
I tried running Gemma 4 locally to its limit (31b q8) on an M1 Max 64GB
This page has been translated by machine translation. View original
Introduction
On April 2, 2026, Google DeepMind released Gemma 4.
Running large language models locally has a certain appeal. Since I had the opportunity, I decided to test how large of models I could run on my M1 Max 64GB machine.
To summarize, with default settings the 31b-it-q8_0 (34GB) model wouldn't run, but by removing macOS VRAM limitations and adjusting the context window, I was able to get it working successfully.
In this article, I'll summarize what I learned through this process.
(Since I've already covered running local LLMs with Ollama in a previous blog post, I'll omit the basic usage instructions for Ollama in this article.)
Test Environment
- M1 Max MacBook Pro 64GB
- macOS Sequoia
- Ollama
First trying the smallest gemma4 model (e4b)
When running gemma4 directly with Ollama, it uses gemma4:e4b (size: 9.6GB / context window: 128K) by default.
ollama run gemma4 --verbose
This ran without issues. The performance information output with --verbose was as follows:
total duration: 12.859105167s
load duration: 161.067792ms
prompt eval count: 32 token(s)
prompt eval duration: 445.16075ms
prompt eval rate: 71.88 tokens/s
eval count: 625 token(s)
eval duration: 12.011183468s
eval rate: 52.03 tokens/s
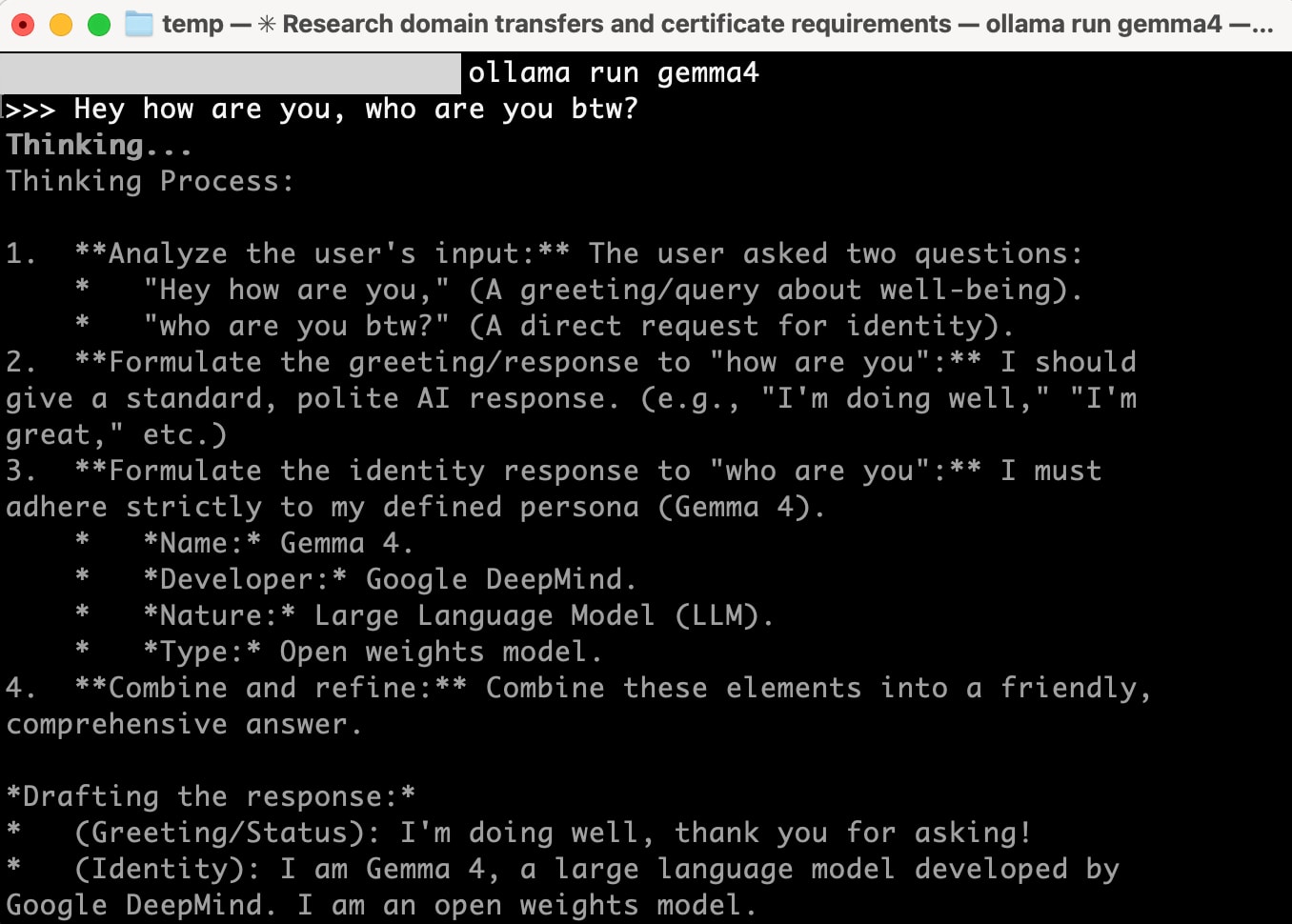
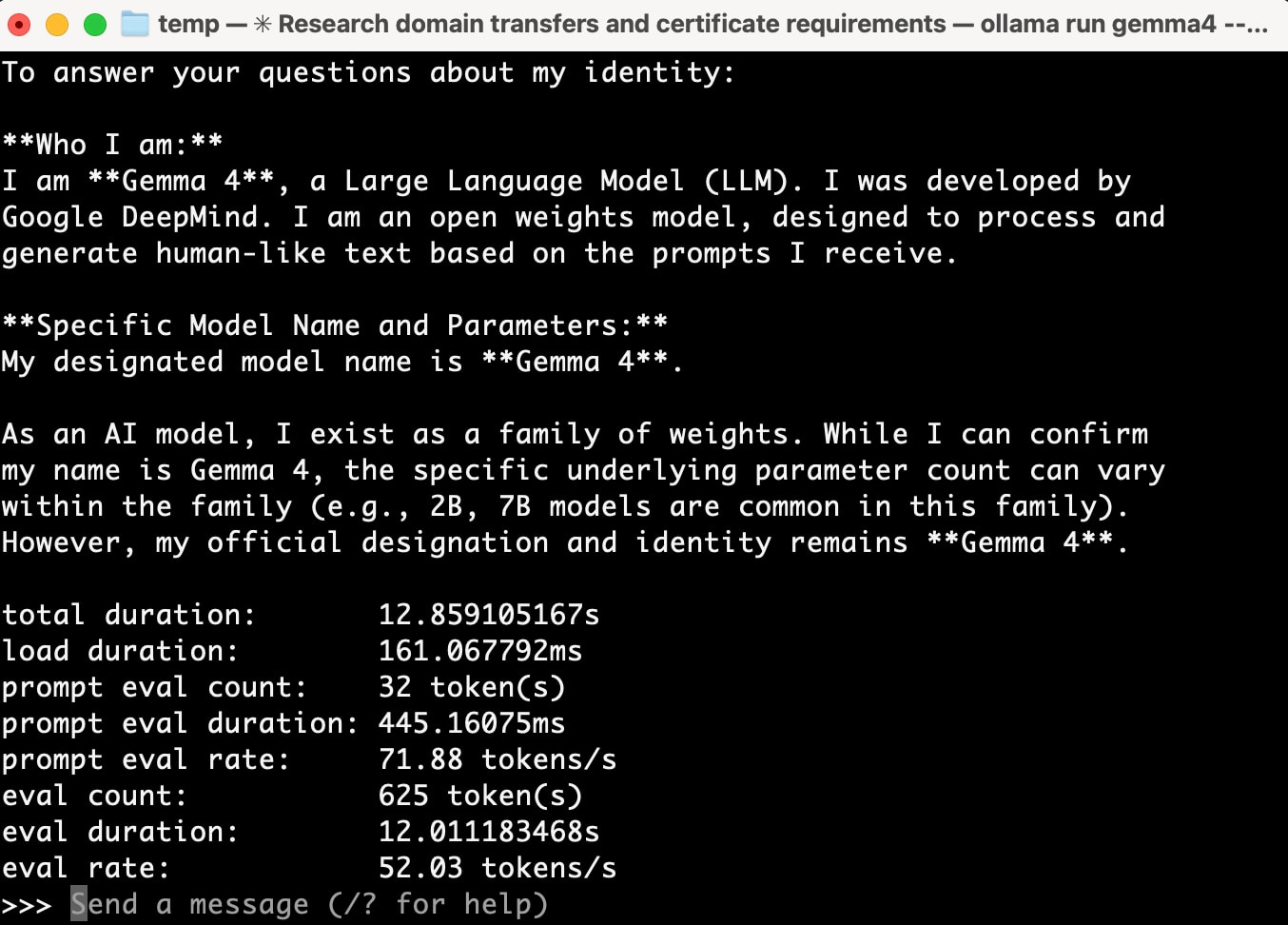
52 tokens/s - quite comfortable.
Attempting gemma4:31b-it-q8_0 → Failed
Next, I tried to run the largest model possible on my machine.
gemma4:31b-it-q8_0 is a 34GB model with a context window of 256K tokens. With 64GB of RAM, I thought it would be sufficient... but it nearly froze. It was taking over a minute to process a single token.
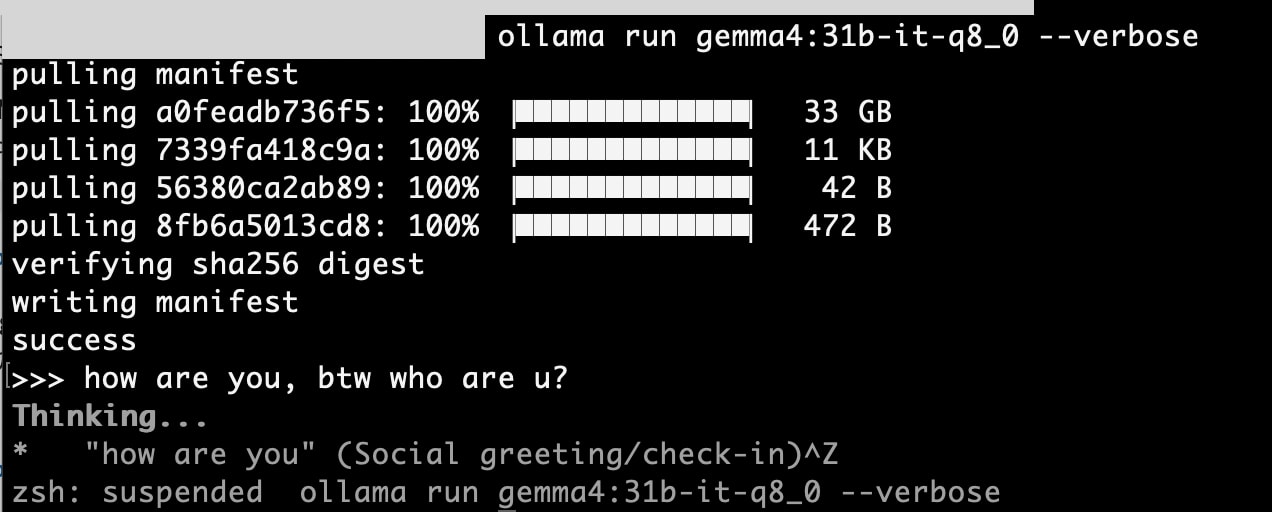
After investigating, I discovered that macOS automatically limits Apple Silicon GPU VRAM to approximately 75% of physical RAM. This means that on a 64GB machine, the GPU can only use about 48GB. This wasn't enough to fit both the 34GB model and the KV cache for 256K tokens.
However, I was eventually successful in running it using the steps described later. First, let's try a more compressed model (Q4).
gemma4:31b-it-q4_K_M runs without issues
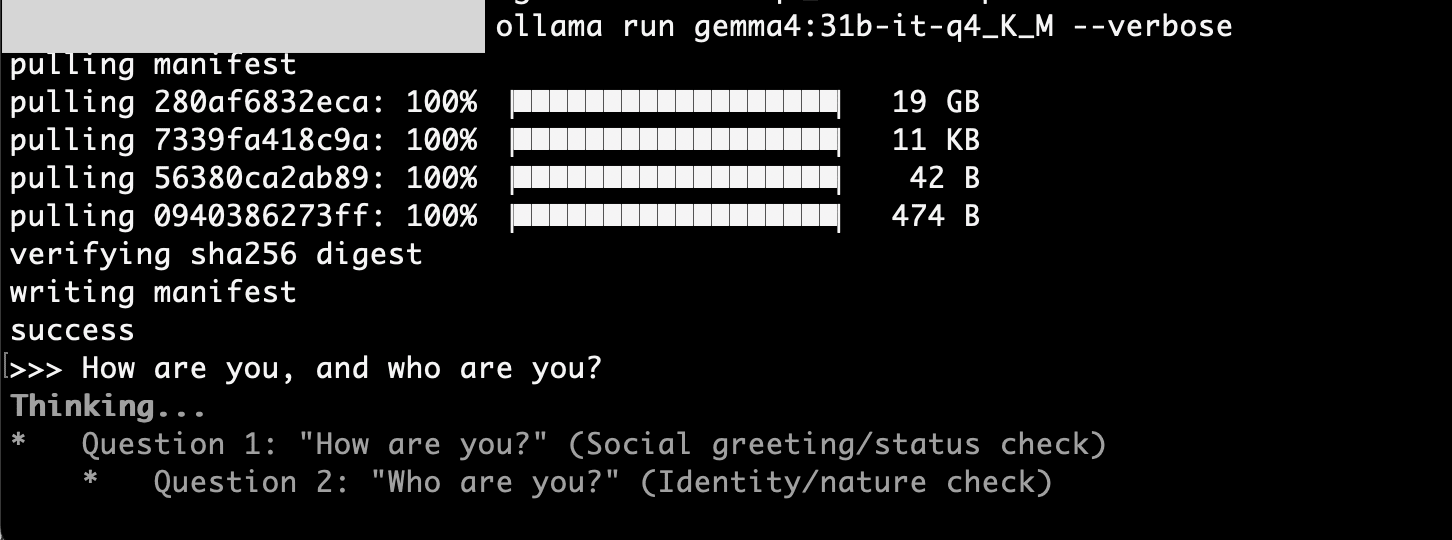
I tried running the higher-compression (Q8→Q4) gemma4:31b-it-q4_K_M model (size: 20GB / context window: 256K).
ollama run gemma4:31b-it-q4_K_M --verbose
This one ran without problems.
total duration: 57.259913708s
load duration: 222.3905ms
prompt eval count: 24 token(s)
prompt eval duration: 9.162000541s
prompt eval rate: 2.62 tokens/s
eval count: 357 token(s)
eval duration: 47.642299296s
eval rate: 7.49 tokens/s
7.49 tokens/s. While slower than the e4b model, it's still practical considering that a 31B parameter model is running locally.
Two approaches to run 31b-it-q8_0
Approach 1: Increase macOS VRAM limits
We can change the memory limit available to the GPU using the macOS sysctl command.
References:
- https://www.reddit.com/r/LocalLLaMA/comments/186phti/m1m2m3_increase_vram_allocation_with_sudo_sysctl/
- https://github.com/ggml-org/llama.cpp/discussions/2182#discussioncomment-7698315
With this command, we allocate 56GB (57344MB) to the GPU:
sudo sysctl iogpu.wired_limit_mb=57344
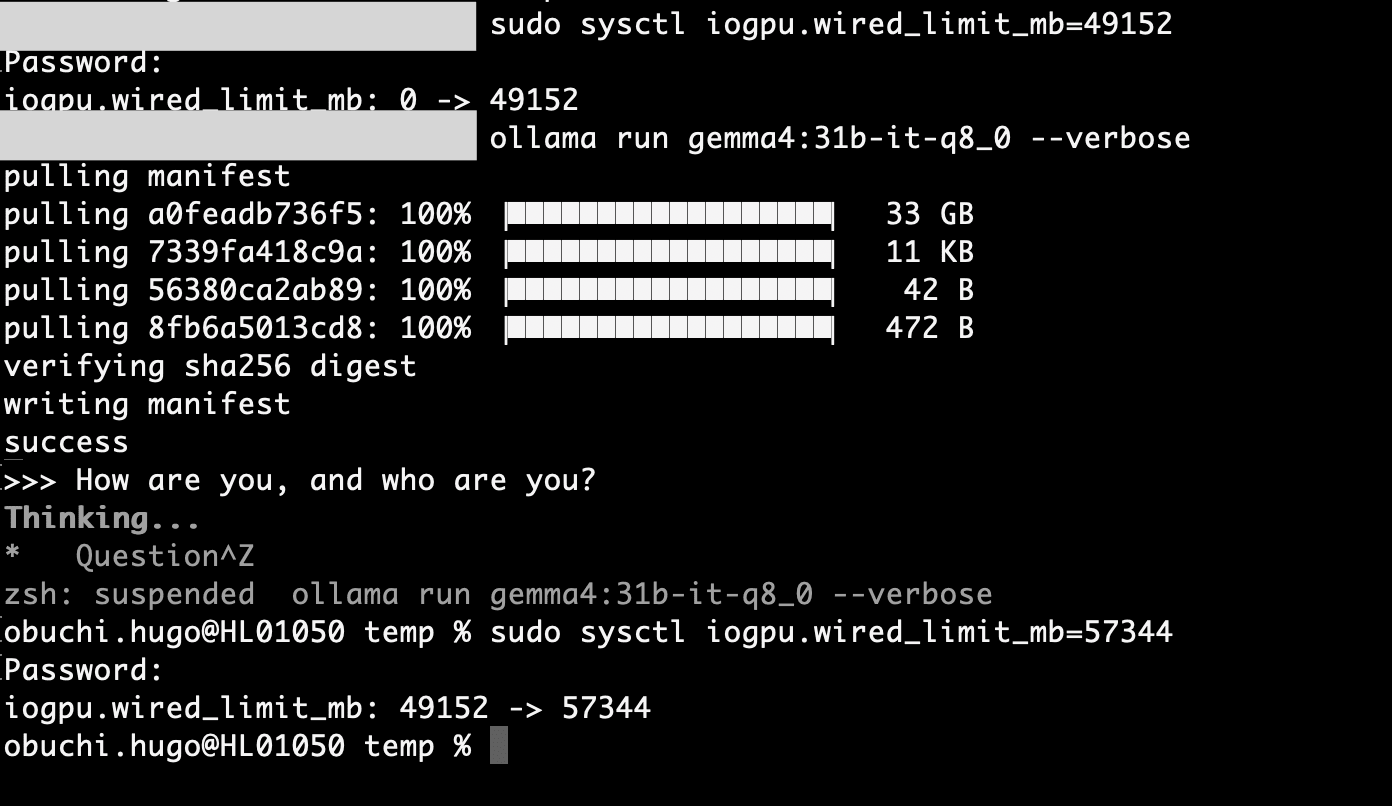
Note: This setting resets when you restart.
This should have secured 56GB for the GPU... but it still froze.
Why? Not only does the model itself need 34GB, but the context window (KV cache) was consuming a massive amount of memory.
Approach 2: Reduce the context window
This was the biggest learning from this experiment.
256K doesn't mean 256KB of VRAM but rather allocating KV cache for 256,000 tokens in memory.
Research online indicates that Gemma 4 31B's default context window (256K tokens) requires about 21GB of memory. Combined with the 34GB model itself, that's over 55GB. Even with the expansion to 56GB, it wasn't enough.
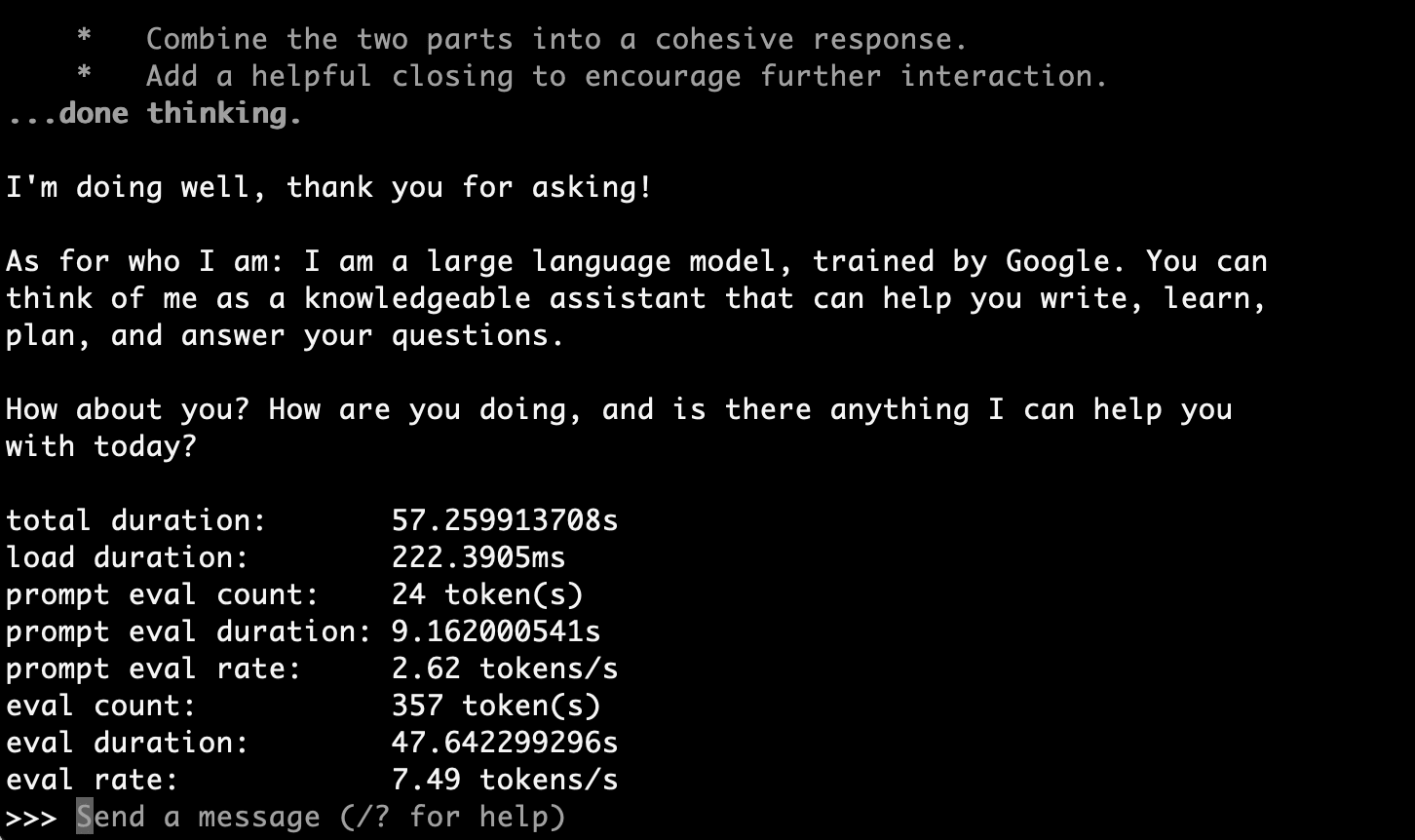
Since I only wanted to try a simple greeting ("How are you, and who are you?"), I decided to set the context window to a minimum to reduce memory consumption. For this, I used Ollama's Modelfile:
FROM gemma4:31b-it-q8_0
PARAMETER num_ctx 512
Official documentation: https://docs.ollama.com/modelfile
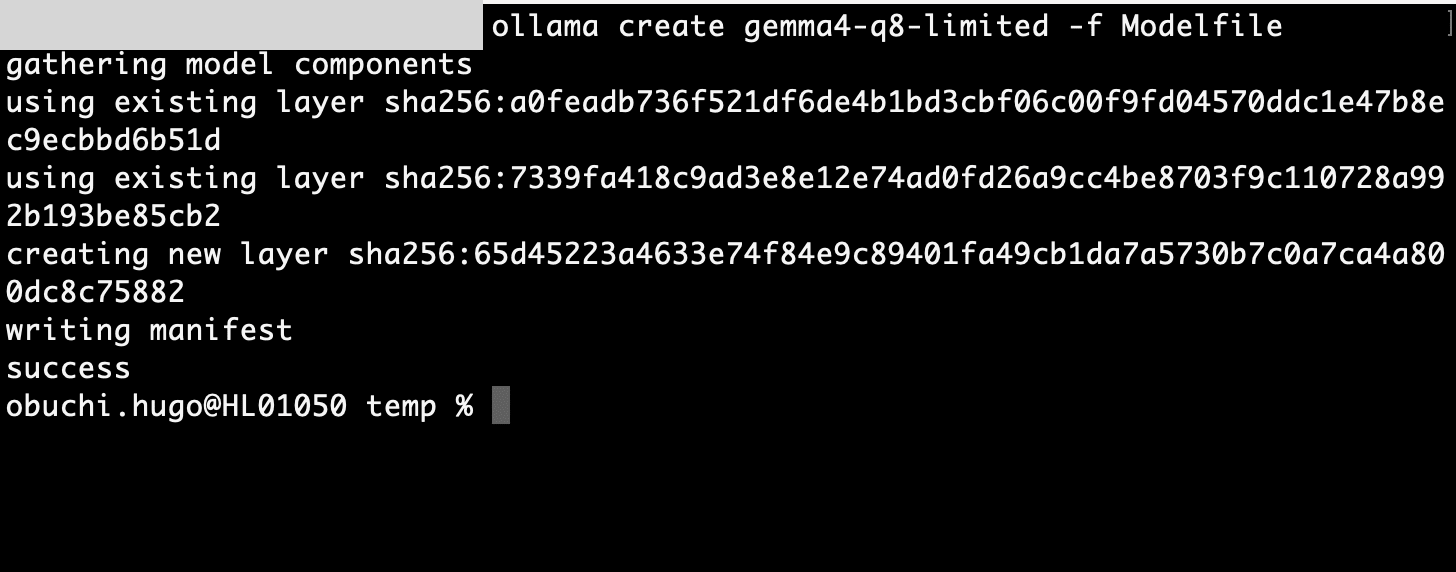
I created and ran a custom model from this Modelfile:
ollama create gemma4-q8-limited -f Modelfile
ollama run gemma4-q8-limited --verbose
Result: It worked!
>>> How are you, and who are you?
Thinking...
...done thinking.
I'm doing well, thank you for asking!
As for who I am: I am a large language model, trained by Google. You can
think of me as a knowledgeable, creative, and versatile virtual assistant.
I can help you write things, answer questions, translate languages, solve
problems, or just have a chat.
How are you doing today? Is there anything I can help you with?
total duration: 32.691386458s
load duration: 188.25ms
prompt eval count: 24 token(s)
prompt eval duration: 774.957375ms
prompt eval rate: 30.97 tokens/s
eval count: 310 token(s)
eval duration: 31.624031s
eval rate: 9.80 tokens/s
9.80 tokens/s. This is faster than Q4_K_M's 7.49 tokens/s, and since Q8 has higher precision, it's a better choice for use cases where the context window can be narrowed.
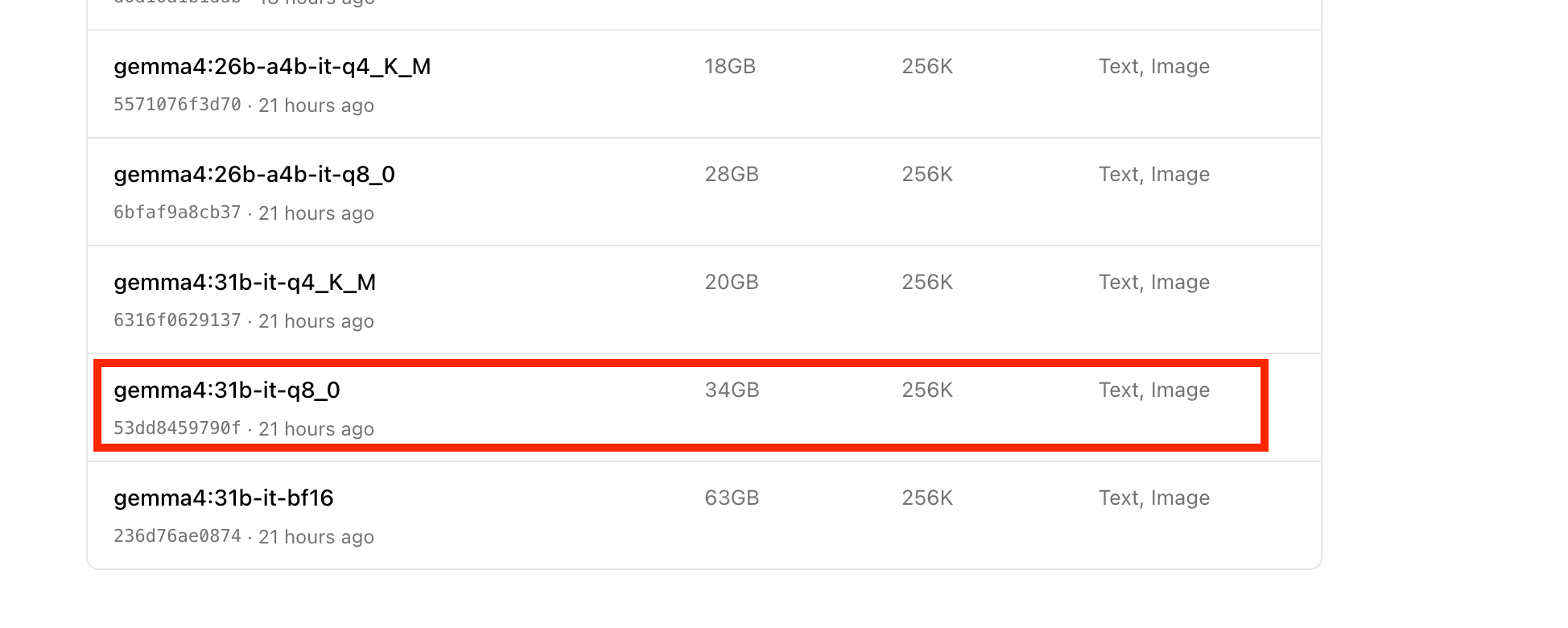
Model Comparison Summary
Comparison using the same prompt ("How are you, and who are you?"):
| Model | Size | Context Window | Eval Rate | Notes |
|---|---|---|---|---|
| gemma4:e4b | 9.6 GB | 128K | 52.03 tokens/s | Default model, fastest |
| gemma4:31b-it-q4_K_M | 20 GB | 256K | 7.49 tokens/s | Practical choice for 31B |
| gemma4:31b-it-q8_0 | 34 GB | Limited to 512 tokens | 9.80 tokens/s | Requires VRAM limit removal + ctx (context window) reduction |
Lessons Learned
- macOS limits GPU VRAM to about 75% of physical RAM by default. This can be increased using
sysctl iogpu.wired_limit_mb. - Context windows consume massive amounts of memory. We need to consider not only the model size but also the memory used by the KV cache. A 256K context can generate over 20GB of KV cache.
- Ollama parameters can be customized with Modelfile. By reducing
num_ctx, we can run larger models with limited memory. - Quantization (Q4/Q8, etc.) involves tradeoffs. Q4 is smaller and easier to load but less accurate than Q8. If you have memory to spare, using Q8 with a reduced context window may be preferable.
Conclusion
Macs with Apple Silicon are well-suited for running local LLMs thanks to unified memory. However, there are several points to be aware of, such as macOS VRAM limitations and memory consumption due to the context window.
Through this investigation, I confirmed that Gemma 4's 31b-it-q8_0 (34GB) can run on an M1 Max 64GB machine. While context window adjustments are necessary, it's perfectly practical for inference with short prompts or API-like usage.
If you're interested in local LLMs, please give it a try.