
AIがコードベースの40%を共同執筆した:4ヶ月155コミットの振り返り
はじめに
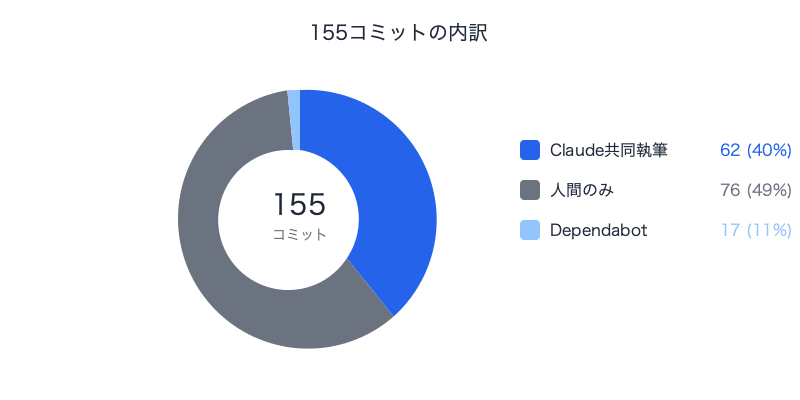
私は4ヶ月間にかけて、問い合わせ対応向けRAGシステムをほぼ一人で開発しました。Next.js + FastAPI + Amazon Bedrock Knowledge Basesという構成のフルスタックアプリケーションです。155コミット、39の設計ドキュメント — その40%にあたる62コミットがClaude Code(AIエージェント)との共同作業でした。
「一部をAIに手伝ってもらった」のではなく、設計・実装・デバッグ・リファクタリングの全フェーズでAIと協働した4ヶ月間の記録です。コミット履歴から、AIとの共同開発が実際にどのようなものだったかを振り返ります。
数字で見る全体像
まず、git履歴から抽出したファクトを並べます。
| 項目 | 値 |
|---|---|
| 期間 | 2026-03-12 〜 2026-06-18(約14週間) |
| 総コミット数 | 155 |
| Claude共同執筆コミット | 62(40%) |
| 人間のみのコミット | 76(49%) |
| Dependabot(自動) | 17(11%) |
設計ドキュメント(.plans/) |
39ファイル |
| Python ソースコード | 約4,500行 |
| TypeScript/TSX ソースコード | 約3,000行 |
| コミットタイプ内訳 | feat: 37, fix: 27, chore: 29, build: 27, docs: 9, refactor: 8 |
Claude共同執筆の判定は、コミットメッセージのトレーラーに Co-Authored-By: Claude が含まれるかどうかで機械的に判別しています。Claude Codeはコミット時に自動でこのトレーラーを付与するため、手動での記録漏れがありません。
Opus → Sonnet:AIモデルの切り替えが履歴に残る
62件のAI共同執筆コミットの内訳は以下でした。
| モデル | コミット数 | 期間 |
|---|---|---|
| Claude Opus 4.6 | 13 | 2026-03-12 〜 03-18(最初の1週間) |
| Claude Sonnet 4.6 | 49 | 2026-03-24 〜 06-18(以降すべて) |
最初の1週間はOpus(最上位モデル)で開発を始め、その後Sonnetに切り替えています。
興味深いのは、この切り替えがコミット履歴に自然と記録されていることです。Co-Authored-By トレーラーのモデル名が変わるだけなので、後から振り返ったときに「あ、ここでモデルを変えたな」とわかります。
Co-Authored-Byの制御:settings.json で切り替え可能
このCo-Authored-Byトレーラーは、実は ~/.claude/settings.json(またはプロジェクトルートの .claude/settings.json)で制御できます。
{
"attribution": {
"commit": "",
"pr": ""
}
}
commit にはコミットメッセージに付与するトレーラーテキスト、pr にはPR作成時のトレーラーテキストを指定します。空文字 "" を設定するとトレーラーが付与されなくなります。 デフォルトでは Co-Authored-By: Claude <noreply@anthropic.com> が自動付与されます。
チームによっては「AIが関与したコミットを明示したい」場合もあれば、「通常のコミットと区別したくない」場合もあるでしょう。この設定で柔軟に切り替えられます。
今回のプロジェクトでは途中からこの設定で無効化しましたが、振り返り分析のためにはトレーラーを残しておく方が有用でした。AI共同開発の実態を後から定量的に分析できるのは、このトレーラーがあってこそです。
.plans/ ディレクトリ:AIとの39回の設計会議
このプロジェクトで最もユニークなアーティファクトは、.plans/ ディレクトリに蓄積された39件の設計ドキュメントです。
これはClaude Codeと機能を実装する前に「計画モード」で作成した設計書です。各ドキュメントの構造は統一されています。
# タイトル
**ステータス:** 完了
**日付:** 2026-XX-XX
## 背景
なぜこの変更が必要か。現状の問題点。
## アプローチ
どう解決するか。技術的な選択の根拠。
## 変更内容
具体的に何をどう変えるか。
いくつか例を挙げます。
例1: Bedrock tool useによる構造化出力
LLMの出力を json.loads + 正規表現でパースしていた箇所で、日本語トークンの多さからトークン上限に達し、JSONが途中で切り捨てられる不具合がありました。Claude Codeとの設計会議で、Bedrock Converse APIの toolConfig + toolChoice を使い、スキーマレベルで有効なJSONを保証するアプローチに切り替えました。
例2: OpenSearch NextGen直接クエリ
Bedrock Knowledge BasesのRetrieve APIがOpenSearch NextGenで403を返すバグ(AWS側の問題)に対し、opensearch-pyで直接KNN検索を行うバイパスを実装しました。既存のBedrock KBインデックスをそのまま利用し、環境変数1つでルーティングを切り替える設計です。
これらの設計書は「使い捨て」ではなく、プロジェクトの意思決定のログとして機能しています。なぜこのアプローチを選んだか、他にどんな選択肢があったか、将来何を再検討すべきか — ADR(Architecture Decision Records)に近い役割です。
AIが助けた場面:パターン別分析
62件のAI共同執筆コミットを分類すると、AIが特に強かった場面が見えてきます。
1. フルスタック機能の初期実装(feat系:約20件)
AIが最も威力を発揮したのは、バックエンドAPI + フロントエンドUI + テストを一気通貫で実装する場面です。
例えば、以下が1回の作業セッションで完成しました。
- FastAPIのエンドポイント追加
- Pydanticモデル定義
- フロントエンドのReactコンポーネント
- SSEイベントの追加
- OpenAPI仕様の更新
人間一人でこれをやると、コンテキストスイッチ(Python → TypeScript → CSSの往復)で集中力が削がれますが、AIはコンテキストを保持したまま全レイヤーを横断できます。
2. デバッグ:原因の仮説立てと検証(fix系:約15件)
AIに「このバグを調査して」と投げると、コードベースを読み込んだ上で複数の仮説を立て、最も可能性の高いものから検証していきます。前述のSSEストリーミング問題のように、一見1つに見える問題が実は4つの独立した原因の複合だったケースでは、人間だけだと最初の1つを直して「治った…?いや治ってない」を繰り返すところを、AIが構造的に分析してくれました。
3. リファクタリングと移行(refactor系:約8件)
boto3 → anthropic SDK移行、Docker基盤の整備、レガシーコードの削除 — これらの「壊さずに置き換える」作業はAIの得意分野です。既存のインターフェースを維持しながら内部実装を差し替える作業は、影響範囲を正確に把握する必要がありますが、AIはコードベース全体をコンテキストに入れて作業できます。
4. ドキュメント・設定(docs/chore系:約15件)
OpenAPI仕様書の自動生成、ユーザーマニュアルの更新、.env の整理、Dockerfileの最適化 — こうした「やらなきゃいけないが後回しにしがちな」作業を、AIに依頼するハードルは極めて低いです。
AIが苦手だった場面
一方で、AIに任せても期待通りにいかなかった場面もあります。
1. 社内固有のドメイン知識
「このチケットのカテゴリIDが特定の値なら対象外として除外する」といった社内ルールは、AIには教えないとわかりません。初期のデータパイプライン実装では、こうしたドメインロジックのすり合わせに時間がかかりました。
2. インフラ・ネットワーク起因のトラブルシューティング
VPN経由のSOCKSプロキシ設定、EC2のインスタンスロール権限、nginxのバッファリング挙動 — 実際に動かしてみないとわからない環境依存の問題は、AIだけでは解決できません。ログを見せながら対話的にデバッグする形になります。
3. UIの微細な調整
「このボタンの位置がちょっと…」「この色味が…」といった感覚的なUI調整は、言語化のコストが高く、自分で直した方が速い場面が多かったです。
開発速度の実際
月別のコミット分布を見ると、開発の濃淡がわかります。
| 月 | コミット数 | 主な作業 |
|---|---|---|
| 3月 | 24 | プロトタイプ構築、データパイプライン基盤 |
| 4月 | 55 | UI刷新、SSEストリーミング |
| 5月 | 60 | 構造化出力、SDK移行、OpenAPI整備 |
| 6月 | 16 | OpenSearch NextGen移行、API Gateway連携 |
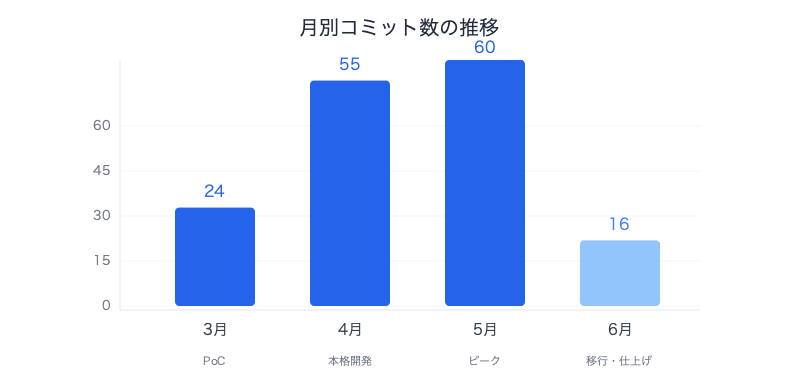
3月はPoCとして技術検証(0.4人月)、4月から本格開発(0.8人月)という計画でしたが、4月・5月にコミット数が急増しています。これはAI共同開発のテンポが掴めてきた時期と一致します。
特筆すべきは、一人のエンジニアがフルスタック(フロントエンド + バックエンド + データパイプライン + インフラ + ドキュメント)を4ヶ月で14バージョンリリースしたという事実です。AI共同開発がなければ、この速度は出なかったと考えています。
AI共同開発のワークフロー
実際の開発フローを紹介します。
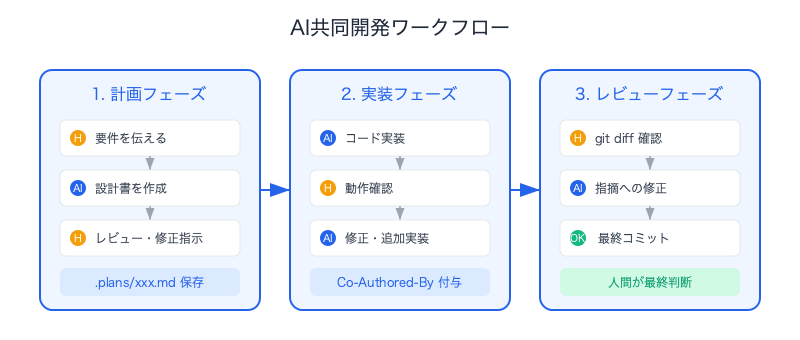
1. 計画フェーズ
人間: 「○○の機能を追加したい。要件は△△」
Claude Code (plan mode): 背景・アプローチ・変更内容の設計書を作成
人間: レビュー・修正指示
→ .plans/xxx.md として保存
2. 実装フェーズ
Claude Code: 設計書に基づいてコード実装
人間: 動作確認・フィードバック
Claude Code: 修正・追加実装
→ コミット(Co-Authored-By: Claude トレーラー自動付与)
3. レビューフェーズ
人間: git diff を確認
Claude Code: コードレビュー指摘への修正
→ 最終コミット
重要なのは、常に人間がレビューとマージの最終判断をしていることです。AIは提案と実装を行いますが、「これで良い」という判断は人間が下します。
CLAUDE.md:AIへの「開発ガイドライン」
プロジェクトルートの CLAUDE.md には、AI向けの開発ルールを記載しています。
## LLM Output Structured Format
Always use Bedrock tool use to enforce structured JSON output.
Never use regex or json.loads to parse raw LLM text responses.
## Scope Rules
- Never generate code for features not explicitly requested.
- Never add fields to Pydantic models unless referenced in both route and frontend.
- If a function has no callers after implementation, delete it before committing.
これは人間の開発者に渡すコーディングガイドラインと同じ発想です。AIが「よかれと思って」余計な機能を追加したり、使われないヘルパー関数を生成したりする傾向があるため、明示的にスコープを制約することで品質を維持しています。
過去の失敗から得た教訓をここに蓄積していくことで、同じミスの再発を防いでいます。
まとめ
4ヶ月間のAI共同開発を振り返って、確信を持って言えることがいくつかあります。
AIが変えたもの:
- コンテキストスイッチの消滅 — Python ↔ TypeScript ↔ CSS ↔ Docker を跨ぐ作業で、人間の集中力が切れる前にAIが実装を完了する
- 「面倒だから後回し」の消滅 — ドキュメント、テスト、設定ファイルの整理など、やった方がいいけど後回しにしがちな作業を気軽に依頼できる
- 設計のドキュメント化 —
.plans/の39ファイルは、AIとの対話がなければ生まれなかった成果物。口頭で「こうしよう」と決めて実装に入る従来のやり方では残らなかった記録
AIが変えなかったもの:
- 設計判断は人間の仕事 — 何を作るか、なぜ作るか、どの選択肢を取るかはすべて人間が決める
- ドメイン知識は教える必要がある — 社内固有のルールや暗黙知は、AIに言語化して伝えるコストがかかる
- レビューは省略できない — AIが書いたコードも、人間が書いたコードも、レビューの重要性は変わらない
62/155という数字は「AIに丸投げした」のではなく、「AIと一緒に設計・実装・レビューのサイクルを155回繰り返した」ことの記録です。










