
I Built an Agent That Automatically Generates and Executes SQL from Natural Language Using Amazon Athena × Bedrock Converse API
This page has been translated by machine translation. View original
Introduction
Amazon Bedrock's Knowledge Base (RAG) is powerful for searching unstructured documents, but it cannot fully handle questions involving aggregation, comparison, or ranking, such as "What is the total sales for Q1 FY2025?"
To address this challenge, we used Bedrock's Converse API (tool_use) to build an agent loop on the application side, enabling Claude to generate SQL, execute it on Athena, and generate answers based on the results.
While it's also possible to use Bedrock Agents (managed service), building your own agent loop gives you the advantage of freedom in streaming control and custom UI. This article introduces the implementation of this approach.
Architecture
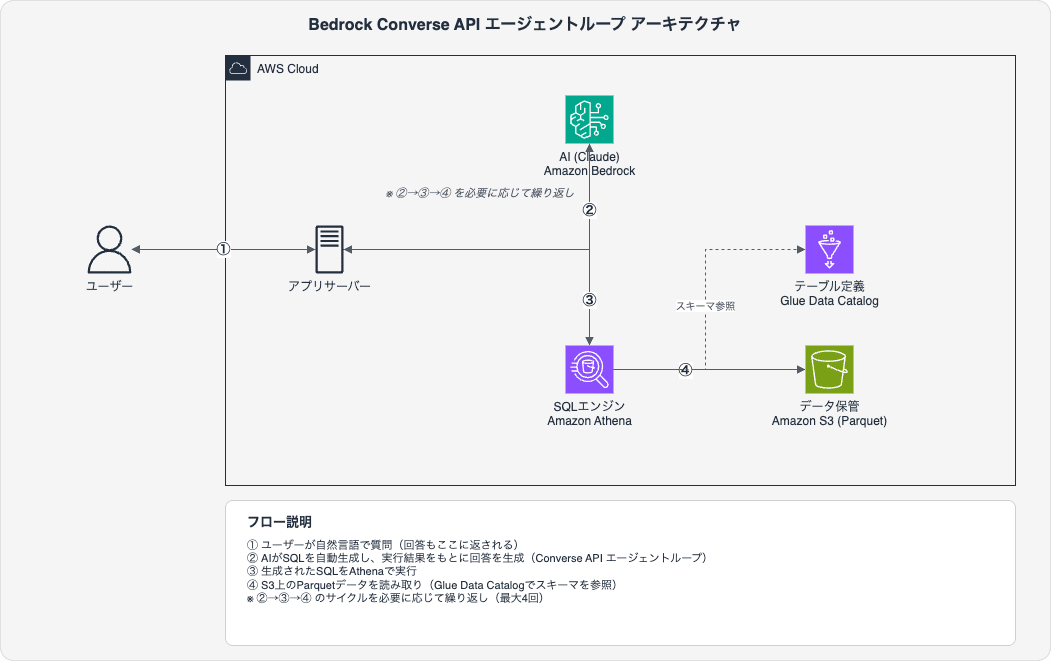
User's question
↓
Application server (FastAPI, etc.)
↓
bedrock_runtime.converse() ← SQL tool defined via tool_use
↓
Claude generates SQL (stop_reason: "tool_use")
↓
App receives SQL and executes directly on Athena (no Lambda needed)
↓
Results added to messages as toolResult
↓
bedrock_runtime.converse() ← Generate answer based on results
↓
(Generate additional SQL if needed → re-execute → loop)
↓
stop_reason: "end_turn" → answer complete
Key point: Instead of Bedrock Agents (managed service), we use the toolConfig of the Converse API to control the loop on the application side. No Lambda or Action Groups are needed — the app calls Athena directly.
Why Converse API Instead of Bedrock Agents?
| Aspect | Bedrock Agents | Converse API + Custom Loop |
|---|---|---|
| Tool execution | Via Lambda (Action Group) | Direct call from app |
| Streaming | Controlled by Agent | Freely customizable |
| UX | Fixed | Can control each step: SQL display, result display, etc. |
| Loop control | Left to Agent | Fine-grained control such as max iteration count |
| Debugging | Check from trace logs | Verify directly from app logs |
| Deployment | Agent + Lambda + Action Group | App only |
If you already have an application server, the Converse API approach is simpler to implement.
Prerequisites & Environment
- An AWS account must be available
- Access to Claude models on Amazon Bedrock must be enabled
- Structured data (CSV/Excel, etc.) must be converted to Parquet format
- Python 3.12 + boto3
- Region: ap-northeast-1 (Tokyo)
Why Parquet?
Athena can also read CSV, but Parquet has the following advantages:
- Columnar format: Reduces scan volume by reading only the necessary columns, lowering costs
- Retains type information: Types such as INT and STRING are automatically recognized
- High compression efficiency: Storage costs are also reduced with Snappy compression
To convert using Python, pandas + pyarrow is the easiest approach:
import pandas as pd
df = pd.read_excel("data.xlsx", sheet_name="Sheet1")
df.to_parquet("output/data.parquet", engine="pyarrow", compression="snappy")
Steps
Step 1: Place Data in S3
Upload Parquet files to S3. The key is to separate by prefix (folder) for each table.
s3://your-bucket/sql/
├── sales/
│ └── sales.parquet
├── employees/
│ └── employees.parquet
└── products/
└── products.parquet
Open the target bucket in the S3 console, create a folder for each table name under the sql/ prefix, and upload the corresponding Parquet file to each folder.
Also create the folder for Athena query result output (athena-results/), which will be described later.
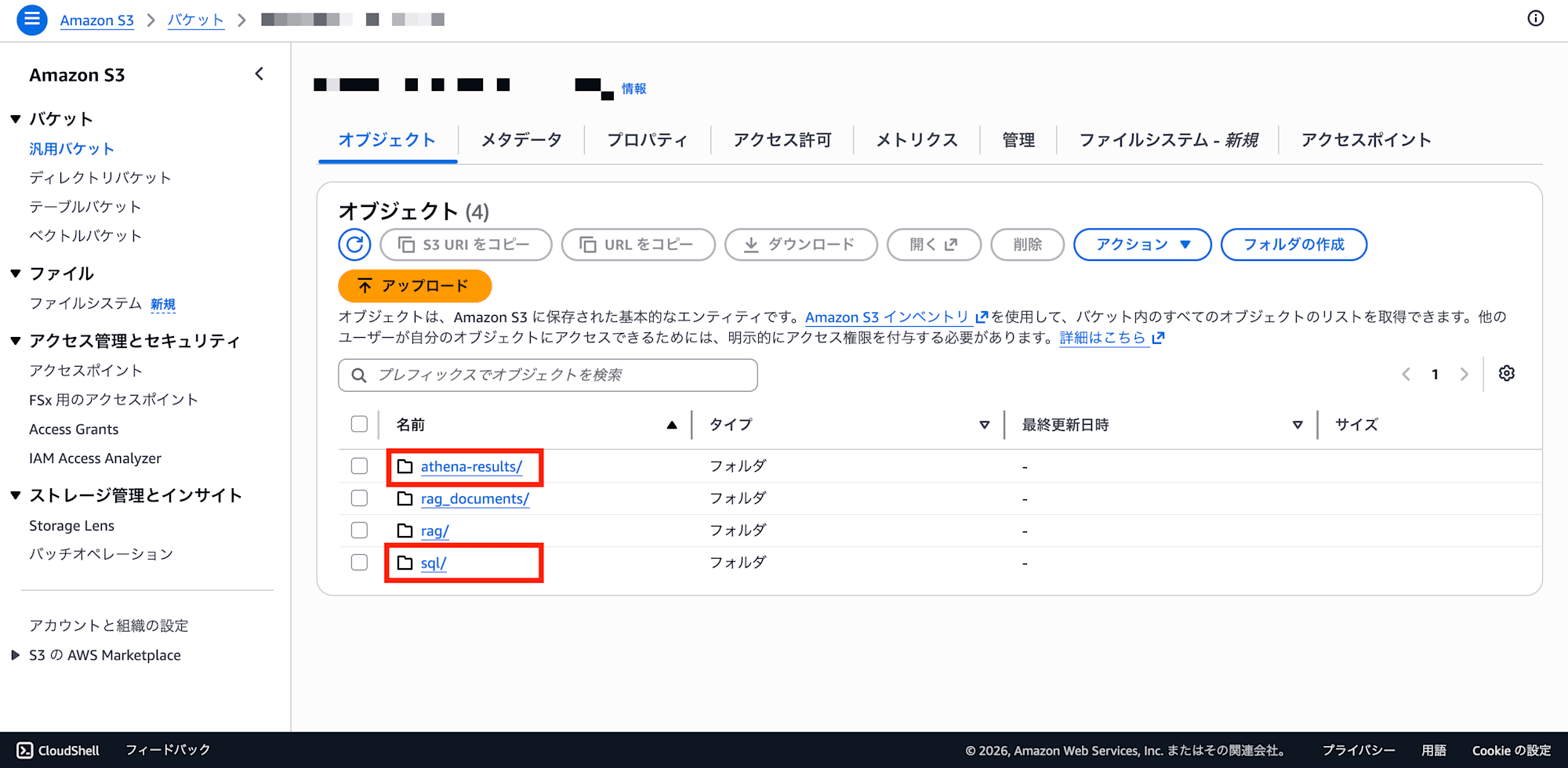
Note: Athena Query Result Output Location (athena-results/)
Every time Athena executes a query, it always writes the results to S3. This is an Athena specification that cannot be omitted.
s3://your-bucket/
├── sql/ ← Source data (Parquet)
│ ├── sales/
│ └── employees/
└── athena-results/ ← Auto-generated by Athena (query results)
├── <query-id-1>.csv
├── <query-id-1>.csv.metadata
├── <query-id-2>.csv
├── <query-id-2>.csv.metadata
└── ...(increases with each query execution)
Why write to S3:
Athena is a serverless query engine that has no persistent storage of its own. Workers are launched to process each query execution and terminate immediately after returning results. Therefore, writing to S3 is mandatory as the place to retain query results.
Output file structure:
| File | Contents |
|---|---|
<query-id>.csv |
The query results themselves (CSV with column headers) |
<query-id>.csv.metadata |
JSON recording query metadata (statistics, scan volume, etc.) |
Processing flow:
- Specify the output destination in
ResultConfiguration.OutputLocationviastart_query_execution() - Athena executes the query and writes the results as a pair of
.csv+.csv.metadata get_query_results()reads that CSV and returns the results
Files accumulate with each query execution at this output location. Repeated development and testing can quickly result in hundreds to thousands of files, so it is recommended to set up automatic deletion using S3 lifecycle rules.
Note that the IAM policy requires both s3:PutObject (for Athena to write) and s3:GetObject (to read results) for this output location.
Step 2: Clean Up athena-results/
As mentioned above, Athena writes result files to S3 every time a query is executed. Since leaving this unchecked causes the object count to balloon, set up automatic deletion using S3 lifecycle rules.
Configuration in the S3 console:
- Open the target bucket in the S3 console
- Go to the "Management" tab → Click "Create lifecycle rule"
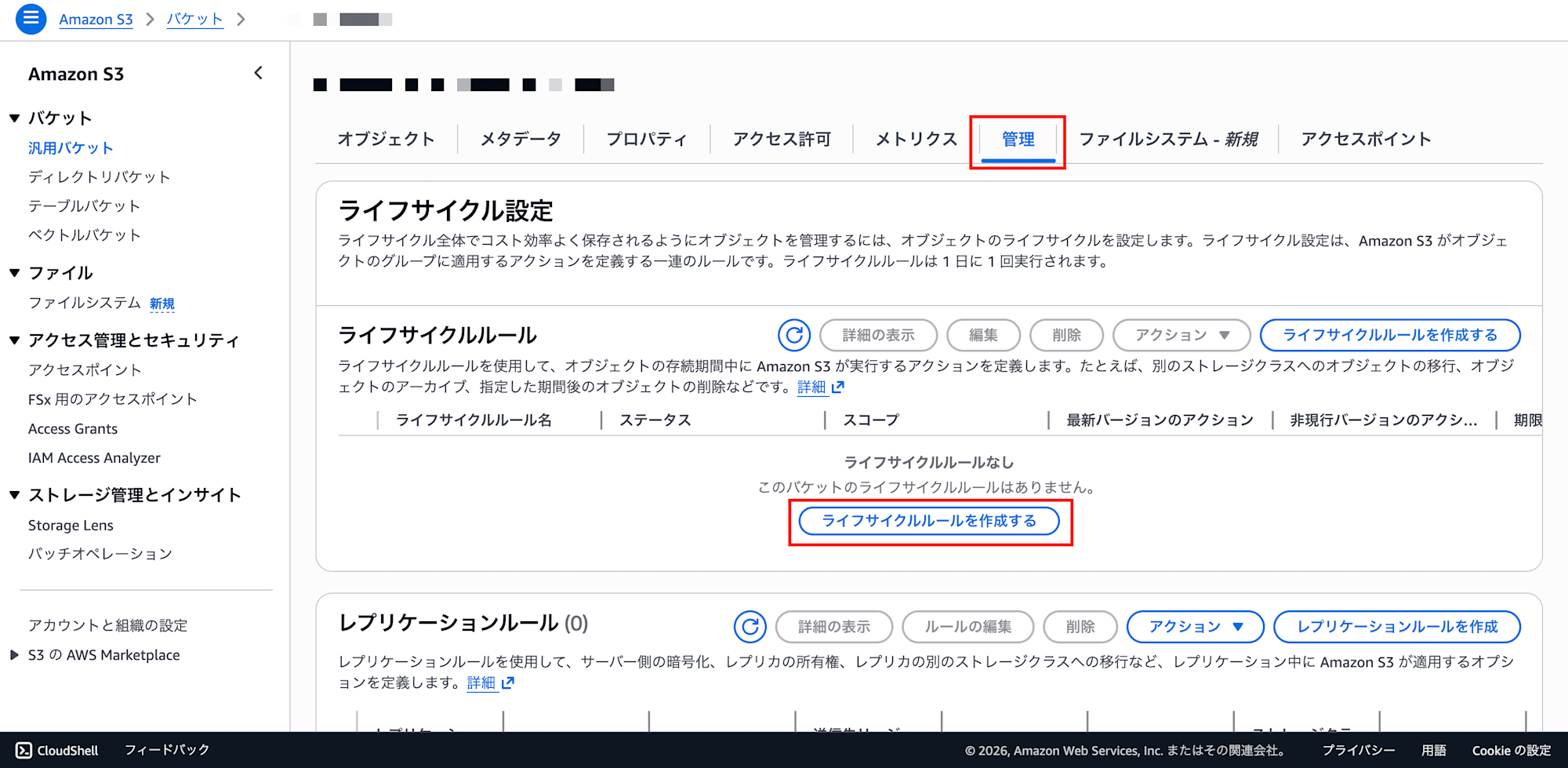
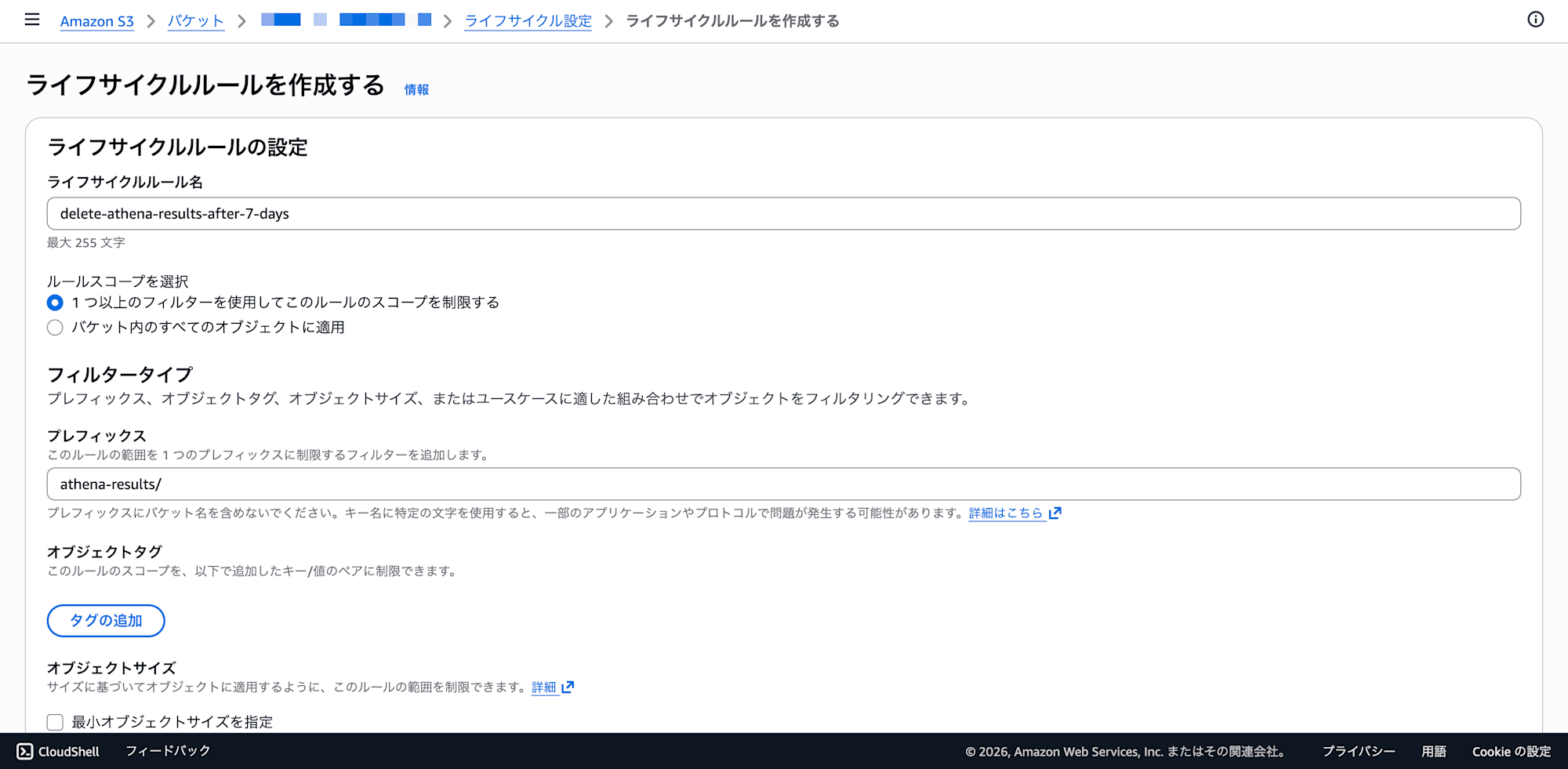
- Lifecycle rule settings:
- Lifecycle rule name:
delete-athena-results-after-7-days - Rule scope: Select "Limit the scope of this rule using one or more filters"
- Prefix: Enter
athena-results/ - Object tags and object size can be left blank as-is
- Lifecycle rule name:
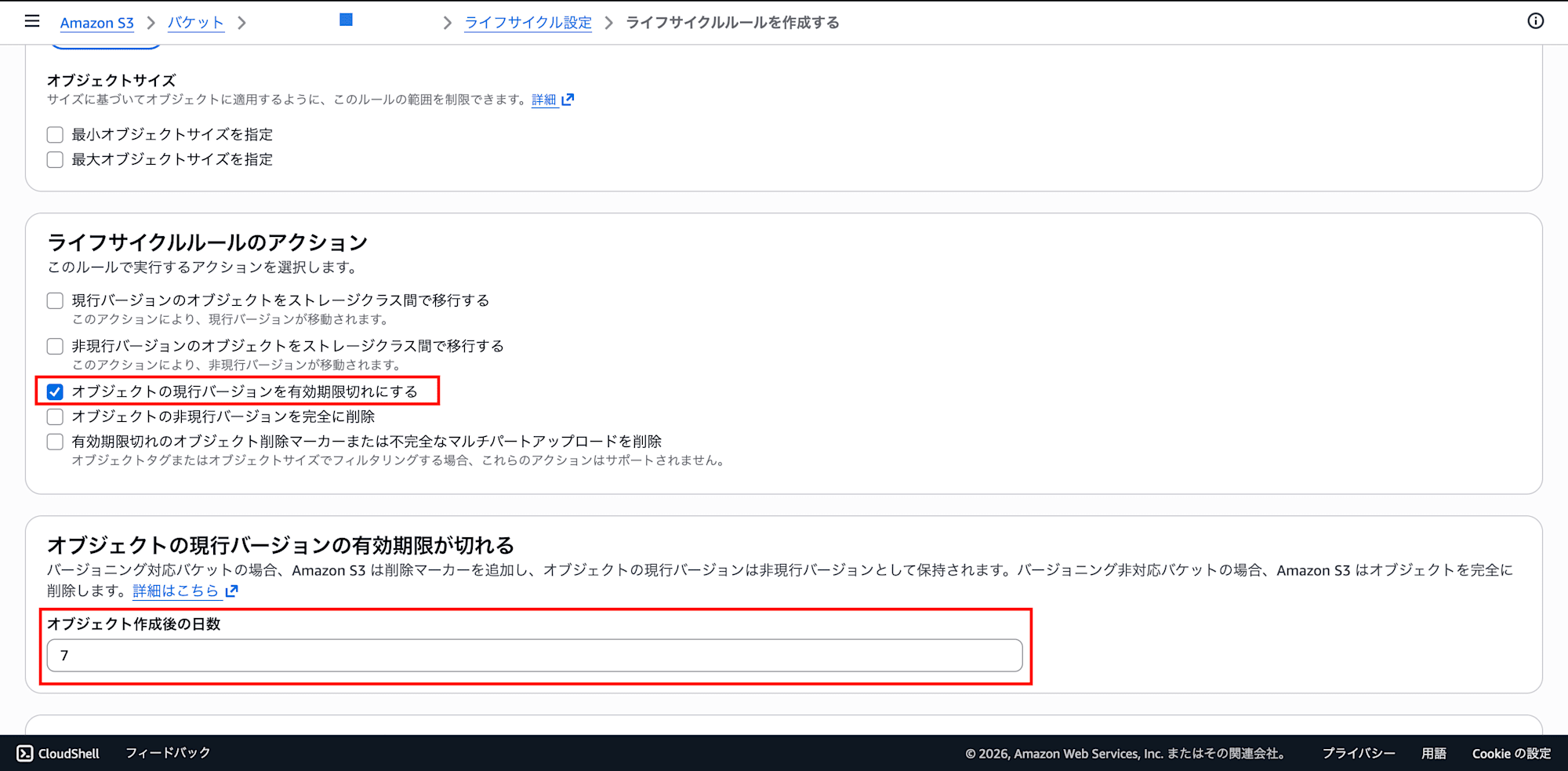
- Lifecycle rule actions:
- Check "Expire current versions of objects"
- A field for entering the number of days will appear in the "Review transition and expiration actions" section at the bottom
- Days: Enter
7(shorter is fine for development environments; adjust according to requirements for production)
- Click "Create rule"
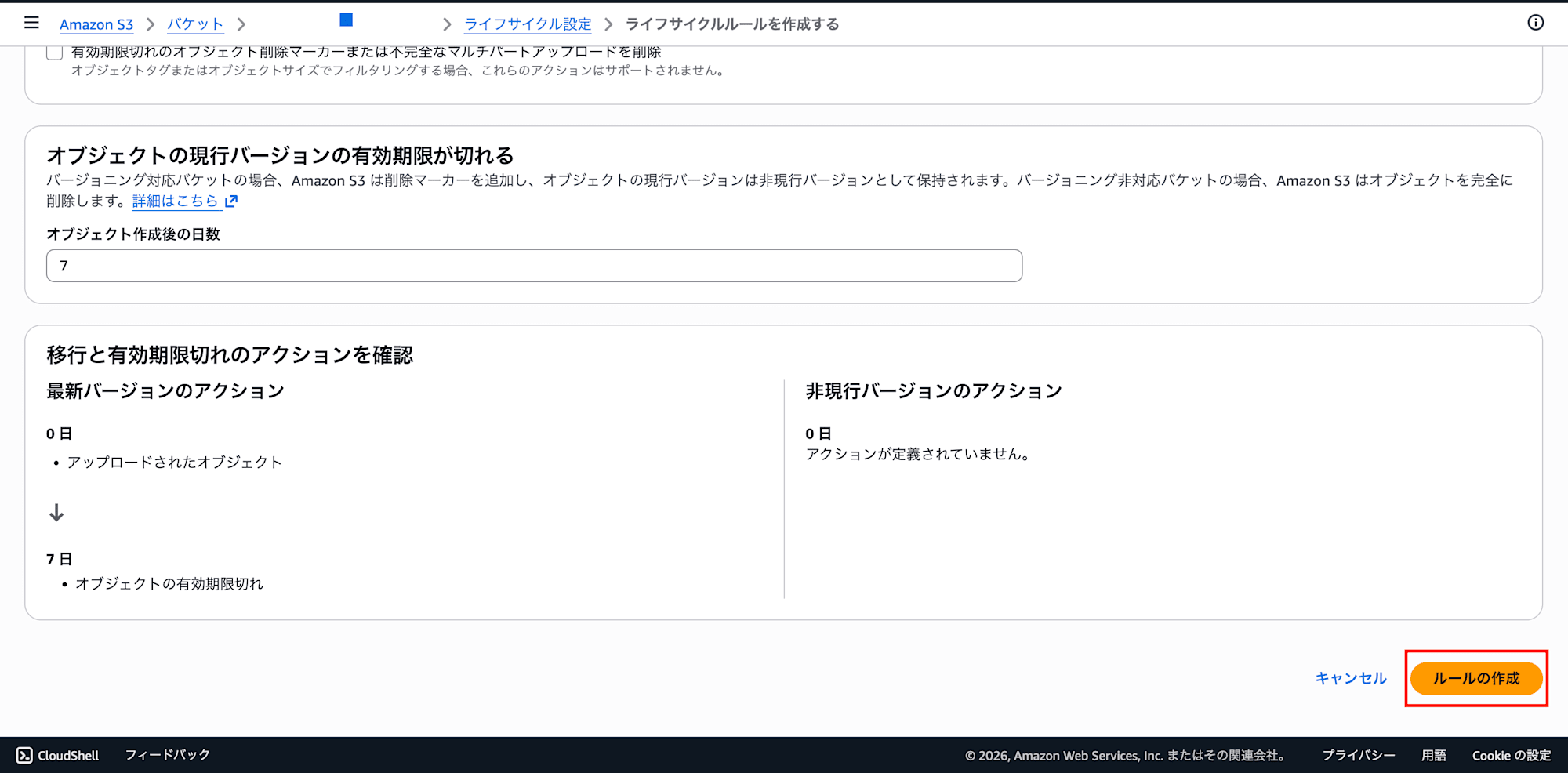
This will automatically delete query results after 7 days, keeping unnecessary storage costs and object count growth under control.
Step 3: Define Database and Tables in Athena
Athena uses Glue Data Catalog metadata to access data on S3. The easiest approach is to run DDL directly from the query editor in the Athena console.
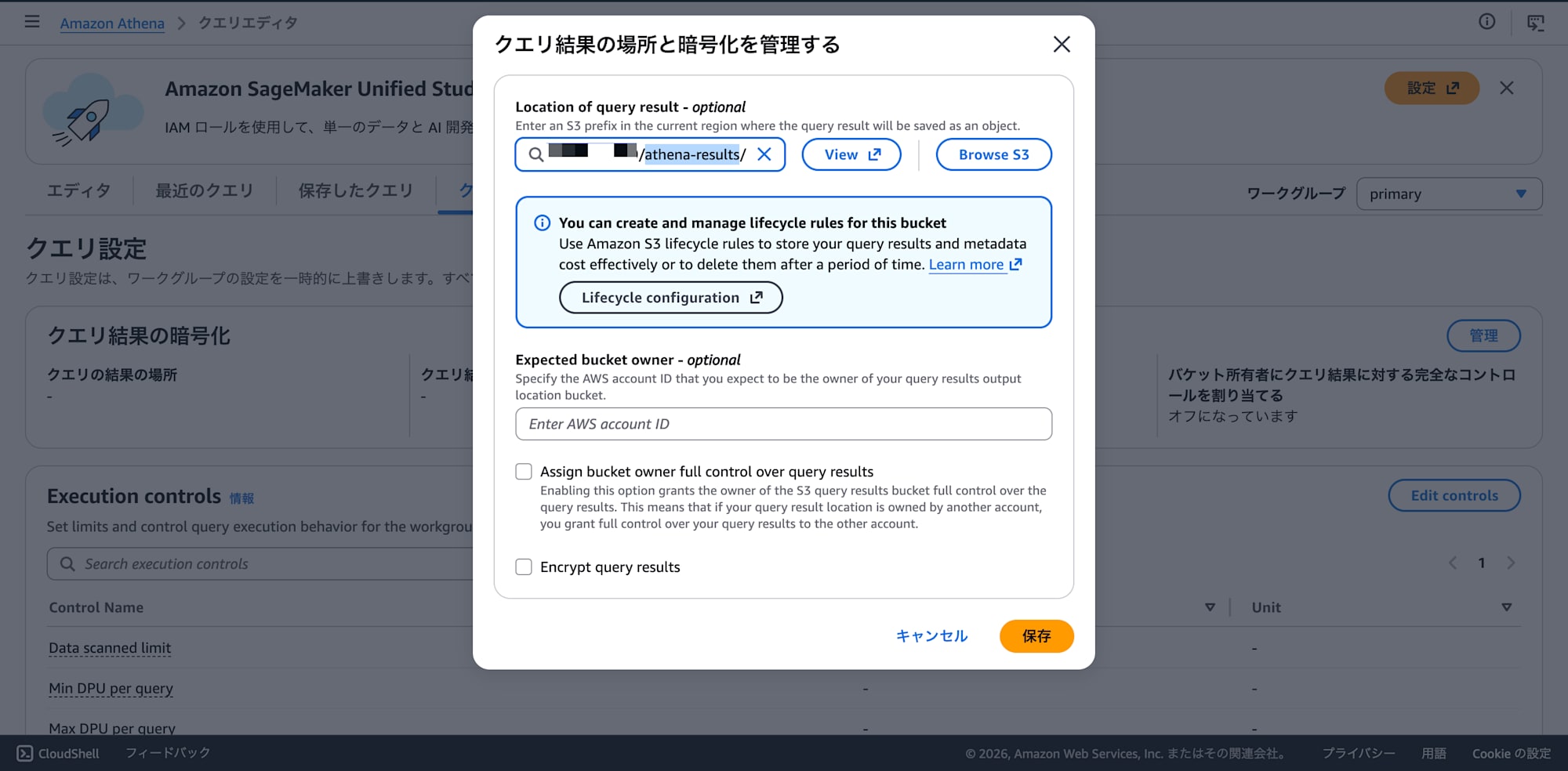
Initial setup — Set query result output location:
If you're using Athena for the first time, you need to configure the result output location before running queries.
- Athena console → Query editor → "Settings" tab → "Manage" button
- Enter
s3://your-bucket/athena-results/in "Location of query result" - Other fields (Expected bucket owner, encryption, etc.) can be left blank
- Click "Save"
Running DDL:
Paste the following DDL one at a time into the query editor and execute. Since Athena only accepts one statement per query execution, running multiple CREATE TABLE statements together will result in an error.
-- Query 1: Create database
CREATE DATABASE IF NOT EXISTS your_database
COMMENT 'Structured data for SQL agent';
-- Query 2: Example table: sales data
CREATE EXTERNAL TABLE your_database.sales (
`region` STRING COMMENT 'Region name',
`fiscal_year` INT COMMENT 'Fiscal year',
`quarter` STRING COMMENT 'Quarter (1Q, 2Q, 3Q, 4Q)',
`revenue_plan` BIGINT COMMENT 'Planned revenue',
`revenue_actual` BIGINT COMMENT 'Actual revenue'
)
STORED AS PARQUET
LOCATION 's3://your-bucket/sql/sales/'
TBLPROPERTIES ('parquet.compression'='SNAPPY');
Key points:
CREATE EXTERNAL TABLEonly references the data on S3 as-is — no data copying occurs- Specify a folder path rather than an individual file for
LOCATION(don't forget the trailing/) - When using Japanese column names, wrap them in backticks in DDL and double quotes in SELECT statements
- To change the schema, redefine it with
DROP TABLE→CREATE TABLE(data on S3 is not deleted)
After creation, verify (also run one at a time):
SELECT * FROM your_database.sales LIMIT 10;
SELECT COUNT(*), MIN(fiscal_year), MAX(fiscal_year) FROM your_database.sales;
Step 4: Set Application Environment Variables
Manage the settings for the application to connect to Athena using environment variables. Configure them according to your deployment method — ECS Fargate task definition, Docker env file, .env file, etc.
| Environment variable | Value | Description |
|---|---|---|
ATHENA_DATABASE |
your_database |
Database name created in Step 3 |
ATHENA_WORKGROUP |
primary |
Athena workgroup (default is primary) |
ATHENA_OUTPUT_S3 |
s3://your-bucket/athena-results/ |
Query result output location |
Step 5: Configure IAM Policy
Grant the application's execution role (ECS task role, etc.) access permissions for Athena, S3, and Glue.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults",
"athena:StopQueryExecution",
"athena:GetWorkGroup"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::your-bucket"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::your-bucket/*"
}
]
}
Key points:
s3:PutObjectis required for Athena to write query results toathena-results/s3:GetObjectis required for both reading data (Parquet insql/) and retrieving resultsglue:GetPartition(s)is required when using partitioned tables (include it in preparation for future expansion)- For production, restricting
Resourcetoarn:aws:s3:::your-bucket/sql/*andarn:aws:s3:::your-bucket/athena-results/*is more secure
Step 6: Implement the Athena Query Execution Module
Instead of Lambda, create a module within the application that calls Athena directly.
"""athena.py — Athena query execution module"""
import asyncio
import re
import time
import boto3
MAX_ROWS = 200
POLL_INTERVAL = 0.5
MAX_WAIT = 30
ATHENA_DATABASE = "your_database"
ATHENA_WORKGROUP = "primary"
ATHENA_OUTPUT_S3 = "s3://your-bucket/athena-results/"
_SELECT_ONLY = re.compile(r"^\s*SELECT\b", re.IGNORECASE)
def _validate_sql(sql: str) -> None:
"""Reject anything other than SELECT statements."""
if not _SELECT_ONLY.match(sql):
raise ValueError(
f"Only SELECT statements are allowed. Received: {sql[:80]!r}"
)
def _run_query_sync(sql: str) -> dict:
"""Execute a query on Athena and return the results (synchronous)."""
athena = boto3.client("athena")
response = athena.start_query_execution(
QueryString=sql,
QueryExecutionContext={"Database": ATHENA_DATABASE},
WorkGroup=ATHENA_WORKGROUP,
ResultConfiguration={"OutputLocation": ATHENA_OUTPUT_S3},
)
execution_id = response["QueryExecutionId"]
# Poll for completion
deadline = time.time() + MAX_WAIT
while time.time() < deadline:
status = athena.get_query_execution(QueryExecutionId=execution_id)
state = status["QueryExecution"]["Status"]["State"]
if state == "SUCCEEDED":
break
if state in ("FAILED", "CANCELLED"):
reason = status["QueryExecution"]["Status"].get(
"StateChangeReason", "unknown"
)
raise RuntimeError(f"Athena query {state}: {reason}")
time.sleep(POLL_INTERVAL)
else:
raise TimeoutError(
f"Athena query did not complete within {MAX_WAIT}s"
)
# Retrieve results
paginator = athena.get_paginator("get_query_results")
pages = paginator.paginate(QueryExecutionId=execution_id)
rows: list[list] = []
columns: list[str] = []
for page in pages:
result = page["ResultSet"]
if not columns:
columns = [
c["Label"]
for c in result["ResultSetMetadata"]["ColumnInfo"]
]
for row in result["Rows"][1 if not rows else 0:]:
values = [d.get("VarCharValue") for d in row["Data"]]
rows.append(values)
if len(rows) >= MAX_ROWS:
return {"columns": columns, "rows": rows, "row_count": len(rows)}
return {"columns": columns, "rows": rows, "row_count": len(rows)}
async def execute_query(sql: str) -> dict:
"""Async wrapper. Executes synchronous processing in a thread pool."""
_validate_sql(sql)
loop = asyncio.get_event_loop()
return await loop.run_in_executor(None, _run_query_sync, sql)
Design points:
| Point | Details |
|---|---|
| Only SELECT allowed | Checked via regex. Even if Claude mistakenly generates DML, it won't be executed |
| Polling method | Athena uses async execution, so a 3-step process: start_query_execution → status check → get_query_results |
| 200-row result limit | To avoid overflowing Claude's context window |
| Async wrapper | Wrapped with run_in_executor for use in async frameworks such as FastAPI |
Step 7: Tool Definition (Converse API toolConfig)
Create the tool definition to pass to the Converse API. This is the interface that tells Claude "a SQL execution tool is available."
EXECUTE_SQL_TOOL = {
"toolSpec": {
"name": "execute_sql_query",
"description": (
"Executes a Presto SQL SELECT query on Athena and returns the results as JSON."
),
"inputSchema": {
"json": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "The Presto SQL SELECT statement to execute",
}
},
"required": ["sql"],
}
},
}
}
Compared to Bedrock Agents' Action Group + OpenAPI schema, this is extremely simple. All you need to do is define the tool's name, description, and parameters in a Python dictionary.
Step 8: Implementing the Agent Loop
This is the core of this article. Using the Converse API, we build our own loop to "have Claude generate SQL → execute it → return results → have it generate an answer."
"""agent_loop.py — SQL agent loop using the Converse API"""
import json
import boto3
from athena import execute_query
MODEL_ID = "ap-northeast-1.anthropic.claude-sonnet-4-6"
MAX_ITERATIONS = 4 # Maximum number of SQL execution iterations
bedrock = boto3.client("bedrock-runtime", region_name="ap-northeast-1")
# Tool definition (created in Step 4)
TOOL_CONFIG = {"tools": [EXECUTE_SQL_TOOL]}
def load_system_prompt() -> str:
with open("system_prompt.md", encoding="utf-8") as f:
return f.read()
async def run_agent(user_message: str, history: list[dict]) -> str:
"""
Runs the agent loop for a user's question and returns the final answer.
Flow:
1. Send messages + tool definition to Converse API
2. If stop_reason is "tool_use" → extract SQL → execute on Athena → add results to messages → re-send
3. If stop_reason is "end_turn" → return text answer
4. Force termination if max iteration count is reached
"""
system_prompt = load_system_prompt()
messages = _build_messages(history, user_message)
for iteration in range(MAX_ITERATIONS):
# ── Converse API call ──
response = bedrock.converse(
modelId=MODEL_ID,
system=[{"text": system_prompt}],
messages=messages,
toolConfig=TOOL_CONFIG,
inferenceConfig={"maxTokens": 4096, "temperature": 0},
)
assistant_message = response["output"]["message"]
stop_reason = response["stopReason"]
# ── If Claude returns a text answer → complete ──
if stop_reason != "tool_use":
for block in assistant_message.get("content", []):
if "text" in block:
return block["text"]
return ""
# ── If Claude returns a tool call ──
tool_use_block = _extract_tool_use(assistant_message)
if not tool_use_block:
return "Failed to generate SQL."
sql = tool_use_block["input"]["sql"]
tool_use_id = tool_use_block["toolUseId"]
print(f"[iteration {iteration + 1}] SQL: {sql}")
# ── Execute SQL on Athena ──
try:
result = await execute_query(sql)
except (ValueError, RuntimeError, TimeoutError) as exc:
result = {"error": str(exc)}
# ── Add results to the conversation as toolResult ──
messages = messages + [
assistant_message, # Claude's assistant message (containing tool_use)
{
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_use_id,
"content": [
{"text": json.dumps(result, ensure_ascii=False)}
],
}
}
],
},
]
# Call converse() again in the next loop iteration
return "Maximum iteration count reached."
def _extract_tool_use(message: dict) -> dict | None:
"""Extract the execute_sql_query toolUse block from an assistant message."""
for block in message.get("content", []):
if "toolUse" in block and block["toolUse"]["name"] == "execute_sql_query":
return block["toolUse"]
return None
def _build_messages(history: list[dict], current: str) -> list[dict]:
"""Convert conversation history to the message format for the Converse API."""
messages = []
for turn in history:
role = turn.get("role")
content = turn.get("content", "")
if role in ("user", "assistant") and content:
messages.append({"role": role, "content": [{"text": content}]})
messages.append({"role": "user", "content": [{"text": current}]})
return messages
Agent loop flow diagram:
messages = [user_message]
┌─── Loop start (max 4 times) ───────────────────────┐
│ │
│ response = converse(messages, toolConfig) │
│ │
│ stop_reason == "end_turn"? ──→ Return text answer │
│ │ No │
│ ↓ │
│ stop_reason == "tool_use" │
│ │ │
│ ↓ │
│ Extract SQL → Execute on Athena │
│ │ │
│ ↓ │
│ messages += [assistant_msg, toolResult_msg] │
│ │ │
│ └──→ Return to loop start │
│ │
└────────────────────────────────────────────────────┘
Implementation key points:
| Point | Details |
|---|---|
Branch on stop_reason |
If "tool_use", execute SQL and continue loop; if "end_turn", answer is complete |
toolResult format |
Linked to the corresponding tool call via toolUseId. This is the Converse API specification |
| Adding messages | Add the assistant message (including tool call) and user message (toolResult) as a pair |
| Limiting iteration count | Claude may query multiple tables sequentially, so set a limit to prevent infinite loops |
| Return errors as results too | Returning Athena errors as JSON allows Claude to correct the SQL and retry |
Step 9: Embed Schema Information in the System Prompt
This is the most important step. For Claude to generate SQL correctly, you need to explicitly describe table definitions and data characteristics in the system prompt.
You are a data analyst for [domain].
## Answer Rules
1. Cite exact figures from search results in your answers
2. Always include units with numerical values
3. If data is not found, respond with "No matching data was found"
4. Do not make assumptions or estimates
## SQL Query Writing Rules
- Syntax: Presto SQL (Athena compatible)
- Wrap Japanese column names in double quotes (e.g., "売上高")
- Use single quotes for string values (e.g., '1Q')
## Table Definitions
### Table name: sales
| Column | Type | Description | Example values |
|--------|-----|------|--------|
| `region` | STRING | Region name | Tokyo, Osaka |
| `fiscal_year` | INT | Fiscal year | 2021–2026 |
| `quarter` | STRING | Quarter | 1Q, 2Q, 3Q, 4Q, Full year |
| `revenue_plan` | BIGINT | Planned revenue (millions of yen) | — |
| `revenue_actual` | BIGINT | Actual revenue (millions of yen) | — |
## Data Notes
- [Filter conditions to avoid double-counting during aggregation]
- [Constraints on specific column value combinations]
- [Fiscal years/periods with missing data]
- [Rules for determining ambiguous terminology]
Prompt design tips:
| Point | Details |
|---|---|
| Table definitions are essential | Claude doesn't know the DB schema. List the name, type, description, and possible values for every column |
| Document aggregation rules clearly | For data containing summary rows, specifically describe filter conditions to prevent double-counting |
| Show JOIN patterns | If joins across multiple tables are needed, include specific SQL examples |
| Define ambiguous terms | If the same word has multiple meanings (e.g., whether "sales" means amount or number of units), establish decision rules |
| Write example values | Claude doesn't know whether the value in the quarter column is '1Q' or 'Q1' |
Lessons from experience: The quality of the system prompt determines 80% of SQL generation accuracy. Writing not just table definitions but also "notes specific to this data" carefully significantly reduces Claude's mistakes. In production use, we stabilized accuracy by including more than 14 rules in the prompt.
Step 10: Verify Operation
Verify operation with questions like the following:
Please tell me the total actual sales across all regions for Q1 FY2025.
When operating correctly, you will see the following flow in the logs:
[iteration 1] SQL: SELECT SUM("revenue_actual") AS total FROM sales WHERE "fiscal_year" = 2025 AND "quarter" = '1Q'
Operation is successful if Claude behaves as follows:
- Analyzes the question and decides to use the
execute_sql_querytool (stop_reason: "tool_use") - Generates an appropriate SELECT statement
- The app executes the query directly on Athena
- Returns the results as
toolResult - Claude interprets the results and answers in natural language (
stop_reason: "end_turn")
Cases where multiple SQL executions occur: For questions like "Compare sales across all business segments," Claude may execute SQL multiple times for each table. In this case, the loop runs multiple times and aggregates all results before answering.
Common Pitfalls
Insufficient IAM Permissions
The application's execution role (ECS task role, etc.) requires athena:*, s3:* (for both data and results buckets), and glue:Get*.
Athena Query Result Output Location
Athena writes query results to S3. Verify write permissions for the path specified in ATHENA_OUTPUT_S3.
Handling Japanese Column Names
- DDL (CREATE TABLE): Enclose with backticks
` - DML (SELECT): Enclose with double quotes
" - Explicitly state the rule to use double quotes in the system prompt. Claude tends to use backticks by default
toolResult Format Errors
In the Converse API, the toolUseId in toolResult must match the ID of the immediately preceding toolUse block. A mismatch will cause the API to return an error.
Claude Not Using SQL
Specifying "Please use the execute_sql_query tool for all questions" in the system prompt improves this behavior.
Cost Estimates
| Service | Billing Unit | Estimate |
|---|---|---|
| Athena | Amount of data scanned | $5/TB (minimal with Parquet) |
| S3 | Storage + requests | Negligible with Parquet at a few MB |
| Bedrock Converse API | Number of input/output tokens | Model-dependent |
The Parquet + Athena combination scans minimal data, and at internal tool usage levels, costs often stay within a few dollars per month. With no Lambda required, there's also less to manage.
Summary
By leveraging tool_use in the Bedrock Converse API and implementing an agent loop on the application side, we achieved natural language SQL queries against structured data.
What we learned:
- You can build your own agent simply by detecting
stop_reason: "tool_use"in the Converse API and looping. The setup is simpler than Bedrock Agents (managed service) - SQL generation accuracy is directly tied to the quality of the system prompt. Write not just table definitions, but also data characteristics, aggregation rules, rules for handling ambiguous terms, and concrete SQL examples
- By calling Athena directly from the application, Lambda Cold Starts and Action Group configuration become unnecessary, resulting in faster responses
- Returning errors as
toolResultallows Claude to independently fix the SQL and retry
If you're hitting the limits of RAG for structured data searches, or if you're concerned about Bedrock Agents constraints (streaming, UI control), give this Converse API + custom loop approach a try.