![[New Service] Amazon Bedrock Managed Knowledge Base Fully Managed RAG Service Now Generally Available (GA)](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[New Service] Amazon Bedrock Managed Knowledge Base Fully Managed RAG Service Now Generally Available (GA)
This page has been translated by machine translation. View original
This is Ishikawa from the Cloud Business Division. At AWS New York Summit on June 17, 2026, Amazon Bedrock Managed Knowledge Base became generally available (GA). It is a fully managed RAG (Retrieval-Augmented Generation) service that allows you to build production-quality AI agents based on enterprise data without managing your own vector databases or data pipelines.
This looks like a strong option for those who want to reduce the man-hours spent on building and operating RAG foundations and quickly move from prototypes to production environments.
What is Amazon Bedrock Managed Knowledge Base
Amazon Bedrock Managed Knowledge Base is a fully managed RAG service where AWS handles everything from data ingestion to vectorization and retrieval, simply by connecting the data sources scattered throughout your organization.
Until now, enabling generative AI applications to answer based on your own company's data required setting up vector stores, handling embedding processing, and building and operating data synchronization pipelines. This service eliminates the need for these tasks, allowing developers to focus on designing agent experiences.
Amazon Bedrock Knowledge Bases offers two types: the Managed Knowledge Base (MANAGED type), where AWS manages the storage, indexing, and retrieval infrastructure, and the traditional Custom Knowledge Base, where you build and manage your own vector store. The one that became GA this time is the former, where embedding and reranking use service-managed models by default (with the option to specify your own models), and storage is also automatically managed.
The overall picture is as follows.
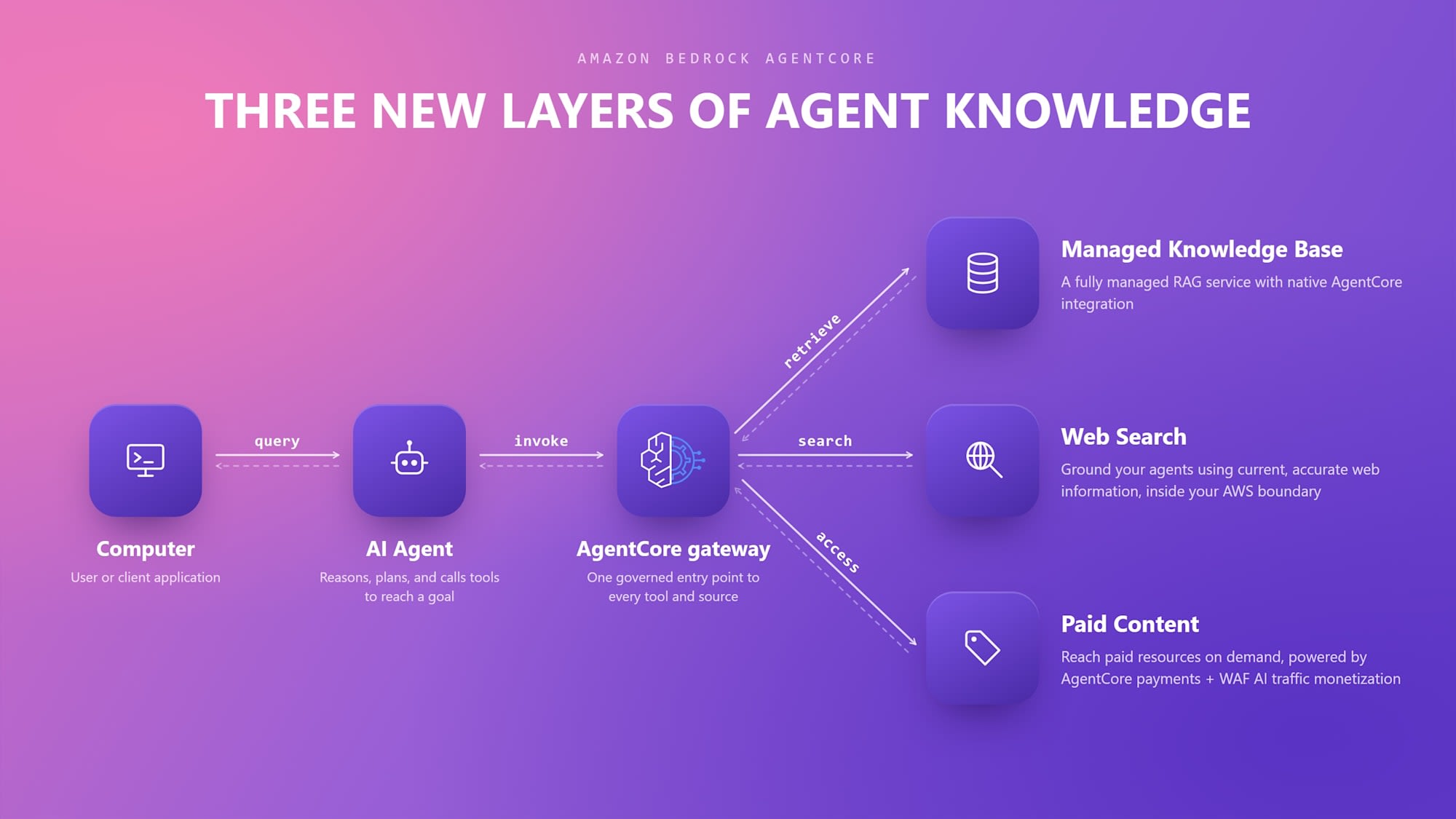
Quote: New in Amazon Bedrock AgentCore: Build agents with broader knowledge and continuous learning
What's New in This Service
The main features of Amazon Bedrock Managed Knowledge Base are as follows.
- 6 native data source connectors included (Amazon S3, SharePoint, Confluence, Google Drive, OneDrive, Web Crawler)
- Automatic data synchronization and managed vector storage optimized for price-performance ratio
- High-precision retrieval through hybrid search and document ranking
- Agentic retrieval that plans and executes queries across multiple knowledge bases, supporting multi-hop queries
- Multimodal knowledge base construction supporting text, video, audio, and images
- Native integration with Amazon Bedrock AgentCore
Operational considerations such as selection of embedding and reranking models, rate limits, and scalability are also managed by AWS. This significantly reduces the engineering effort that was previously required to build custom ingestion pipelines.
Agentic Retrieval
The retrieval in this service goes beyond simple chunk (document fragment) matching. It plans queries across multiple knowledge bases, associates concepts, and evaluates intermediate results to derive the information needed for answers. A key feature is the ability to handle complex queries spanning multiple topics without having to tune the retrieval logic yourself.
Supported Regions
Available in the following regions at GA.
- US East (N. Virginia)
- US West (Oregon)
- Asia Pacific (Sydney, Tokyo)
- Europe (Ireland, Frankfurt, London)
- AWS GovCloud (US-West)
The fact that the Tokyo region is supported is a welcome point for domestic users.
Anticipated Use Cases
The official announcement and related blog posts highlight the following use cases.
- Internal knowledge search and work assistants for employees
- Customer support automation and improved response accuracy
- Handling inquiries about internal policies and business procedures
- Answering complex queries spanning multiple topics
In particular, improved accuracy through agentic retrieval can be expected for inquiries that require understanding across multiple documents, such as internal policies and procedures.
How to Use
You can get started by creating a knowledge base from the Amazon Bedrock console and connecting a data source connector. A link is already displayed at the top of the screen.

Specify the S3 path of the document in the S3 URL and click the [Create knowledge base] button to create it immediately.
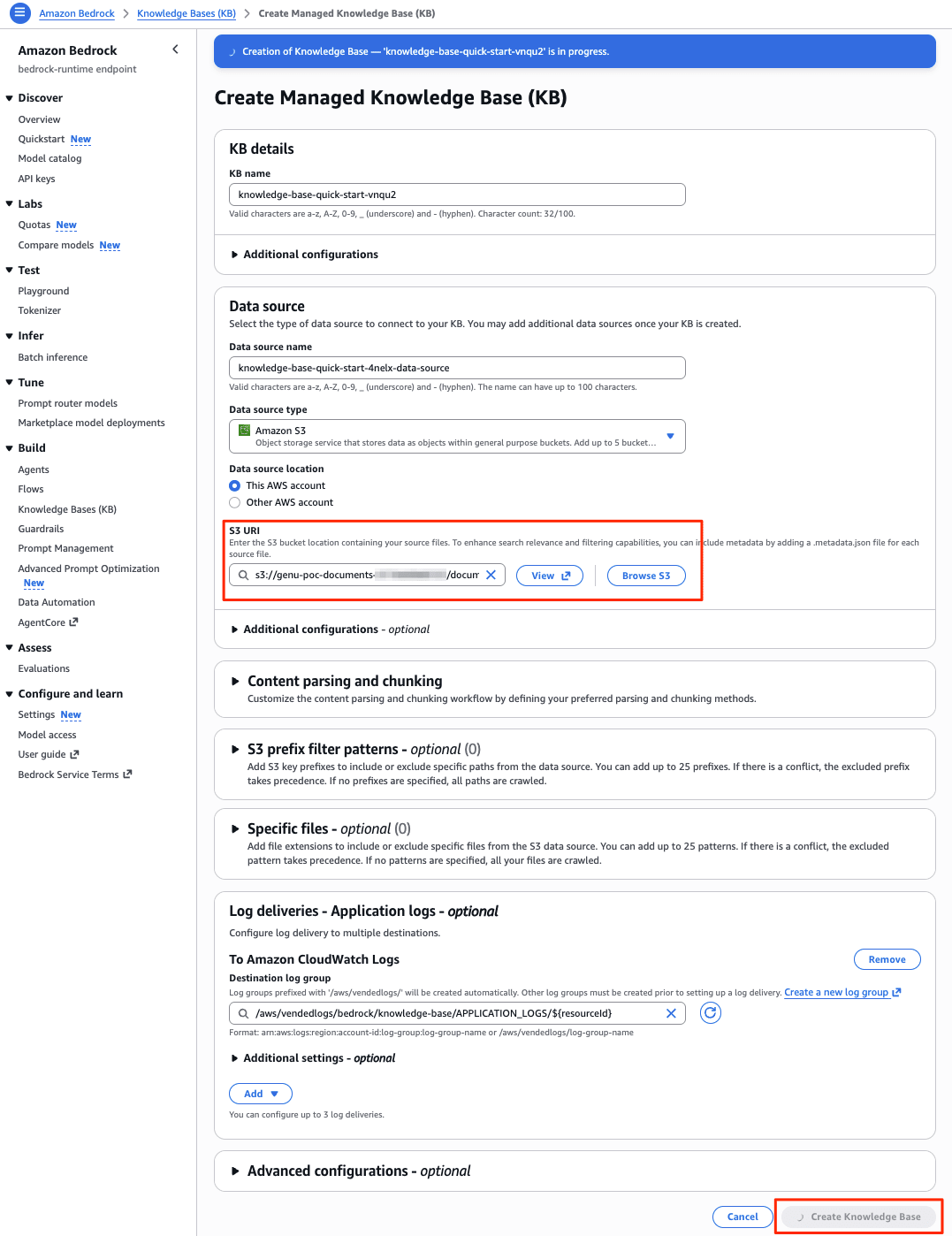
It may depend on the volume of documents, but it was completed in 2 to 3 minutes.
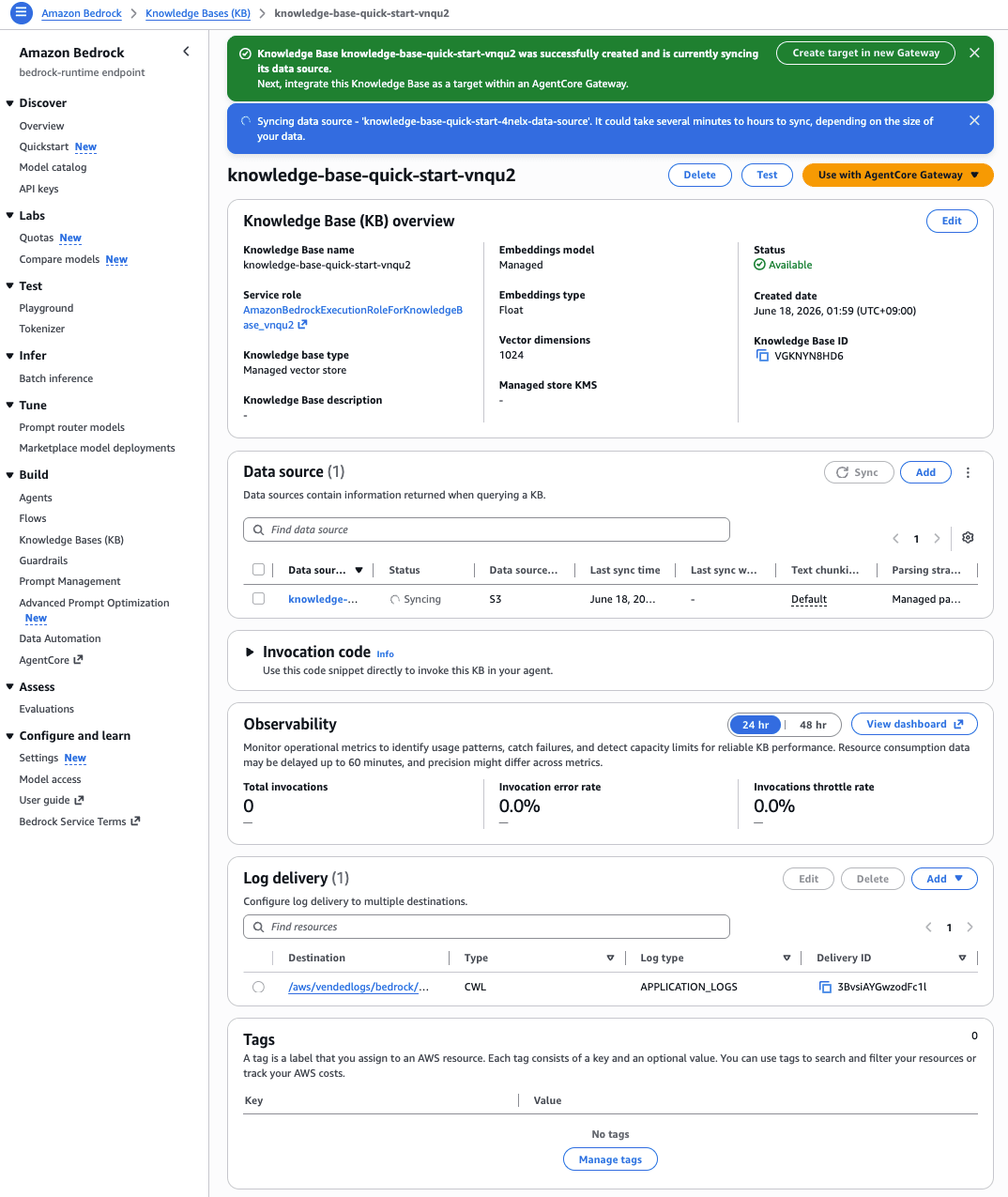
For specific creation procedures and API specifications, please refer to the official documentation mentioned below.
Notes on Usage
- Regarding pricing, the announcement did not include specific details. For actual use, we recommend checking the latest pricing structure on the official pricing page (see the official documentation and pricing page for details).
- When connecting external services such as SharePoint or Google Drive as data sources, authentication and permission settings on each service's side will be required (see the official documentation for details).
Closing
With the GA of Amazon Bedrock Managed Knowledge Base, you can now quickly launch production-quality AI agents based on your own company's data without building or operating your own vector stores or data synchronization pipelines. With 6 native connectors, multimodal support, agentic retrieval, and native integration with Amazon Bedrock AgentCore, the development experience for RAG applications has taken a major step forward.
If you have been struggling with building the foundation for RAG, or if you are considering putting generative AI applications that leverage internal data into production, why not consider this service, which is now also available in the Tokyo region?

