
I tried running Gemma 4 locally on a MacBook (16GB) — from model selection and UI setup with Ollama to practical project use
This page has been translated by machine translation. View original
Introduction
Gemma 4, released by Google in 2026, has been attracting attention as an open-weight LLM that can run locally. Having your own AI endpoint with zero API cost is appealing, but the first hurdle is "will it run on my MacBook?"
This article introduces the process of running Gemma 4 locally on a MacBook with 16GB memory (Apple M5). Along the way, I experienced failures including a completely frozen screen with the first model I chose, but ultimately reached a point where it could be used in a real project.
Overview of the Gemma 4 Family
Gemma 4 has four variations.
| Model | Parameters | Architecture | Disk Space (Q4) | Required Memory | Features |
|---|---|---|---|---|---|
| E2B | 2.3B | Dense | ~2 GB | ~3-4 GB | Ultra-lightweight, for edge devices |
| E4B | 4.5B | Dense | ~3 GB | ~5-6 GB | Balanced, comfortable on most Macs |
| 26B (MoE) | 25.2B (Active: 3.8B) | Mixture of Experts | ~17 GB | ~18-19 GB | High quality but heavy memory usage |
| 31B | 31B | Dense | ~20 GB | ~20+ GB | Highest quality, 32GB+ recommended |
The important point here is that disk space and required memory are different things. Disk space is the storage needed to save the model files, while required memory is the GPU/CPU memory used when actually loading the model for inference.
Step 1: Check Your MacBook's Specs
First, check the available memory on your machine.
sysctl hw.memsize
hw.memsize: 17179869184
This is a 16GB MacBook. With Apple Silicon, the CPU and GPU share the same unified memory. There is no separate "VRAM" region; the GPU uses a portion of the physical memory.
When you start Ollama, it shows the actual amount of available memory.
inference compute id=0 library=Metal name=Metal description="Apple M5"
total="11.8 GiB" available="11.8 GiB"
Out of 16GB, after subtracting what the OS and system use, we can see that approximately 11.8GB is allocated to the model.
Step 2: Installing Ollama
Ollama is a local LLM execution environment. It can be installed with Homebrew.
brew install ollama
Start the server.
ollama serve
Pull and run models in a separate terminal tab.
Step 3: The Story of Failing with 26B MoE
Looking at the spec table alone, the 26B MoE might seem lightweight because "only 3.8B active parameters." Mixture of Experts doesn't use all parameters during inference — instead, only some experts are activated per token.
However, all model parameters need to be loaded into memory. Having fewer active parameters is about computation, not memory usage — the full parameter count occupies memory.
ollama pull gemma4:26b
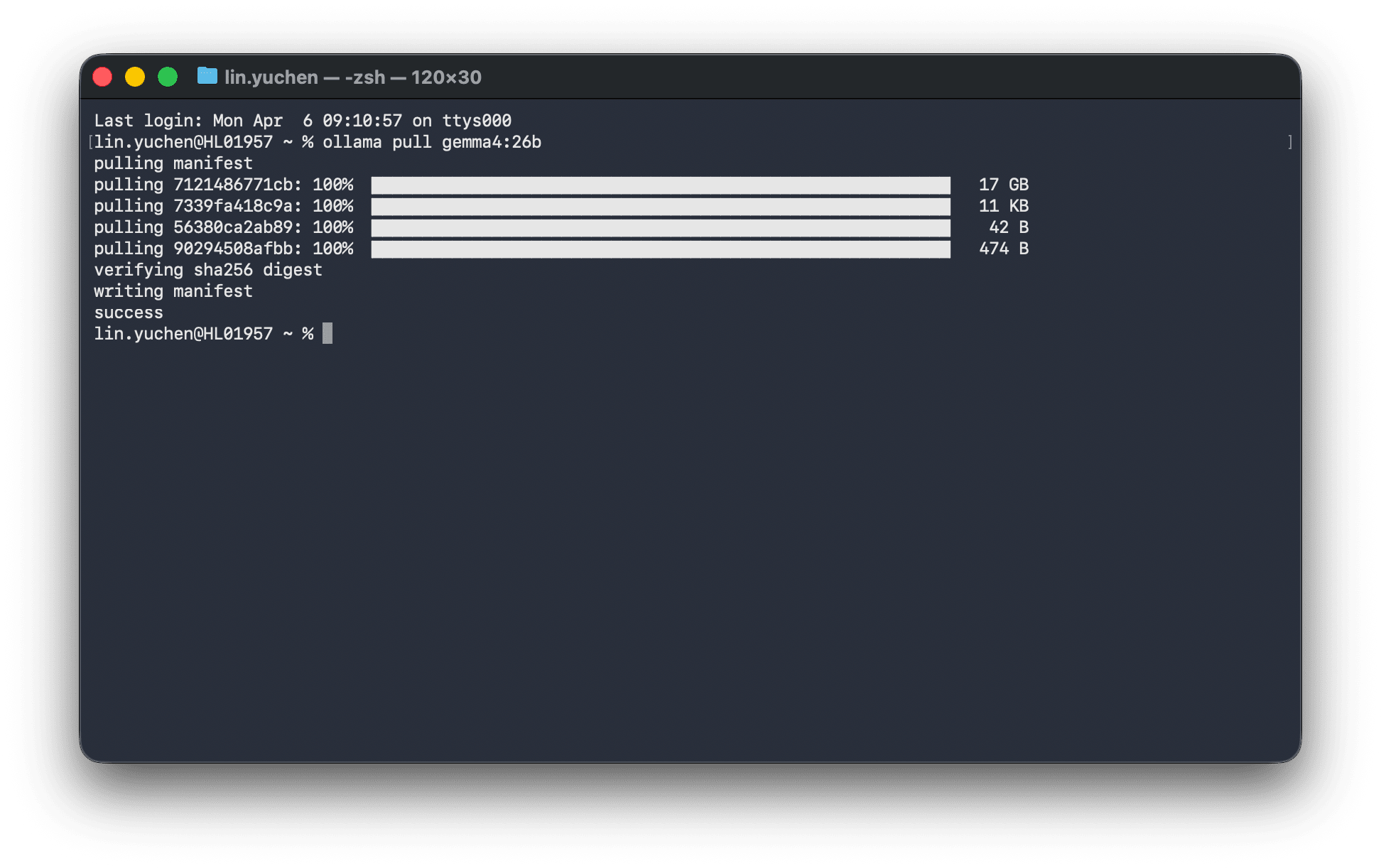
After the 17GB download completed and I tried to run it...
model weights device=Metal size="10.0 GiB"
model weights device=CPU size="7.3 GiB" ← Overflowing to CPU because it doesn't fit in GPU
offloaded 20/31 layers to GPU ← Only 20 of 31 layers fit in GPU
total memory size="18.8 GiB" ← Required memory 18.8GB > Available 11.8GB
The screen completely froze. After 13 minutes of being unable to operate, an HTTP 500 error was returned.
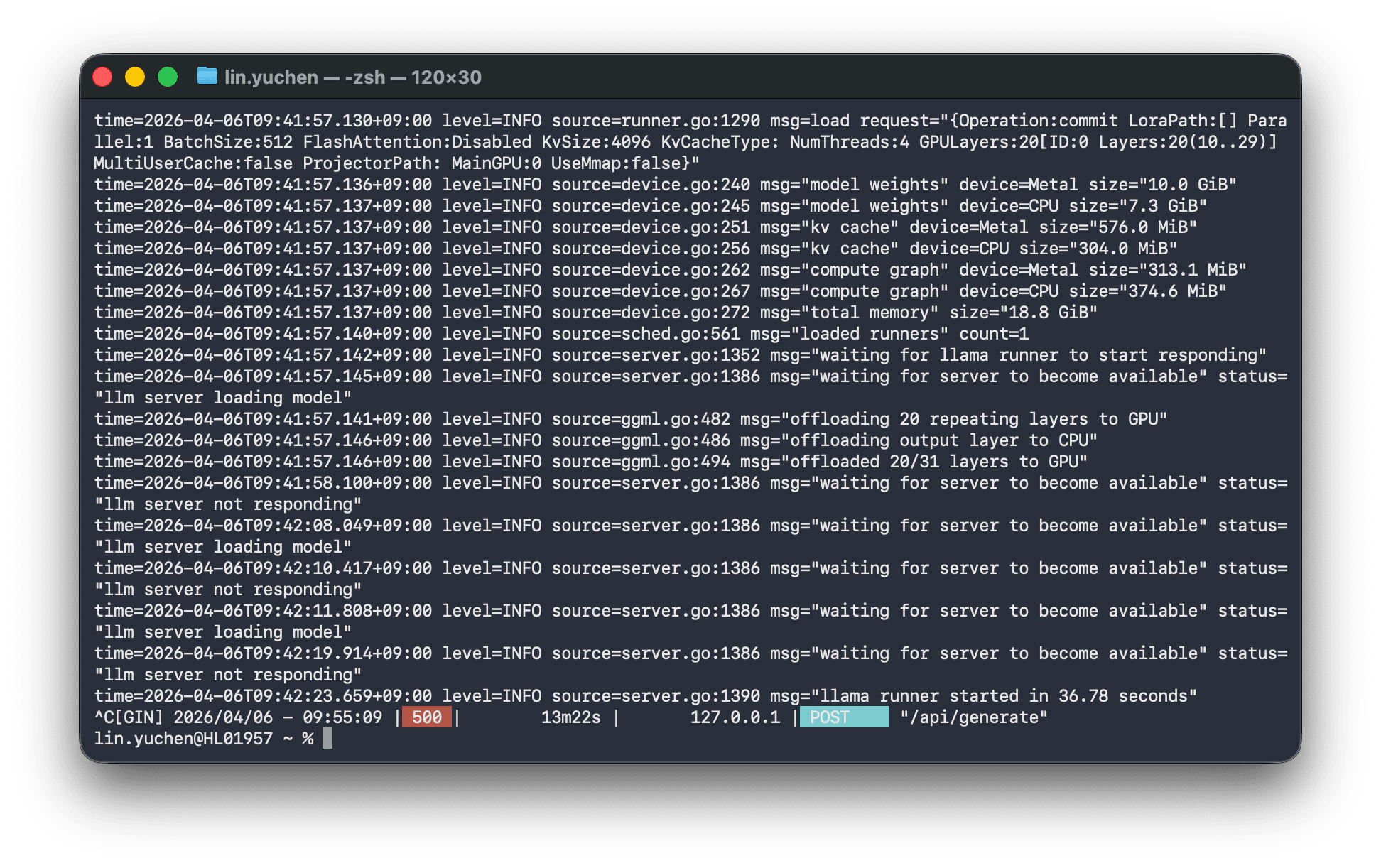
The portion that didn't fit in GPU memory overflowed (offloaded) to CPU memory, and the data transfer between GPU↔CPU became a bottleneck, making the entire machine unresponsive.
Delete the unnecessary model to free up disk space.
ollama rm gemma4:26b
Step 4: Running Comfortably with E4B
Switching to E4B with a fresh start.
ollama pull gemma4:e4b
After downloading, let's test it.
curl -s http://localhost:11434/api/generate \
-d '{"model":"gemma4:e4b","prompt":"Say hello in one sentence.","stream":false}'
{
"model": "gemma4:e4b",
"response": "Hello!",
"total_duration": 12755806500,
"load_duration": 12189128000,
"eval_count": 3,
"eval_duration": 60049084
}
The first time takes about 12 seconds to load the model, but once loaded it stays in memory. Let's look at response speeds on subsequent calls.
# Test with chat format
curl -s http://localhost:11434/api/chat \
-d '{
"model": "gemma4:e4b",
"messages": [{"role": "user", "content": "What is the capital of Japan?"}],
"stream": false
}'
| Test | Response Time |
|---|---|
| Short question ("What is the capital of Japan?") | 0.5 sec |
| Creative ("Write a haiku") | 0.9 sec |
| Long answer ("Explain an API in 2-3 sentences") | 13.5 sec |
No screen freezing, running comfortably. E4B fits within about 5-6GB of memory, leaving plenty of room within the 11.8GB constraint.
Step 5: Building a Chat UI with Open WebUI
Since Ollama itself is an API server, you'll want a separate chat UI usable from a browser. Open WebUI is the most popular choice.
Preparing the Docker Runtime
There are several options for using Docker on macOS.
| Tool | Cost | Features |
|---|---|---|
| Docker Desktop | Free for personal use, paid for commercial use (250+ employees or $10M+ revenue) | Official GUI |
| OrbStack | Free for personal use, $8/month for commercial use (revenue $10K+) | Lightweight, fast, Apple Silicon optimized |
| Colima | Completely free (MIT License) | CLI-based, no license issues for commercial use |
| Podman Desktop | Completely free (Apache 2.0) | Developed by Red Hat, has GUI |
Both Docker Desktop and OrbStack require license fees for commercial use. Be careful if using for business purposes. This time I chose Colima, which can be used without worrying about licensing.
brew install colima docker
colima start
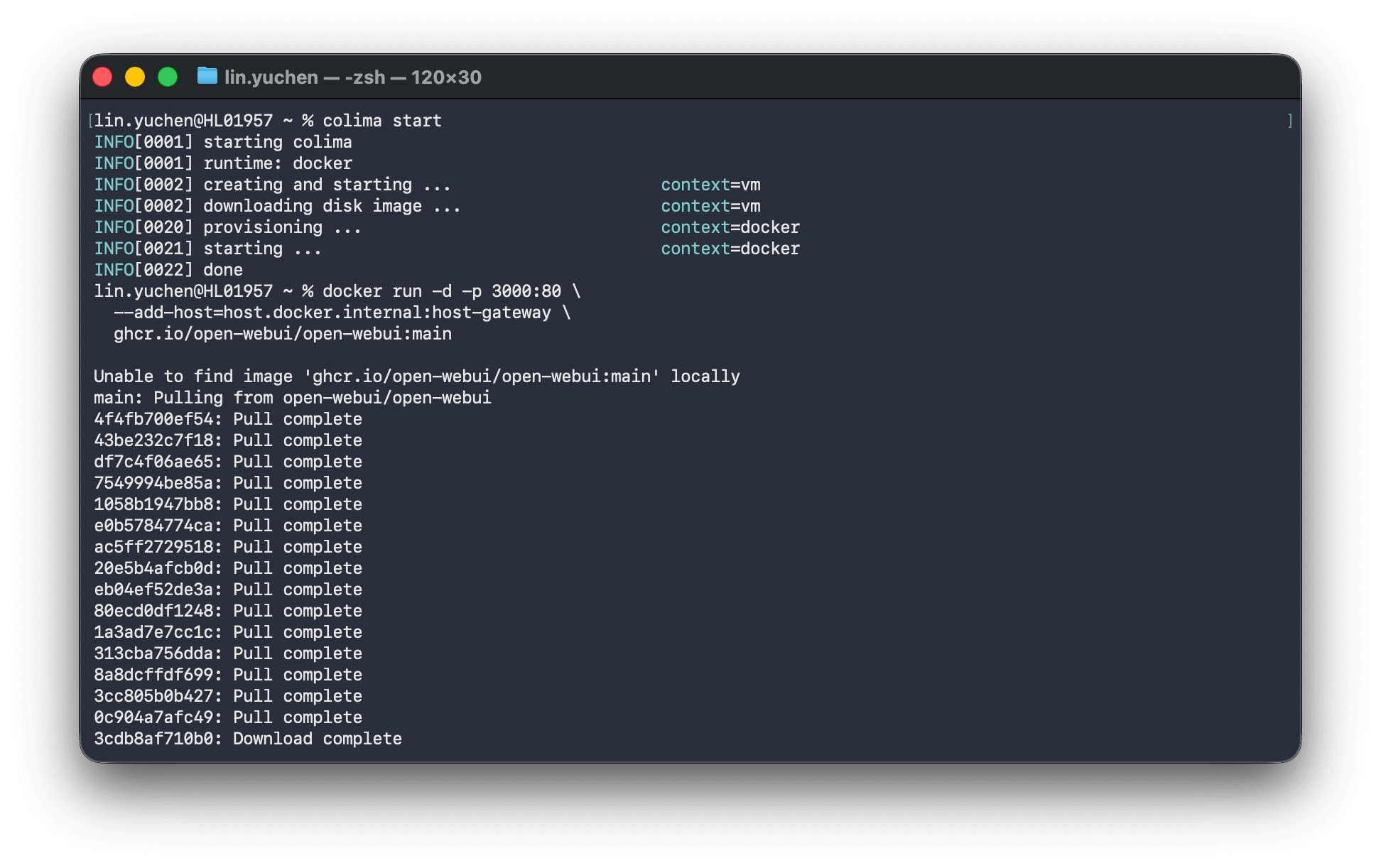
colima start launches a Linux VM where Docker Engine becomes available. After that, regular docker commands work as-is.
Starting Open WebUI
docker run -d --network=host \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
ghcr.io/open-webui/open-webui:main
Using --network=host allows the container to directly share the host machine's network, ensuring reliable connection to Ollama. In this case, the Open WebUI port will be 8080.
Opening http://localhost:8080 in your browser will display a ChatGPT-style interface. Create an account on first access.
Configuring the Ollama Connection
On first launch, the model selector may show "No models available." This means Open WebUI cannot find the Ollama endpoint.
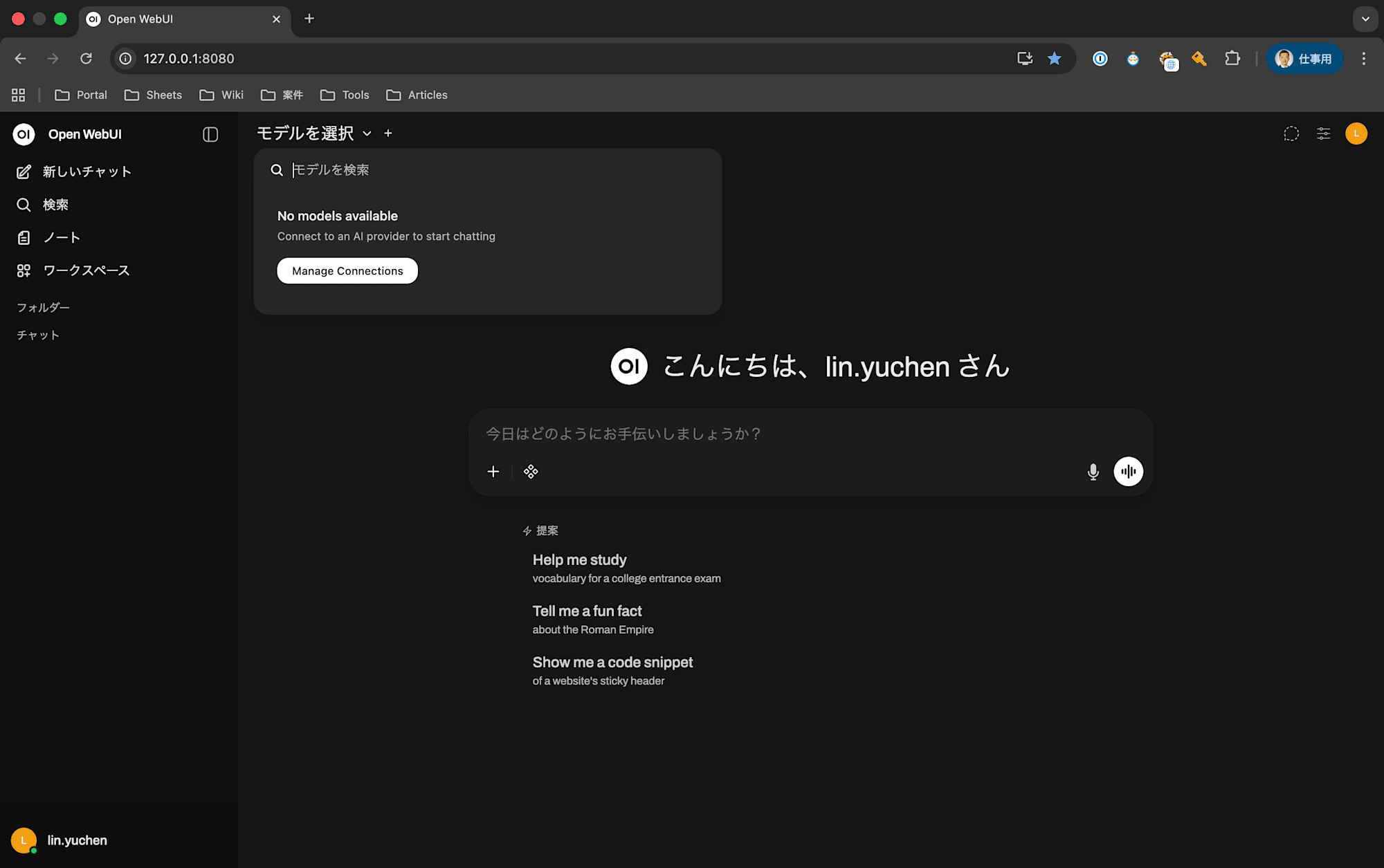
- Click "Manage Connections" at the top of the screen
- Set the Ollama API URL to:
http://host.docker.internal:11434 - Once the connection is confirmed,
gemma4:e4bwill appear in the model list
Once connected, you can interact with Gemma 4 through the ChatGPT-style interface.
Step 6: Real-World Application — A Text-to-SQL Agent
The true value of a local LLM becomes clear when used in an actual project. Here I'll introduce a use case with a Text-to-SQL agent that generates SQL from natural language Japanese.
Project Overview
The system takes natural language questions about Japanese financial data (area-based P&L, sales by product category), generates SQL, executes it, and returns results.
User: "What are the cumulative sales for Kanto in 2025?"
↓
Gemma 4 (E4B) generates SQL
↓
SELECT SUM(売上_実績) FROM area_pl WHERE エリア = '関東' AND 年度 = 2025
↓
Result: 12,345 million yen
Integrating the Ollama Python Client
Calling Ollama from Python is very straightforward.
pip install ollama
import ollama
MODEL = "gemma4:e4b"
response = ollama.chat(
model=MODEL,
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "What are the Kanto sales?"},
],
)
sql = response.message.content.strip()
The ollama library connects to localhost:11434 by default, so no environment variables or URL configuration is needed.
Including Schema Information in the Prompt
To get the LLM to generate accurate SQL, table definitions and column names are dynamically embedded in the system prompt.
from functools import lru_cache
@lru_cache
def build_system_prompt():
return f"""You are a SQL expert.
Based on the table definitions below, generate only a DuckDB-compatible SELECT statement for the user's question.
{schema_definitions}
Rules:
- Generate only SELECT statements (INSERT, UPDATE, DELETE are prohibited)
- Use table names and column names in Japanese as-is
"""
Why We Chose a Local LLM
| Aspect | Local (Ollama) | Cloud API |
|---|---|---|
| Cost | Free | Token-based billing |
| Latency | No network needed | API round-trip required |
| Privacy | Data stays local | Transmission required |
| Quality | E4B class | Claude/GPT-4 class |
| Setup | Just start Ollama | API key management required |
During the PoC phase, a local LLM that allows zero-cost, fast iteration was ideal. Since the design switches to a cloud API (Claude, etc.) for production, migration is as simple as replacing ollama.chat() with the Anthropic SDK.
Summary
Here's a summary of the process of running Gemma 4 locally on a MacBook (16GB).
- Apple Silicon's unified memory allows approximately 70-75% for the model (about 11.8GB for 16GB)
- MoE active parameter count ≠ required memory. The 26B MoE requires 18.8GB and couldn't run on a 16GB machine
- Gemma 4 E4B is the sweet spot for 16GB machines. It fits within 5-6GB and responses are fast
- Ollama + Open WebUI lets you build a complete chat UI without writing code
- Easy integration in real projects via the
ollamaPython library
Local LLMs are ideal for PoC and early-stage prototyping. No API key management, no token billing, and you can iterate quickly while maintaining privacy. Even on a 16GB MacBook, choosing the right model is enough to build a sufficiently practical environment.
