
Clean Architecture・SOLID・DIPを改めて整理してみた — AI駆動開発の時代にまだ使えるのか?
はじめに
「Clean Architectureって結局なに?」「SOLIDのDって何の略だっけ?」——こういう疑問、ありませんか?
設計パターンの名前は知っているけれど、実際にどう関係しているのか、そしてClaude Codeのようなコーディングエージェントが当たり前になった今の時代に、これらのパターンはまだ有効なのか。そんな疑問をきっかけに、改めて整理してみました。
コードレビューで「ユースケースがリポジトリ相当の処理をしている」と指摘されたことが、改めて整理するきっかけでした。自分では「ユースケース層」のつもりで書いていたコードが、実はデータ永続化ロジックをそのまま含んでいたのです。
Clean Architectureとは何か
Robert C. Martin(Uncle Bob)が2012年のブログ記事「The Clean Architecture」で提唱した、依存性のルールを中心とした設計パターンです(書籍化は2017年)。ヘキサゴナルアーキテクチャ(Ports & Adapters)やオニオンアーキテクチャといった先行する考え方を統合したものでもあります。
核となるルールはシンプル:外側のレイヤーが内側のレイヤーに依存する。逆は許されない。
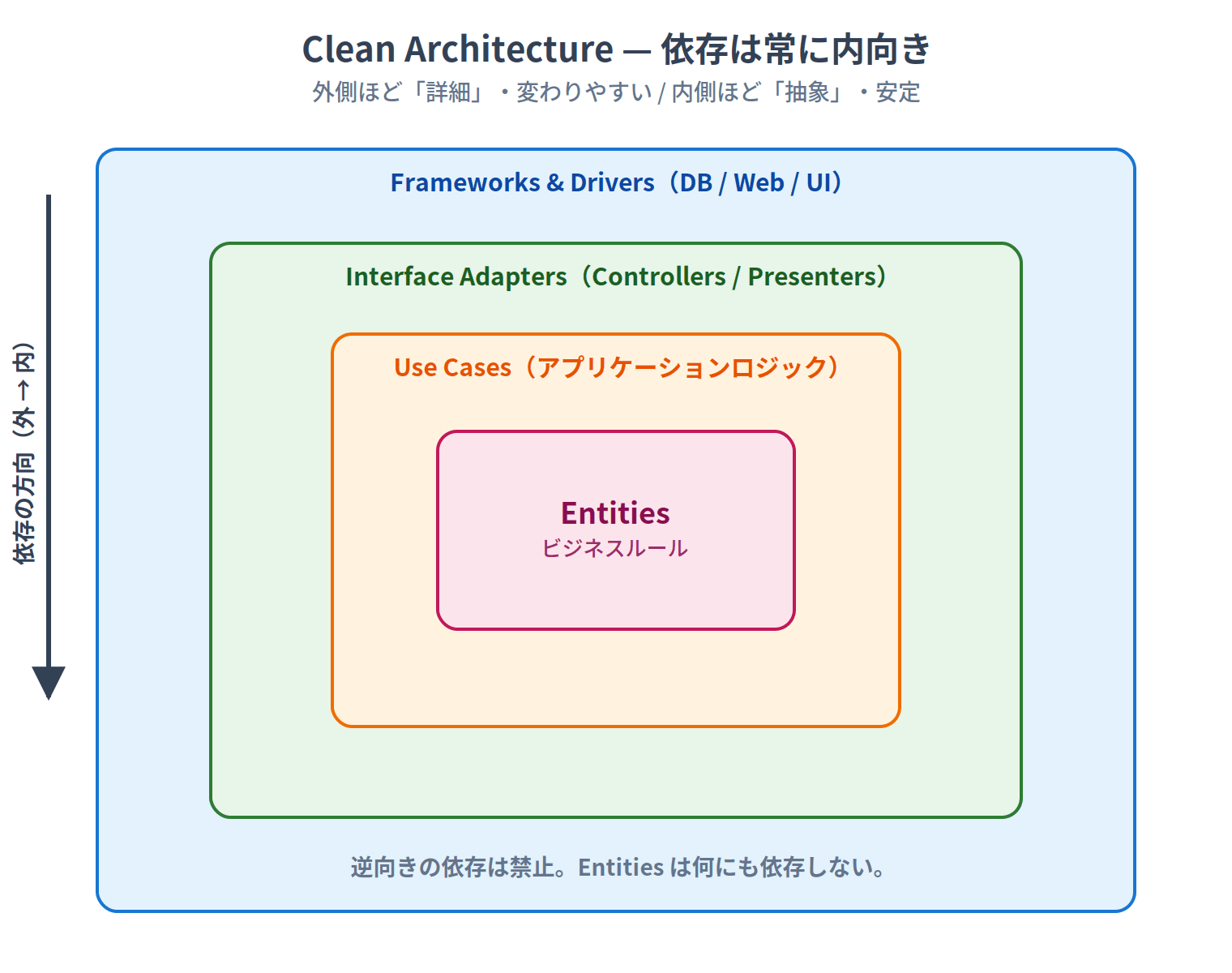
レイヤーは入れ子(包含関係)になっており、依存の矢印はすべて内側を向きます。外側ほど「詳細」で変わりやすく、内側ほど「抽象」で安定しています。Entitiesは何にも依存せず、最も安定しています。
4つのレイヤーを内側から順に見ていくと:
| レイヤー | 役割 | 例 |
|---|---|---|
| Entities | コアなビジネスルール。依存なし | User, Order |
| Use Cases | アプリケーション固有のロジック | CreateUser, PlaceOrder |
| Interface Adapters | データ形式の変換 | Controllers, Presenters, Repository実装 |
| Frameworks & Drivers | DB・Webフレームワーク・UI | PostgreSQL, Express, React |
最も重要なポイントは、ビジネスロジックがDBやフレームワークの存在を知らないということです。Expressを使っていてもFastifyに変えても、PostgreSQLからMongoDBに乗り換えても、ドメイン層には手を加えなくて済みます。
SOLID原則 — 5つの設計原則
Clean Architectureの背景にある設計思想がSOLID原則です。こちらもRobert C. Martinが整理したものです。
S — Single Responsibility Principle(単一責任の原則)
1つのクラス(モジュール)は、変更の理由が1つだけであるべき。
// NG: UserServiceが認証もメール送信もDB永続化も担当
class UserService {
authenticate() { ... }
sendEmail() { ... }
saveToDb() { ... }
}
// OK: 責務ごとに分離
class AuthService { authenticate() { ... } }
class EmailService { sendEmail() { ... } }
class UserRepository { save() { ... } }
O — Open/Closed Principle(開放閉鎖の原則)
拡張に対して開いていて、修正に対して閉じている。
// NG: フォーマット追加のたびにif文を修正
if (type === "pdf") { ... }
else if (type === "csv") { ... }
// OK: 新しいクラスを追加するだけ
interface Exporter { export(data: Data): void }
class PdfExporter implements Exporter { ... }
class CsvExporter implements Exporter { ... } // 追加するだけ
L — Liskov Substitution Principle(リスコフの置換原則)
サブタイプは、基底型の契約を破らずに置換可能であるべき。
// NG: Penguinはflyの契約を破る(Birdとして置換できない)
class Bird { fly(): void { ... } }
class Penguin extends Bird {
fly() { throw new Error("ペンギンは飛べない") } // 契約違反
}
// OK: 飛べるかどうかで抽象を分ける
interface Bird { eat(): void }
interface FlyingBird extends Bird { fly(): void }
class Sparrow implements FlyingBird { ... }
class Penguin implements Bird { ... } // flyを持たないので置換問題が起きない
I — Interface Segregation Principle(インターフェース分離の原則)
クライアントが使わないメソッドへの依存を強制しない。大きなインターフェースより、小さなインターフェースを複数に分ける。
// NG: 1つの巨大インターフェース。印刷専用機もscan/faxの実装を強制される
interface Machine { print(): void; scan(): void; fax(): void }
// OK: 役割ごとに分離。必要なものだけ実装すればよい
interface Printer { print(): void }
interface Scanner { scan(): void }
class SimplePrinter implements Printer { print() { ... } }
D — Dependency Inversion Principle(依存性逆転の原則)
ここが今回の話の核心です。次のセクションで詳しく見ていきます。
DIP — 「依存性の逆転」とは何が逆転するのか
DIPのルールは2つ:
- 高レベルモジュールは低レベルモジュールに依存すべきでない。 どちらも抽象に依存すべき
- 抽象は詳細に依存すべきでない。 詳細が抽象に依存すべき
言葉だけだと分かりにくいので、具体例で見てみます。
DIPなし
class StripePayment {
charge(amount: number) { /* Stripe API呼び出し */ }
}
class OrderService {
private payment = new StripePayment() // ← 直接依存
placeOrder(amount: number) {
this.payment.charge(amount)
}
}
依存の方向:
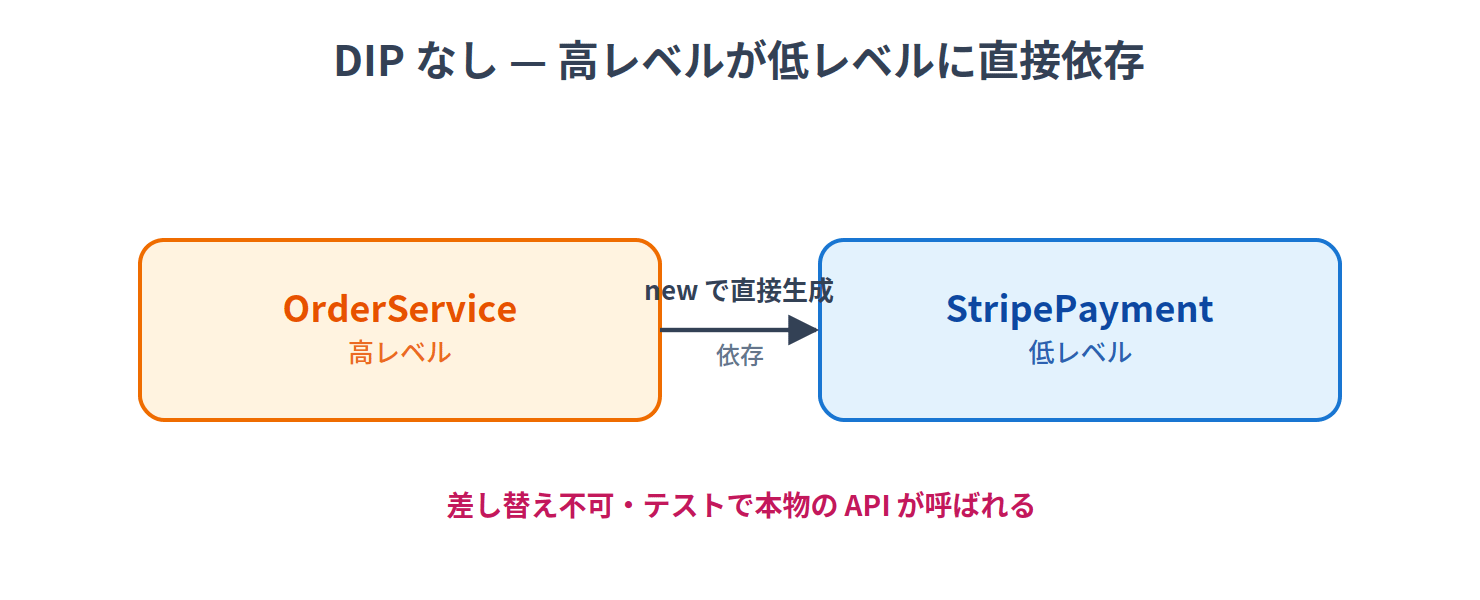
問題:PayPalに切り替えたい場合、OrderServiceを修正する必要があります。テスト時に本物のStripe APIが呼ばれてしまいます。
DIPあり
// 1. 抽象(インターフェース)を定義
interface PaymentGateway {
charge(amount: number): void
}
// 2. 高レベルは抽象に依存
class OrderService {
constructor(private payment: PaymentGateway) {}
placeOrder(amount: number) {
this.payment.charge(amount)
}
}
// 3. 低レベルが抽象を実装
class StripePayment implements PaymentGateway {
charge(amount: number) { /* Stripe API */ }
}
class PayPalPayment implements PaymentGateway {
charge(amount: number) { /* PayPal API */ }
}
class FakePayment implements PaymentGateway {
charge(amount: number) { /* テスト用 */ }
}
依存の方向:
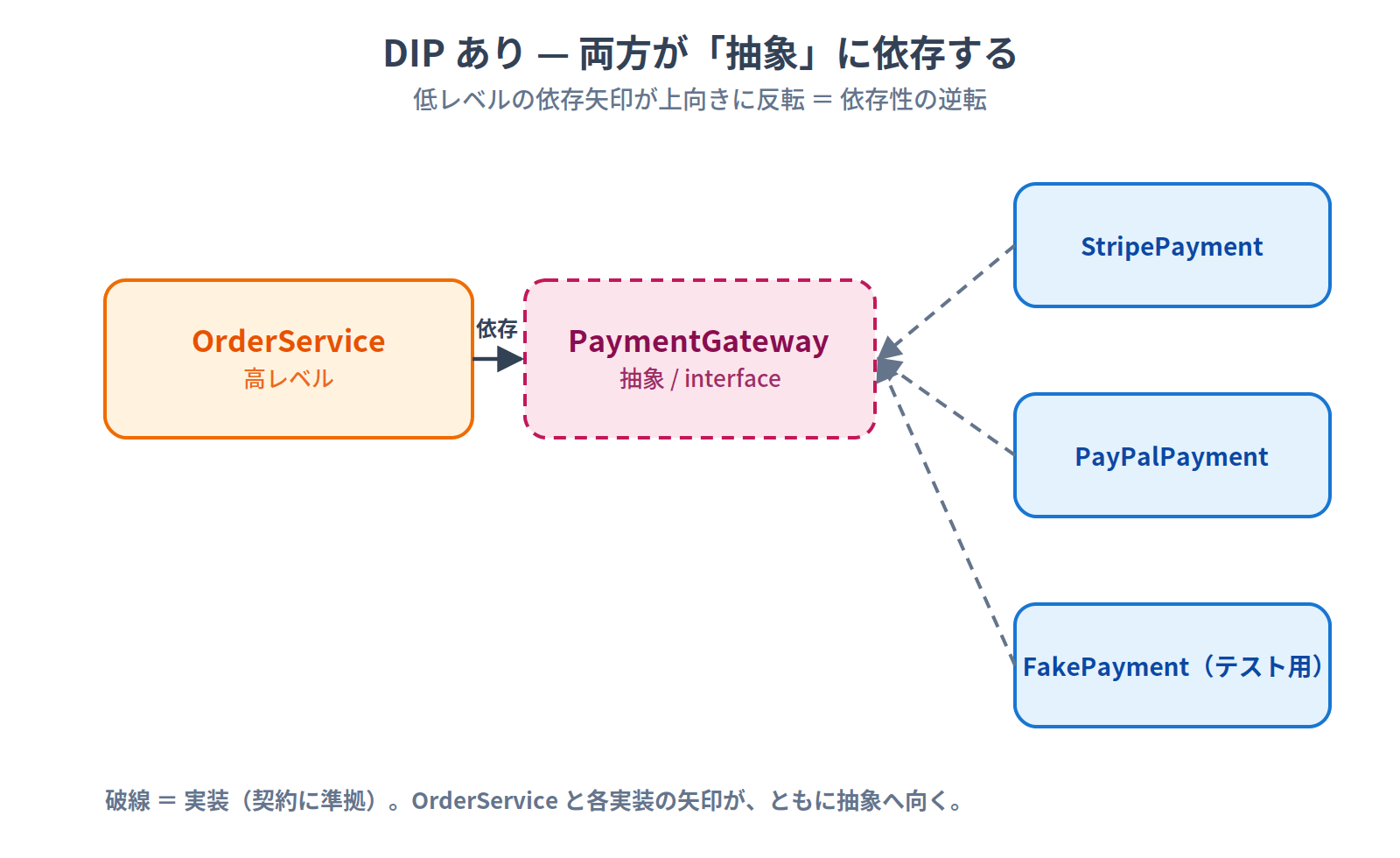
両方の矢印がインターフェースに向いています。 これが「両方が抽象に依存する」という意味です。
- 高レベル(OrderService)はインターフェースを経由して呼び出す
- 低レベル(StripePayment)はインターフェースの契約に準拠する
インターフェースが変われば、どちらも影響を受ける。だから「両方が抽象に依存する」と言えるのです。
何が「逆転」しているのか? 通常、依存は「高レベル → 低レベル」に流れます。DIPを適用すると、低レベルモジュールの依存の矢印が上向きに反転し、抽象に向かいます。この矢印の反転が「逆転(Inversion)」です。
Repositoryパターン — DIPのデータアクセス版
Repositoryパターンは、DIPをデータアクセスに適用した教科書的な例です。
// ドメイン層がインターフェースを定義
interface UserRepository {
findById(id: string): User
save(user: User): void
}
// インフラ層が実装を提供
class PostgresUserRepository implements UserRepository {
findById(id: string) { /* SQLクエリ */ }
save(user: User) { /* INSERT/UPDATE */ }
}
// ユースケースはインターフェースだけを知っている
class CreateOrder {
constructor(private users: UserRepository) {}
execute(userId: string) {
const user = this.users.findById(userId) // Postgresかどうか知らない
// ビジネスロジック...
}
}
注目すべきは、インターフェースをドメイン層が「所有」し、実装をインフラ層が「提供」するという所有権の向きです。
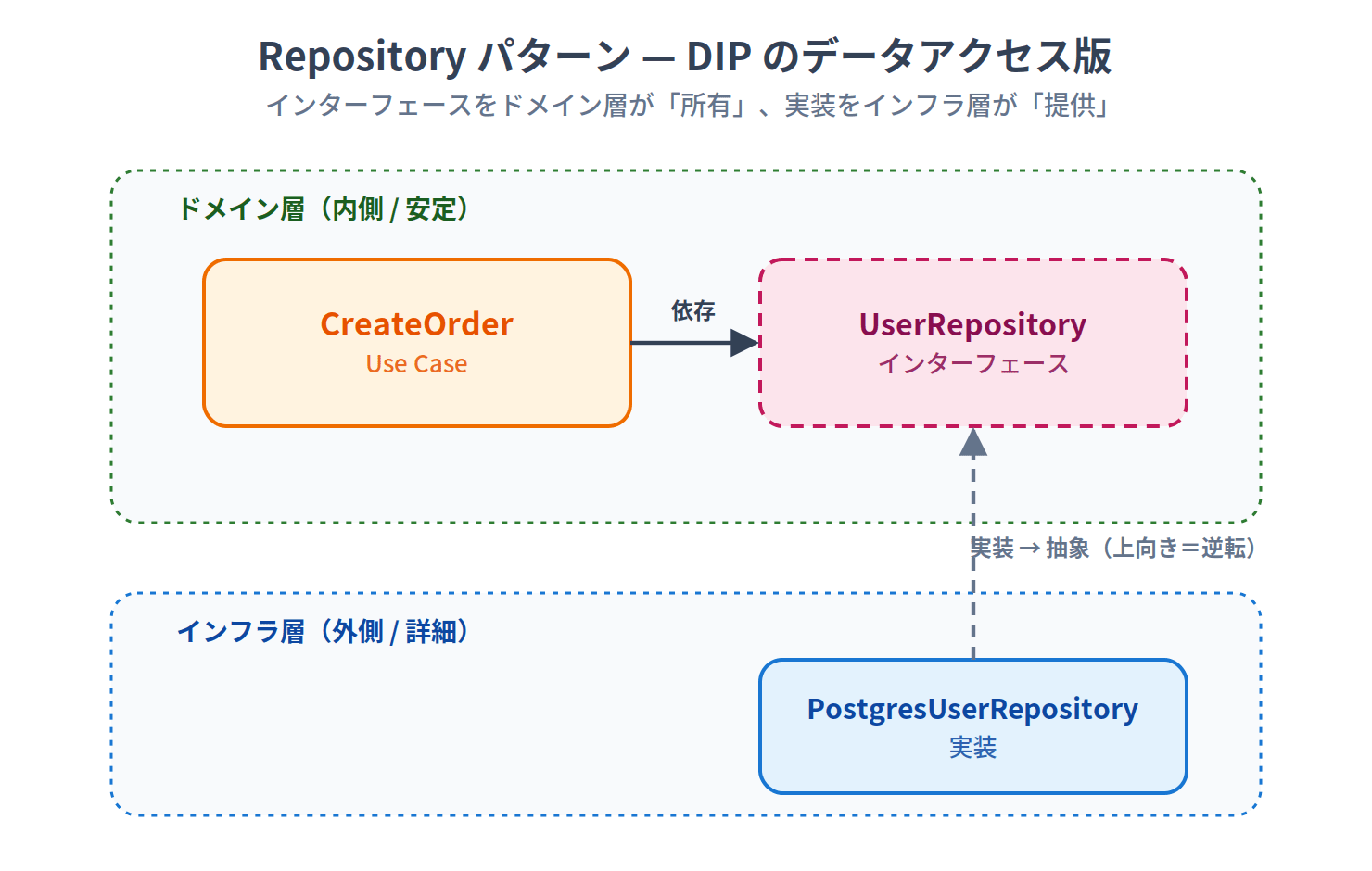
実装(PostgresUserRepository)からインターフェースへ矢印が上向きに伸びている点が、まさにDIPの「逆転」です。
ORMとの関係 — Prisma/Drizzleで境界が曖昧に
ORM(Object-Relational Mapping)は、DBテーブルとコードのオブジェクトをマッピングするツールです。SQLを直接書く代わりに、コードでDBを操作できます。
// ORMなし(生SQL)
const result = await db.query('SELECT * FROM users WHERE id = $1', [1])
// ORMあり(Prisma)
const user = await prisma.user.findUnique({ where: { id: 1 } })
ここで疑問が出てきます:ORMがすでにDBを抽象化しているなら、Repositoryパターンはさらにその上に抽象を重ねることになるのでは?
// PrismaがすでにきれいなAPIを提供している
const user = await prisma.user.findUnique({ where: { id } })
// Repositoryでさらにラップ... 冗長では?
class UserRepository {
findById(id: string) {
return prisma.user.findUnique({ where: { id } })
}
}
これは実際にコミュニティでも議論が分かれるポイントです:
| 判断基準 | Repositoryあり | Repositoryなし(ORM直接利用) |
|---|---|---|
| テスト | モックが簡単 | DBごとテストが必要 |
| データソース変更 | 実装差し替えだけ | 全箇所修正 |
| コード量 | 多い(インターフェース + 実装) | 少ない |
| 現実的な判断 | 「DBを変える可能性があるか?」で判断 | 多くのプロジェクトでは変えない |
DBだけがRepositoryではない — ブラウザのlocalStorageも同じ構造になる
Repositoryパターンが登場するのはRDBやクラウドDBのときだけではありません。フロントエンド開発でも同じ構造が自然に現れます。
たとえばブラウザ側でデータをlocalStorageに保持する場合を考えてみます。
// ストア層(Repositoryの実装に相当): localStorageの詳細を隠す
class ItemStore {
static load(key: string): Item[] {
const raw = localStorage.getItem(key)
return raw ? JSON.parse(raw) : []
}
static save(key: string, items: Item[]): void {
localStorage.setItem(key, JSON.stringify(items))
}
}
// ユースケース層: localStorageの存在を知らない
class ItemUsecase {
static add(key: string, item: Item): void {
const current = ItemStore.load(key)
// ビジネスルール: 重複チェック、上限管理...
const updated = [item, ...current].slice(0, 50)
ItemStore.save(key, updated)
}
}
ItemStoreがlocalStorageの詳細(キー名、シリアライズ方法)を封じ込め、ItemUsecaseは「保存する」「読む」という契約だけを知っています。localStorageをIndexedDBに変えるとしても、ユースケース層は変わりません。
Repositoryパターンは「DBの前に置くもの」ではなく、「データの永続化手段を抽象化するもの」です。RDB、NoSQL、キャッシュ、localStorage、外部API——どれが実装でも構造は同じです。
Use Caseの設計 — 主語は「人間」、動詞は「人間のアクション」
Clean Architectureの各レイヤーの中で、Use Case層の設計が最も迷いやすいポイントです。ここで重要な原則があります:
Use Caseの名前は「人間が何を達成したいか」を表すべき。 アジャイルのユーザーストーリーと同じ発想です。
✅ 良いUse Case名(人間のアクション):
PlaceOrder ← 「注文する」
RegisterUser ← 「ユーザー登録する」
CancelSubscription ← 「サブスクを解約する」
TransferMoney ← 「送金する」
❌ 悪いUse Case名(システムの機械的処理):
InsertOrderRecord ← DBの操作を表している
UpdateUserTable ← テーブル名が出てくる時点でNG
SendHttpRequest ← 通信手段の詳細
ValidateAndPersist ← 何のバリデーション?何を永続化?
Use Caseは「何を・どの順で」、Repositoryは「どうやって」
Use Caseはビジネスフローのオーケストレーターです。何が起きるべきかとどの順序で起きるかを知っていますが、どうやって実行するかは知りません。
class PlaceOrder {
constructor(
private orders: OrderRepository,
private payments: PaymentGateway,
private notifications: NotificationService
) {}
execute(userId: string, items: CartItem[]) {
// ビジネスルールはここに書く
const order = Order.create(userId, items)
if (order.total() > 10000) {
throw new Error("注文上限を超えています")
}
// どうやって保存する? 知らない。Repositoryに任せる
this.orders.save(order)
// どうやって決済する? 知らない。Gatewayに任せる
this.payments.charge(order.total())
// どうやって通知する? 知らない。Serviceに任せる
this.notifications.notifyOrderPlaced(order)
}
}
各レイヤーの責務を整理すると:
| レイヤー | 責務 | 知っていること |
|---|---|---|
| Use Case | ビジネスフロー、ビジネスルール、オーケストレーション | ドメインエンティティ + Repository/Serviceのインターフェース |
| Repository(インターフェース) | データ永続化の抽象 | エンティティの保存・取得方法の「契約」 |
| Data Layer(実装) | 実際のDB操作、API呼び出し、キャッシュ | SQL, HTTP, Redis, ファイルシステム |
具体的な流れを図にすると:
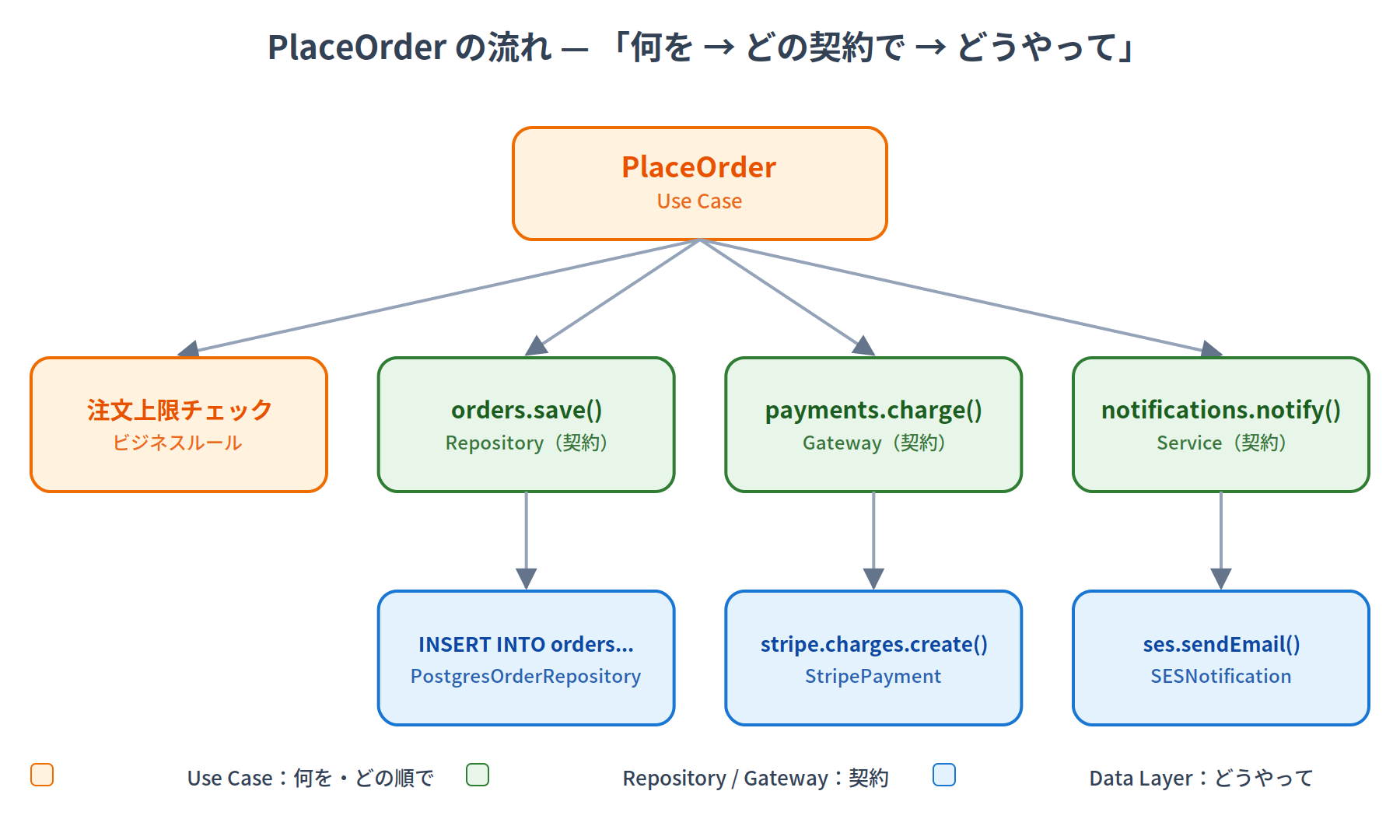
左から右、上から下へ「何を(Use Case)→ どの契約で(Repository)→ どうやって(Data Layer)」と抽象度が下がっていくのが分かります。
Use Caseに書いてはいけないもの
// ❌ Use Caseに機械的・データ層の処理が入っている
class PlaceOrder {
execute() {
// SQLがUse Caseに — NG
await db.query('INSERT INTO orders VALUES...')
// HTTP通信の詳細がUse Caseに — NG
await fetch('https://api.stripe.com/charges', { headers: ... })
// キャッシュロジックがUse Caseに — NG
await redis.set(`order:${id}`, JSON.stringify(order))
}
}
これらはすべてRepository/Gatewayのインターフェースの裏側に隠すべきです。Use Caseはsave(order)と言うだけ——トランザクション管理、キャッシュ、リトライはRepositoryの責務です。
ビジネスルールの置き場所 — EntityとUse Caseの使い分け
// Entity: 自分自身に関する不変条件
class Order {
addItem(item: CartItem) {
if (this.items.length >= 50) {
throw new Error("1注文50品まで") // ← Entity自身のルール
}
this.items.push(item)
}
}
// Use Case: エンティティ横断のルール、フロー制御
class PlaceOrder {
execute(userId: string, items: CartItem[]) {
const user = this.users.findById(userId)
if (user.isSuspended()) {
throw new Error("停止中のアカウント") // ← 複数エンティティにまたがるルール
}
const order = Order.create(userId, items)
// ...
}
}
- Entity: 自己完結した不変条件(「注文は50品まで」)
- Use Case: エンティティ横断のルール、フロー制御(「停止中のユーザーは注文できない」)
システム起点のUse Caseもある
すべてのUse Caseが人間起点とは限りません。
ProcessExpiredSubscriptions ← cronジョブが起動、人間ではない
RecalculatePricing ← イベント駆動
SyncInventoryFromWarehouse ← 定期連携
ただし、これらもビジネスレベルの意図を表しています。判断基準は「ドメインエキスパート(業務の専門家)がその名前を聞いて理解できるか?」です。理解できるなら、良いUse Case名です。
メソッド名で「どこに書くべきか」がわかる — load vs list
Use CaseとRepositoryを分けていると、メソッド名が自然に変わることに気づきます。
// Repository(ストア層): ストレージ操作を表す動詞
class ItemStore {
static load(key: string): Item[] // ストレージから読み込む
static save(key: string, items: Item[]): void // ストレージに書き込む
}
// Use Case: ユーザーのアクションを表す動詞
class ItemUsecase {
static list(key: string): GroupedItems // ユーザーが「一覧を見る」
static add(key: string, item: Item): void // ユーザーが「追加する」
static remove(key: string, id: string): void // ユーザーが「削除する」
}
load はストレージ操作の語彙です。Use Caseにloadが出てきたら、「ストレージの詳細が漏れている」サインかもしれません。Use Caseが使う動詞は、ユーザーがやりたいことに近い言葉——list、add、remove、submit——であるべきです。
このような命名のずれを手がかりに、「このロジックはどのレイヤーに属するか?」を判断できます。
抽象化されたインターフェースの上に構築するメリット
DIPやRepositoryに限らず、インターフェースを挟むことで得られるメリットを整理します。
実装を差し替えてもビジネスロジックに触らない
// 月曜: Stripe
const app = new OrderService(new StripePayment())
// 火曜: CEOがPayPalに変更と言った
const app = new OrderService(new PayPalPayment())
// OrderServiceのコードは一切変更なし
テストで外部サービスを使わない
const fake = new FakePayment()
const service = new OrderService(fake)
service.placeOrder(100)
// 本物のStripeは呼ばれない。ミリ秒で完了
チーム並行開発
チームA: PaymentGatewayインターフェースに対してOrderServiceを実装
チームB: PaymentGatewayインターフェースを実装してStripePaymentを作成
→ インターフェースが契約。お互いを待つ必要がない
影響範囲が小さい
インターフェースなし: DBライブラリ変更 → importしている全ファイルを修正
インターフェースあり: DBライブラリ変更 → 新しい実装クラスだけ修正
AI駆動開発の時代に、これらのパターンはまだ有効か?
Claude CodeのようなAIコーディングエージェントが普及した今、これらの設計パターンの価値は変わったのでしょうか。
AIと相性が良い点
| 特性 | AIにとっての利点 |
|---|---|
| SRP(小さなファイル・明確な責務) | AIはフォーカスされたファイルを正確に読み書きできる。巨大なGodクラスはAIも混乱する |
| 明確なインターフェース | 契約が明示されていれば、AIは実装を高速に生成できる |
| 関心の分離 | AIがインフラ層を変更しても、ドメインロジックが壊れにくい |
| Repositoryパターン | インターフェースがあれば、AIは自信を持って実装を差し替えられる |
AIで重要度が下がった点
| 懸念 | 変化 |
|---|---|
| ボイラープレートが多い | AIがボイラープレートを高速に生成するため、「コード量が増える」というデメリットが薄れた |
| 厳密なレイヤー分離 | AIはファイル横断の変更も得意なため、厳密な分離がなくても大きな問題にならない |
AIコーディングで本当に重要なこと
- 読みやすく一貫性のあるコード — AIは予測可能なパターンで最も高い精度を発揮する
- 小さなファイル、明確な境界 — AIのコンテキストウィンドウと相性が良い
- 良い命名 — AIは名前から意図を推測する。
UserRepository.findByIdはdb.query("SELECT...")より遥かに扱いやすい - テスト — AIが自分の変更を検証できる。テストは仕様書としても機能する
実際にAIコーディングで気づいたこと
Claude Codeを使って開発していると、AIはレイヤー構造を「知ってはいる」が「守るとは限らない」と感じます。
たとえば「ユースケースにデータ永続化のロジックを追加して」と指示すると、AIはそれに素直に従い、Use Caseの中にlocalStorage操作を直接書いてしまうことがあります。AIは文脈から「効率的に動くコード」を生成しますが、「このコードが正しいレイヤーにあるか」を自発的に考えるわけではありません。
ここでコードレビューが機能します。 人間のレビュアーが「Use Caseがリポジトリ相当の処理をしている」と指摘してくれることで、AIが生成したコードのレイヤー違反を発見できます。この経験が、改めてClean Architectureを整理するきっかけになりました。
また、AI駆動開発での現実的なDIP適用として、インターフェースを省略したレイヤー分離という落とし所もあります。
// フォーマルなDIP: インターフェース + 実装クラス(正統派)
interface ItemRepository { load(): Item[]; save(items: Item[]): void }
class LocalStorageItemRepository implements ItemRepository { ... }
// 実用的な分離: 静的クラスでレイヤーを分ける(インターフェースなし)
class ItemStore { static load(): Item[] { ... }; static save(): void { ... } }
class ItemUsecase { static list(): Item[] { return ItemStore.load() } }
後者は厳密なDIPではありませんが、ビジネスロジックとデータアクセスの分離という本質は保たれています。フロントエンドのローカル状態管理など、テスト要件や拡張要件が軽いケースでは、このくらいの粒度で十分なことが多いです。
AIはボイラープレートを高速に生成してくれるので、「インターフェースを書くのが面倒」というデメリットはほぼ解消されています。フォーマルなDIPを採用するかは、プロジェクトのテスト戦略と拡張性要件で判断するとよいでしょう。
まとめ
| 概念 | 一言で言うと |
|---|---|
| Clean Architecture | レイヤー構造。外→内に依存。ビジネスロジックを保護する |
| SOLID | 5つの設計原則。保守性・柔軟性・テスト容易性のための指針 |
| DIP | 抽象に依存し、依存の方向を逆転させるメカニズム |
| Repository | DIPをデータアクセスに適用した代表例 |
| ORM | DB操作の抽象化。Repositoryとの二重抽象は要判断 |
これらのパターンは2026年のAI駆動開発でも有効です。ただし、プロジェクトの複雑さに応じて適用レベルを調整すべきという原則は変わりません。
シンプルなCRUD API → フラット構造、Repositoryパターン不要
中規模アプリ → サービス層 + Repository、軽い分離
複雑なドメイン → Clean Architecture + DDDが効果を発揮
AI時代だからといってClean Architectureを採用する必要もなければ、捨てる必要もありません。AIツールは選んだ構造を増幅します——きれいなコードはよりきれいに、雑なコードはより速く散らかります。









