
Image Generation AI Architecture Showdown: Autoregressive vs Diffusion — Who Will Win in 2026?
This page has been translated by machine translation. View original
Introduction
"So what's actually the difference between gpt-image-1 and DALL-E 3?"
If you've been using image generation AI, you might have found yourself wondering this. Both are models made by OpenAI, yet their architectures are fundamentally different. When I looked into it, I found a major paradigm shift taking place that is shaking the entire image generation AI industry.
In this article, we'll dig into the differences between Autoregressive and Diffusion models, and follow the market trends as of 2026.
Autoregressive vs Diffusion — What's the Essential Difference?
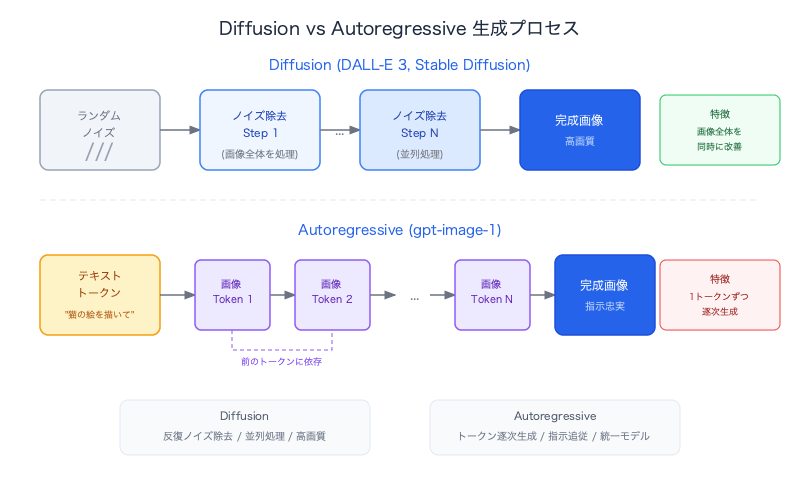
Diffusion Models (DALL-E 3, Stable Diffusion, Midjourney)
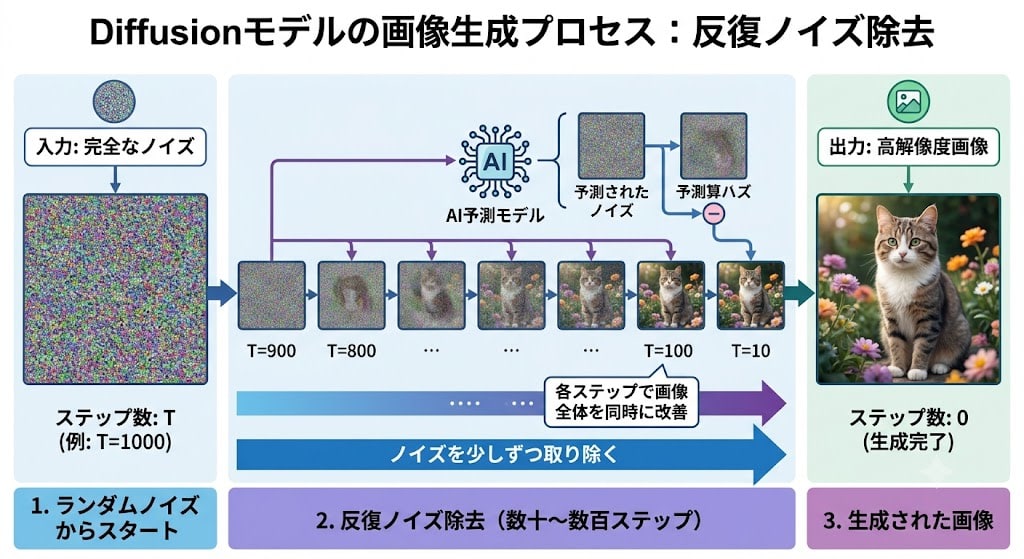
Diffusion models generate images through iterative denoising.
- Start from random noise
- Gradually remove the noise (tens to hundreds of steps)
- Improve the entire image simultaneously at each step
Because the entire image is processed in parallel, they excel at global coherence (overall composition and balance).
Autoregressive Models (gpt-image-1)
On the other hand, gpt-image-1 is an autoregressive model. It generates images using exactly the same principle as GPT generating text — predicting the next token — with no denoising involved whatsoever.
In other words, the same approach used for LLM text generation is being applied to images.
| Property | Diffusion | Autoregressive |
|---|---|---|
| Generation Process | Noise → iterative removal → image | Tokens generated one by one sequentially |
| Parallelism | High (processes entire image simultaneously) | Low (sequential processing) |
| Text Rendering | Weak (historically) | Strong (tokens = the domain where text excels) |
| Instruction Following | Weak | Strong (same model as text understanding) |
| Image Quality | High (artistic expression) | Improving (resolved through scale) |
Why Did Two Approaches Emerge? — The Wall Between Discrete and Continuous
Behind the existence of these two approaches lies a difference in the nature of data.
- Images = Continuous data. Even if you randomly change 10% of the pixels in a photo of a cat, it still looks like a cat. You can smoothly transition from "complete noise" to "a sharp image."
- Text = Discrete data. Adding 10% noise to the word
CATdoesn't produce a "blurry cat." It either becomes a different word likeHAT, or just a meaningless string of characters.
This "continuous vs. discrete" wall gave rise to the division: Diffusion for images, Autoregressive for text. And the reason Autoregressive models convert images into tokens (discrete units) before generating them is precisely a strategy for overcoming this wall.
Why Are Diffusion Models Bad at Text Rendering?
Have you ever seen distorted characters in AI-generated images? For Diffusion models, text within an image is simply a visual shape. When denoising "EXIT," rather than understanding it as 4 characters E-X-I-T, it tries to draw 4 independent geometric shapes. If pixels shift slightly during an intermediate step and "E" transforms into "F," the model doesn't perceive any visual problem.
Autoregressive models, on the other hand, generate images in the same token space as text, so they can render characters while retaining their "meaning." The difference in "Text Rendering" in the comparison table arises from this structural difference.
How Do Autoregressive Models Generate Images?
Being told "images are created the same way as text" might not click immediately. Let's walk through the concrete process.
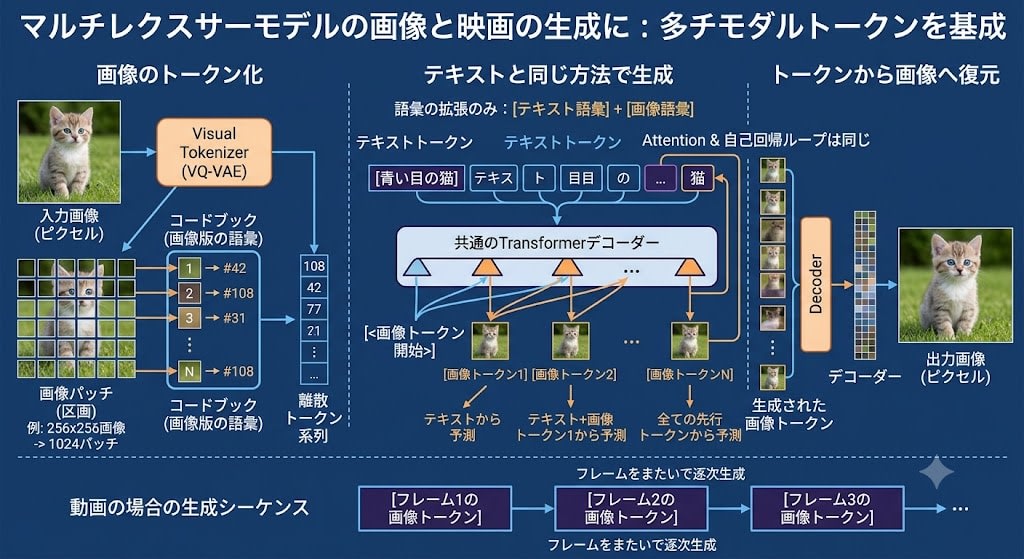
Step 1: Image Tokenization
The image is passed through a Visual Tokenizer (such as VQ-VAE) and converted into discrete tokens.
- Example: A 256×256 image → approximately 1024 tokens
- Each token = a small patch (section) of the image
- Mapped to a codebook (the image equivalent of a "vocabulary")
Step 2: Generation Using the Same Method as Text
[Text tokens] → [Image token 1] → [Image token 2] → ... → [Image token N]
↑ predicted from ↑ predicted from ↑ predicted from
text text + token 1 all preceding tokens
Same Transformer, same Attention, same autoregressive loop. Only the vocabulary has been expanded: text vocabulary + image vocabulary.
Step 3: Reconstructing the Image from Tokens
Image tokens → Decoder → Pixel image
For video, the same idea applies: frame 1 tokens → frame 2 tokens → ... generating sequentially across frames.
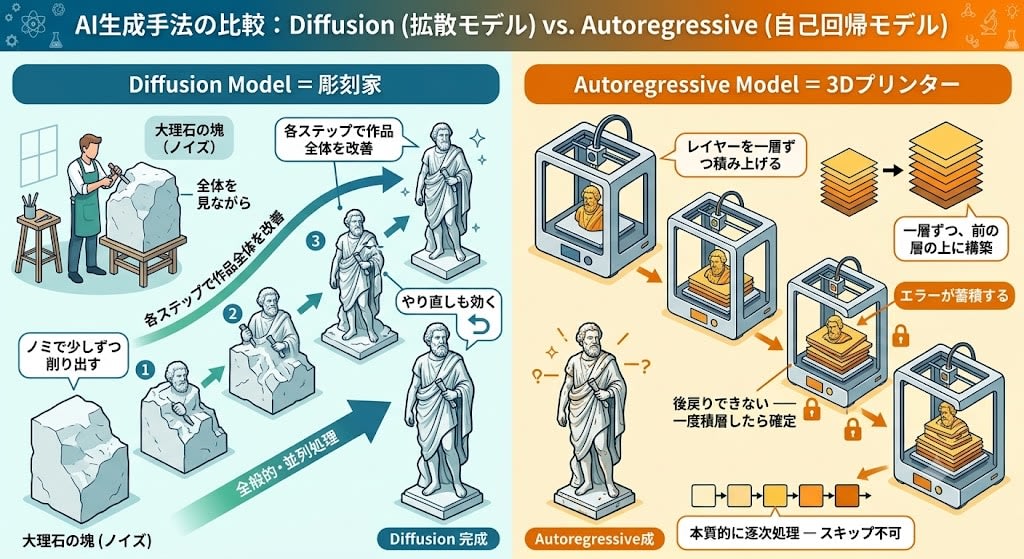
A 3D Printer and a Sculptor — An Analogy to Grasp Intuitively
These two approaches can actually be understood at a glance by comparing them to something familiar.
Diffusion = Sculptor
Chiseling away little by little from a block of marble (noise), looking at the whole piece throughout. Improving the entire work at each step. Corrections are possible.
Autoregressive = 3D Printer
Building up layers one at a time.
- Layer by layer, constructing on top of the previous layer
- No going back — once a layer is laid down, it's final
- Errors accumulate — if there's a bad layer, everything above it is affected
- Inherently sequential — cannot be skipped
There's also a painter analogy, but a painter can redo their work. A 3D printer cannot. This matches precisely with the Autoregressive constraint of "once output, you can't go back."
The Error Accumulation Problem — How to Address Autoregressive's Weakness
Some of you may have noticed this from the 3D printer analogy. Autoregressive models have an inherent weakness called error accumulation. If a previous step is wrong, it propagates to everything that follows.
So why did OpenAI adopt this approach?
Possible reasons:
- Unified architecture — Both text and images are handled by the same model. The scaling story becomes simpler.
- Prioritizing instruction following — Since text understanding and image generation share the same space, fidelity to prompts is high.
- Mitigation through large-scale training — Error accumulation is a theoretical weakness, but it can be suppressed to a practical level with sufficient scale and training techniques.
Much of the industry believes the best approach is a "Transformer and Diffusion hybrid (DiT: Diffusion Transformer)," but OpenAI deliberately chose the pure Autoregressive path.
Self-Correction Through Reasoning — A New Answer to Error Accumulation
Here, a question arises. Just as LLMs improved text quality by "thinking before answering," can image generation also "think while drawing"?
This is actually becoming exactly the structural strength of Autoregressive models. The introduction of Reasoning models to image generation with GPT Image 2 (April 2026) is the first step in this direction.
Possible Approaches
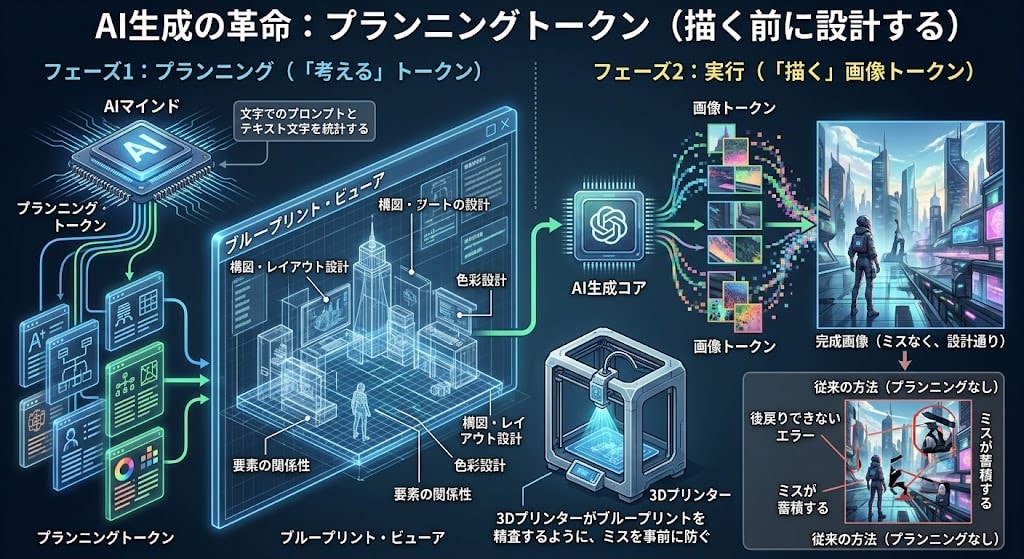
1. Planning Tokens — Designing Before Drawing
Before generating image tokens, "think" about composition, layout, and color design using text reasoning tokens. Like a 3D printer carefully reviewing a blueprint before printing, mistakes are prevented in advance.
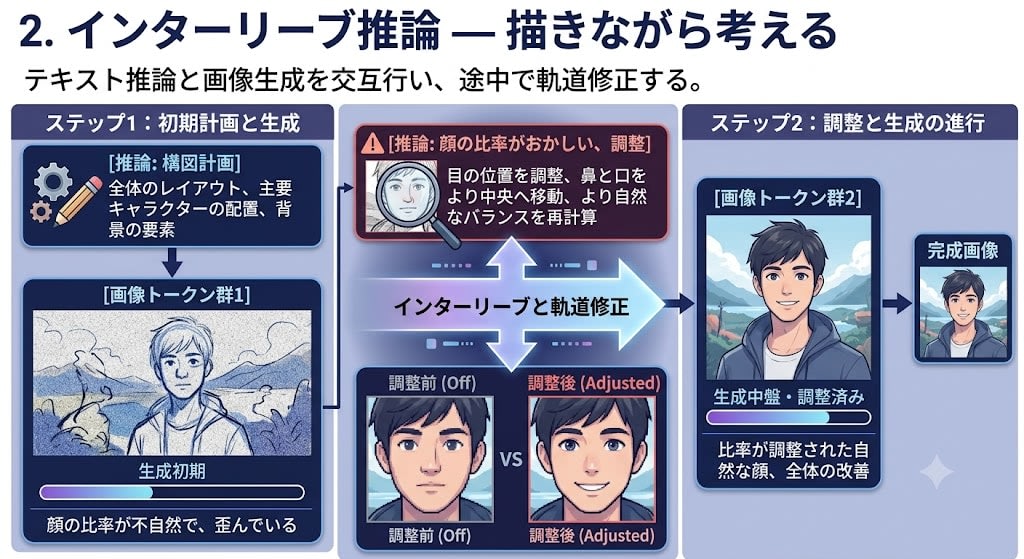
2. Interleaved Reasoning — Thinking While Drawing
[Reasoning: composition plan] → [Image token group 1] → [Reasoning: facial proportions are off, adjusting] → [Image token group 2] → ...
Alternating between text reasoning and image generation, making course corrections midway.
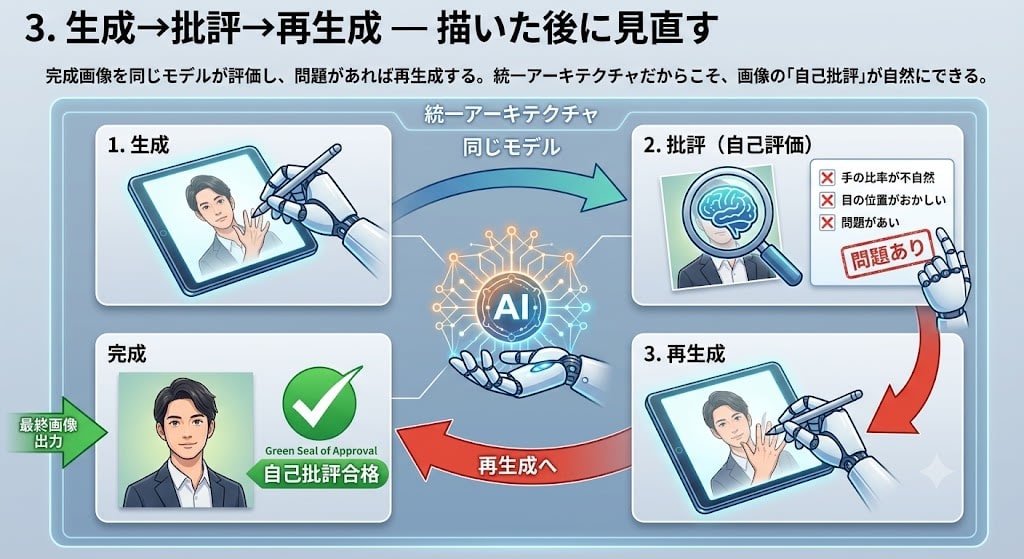
3. Generate → Critique → Regenerate — Reviewing After Drawing
The same model evaluates the completed image, and if there are problems, it regenerates. Because of the unified architecture, "self-critique" of images comes naturally.
Why Is This a Structural Advantage for AR?
This is the crucial point. Self-correction through Reasoning is an advantage unique to Autoregressive models.
- AR models share the same reasoning mechanisms as LLMs. Chain-of-thought, self-critique, and planning are native capabilities.
- Diffusion models operate in a continuous latent space, so there is no natural place to insert a "thinking" step.
- The unified architecture allows reasoning about image composition using the same Attention mechanism used to reason about text.
Extending the 3D printer analogy: a 3D printer that can pause before printing each layer, inspect the work done so far, and adjust the remaining blueprint. The error accumulation problem doesn't disappear, but it is significantly mitigated.
DiT (Diffusion Transformer) — Understanding the Third Option
We've looked closely at Diffusion and Autoregressive so far, but the architecture most widely adopted in image generation in 2026 is actually neither — it's DiT (Diffusion Transformer). Sora, Stable Diffusion 3, Flux, and Imagen 3 all use DiT.
The Limits of U-Net
Traditional Diffusion models (DALL-E 2, Stable Diffusion 1.x/2.x) used a CNN-based architecture called U-Net at the core of the denoising step. U-Net excels at image processing, but had two limitations:
- A scaling wall — Performance improvements tend to plateau even as parameters increase.
- Weak global context understanding — CNNs are strong at local pattern recognition but struggle to capture semantic coherence across the entire image.
The DiT Idea: Swapping Out the Denoising "Engine"
The idea behind DiT is simple. Maintain the Diffusion generation process (noise → iterative denoising → image) as-is, and replace the neural network that denoises at each step from U-Net to Transformer.
Traditional Diffusion: Noisy image → [U-Net] → slightly cleaner image → [U-Net] → ... → final image
DiT: Noisy image → [Transformer] → slightly cleaner image → [Transformer] → ... → final image
The generation principle is the same "sculptor" method. The image is that instead of a chisel, a more precise tool is now being used to carve.

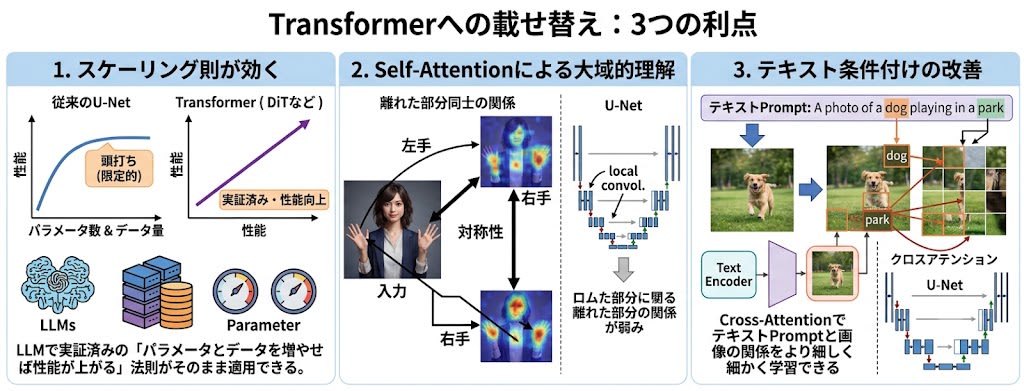
Why Replace It With a Transformer?
Swapping in a Transformer brings three advantages:
- Scaling laws apply — The law "increasing parameters and data improves performance," proven in LLMs, can be applied directly. This benefit was limited with U-Net.
- Global understanding through Self-Attention — Can directly capture the relationship between distant parts of an image (e.g., the symmetry of left and right hands).
- Improved text conditioning — Cross-Attention allows for more fine-grained learning of the relationship between text prompts and images.
Strictly speaking, DiT is a pure Diffusion model. The generation process is iterative denoising, not sequential token generation. However, because it uses a Transformer internally, it benefits from the same scaling as AR models.
It is called a "hybrid" because it combines Diffusion's generation philosophy + Transformer's scaling capability.
Market Trends in 2026 — The Competition Among Three Approaches
Pure Autoregressive (OpenAI Camp)
Has achieved great commercial success.
- GPT Image 1 launch week: over 700 million images generated, over 130 million users
- GPT Image 1.5 (December 2025): 1st place on the Arena text-to-image leaderboard (ELO 1264, 29 points ahead of 2nd place)
- GPT Image 2 (April 2026): Reasoning model introduced to image generation
- Many startups migrating from Diffusion servers to the OpenAI API
Pure Diffusion (Open Source Camp)
Still going strong.
- Open source models such as Flux and Stable Diffusion 3 are active
- Artist communities support Diffusion for its fine-grained aesthetic control
- The fine-tuning and LoRA ecosystem has matured
Hybrid DiT (Academic / Emerging Players)
The cutting edge of research.
- DiT (Diffusion Transformer) architecture: adopted by SD3, Flux, Sora, and Imagen 3
- MIT research: AR captures rough structure, a small Diffusion model finishes the details → 9x speed improvement, equivalent quality
- Combines Transformer's global understanding + Diffusion's image quality
| Approach | Strengths | Weaknesses | Representative Examples |
|---|---|---|---|
| Pure AR | Instruction following, text rendering, unified model | Error accumulation, historically lower quality | GPT Image 1/1.5/2 |
| Pure Diffusion | Image quality, artistic control, OSS | Speed, weak text rendering | Midjourney, SD3, Flux |
| Hybrid DiT | Balance of speed and quality | Architectural complexity | Sora, Imagen 3, SD3 |

Not "One Dominant Force" But a "Three-Way Rivalry"
As of 2026, there are no signs of Diffusion being abandoned. Rather, all three approaches coexist in their respective domains.
- Product/UX focus → Autoregressive (OpenAI)
- Open source/Art → Diffusion
- Research/Performance optimization → Hybrid DiT
What Lies Beyond — "Denoising Thought"
We've stated above that "text is discrete, so Diffusion is unsuitable for it," but there is one interesting perspective to consider. The human thought process itself is continuous and noisy.
Before writing a sentence, the brain doesn't hold a clear token sequence. It holds a "hazy cloud" of concepts, emotions, and spatial relationships, which it gradually crystallizes and organizes into structured language. This is remarkably similar to a denoising process.
Researchers are already moving in this direction. Rather than adding noise directly to text tokens, an approach called Embedding Diffusion is being experimented with — denoising "thought vectors" from random noise in a vector embedding space, then converting the completed thought vectors into text via a decoder. I-JEPA (Joint Embedding Predictive Architecture), proposed by Meta's Yann LeCun, also aims for prediction and refinement of abstract concepts in continuous space, pointing in the same direction.
The AR vs. Diffusion conflict may not end with the "three-way rivalry" of 2026. Denoising ideas in a continuous thought space before converting them to language or images — the possibility of such a fourth paradigm may be waiting just ahead.
Summary
- The difference between gpt-image-1 and DALL-E 3 is a fundamental architectural difference: Autoregressive (sequential token generation) vs. Diffusion (iterative denoising)
- At the root of this divergence is a mathematical wall called "continuous data vs. discrete data." Tokenizing images in AR models is a strategy for overcoming this wall
- Autoregressive tokenizes images and generates them the same way as LLMs. Like a 3D printer, it builds up layer by layer with no going back
- Diffusion's weakness in text rendering is because it treats characters as "shapes" rather than "meaning." AR models solve this problem by sharing a token space
- There is a theoretical weakness of error accumulation, but a solution unique to AR models — self-correction through Reasoning (thinking before drawing, making course corrections while drawing) — is beginning to emerge
- The 2026 market is a three-way contest of "AR vs. Diffusion vs. Hybrid." Rather than one disappearing, specialization by use case is advancing
- Beyond that, the possibility of a "fourth paradigm" — denoising ideas in a continuous thought space before converting them to output — is also coming into view
