
Amazon Athena × Bedrock Converse APIで自然言語からSQLを自動生成・実行するエージェントを構築してみた
はじめに
Amazon Bedrock の Knowledge Base(RAG)は非構造化ドキュメントの検索に強力ですが、「2025年度1Qの売上合計は?」のような集計・比較・ランキングを含む質問にはRAGだけでは対応しきれません。
この課題に対して、Bedrock の Converse API(tool_use) を使い、アプリケーション側でエージェントループを組むことで、Claude に SQL を生成させ、Athena で実行し、結果をもとに回答を生成する仕組みを構築しました。
Bedrock Agents(マネージドサービス)を使う方法もありますが、自前でエージェントループを組むことでストリーミング制御やカスタムUIが自由になるメリットがあります。本記事ではこのアプローチの実装を紹介します。
アーキテクチャ
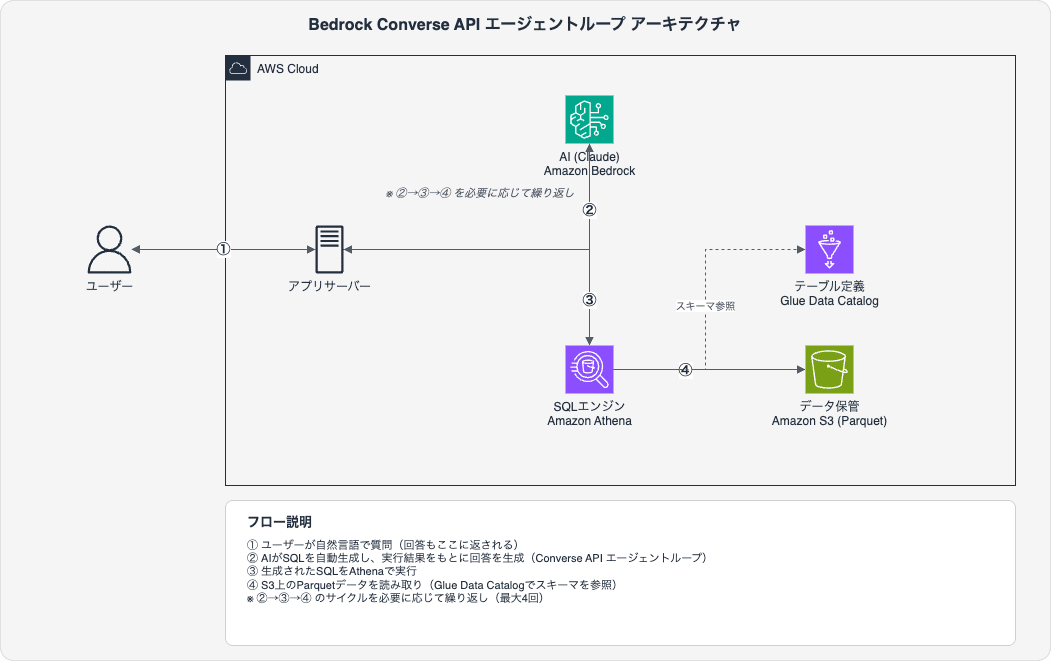
ユーザーの質問
↓
アプリケーションサーバー(FastAPI 等)
↓
bedrock_runtime.converse() ← tool_use でSQLツールを定義
↓
Claude が SQL を生成(stop_reason: "tool_use")
↓
アプリが SQL を受け取り、Athena に直接実行(Lambda 不要)
↓
結果を toolResult としてメッセージに追加
↓
bedrock_runtime.converse() ← 結果をもとに回答生成
↓
(必要なら追加SQLを生成 → 再実行 → ループ)
↓
stop_reason: "end_turn" で回答完了
ポイント: Bedrock Agents(マネージドサービス)ではなく、Converse API の toolConfig を使ってアプリ側でループを制御します。Lambda も Action Group も不要で、アプリから Athena を直接呼びます。
なぜ Bedrock Agents ではなく Converse API?
| 観点 | Bedrock Agents | Converse API + 自前ループ |
|---|---|---|
| ツール実行 | Lambda 経由(Action Group) | アプリから直接呼び出し |
| ストリーミング | Agent 側が制御 | 自由にカスタマイズ可能 |
| UX | 固定的 | SQL表示、実行結果表示などステップごとに制御可 |
| ループ制御 | Agent任せ | 最大反復回数など細かく制御 |
| デバッグ | トレースログから確認 | アプリログで直接確認 |
| デプロイ | Agent + Lambda + Action Group | アプリのみ |
既にアプリケーションサーバーがある場合は、Converse API の方がシンプルに組めます。
前提・環境
- AWSアカウントが利用可能であること
- Amazon Bedrock で Claude モデルへのアクセスが有効化済みであること
- 構造化データ(CSV/Excel等)を Parquet 形式に変換済みであること
- Python 3.12 + boto3
- リージョン:ap-northeast-1(東京)を使用
なぜ Parquet?
Athena は CSV も読めますが、Parquet には以下の利点があります:
- カラムナ形式:必要なカラムだけ読むためスキャン量が減り、コストが下がる
- 型情報を保持:INT, STRING 等の型が自動的に認識される
- 圧縮効率が高い:Snappy 圧縮でストレージコストも削減
Python で変換する場合は pandas + pyarrow が簡単です:
import pandas as pd
df = pd.read_excel("data.xlsx", sheet_name="Sheet1")
df.to_parquet("output/data.parquet", engine="pyarrow", compression="snappy")
手順
Step 1: S3 にデータを配置する
Parquet ファイルを S3 にアップロードします。テーブルごとにプレフィックス(フォルダ)を分けるのがポイントです。
s3://your-bucket/sql/
├── sales/
│ └── sales.parquet
├── employees/
│ └── employees.parquet
└── products/
└── products.parquet
S3 コンソールで対象バケットを開き、sql/ プレフィックスの下にテーブル名ごとのフォルダを作成し、各フォルダに対応する Parquet ファイルをアップロードします。
また、後述のAthena のクエリ結果出力先フォルダ(athena-results/)を作成します。
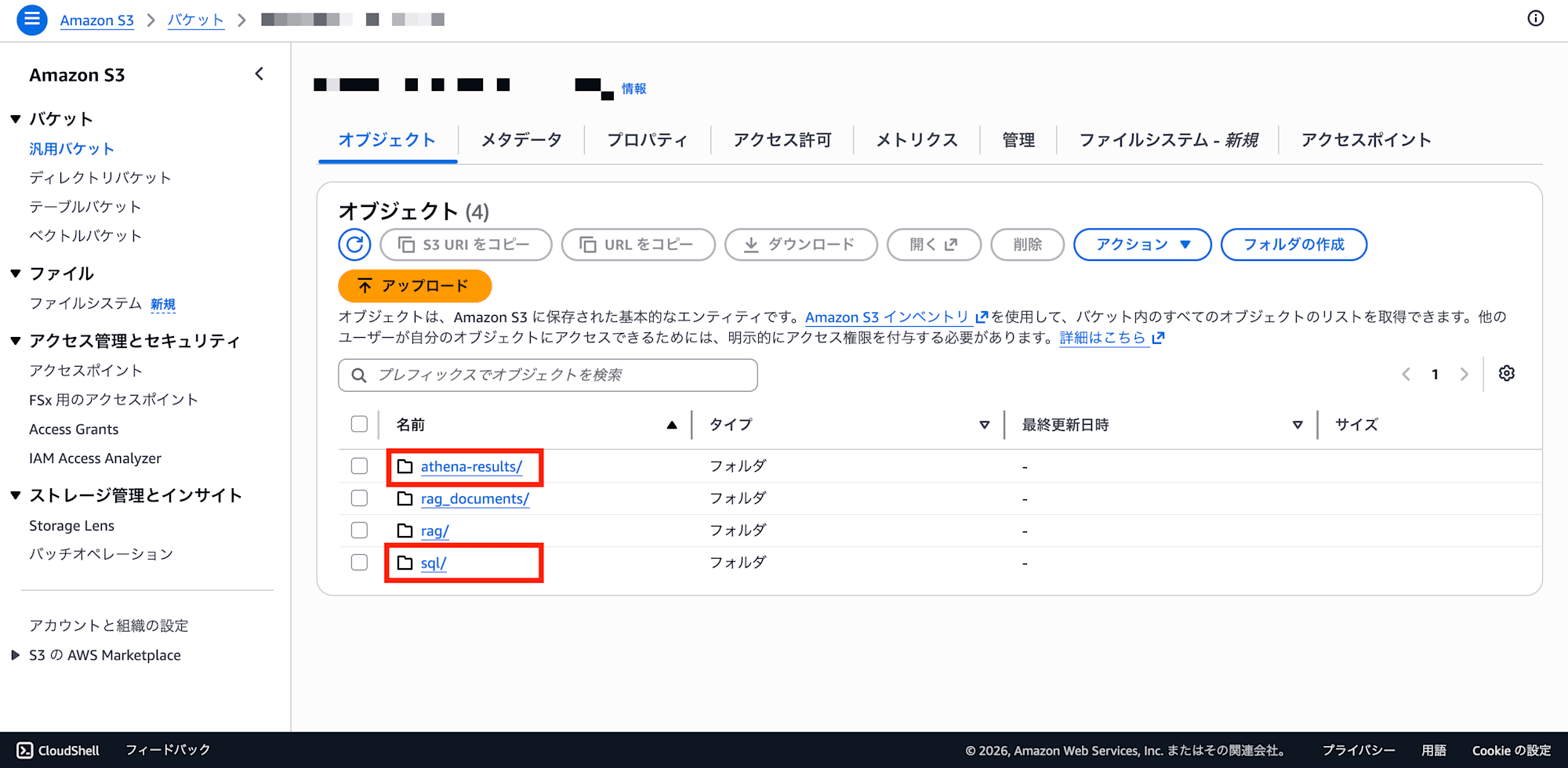
補足: Athena のクエリ結果出力先(athena-results/)
Athena はクエリを実行するたびに、結果を必ず S3 に書き出します。これは Athena の仕様で省略できません。
s3://your-bucket/
├── sql/ ← 元データ(Parquet)
│ ├── sales/
│ └── employees/
└── athena-results/ ← Athena が自動生成(クエリ結果)
├── <query-id-1>.csv
├── <query-id-1>.csv.metadata
├── <query-id-2>.csv
├── <query-id-2>.csv.metadata
└── ...(クエリ実行のたびに増える)
なぜ S3 に書き出すのか:
Athena はサーバーレスのクエリエンジンで、自身に永続的なストレージを持ちません。クエリ実行のたびにワーカーが起動して処理し、結果を返したら即座に終了します。そのため、クエリ結果を保持する場所として S3 への書き出しが必須になっています。
出力ファイルの構成:
| ファイル | 内容 |
|---|---|
<query-id>.csv |
クエリ結果そのもの(カラムヘッダー付き CSV) |
<query-id>.csv.metadata |
クエリのメタデータ(統計情報・スキャン量など)を記録した JSON |
処理の流れ:
start_query_execution()でResultConfiguration.OutputLocationに出力先を指定- Athena がクエリを実行し、結果を
.csv+.csv.metadataのペアで書き出す get_query_results()がその CSV を読んで結果を返す
この出力先はクエリ実行のたびにファイルが増え続けます。開発・テストを繰り返すとすぐに数百〜数千ファイルになるため、S3 ライフサイクルルールで自動削除することをおすすめします。
なお、IAM ポリシーではこの出力先に対する s3:PutObject(Athena が書き込む)と s3:GetObject(結果を読む)の両方が必要です。
Step 2: athena-results/ のクリーンアップ
前述の通り、Athena はクエリ実行のたびに結果ファイルを S3 に書き出します。放置するとオブジェクト数が膨れるため、S3 ライフサイクルルールで自動削除を設定しましょう。
S3 コンソールでの設定:
- S3 コンソールで対象バケットを開く
- 「管理」タブ → 「ライフサイクルルールを作成する」をクリック
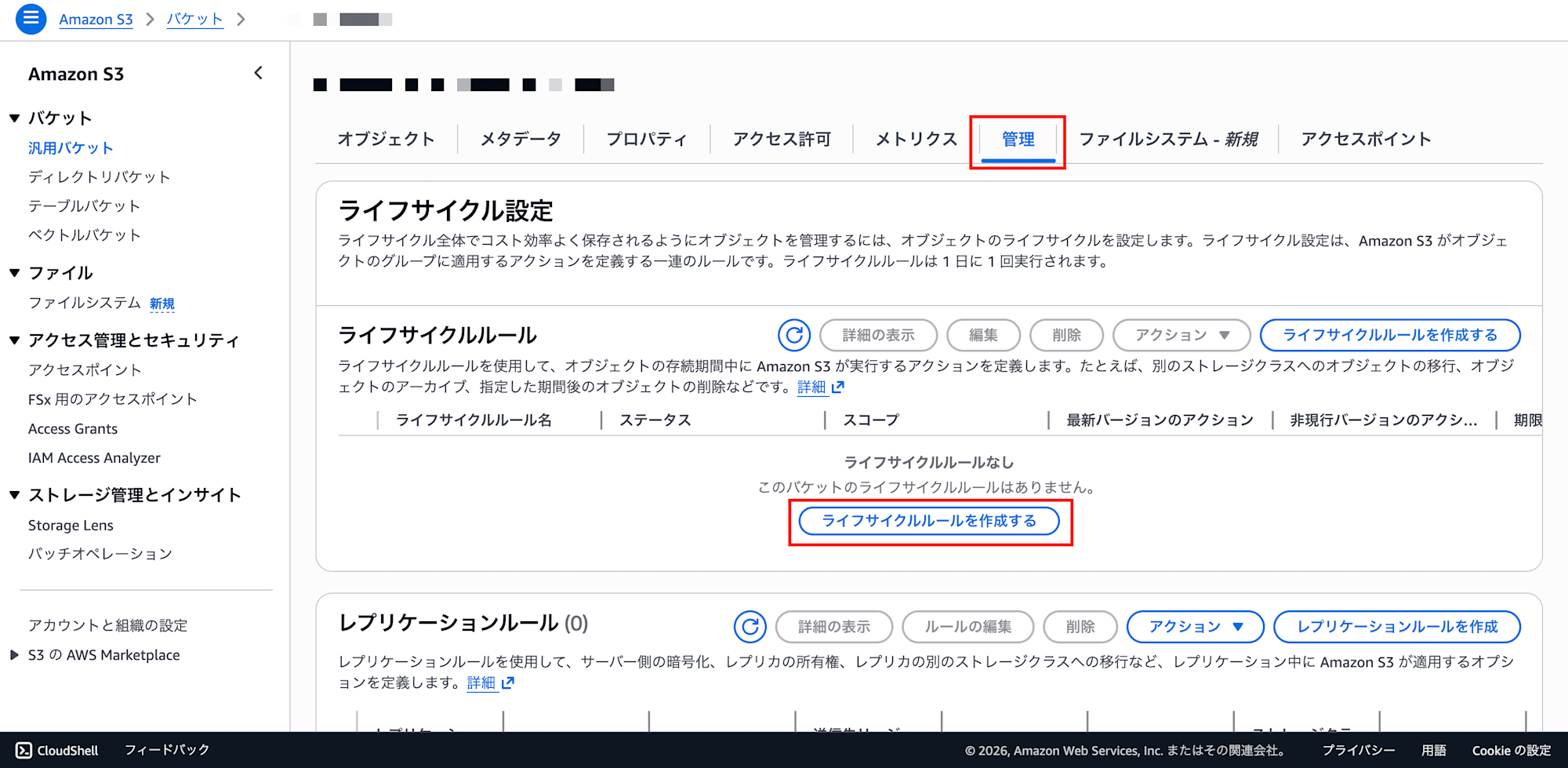
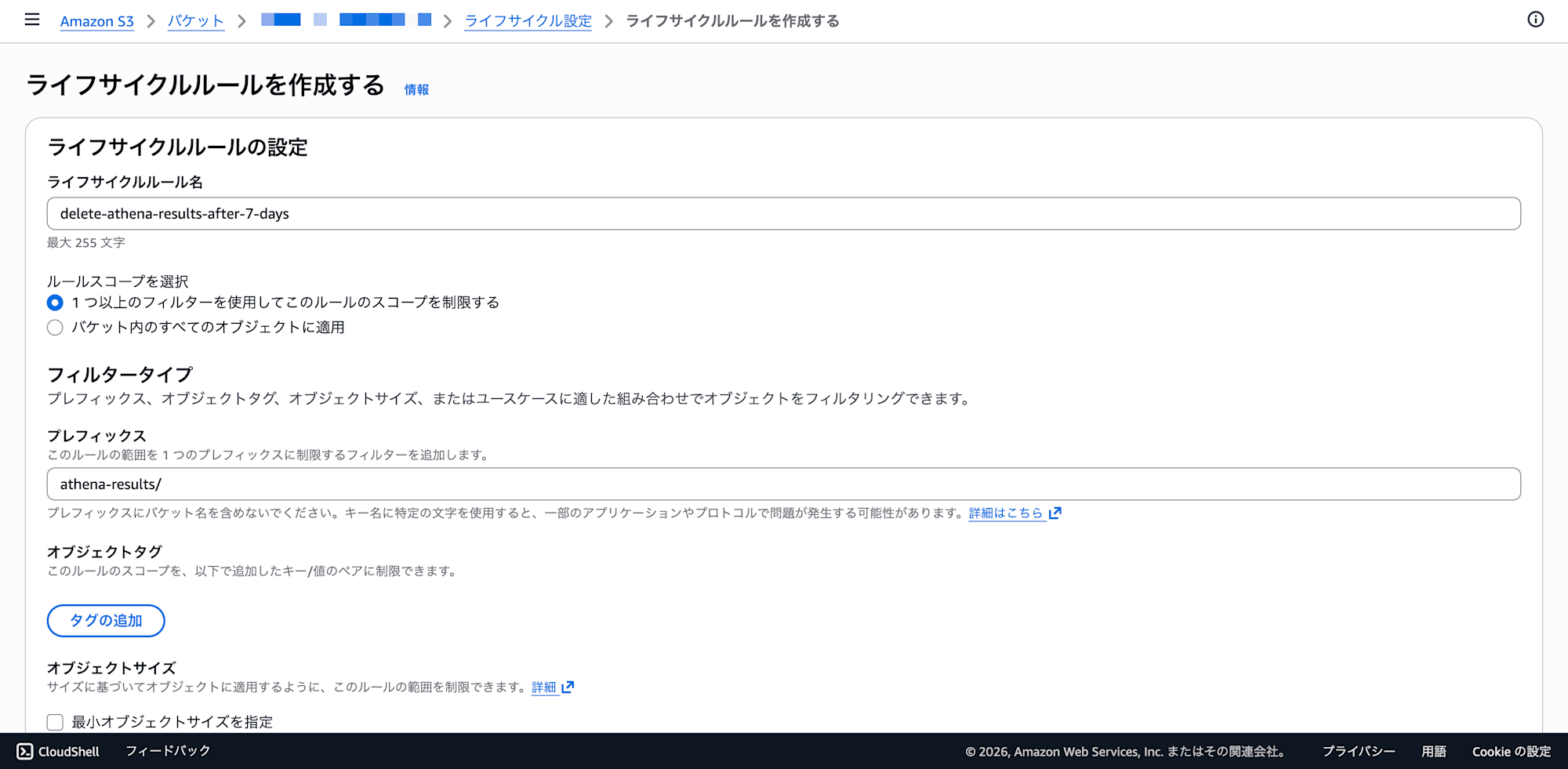
- ライフサイクルルールの設定:
- ライフサイクルルール名:
delete-athena-results-after-7-days - ルールスコープ: 「1つ以上のフィルターを使用してこのルールのスコープを制限する」を選択
- プレフィックス:
athena-results/を入力 - オブジェクトタグ、オブジェクトサイズはそのまま空でOK
- ライフサイクルルール名:
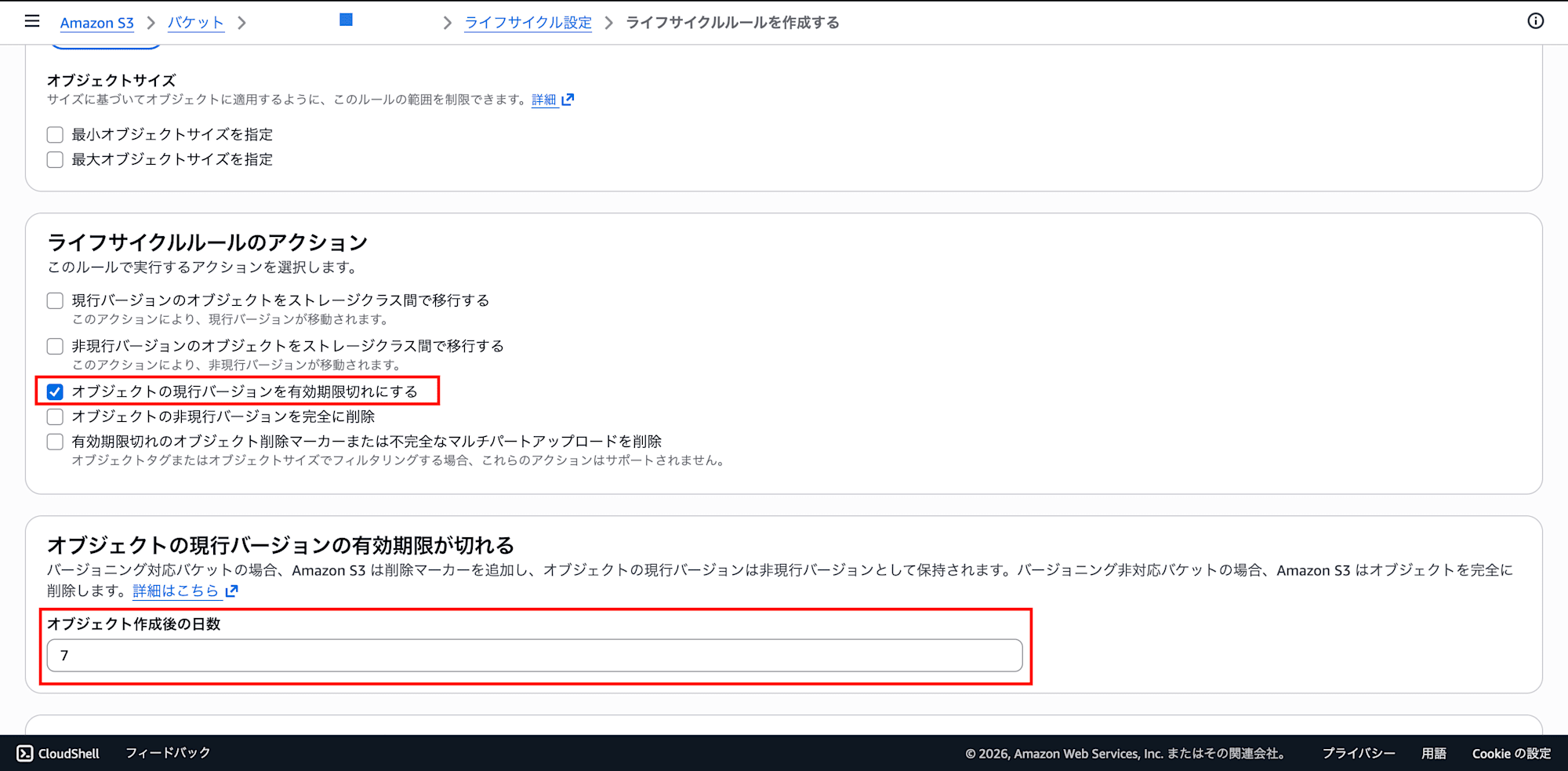
- ライフサイクルルールのアクション:
- 「オブジェクトの現行バージョンを有効期限切れにする」にチェック
- 下部の「移行と有効期限切れのアクションを確認」セクションに日数入力欄が表示される
- 日数:
7を入力(開発環境なら短くてOK。本番では要件に応じて調整)
- 「ルールの作成」をクリック
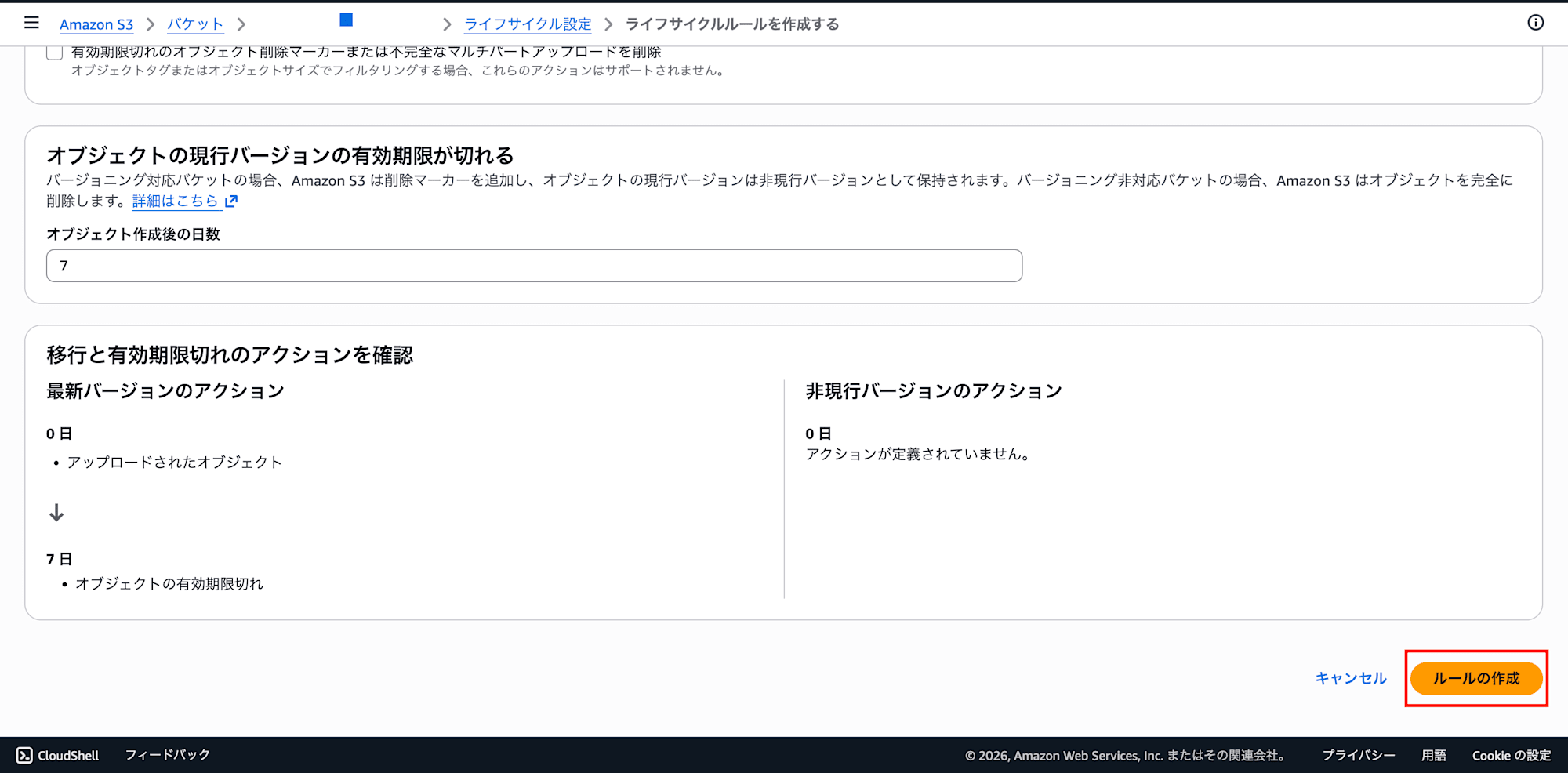
これでクエリ結果が7日後に自動削除され、不要なストレージコストとオブジェクト数の増加を抑えられます。
Step 3: Athena でデータベース・テーブルを定義する
Athena は Glue Data Catalog のメタデータを使ってS3上のデータにアクセスします。Athena コンソールのクエリエディタから直接 DDL を実行するのが最も簡単です。
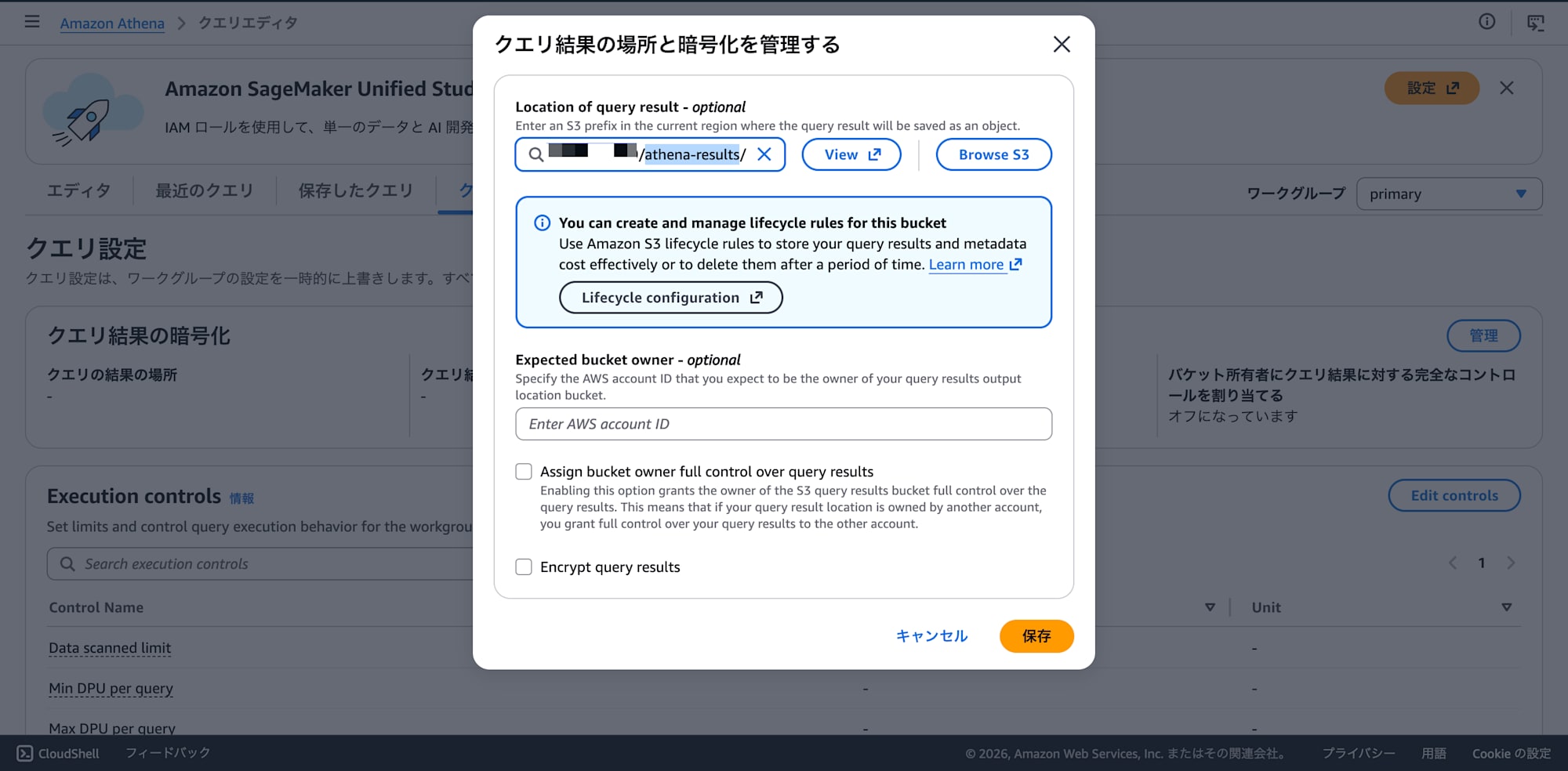
初回セットアップ — クエリ結果の出力先を設定:
Athena を初めて使う場合、クエリを実行する前に結果の出力先を設定する必要があります。
- Athena コンソール → クエリエディタ → 「クエリ設定」タブ → 「管理」ボタン
- 「Location of query result」に
s3://your-bucket/athena-results/を入力 - 他の項目(Expected bucket owner、暗号化等)は空のままでOK
- 「保存」をクリック
DDL の実行:
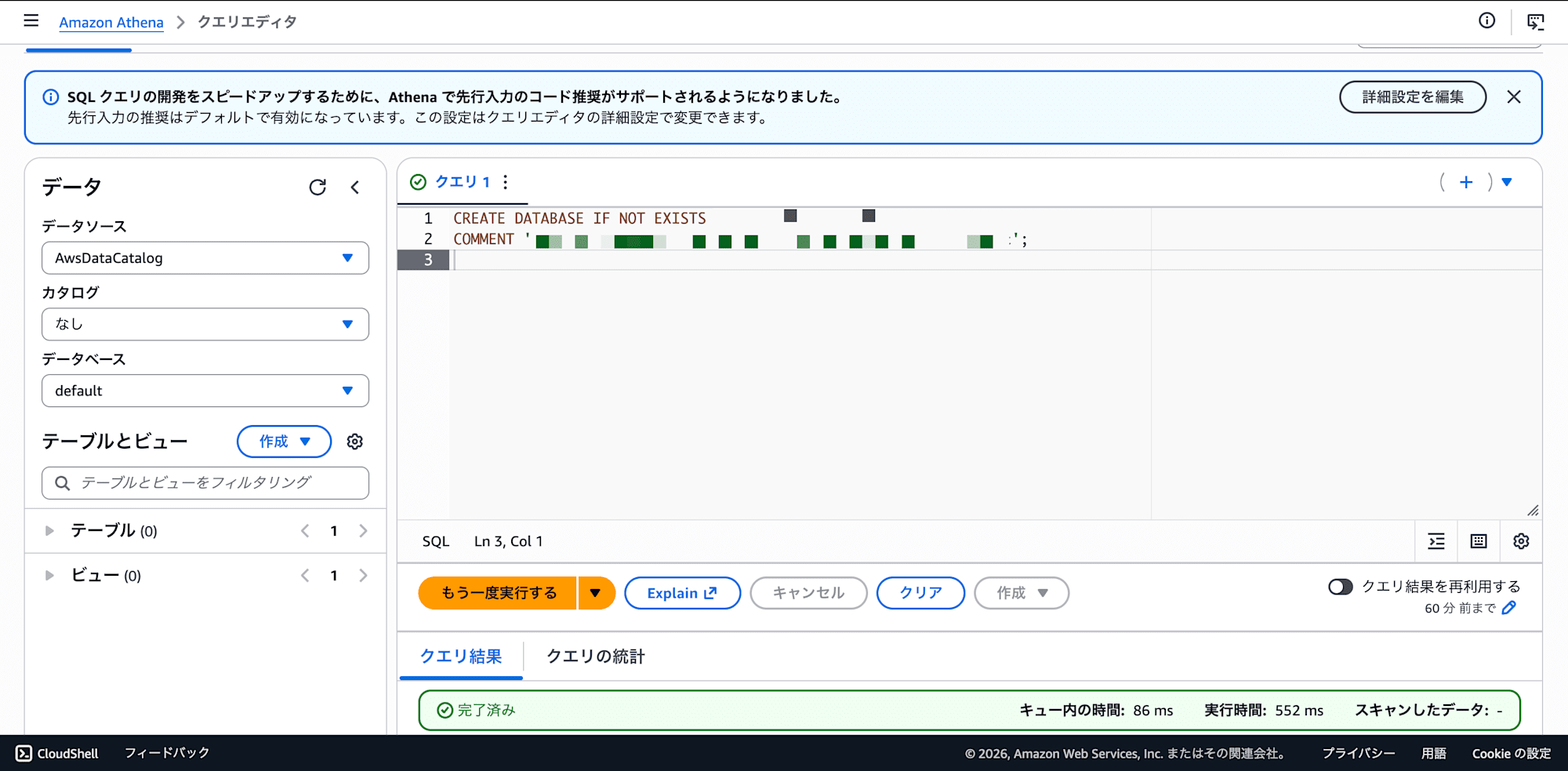
以下の DDL を1つずつクエリエディタに貼り付けて実行します。Athena は1回のクエリ実行で1ステートメントしか受け付けないため、複数の CREATE TABLE をまとめて実行するとエラーになります。
-- クエリ1: データベースを作成
CREATE DATABASE IF NOT EXISTS your_database
COMMENT 'Structured data for SQL agent';
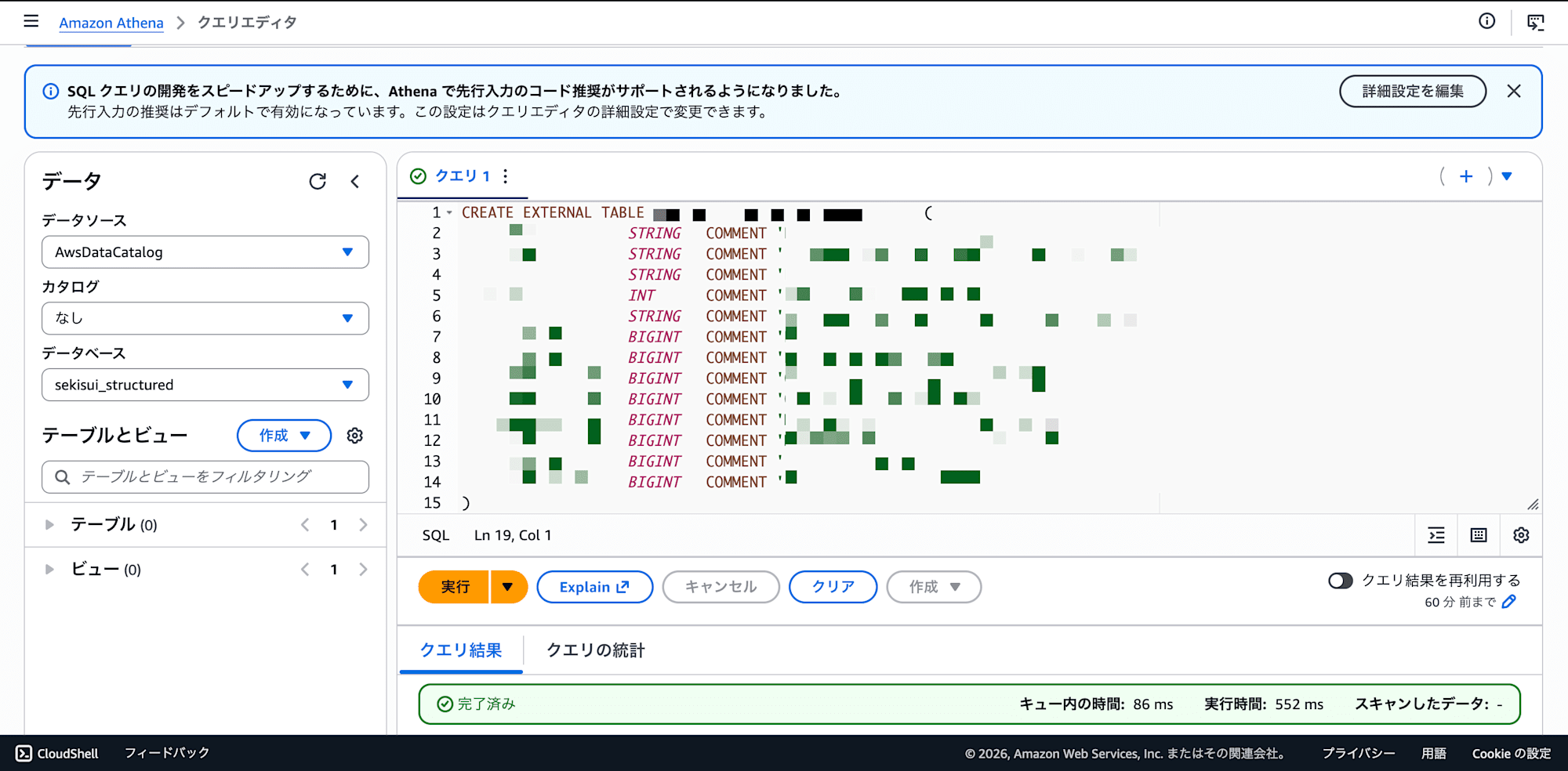
-- クエリ2: テーブル例:売上データ
CREATE EXTERNAL TABLE your_database.sales (
`region` STRING COMMENT '地域名',
`fiscal_year` INT COMMENT '会計年度',
`quarter` STRING COMMENT '四半期 (1Q, 2Q, 3Q, 4Q)',
`revenue_plan` BIGINT COMMENT '計画売上高',
`revenue_actual` BIGINT COMMENT '実績売上高'
)
STORED AS PARQUET
LOCATION 's3://your-bucket/sql/sales/'
TBLPROPERTIES ('parquet.compression'='SNAPPY');
ポイント:
CREATE EXTERNAL TABLEはS3上のデータをそのまま参照するだけで、データのコピーは発生しないLOCATIONはファイル単体ではなくフォルダのパスを指定する(末尾の/を忘れずに)- 日本語カラム名を使う場合、DDL ではバッククォート、SELECT 文ではダブルクォートで囲む
- スキーマ変更時は
DROP TABLE→CREATE TABLEで再定義(S3上のデータは消えない)
作成したら確認(これも1つずつ実行):
SELECT * FROM your_database.sales LIMIT 10;
SELECT COUNT(*), MIN(fiscal_year), MAX(fiscal_year) FROM your_database.sales;
Step 4: アプリケーションの環境変数を設定する
アプリケーションが Athena に接続するための設定を環境変数で管理します。ECS Fargate のタスク定義、Docker の env ファイル、または .env ファイルなど、デプロイ方式に応じた方法で設定してください。
| 環境変数 | 値 | 説明 |
|---|---|---|
ATHENA_DATABASE |
your_database |
Step 3 で作成したデータベース名 |
ATHENA_WORKGROUP |
primary |
Athena のワークグループ(デフォルトは primary) |
ATHENA_OUTPUT_S3 |
s3://your-bucket/athena-results/ |
クエリ結果の出力先 |
Step 5: IAM ポリシーを設定する
アプリケーションの実行ロール(ECS タスクロール等)に、Athena・S3・Glue へのアクセス権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"athena:StartQueryExecution",
"athena:GetQueryExecution",
"athena:GetQueryResults",
"athena:StopQueryExecution",
"athena:GetWorkGroup"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:GetDatabase",
"glue:GetTable",
"glue:GetTables",
"glue:GetPartition",
"glue:GetPartitions"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::your-bucket"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject"
],
"Resource": "arn:aws:s3:::your-bucket/*"
}
]
}
ポイント:
s3:PutObjectは Athena がクエリ結果をathena-results/に書き出すために必要s3:GetObjectはデータ読み取り(sql/内の Parquet)と結果取得の両方に必要glue:GetPartition(s)はパーティション付きテーブルを使う場合に必要(将来の拡張に備えて含めておく)- 本番では
Resourceをarn:aws:s3:::your-bucket/sql/*とarn:aws:s3:::your-bucket/athena-results/*に絞ることでより安全になる
Step 6: Athena クエリ実行モジュールを実装する
Lambda ではなく、アプリケーション内に Athena を直接呼ぶモジュールを作ります。
"""athena.py — Athena クエリ実行モジュール"""
import asyncio
import re
import time
import boto3
MAX_ROWS = 200
POLL_INTERVAL = 0.5
MAX_WAIT = 30
ATHENA_DATABASE = "your_database"
ATHENA_WORKGROUP = "primary"
ATHENA_OUTPUT_S3 = "s3://your-bucket/athena-results/"
_SELECT_ONLY = re.compile(r"^\s*SELECT\b", re.IGNORECASE)
def _validate_sql(sql: str) -> None:
"""SELECT 文以外を拒否する。"""
if not _SELECT_ONLY.match(sql):
raise ValueError(
f"Only SELECT statements are allowed. Received: {sql[:80]!r}"
)
def _run_query_sync(sql: str) -> dict:
"""Athena でクエリを実行し、結果を返す(同期)。"""
athena = boto3.client("athena")
response = athena.start_query_execution(
QueryString=sql,
QueryExecutionContext={"Database": ATHENA_DATABASE},
WorkGroup=ATHENA_WORKGROUP,
ResultConfiguration={"OutputLocation": ATHENA_OUTPUT_S3},
)
execution_id = response["QueryExecutionId"]
# ポーリングで完了を待つ
deadline = time.time() + MAX_WAIT
while time.time() < deadline:
status = athena.get_query_execution(QueryExecutionId=execution_id)
state = status["QueryExecution"]["Status"]["State"]
if state == "SUCCEEDED":
break
if state in ("FAILED", "CANCELLED"):
reason = status["QueryExecution"]["Status"].get(
"StateChangeReason", "unknown"
)
raise RuntimeError(f"Athena query {state}: {reason}")
time.sleep(POLL_INTERVAL)
else:
raise TimeoutError(
f"Athena query did not complete within {MAX_WAIT}s"
)
# 結果を取得
paginator = athena.get_paginator("get_query_results")
pages = paginator.paginate(QueryExecutionId=execution_id)
rows: list[list] = []
columns: list[str] = []
for page in pages:
result = page["ResultSet"]
if not columns:
columns = [
c["Label"]
for c in result["ResultSetMetadata"]["ColumnInfo"]
]
for row in result["Rows"][1 if not rows else 0:]:
values = [d.get("VarCharValue") for d in row["Data"]]
rows.append(values)
if len(rows) >= MAX_ROWS:
return {"columns": columns, "rows": rows, "row_count": len(rows)}
return {"columns": columns, "rows": rows, "row_count": len(rows)}
async def execute_query(sql: str) -> dict:
"""非同期ラッパー。スレッドプールで同期処理を実行する。"""
_validate_sql(sql)
loop = asyncio.get_event_loop()
return await loop.run_in_executor(None, _run_query_sync, sql)
設計ポイント:
| ポイント | 内容 |
|---|---|
| SELECT のみ許可 | 正規表現でチェック。Claude が誤って DML を生成しても実行されない |
| ポーリング方式 | Athena は非同期実行のため、start_query_execution → ステータスチェック → get_query_results の3段階 |
| 結果の上限 200行 | Claude のコンテキストウィンドウを溢れさせないため |
| 非同期ラッパー | FastAPI 等の async フレームワークで使えるよう run_in_executor でラップ |
Step 7: ツール定義(Converse API の toolConfig)
Converse API に渡すツール定義を作成します。これが Claude に「SQL実行ツールが使える」ことを伝えるインターフェースです。
EXECUTE_SQL_TOOL = {
"toolSpec": {
"name": "execute_sql_query",
"description": (
"Presto SQL SELECTクエリをAthenaで実行し、結果をJSONで返します。"
),
"inputSchema": {
"json": {
"type": "object",
"properties": {
"sql": {
"type": "string",
"description": "実行するPresto SQL SELECT文",
}
},
"required": ["sql"],
}
},
}
}
Bedrock Agents の Action Group + OpenAPI スキーマと比べると非常にシンプルです。Python の辞書でツールの名前・説明・パラメータを定義するだけで済みます。
Step 8: エージェントループの実装
ここが本記事の核心です。Converse API を使って「Claude にSQLを生成させ → 実行し → 結果を返し → 回答を生成させる」ループを自前で組みます。
"""agent_loop.py — Converse API を使った SQL エージェントループ"""
import json
import boto3
from athena import execute_query
MODEL_ID = "ap-northeast-1.anthropic.claude-sonnet-4-6"
MAX_ITERATIONS = 4 # SQL実行の最大反復回数
bedrock = boto3.client("bedrock-runtime", region_name="ap-northeast-1")
# ツール定義(Step 4 で作成したもの)
TOOL_CONFIG = {"tools": [EXECUTE_SQL_TOOL]}
def load_system_prompt() -> str:
with open("system_prompt.md", encoding="utf-8") as f:
return f.read()
async def run_agent(user_message: str, history: list[dict]) -> str:
"""
ユーザーの質問に対してエージェントループを実行し、最終回答を返す。
フロー:
1. Converse API にメッセージ + ツール定義を送信
2. stop_reason が "tool_use" なら → SQL抽出 → Athena実行 → 結果をメッセージに追加 → 再送信
3. stop_reason が "end_turn" なら → テキスト回答を返す
4. 最大反復回数に達したら強制終了
"""
system_prompt = load_system_prompt()
messages = _build_messages(history, user_message)
for iteration in range(MAX_ITERATIONS):
# ── Converse API 呼び出し ──
response = bedrock.converse(
modelId=MODEL_ID,
system=[{"text": system_prompt}],
messages=messages,
toolConfig=TOOL_CONFIG,
inferenceConfig={"maxTokens": 4096, "temperature": 0},
)
assistant_message = response["output"]["message"]
stop_reason = response["stopReason"]
# ── Claude がテキスト回答を返した場合 → 完了 ──
if stop_reason != "tool_use":
for block in assistant_message.get("content", []):
if "text" in block:
return block["text"]
return ""
# ── Claude がツール呼び出しを返した場合 ──
tool_use_block = _extract_tool_use(assistant_message)
if not tool_use_block:
return "SQLの生成に失敗しました。"
sql = tool_use_block["input"]["sql"]
tool_use_id = tool_use_block["toolUseId"]
print(f"[iteration {iteration + 1}] SQL: {sql}")
# ── Athena で SQL を実行 ──
try:
result = await execute_query(sql)
except (ValueError, RuntimeError, TimeoutError) as exc:
result = {"error": str(exc)}
# ── 結果を toolResult として会話に追加 ──
messages = messages + [
assistant_message, # Claude のアシスタントメッセージ(tool_use を含む)
{
"role": "user",
"content": [
{
"toolResult": {
"toolUseId": tool_use_id,
"content": [
{"text": json.dumps(result, ensure_ascii=False)}
],
}
}
],
},
]
# ループの次の反復で再度 converse() を呼ぶ
return "最大反復回数に達しました。"
def _extract_tool_use(message: dict) -> dict | None:
"""アシスタントメッセージから execute_sql_query の toolUse ブロックを抽出する。"""
for block in message.get("content", []):
if "toolUse" in block and block["toolUse"]["name"] == "execute_sql_query":
return block["toolUse"]
return None
def _build_messages(history: list[dict], current: str) -> list[dict]:
"""会話履歴を Converse API のメッセージ形式に変換する。"""
messages = []
for turn in history:
role = turn.get("role")
content = turn.get("content", "")
if role in ("user", "assistant") and content:
messages.append({"role": role, "content": [{"text": content}]})
messages.append({"role": "user", "content": [{"text": current}]})
return messages
エージェントループの流れを図解:
messages = [user_message]
┌─── ループ開始(最大 4 回)────────────────────────┐
│ │
│ response = converse(messages, toolConfig) │
│ │
│ stop_reason == "end_turn"? ──→ テキスト回答を返す │
│ │ No │
│ ↓ │
│ stop_reason == "tool_use" │
│ │ │
│ ↓ │
│ SQL を抽出 → Athena で実行 │
│ │ │
│ ↓ │
│ messages += [assistant_msg, toolResult_msg] │
│ │ │
│ └──→ ループ先頭に戻る │
│ │
└────────────────────────────────────────────────────┘
実装の要点:
| ポイント | 詳細 |
|---|---|
stop_reason で分岐 |
"tool_use" ならSQLを実行してループ継続、"end_turn" なら回答完了 |
toolResult の形式 |
toolUseId で対応するツール呼び出しと紐付ける。Converse API の仕様 |
| メッセージの追加 | assistant メッセージ(ツール呼び出し含む)と user メッセージ(toolResult)をペアで追加する |
| 反復回数の制限 | Claude が複数テーブルを順番にクエリする場合があるため、上限を設けて無限ループを防止 |
| エラーも結果として返す | Athena のエラーを JSON で返すと、Claude が SQL を修正して再試行する |
Step 9: システムプロンプトにスキーマ情報を埋め込む
ここが最も重要なステップです。 Claude がSQLを正しく生成するには、テーブル定義やデータの特性をシステムプロンプトに明示的に記述する必要があります。
あなたは[ドメイン]のデータアナリストです。
## 回答ルール
1. 検索結果から正確な数値を引用して回答してください
2. 数値には必ず単位を付けてください
3. データが見つからない場合は「該当データが見つかりませんでした」と回答してください
4. 推測や概算は行わないでください
## SQLクエリ記述ルール
- 構文: Presto SQL(Athena互換)
- 日本語カラム名はダブルクォートで囲む(例: "売上高")
- 文字列値はシングルクォート(例: '1Q')
## テーブル定義
### テーブル名: sales
| カラム | 型 | 説明 | 値の例 |
|--------|-----|------|--------|
| `region` | STRING | 地域名 | 東京, 大阪 |
| `fiscal_year` | INT | 会計年度 | 2021〜2026 |
| `quarter` | STRING | 四半期 | 1Q, 2Q, 3Q, 4Q, 通期 |
| `revenue_plan` | BIGINT | 計画売上高(百万円) | — |
| `revenue_actual` | BIGINT | 実績売上高(百万円) | — |
## データの注意点
- [集計時に二重計上を避けるフィルタ条件]
- [特定のカラム値の組み合わせ制約]
- [欠損データの年度・期間]
- [曖昧な用語の判定ルール]
プロンプト設計のコツ:
| ポイント | 詳細 |
|---|---|
| テーブル定義は必須 | Claude はDBスキーマを知らない。全カラムの名前・型・説明・取りうる値を列挙する |
| 集計ルールを明記 | サマリー行が含まれるデータでは、二重計上を防ぐフィルタ条件を具体的に記述する |
| JOIN パターンを示す | 複数テーブルの結合が必要な場合、具体的なSQLの例を含める |
| 曖昧な用語の定義 | 同じ言葉が複数の意味を持つ場合(例:「売上」が金額と棟数のどちらか)、判定ルールを定める |
| 値の例を書く | quarter カラムに入る値が '1Q' なのか 'Q1' なのか、Claude は知らない |
経験上の教訓: システムプロンプトの品質がSQL生成精度の 80% を決めます。テーブル定義だけでなく、「このデータ特有の注意点」を丁寧に書くことで、Claude のミスが大幅に減ります。実運用では14項目以上のルールをプロンプトに記載して精度を安定させました。
Step 10: 動作確認
以下のような質問で動作確認します:
2025年度1Qの全地域の売上実績合計を教えてください。
正常に動作すると、ログに以下のような流れが見えます:
[iteration 1] SQL: SELECT SUM("revenue_actual") AS total FROM sales WHERE "fiscal_year" = 2025 AND "quarter" = '1Q'
Claude が以下のように動作すれば成功です:
- 質問を解析し、
execute_sql_queryツールの使用を決定(stop_reason: "tool_use") - 適切な SELECT 文を生成
- アプリが Athena に直接クエリ実行
- 結果を
toolResultとして返却 - Claude が結果を解釈し、自然言語で回答(
stop_reason: "end_turn")
複数回のSQL実行が発生するケース: 「全事業セグメントの売上を比較して」のような質問では、Claude がテーブルごとに複数回SQLを実行することがあります。この場合、ループが複数回回り、全結果を集約してから回答します。
つまずきやすいポイント
IAM 権限不足
アプリの実行ロール(ECS タスクロール等)に athena:*, s3:*(データ・結果バケット両方), glue:Get* が必要です。
Athena のクエリ結果出力先
Athena はクエリ結果を S3 に書き出します。ATHENA_OUTPUT_S3 で指定したパスへの書き込み権限を確認してください。
日本語カラム名の扱い
- DDL(CREATE TABLE): バッククォート
`で囲む - DML(SELECT): ダブルクォート
"で囲む - システムプロンプトにはダブルクォートの使用をルールとして明記すること。Claude はデフォルトでバッククォートを使いがちです
toolResult の形式エラー
Converse API では toolResult の toolUseId が直前の toolUse ブロックの ID と一致する必要があります。不一致だと API がエラーを返します。
Claude が SQL を使わない
システムプロンプトに「すべての質問に execute_sql_query ツールを使用してください」と明記すると改善します。
コスト感
| サービス | 課金単位 | 目安 |
|---|---|---|
| Athena | スキャンしたデータ量 | $5/TB(Parquet なら最小限) |
| S3 | ストレージ + リクエスト | Parquet 数 MB なら無視できる |
| Bedrock Converse API | 入出力トークン数 | モデル依存 |
Parquet + Athena の組み合わせはスキャン量が少なく、社内ツールレベルの利用なら月数ドル程度に収まることが多いです。Lambda が不要な分、管理対象も減ります。
まとめ
Bedrock Converse API の tool_use を活用し、アプリケーション側でエージェントループを組むことで、構造化データへの自然言語SQLクエリを実現しました。
学んだこと:
- Converse API の
stop_reason: "tool_use"を検知してループを回すだけで、自前のエージェントが組める。Bedrock Agents(マネージドサービス)より構成がシンプル - SQL生成の精度はシステムプロンプトの品質に直結する。テーブル定義だけでなく、データ特性・集計ルール・曖昧な用語の判定ルール・具体的なSQLの例まで書く
- アプリから Athena を直接呼ぶことで、Lambda の Cold Start やAction Group の設定が不要になり、レスポンスも速い
- エラーも
toolResultとして返すことで、Claude が SQL を自力で修正して再試行できる
構造化データの検索でRAGの限界を感じている方、また Bedrock Agents の制約(ストリーミングやUI制御)が気になっている方は、この Converse API + 自前ループのアプローチを試してみてください。








