
AI Co-Authored 40% of the Codebase: A Retrospective on 155 Commits Over 4 Months
This page has been translated by machine translation. View original
Introduction
I spent 4 months developing a RAG system for inquiry handling almost entirely on my own. It's a full-stack application built with Next.js + FastAPI + Amazon Bedrock Knowledge Bases. 155 commits, 39 design documents — 62 of those commits, or 40%, were collaborative work with Claude Code (an AI agent).
This isn't a story of "getting some AI help here and there" — it's a record of 4 months of collaborating with AI across every phase: design, implementation, debugging, and refactoring. I'll look back at what AI-assisted development actually looked like, using the commit history as my guide.
The Big Picture in Numbers
First, let me lay out the facts extracted from the git history.
| Item | Value |
|---|---|
| Period | 2026-03-12 to 2026-06-18 (approx. 14 weeks) |
| Total commits | 155 |
| Claude co-authored commits | 62 (40%) |
| Human-only commits | 76 (49%) |
| Dependabot (automated) | 17 (11%) |
Design documents (.plans/) |
39 files |
| Python source code | approx. 4,500 lines |
| TypeScript/TSX source code | approx. 3,000 lines |
| Commit type breakdown | feat: 37, fix: 27, chore: 29, build: 27, docs: 9, refactor: 8 |
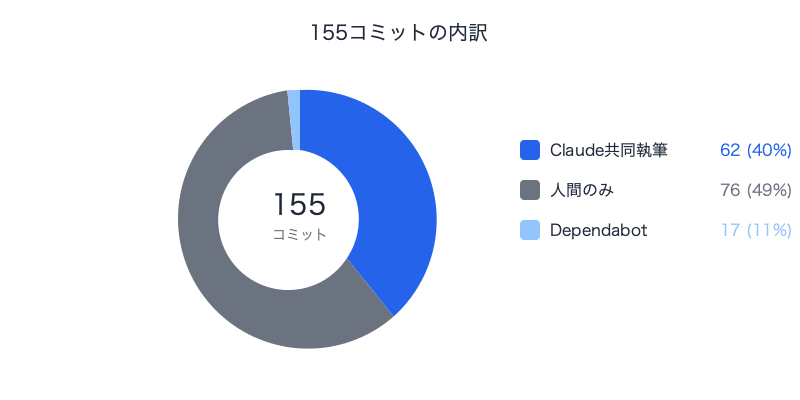
Claude co-authorship is determined mechanically by checking whether the commit message trailer contains Co-Authored-By: Claude. Since Claude Code automatically appends this trailer at commit time, there's no risk of manual omissions.
Opus → Sonnet: Model Switches Preserved in History
The breakdown of the 62 AI co-authored commits was as follows.
| Model | Commits | Period |
|---|---|---|
| Claude Opus 4.6 | 13 | 2026-03-12 to 03-18 (first week) |
| Claude Sonnet 4.6 | 49 | 2026-03-24 to 06-18 (all thereafter) |
I started development with Opus (the top-tier model) for the first week, then switched to Sonnet.
What's interesting is that this switch is naturally recorded in the commit history. Since only the model name in the Co-Authored-By trailer changes, looking back later makes it easy to see "ah, this is where I switched models."
Controlling Co-Authored-By: Toggling via settings.json
This Co-Authored-By trailer can actually be controlled via ~/.claude/settings.json (or .claude/settings.json in the project root).
{
"attribution": {
"commit": "",
"pr": ""
}
}
commit specifies the trailer text appended to commit messages, and pr specifies the trailer text when creating PRs. Setting an empty string "" disables the trailer. By default, Co-Authored-By: Claude <noreply@anthropic.com> is added automatically.
Some teams may want to explicitly mark commits where AI was involved, while others may prefer not to distinguish them from regular commits. This setting lets you switch flexibly.
In this project, I disabled it partway through using this setting, but for retrospective analysis, keeping the trailers would have been more useful. The ability to quantitatively analyze the reality of AI co-development after the fact is only possible because of these trailers.
The .plans/ Directory: 39 Design Sessions with AI
The most unique artifact from this project is the 39 design documents accumulated in the .plans/ directory.
These are design specs created in "planning mode" with Claude Code before implementing each feature. Each document follows a consistent structure.
# Title
**Status:** Complete
**Date:** 2026-XX-XX
## Background
Why this change is needed. Current problems.
## Approach
How to solve it. Rationale for technical choices.
## Changes
What specifically is being changed and how.
Here are a few examples.
Example 1: Structured Output via Bedrock Tool Use
There was a bug where a section that parsed LLM output using json.loads + regex would hit the token limit due to the high number of Japanese tokens, causing JSON to be truncated mid-output. In a design session with Claude Code, we switched to an approach using Bedrock Converse API's toolConfig + toolChoice to guarantee valid JSON at the schema level.
Example 2: Direct OpenSearch NextGen Queries
In response to a bug where Bedrock Knowledge Bases' Retrieve API was returning 403s on OpenSearch NextGen (an AWS-side issue), we implemented a bypass that performs KNN search directly using opensearch-py. The design reuses the existing Bedrock KB index as-is and switches routing with a single environment variable.
These design documents aren't "throwaway" artifacts — they function as a log of the project's decision-making. Why this approach was chosen, what other options existed, what should be reconsidered in the future — they serve a role similar to ADRs (Architecture Decision Records).
Where AI Helped: Analysis by Pattern
Categorizing the 62 AI co-authored commits reveals the scenarios where AI was especially powerful.
1. Initial Implementation of Full-Stack Features (feat: approx. 20 commits)
Where AI showed its greatest strength was implementing backend API + frontend UI + tests all at once in a single pass.
For example, the following were completed in a single work session:
- Adding a FastAPI endpoint
- Defining Pydantic models
- Creating a React component on the frontend
- Adding SSE events
- Updating the OpenAPI spec
Doing this alone as a human drains focus through context switching (bouncing between Python → TypeScript → CSS), but AI can traverse all layers while maintaining context.
2. Debugging: Forming and Testing Hypotheses (fix: approx. 15 commits)
When you hand AI a "investigate this bug" task, it reads through the codebase, forms multiple hypotheses, and starts validating from the most likely one. In cases like the SSE streaming issue mentioned earlier, where what looks like one problem turns out to be a compound of four independent causes, a human alone would repeatedly fix one thing and wonder "did that fix it… no it didn't," while AI was able to analyze it structurally.
3. Refactoring and Migrations (refactor: approx. 8 commits)
boto3 → anthropic SDK migration, Docker infrastructure setup, legacy code removal — these "replace without breaking" tasks are AI's strong suit. Swapping out internal implementations while preserving existing interfaces requires a precise understanding of the blast radius, and AI can work with the entire codebase in context.
4. Documentation and Configuration (docs/chore: approx. 15 commits)
Auto-generating OpenAPI specs, updating user manuals, organizing .env files, optimizing Dockerfiles — the barrier to asking AI to handle these "necessary but easy to put off" tasks is extremely low.
Where AI Struggled
On the other hand, there were also cases where handing things off to AI didn't go as expected.
1. Internal Domain-Specific Knowledge
Internal rules like "if this ticket's category ID is a specific value, exclude it" aren't something AI knows without being told. In the early data pipeline implementation, aligning on this kind of domain logic took time.
2. Troubleshooting Infrastructure and Network Issues
SOCKS proxy settings over VPN, EC2 instance role permissions, nginx buffering behavior — environment-specific issues that can only be uncovered by actually running things can't be resolved by AI alone. It turns into an interactive debugging process of showing AI the logs and working through it together.
3. Fine-Grained UI Adjustments
Situations like "this button position is a bit off…" or "this color feels slightly wrong…" — these sensory UI tweaks have a high cost to verbalize, and in many cases it was faster to just fix them myself.
Development Speed in Practice
Looking at the monthly commit distribution reveals the ebb and flow of development.
| Month | Commits | Primary Work |
|---|---|---|
| March | 24 | Prototype construction, data pipeline foundation |
| April | 55 | UI overhaul, SSE streaming |
| May | 60 | Structured output, SDK migration, OpenAPI setup |
| June | 16 | OpenSearch NextGen migration, API Gateway integration |
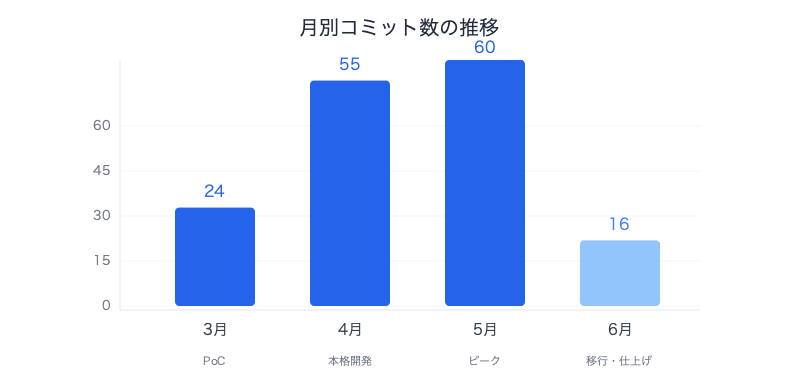
The plan was to use March as PoC and technical validation (0.4 person-months) and begin full development from April (0.8 person-months), but commit counts spiked sharply in April and May. This coincides with the period when I was getting the hang of the AI co-development rhythm.
Notably, a single engineer released 14 versions of a full-stack application (frontend + backend + data pipeline + infrastructure + documentation) in 4 months. I believe this pace would not have been achievable without AI co-development.
The AI Co-Development Workflow
Here's what the actual development flow looked like.
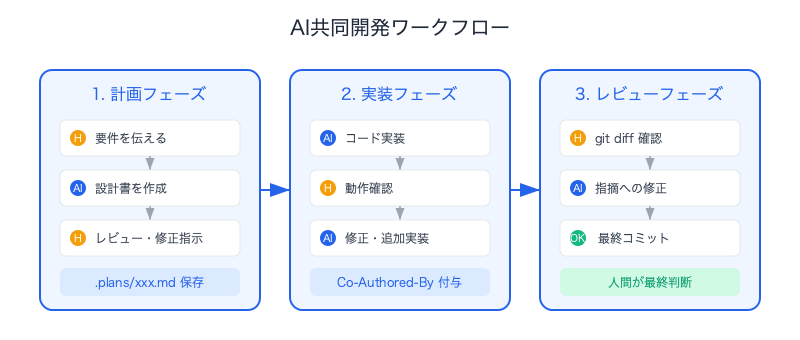
1. Planning Phase
Human: "I want to add ○○ feature. Requirements are △△"
Claude Code (plan mode): Creates design doc covering background, approach, and changes
Human: Reviews and provides revision instructions
→ Saved as .plans/xxx.md
2. Implementation Phase
Claude Code: Implements code based on design doc
Human: Verifies behavior and provides feedback
Claude Code: Makes fixes and additional implementations
→ Commit (Co-Authored-By: Claude trailer automatically appended)
3. Review Phase
Human: Reviews git diff
Claude Code: Makes fixes in response to code review comments
→ Final commit
The key point is that humans always make the final call on review and merge. AI proposes and implements, but the judgment of "this is good enough" is made by the human.
CLAUDE.md: "Development Guidelines" for AI
The CLAUDE.md file in the project root contains development rules written for the AI.
## LLM Output Structured Format
Always use Bedrock tool use to enforce structured JSON output.
Never use regex or json.loads to parse raw LLM text responses.
## Scope Rules
- Never generate code for features not explicitly requested.
- Never add fields to Pydantic models unless referenced in both route and frontend.
- If a function has no callers after implementation, delete it before committing.
This is the same concept as a coding guidelines document handed to a human developer. Because AI tends to "helpfully" add extra features or generate helper functions that never get used, explicitly constraining scope is how quality is maintained.
Accumulating lessons learned from past mistakes here prevents the same errors from recurring.
Conclusion
Looking back on 4 months of AI co-development, there are several things I can say with confidence.
What AI changed:
- Elimination of context switching — For work spanning Python ↔ TypeScript ↔ CSS ↔ Docker, AI completes the implementation before human focus breaks down
- Elimination of "too much trouble, I'll do it later" — Tasks like documentation, tests, and config file cleanup — things that should be done but tend to get deferred — can be easily delegated
- Documented design decisions — The 39 files in
.plans/are artifacts that would never have existed without dialogue with AI. They're records that wouldn't have been preserved with the traditional approach of deciding "let's do it this way" verbally and jumping straight into implementation
What AI didn't change:
- Design decisions are the human's job — What to build, why to build it, and which options to choose are all decided by humans
- Domain knowledge must be taught — Internal rules and tacit knowledge need to be verbalized and communicated to AI, which takes effort
- Review cannot be skipped — Whether code is written by AI or by a human, the importance of review doesn't change
The number 62/155 isn't a record of "delegating everything to AI" — it's a record of going through the cycle of design, implementation, and review 155 times together with AI.
