![[Update] I Actually Tried Amazon SageMaker Data Agent Now That It Can Discover Data from Business Terminology](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[Update] I Actually Tried Amazon SageMaker Data Agent Now That It Can Discover Data from Business Terminology
This page has been translated by machine translation. View original
This is Ishikawa from the Cloud Business Division. Amazon SageMaker Data Agent can now reference business context (glossary terms, metadata, and README) from SageMaker Catalog to discover datasets and generate SQL/Python from business terminology rather than technical table names, so I tried it out.
SageMaker Data Agent is an interactive agent that enables data exploration, analysis, and visualization using natural language from notebooks and the Query Editor in SageMaker Unified Studio. This Data Agent can now reference business context and metadata accumulated in SageMaker Catalog.
For example, even if data users don't remember technical table names like tbl_cust_001, they can simply ask in business terms such as "What data is available about customer churn?" or "Calculate customer retention rate," and the agent will identify the appropriate tables and columns to generate more accurate code. A notable feature is the ability to leverage metadata synchronized from Collibra, Atlan, and Alation.
What is SageMaker Data Agent Business Context Integration?
According to the official documentation, when you ask the Data Agent a question, tables are identified through the following process:
- Search for accessible tables from technical metadata in AWS Glue Data Catalog or Redshift
- Query business context to find assets matching business terminology
- Integrate technical metadata and business metadata to identify the correct table
- Generate SQL/PySpark referencing the correct catalog, database, table, and columns
The business context queried by the agent consists of the following four elements registered in SageMaker Catalog:
- Glossary terms
- Custom metadata forms
- Asset summaries
- README
This flow can be illustrated as follows:
This integration feature is available in SageMaker Unified Studio notebooks (Data Notebook) and the Query Editor. Note that Data Agent is a feature that operates within the SageMaker Unified Studio UI, and at the time of writing this article, there is no way to directly call the agent from the CLI or SDK. Therefore, in this article, business metadata is added using the AWS CLI, and queries to the agent are performed through the Query Editor interface.
Trying It Out
Prerequisites
- SageMaker Unified Studio domain (IAM-based domain used this time)
- Project and data assets already published in SageMaker Catalog
- Verification environment: Region ap-northeast-1
For the verification subject, I used the quick_workshop.order_info table prepared for a workshop. This is a Glue View that joins order details (order) with a customer industry master (customer_industry) on customer ID, and contains 19 columns of Japanese sales data including customer name, sales, profit, industry, and sector.
Verification Scenario
While this table has columns such as sales and profit, there is no column that directly corresponds to the business concept of "LTV (customer lifetime value)." Therefore, the verification steps are:
- Attach business metadata (glossary tags, summary, README) to
order_info - Query the Data Agent with the business term "What data is available for LTV analysis?"
- Confirm whether the agent can identify
order_infofrom the term "LTV," which does not exist in the technical column names
If it can identify this, it serves as proof that business context is working.
Step 1: Confirming the Initial State (Without Business Metadata)
First, let's confirm the state before adding metadata. Since order_info is managed as a DataZone asset on SageMaker Catalog, we check it with get-asset.
$ aws datazone get-asset \
--domain-identifier dzd-d3w2uawk8vo7a1 \
--identifier 4iwqc4p3huask9 \
--query '{description:description, glossaryTerms:glossaryTerms, forms:formsOutput[].formName}' \
--output json
{
"description": null,
"glossaryTerms": null,
"forms": [
"GlueViewForm",
"SubscriptionTermsForm",
"DataSourceReferenceForm",
"AssetCommonDetailsForm"
]
}
Both description and glossaryTerms are empty, and the asset only has technical metadata forms. The domain had a glossary called "Customer Metrics" with three terms registered — LTV, Churn Rate, and ARR — but none were linked to order_info.
Step 2: Adding Business Metadata
This is the technical core of this verification. DataZone assets follow an immutable revision model, and there is no API like update-asset. Adding metadata is done by creating a new revision with create-asset-revision.
The following three items are added:
--description: Asset description (describing business purpose)- Glossary tags: Link the "LTV" term via
--glossary-terms - Summary and README: Stored in the
summary/readMefields ofAssetCommonDetailsForm
The fact that summary and README go into AssetCommonDetailsForm can be confirmed by checking the form type definition. Both summary (up to 5,000 characters) and readMe (up to 10,240 characters) have the @searchable attribute, making them exactly the fields that the Data Agent targets for search.
One important note: since create-asset-revision creates a new revision, omitting existing forms from --forms-input will delete them. Therefore, the request is structured to re-supply the existing four forms (such as GlueViewForm) while adding only summary and readMe to AssetCommonDetailsForm. The execution was done by organizing the content into a JSON file and passing it via --cli-input-json.
The added README is the following Markdown. Business terminology is intentionally included here:
## order_info (Order/Customer Analysis View)
A foundational view for sales and customer analysis, combining order details with customer industry classification.
### Main Use Cases
- Calculating Customer Lifetime Value (LTV): Aggregate customer name × sales
- Sales and profit analysis by industry/sector
- Visualization of profit margin (profit ÷ sales)
### Related Business Terms
- LTV (Customer Lifetime Value): The customer name × sales in this view is the source data for calculation
Run create-asset-revision to create a new version with updated metadata for the asset that exists in the current catalog.
create_asset_revision_request.json (Click to expand)
{
"domainIdentifier": "dzd-d3w2uawk8vo7a1",
"identifier": "4iwqc4p3huask9",
"name": "order_info",
"description": "An analysis view joining order details (order) with the customer industry master (customer_industry) on customer ID. Used as the base data for per-customer sales, profit, and discount analysis, industry/sector sales trends, and customer lifetime value (LTV) calculation.",
"glossaryTerms": [
"btm8669qf3vrfd"
],
"formsInput": [
{
"formName": "GlueViewForm",
"typeIdentifier": "amazon.datazone.GlueViewFormType",
"typeRevision": "12",
"content": "{\"catalogId\":\"<AWS-ACCOUNT_ID>\",\"databaseName\":\"quick_workshop\",\"columns\":[{\"dataType\":\"int\",\"columnName\":\"no\"},{\"dataType\":\"string\",\"columnName\":\"オーダーid\"},{\"dataType\":\"string\",\"columnName\":\"オーダー日付\"},{\"dataType\":\"int\",\"columnName\":\"日付キー\"},{\"dataType\":\"string\",\"columnName\":\"都道府県\"},{\"dataType\":\"string\",\"columnName\":\"市\"},{\"dataType\":\"string\",\"columnName\":\"地域\"},{\"dataType\":\"int\",\"columnName\":\"郵便番号\"},{\"dataType\":\"string\",\"columnName\":\"連絡先\"},{\"dataType\":\"string\",\"columnName\":\"顧客名\"},{\"dataType\":\"int\",\"columnName\":\"顧客id\"},{\"dataType\":\"string\",\"columnName\":\"プロダクト\"},{\"dataType\":\"string\",\"columnName\":\"ライセンス\"},{\"dataType\":\"double\",\"columnName\":\"売上\"},{\"dataType\":\"int\",\"columnName\":\"品数\"},{\"dataType\":\"double\",\"columnName\":\"ディスカウント\"},{\"dataType\":\"double\",\"columnName\":\"利益\"},{\"dataType\":\"string\",\"columnName\":\"産業\"},{\"dataType\":\"string\",\"columnName\":\"セクター\"}],\"query\":\"{\\\"originalSql\\\":\\\"SELECT\\\\n o.\\\\\\\"no\\\\\\\"\\\\n, o.\\\\\\\"オーダーid\\\\\\\"\\\\n, o.\\\\\\\"オーダー日付\\\\\\\"\\\\n, o.\\\\\\\"日付キー\\\\\\\"\\\\n, o.\\\\\\\"都道府県\\\\\\\"\\\\n, o.\\\\\\\"市\\\\\\\"\\\\n, o.\\\\\\\"地域\\\\\\\"\\\\n, o.\\\\\\\"郵便番号\\\\\\\"\\\\n, o.\\\\\\\"連絡先\\\\\\\"\\\\n, o.\\\\\\\"顧客名\\\\\\\"\\\\n, o.\\\\\\\"顧客id\\\\\\\"\\\\n, o.\\\\\\\"プロダクト\\\\\\\"\\\\n, o.\\\\\\\"ライセンス\\\\\\\"\\\\n, o.\\\\\\\"売上\\\\\\\"\\\\n, o.\\\\\\\"品数\\\\\\\"\\\\n, o.\\\\\\\"ディスカウント\\\\\\\"\\\\n, o.\\\\\\\"利益\\\\\\\"\\\\n, ci.\\\\\\\"産業\\\\\\\"\\\\n, ci.\\\\\\\"セクター\\\\\\\"\\\\nFROM\\\\n (\\\\\\\"quick_workshop\\\\\\\".\\\\\\\"order\\\\\\\" o\\\\nINNER JOIN \\\\\\\"quick_workshop\\\\\\\".\\\\\\\"customer_industry\\\\\\\" ci ON (o.\\\\\\\"顧客id\\\\\\\" = ci.\\\\\\\"顧客id\\\\\\\"))\\\\n\\\",\\\"catalog\\\":\\\"awsdatacatalog\\\",\\\"schema\\\":\\\"quick_workshop\\\",\\\"columns\\\":[{\\\"name\\\":\\\"no\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"オーダーid\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"オーダー日付\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"日付キー\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"都道府県\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"市\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"地域\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"郵便番号\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"連絡先\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"顧客名\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"顧客id\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"プロダクト\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"ライセンス\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"売上\\\",\\\"type\\\":\\\"double\\\"},{\\\"name\\\":\\\"品数\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"ディスカウント\\\",\\\"type\\\":\\\"double\\\"},{\\\"name\\\":\\\"利益\\\",\\\"type\\\":\\\"double\\\"},{\\\"name\\\":\\\"産業\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"セクター\\\",\\\"type\\\":\\\"varchar\\\"}],\\\"owner\\\":\\\"<AWS-ACCOUNT_ID>\\\",\\\"runAsInvoker\\\":false,\\\"properties\\\":{},\\\"isProtected\\\":false,\\\"isMultiDialect\\\":false}\",\"region\":\"ap-northeast-1\",\"tableArn\":\"arn:aws:glue:ap-northeast-1:<AWS-ACCOUNT_ID>:table/quick_workshop/order_info\",\"tableName\":\"order_info\"}"
},
{
"formName": "SubscriptionTermsForm",
"typeIdentifier": "amazon.datazone.SubscriptionTermsFormType",
"typeRevision": "2",
"content": "{\"approvalRequired\":\"YES\"}"
},
{
"formName": "DataSourceReferenceForm",
"typeIdentifier": "amazon.datazone.DataSourceReferenceFormType",
"typeRevision": "5",
"content": "{\"dataSourceIdentifier\":{\"id\":\"6mguy6thu4gtjt\",\"version\":\"latest\"},\"filterableDataSourceId\":\"6mguy6thu4gtjt\",\"dataSourceType\":\"GLUE\"}"
},
{
"formName": "AssetCommonDetailsForm",
"typeIdentifier": "amazon.datazone.AssetCommonDetailsFormType",
"typeRevision": "8",
"content": "{\"sourceIdentifier\": \"arn:aws:glue:ap-northeast-1:<AWS-ACCOUNT_ID>:table/quick_workshop/order_info\", \"summary\": \"This is the core dataset for customer purchasing behavior analysis and sales analysis. It holds customer name, product, sales, quantity, discount, and profit for each order, with customer industry/sector attributes already joined. It can be used for customer lifetime value (LTV), industry sales rankings, profit margin analysis, and customer segment analysis.\", \"readMe\": \"## order_info (Order/Customer Analysis View)\\n\\nA foundational view for sales and customer analysis, combining order details with customer industry classification.\\n\\n### Main Use Cases\\n- Calculating Customer Lifetime Value (LTV): Aggregate customer name × sales\\n- Sales and profit analysis by industry/sector\\n- Visualization of profit margin (profit ÷ sales)\\n- Analysis of discount impact on profit\\n\\n### Key Columns\\n- Customer Name / Customer ID: Customer identification\\n- Sales / Profit / Discount: Monetary metrics\\n- Industry / Sector: Customer industry classification\\n- Product / License: Sold products\\n\\n### Related Business Terms\\n- LTV (Customer Lifetime Value): The customer name × sales in this view is the source data for calculation\"}"
}
],
"clientToken": "blog-writer-20260609-cff3d144-enrich-001"
}
% aws datazone create-asset-revision \
--region ap-northeast-1 \
--cli-input-json file://create_asset_revision_request.json \
--query '{revision:revision, description:description, glossaryTerms:glossaryTerms, formsOutput:formsOutput[].formName}' \
--output json
{
"revision": "2",
"description": "An analysis view joining order details (order) with the customer industry master (customer_industry) on customer ID. Used as the base data for per-customer sales, profit, and discount analysis, industry/sector sales trends, and customer lifetime value (LTV) calculation.",
"glossaryTerms": [
"btm8669qf3vrfd"
],
"formsOutput": [
"GlueViewForm",
"SubscriptionTermsForm",
"DataSourceReferenceForm",
"AssetCommonDetailsForm"
]
}
Revision 2 was created, with description, glossaryTerms (LTV), and summary/readMe added, while the existing four forms were preserved.
Step 3: Confirming Reflection in the Catalog
What the Data Agent searches is the published listings in the catalog. To reflect the created revision 2 in the catalog, re-publish it.
$ aws datazone create-listing-change-set \
--domain-identifier dzd-d3w2uawk8vo7a1 \
--entity-type ASSET --entity-identifier 4iwqc4p3huask9 \
--entity-revision 2 --action PUBLISH
{
"listingId": "didt0hra2stxg9",
"listingRevision": "3"
}
After reflecting the changes, searching the catalog with business terminology now returns order_info as a hit.
$ aws datazone search-listings \
--domain-identifier dzd-d3w2uawk8vo7a1 \
--search-text "Customer Lifetime Value LTV" \
--query 'items[].assetListing.{Name:name, GTerms:glossaryTerms[].name}' \
--output json
[
{
"Name": "order_info",
"GTerms": [ "LTV" ]
}
]
At this point, we have established a state where order_info can be reached from the business term "LTV."
Step 4: Querying the Data Agent with Business Terminology in the Query Editor
Sign in to the SageMaker Unified Studio portal and open the "Query Editor" for the project. The Data Agent chat panel is displayed on the right side of the screen. Submit the following question. No table name is specified at all — the query uses only the business term "LTV."
I want to analyze Customer Lifetime Value (LTV). Which table should I use?
Please also explain why you chose that table and provide SQL to approximate LTV.
Select "Athena (SQL)" from the connection selector and send the same question again. The agent then explores from the Glue catalog → database → tables, checks the business metadata, and recommends order_info as follows:
Please see the entire flow below.
Key points from the response are quoted below:
quick_workshop.order_info(Most recommended)This table has the "LTV" term tag applied and is designed as the core dataset for customer purchasing behavior analysis and sales analysis.
Reasons for selection:
- Customer ID (
顧客id) enables data aggregation per customer- Contains sales data (
売上), the basic LTV metric- Order date (
オーダー日付) enables period analysis- Also contains profit (
利益) data for more detailed analysis- Includes industry and sector information, enabling segment-based LTV analysis
- Business metadata explicitly states it is dedicated to LTV analysis
What is noteworthy is the reason for selection. The first point explicitly cites the "LTV" term tag added in Step 2, and the second point directly quotes the added summary (core dataset for customer purchasing behavior and sales analysis). Despite the absence of a column named "LTV" in order_info, we were able to confirm that the table was identified based on business metadata. This is the effect of business context integration.
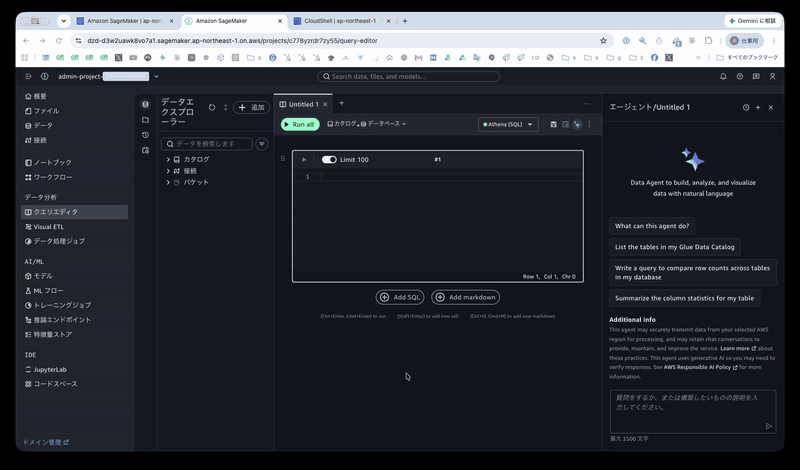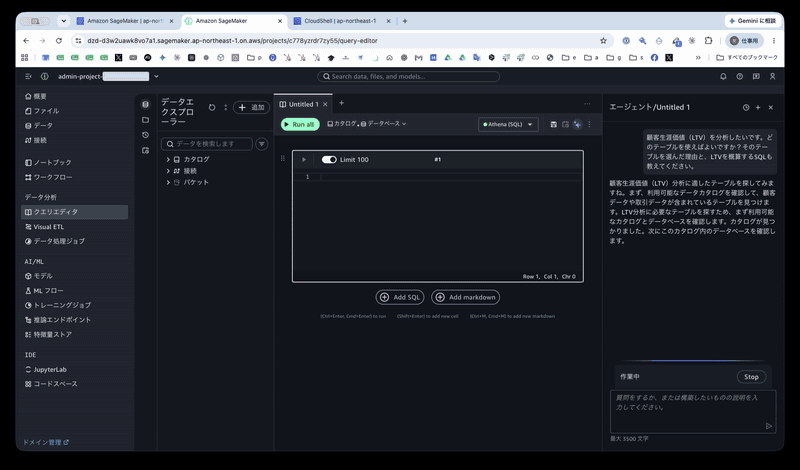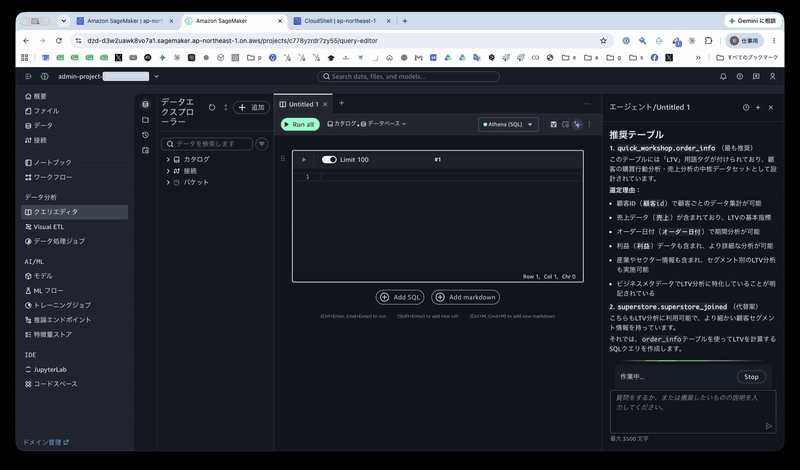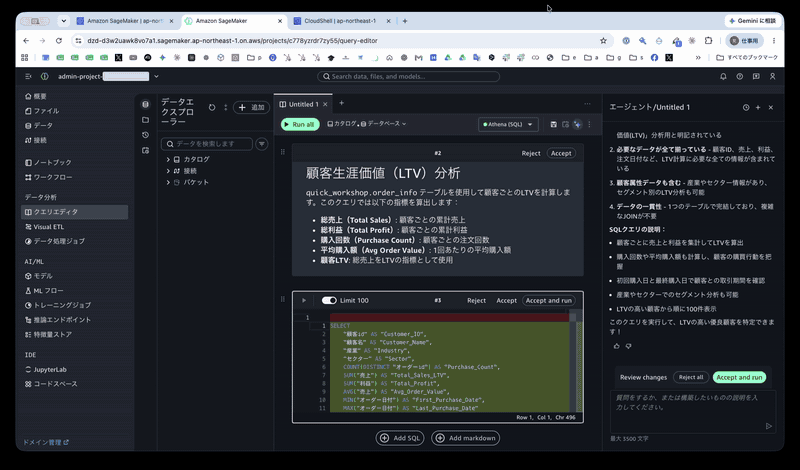
Step 5: Running the Generated SQL (A Stumbling Point)
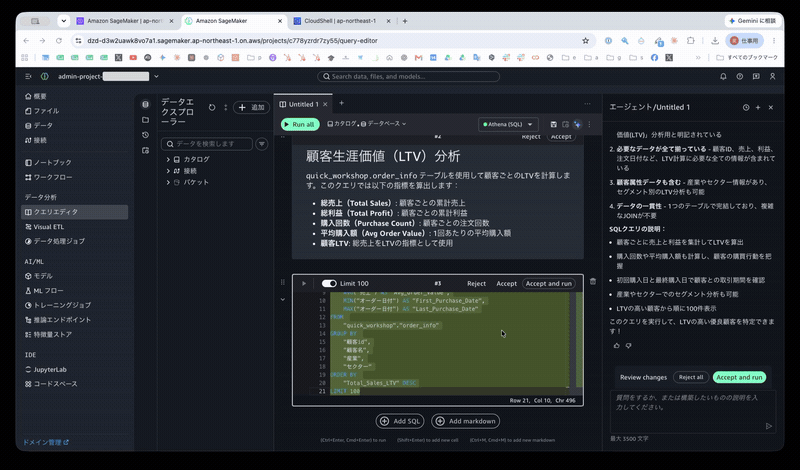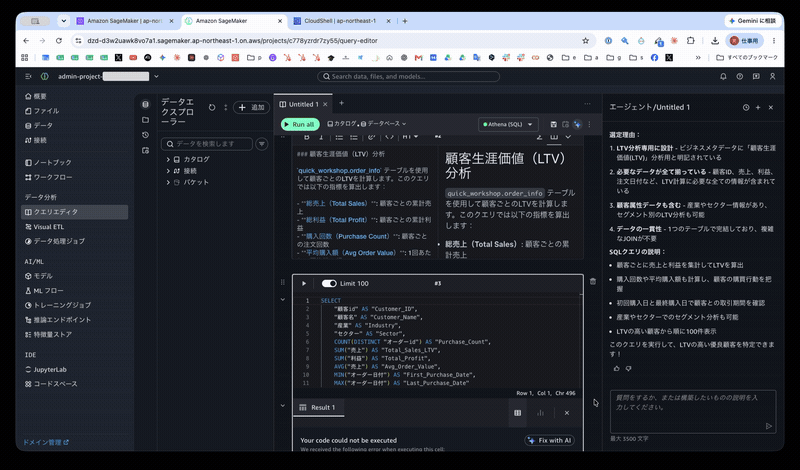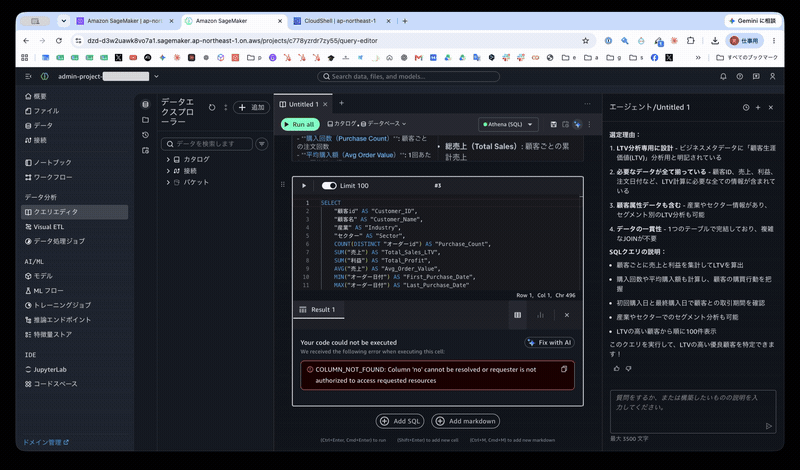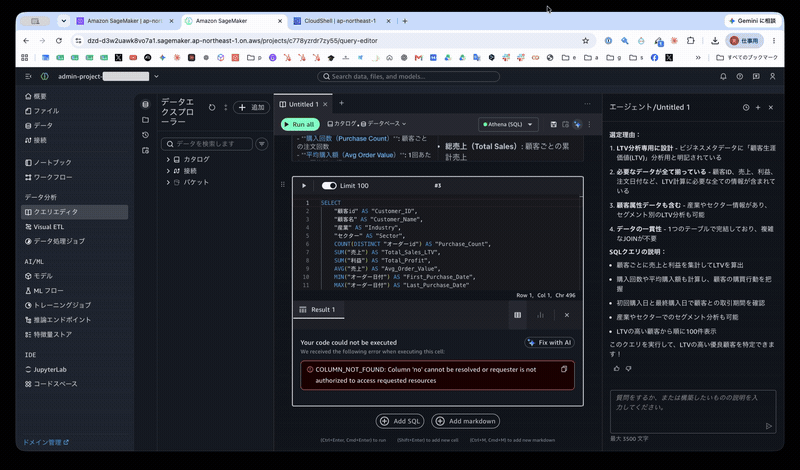
The agent generated a "Customer LTV Analysis" description and its SQL, and inserted it into a cell.
Customer Lifetime Value (LTV) Analysis
Calculate LTV per customer using the
quick_workshop.order_infotable. This query calculates the following metrics:
- Total Sales: Cumulative sales per customer
- Total Profit: Cumulative profit per customer
- Purchase Count: Number of orders per customer
- Average Order Value: Average purchase amount per order
- Customer LTV: Total sales used as the LTV metric
SELECT
"顧客id" AS "Customer_ID",
"顧客名" AS "Customer_Name",
"産業" AS "Industry",
"セクター" AS "Sector",
COUNT(DISTINCT "オーダーid") AS "Purchase_Count",
SUM("売上") AS "Total_Sales_LTV",
SUM("利益") AS "Total_Profit",
AVG("売上") AS "Avg_Order_Value",
MIN("オーダー日付") AS "First_Purchase_Date",
MAX("オーダー日付") AS "Last_Purchase_Date"
FROM
"quick_workshop"."order_info"
GROUP BY
"顧客id",
"顧客名",
"産業",
"セクター"
ORDER BY
"Total_Sales_LTV" DESC
LIMIT 100
Press the [Accept and run] button on the right to execute the query.
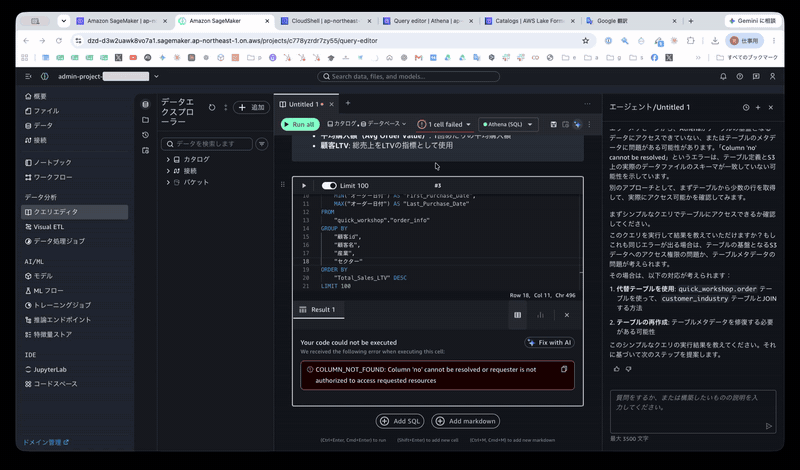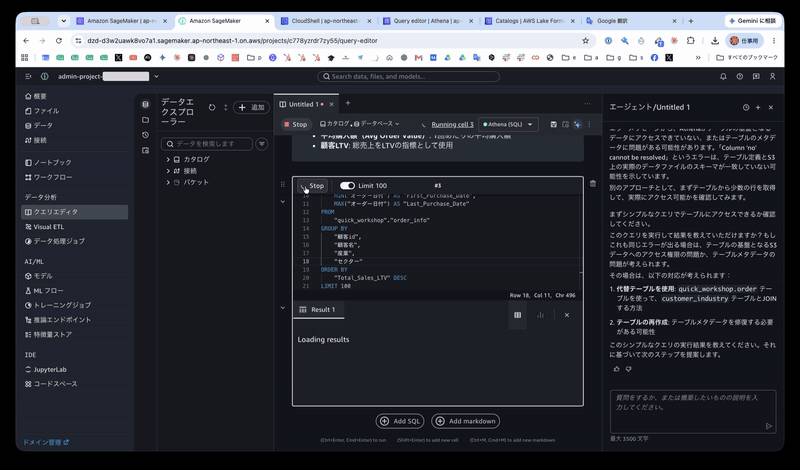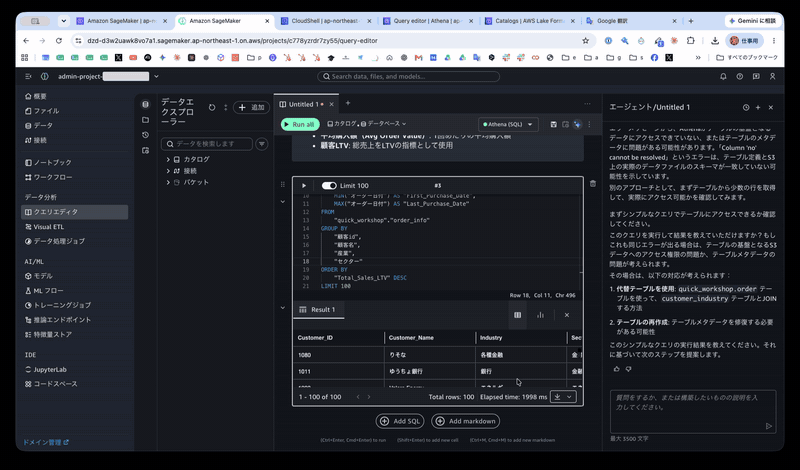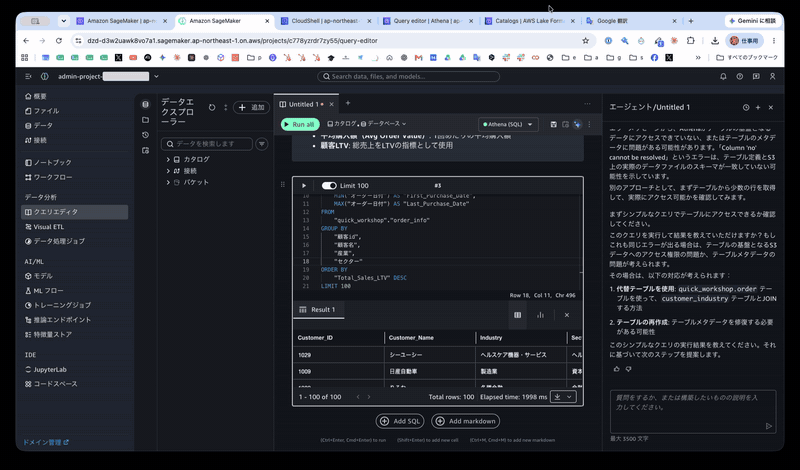
The following error occurred. The suspected cause was either a missing column called no, or that permissions had not been granted.
COLUMN_NOT_FOUND: Column 'no' cannot be resolved or requester is not authorized to access requested resources
Initially, I tried to fix the issue using the [Fix with AI] button and chat, but ultimately the root cause was that Lake Formation permissions for the table had not been granted to the SageMaker IAM role AmazonSageMakerAdminIAMExecutionRole_1. After granting the permissions and retrying, it succeeded.
The actual data retrieved is as follows (excerpt of the first few rows):
| Customer_ID | Customer_Name | Industry | Sector | Purchase_Count | Total_Sales_LTV | Total_Profit | Avg_Order_Value | First_Purchase_Date | Last_Purchase_Date |
|---|---|---|---|---|---|---|---|---|---|
| 1029 | シーユーシー | Healthcare Equipment & Services | Healthcare | 58 | 55719.21 | 5953.2038 | 415.815 | 2018/1/14 | 2021/12/24 |
| 1009 | 日産自動車 | Manufacturing | Capital Goods & Services | 102 | 43807.5424 | 3970.0102 | 253.2227884 | 2018/3/3 | 2021/12/25 |
| 1080 | りそな | Diversified Financials | Financials | 102 | 42904.167 | 5531.8834 | 223.4592031 | 2018/3/17 | 2021/12/30 |
| 1011 | ゆうちょ銀行 | Banks | Financials | 65 | 41255.9471 | 6449.8554 | 312.5450538 | 2018/6/15 | 2021/12/22 |
| 1093 | Valero Energy | Energy | Energy | 58 | 41220.4188 | 10308.6297 | 392.5754171 | 2018/3/18 | 2021/12/16 |
| 1060 | ビックカメラ | Retail | Consumer Discretionary | 58 | 40360.163 | 7937.4915 | 366.9105727 | 2018/1/21 | 2021/12/24 |
| 1088 | 日本包材株式会社 | Consumer Products | Consumer Staples | 87 | 40326.344 | 1690.5775 | 219.164913 | 2018/3/21 | 2021/12/31 |
We were able to confirm the entire flow from querying with business terminology to table discovery, SQL generation, and actual data calculation.
Discussion
Here is a summary of the findings obtained from this verification.
- Business context integration clearly works: We were able to identify
order_infofrom the business concept "LTV," which does not exist as a column name. Moreover, the agent specifically cited the glossary tags and summary we added as the reasons for selection, confirming that the matching is not based solely on technical metadata. The design philosophy — where glossaries and READMEs maintained by data stewards directly improve agent accuracy — was palpable. - Investment in metadata maintenance pays off: Conversely, if glossary terms, summaries, and README are left empty, the true value of this feature will not be realized. In this verification, before adding the metadata, catalog searches using business terminology could not reach
order_info. This behavior matched exactly with the announcement that existing investments in catalog maintenance can be leveraged directly. - A connection must be selected first in Query Editor: To have the Data Agent search the catalog, it was necessary to first select an Athena or Redshift connection.
- AWS Lake Formation permission grants are required: Even if asset creation and table metadata retrieval are possible, queries will fail with an error without access permissions, so permission grants are required. This cannot be changed via the [Fix with AI] button or chat.
As a limitation, the Data Agent can only be used in the SageMaker Unified Studio UI (Data Notebook / Query Editor), and direct invocation from CLI/SDK is not available. On the other hand, since the business metadata that the agent references can be fully automated and codified using the datazone API as shown in this article, scripting metadata maintenance for multiple tables makes it easier to extend the benefits of this feature across the entire organization.
Closing
I tried out Amazon SageMaker Data Agent's business context integration using quick_workshop.order_info as the subject. As a result of adding glossary tags and a summary, the agent correctly identified order_info — which has no column named LTV — from the business-terminology question "What data is available for LTV analysis?" and cited the added metadata as its reasoning.
It is a great value for business users who don't know technical table names to be able to reach data through well-maintained business terminology. At the same time, even if asset creation and table metadata retrieval are possible, queries will fail with an error without access permissions, so permission grants are required. Since the roles of data consumers and those managing data governance are separate, this can also be considered correct behavior.
Since adding metadata itself can be automated with datazone create-asset-revision, why not move forward with building the foundation for self-service analytics leveraging Data Agent, alongside catalog maintenance? I hope this article is helpful to someone.
