![[アップデート] Amazon SageMaker Data Agent が業務用語からのデータ発見が可能になったので実際に試してみた](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[アップデート] Amazon SageMaker Data Agent が業務用語からのデータ発見が可能になったので実際に試してみた
クラウド事業本部の石川です。Amazon SageMaker Data Agent が SageMaker Catalog のビジネスコンテキスト(用語集・メタデータ・README)を参照し、技術的なテーブル名ではなく業務用語からデータセットの発見と SQL/Python の生成を行えるようになりましたので、実際に試してみました。
SageMaker Data Agent は、SageMaker Unified Studio のノートブックや Query Editor から自然言語でデータの探索・分析・可視化を行える対話型エージェントです。この Data Agent が SageMaker Catalogに蓄積されたビジネスコンテキストとメタデータを参照できるようになりました。
例えば、データ利用者は tbl_cust_001 のような技術的なテーブル名を覚えていなくても、「顧客の解約に関するデータは?」「顧客維持率を計算して」といった業務用語で問い合わせるだけで、エージェントが適切なテーブルとカラムを特定し、より正確なコードを生成してくれます。Collibra・Atlan・Alation から同期したメタデータも活用できる点が特徴です。
SageMaker Data Agent のビジネスコンテキスト統合とは
公式ドキュメントによると、Data Agent に質問すると以下の流れでテーブルが特定されます。
- AWS Glue Data Catalog や Redshift の技術メタデータからアクセス可能なテーブルを検索する
- ビジネスコンテキストを照会し、業務用語に一致する資産を探す
- 技術メタデータとビジネスメタデータを統合して正しいテーブルを特定する
- 正しいカタログ・データベース・テーブル・カラムを参照する SQL / PySpark を生成する
エージェントが照会するビジネスコンテキストは、SageMaker Catalog に登録された次の4要素です。
- 用語集(glossary terms)
- カスタムメタデータフォーム(metadata forms)
- 資産のサマリー(summary)
- README
この流れを図にすると以下のようになります。
この統合機能は、SageMaker Unified Studio のノートブック(Data Notebook)と Query Editor で利用できます。なお、Data Agent はあくまで SageMaker Unified Studio の UI 上で動作する機能であり、本記事執筆時点では CLI や SDK から直接エージェントを呼び出す手段は提供されていません。そのため本記事では、ビジネスメタデータの付与を AWS CLI で行い、エージェントへの問い合わせは Query Editor の画面上で実施しています。
やってみた
前提条件
- SageMaker Unified Studio ドメイン(今回は IAM ベースのドメインを使用)
- SageMaker Catalog にプロジェクトとデータ資産が公開済みであること
- 検証環境: リージョン ap-northeast-1
検証の題材には、ワークショップ用に用意されていた quick_workshop.order_info テーブルを使用します。これは受注明細(order)と顧客の産業マスタ(customer_industry)を顧客IDで結合した Glue View で、顧客名・売上・利益・産業・セクター など19カラムを持つ日本語の販売データです。
検証のシナリオ
このテーブルには 売上 や 利益 といったカラムはありますが、「LTV(顧客生涯価値)」という業務概念に直接対応するカラムは存在しません。そこで、
order_infoにビジネスメタデータ(用語集タグ・サマリー・README)を付与し、- Data Agent に「LTV 分析に使えるデータは?」と業務用語で問い合わせて、
- 技術カラム名にない「LTV」という用語からエージェントが
order_infoを特定できるか
を確認します。これが特定できれば、ビジネスコンテキストが効いている証拠になります。
Step 1: 事前状態の確認(ビジネスメタデータが無い状態)
まず付与前の状態を確認します。order_info は SageMaker Catalog 上では DataZone の資産(asset)として管理されているため、get-asset で確認します。
$ aws datazone get-asset \
--domain-identifier dzd-d3w2uawk8vo7a1 \
--identifier 4iwqc4p3huask9 \
--query '{description:description, glossaryTerms:glossaryTerms, forms:formsOutput[].formName}' \
--output json
{
"description": null,
"glossaryTerms": null,
"forms": [
"GlueViewForm",
"SubscriptionTermsForm",
"DataSourceReferenceForm",
"AssetCommonDetailsForm"
]
}
description も glossaryTerms も空で、技術メタデータのフォームしか持たない状態です。ドメインには「Customer Metrics」という用語集があり LTV・Churn Rate・ARR の3用語が登録済みでしたが、order_info には紐付いていませんでした。
Step 2: ビジネスメタデータの付与
ここがこの検証の技術的な肝です。DataZone のアセットはイミュータブルなリビジョンモデルになっており、update-asset のような API は存在せず、メタデータの付与は create-asset-revision で新しいリビジョンを作成することで行います。
付与する内容は次の3点です。
--description: 資産の説明文(業務的な用途を記述)- 用語集タグ:
--glossary-termsで「LTV」用語を紐付け - サマリーと README:
AssetCommonDetailsFormのsummary/readMeフィールドに格納
サマリーと README が AssetCommonDetailsForm に入る点は、フォームタイプの定義を確認すると分かります。summary(最大5000文字)と readMe(最大10240文字)はいずれも @searchable 属性を持っており、まさに Data Agent が検索対象とするフィールドです。
ひとつ注意点があります。create-asset-revision は新リビジョンを作るため、既存のフォームを --forms-input で省略すると消えてしまいます。そのため、既存の4フォーム(GlueViewForm 等)をそのまま再供給したうえで、AssetCommonDetailsForm にだけ summary と readMe を追記する形でリクエストを組み立てます。実行は内容を JSON ファイルにまとめて --cli-input-json で渡しました。
付与した README は以下のような Markdown です。ここでは、業務用語を意図的に盛り込んでいます。
## order_info(受注・顧客分析ビュー)
受注明細と顧客の産業分類を結合した、売上・顧客分析の基盤ビューです。
### 主なユースケース
- 顧客生涯価値(LTV)の算出: 顧客名 × 売上 を集計
- 産業/セクター別の売上・利益分析
- 利益率(利益 ÷ 売上)の可視化
### 関連ビジネス用語
- LTV(顧客生涯価値): 本ビューの 顧客名 × 売上 が算出元データ
create-asset-revision を実行して、既存カタログに存在するアセットに対して、メタデータを更新した新しいバージョンを作ります。
create_asset_revision_request.json (クリックで展開)
{
"domainIdentifier": "dzd-d3w2uawk8vo7a1",
"identifier": "4iwqc4p3huask9",
"name": "order_info",
"description": "受注明細(order)と顧客産業マスタ(customer_industry)を顧客IDで結合した分析用ビューです。顧客別の売上・利益・ディスカウント、産業・セクター別の販売動向、顧客生涯価値(LTV)算出の基盤データとして利用します。",
"glossaryTerms": [
"btm8669qf3vrfd"
],
"formsInput": [
{
"formName": "GlueViewForm",
"typeIdentifier": "amazon.datazone.GlueViewFormType",
"typeRevision": "12",
"content": "{\"catalogId\":\"<AWS-ACCOUNT_ID>\",\"databaseName\":\"quick_workshop\",\"columns\":[{\"dataType\":\"int\",\"columnName\":\"no\"},{\"dataType\":\"string\",\"columnName\":\"オーダーid\"},{\"dataType\":\"string\",\"columnName\":\"オーダー日付\"},{\"dataType\":\"int\",\"columnName\":\"日付キー\"},{\"dataType\":\"string\",\"columnName\":\"都道府県\"},{\"dataType\":\"string\",\"columnName\":\"市\"},{\"dataType\":\"string\",\"columnName\":\"地域\"},{\"dataType\":\"int\",\"columnName\":\"郵便番号\"},{\"dataType\":\"string\",\"columnName\":\"連絡先\"},{\"dataType\":\"string\",\"columnName\":\"顧客名\"},{\"dataType\":\"int\",\"columnName\":\"顧客id\"},{\"dataType\":\"string\",\"columnName\":\"プロダクト\"},{\"dataType\":\"string\",\"columnName\":\"ライセンス\"},{\"dataType\":\"double\",\"columnName\":\"売上\"},{\"dataType\":\"int\",\"columnName\":\"品数\"},{\"dataType\":\"double\",\"columnName\":\"ディスカウント\"},{\"dataType\":\"double\",\"columnName\":\"利益\"},{\"dataType\":\"string\",\"columnName\":\"産業\"},{\"dataType\":\"string\",\"columnName\":\"セクター\"}],\"query\":\"{\\\"originalSql\\\":\\\"SELECT\\\\n o.\\\\\\\"no\\\\\\\"\\\\n, o.\\\\\\\"オーダーid\\\\\\\"\\\\n, o.\\\\\\\"オーダー日付\\\\\\\"\\\\n, o.\\\\\\\"日付キー\\\\\\\"\\\\n, o.\\\\\\\"都道府県\\\\\\\"\\\\n, o.\\\\\\\"市\\\\\\\"\\\\n, o.\\\\\\\"地域\\\\\\\"\\\\n, o.\\\\\\\"郵便番号\\\\\\\"\\\\n, o.\\\\\\\"連絡先\\\\\\\"\\\\n, o.\\\\\\\"顧客名\\\\\\\"\\\\n, o.\\\\\\\"顧客id\\\\\\\"\\\\n, o.\\\\\\\"プロダクト\\\\\\\"\\\\n, o.\\\\\\\"ライセンス\\\\\\\"\\\\n, o.\\\\\\\"売上\\\\\\\"\\\\n, o.\\\\\\\"品数\\\\\\\"\\\\n, o.\\\\\\\"ディスカウント\\\\\\\"\\\\n, o.\\\\\\\"利益\\\\\\\"\\\\n, ci.\\\\\\\"産業\\\\\\\"\\\\n, ci.\\\\\\\"セクター\\\\\\\"\\\\nFROM\\\\n (\\\\\\\"quick_workshop\\\\\\\".\\\\\\\"order\\\\\\\" o\\\\nINNER JOIN \\\\\\\"quick_workshop\\\\\\\".\\\\\\\"customer_industry\\\\\\\" ci ON (o.\\\\\\\"顧客id\\\\\\\" = ci.\\\\\\\"顧客id\\\\\\\"))\\\\n\\\",\\\"catalog\\\":\\\"awsdatacatalog\\\",\\\"schema\\\":\\\"quick_workshop\\\",\\\"columns\\\":[{\\\"name\\\":\\\"no\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"オーダーid\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"オーダー日付\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"日付キー\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"都道府県\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"市\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"地域\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"郵便番号\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"連絡先\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"顧客名\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"顧客id\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"プロダクト\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"ライセンス\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"売上\\\",\\\"type\\\":\\\"double\\\"},{\\\"name\\\":\\\"品数\\\",\\\"type\\\":\\\"integer\\\"},{\\\"name\\\":\\\"ディスカウント\\\",\\\"type\\\":\\\"double\\\"},{\\\"name\\\":\\\"利益\\\",\\\"type\\\":\\\"double\\\"},{\\\"name\\\":\\\"産業\\\",\\\"type\\\":\\\"varchar\\\"},{\\\"name\\\":\\\"セクター\\\",\\\"type\\\":\\\"varchar\\\"}],\\\"owner\\\":\\\"<AWS-ACCOUNT_ID>\\\",\\\"runAsInvoker\\\":false,\\\"properties\\\":{},\\\"isProtected\\\":false,\\\"isMultiDialect\\\":false}\",\"region\":\"ap-northeast-1\",\"tableArn\":\"arn:aws:glue:ap-northeast-1:<AWS-ACCOUNT_ID>:table/quick_workshop/order_info\",\"tableName\":\"order_info\"}"
},
{
"formName": "SubscriptionTermsForm",
"typeIdentifier": "amazon.datazone.SubscriptionTermsFormType",
"typeRevision": "2",
"content": "{\"approvalRequired\":\"YES\"}"
},
{
"formName": "DataSourceReferenceForm",
"typeIdentifier": "amazon.datazone.DataSourceReferenceFormType",
"typeRevision": "5",
"content": "{\"dataSourceIdentifier\":{\"id\":\"6mguy6thu4gtjt\",\"version\":\"latest\"},\"filterableDataSourceId\":\"6mguy6thu4gtjt\",\"dataSourceType\":\"GLUE\"}"
},
{
"formName": "AssetCommonDetailsForm",
"typeIdentifier": "amazon.datazone.AssetCommonDetailsFormType",
"typeRevision": "8",
"content": "{\"sourceIdentifier\": \"arn:aws:glue:ap-northeast-1:<AWS-ACCOUNT_ID>:table/quick_workshop/order_info\", \"summary\": \"顧客の購買行動分析・売上分析の中核データセットです。受注1件ごとに顧客名・プロダクト・売上・品数・ディスカウント・利益を保持し、顧客の産業/セクター属性を結合済みです。顧客生涯価値(LTV)、産業別売上ランキング、利益率分析、顧客セグメント分析に利用できます。\", \"readMe\": \"## order_info(受注・顧客分析ビュー)\\n\\n受注明細と顧客の産業分類を結合した、売上・顧客分析の基盤ビューです。\\n\\n### 主なユースケース\\n- 顧客生涯価値(LTV)の算出: 顧客名 × 売上 を集計\\n- 産業/セクター別の売上・利益分析\\n- 利益率(利益 ÷ 売上)の可視化\\n- ディスカウントが利益に与える影響分析\\n\\n### 主要カラム\\n- 顧客名 / 顧客id: 顧客の識別\\n- 売上 / 利益 / ディスカウント: 金額系メトリクス\\n- 産業 / セクター: 顧客の業種分類\\n- プロダクト / ライセンス: 販売商品\\n\\n### 関連ビジネス用語\\n- LTV(顧客生涯価値): 本ビューの 顧客名 × 売上 が算出元データ\"}"
}
],
"clientToken": "blog-writer-20260609-cff3d144-enrich-001"
}
% aws datazone create-asset-revision \
--region ap-northeast-1 \
--cli-input-json file://create_asset_revision_request.json \
--query '{revision:revision, description:description, glossaryTerms:glossaryTerms, formsOutput:formsOutput[].formName}' \
--output json
{
"revision": "2",
"description": "受注明細(order)と顧客産業マスタ(customer_industry)を顧客IDで結合した分析用ビューです。顧客別の売上・利益・ディスカウント、産業・セクター別の販売動向、顧客生涯価値(LTV)算出の基盤データとして利用します。",
"glossaryTerms": [
"btm8669qf3vrfd"
],
"formsOutput": [
"GlueViewForm",
"SubscriptionTermsForm",
"DataSourceReferenceForm",
"AssetCommonDetailsForm"
]
}
リビジョン2が作成され、description、glossaryTerms(LTV)、summary/readMe が付与され、既存の4フォームも保全されました。
Step 3: カタログへの反映確認
Data Agent が検索するのはカタログに公開されたリスティングです。作成したリビジョン2をカタログに反映するため、再公開します。
$ aws datazone create-listing-change-set \
--domain-identifier dzd-d3w2uawk8vo7a1 \
--entity-type ASSET --entity-identifier 4iwqc4p3huask9 \
--entity-revision 2 --action PUBLISH
{
"listingId": "didt0hra2stxg9",
"listingRevision": "3"
}
反映後、業務用語でカタログ検索すると order_info がヒットするようになりました。
$ aws datazone search-listings \
--domain-identifier dzd-d3w2uawk8vo7a1 \
--search-text "顧客生涯価値 LTV" \
--query 'items[].assetListing.{Name:name, GTerms:glossaryTerms[].name}' \
--output json
[
{
"Name": "order_info",
"GTerms": [ "LTV" ]
}
]
ここまでで「LTV」という業務用語から order_info に到達できる状態になりました。
Step 4: Query Editor で Data Agent に業務用語で質問する
SageMaker Unified Studio のポータルにサインインし、プロジェクトの「クエリエディタ」を開きます。画面右側に Data Agent のチャットパネルが表示されます。次の質問を投げます。テーブル名は一切指定せず、業務用語の「LTV」だけで問い合わせます。
顧客生涯価値(LTV)を分析したいです。どのテーブルを使えばよいですか?
そのテーブルを選んだ理由と、LTVを概算するSQLも教えてください。
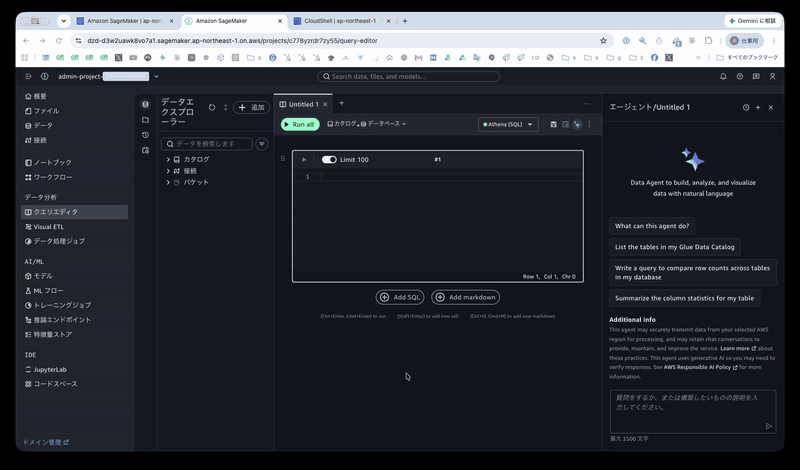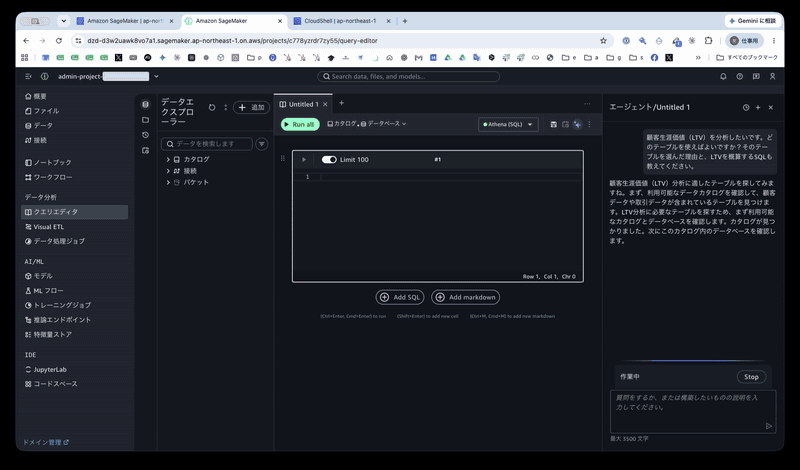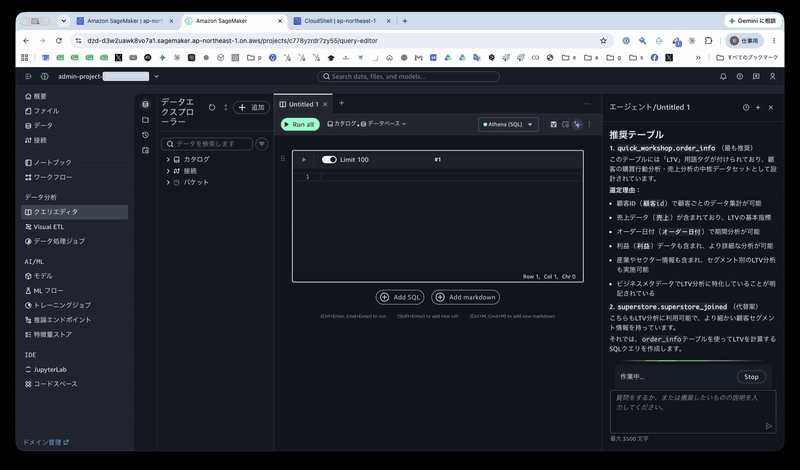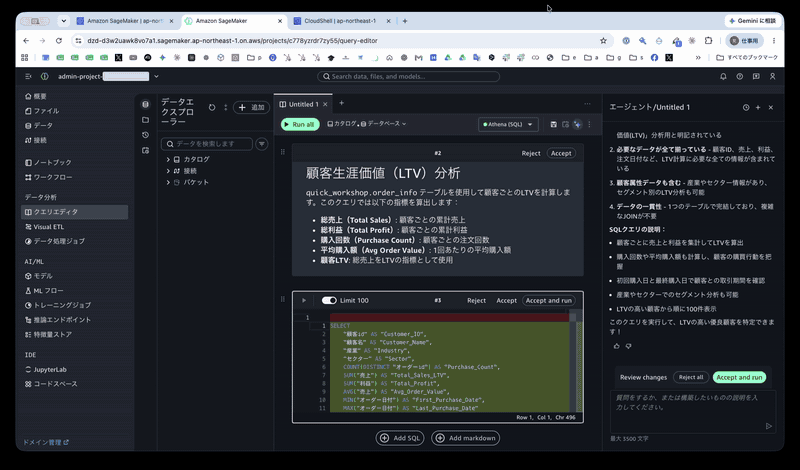
接続セレクタから「Athena (SQL)」を選択し、改めて同じ質問を送信します。すると、エージェントは Glue カタログ → データベース → テーブルと探索したうえで、ビジネスメタデータを確認し、次のように order_info を推奨してきました。
以下、一連の流れをご覧ください。
応答の要点を引用します。
quick_workshop.order_info(最も推奨)このテーブルには「LTV」用語タグが付けられており、顧客の購買行動分析・売上分析の中核データセットとして設計されています。
選定理由:
- 顧客ID(
顧客id)で顧客ごとのデータ集計が可能- 売上データ(
売上)が含まれており、LTVの基本指標- オーダー日付(
オーダー日付)で期間分析が可能- 利益(
利益)データも含まれ、より詳細な分析が可能- 産業やセクター情報も含まれ、セグメント別のLTV分析も実施可能
- ビジネスメタデータでLTV分析に特化していることが明記されている
注目すべきは選定理由です。1点目で Step 2 で付与した「LTV」用語タグを明示的に引用し、2点目では 付与したサマリー(顧客の購買行動分析・売上分析の中核データ)をそのまま引用しています。order_info のカラムに「LTV」という名前は存在しないにもかかわらず、ビジネスメタデータを根拠にテーブルを特定できていることが確認できました。これがビジネスコンテキスト統合の効果です。
Step 5: 生成された SQL を実行してみる(つまずきポイント)
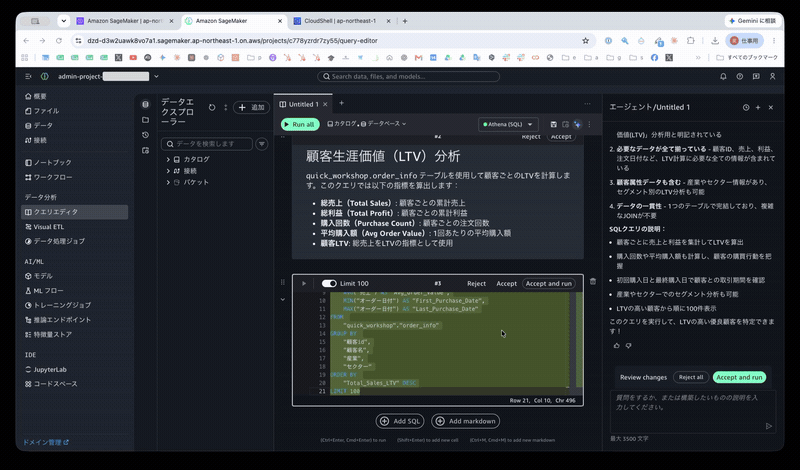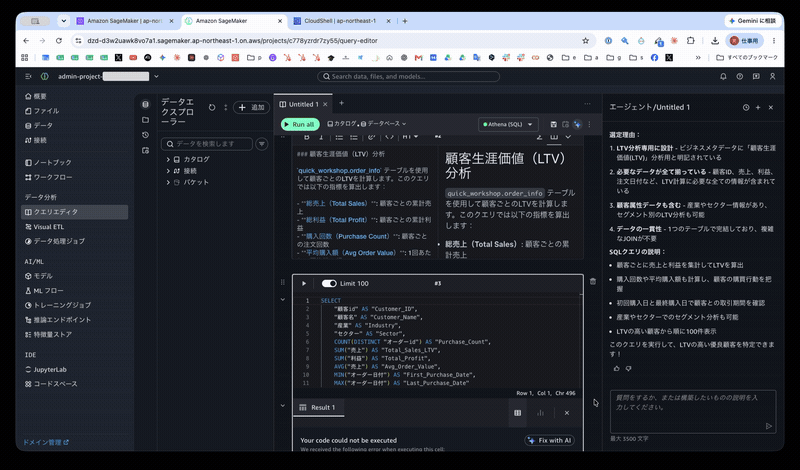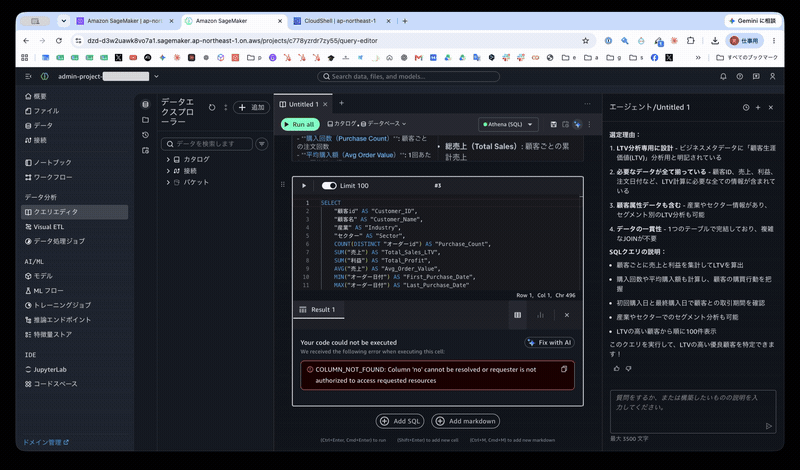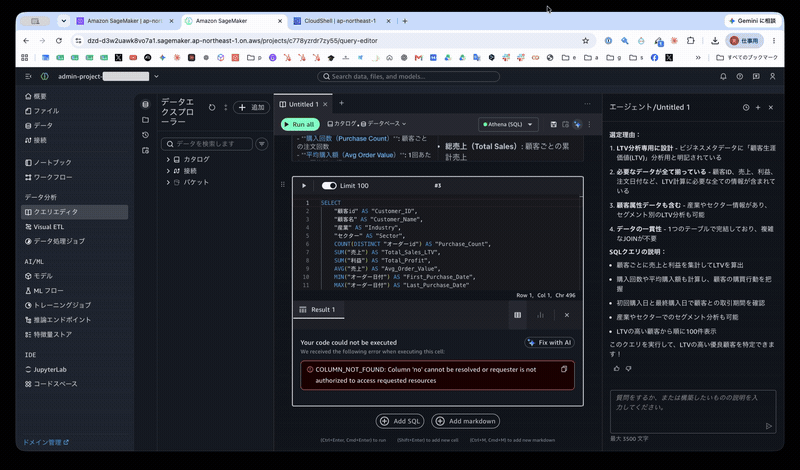
エージェントは「顧客別LTV分析」についてと、その SQL を生成し、セルに挿入しました。
顧客生涯価値(LTV)分析
quick_workshop.order_infoテーブルを使用して顧客ごとのLTVを計算します。このクエリでは以下の指標を算出します:
- 総売上(Total Sales): 顧客ごとの累計売上
- 総利益(Total Profit): 顧客ごとの累計利益
- 購入回数(Purchase Count): 顧客ごとの注文回数
- 平均購入額(Avg Order Value): 1回あたりの平均購入額
- 顧客LTV: 総売上をLTVの指標として使用
SELECT
"顧客id" AS "Customer_ID",
"顧客名" AS "Customer_Name",
"産業" AS "Industry",
"セクター" AS "Sector",
COUNT(DISTINCT "オーダーid") AS "Purchase_Count",
SUM("売上") AS "Total_Sales_LTV",
SUM("利益") AS "Total_Profit",
AVG("売上") AS "Avg_Order_Value",
MIN("オーダー日付") AS "First_Purchase_Date",
MAX("オーダー日付") AS "Last_Purchase_Date"
FROM
"quick_workshop"."order_info"
GROUP BY
"顧客id",
"顧客名",
"産業",
"セクター"
ORDER BY
"Total_Sales_LTV" DESC
LIMIT 100
右の [Accept and run] ボタンを押してクエリを実行します。
下記のエラーが発生しました。noというカラムがないのか、そもそも権限が付与されていないかと予想されます。
COLUMN_NOT_FOUND: Column 'no' cannot be resolved or requester is not authorized to access requested resources
最初は、[Fix with AI]ボタンやチャットから修正を試みましたが、最終的にエラーの原因は、SageMakerのIAMロールAmazonSageMakerAdminIAMExecutionRole_1 にテーブルへのLake Formation権限付与がされていなかったためです。権限を付与してリトライしたら成功しました。
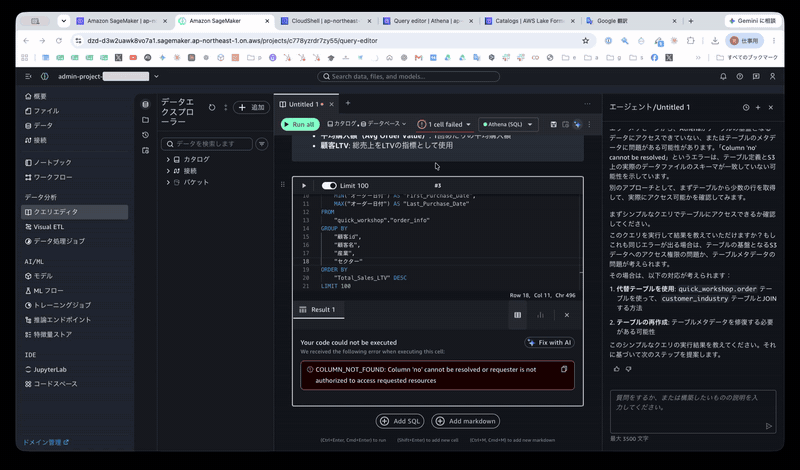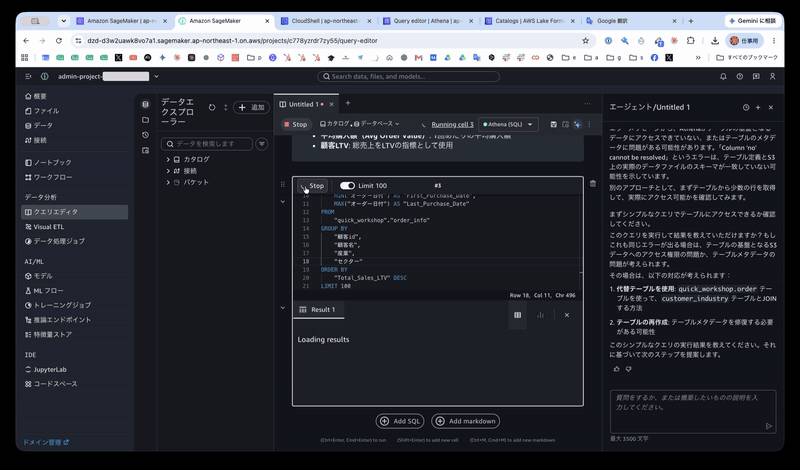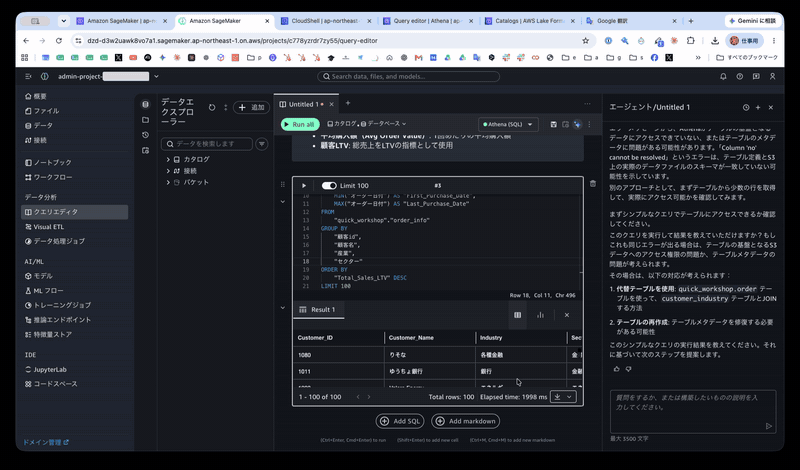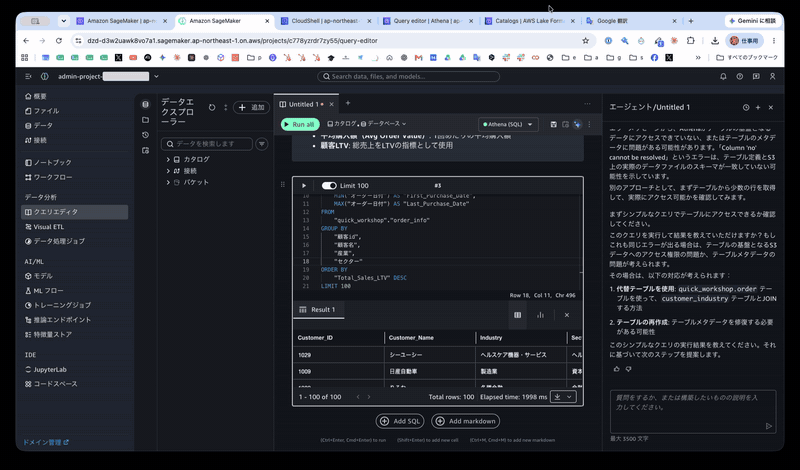
実際に取得したデータは以下のとおりです。(前頭の数件の抜粋です。)
| Customer_ID | Customer_Name | Industry | Sector | Purchase_Count | Total_Sales_LTV | Total_Profit | Avg_Order_Value | First_Purchase_Date | Last_Purchase_Date |
|---|---|---|---|---|---|---|---|---|---|
| 1029 | シーユーシー | ヘルスケア機器・サービス | ヘルスケア | 58 | 55719.21 | 5953.2038 | 415.815 | 2018/1/14 | 2021/12/24 |
| 1009 | 日産自動車 | 製造業 | 資本財・サービス | 102 | 43807.5424 | 3970.0102 | 253.2227884 | 2018/3/3 | 2021/12/25 |
| 1080 | りそな | 各種金融 | 金融 | 102 | 42904.167 | 5531.8834 | 223.4592031 | 2018/3/17 | 2021/12/30 |
| 1011 | ゆうちょ銀行 | 銀行 | 金融 | 65 | 41255.9471 | 6449.8554 | 312.5450538 | 2018/6/15 | 2021/12/22 |
| 1093 | Valero Energy | エネルギー | エネルギー | 58 | 41220.4188 | 10308.6297 | 392.5754171 | 2018/3/18 | 2021/12/16 |
| 1060 | ビックカメラ | 小売 | 一般消費財・サービス | 58 | 40360.163 | 7937.4915 | 366.9105727 | 2018/1/21 | 2021/12/24 |
| 1088 | 日本包材株式会社 | コンシューマ製品 | 生活必需品 | 87 | 40326.344 | 1690.5775 | 219.164913 | 2018/3/21 | 2021/12/31 |
業務用語での問い合わせから、テーブルの発見・SQL 生成・実データの算出まで一連の流れを確認できました。
考察
今回の検証で得られた知見を整理します。
- ビジネスコンテキスト統合は明確に機能している: カラム名に存在しない「LTV」という業務概念から
order_infoを特定できました。しかもエージェントは選定理由として、付与した用語集タグとサマリーを具体的に挙げており、技術メタデータだけのマッチングではないことが分かります。データスチュワードが整備した用語集や README が、そのままエージェントの精度に効くという設計思想が体感できました。 - メタデータ整備の投資が活きる: 逆に言えば、用語集・サマリー・README が空のままだとこの機能の真価は出ません。今回は付与前のカタログ検索では業務用語で
order_infoに到達できませんでした。既存のカタログ整備への投資をそのまま活用できる、というアナウンスのとおりの挙動でした。 - Query Editor では先に接続が必要: Data Agent にカタログを検索させるには、先に Athena もしくは Redshift の接続を選択しておく必要がありました。
- AWS Lake Formation の権限付与: アセットの作成、テーブルメタデータの取得ができたとしても、クエリできるかは、アクセス権限がないとエラーになりますので権限付与が必要です。これは、[Fix with AI]ボタンやチャットから変更できません。
制限事項として、Data Agent は SageMaker Unified Studio の UI(Data Notebook / Query Editor)でのみ利用でき、CLI / SDK からの直接呼び出しはできません。一方で、エージェントが参照するビジネスメタデータの付与は今回のように datazone の API で完全に自動化・コード化できるため、複数テーブルへのメタデータ整備をスクリプト化しておくと、この機能の効果を組織全体に広げやすいと感じました。
最後に
Amazon SageMaker Data Agent のビジネスコンテキスト統合を、quick_workshop.order_info を題材に試してみました。用語集タグとサマリーを付与した結果、エージェントは「LTV 分析に使えるデータは?」という業務用語の質問から、カラム名に LTV を持たない order_info を正しく特定し、その根拠として付与したメタデータを引用してくれました。
技術的なテーブル名を知らない業務担当者でも、整備されたビジネス用語でデータにたどり着けるのは大きな価値です。一方で、アセットの作成、テーブルメタデータの取得ができたとしても、クエリできるかは、アクセス権限がないとエラーになりますので権限付与が必要です。データ活用する立場とデータガバナンスを管理する立場は別なので、正しい動作とも言えます。
メタデータの付与自体は datazone create-asset-revision で自動化できますので、カタログの整備とあわせて、Data Agent を活用したセルフサービス分析の土台づくりを進めてみてはいかがでしょうか。この記事がどなたかのお役に立てば幸いです。











