
I Reorganized Clean Architecture, SOLID, and DIP Again — Are They Still Useful in the Age of AI-Driven Development?
This page has been translated by machine translation. View original
Introduction
"What exactly is Clean Architecture?" "What does the D in SOLID stand for again?" — Do you have questions like these?
You know the names of design patterns, but you're not sure how they actually relate to each other, and whether these patterns are still valid in an era where coding agents like Claude Code have become commonplace. Those kinds of questions prompted me to organize my thoughts on the topic.
A code review comment pointing out that "the use case is doing repository-level processing" was what prompted me to revisit this. Code I thought I'd written as a "use case layer" actually contained data persistence logic directly embedded in it.
What is Clean Architecture?
It's a design pattern centered around the dependency rule, proposed by Robert C. Martin (Uncle Bob) in his 2012 blog post "The Clean Architecture" (later published as a book in 2017). It also integrates earlier ideas such as Hexagonal Architecture (Ports & Adapters) and Onion Architecture.
The core rule is simple: outer layers depend on inner layers. The reverse is not allowed.
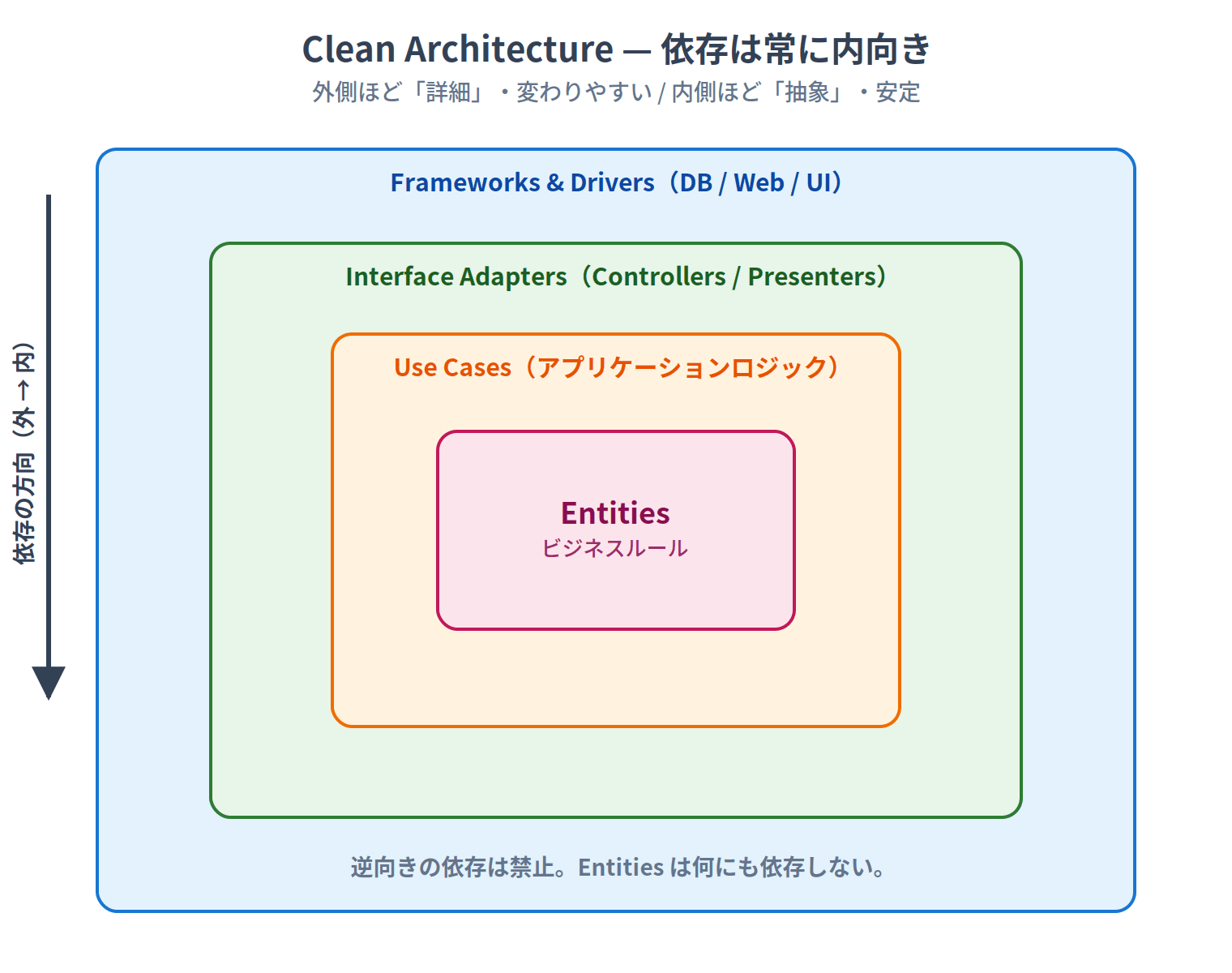
The layers are nested (contained within each other), and all dependency arrows point inward. The further out you go, the more "detailed" and changeable; the further in, the more "abstract" and stable. Entities depend on nothing and are the most stable.
Looking at the four layers from the inside out:
| Layer | Role | Examples |
|---|---|---|
| Entities | Core business rules. No dependencies | User, Order |
| Use Cases | Application-specific logic | CreateUser, PlaceOrder |
| Interface Adapters | Data format conversion | Controllers, Presenters, Repository implementations |
| Frameworks & Drivers | DB, web frameworks, UI | PostgreSQL, Express, React |
The most important point is that business logic has no knowledge of the DB or framework. Whether you're using Express or switch to Fastify, or migrate from PostgreSQL to MongoDB, you don't need to touch the domain layer.
SOLID Principles — 5 Design Principles
The design philosophy behind Clean Architecture is the SOLID principles, also organized by Robert C. Martin.
S — Single Responsibility Principle
A class (module) should have only one reason to change.
// NG: UserService handles authentication, email sending, and DB persistence
class UserService {
authenticate() { ... }
sendEmail() { ... }
saveToDb() { ... }
}
// OK: Separated by responsibility
class AuthService { authenticate() { ... } }
class EmailService { sendEmail() { ... } }
class UserRepository { save() { ... } }
O — Open/Closed Principle
Open for extension, closed for modification.
// NG: Modify the if statement every time a format is added
if (type === "pdf") { ... }
else if (type === "csv") { ... }
// OK: Just add a new class
interface Exporter { export(data: Data): void }
class PdfExporter implements Exporter { ... }
class CsvExporter implements Exporter { ... } // Just add it
L — Liskov Substitution Principle
Subtypes should be substitutable for their base types without violating the contract.
// NG: Penguin breaks the fly contract (cannot substitute as a Bird)
class Bird { fly(): void { ... } }
class Penguin extends Bird {
fly() { throw new Error("Penguins can't fly") } // Contract violation
}
// OK: Separate abstractions based on ability to fly
interface Bird { eat(): void }
interface FlyingBird extends Bird { fly(): void }
class Sparrow implements FlyingBird { ... }
class Penguin implements Bird { ... } // No substitution problem since it doesn't have fly
I — Interface Segregation Principle
Don't force clients to depend on methods they don't use. Prefer multiple small interfaces over one large interface.
// NG: One massive interface. Print-only machines are forced to implement scan/fax
interface Machine { print(): void; scan(): void; fax(): void }
// OK: Separated by role. Only implement what you need
interface Printer { print(): void }
interface Scanner { scan(): void }
class SimplePrinter implements Printer { print() { ... } }
D — Dependency Inversion Principle
This is the core of today's discussion. We'll look at it in detail in the next section.
DIP — What Exactly Gets "Inverted" in Dependency Inversion?
DIP has two rules:
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
It's hard to understand from words alone, so let's look at a concrete example.
Without DIP
class StripePayment {
charge(amount: number) { /* Stripe API call */ }
}
class OrderService {
private payment = new StripePayment() // ← Direct dependency
placeOrder(amount: number) {
this.payment.charge(amount)
}
}
Direction of dependency:
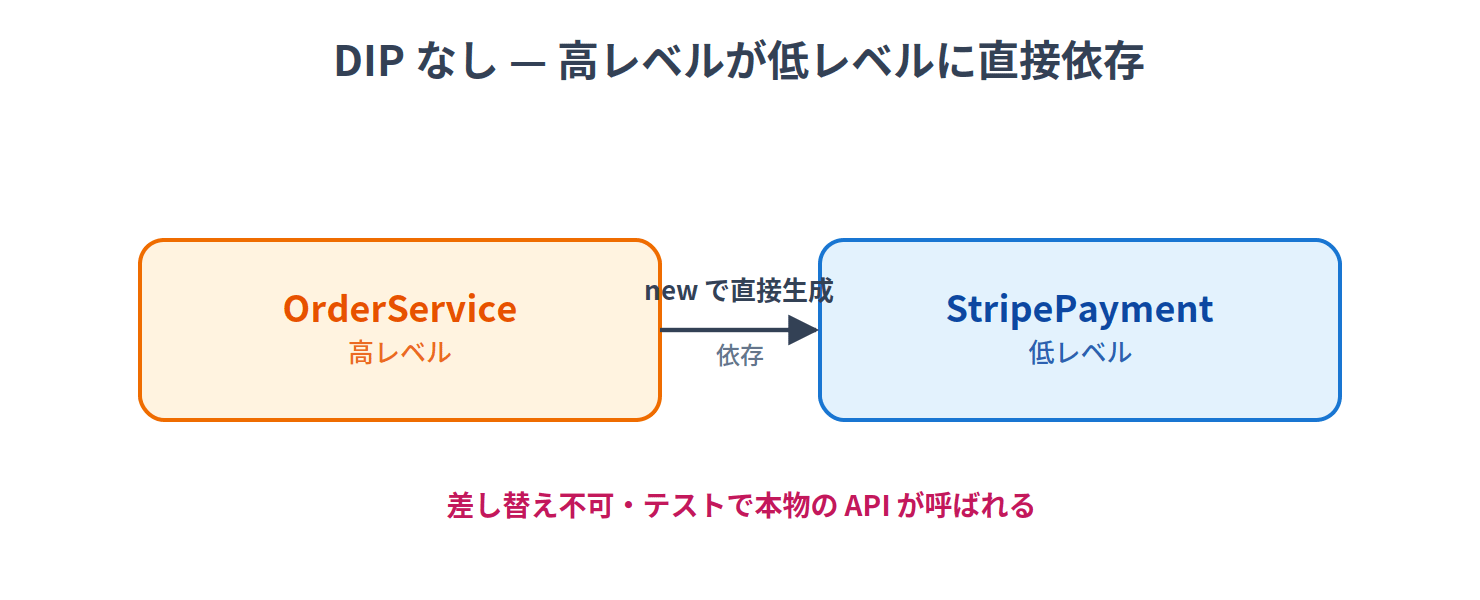
Problem: If you want to switch to PayPal, you need to modify OrderService. During testing, the real Stripe API gets called.
With DIP
// 1. Define an abstraction (interface)
interface PaymentGateway {
charge(amount: number): void
}
// 2. High-level depends on the abstraction
class OrderService {
constructor(private payment: PaymentGateway) {}
placeOrder(amount: number) {
this.payment.charge(amount)
}
}
// 3. Low-level implements the abstraction
class StripePayment implements PaymentGateway {
charge(amount: number) { /* Stripe API */ }
}
class PayPalPayment implements PaymentGateway {
charge(amount: number) { /* PayPal API */ }
}
class FakePayment implements PaymentGateway {
charge(amount: number) { /* For testing */ }
}
Direction of dependency:
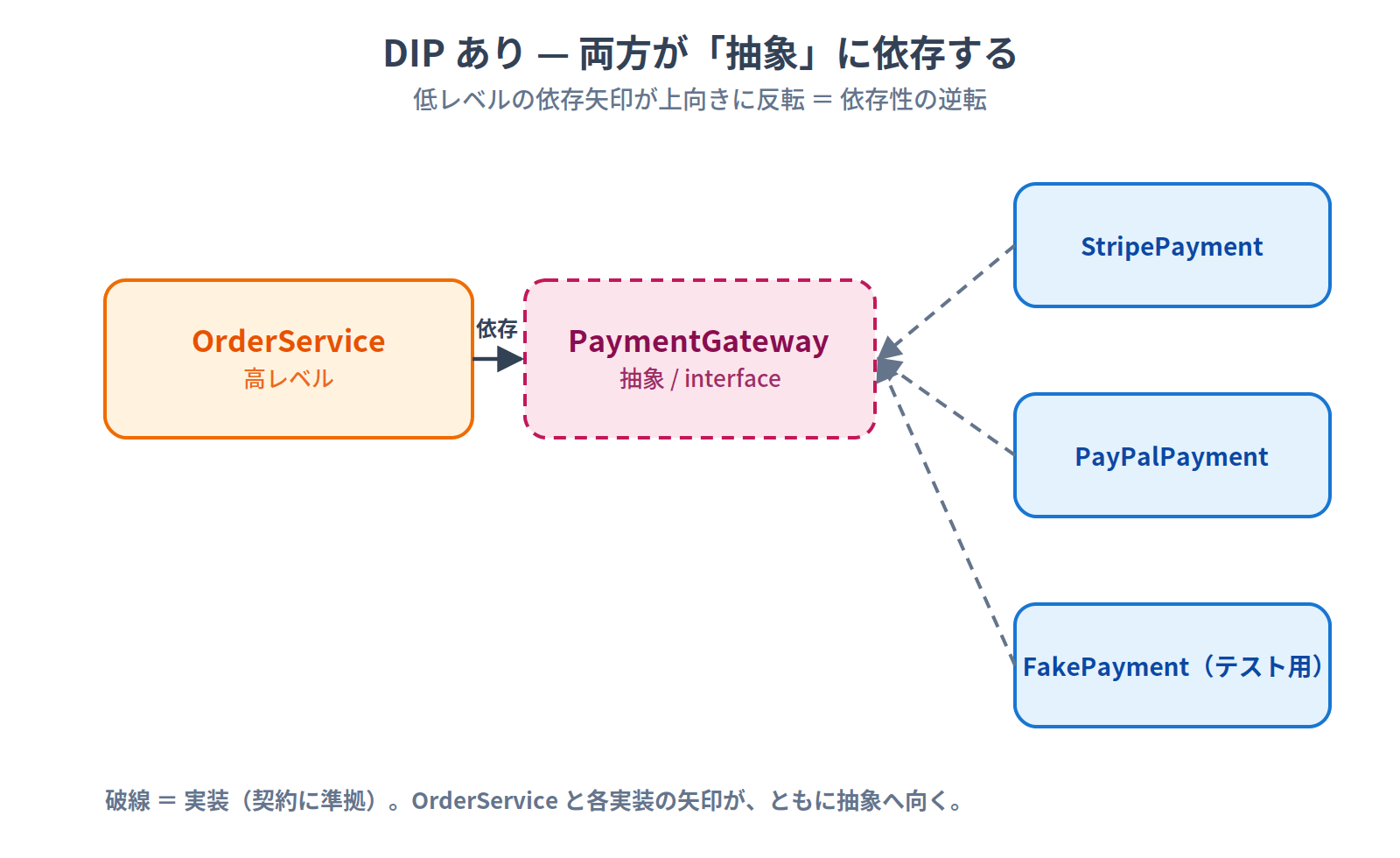
Both arrows point toward the interface. This is what "both depend on the abstraction" means.
- High-level (OrderService) calls through the interface
- Low-level (StripePayment) conforms to the interface's contract
If the interface changes, both are affected. That's why we can say "both depend on the abstraction."
What exactly gets "inverted"? Normally, dependencies flow "high-level → low-level." When DIP is applied, the dependency arrow of the low-level module flips upward toward the abstraction. This reversal of the arrow is the "Inversion."
Repository Pattern — The Data Access Version of DIP
The Repository pattern is a textbook example of applying DIP to data access.
// The domain layer defines the interface
interface UserRepository {
findById(id: string): User
save(user: User): void
}
// The infrastructure layer provides the implementation
class PostgresUserRepository implements UserRepository {
findById(id: string) { /* SQL query */ }
save(user: User) { /* INSERT/UPDATE */ }
}
// The use case only knows the interface
class CreateOrder {
constructor(private users: UserRepository) {}
execute(userId: string) {
const user = this.users.findById(userId) // Doesn't know it's Postgres
// Business logic...
}
}
Worth noting is the direction of ownership: the domain layer "owns" the interface, and the infrastructure layer "provides" the implementation.
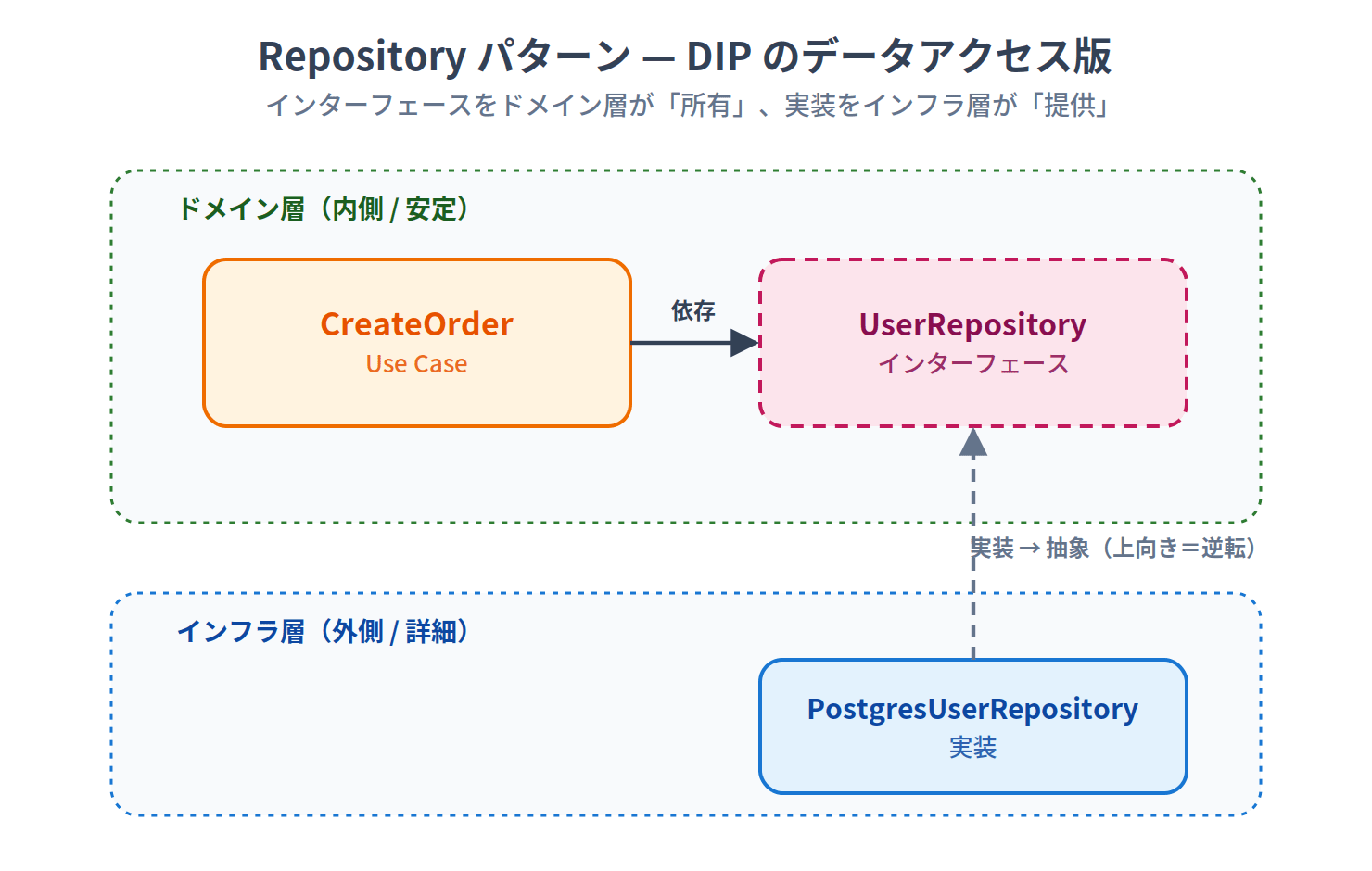
The arrow pointing upward from the implementation (PostgresUserRepository) to the interface is precisely the "inversion" of DIP.
The Relationship with ORMs — Boundaries Become Blurry with Prisma/Drizzle
An ORM (Object-Relational Mapping) is a tool that maps DB tables to objects in your code. Instead of writing SQL directly, you can operate the DB through code.
// Without ORM (raw SQL)
const result = await db.query('SELECT * FROM users WHERE id = $1', [1])
// With ORM (Prisma)
const user = await prisma.user.findUnique({ where: { id: 1 } })
A question arises here: If the ORM already abstracts the DB, doesn't adding a Repository pattern layer another abstraction on top?
// Prisma already provides a clean API
const user = await prisma.user.findUnique({ where: { id } })
// Wrapping it further with Repository... isn't that redundant?
class UserRepository {
findById(id: string) {
return prisma.user.findUnique({ where: { id } })
}
}
This is actually a point of debate in the community:
| Criteria | With Repository | Without Repository (direct ORM use) |
|---|---|---|
| Testing | Easy to mock | Requires testing with the DB |
| Data source change | Just swap the implementation | Modify every location |
| Amount of code | More (interface + implementation) | Less |
| Practical judgment | Decide based on "Is there a chance we'll change the DB?" | Most projects won't change it |
Repository Isn't Just for DBs — Browser localStorage Has the Same Structure
The Repository pattern doesn't only appear when dealing with RDBs or cloud DBs. In frontend development, the same structure arises naturally.
Consider a case where data is stored in localStorage on the browser side.
// Store layer (equivalent to Repository implementation): hides localStorage details
class ItemStore {
static load(key: string): Item[] {
const raw = localStorage.getItem(key)
return raw ? JSON.parse(raw) : []
}
static save(key: string, items: Item[]): void {
localStorage.setItem(key, JSON.stringify(items))
}
}
// Use case layer: has no knowledge of localStorage
class ItemUsecase {
static add(key: string, item: Item): void {
const current = ItemStore.load(key)
// Business rules: duplicate checks, limit management...
const updated = [item, ...current].slice(0, 50)
ItemStore.save(key, updated)
}
}
ItemStore encapsulates the details of localStorage (key names, serialization method), and ItemUsecase only knows the contract of "save" and "read." Even if you switch from localStorage to IndexedDB, the use case layer doesn't change.
The Repository pattern is not "something you put in front of a DB" — it's "something that abstracts the means of data persistence." Whether the implementation is an RDB, NoSQL, cache, localStorage, or external API, the structure is the same.
Use Case Design — The Subject Is "Humans," the Verb Is "Human Actions"
Among all the layers in Clean Architecture, Use Case layer design is where people tend to get confused most. There's an important principle here:
Use Case names should express "what a human wants to achieve." It's the same idea as agile user stories.
✅ Good Use Case names (human actions):
PlaceOrder ← "Place an order"
RegisterUser ← "Register as a user"
CancelSubscription ← "Cancel a subscription"
TransferMoney ← "Transfer money"
❌ Bad Use Case names (mechanical system processing):
InsertOrderRecord ← Describes a DB operation
UpdateUserTable ← Table names appearing is already a problem
SendHttpRequest ← Details of the communication method
ValidateAndPersist ← What validation? What is being persisted?
Use Cases Say "What and in What Order," Repositories Say "How"
A Use Case is an orchestrator of business flow. It knows what should happen and in what order it should happen, but it doesn't know how to execute it.
class PlaceOrder {
constructor(
private orders: OrderRepository,
private payments: PaymentGateway,
private notifications: NotificationService
) {}
execute(userId: string, items: CartItem[]) {
// Business rules go here
const order = Order.create(userId, items)
if (order.total() > 10000) {
throw new Error("Order limit exceeded")
}
// How to save? Don't know. Delegate to Repository
this.orders.save(order)
// How to charge? Don't know. Delegate to Gateway
this.payments.charge(order.total())
// How to notify? Don't know. Delegate to Service
this.notifications.notifyOrderPlaced(order)
}
}
Organizing the responsibilities of each layer:
| Layer | Responsibility | What it knows |
|---|---|---|
| Use Case | Business flow, business rules, orchestration | Domain entities + Repository/Service interfaces |
| Repository (interface) | Abstraction of data persistence | The "contract" for saving/retrieving entities |
| Data Layer (implementation) | Actual DB operations, API calls, caching | SQL, HTTP, Redis, file system |
Visualizing the concrete flow:
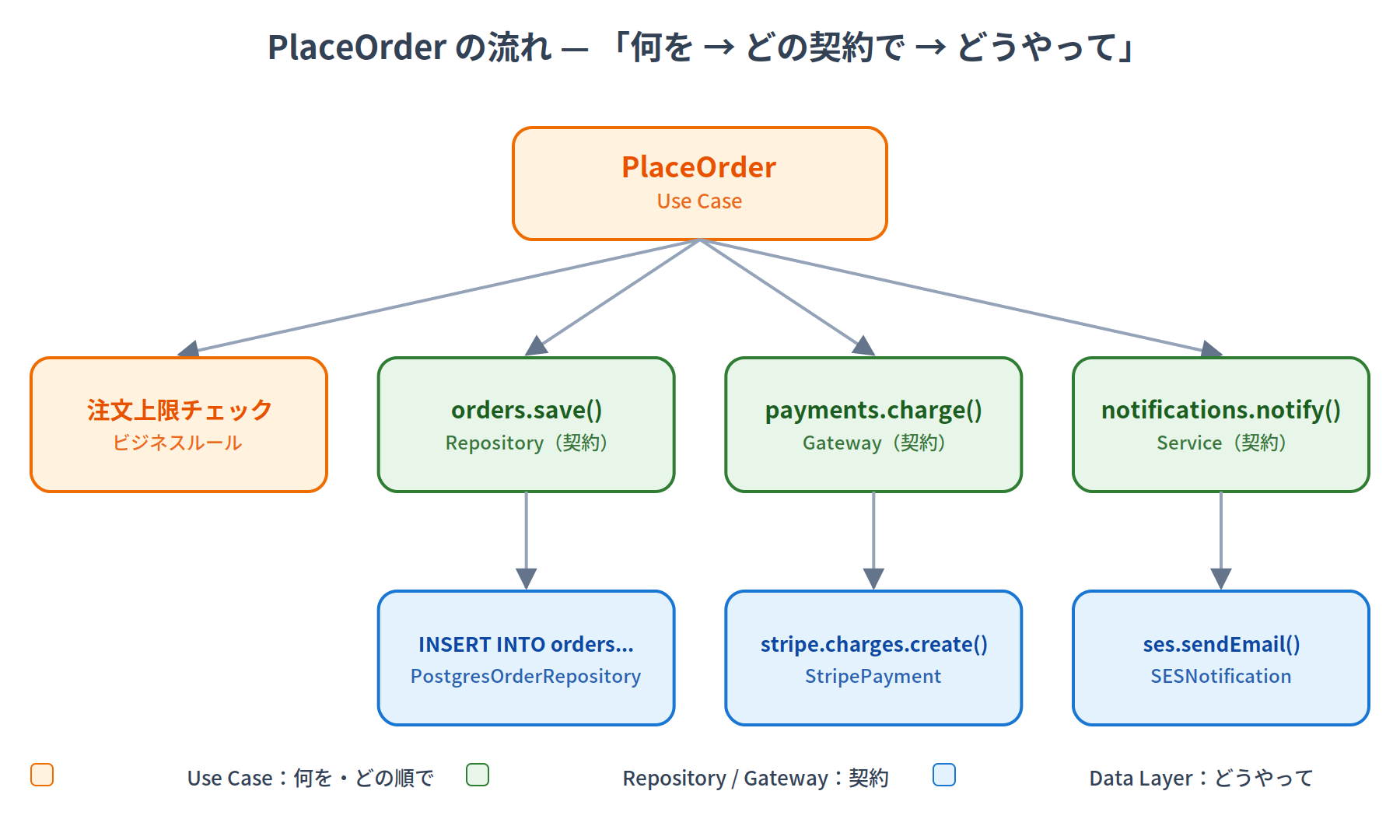
You can see the level of abstraction decreasing from left to right, top to bottom: "what (Use Case) → through which contract (Repository) → how (Data Layer)."
What Doesn't Belong in a Use Case
// ❌ Mechanical/data layer processing inside a Use Case
class PlaceOrder {
execute() {
// SQL in a Use Case — NG
await db.query('INSERT INTO orders VALUES...')
// HTTP communication details in a Use Case — NG
await fetch('https://api.stripe.com/charges', { headers: ... })
// Cache logic in a Use Case — NG
await redis.set(`order:${id}`, JSON.stringify(order))
}
}
All of these should be hidden behind Repository/Gateway interfaces. The Use Case only says save(order) — transaction management, caching, and retries are the Repository's responsibility.
Where to Put Business Rules — Distinguishing Between Entities and Use Cases
// Entity: invariants about itself
class Order {
addItem(item: CartItem) {
if (this.items.length >= 50) {
throw new Error("Maximum 50 items per order") // ← The entity's own rule
}
this.items.push(item)
}
}
// Use Case: rules spanning multiple entities, flow control
class PlaceOrder {
execute(userId: string, items: CartItem[]) {
const user = this.users.findById(userId)
if (user.isSuspended()) {
throw new Error("Account is suspended") // ← Rule spanning multiple entities
}
const order = Order.create(userId, items)
// ...
}
}
- Entity: Self-contained invariants ("maximum 50 items per order")
- Use Case: Rules spanning entities, flow control ("suspended users cannot place orders")
There Are Also System-Initiated Use Cases
Not all Use Cases are human-initiated.
ProcessExpiredSubscriptions ← Triggered by a cron job, not a human
RecalculatePricing ← Event-driven
SyncInventoryFromWarehouse ← Periodic sync
However, these also express business-level intent. The criterion is: "Would a domain expert (a business specialist) understand the name when they hear it?" If yes, it's a good Use Case name.
Method Names Tell You "Where It Belongs" — load vs list
When you separate Use Cases and Repositories, you'll notice that method names naturally differ.
// Repository (store layer): verbs expressing storage operations
class ItemStore {
static load(key: string): Item[] // Read from storage
static save(key: string, items: Item[]): void // Write to storage
}
// Use Case: verbs expressing user actions
class ItemUsecase {
static list(key: string): GroupedItems // User "views a list"
static add(key: string, item: Item): void // User "adds an item"
static remove(key: string, id: string): void // User "removes an item"
}
load is storage operation vocabulary. If load appears in a Use Case, it might be a sign that "storage details are leaking out." The verbs a Use Case uses should be closer to what the user wants to do — list, add, remove, submit.
You can use these naming discrepancies as clues to judge "which layer does this logic belong to?"
The Benefits of Building on Abstracted Interfaces
Beyond DIP and Repository, let's organize the benefits of inserting an interface.
Swap Implementations Without Touching Business Logic
// Monday: Stripe
const app = new OrderService(new StripePayment())
// Tuesday: CEO said to switch to PayPal
const app = new OrderService(new PayPalPayment())
// OrderService code is completely unchanged
Don't Use External Services in Tests
const fake = new FakePayment()
const service = new OrderService(fake)
service.placeOrder(100)
// The real Stripe isn't called. Completes in milliseconds
Parallel Team Development
Team A: Implements OrderService against the PaymentGateway interface
Team B: Implements PaymentGateway interface to create StripePayment
→ The interface is the contract. No need to wait for each other
Smaller Blast Radius
Without interface: DB library change → Fix every file that imports it
With interface: DB library change → Only fix the new implementation class
Are These Patterns Still Valid in the Age of AI-Driven Development?
Now that AI coding agents like Claude Code are widespread, has the value of these design patterns changed?
Points Where AI Works Well
| Characteristic | Benefit for AI |
|---|---|
| SRP (small files, clear responsibilities) | AI can accurately read and write focused files. God classes confuse AI too |
| Clear interfaces | If the contract is explicit, AI can generate implementations quickly |
| Separation of concerns | Even if AI changes the infrastructure layer, domain logic is less likely to break |
| Repository pattern | With interfaces, AI can swap implementations with confidence |
Points That Have Become Less Important with AI
| Concern | Change |
|---|---|
| Lots of boilerplate | Since AI generates boilerplate quickly, the drawback of "more code" has diminished |
| Strict layer separation | Since AI is also good at cross-file changes, the lack of strict separation doesn't cause as much trouble |
What Really Matters in AI Coding
- Readable, consistent code — AI performs best with predictable patterns
- Small files, clear boundaries — Works well with AI's context window
- Good naming — AI infers intent from names.
UserRepository.findByIdis far easier to work with thandb.query("SELECT...") - Tests — AI can verify its own changes. Tests also function as specifications
What I've Noticed When Actually Coding with AI
When developing with Claude Code, I've come to feel that AI "knows" the layer structure but "doesn't necessarily follow it."
For example, if you instruct it to "add data persistence logic to the use case," the AI will dutifully comply and directly write localStorage operations inside the Use Case. AI generates "code that works efficiently" from context, but it doesn't spontaneously consider "is this code in the right layer?"
This is where code review does its job. A human reviewer pointing out "the use case is doing repository-level processing" lets you catch layer violations in AI-generated code. This experience was what prompted me to organize my thoughts on Clean Architecture again.
Also, as a practical DIP application in AI-driven development, layer separation without interfaces is a viable middle ground.
// Formal DIP: interface + implementation class (orthodox approach)
interface ItemRepository { load(): Item[]; save(items: Item[]): void }
class LocalStorageItemRepository implements ItemRepository { ... }
// Practical separation: separate layers with static classes (no interface)
class ItemStore { static load(): Item[] { ... }; static save(): void { ... } }
class ItemUsecase { static list(): Item[] { return ItemStore.load() } }
The latter is not strict DIP, but the essence of separating business logic from data access is preserved. For cases with light testing and extensibility requirements — such as frontend local state management — this level of granularity is often sufficient.
Since AI generates boilerplate quickly, the drawback of "writing interfaces is tedious" is largely eliminated. Whether to adopt formal DIP is best decided based on the project's testing strategy and extensibility requirements.
Summary
| Concept | In a nutshell |
|---|---|
| Clean Architecture | Layered structure. Outer → inner dependencies. Protects business logic |
| SOLID | 5 design principles. Guidelines for maintainability, flexibility, and testability |
| DIP | A mechanism that depends on abstractions and inverts the direction of dependency |
| Repository | A representative example of applying DIP to data access |
| ORM | Abstraction of DB operations. Double abstraction with Repository requires judgment |
These patterns remain valid in AI-driven development in 2026. However, the principle that you should adjust the level of application based on the complexity of the project doesn't change.
Simple CRUD API → Flat structure, Repository pattern not needed
Medium-sized app → Service layer + Repository, light separation
Complex domain → Clean Architecture + DDD delivers its value
Just because it's the AI era doesn't mean you need to adopt Clean Architecture, nor do you need to abandon it. AI tools amplify the structure you've chosen — clean code becomes cleaner, messy code gets messy faster.