- Use Judge H to create a "contrary program D"
- If H says "will halt" → D loops forever
- If H says "will loop" → D halts immediately
- Apply D to D itself (make it judge itself)
- Whatever answer H gives, a contradiction results
This is the same structure as "the sentence that lies." The moment it refers to itself, any answer leads to contradiction. Judge H cannot exist in principle.
In other words, the dream of "Can mathematics be completely mechanized?" was proven to be impossible.
The Unintended Byproduct: The Concept of a Computer That "Can Do Anything"
What matters is not the conclusion of the proof, but what was needed in order to construct the proof.
To "prove the halting problem," Turing first had to rigorously define "what it means to compute." This gave birth to the Turing machine——an abstract model of a machine that reads and writes symbols on a tape and changes state according to rules.
Turing then noticed a decisive property of this machine. The program itself is data.
What does this mean?
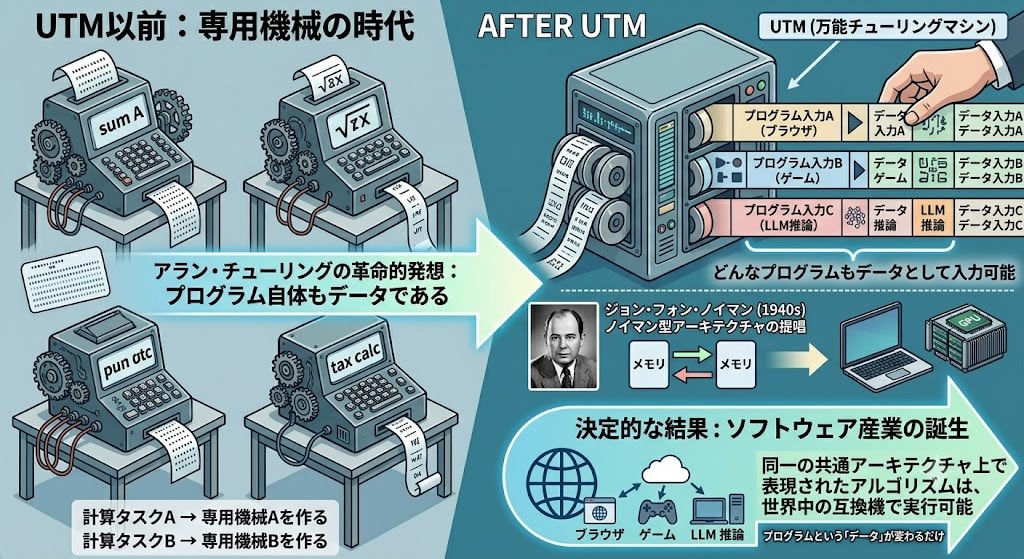
You can write "input data" on the tape of a Turing machine. But you can also write "the procedure of how to operate (the program)" on the same tape. That means a procedure is also a kind of data. And if that's the case——a universal machine that can receive any program description as input and execute it can be built.
This is called the Universal Turing Machine (UTM).
Why this idea was revolutionary becomes clear when compared to the world before it:
Before UTM: Computing task A → Build dedicated machine A
Computing task B → Build dedicated machine B
Computing task C → Build dedicated machine C
After UTM: Any task → The same 1 machine + different program (input)
This is your laptop. The browser, the game, the LLM inference——the hardware doesn't change. Only the "data" called a program changes.
John von Neumann read Turing's paper and in the 1940s translated this concept into actual computer design (von Neumann architecture). Storing programs in the same memory as data——every computer today follows this design.
With this design becoming an industry standard, something decisive happened. Algorithms expressible on this common architecture run on any compatible hardware. Anyone who writes a program can run it on compatible machines around the world. Even without a specific dedicated machine, you can participate with just an algorithmic idea. This is the foundation of the software industry, and the reason why LLM training code runs on GPU clusters all around the world.
However, the 1936 proof also settled one more thing. The "limits of computability" that Turing himself drew also apply to LLMs. Neither ChatGPT nor Claude can solve the halting problem in principle——meaning it is impossible to completely guarantee whether any arbitrary program is correct. The same paper that gave birth to computers also defined the permanent ceiling for every AI running on those computers.
In trying to prove the limits of mathematics, the concept of "a computer that can do anything" was born.
Side note: 14 years later in 1950, Turing posed the question "Can machines think?" and proposed the Turing Test to test whether humans and machines could be distinguished. It is the conceptual ancestor of conversational tests for evaluating LLM capabilities. Also, the highest honor award in computer science is called the Turing Award (ACM Turing Award), and it holds enough authority to be called "the Nobel Prize of computer science." As we will discuss later, the key figures in deep learning also received this award.
Chapter 2 — Can "Information" Be Measured Mathematically? — Claude Shannon (1948)
The Problem He Was Trying to Solve
In the 1940s, Claude Shannon, a researcher at Bell Labs, had a practical concern:
"How accurately can information be sent over noisy telephone lines?"
It was a problem of telephone engineering, unrelated to AI or machine learning.
Why It Was Necessary to Define "What Is Information"
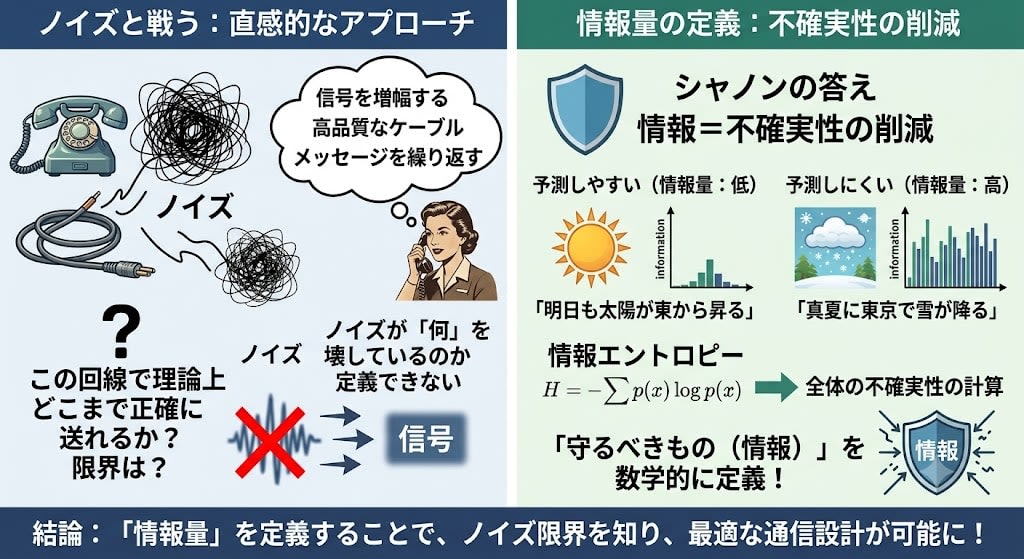
Engineers of the time dealt with noise intuitively. Amplify the signal, improve cable quality, repeat messages. However, they could not answer one fundamental question:
"How accurately can information theoretically be transmitted over this noisy line? Where is the limit?"
The reason they couldn't answer was simple. They could not mathematically define what noise was destroying.
Think about it. Noise corrupts signals. So what "part" of the signal is it a problem to corrupt?
For example, if the message "THE CAT SAT ON THE MAT" is partially garbled by noise:
- "C" in "CAT" disappears → The meaning is broken. Fatal.
- "THE" becomes "TH_" → The reader can restore it. No problem.
- The second "THE" disappears → The reader already predicted it. Information loss is small.
There is an important discovery here. Not all parts of a message carry equal information. Predictable parts carry little information; unpredictable parts carry much information. Noise truly does harm when it destroys the parts with high information content.
In other words, to fight noise, you first need to know "what to protect." To know what to protect, you need to define "what information is."
Defining "Information Content"
Shannon's answer: "Information is the reduction of uncertainty. The more unpredictable an event, the greater its information content."
"The sun will rise in the east tomorrow"——everyone knows it. Information content is nearly zero.
"It snows in Tokyo in midsummer"——unexpected. High information content.
This intuition was formalized as information entropy——a formula that "calculates the overall unpredictability based on the probability of each event occurring," producing larger values when prediction is more difficult.
Incidentally, the word "bit" also appeared in this era, but Shannon himself did not invent it. The concept of binary numbers using 0 and 1 traces back to Leibniz (1703), and the word "bit" was coined by colleague John Tukey and popularized by Shannon in his paper. Shannon's essential invention was not "0 or 1," but the mathematics itself of quantifying information.
Side note: It is widely said that Anthropic's AI assistant "Claude" was named after Claude Shannon. An AI bearing the name of the man who created information theory is quite a suggestive choice.
The Engineering Shannon's Answer Unleashed
By defining information, everything became quantifiable:
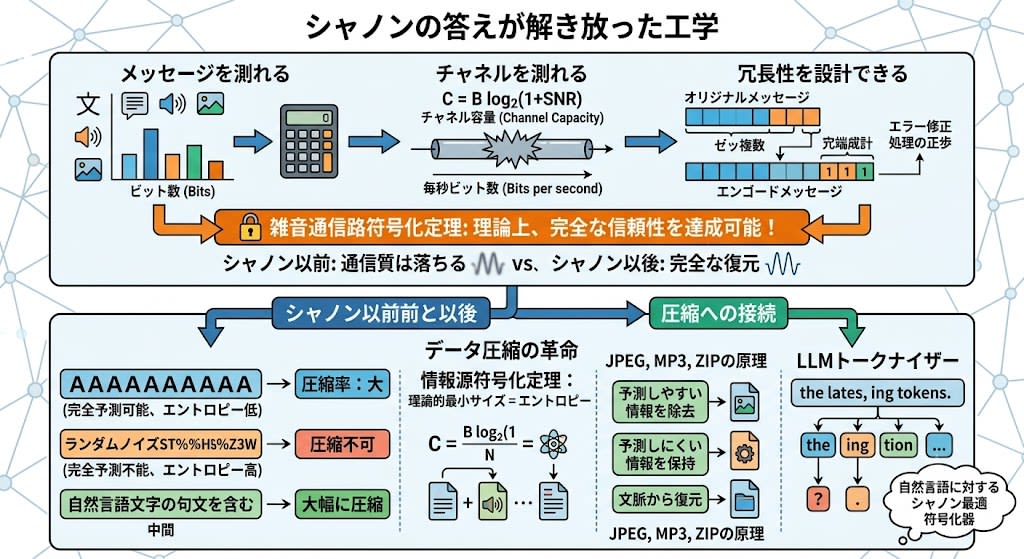
- Messages can be measured — You can calculate how many bits of information they contain
- Channels can be measured — You can calculate how many bits per second a line can reliably carry (channel capacity)
- Redundancy can be designed — You can calculate how many bits to add for error correction
And the most important result——the noisy-channel coding theorem: as long as the information rate is below channel capacity, no matter how much noise there is, with appropriate coding, communication can be achieved with virtually no errors.
Before Shannon, engineers believed that poor communication quality on noisy lines was unavoidable. Shannon proved otherwise. Noise defines the limit, but below that limit, perfect reliability is achievable——given the right coding.
The Connection to Compression: Parts with Little Information Can Be Discarded
Shannon's definition of information content spawned another revolution——data compression.
According to the source coding theorem, the theoretical minimum size to which a message can be compressed equals its entropy (information content). That is:
- "AAAAAAAAAA"——completely predictable, entropy nearly zero → can be compressed to nearly zero
- Random noise——completely unpredictable, maximum entropy → cannot be compressed
- Natural language——intermediate, many patterns → can be compressed significantly
JPEG, MP3, ZIP files——all follow this principle. Remove the predictable (low information) parts, preserve the unpredictable (high information) parts. During decompression, restore the parts that can be predicted from context.
LLM tokenizers (BPE——Byte Pair Encoding) are also compression in this sense. Frequently occurring sequences ("the," "ing," "tion") become a single token, while rare sequences remain as individual characters. A tokenizer is literally a Shannon-optimal encoder for natural language.
The Connection to LLMs: From Training to Inference
Training: Cross-Entropy Loss
The core question when training an LLM is "How accurately can the model predict the next word?"
The metric used to measure this "prediction accuracy" is cross-entropy loss——derived directly from Shannon's entropy.
Loss = -(sum of: correct probability × log(model's predicted probability))
When an LLM learns, the model strives to minimize this value. In other words, reducing "surprise" at the next token is the entire purpose of training. Shannon's definition of "information = reduction of uncertainty" becomes the learning objective itself.
Inference: Temperature Is the Entropy Knob
Shannon's concept of "surprise" also connects directly to controlling LLM output. The Temperature parameter is a knob that directly manipulates the entropy of the output distribution.
P(token) = softmax(logit / temperature)
| Temperature | Effect on distribution | Shannon entropy |
|---|---|---|
| → 0 | Concentrates on highest-probability token | Entropy → 0 (zero surprise) |
| = 1 | Model's natural distribution | Natural entropy |
| > 1 | Distribution flattens, all tokens become more equal | Entropy rises (more surprise) |
Low temperature = always choosing the most predictable (low information) token. High temperature = sampling from a higher-entropy distribution = more creative but potentially less consistent.
When you raise the Temperature to "write more creatively," you are literally raising the Shannon entropy of the output.
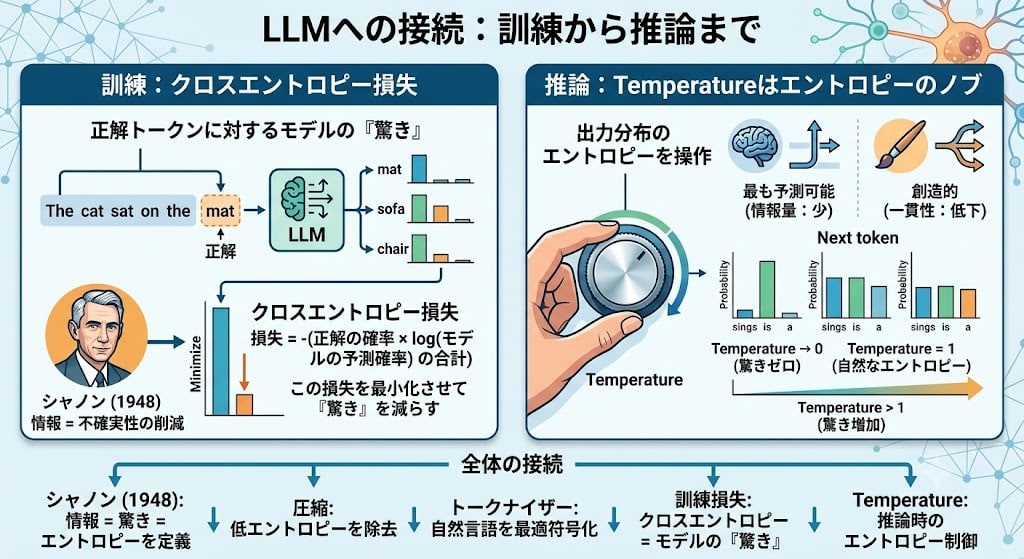
The Full Connection
Shannon (1948): Defines information = surprise = entropy
↓
Compression: Removes low-entropy (predictable) parts, preserves high-entropy
↓
Tokenizer: BPE optimally encodes language on the same principle
↓
Training loss: Cross-entropy = model's "surprise" at the correct token
↓
Temperature: Controls entropy of the output distribution at inference
A single mathematical framework applies to every layer of building and operating LLMs. Shannon's mathematics——born from wanting to reduce noise on telephone lines——80 years later became both "the definition of LLM intelligence" and "the creativity adjustment knob."
Chapter 3 — Can Machines Learn? — Optimism, Setbacks, and Revival
The Age of Optimism: The Perceptron (1958)
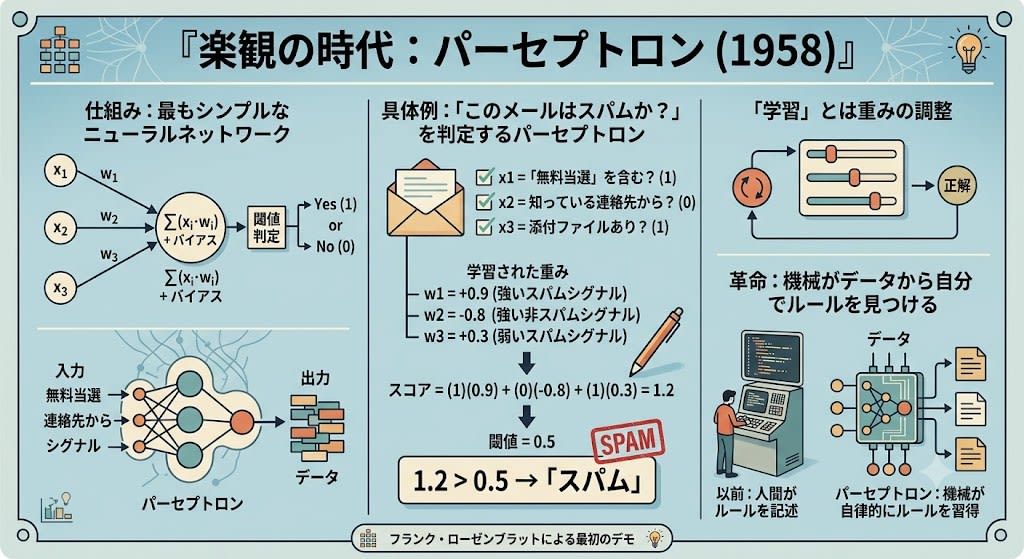
The first demonstration that "machines can learn" was Frank Rosenblatt's perceptron.
The mechanism is simple. The simplest possible neural network——a circuit with just one "neuron."
Input Weights Sum Output
x1 ----(w1)----\
x2 ----(w2)-----→ Σ(xi·wi) + bias → threshold check → 0 or 1
x3 ----(w3)----/
- Receive multiple inputs (numbers)
- Multiply each by a "weight" and sum them
- If the sum exceeds a certain threshold, output "Yes (1)"; otherwise output "No (0)"
Let's look at a concrete example. A perceptron that judges "Is this email spam?":
Inputs:
x1 = Contains "free winner"? (1 or 0)
x2 = From a known contact? (1 or 0)
x3 = Has an attachment? (1 or 0)
Learned weights:
w1 = +0.9 (strong spam signal)
w2 = -0.8 (strong non-spam signal)
w3 = +0.3 (weak spam signal)
Score = (1)(0.9) + (0)(-0.8) + (1)(0.3) = 1.2
Threshold = 0.5
1.2 > 0.5 → "Spam"
"Learning" is the adjustment of these weights. Start with random weights, make corrections little by little while checking answers. After repeating thousands of times, the weights converge to appropriate values.
Before the perceptron, every program ran on rules hand-written by humans. The perceptron was a revolutionary demonstration of the concept of machines finding their own rules from data.
The New York Times reported: "The Navy revealed the embryo of an electronic computer that it expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence." An air of optimism was in the air.
The Setback: The First AI Winter (1969)
Marvin Minsky and Seymour Papert poured cold water on it.
The perceptron has mathematical limitations.
One question might arise here: "As Turing proved in 1936, a universal Turing machine can perform any computation. Why would something as trivial as XOR be a problem?"
The answer is that Turing's universality and the perceptron's learning are completely different capabilities.
- Turing's universality: If a human writes the correct program, any computation can be done. XOR? It can be written with one line of
if. - The perceptron's promise: The machine discovers the rules by itself from data. Humans don't write the rules.
What XOR destroyed was not "computational ability" but the learning mechanism itself.
Let's look at it concretely. XOR (exclusive or) is the simple rule "output 0 if both inputs are 1 or both are 0; output 1 if only one is 1." When plotted on a 2D plane:
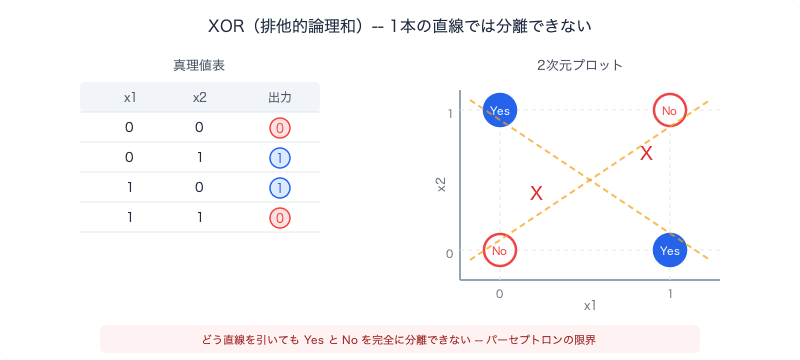
The perceptron tries to separate Yes and No with a single straight line. But looking at the figure above, it is impossible to separate ● and ○ with one straight line. No matter how you draw the line, they will always be mixed.
This alone might be dismissed as "XOR is a special case." But what Minsky and Papert proved was not just about XOR. They showed that the entire class of problems requiring nonlinear decision boundaries——parity judgment (even/odd discrimination), symmetry detection, connectivity judgment, and so on——were all impossible for the perceptron. XOR was merely the simplest and most embarrassing counterexample.
And the reason this was devastating was the gap between expectations and reality. The media reported "a machine that walks and talks." Mathematicians proved that machine couldn't even learn XOR. The conclusion for funders was "neural networks = dead end." This was the trigger for the first AI winter. Research funding was frozen, and many neural network researchers lost their jobs.

However, their book contained one line of a footnote:
"A multilayer network might be able to solve this problem. However, how to train it is unknown."
This "however" defined the research agenda for the next 17 years.
The Revival: Backpropagation (1986)
The "however" was solved by Rumelhart, Hinton, and Williams with backpropagation.
A multilayer network is multiple perceptrons connected together. Each perceptron has its own weights, grouped by layer.
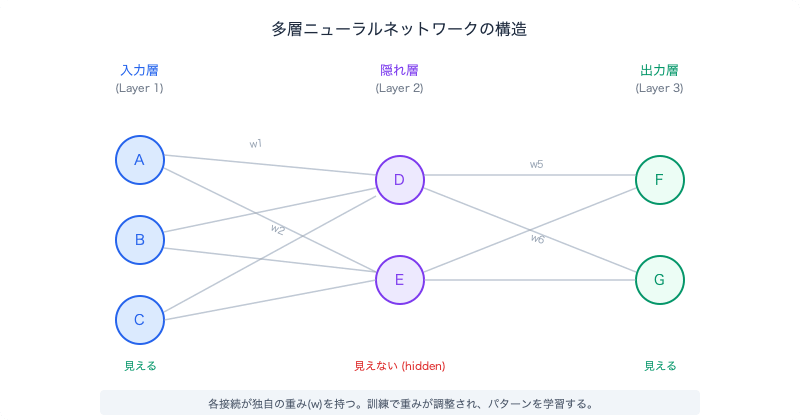
In this figure, the middle Layer 2 is called a hidden layer. Being "hidden" doesn't mean something is concealed. The input layer is where users feed data; the output layer is where users receive results——both are "visible" to the user. Meanwhile, the middle layer is an internal workspace that users don't directly touch. Because it's not visible from outside, it's "hidden."
When layers are added, it is these hidden layers that increase. There is always exactly one input layer and one output layer. How many hidden layers are stacked between them is "the depth of the network," and this is what "deep" means in "deep learning." This concept of "hidden" will reappear in Chapter 5, so keep it in mind.
The flow of learning is intuitive:
- Initialize all weights with random values (without randomness, all neurons learn the same thing)
- Input data, pass it through all layers, and produce a prediction ("This image is a cat")
- Check the answer and calculate how much was wrong
- Trace backward from output to input "which weights contributed to this error"
- Adjust each weight slightly according to its contribution (weights are overwritten; no snapshots remain)
- Repeat this millions of times
Only the final output knows the correct answer. No one knows "what the intermediate layers should correctly output." "The correct edge detection result of Layer 1 for a cat image"——there's no correct answer for that.
Input → [Layer1] → [Layer2] → [Layer3] → Output vs Correct Answer
↑
The only scoring point
So the error signal is propagated backward from the output. Using the mathematical chain rule——the principle that "if A influences B and B influences C, then A's influence on C is the product of the two effects"——the responsibility of each layer is calculated in sequence.
Forward pass (left → right):
Input → Layer1 → Layer2 → Layer3 → Output → "Wrong!"
Backward pass (right → left):
"Wrong!" → Layer3's responsibility → Layer2's responsibility → Layer1's responsibility
"Layer3, your responsibility is 40% → adjust weights by 40%"
"Layer2, your responsibility is 35% → adjust weights by 35%"
"Layer1, your responsibility is 25% → adjust weights by 25%"
The error propagates backward——hence backpropagation.
It was shown that multilayer networks can be trained this way, solving the problem that Minsky et al. said was "unknown."
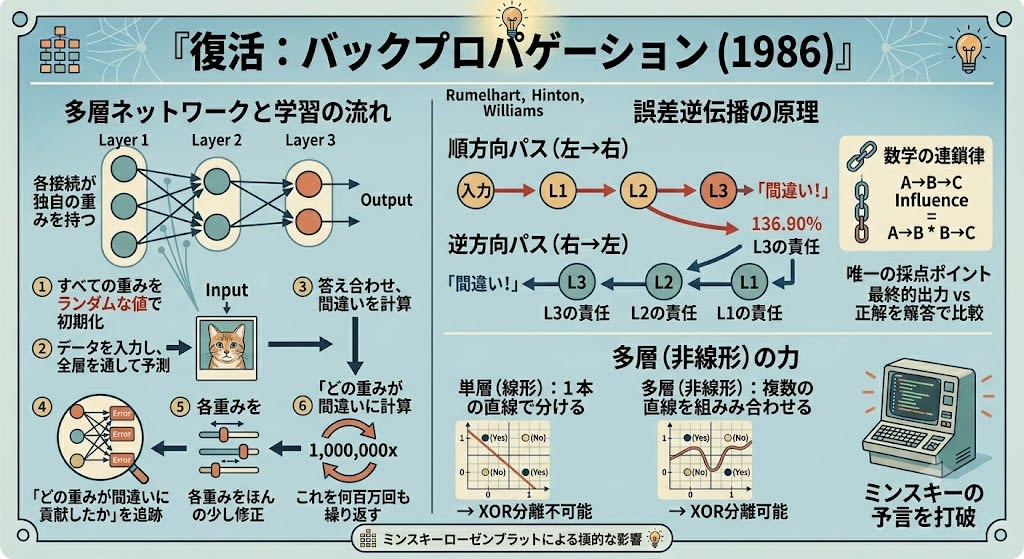
Why does adding layers solve the problem? The core is the difference between linear and nonlinear. A perceptron (single layer) can only draw one straight line——this is the linear limitation. In a multilayer network, each layer draws its own straight line, and combining them creates curved or complex-shaped decision boundaries. This is nonlinear.
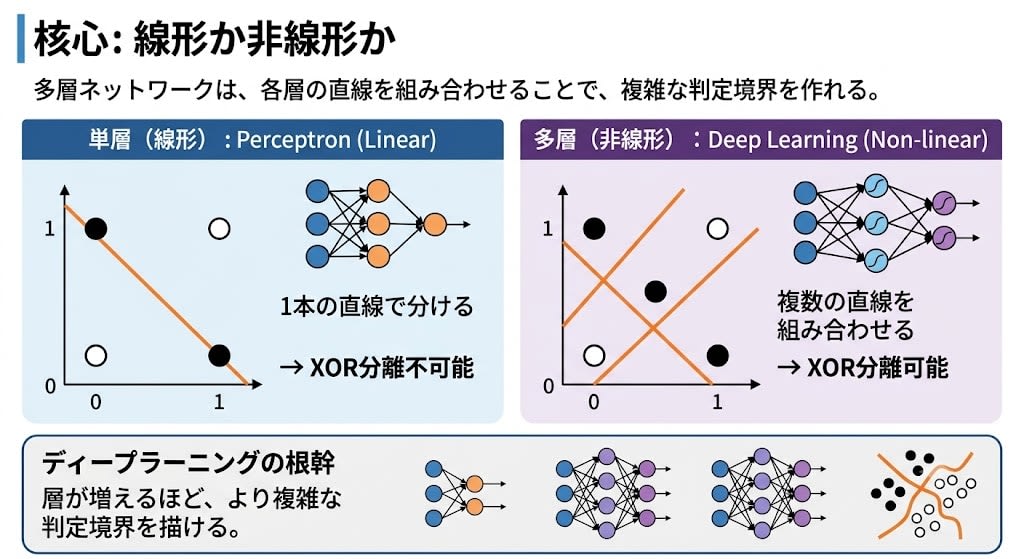
The more layers there are, the more complex the decision boundary that can be drawn. This is the foundation of deep learning.
However, there was a large wall between theory and practice. Training multilayer networks requires enormous computation, and the hardware of the 1980s–90s could not run training at a practical speed.
Breaking the Speed Wall: The Arrival of GPUs (2012)
Even after backpropagation was established, multilayer networks remained far from practical use for a while. Not enough data. Too slow to compute.
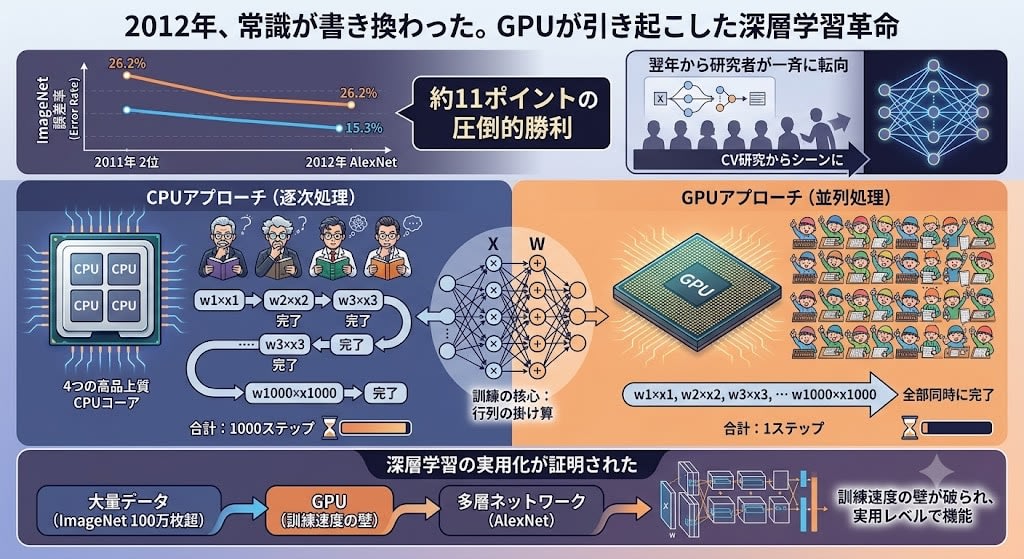
In 2012, the situation was completely transformed by the ImageNet competition (classifying over 1 million images into 1,000 categories). A model called AlexNet achieved overwhelming results. Against second place's error rate of 26.2%, AlexNet achieved 15.3%——a gap of about 11 percentage points. In the machine learning world, improvements of 1–2 percentage points year-over-year were normal, and 11 points was an understated way of saying "crushed the competition." Many computer vision researchers switched to deep learning the following year, and the industry's common sense was rewritten.
What AlexNet used was a GPU (graphics chip). Why were GPUs so effective? Until then, training had been done on CPUs, but CPUs and GPUs have fundamentally different design philosophies.
A CPU has a small number of high-performance cores (4–16) and is designed to handle complex tasks sequentially. A GPU, on the other hand, has thousands of simple cores (4,000+) and is designed to simultaneously execute large numbers of simple calculations.
CPU: 4 skilled mathematicians solving complex problems in sequence
GPU: 4,000 elementary school students solving addition problems all at once
Training a neural network is largely matrix multiplication——the simple repeated calculation of multiplying and summing thousands of weights with thousands of inputs. And each multiplication is independent of the others; the result of w3×x3 doesn't need to wait for the result of w1×x1.
CPU approach (sequential):
w1×x1 → done → w2×x2 → done → w3×x3 → done → ... → w1000×x1000 → done
Total: 1000 steps
GPU approach (parallel):
w1×x1, w2×x2, w3×x3, ... w1000×x1000 → all done simultaneously
Total: 1 step
Training AlexNet took weeks to months on a CPU, but only days on a GPU. Same mathematics, same results——just massively parallelized. The GPU broke down the wall of training speed, proving that the combination of "GPU + large amounts of data + multilayer networks" works at a practical level.
However, AlexNet was an 8-layer network. "Deeper (more layers) should mean smarter," but when trying to make networks deeper, another wall stands in the way.
Side note: One of AlexNet's authors, Geoffrey Hinton, also has his name on the 1986 backpropagation paper. The same person who survived the AI winter led the revival of deep learning 26 years later. In 2018, Hinton received the Turing Award along with Yann LeCun and Yoshua Bengio; all three are together called "the godfathers of deep learning."
Side note: NVIDIA, which makes GPUs, was originally a company for gaming graphics. 3D rendering in games also involves "executing the same calculations in parallel for large numbers of pixels"——and this is structurally identical to the matrix operations of neural networks. The AI boom made NVIDIA one of the most valuable companies in the world——the fact that a gaming chip became the optimal tool for AI training is one of the "unintended connections" traced in this article.
Going Even Deeper: Overcoming Vanishing Gradients (2010s)
Even after GPUs solved the speed problem, making networks deeper itself faced another wall——the vanishing gradient problem.
As seen with backpropagation, the only scoring point is the final output. The error signal has no choice but to travel backward through the layers. And with each layer it passes through, the signal shrinks by multiplication. The coefficient of each multiplication is typically less than 1 (e.g., 0.3), so repeatedly multiplying by a small number rapidly approaches zero.
3 layers: 0.3 × 0.3 × 0.3 = 0.027 ← small but usable
10 layers: 0.3^10 ≈ 0.000006 ← nearly zero
50 layers: 0.3^50 ≈ 0.00000000000000000000000... ← effectively zero
The closer to the final layer, the stronger the feedback; the closer to the first layer, the more the feedback vanishes:
Layer1 Layer2 Layer3 ... Layer50 Output
←×0.3← ←×0.3← ←×0.3← ... ←×0.3← Error!
Layer50: "30% wrong, adjust!" ← can learn
Layer25: "0.000001% wrong" ← barely learns
Layer1: "0.0000000000% wrong" ← can't move, can't learn
This is like having a broken building foundation that can't be repaired. Layer 1 is the layer that should learn basic features (edges, simple patterns), but because feedback doesn't reach it, it can't learn. If the foundation is random, nothing built on top of it means anything.
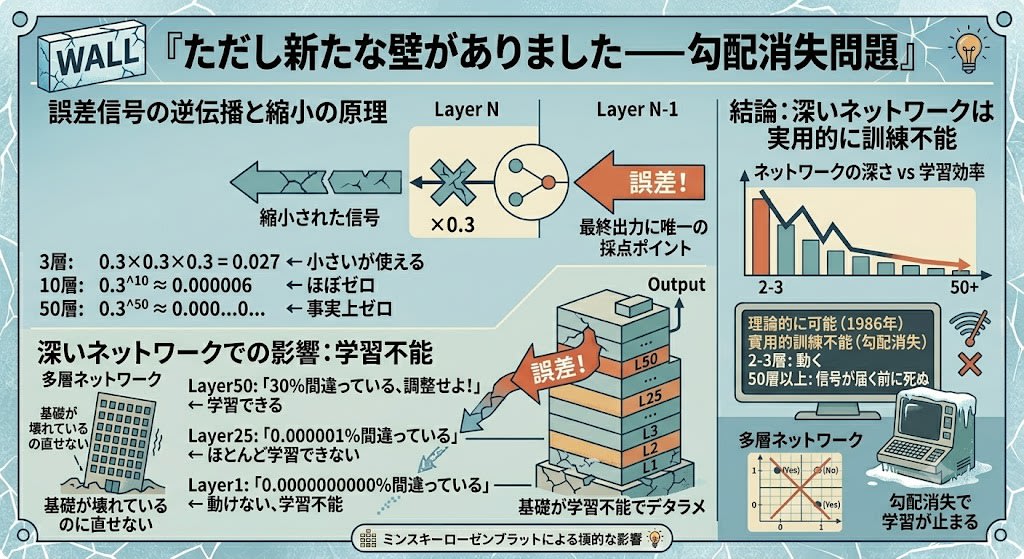
This wall was gradually overcome through a combination of techniques.
Earlier, I explained that the coefficient of each layer's multiplication is less than 1, like "0.3." Where does this coefficient come from? The answer is the activation function——the function that determines how each neuron transforms its output.
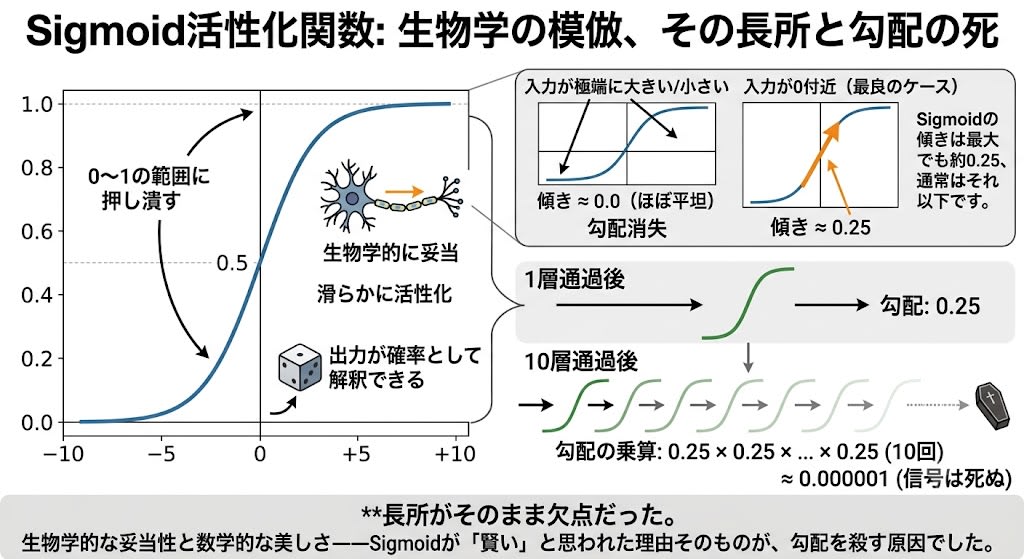
What had been used for a long time was Sigmoid. Sigmoid was designed to mimic biological neurons. Actual neurons don't simply turn on or off; they activate smoothly according to the strength of stimulation. Sigmoid reproduces this with a smooth S-shaped curve, transforming any input to a range of 0 to 1.
However, in backpropagation, the "coefficient of responsibility" for each layer is determined by the slope (gradient) of this activation function. The slope of Sigmoid is at most about 0.25, and usually less.
Sigmoid slope:
Input is extremely large/small → slope ≈ 0.0 (nearly flat)
Input near 0 (best case) → slope ≈ 0.25
Best case per layer: ×0.25
After 10 layers: 0.25^10 ≈ 0.000001 → signal dies
Biological plausibility and mathematical elegance——the very reasons Sigmoid was considered "smart" were the cause of killing the gradient. The strengths themselves were the weaknesses.
ReLU: Why "Naive" Won
ReLU (Rectified Linear Unit) is surprisingly simple. "If positive, pass through as-is; if negative, output zero"——that's it.
Mathematicians initially dismissed it. Too crude. Has a point of non-differentiability. Doesn't resemble neurons at all.
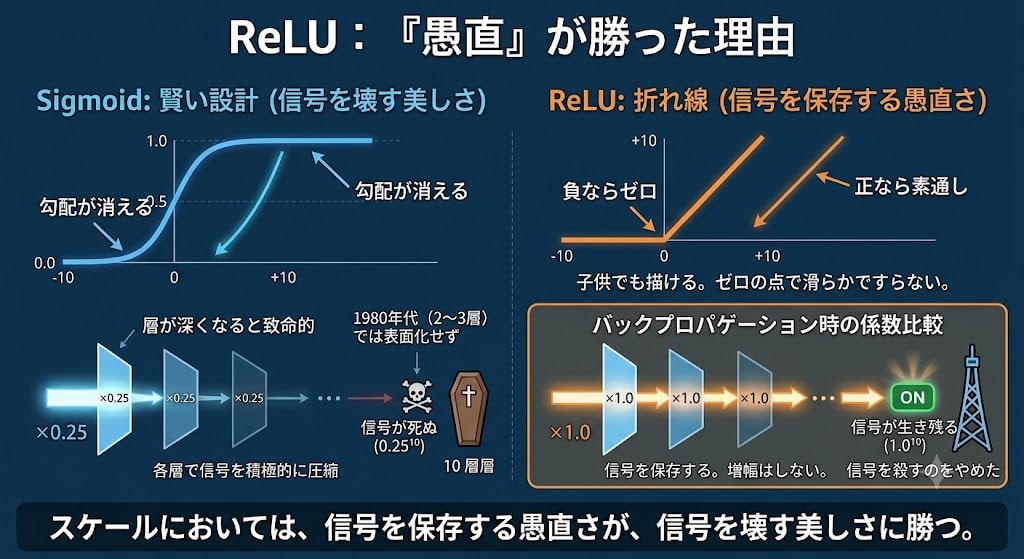
However, ReLU's slope for positive values is exactly 1.0. Not 0.25, not 0.1, but 1.
Coefficient comparison during backpropagation:
Sigmoid: ×0.25 → ×0.25 → ×0.25 → ... → signal dies
After 10 layers: 0.25^10 = 0.000001
ReLU: ×1.0 → ×1.0 → ×1.0 → ... → signal survives
After 10 layers: 1.0^10 = 1.0
ReLU doesn't "amplify" the signal. It simply stopped killing it. Sigmoid was actively compressing the signal at each layer. ReLU just passes it through.
In the 1980s, networks were only 2–3 layers deep, and Sigmoid's problem was not apparent. Only when layers grew deep did the hidden cost of the "smart design" become fatal. At scale, the naivety of preserving the signal beats the elegance of destroying it.
However, Sigmoid wasn't "wrong." It was correct but could not withstand scaling. Like training wheels on a bicycle——the right design for a beginner, but they get in the way of a racer. In fact, Sigmoid is still used today in specific applications——Yes/No classification in output layers (where 0–1 probabilities are needed) and gate control within memory cells. However, for hidden layers of deep networks, ReLU is now the standard.
Residual Connections (ResNet, 2015): Another Solution
While ReLU suppressed signal attenuation within each layer, residual connections (ResNet) tackled vanishing gradients from a completely different angle.
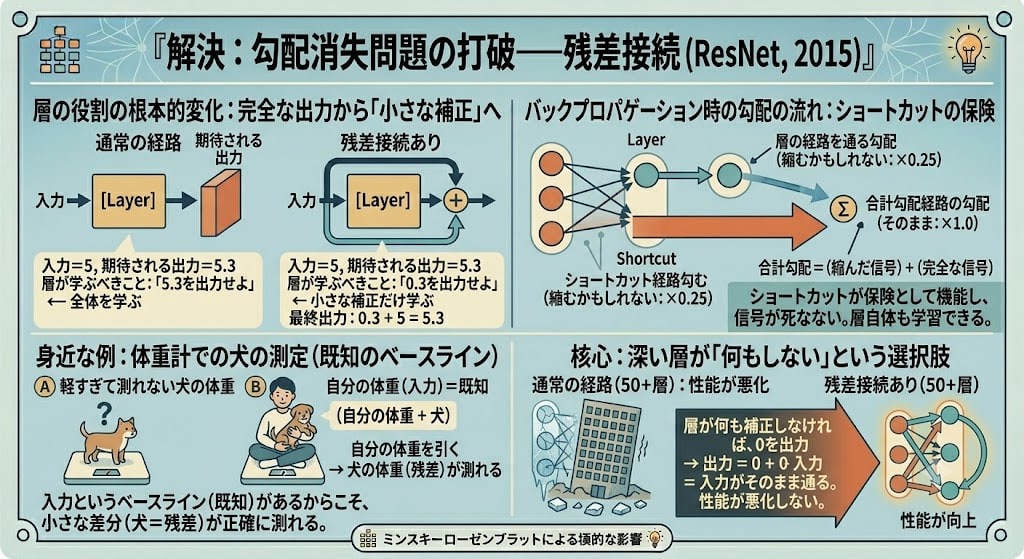
In a normal network, each layer is required to "receive input and generate a complete output." With residual connections, the input passes through a shortcut path and is added directly to the output.
Normal path: Input → [Layer] → Output
With residual: Input → [Layer] → Layer result + Input = Output
│ ↑
└───────────────────────────────┘
Shortcut (input is added as-is)
What does this change? The job of the layer changes fundamentally.
Without residual connection:
Input = 5, expected output = 5.3
What the layer must learn: "output 5.3" ← learn the whole thing
With residual connection:
Input = 5, expected output = 5.3
Output = layer result + input
What the layer must learn: "output 0.3" ← learn only the small correction
Final output: 0.3 + 5 = 5.3
The layer's role changes from "generate the complete output" to "learn the small correction (residual) relative to the input." That's why it's called a residual connection.
As a familiar example: if you want to weigh a dog that is too light for the scale to measure alone——hold the dog and stand on the scale together, then subtract your own weight to get the dog's weight. Because you have a known baseline (your own weight = input), the small difference (the dog = residual) can be measured accurately. Residual connections work the same way: by retaining the input as a baseline, the small correction that the layer needs to learn becomes detectable.
There is also a decisive difference for gradients. In backpropagation, gradients flow through both paths:
Backward pass:
Gradient through the layer path (may shrink: ×0.25)
╱
Total gradient =
╲
Gradient through the shortcut path (passes through as-is: ×1.0)
Total = (shrunken signal) + (complete signal)
Even if the gradient shrinks to 0.001 through the layer path, the shortcut path adds 1.0. The total is approximately 1.001. The shortcut functions as insurance so the signal doesn't die. And since gradients also flow through the layer path, the layer itself can still learn——because the feedback doesn't disappear.
What if the layer finds no useful correction to make? It just outputs 0. Output = 0 + input = input passes through unchanged. Because the layer has the option of "doing nothing," adding deep layers doesn't degrade performance.
ResNet successfully trained a 152-layer network with this mechanism and won ImageNet 2015.
ReLU and ResNet: Different Approaches, Same Goal
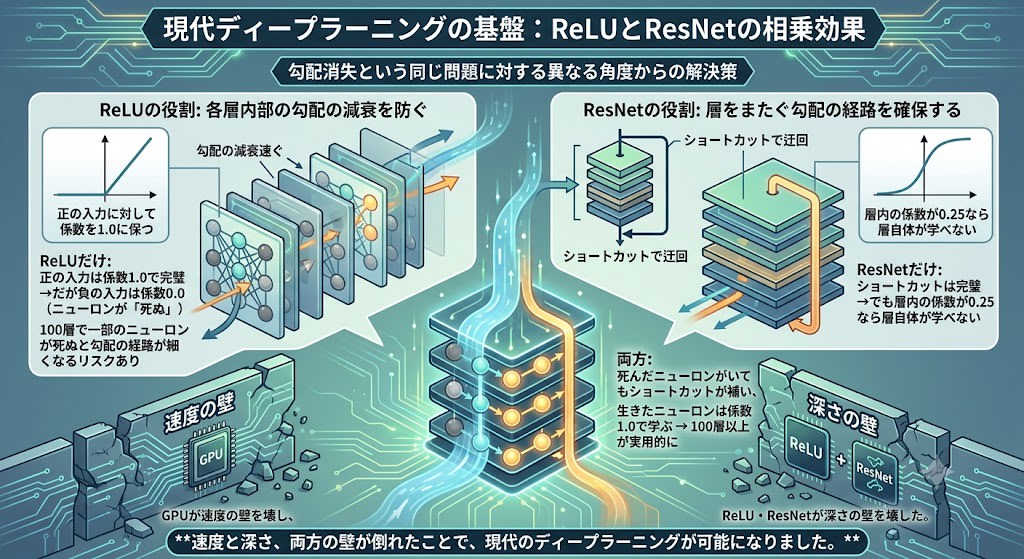
ReLU and ResNet are solutions from different angles to the same problem of vanishing gradients. ReLU prevents gradient attenuation within each layer (keeping the coefficient at 1.0), while ResNet ensures a detour path for gradients across layers. In modern deep learning, combining both has made networks of 100+ layers practical.
GPUs broke down the speed wall, and ReLU and ResNet broke down the depth wall. With both the speed and depth walls demolished, modern deep learning became possible.
Chapter 4 — What Does It Mean to Turn Words into Numbers? — The Geometry of Meaning
Computers Can Only Handle Numbers
The story so far has been about "how to make learning accurate." And every success story up to this point dealt with data that was already numbers. Images are pixel values (each pixel is color information from 0–255). Sound is waveform values. Stock prices, temperatures, sensor data——all are numbers from the start. They can be input directly into a neural network.
But words are not numbers. "Cat," "economy," "beautiful"——these are symbols, and they cannot be input directly into the matrix calculations of a neural network. To build an LLM, you first needed to solve the fundamental problem of "how to convert words into numbers?"
The simplest approach: assign numbers like "cat=1, dog=2, sky=3…." But this means there is no meaningful relationship between "cat" and "dog." The information that "cats and dogs are similar" and "cats and spaceships are far apart" is not in the numbers.
Word2Vec: Placing Meaning as Coordinates in Space (2013)
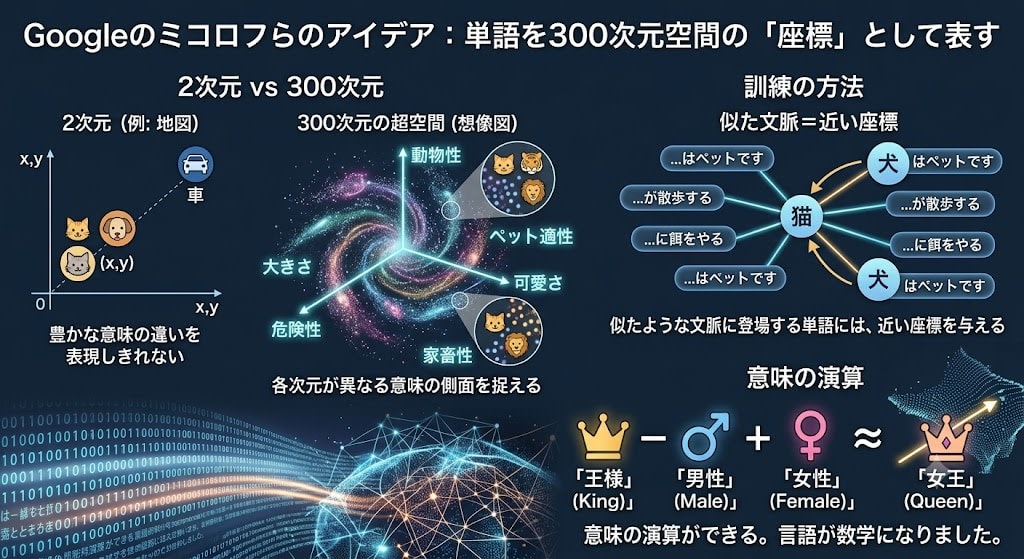
The idea shown by Mikolov et al. at Google: represent each word as "coordinates (a vector)" in a high-dimensional space.
What does "high-dimensional" mean? The maps we use in daily life are 2-dimensional (east-west, north-south); inside a building it's 3-dimensional (plus up-down). In Word2Vec, one word is represented by 300-dimensional coordinates. Humans cannot visualize a 300-dimensional space, but mathematically, distances and directions can be calculated just as with 2D or 3D space.
Why are 300 dimensions needed? Because the meaning of language is multifaceted. The word "cat" is characterized along countless axes: "Is it an animal?" "Is it a pet?" "How big is it?" "Is it dangerous?" "Is it cute?" 2–3 dimensions cannot express the richness of these meaningful differences. With 300 dimensions, each dimension can capture a different aspect of meaning.
The training method is simple: learn to "give nearby coordinates to words that appear in similar contexts." "Cat" and "dog" both appear in contexts like "pet," "food," and "walk," so their coordinates become close.
The "map of meaning" that emerged had a remarkable property:
coordinates of "king" − coordinates of "man" + coordinates of "woman" ≈ coordinates of "queen"
Arithmetic with meaning is possible. Language became mathematics.
Side note: There is a predecessor to the idea that "meaning lies in relationships." In 1998, Stanford graduate students Larry Page and Sergey Brin proposed PageRank in their paper "The Anatomy of a Large-Scale Hypertextual Web Search Engine." The search engines of the time ranked pages by keyword frequency, but PageRank measured importance by how many other pages linked to a given page——that is, by the structural relationships of the Web. The idea that "relationships with surroundings represent the essence better than the content itself" is strikingly similar to Word2Vec's principle that "a word's meaning is determined by surrounding context (co-occurring words)." And the Google born from this PageRank later established Google Brain, which produced the 2017 "Attention Is All You Need" (Transformer) paper. A search engine company invented the core architecture of LLMs——this too is one of those "unintended connections."
How Do We Measure "Closeness"? — Cosine Similarity
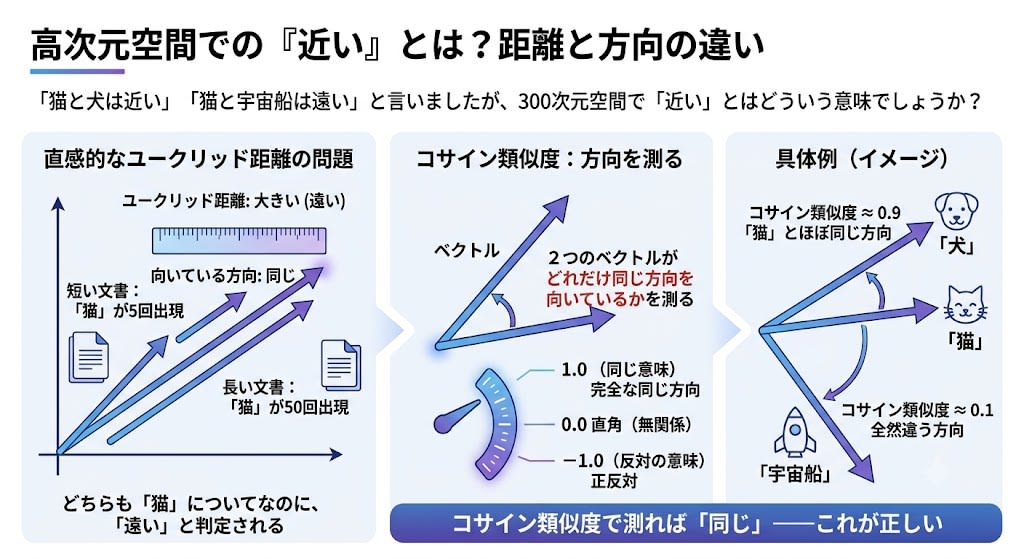
We said "cats and dogs are close" and "cats and spaceships are far apart," but what does "close" mean in 300-dimensional space?
Intuitively, we might want to use the distance between two points (Euclidean distance). However, in high-dimensional space, direction captures semantic similarity better than distance.
Let's look at a concrete example. Suppose we have a long document and a short document about "cats."
Short document: "cat" appears 5 times → Vector magnitude: small
Long document: "cat" appears 50 times → Vector magnitude: large (stretches 10x further than the 5-occurrence document)
Euclidean distance between the two: large (far apart)
Direction both are pointing: the same
Both are "documents written about cats," yet when measured by distance, they are judged as "far apart." Measured by direction, they are "the same"——that is the correct result.
Cosine similarity measures how much two vectors point in the same direction.
Cosine similarity:
Exactly the same direction → 1.0 (same meaning)
Perpendicular (unrelated) → 0.0
Opposite directions → -1.0 (opposite meaning)
Example (conceptual):
"dog" ↗ ← nearly the same direction as "cat" → cosine similarity ≈ 0.9
"cat" →
"spaceship" ↓ ← completely different direction → cosine similarity ≈ 0.1
This is the foundation of today's RAG (Retrieval-Augmented Generation) and semantic search. A user's query is converted into a vector, cosine similarity is calculated against the vectors of documents in the database, and the document with the closest direction is retrieved. The idea of "measuring meaning by direction," which began with Word2Vec, has become the search engine of modern AI applications.
This technology is called Embedding.
Why Embeddings Are Indispensable to LLMs
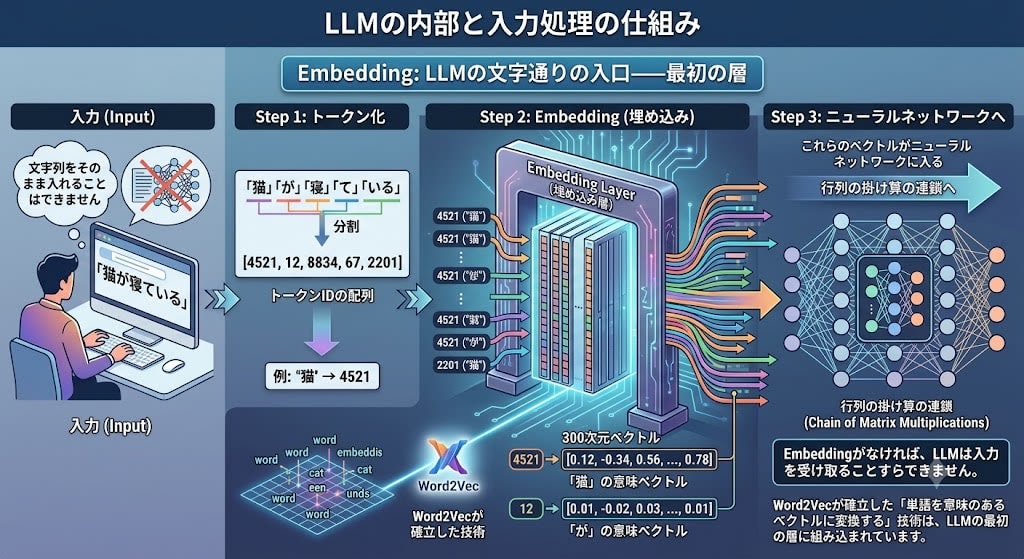
The importance of embeddings goes beyond RAG and search. They are the very gateway through which LLMs process language.
The internals of an LLM are a neural network——a chain of matrix multiplications. Matrix multiplications require numerical vectors. You cannot feed the string "cat" directly into a neural network.
When inputting the sentence "The cat is sleeping" into an LLM:
Step 1: Tokenization
"The" "cat" "is" "sleeping" → [4521, 12, 8834, 67, 2201]
Step 2: Embedding (convert each token ID into a 300-dimensional vector)
4521 → [0.12, -0.34, 0.56, ..., 0.78] ← meaning vector for "cat"
12 → [0.01, -0.02, 0.03, ..., 0.01] ← meaning vector for "is"
...
Step 3: These vectors are fed into the neural network
Without embeddings, an LLM cannot even receive its input. The technology of "converting words into meaningful vectors," established by Word2Vec, is built into the literal gateway——the first layer——of LLMs.
So far, we have solved "how to turn words into numbers." But the next problem awaits. Simply converting words into vectors causes the order of words (context) to be lost. "The dog chased the cat" and "The cat chased the dog"——the word vectors are the same, but the meanings are opposite.
How do we handle context? That question is the theme of the next chapter. And the first researchers to seriously tackle this question were those working on machine translation.
Continued in Part 2: In Chapter 5, we trace how Attention emerged from the structural limitations of RNNs, and how the Transformer evolved "from a patch into an architecture." Then on to GPT-3's scaling revolution, alignment through RLHF, and the current era of efficiency——the second half of how LLMs were completed "without being designed."
