
Let's try using Tsumiki's Kairo command to create an automatic description generator tool for BigQuery tables

I'm Suto from the Data Business Division.
Classmethod has released "Tsumiki," an AI-assisted test-driven development framework.
I want to try using it, so I'll give it a go!
Tsumiki is designed to be used with Claude Code. Therefore, I will install the "Claude Code for VSCode" extension and run Claude Code (Tsumiki) within the Visual Studio Code environment.
About the AI-assisted test-driven development framework "Tsumiki"
Tsumiki uses Claude Code to provide a systematic development process from requirements definition to design, task breakdown, and implementation. The main commands available are as follows:
Kairo commands (comprehensive development flow)
- kairo-requirements - Requirements definition
- kairo-design - Design document generation
- kairo-tasks - Task breakdown
- kairo-task-verify - Task content verification
- kairo-implement - Implementation execution
TDD commands (individual execution)
- tdd-requirements - TDD requirements definition
- tdd-testcases - Test case creation
- tdd-red - Test implementation (Red)
- tdd-green - Minimal implementation (Green)
- tdd-refactor - Refactoring
- tdd-verify-complete - TDD completion verification
Reverse Engineering commands
- rev-tasks - Reverse generation of task lists from existing code
- rev-design - Reverse generation of design documents from existing code
- rev-specs - Reverse generation of test specifications from existing code
- rev-requirements - Reverse generation of requirements documents from existing code
DIRECT commands (used when a TASK is identified as DIRECT)
- direct-setup - Execute setup for DIRECT tasks
- direct-verify - Verify and test configurations executed in DIRECT tasks
Since this is my first attempt, I'll keep it simple and see what resources can be generated from requirements definition (kairo-requirements) to implementation (kairo-implement), with minimal human intervention or modifications.
Let's try it
Assuming Claude Code is already installed, I'll follow the README at the URL below to install Tsumiki.
As mentioned in the title, I'll try to build a "CLI tool that automatically generates BigQuery table descriptions."### Requirements Document Creation (/kairo-requirements)
Let's run the /kairo-requirements command in Claude Code, which prompts us to enter an overview of the requirements.
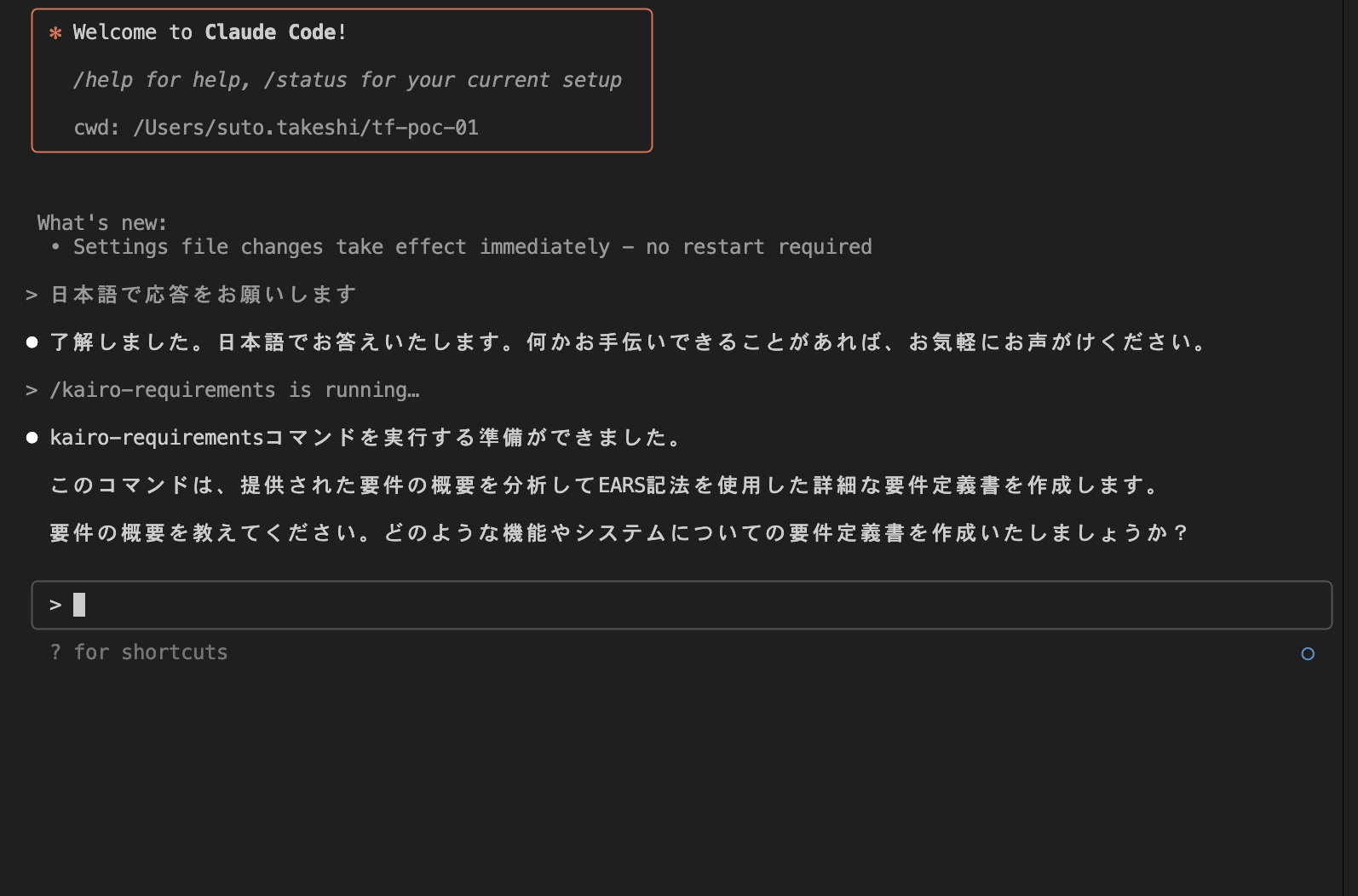
While most AI-generation articles show what can be created from just a single sentence like "make an app that can do X" or "create a tool that can do Y", I'd like to provide more detailed requirements in bullet points to see what can be produced. I've entered the following text for execution.
※I'm keeping it relatively brief because writing too much in the prompt can reduce accuracy. If you need to convey more information, it's better to write it in a text file and have it read from there.
I want to build a CLI tool that automatically adds Descriptions to existing BigQuery tables. The requirements are as follows:
・Using natural language input, specify the existing BigQuery table name and a Google Spreadsheet containing information about the table
・After retrieving the DDL of the specified table, use the Gemini API to automatically generate descriptions for tables and columns based on the DDL content and spreadsheet information
・Generate SQL with DDL that includes the automatically generated descriptions
・Create a pull request on GitHub with the generated DDL
When the command completed, a requirements document was created in the docs/spec folder as follows:
requirements_document.md
# BigQuery Table Description Auto-Generation CLI Tool Requirements Document
## Overview
A CLI tool that automates the process of generating descriptions for existing BigQuery tables and their columns using natural language input and Google Spreadsheet information, leveraging the Gemini API, and creating GitHub pull requests with updated DDL.
## User Stories
### Story 1: Automatic Table Description Generation
- **As a** Data Engineer
- **I want to** efficiently add Description information to existing BigQuery tables
- **So that** I can improve table comprehensibility and maintainability, promoting data asset utilization within the team
### Story 2: Easy Operation with Natural Language
- **As a** Data Analyst
- **I want to** specify table information using natural language without complex configuration
- **So that** I can document tables without knowing technical details
### Story 3: Workflow Integration through Automatic PR Creation
- **As a** Project Manager
- **I want to** integrate Description update tasks into the code review workflow
- **So that** I can ensure transparency and quality control of changes
## Functional Requirements (EARS Format)
### Normal Requirements
- REQ-001: The system must accept BigQuery table names via natural language input
- REQ-002: The system must accept Google Spreadsheet URL or ID
- REQ-003: The system must retrieve the DDL for the specified table via BigQuery API
- REQ-004: The system must use Gemini API to automatically generate Description text
- REQ-005: The system must generate Descriptions in Japanese
- REQ-006: The system must output DDL SQL containing the generated Descriptions
- REQ-007: The system must automatically create a pull request on GitHub
### Conditional Requirements
- REQ-101: If the table does not exist, the system must display an error message and terminate processing
- REQ-102: If the spreadsheet is not accessible, the system must execute an alternative method or error handling
- REQ-103: If the Gemini API call fails, the system must execute a retry mechanism
- REQ-104: If GitHub API access fails, the system must save the generated DDL as a local file
### State Requirements
- REQ-201: When authentication credentials are not configured, the system must display authentication setup guidance
- REQ-202: When DDL is already generated, the system must provide a preview display and confirmation prompt
### Optional Requirements
- REQ-301: The system may provide functionality to edit generated Descriptions
- REQ-302: The system may provide batch processing functionality for multiple tables
- REQ-303: The system may provide customization features for Description generation rules
### Constraint Requirements
- REQ-401: The system must handle Google Cloud authentication appropriately
- REQ-402: The system must consider Gemini API usage limits
- REQ-403: The system must consider GitHub API rate limits
## Non-Functional Requirements
### Performance
- NFR-001: DDL retrieval must complete within 30 seconds
- NFR-002: Description generation must complete within 2 minutes per table
- NFR-003: GitHub PR creation must complete within 1 minute
### Security
- NFR-101: The system must securely manage authentication credentials
- NFR-102: The system must not output API keys to logs
- NFR-103: The system must configure access rights following the principle of least privilege
### Usability
- NFR-201: The system must provide an intuitive command line interface
- NFR-202: The system must clearly display processing status to users
- NFR-203: The system must display useful error messages when errors occur
### Availability
- NFR-301: The system must have resilience against temporary network failures
- NFR-302: The system must provide appropriate recovery functionality for API call failures
### Compatibility
- NFR-401: The system must work on macOS, Linux, and Windows environments
- NFR-402: The system must work with Python 3.8 or higher
## Edge Cases
### Error Handling
- EDGE-001: Handling cases where there are no permissions for the BigQuery table
- EDGE-002: Handling cases where the spreadsheet is empty or in an invalid format
- EDGE-003: Handling cases where the Gemini API response is abnormal
- EDGE-004: Handling cases where there are no write permissions to the GitHub repository
- EDGE-005: Handling cases where network connection is unstable
### Boundary Values
- EDGE-101: Processing very large tables (1000+ columns)
- EDGE-102: Processing table names and column names containing special characters
- EDGE-103: Handling character limit per Gemini API request
- EDGE-104: Processing in mixed Japanese and English environments
### Data Consistency
- EDGE-201: Processing policy for tables with existing Descriptions
- EDGE-202: Handling cases where table structure changes during DDL execution
- EDGE-203: Avoiding conflicts when multiple users process the same table simultaneously
## Acceptance Criteria
### Functional Tests
- [ ] Can correctly specify table name and spreadsheet using natural language input
- [ ] Can successfully retrieve DDL using BigQuery API
- [ ] Can generate Description text using Gemini API
- [ ] DDL with generated Descriptions is output with correct syntax
- [ ] Pull requests are created using GitHub API
- [ ] Appropriate errors are displayed when non-existent tables are specified
- [ ] Clear guidance is displayed during authentication errors
### Non-Functional Tests
- [ ] Processing completes within 2 minutes for typical tables (around 50 columns)
- [ ] API keys are not displayed in log files or console output
- [ ] Appropriate retries occur during network failures
- [ ] Works on multiple platforms (macOS, Linux, Windows)
- [ ] Table and column names containing Japanese are processed correctly
### Usability Tests
- [ ] First-time users can complete authentication setup within 10 minutes
- [ ] Command line argument specification is intuitive
- [ ] The next action for users is clear when errors occur
- [ ] Processing progress can be monitored in real-time
## Technical Constraints
### Dependencies
- Google Cloud SDK
- GitHub CLI or GitHub API access token
- Gemini API access permissions
- Python environment (3.8 or higher)
### API Limitations
- BigQuery API: 100,000 requests per day (default)
- Gemini API: 60 requests per minute (depends on subscription plan)
- GitHub API: 5,000 requests per hour for authenticated users
### Configuration Requirements
- Google Cloud authentication credentials in `~/.config/gcloud/`
- GitHub authentication credentials (token or CLI authentication)
- Gemini API key (environment variable or configuration file)
---
**Creation Date:** 2025-08-20
**Version:** 1.0
**File Path:** `docs/spec/bigquery-description-cli-requirements.md`
```:::
Main functional requirements, non-functional requirements, and test requirements were thoroughly considered.
### Design Based on Requirements Document (/kairo-design)
With the requirements document somewhat complete, I proceeded with the design based on it.
I executed the `/kairo-design` command, and after completion, design documents were created in the design folder as shown below.
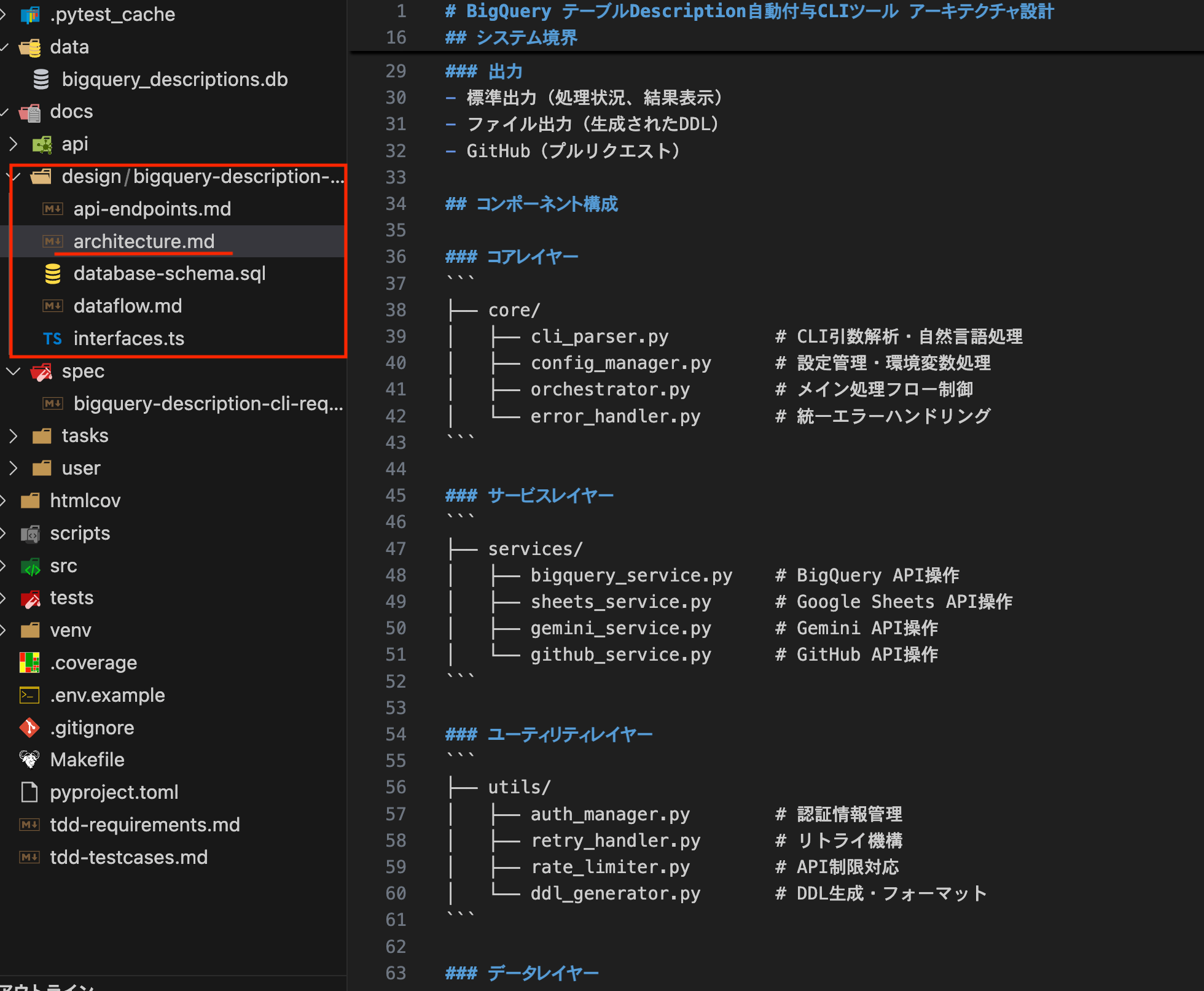
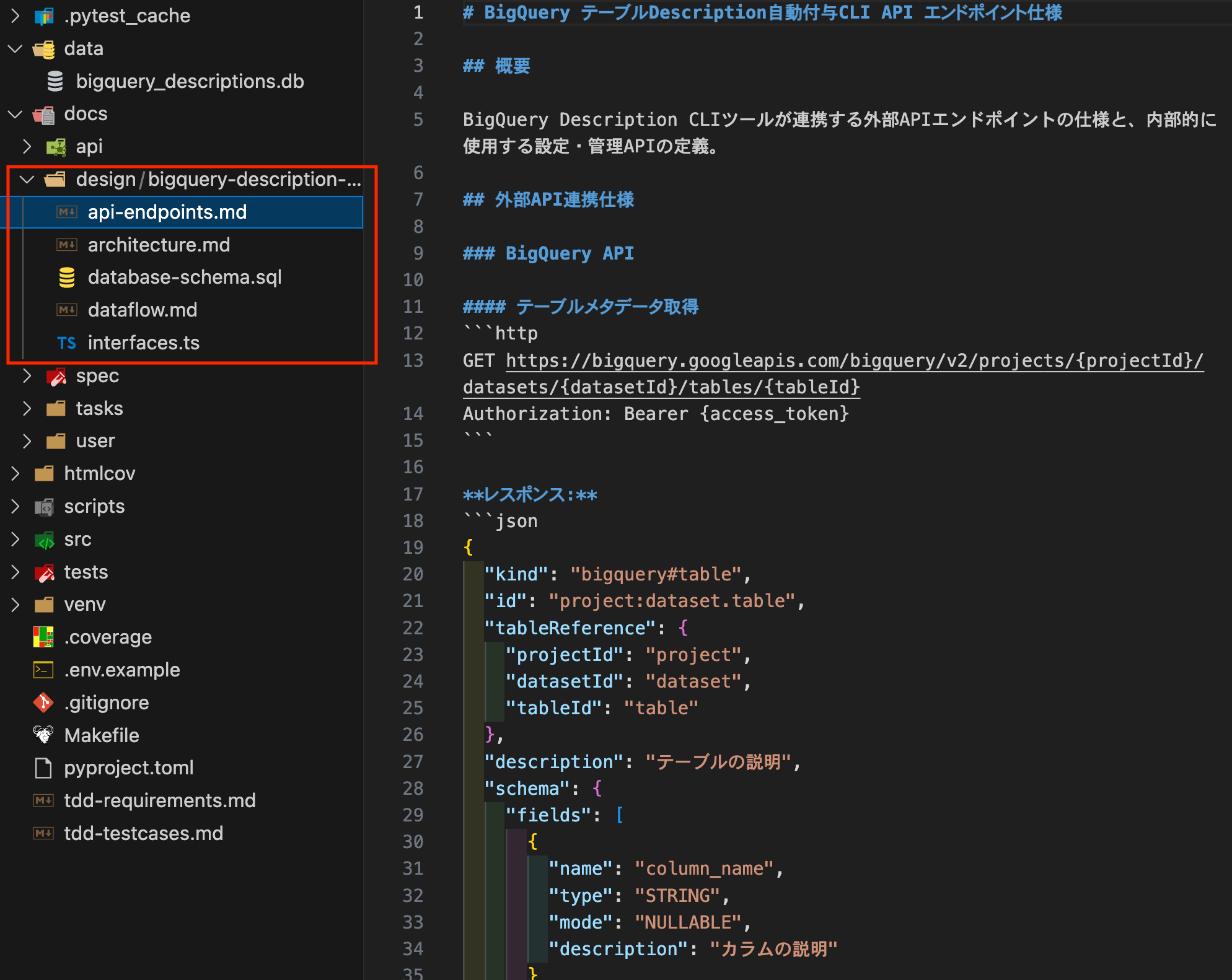
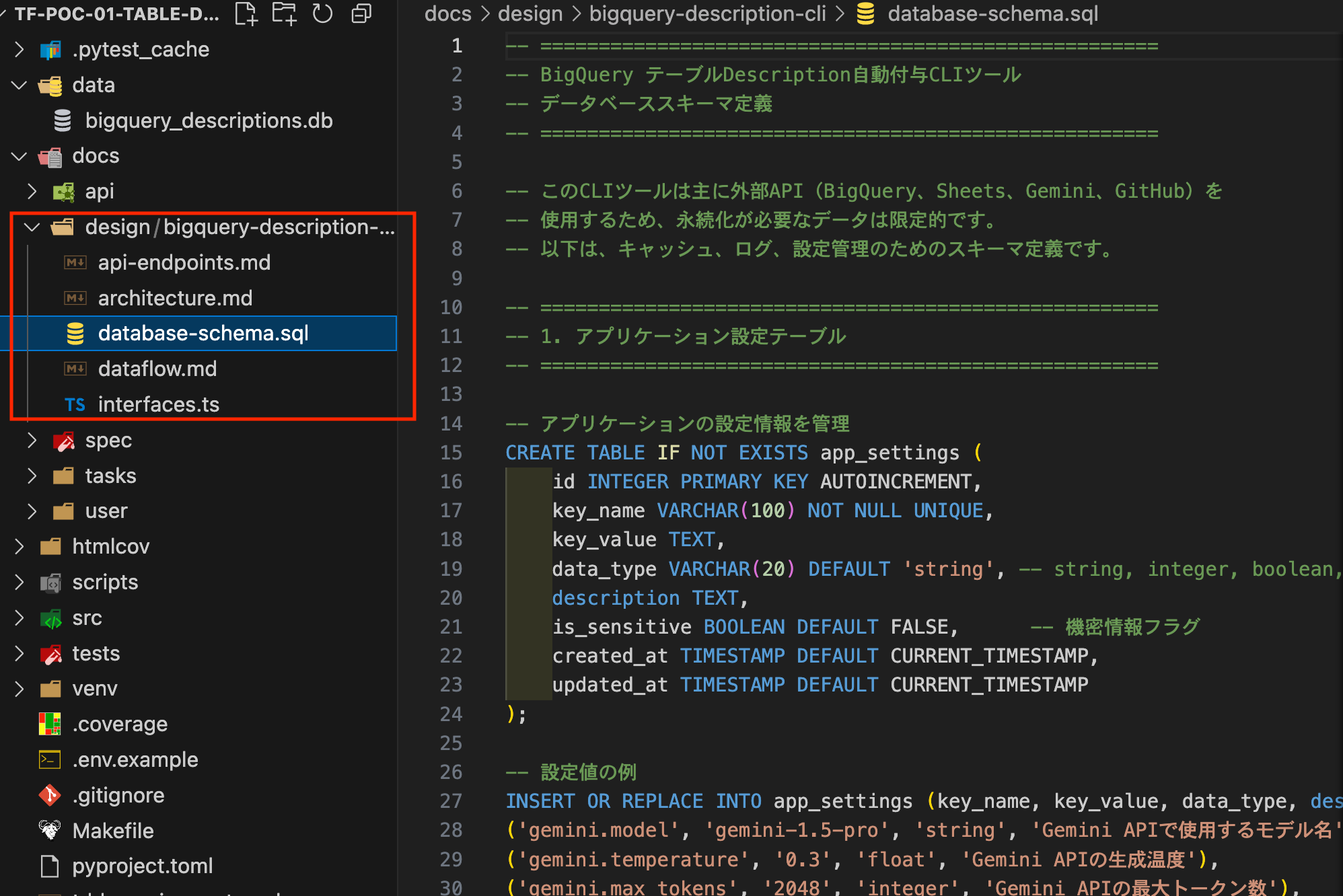
The component structure was thoroughly documented. In addition to the API design, it even included database schema design for tool execution history and log storage. (I initially thought we wouldn't need persistent DB tables since we're just making external API requests, but I was surprised to see that it thoroughly considered things like logs and caching.)
### Task Organization Based on Design Document (/kairo-tasks)
The tool helps prepare for implementation based on the design document.
I executed `/kairo-tasks` to create and organize a task list for resource implementation.
After completion, the following task list was created:
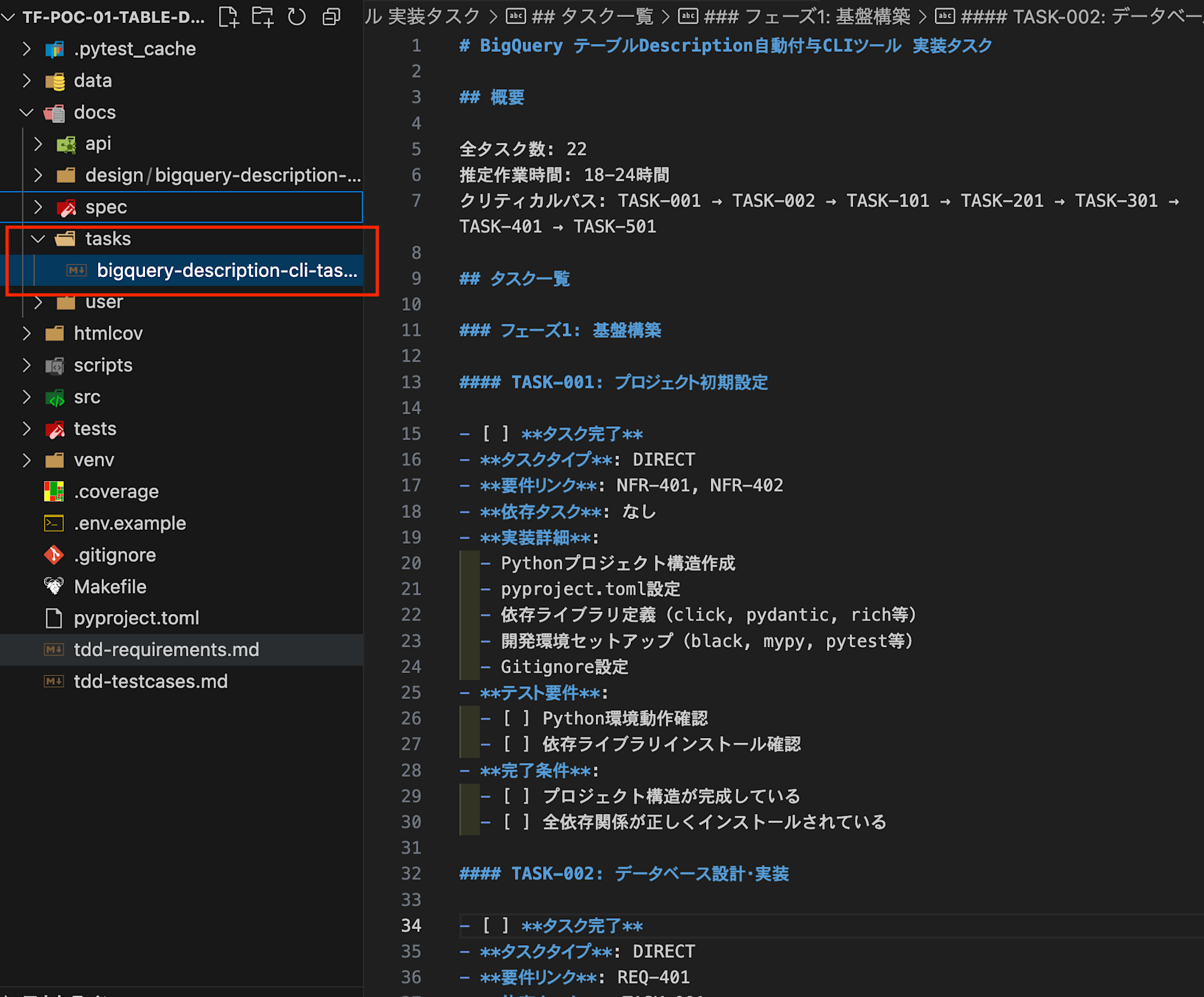
It thoroughly covered everything from installing dependencies to implementing resources and testing. (In this case, there were phases 1-6)
It's impressive that it displays estimated work time and critical paths.### Task Implementation (/kairo-implement)
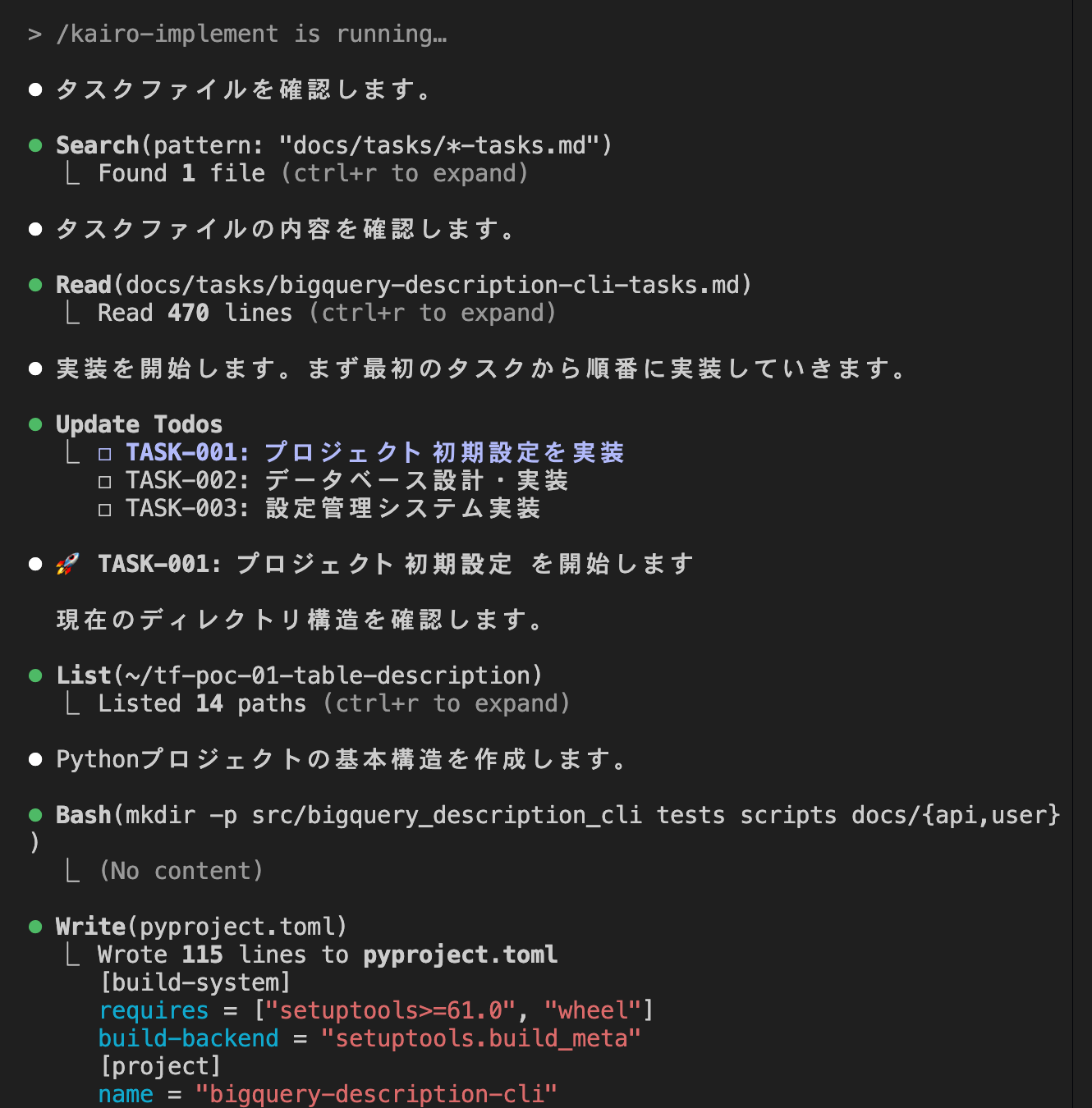
Finally, let's implement the tasks.
When you execute the `/kairo-implements` command, resource implementation begins according to the task list.
It seems to handle everything from installing dependencies, so it also takes care of all the hassle of preparing the development environment.
Even if execution commands result in errors, it continues implementation while fixing those errors.
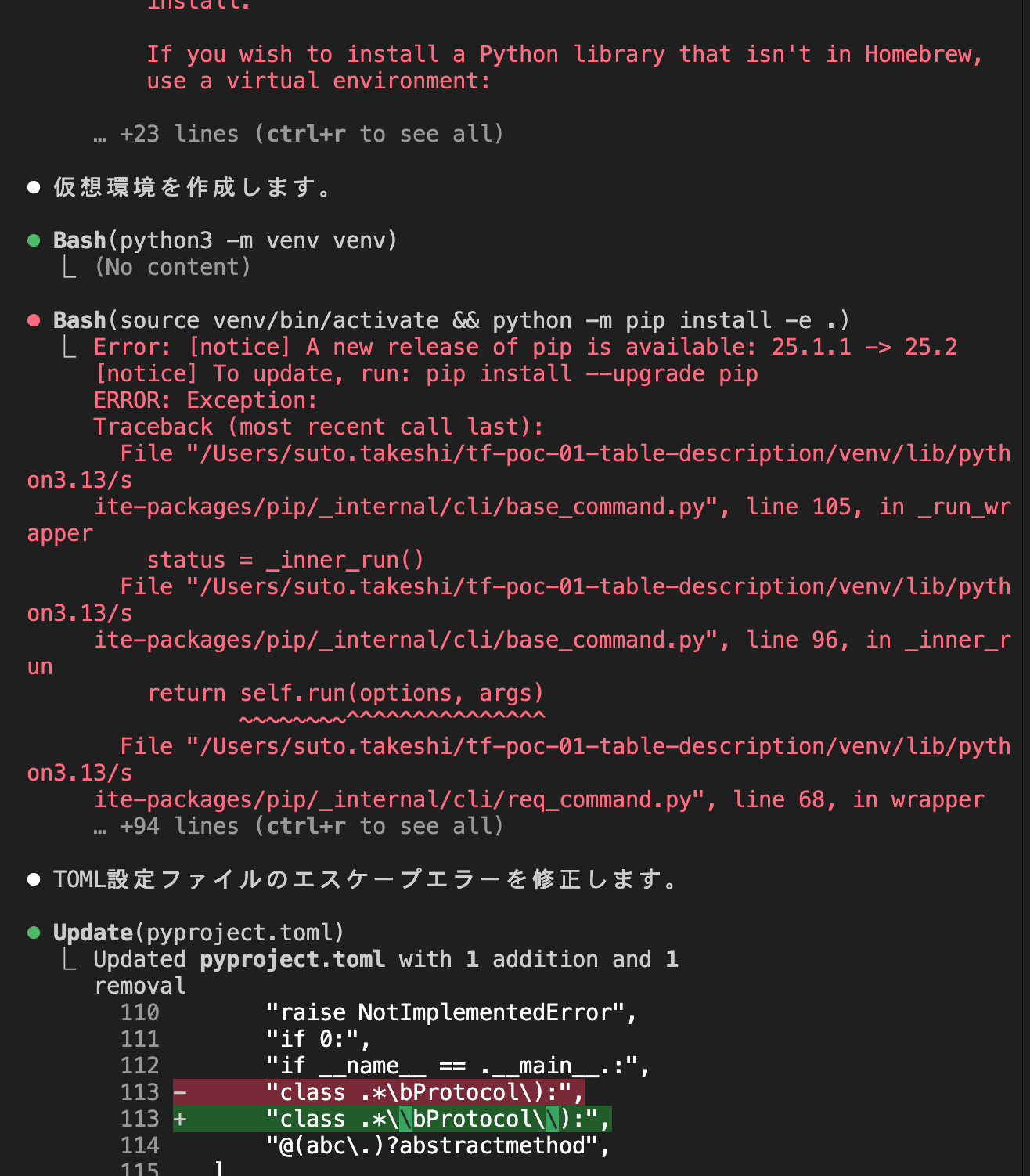
Also, it seemed to be proceeding with implementation while handling necessary and possible test cases at key points, so I felt it was executing more efficiently than a development process that a user would have to think through!
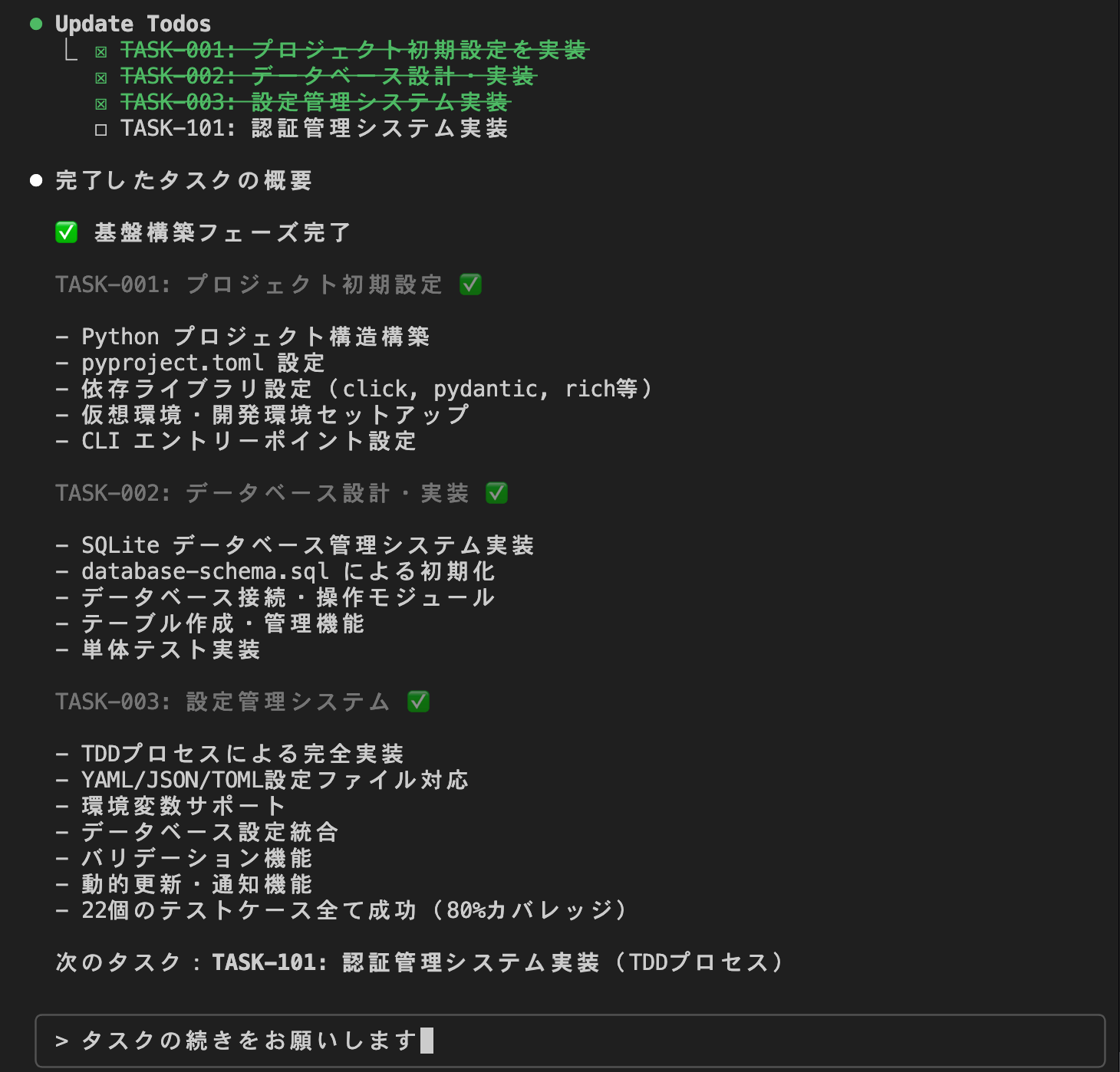
Additionally, completed tasks were checked off, allowing for progress management.
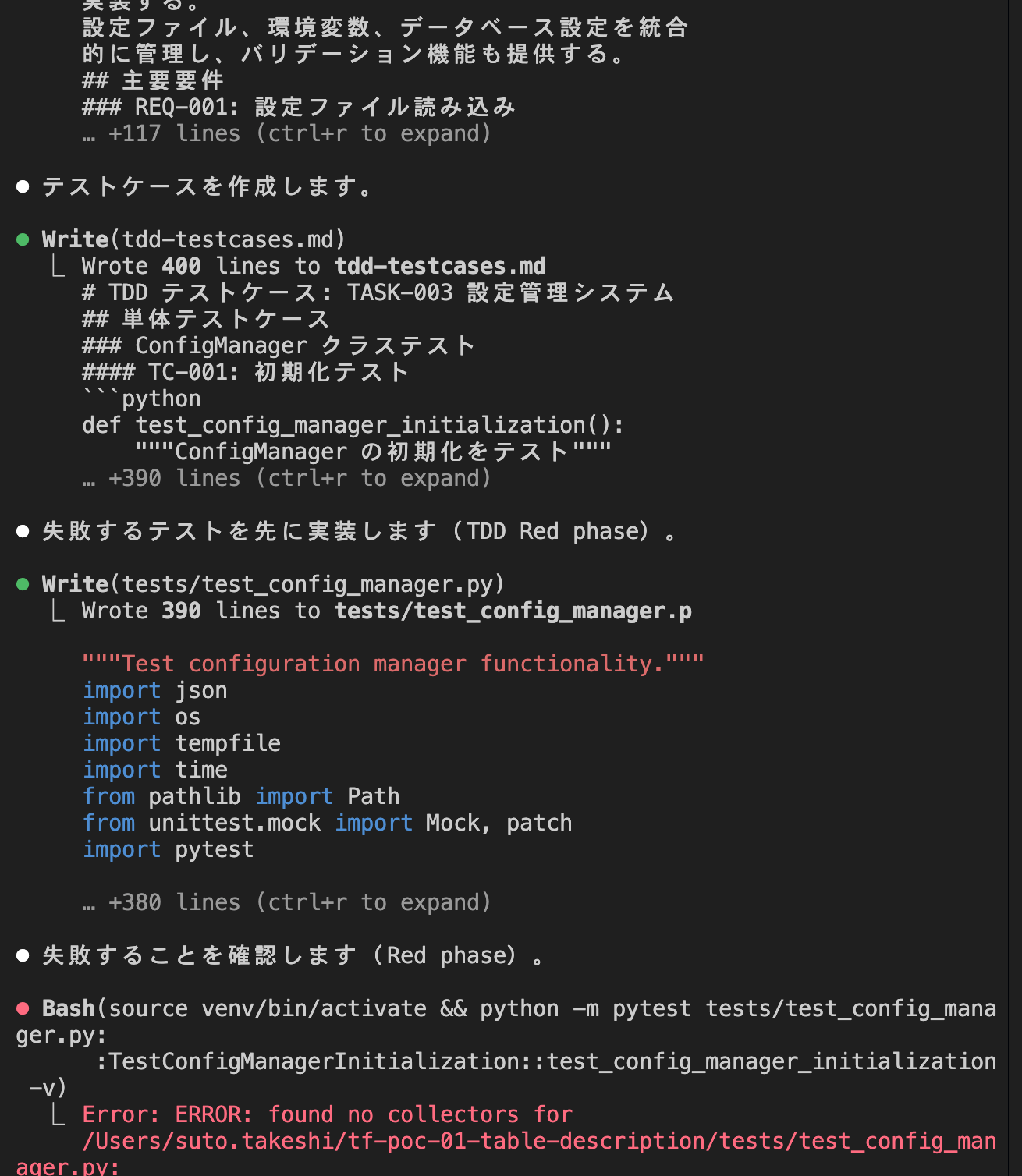
This time, once the "Phase 1: Foundation Building" tasks were completed, the implementation paused and returned to the Claude Code CLI.
So when I instructed it to continue the tasks or executed `/kairo-implement` again, it started implementing "Phase 2: Authentication and External API Foundation."
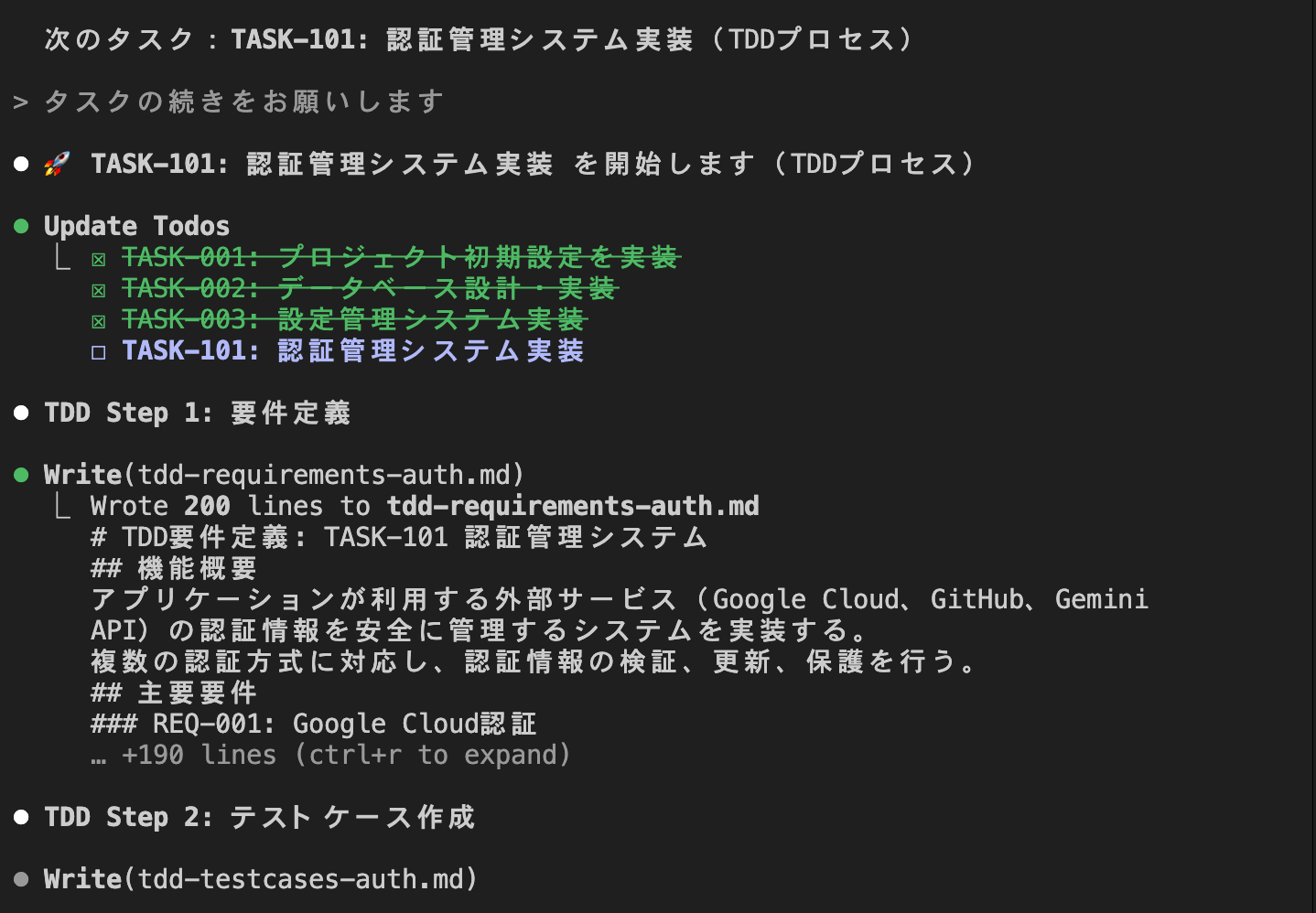
The fees incurred in Claude Code up to this interim progress are as follows:
- 8/20: Executed `/kairo-requirements` and `/kairo-design`
- 8/22: Executed `/kairo-tasks` (redone once due to input errors, etc.)
- 8/25: Executed `/kairo-implement` (from Phase 1 to midway through Phase 2)
- 8/26: Executed `/kairo-implement` (to midway through Phase 3)
- 8/27: Executed `/kairo-implement` (through Phase 3)
- 8/28: Executed `/kairo-implement` (to midway through Phase 4)
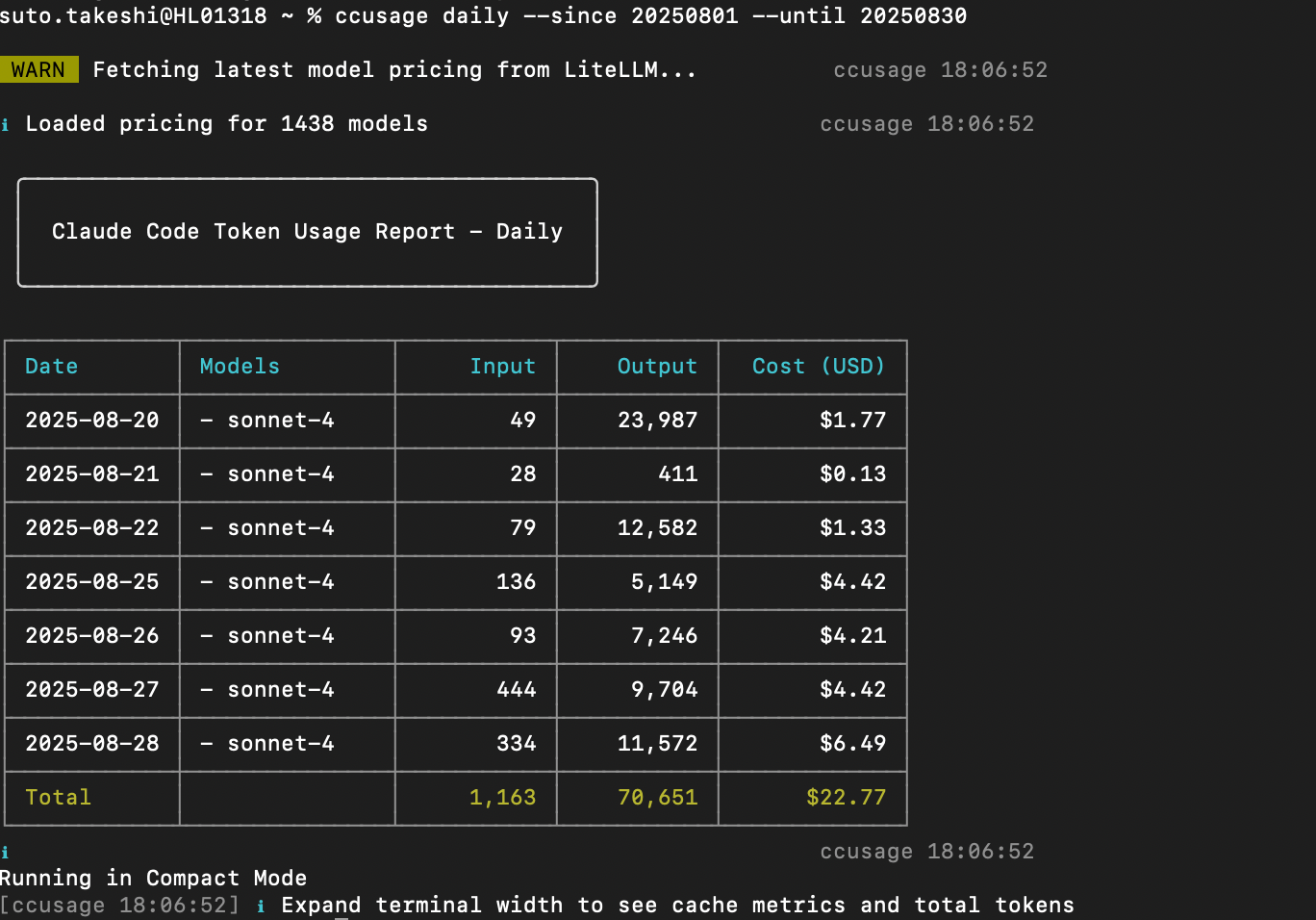
As expected, implementation costs were high because there were more resources to build than anticipated.## In Conclusion
I introduced how to create BigQuery-related tools using Tsumiki.
While I thought it would be sufficient to have the main functions and some error handling properly built, I was surprised that components were generated with a clear focus on production environment integration, including security, performance, and availability considerations.
Next, I plan to proceed to complete the implementation and verify whether the resources work properly.
Also, I think [Kiro](https://aws.amazon.com/jp/blogs/news/introducing-kiro/) should be able to do similar things, so I'd like to try Kiro at some point.
[Update]
The official service has now released an automatic description generation feature...
It seems it doesn't support Japanese output yet.
I'm curious about what information it uses for generation and its internal specifications.
https://dev.classmethod.jp/articles/bigquery-generate-description/






