画像生成AIのアーキテクチャ対決:Autoregressive vs Diffusion — 2026年の勝者は?
はじめに
「gpt-image-1とDALL-E 3って、結局何が違うの?」
画像生成AIを使っていると、こんな疑問が浮かびませんか? 両方ともOpenAIが作ったモデルなのに、アーキテクチャが根本的に異なります。調べてみると、そこには画像生成AI業界全体を揺るがす大きなパラダイムシフトが起きていました。
本記事では、Autoregressive(自己回帰)モデルとDiffusion(拡散)モデルの違いを掘り下げ、2026年現在の市場動向まで追いかけてみます。
Autoregressive vs Diffusion — 何が本質的に違うのか?
Diffusionモデル(DALL-E 3、Stable Diffusion、Midjourney)
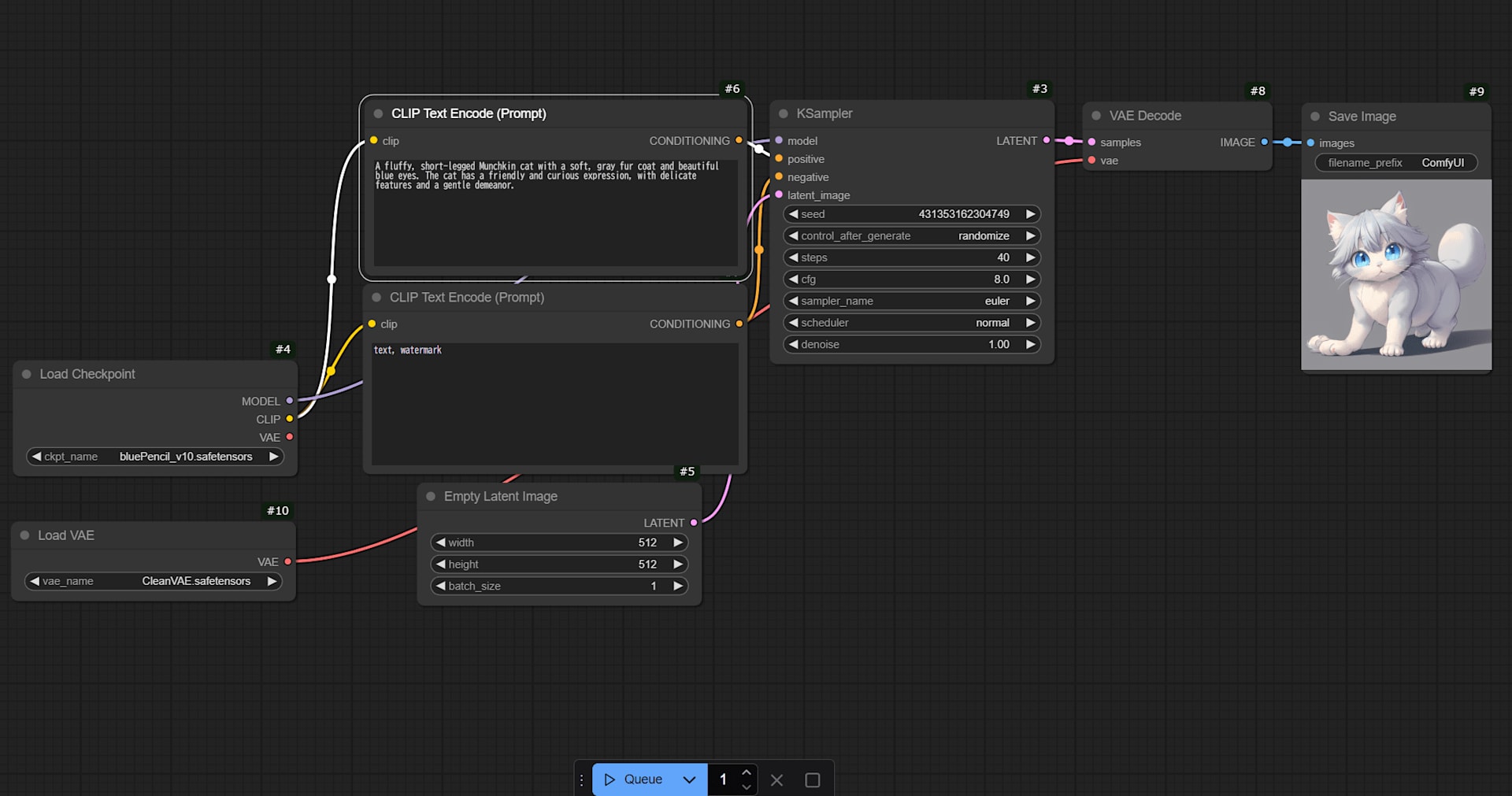
Diffusionモデルは反復ノイズ除去で画像を生成します。
- ランダムノイズからスタート
- ノイズを少しずつ取り除く(数十〜数百ステップ)
- 各ステップで画像全体を同時に改善
画像全体を並列に処理するため、グローバルな整合性(全体的な構図やバランス)に強みがあります。
Autoregressiveモデル(gpt-image-1)
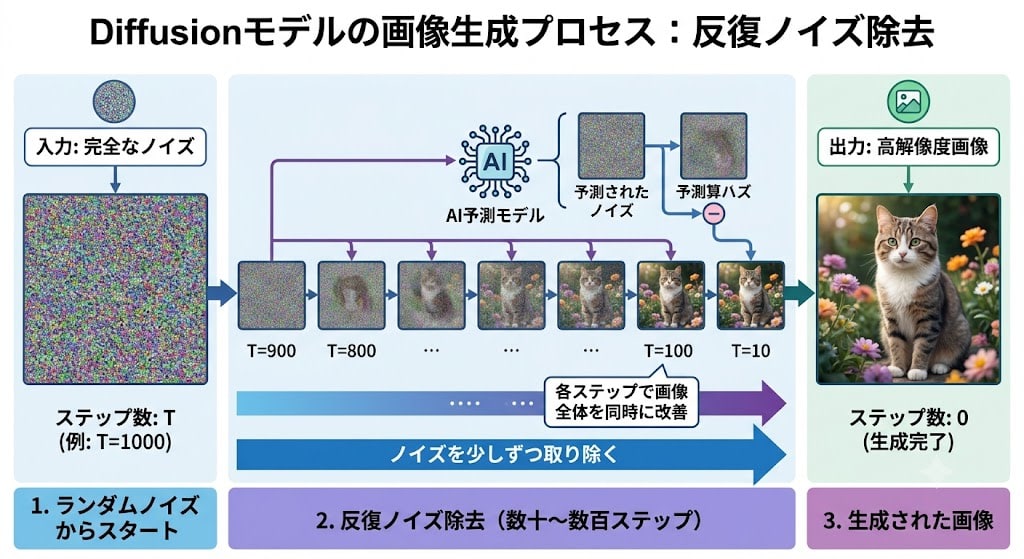
一方、gpt-image-1は自己回帰モデルです。これはGPTがテキストを生成するのとまったく同じ原理 — 次のトークンを予測する — で画像を生成します。ノイズ除去は一切関与しません。
つまり、LLMのテキスト生成と同じアプローチを画像に適用しているということです。
| 特性 | Diffusion | Autoregressive |
|---|---|---|
| 生成プロセス | ノイズ → 反復除去 → 画像 | トークンを1つずつ逐次生成 |
| 並列性 | 高い(画像全体を同時処理) | 低い(逐次処理) |
| テキスト描画 | 苦手(歴史的に) | 得意(トークン = テキストの得意領域) |
| 指示追従性 | 弱い | 強い(テキスト理解と同じモデル) |
| 画像品質 | 高い(芸術的表現) | 改善中(スケールで解決) |
なぜ2つのアプローチに分かれたのか? — 離散と連続の壁
この2つのアプローチが存在する背景には、データの性質の違いがあります。
- 画像 = 連続データ。猫の写真のピクセルを10%ランダムに変えても、まだ猫に見える。「完全なノイズ」から「鮮明な画像」へ滑らかに遷移できる
- テキスト = 離散データ。単語
CATに10%のノイズを加えても「ぼやけた猫」にはならない。HATという別の単語か、意味不明な文字列になるだけ
この「連続 vs 離散」の壁が、画像にはDiffusion、テキストにはAutoregressiveという棲み分けを生みました。そしてAutoregressiveモデルが画像をトークン(離散単位)に変換してから生成するのは、まさにこの壁を乗り越えるための戦略です。
なぜDiffusionはテキスト描画が苦手なのか?
AI生成画像で文字が崩れる現象を見たことがありませんか? Diffusionモデルにとって、画像内の文字は単なる視覚的な形状です。「EXIT」をデノイズする際、E-X-I-Tの4文字として理解するのではなく、4つの独立した幾何学的形状を描こうとします。途中のステップでピクセルがわずかにずれると、「E」が「F」に変形しても、モデルは視覚的に問題を感じません。
一方、Autoregressiveモデルはテキストと同じトークン空間で画像を生成するため、文字の「意味」を保持したまま描画できます。比較表の「テキスト描画」の差は、この構造的な違いから生まれています。
Autoregressiveモデルはどうやって画像を生成するのか?
「テキストと同じ方法で画像を作る」と言われても、ピンとこないかもしれません。具体的な流れを見てみましょう。
Step 1: 画像のトークン化
画像をVisual Tokenizer(VQ-VAEなど)に通して、離散トークンに変換します。
- 例:256×256の画像 → 約1024個のトークン
- 各トークン = 画像の小さなパッチ(区画)
- コードブック(画像版の「語彙」)にマッピング
Step 2: テキストと同じ方法で生成
[テキストトークン] → [画像トークン1] → [画像トークン2] → ... → [画像トークンN]
↑ テキストから ↑ テキスト+ ↑ 全ての先行
予測 トークン1から予測 トークンから予測
同じTransformer、同じAttention、同じ自己回帰ループ。語彙が拡張されただけです:テキスト語彙 + 画像語彙。
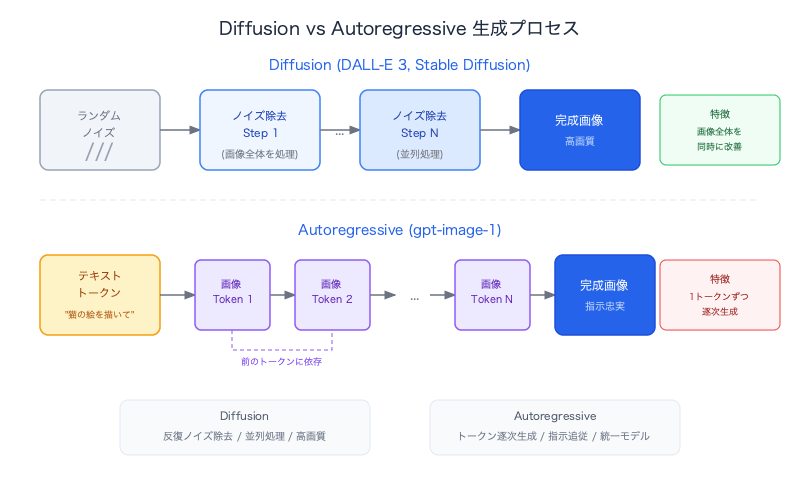
Step 3: トークンから画像へ復元
画像トークン → デコーダー → ピクセル画像
動画の場合も同じ考え方で、フレーム1のトークン → フレーム2のトークン → ... とフレームをまたいで逐次生成します。
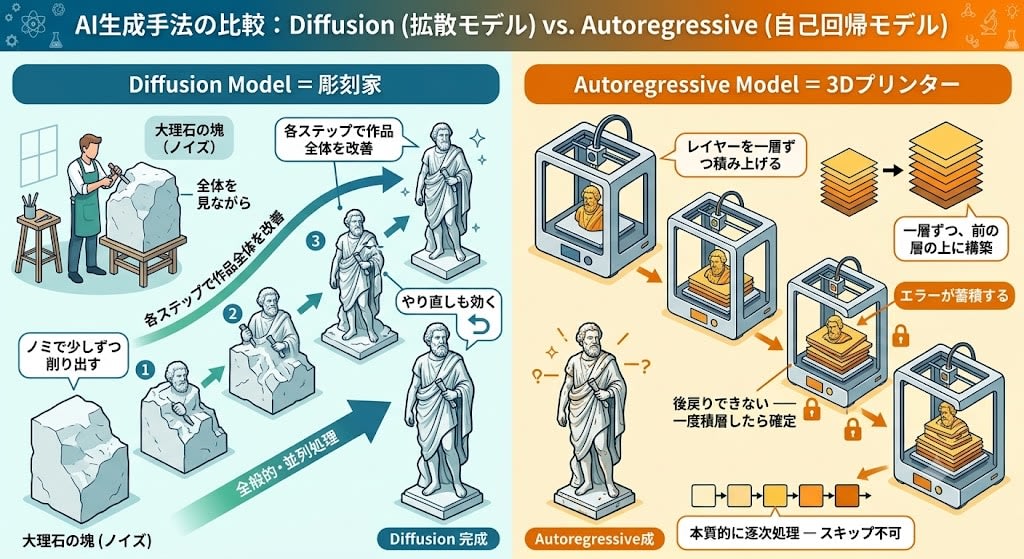
3Dプリンターと彫刻家 — 直感で掴むアナロジー
この2つのアプローチ、実は身近なもので例えると一発で理解できます。
Diffusion = 彫刻家
大理石の塊(ノイズ)から、全体を見ながらノミで少しずつ削り出す。各ステップで作品全体を改善していく。やり直しも効く。
Autoregressive = 3Dプリンター
レイヤーを一層ずつ積み上げていく。
- 一層ずつ、前の層の上に構築
- 後戻りできない — 一度積層したら確定
- エラーが蓄積する — 悪い層があると、その上の全てに影響
- 本質的に逐次処理 — スキップ不可
画家(painter)のアナロジーもありますが、画家は描き直しができます。3Dプリンターはできません。これがAutoregressiveの「一度出力したら戻れない」制約と正確に一致します。
エラー蓄積問題 — Autoregressiveの弱点にどう向き合うか?
3Dプリンターのアナロジーで気づいた方もいるでしょう。Autoregressiveモデルにはエラー蓄積という本質的な弱点があります。前のステップが間違っていると、その後の全てに波及します。
では、なぜOpenAIはこのアプローチを採用したのか?
考えられる理由:
- 統一アーキテクチャ — テキストも画像も同じモデルで処理。スケーリングの話がシンプルになる
- 指示追従性の優先 — テキスト理解と画像生成が同じ空間にあるため、プロンプトへの忠実度が高い
- 大規模学習による緩和 — エラー蓄積は理論的な弱点だが、十分なスケールとトレーニング技法で実用レベルまで抑えられる
業界の多くは「TransformerとDiffusionのハイブリッド(DiT: Diffusion Transformer)」が最良と考えていますが、OpenAIはあえて純粋なAutoregressive路線を選びました。
Reasoningで自己修正 — エラー蓄積への新しい解答
ここで一つ疑問が浮かびます。LLMが「考えてから答える」ことでテキストの品質を上げたように、画像生成でも「考えながら描く」ことはできないのか?
実はこれがまさに、Autoregressiveモデルの構造的な強みになりつつあります。GPT Image 2(2026年4月)がReasoningモデルを画像生成に導入したのは、この方向の第一歩です。
考えられるアプローチ
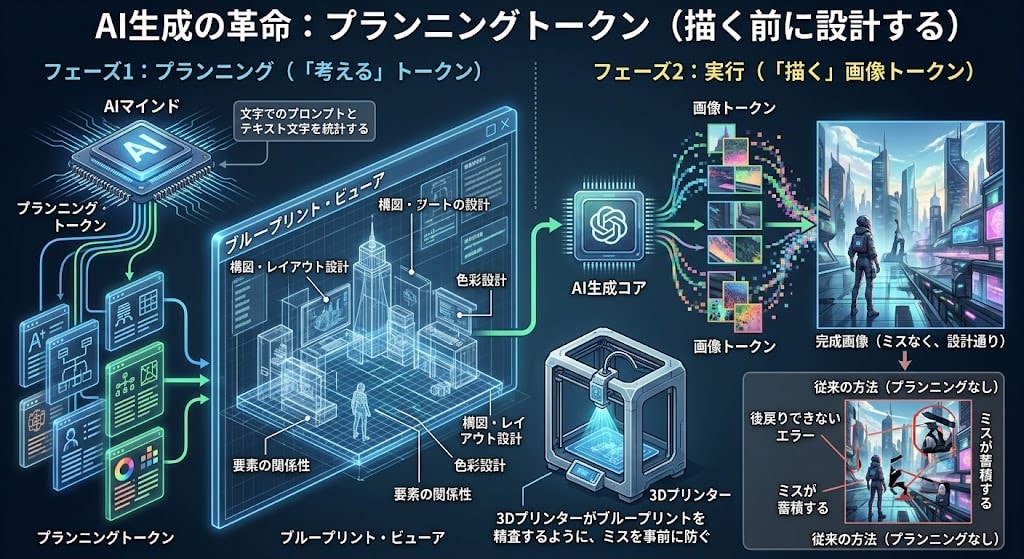
1. プランニングトークン — 描く前に設計する
画像トークンを生成する前に、テキストの推論トークンで構図・レイアウト・色彩設計を「考える」。3Dプリンターが印刷前にブループリントを精査するように、ミスを事前に防ぐ。
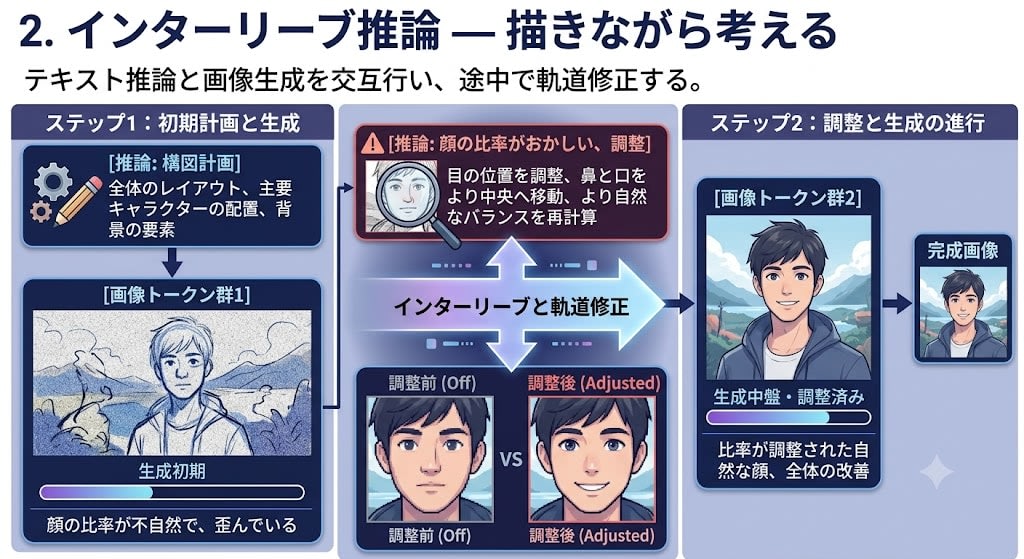
2. インターリーブ推論 — 描きながら考える
[推論: 構図計画] → [画像トークン群1] → [推論: 顔の比率がおかしい、調整] → [画像トークン群2] → ...
テキスト推論と画像生成を交互に行い、途中で軌道修正する。
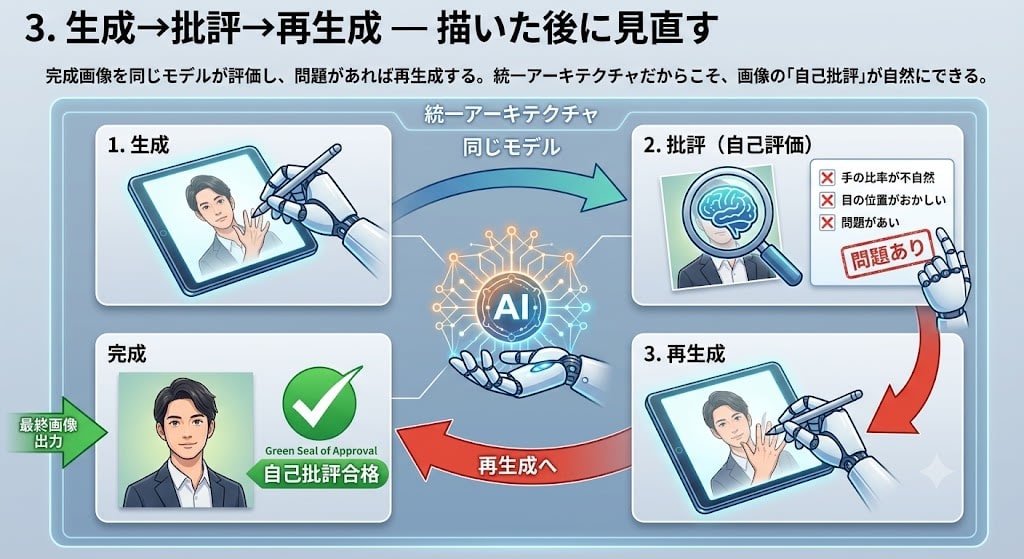
3. 生成→批評→再生成 — 描いた後に見直す
完成画像を同じモデルが評価し、問題があれば再生成する。統一アーキテクチャだからこそ、画像の「自己批評」が自然にできる。
なぜこれがARの構造的優位なのか?
ここが重要なポイントです。Reasoningによる自己修正は、Autoregressiveモデルに固有の利点です。
- ARモデルはLLMと同じ推論機構を共有している。Chain-of-thought、自己批評、計画立案はネイティブな能力
- Diffusionモデルは連続的な潜在空間で動作するため、「考える」ステップを挿入する自然な場所がない
- 統一アーキテクチャにより、テキストについて推論するのと同じAttention機構で画像の構成についても推論できる
3Dプリンターのアナロジーを拡張すると:各層を印刷する前に一度止まり、これまでの出来を検査し、残りの設計図を調整できる3Dプリンター。エラー蓄積問題が消えるわけではありませんが、大幅に緩和されます。
DiT(Diffusion Transformer)— 第三の選択肢を理解する
ここまでDiffusionとAutoregressiveの2つを詳しく見てきましたが、実は2026年の画像生成で最も広く採用されているアーキテクチャは、どちらでもない DiT(Diffusion Transformer) です。Sora、Stable Diffusion 3、Flux、Imagen 3 — いずれもDiTを採用しています。
U-Netの限界
従来のDiffusionモデル(DALL-E 2、Stable Diffusion 1.x/2.x)は、ノイズ除去ステップの中核にU-NetというCNNベースのアーキテクチャを使っていました。U-Netは画像処理には優れていますが、2つの限界がありました:
- スケーリングの壁 — パラメータを増やしても性能向上が頭打ちになりやすい
- 大域的な文脈理解の弱さ — CNNは局所的なパターン認識には強いが、画像全体の意味的な整合性を捉えるのが苦手
DiTの発想:ノイズ除去の「エンジン」を載せ替える
DiTのアイデアはシンプルです。Diffusionの生成プロセス(ノイズ→反復除去→画像)はそのまま維持し、各ステップでノイズを除去するニューラルネットワークをU-NetからTransformerに置き換える。
従来のDiffusion: ノイズ画像 → [U-Net] → 少しきれいな画像 → [U-Net] → ... → 完成画像
DiT: ノイズ画像 → [Transformer] → 少しきれいな画像 → [Transformer] → ... → 完成画像
生成の原理は同じ「彫刻家」方式。ただしノミの代わりに、より精密なツールで削るようになった、というイメージです。

なぜTransformerに置き換えるのか?
Transformerへの載せ替えは3つの利点をもたらします:
- スケーリング則が効く — LLMで実証済みの「パラメータとデータを増やせば性能が上がる」法則がそのまま適用できる。U-Netではこの恩恵が限定的だった
- Self-Attentionによる大域的理解 — 画像の離れた部分同士の関係(例:左手と右手の対称性)を直接捉えられる
- テキスト条件付けの改善 — Cross-AttentionでテキストPromptと画像の関係をより細かく学習できる
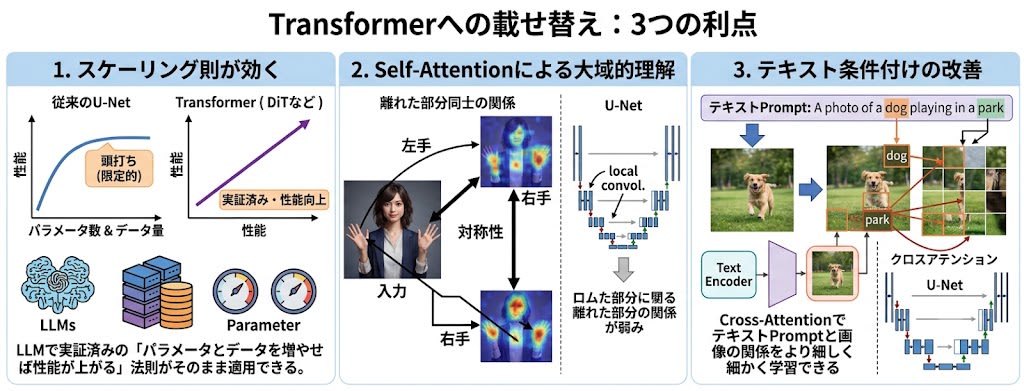
厳密にはDiTは純粋なDiffusionモデルです。生成プロセスはノイズ除去の反復であり、トークンの逐次生成ではありません。ただし、内部にTransformerを使っているため、ARモデルと同じスケーリングの恩恵を受けます。
「ハイブリッド」と呼ばれるのは、Diffusionの生成哲学 + Transformerのスケーリング能力を組み合わせているからです。
2026年の市場動向 — 3つのアプローチの競争
純粋Autoregressive(OpenAI陣営)
商業的に大成功を収めています。
- GPT Image 1 ローンチ初週:7億枚以上の画像生成、1.3億人以上のユーザー
- GPT Image 1.5(2025年12月):Arena text-to-imageリーダーボードで1位(ELO 1264、2位に29ポイント差)
- GPT Image 2(2026年4月):画像生成にReasoningモデルを導入
- 多くのスタートアップがDiffusionサーバーからOpenAI APIに移行
純粋Diffusion(オープンソース陣営)
依然として健在です。
- Flux、Stable Diffusion 3などのオープンソースモデルが活発
- アーティストコミュニティは微細な審美的コントロールの面でDiffusionを支持
- ファインチューニングやLoRAのエコシステムが成熟
ハイブリッド DiT(学術・新興勢力)
研究の最前線です。
- DiT(Diffusion Transformer)アーキテクチャ:SD3、Flux、Sora、Imagen 3が採用
- MITの研究:ARで大まかな構造を捉え、小さなDiffusionモデルで細部を仕上げる → 9倍の速度向上、品質は同等
- Transformerの大域的理解力 + Diffusionの画像品質を両立
| アプローチ | 強み | 弱み | 代表例 |
|---|---|---|---|
| 純粋AR | 指示追従、テキスト描画、統一モデル | エラー蓄積、歴史的に品質劣後 | GPT Image 1/1.5/2 |
| 純粋Diffusion | 画像品質、芸術的制御、OSS | 速度、テキスト描画が弱い | Midjourney, SD3, Flux |
| Hybrid DiT | 速度と品質の両立 | アーキテクチャの複雑性 | Sora, Imagen 3, SD3 |

「一強」ではなく「三国志」
2026年現在、Diffusionが捨てられる兆候はありません。むしろ3つのアプローチがそれぞれの領域で共存しています。
- プロダクト/UX重視 → Autoregressive(OpenAI)
- オープンソース/アート → Diffusion
- 研究/性能最適化 → Hybrid DiT
その先にあるもの — 「思考のデノイズ」
ここまで「テキストは離散的だからDiffusionは不向き」と述べましたが、一つ興味深い視点があります。人間の思考プロセス自体は連続的でノイジーだということです。
文章を書く前、脳は明確なトークン列を持っているわけではありません。概念・感情・空間的関係の「ぼんやりとした雲」を抱えていて、それを徐々に結晶化させ、構造化された言語に落とし込んでいます。これはまさにデノイジングのプロセスに似ています。
研究者たちは既にこの方向に動いています。テキストのトークンに直接ノイズを加えるのではなく、ベクトル埋め込み空間でランダムノイズから「思考ベクトル」をデノイズし、完成した思考ベクトルをデコーダでテキストに変換するEmbedding Diffusionというアプローチが実験されています。MetaのYann LeCunが提唱する**I-JEPA(Joint Embedding Predictive Architecture)**も、連続空間での抽象的な概念の予測・精緻化を目指しており、同じ方向性です。
AR vs Diffusionの対立は、2026年の「三国志」で終わりではないかもしれません。連続的な思考空間でアイデアをデノイズしてから言語や画像に変換する — そんな第四のパラダイムが、この先に待っている可能性があります。
まとめ
- gpt-image-1とDALL-E 3の違いは、Autoregressive(トークン逐次生成)vs Diffusion(反復ノイズ除去)というアーキテクチャの根本的な差異
- この分岐の根底には「連続データ vs 離散データ」という数学的な壁がある。ARモデルが画像をトークン化するのは、この壁を乗り越える戦略
- Autoregressiveは画像をトークン化してLLMと同じ方法で生成する。3Dプリンターのように一層ずつ積み上げ、後戻りできない
- Diffusionがテキスト描画を苦手とするのは、文字を「意味」ではなく「形状」として扱うため。ARモデルはトークン空間を共有することでこの問題を解決
- エラー蓄積という理論的弱点があるが、Reasoningによる自己修正(描く前に考える、描きながら軌道修正する)というARモデル固有の解決策が登場しつつある
- 2026年の市場は「AR vs Diffusion vs Hybrid」の三つ巴。どれか一つが消えるのではなく、用途に応じた使い分けが進んでいる
- その先には、連続的な思考空間でアイデアをデノイズしてから出力に変換する「第四のパラダイム」の可能性も見えている