![[新サービス] Amazon Bedrock Managed Knowledge Base フルマネージド RAG サービス が一般提供開始(GA)](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-e3065182082062711612153bbdcf1d96/c04359de689df2f56eb066576ab63fb5/amazon-bedrock?w=3840&fm=webp)
[新サービス] Amazon Bedrock Managed Knowledge Base フルマネージド RAG サービス が一般提供開始(GA)
クラウド事業本部の石川です。2026 年 6 月 17 日のAWS New York Summtにて、Amazon Bedrock Managed Knowledge Base が一般提供(GA)になりました。ベクトルデータベースやデータパイプラインを自前で管理することなく、エンタープライズデータに基づいた本番品質の AI エージェントを構築できる、フルマネージドな RAG(Retrieval-Augmented Generation:検索拡張生成)サービスです。
RAG の基盤構築や運用に費やしていた工数を削減し、プロトタイプから本番環境へ素早く移行したい方にとって、有力な選択肢になりそうです。
Amazon Bedrock Managed Knowledge Base とは
Amazon Bedrock Managed Knowledge Base は、企業内に散在するデータソースを接続するだけで、データの取り込みからベクトル化、検索までを AWS 側がすべて管理してくれるフルマネージド型の RAG サービスです。
生成 AI アプリケーションが自社データに基づいて回答できるようにするには、これまでベクトルストアのセットアップや埋め込み(embedding)処理、データ同期パイプラインの構築・運用が必要でした。本サービスではこれらの作業が不要になり、開発者はエージェントの体験設計に集中できます。
Amazon Bedrock Knowledge Bases には、ストレージ・インデックス・検索インフラまで AWS が管理する**Managed Knowledge Base(MANAGED型)**と、ベクトルストアを自分で構築・管理する従来の Custom Knowledge Baseの 2 種類があります。今回 GA となったのは前者にあたり、埋め込みやリランキングはデフォルトでサービス管理モデルが使われ(任意で独自モデルの指定も可能)、ストレージも自動管理されます。
全体像は以下のとおりです。
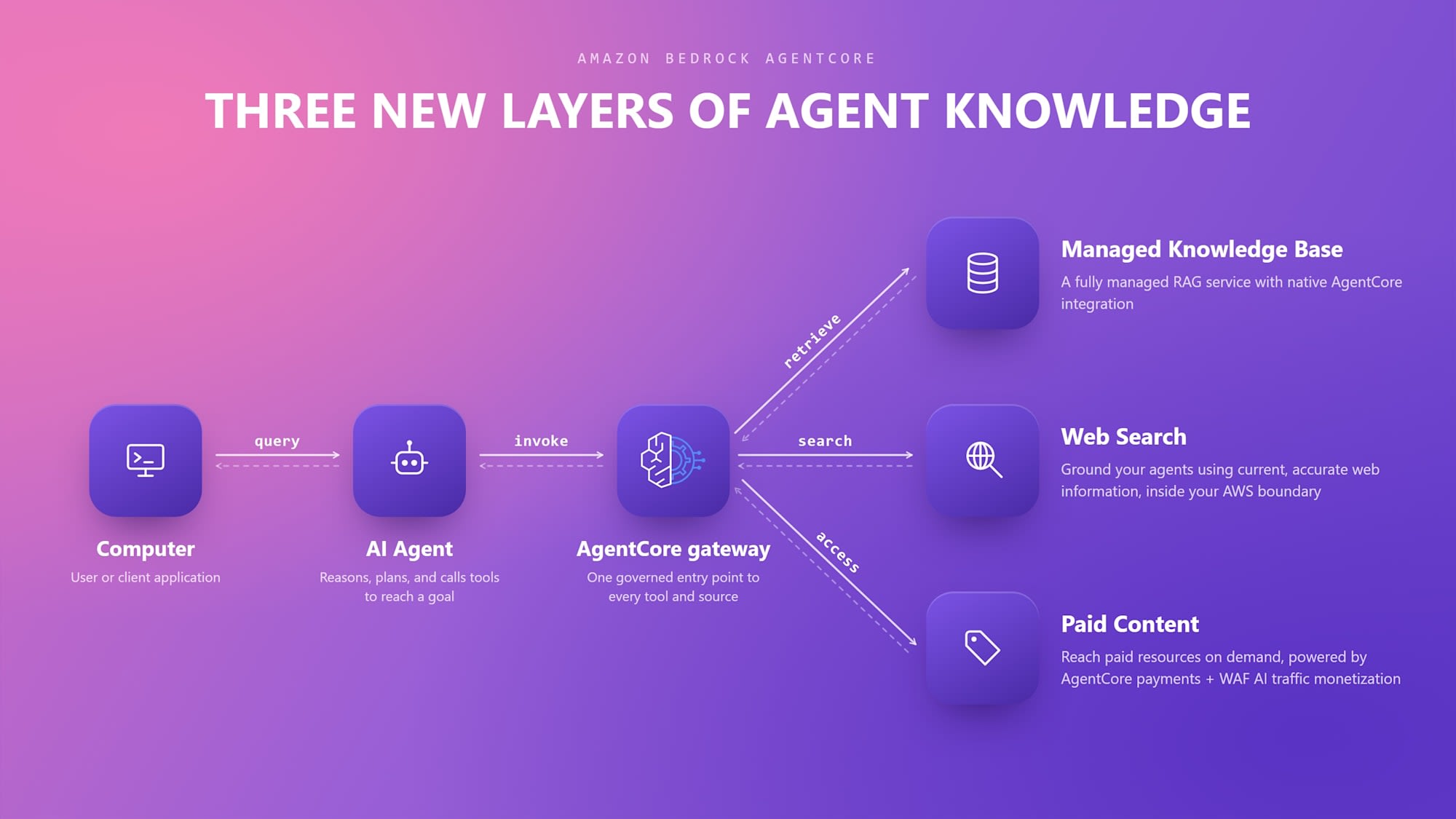
引用: New in Amazon Bedrock AgentCore: Build agents with broader knowledge and continuous learning
新サービスの内容
Amazon Bedrock Managed Knowledge Base の主な特徴は以下のとおりです。
- 6 種類のネイティブデータソースコネクタを搭載(Amazon S3、SharePoint、Confluence、Google Drive、OneDrive、Web クローラー)
- データの自動同期と、価格性能比に最適化されたマネージド型ベクトルストレージ
- ハイブリッド検索とドキュメントランキングによる高精度な検索
- 複数のナレッジベースをまたいでクエリを計画・実行するエージェント型検索(agentic retrieval)。マルチホップな問い合わせにも対応
- テキスト・動画・音声・画像に対応したマルチモーダルなナレッジベースの構築
- Amazon Bedrock AgentCore とのネイティブ統合
埋め込みモデルやリランキング(再ランク付け)モデルの選定、レート制限、スケーラビリティといった運用上の考慮事項も AWS 側で管理されます。これにより、従来はカスタムの取り込みパイプライン構築に要していたエンジニアリング工数を大幅に削減できます。
エージェント型検索(agentic retrieval)
本サービスの検索は、単純なチャンク(文書の断片)一致にとどまりません。複数のナレッジベースにまたがってクエリを計画し、概念間の関連付けや中間結果の評価を行いながら回答に必要な情報を導き出します。複数トピックにまたがる複雑な問い合わせに対しても、検索ロジックを自前でチューニングすることなく対応できる点が特長です。
対応リージョン
GA 時点で以下のリージョンで利用可能です。
- 米国東部(バージニア北部)
- 米国西部(オレゴン)
- アジアパシフィック(シドニー、東京)
- 欧州(アイルランド、フランクフルト、ロンドン)
- AWS GovCloud(米国西部)
東京リージョンが対応している点は、国内のユーザーにとって嬉しいポイントです。
想定されるユースケース
公式の発表および関連ブログでは、以下のようなユースケースが挙げられています。
- 従業員向けの社内ナレッジ検索・業務アシスタント
- カスタマーサポートの自動化と回答精度の向上
- 社内ポリシーや業務手順に関する問い合わせへの対応
- 複数のトピックにまたがる複雑な問い合わせへの回答
特に、社内ポリシーや手続きのように複数のドキュメントを横断して理解する必要がある問い合わせにおいて、エージェント型検索による精度向上が期待できます。
利用方法
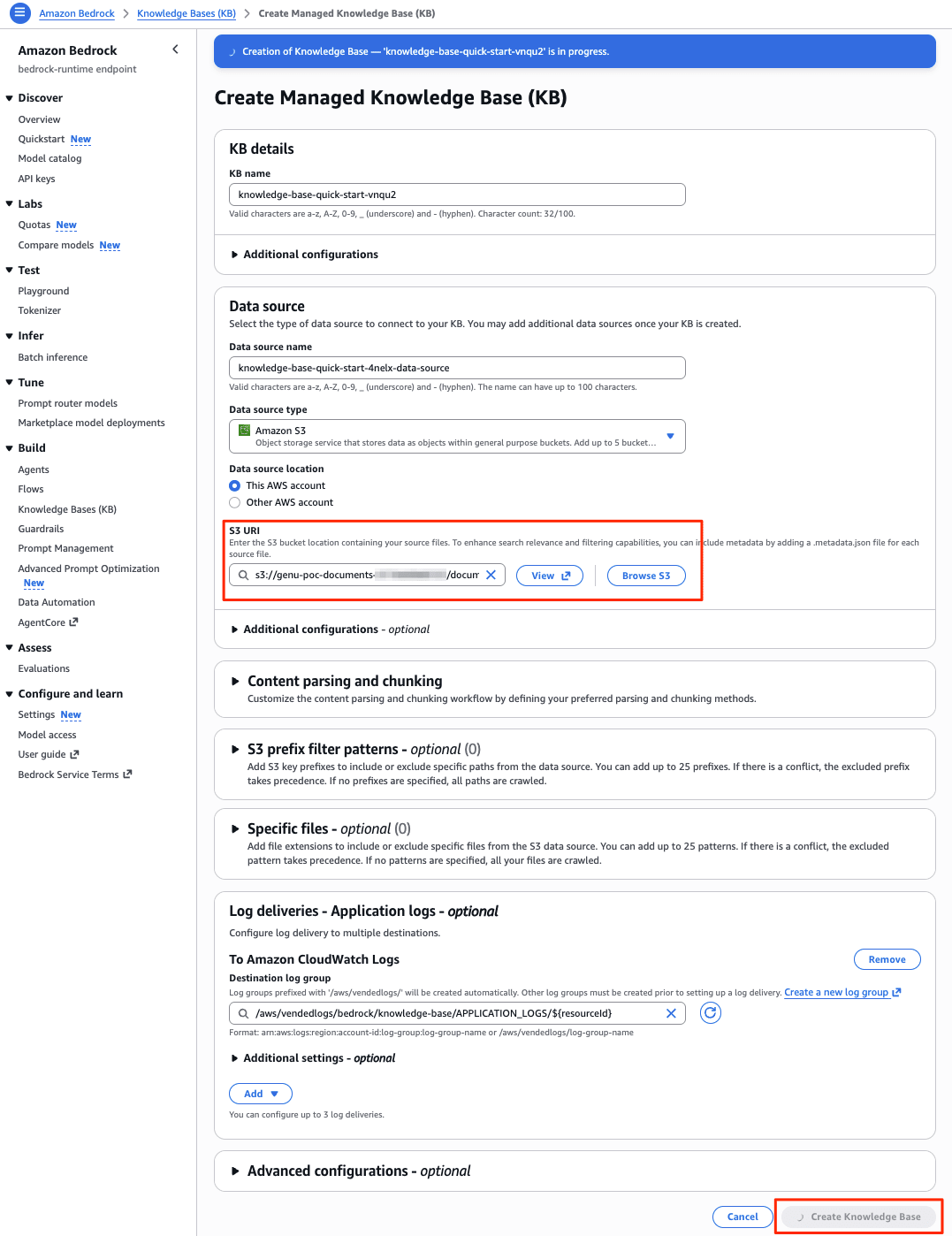
Amazon Bedrock のコンソールからナレッジベースを作成し、データソースコネクタを接続することで利用を開始できます。早速、画面の上部にリンクが表示されています。

S3 URLにドキュメントのS3のパスを指定して、[Create knowlge base]ボタンを押すと直ちに作成されます。
ドキュメントの量によると思いますが、2~3分でできました。
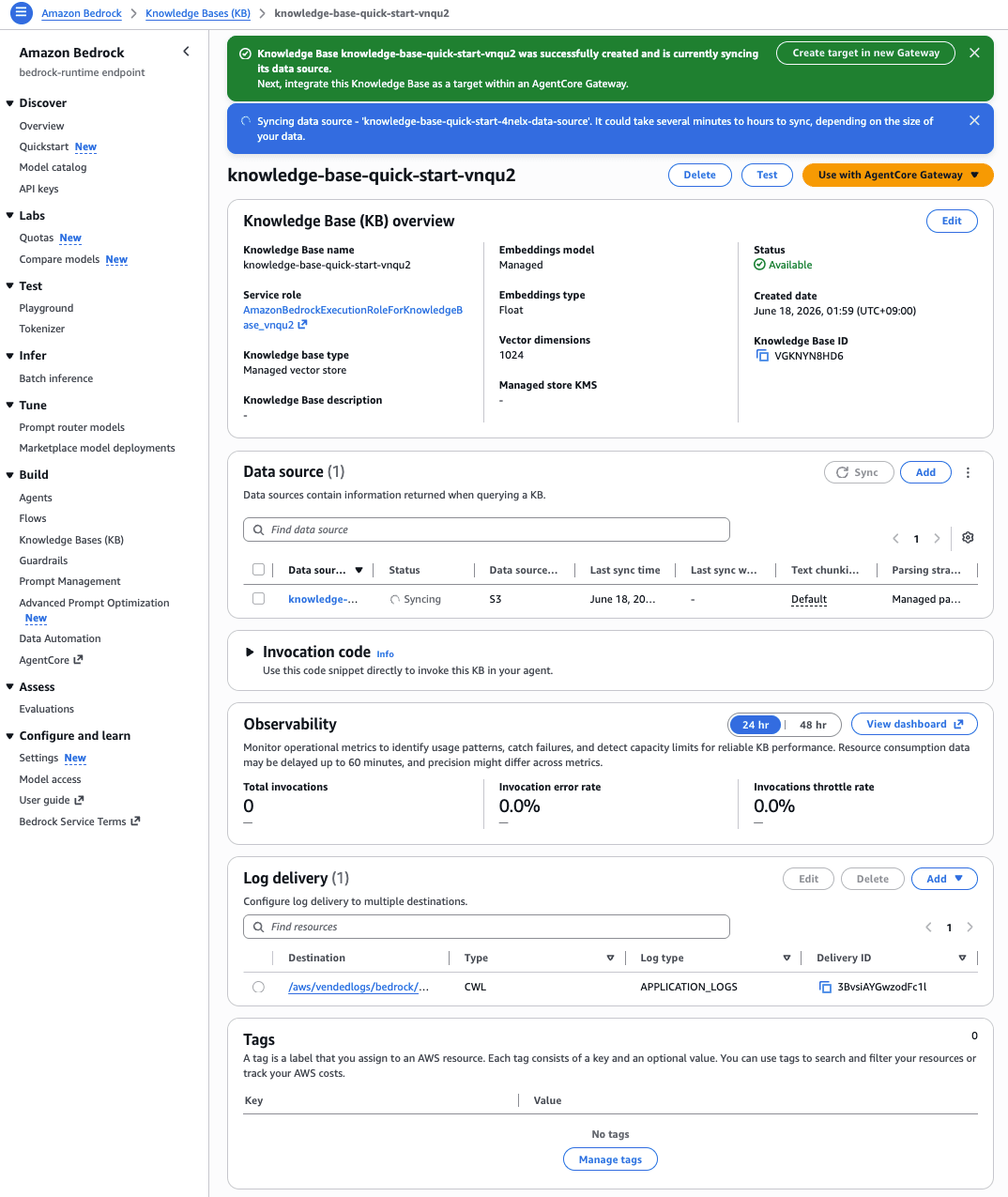
具体的な作成手順や API 仕様については、後述の公式ドキュメントをご確認ください。
利用上の注意
- 料金については、今回の発表では具体的な記載がありませんでした。実際の利用にあたっては、最新の料金体系を公式の料金ページで確認することをおすすめします(詳細は公式ドキュメント・料金ページを参照)。
- データソースとして SharePoint や Google Drive などの外部サービスを接続する場合、各サービス側の認証・権限設定が必要になります(詳細は公式ドキュメントを参照)。
最後に
Amazon Bedrock Managed Knowledge Base の GA により、ベクトルストアやデータ同期パイプラインを自前で構築・運用することなく、自社データに基づいた本番品質の AI エージェントを素早く立ち上げられるようになりました。6 種類のネイティブコネクタ、マルチモーダル対応、エージェント型検索、そして Amazon Bedrock AgentCore とのネイティブ統合により、RAG アプリケーションの開発体験が大きく前進しています。
RAG の基盤構築に手間取っていた方や、社内データを活用した生成 AI アプリケーションの本番化を検討されている方は、東京リージョンでも利用できるようになった本サービスを、検討してみてはいかがでしょうか。









