
I tried building an LLM usage-based switching environment with NVIDIA LLM Router (Basics Edition)
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
Model usage fees have been rising sharply over the past few months... Claude Opus 4.8 output is $25 per 1M tokens, and GPT-5.5 and Gemini 3.1 Pro have lined up in the same price range. For personal use, it's manageable within a Claude Code or Codex subscription, but when scaling across an organization, "all Opus" starts putting serious pressure on the monthly budget.
Many of you may be feeling the nagging sense that "light queries are still hitting Opus, but I'm also scared to throw hard problems at a smaller model."
That's where LLM Router comes in—a mechanism that automatically switches models based on the content of a question. There's functionality like OpenRouter's Auto Router, but this time I tried running NVIDIA LLM Router v3, which you can build yourself, on a DGX Spark. The scope of this article covers not just cloud models via API, but also routing that mixes in local LLMs running on the DGX Spark into the same pool.
Background: Why Mixing Models Has Become a Realistic Conversation
For light personal use, you can squeeze it into a subscription for a few thousand yen. But once you start using Claude Code or Codex regularly for work, that stops being the case. With just 1 user making 300 requests per day at an average output of 1,500 tokens, that's 6,600 requests per month—coming in just under $250/month for all Opus 4.8. That's right around where you'd exceed the Claude Code Max ($200/month) ceiling.
Scale that up to a team of 5 where each person is running agents continuously, and it jumps another order of magnitude. Here's a rough estimate assuming 5 people × 33,000 requests/month × average output 1,500 tokens (165,000 requests/month total).
| Configuration | Unit Price | Monthly Estimate |
|---|---|---|
| All Opus 4.8 | output $25 / 1M | ~$6,200 |
| All Sonnet 4.6 | output $15 / 1M | ~$3,700 |
| Opus 30% / Sonnet 50% / Haiku 20% mix | weighted avg $16 / 1M | ~$4,000 |
The numbers use the output unit prices for the current generation Claude Opus 4.8 / Sonnet 4.6 / Haiku 4.5 as of 2026 (the v3 default pool includes Opus 4.6, but since the price range and behavior are close enough, the monthly estimates use the latest generation pricing).
Looking at the numbers alone, it's tempting to say "Sonnet is enough," but these are based on average token counts—in practice, hard questions tend to produce longer outputs, pushing up the Opus ratio and making it a bit more expensive. Conversely, for light questions, output is much shorter and Haiku would likely suffice in many cases. There's room for another tier of differentiation between "all Opus" and "all Sonnet."
When translating this kind of differentiation into implementation at the organizational level, the three things I personally care about are: cost predictability—wanting the monthly budget to be readable; auditability—wanting all routing decisions and their rationale plus actual call logs preserved; and data sovereignty—wanting a clear boundary where queries containing sensitive information go on-premises and everything else goes to the cloud.
Once you scale to an organization, these concerns hit all at once. That's what this article is really about.
Surveying the Router Options
When you first think "I need a router," OpenRouter is usually the first candidate that comes to mind. Just specify the model slug openrouter/auto and a NotDiamond-based router looks at the prompt and picks a model. Recently, separate router families like Fusion Router and Pareto Router have been added, expanding the options.
Here's a comparison with NVIDIA LLM Router v3:
| Aspect | OpenRouter Auto | OpenRouter Fusion | OpenRouter Pareto | NVIDIA LLM Router v3 |
|---|---|---|---|---|
| Purpose | Cost optimization | Quality improvement (multi-model deliberation) | Coding-focused | Cost optimization, self-host |
| Decision logic | NotDiamond (closed) | Judge model comparison JSON | AA percentile (external) | Encoder + MLP estimating P(correct) |
| Model pool | Operator-curated | 1–8 panel + 1 judge | Tier-based curated | Re-trainable with self-host, on-prem mixing supported |
| Cost structure | Single model pricing | 4–5× single model | Single model pricing | Self-host inference + single model pricing |
| Re-train on own data | Not possible | Not possible | Not possible | Possible |
Fusion Router is a different category of functionality—"deliberation across multiple models"—focused on quality improvement rather than cost optimization. Since a panel of 3 models + 1 judge fires per request, the cost is 4–5× a single model. Pareto Router uses Artificial Analysis coding percentiles and selects the cheapest option from 3 tiers via min_coding_score—philosophically close to v3's tolerance.
The natural question here is: if SaaS OpenRouter does the job, what's the point of self-hosting NVIDIA LLM Router v3? The way I see it, the differentiators are: being able to visualize the routing decision rationale, freezing the shortlist for reproducibility, mixing on-prem models into the pool, and re-training on your own data. If enterprise requirements mean "a black-box routing decision won't pass an audit" or "sensitive queries must stay on-prem," then forking and running v3 becomes a real option.
Where NVIDIA LLM Router v3 Stands Today
When you visit the LLM Router repository, you'll see several branches lined up, which is a bit disorienting at first. It's gone through generations—v1, v2, and v3—and the currently active one is the v3 branch (based on the repository description).
Here's the state of the most recent commits per branch:
| Branch | Latest Commit | Implementation Status |
|---|---|---|
main (v1) |
2026-04-29 | Implementation stopped 2025-12-19; only Helm examples updated since |
experimental (v2) |
2026-04-14 | Implementation stopped 2025-12-31; only CI config since |
v3 |
2026-05-07 | Ongoing; LiteLLM Proxy external sidecar hook added |
v1 and v2 are effectively in maintenance mode, and v3 is the de facto main line. The default branch is still experimental, so you might momentarily wonder "which one should I look at?"—but following the README leads you straight to v3.
The v3 README opens with this:
Reference implementation only.
This branch is a reference implementation demonstrating prefill-based LLM routing.
For production deployment, please fork this repository.
"Reference implementation only"—meaning if you want to take it to production, fork it and integrate it at your own responsibility. It's worth noting that the Blueprint's "recommended for production deployment" positioning has been stripped from v3. On the flip side, it's built with the assumption that you'll fork it and adapt it to your use case, so it leaves plenty of room for customization.
The README also includes a self-comparison table across v1 / v2 / v3. v3 restores the proxying functionality from v1 while cutting the multimodal support from v2 to focus on text-only. The pool includes 9 models spanning roughly a 500× price difference between the cheapest and most expensive, and the pre-trained routing model is included as-is. The fastest way forward is to just run it and get a feel for the behavior.
One structural point worth noting: v3 is the layer that decides which model to call, while the actual calling is delegated to OpenRouter or LiteLLM. The default pool's cloud models are curated assuming OpenRouter prefixes, so routing decisions can be executed directly via OpenRouter, and you can also inject routing decisions into an existing LiteLLM Proxy. The decision algorithm we'll look at in the next section is about the "selection" side, with this division of responsibilities in mind.
How Does It Select a Model?
v3's routing decision roughly follows this flow:
The question is passed through an Encoder (Qwen3.5-0.8B; ~100ms on GPU, ~5 seconds on CPU) to extract the hidden states representing the "semantic vector" of the question. These are dimensionality-reduced via PCA, then fed into a small MLP decision model, which outputs the probability of each model in the pool "correctly answering" the question—P(correct).
This is where the tolerance parameter comes in. The threshold is set as threshold = max(P) − tolerance, and the cheapest model above the threshold is selected. With tolerance = 0, the most capable model is always selected; with tolerance = 1.0, the cheapest is always selected. The default of 0.20 is positioned as the balance point between maintaining quality and reducing cost.
From the README's example:
P(correct): Cost:
nemotron-nano: 0.92 $0.05/M
gpt-oss-120b: 0.95 $0.43/M
claude-opus: 0.97 $25.78/M
tolerance = 0.20
→ threshold = 0.97 − 0.20 = 0.77
Models above threshold:
nemotron-nano ✓ → cheapest, so selected
gpt-oss-120b ✓
claude-opus ✓
Escaping the state of "Opus gets called even for light questions" is exactly what this mechanism enables. When I tried throwing a light query like "What is 2 + 2?" on actual hardware, the confidence for all 9 models hugged a low range of 0.03–0.26. The absolute values of P(correct) are relative to the training judge, so seeing "addition at 0.17" is expected behavior. I find it easier to think of the values as relative within the same question, not absolute.
The implementation has a 4-layer structure: Core contains BaseRouter / PrefillRouter / PoolConfig / RoutingResult; Training has collect / train / evaluate CLIs; Adapters includes 6 variants like LiteLLM Strategy, Standalone Server, LiteLLM Proxy, and Sidecar; and Plugins ships the NemoHermes OpenClaw plugin as standard.
First: Running Just the Routing Decision
Now let's get hands-on. v3's default pool uses cloud models via OpenRouter, but the routing decision itself runs entirely on the encoder and checkpoint—so you can get a feel for the behavior without an OpenRouter API key. Let's walk through it from forking and checking out.
git clone https://github.com/NVIDIA-AI-Blueprints/llm-router
cd llm-router
git checkout v3
git lfs install
git lfs pull
pip install -e '.[prefill,litellm]'
Once setup is done, call it directly from Python:
from model_router_toolkit.config import load_config, build_router_from_config
config = load_config("configs/v1-9models-qwen08b.yaml")
router = build_router_from_config(config)
result = router.route("What is the capital of France?", tolerance=0.20)
print(f"Selected: {result.selected_model}")
print(f"Confidence: {result.selected_confidence:.3f}")
The v1- prefix in configs/v1-9models-qwen08b.yaml is a bit confusing, but it means "pool configuration version 1"—unrelated to the v1 main branch. Peeking inside shows a 9-model pool defined, ranging from Nemotron nano to GPT-5 and Claude Opus 4.6. Since Claude Opus is included in the default pool, passing a single OpenRouter API key gets you working Anthropic routing out of the box.
| Slot | Model | OpenRouter slug | output $/M |
|---|---|---|---|
| 1 | Nemotron 3 Nano (Reasoning) | nvidia/nemotron-3-nano-30b-a3b |
0.20 |
| 2 | GPT-OSS 20B High | openai/gpt-oss-20b |
0.25 |
| 3 | Nemotron 3 Super (free) | nvidia/nemotron-3-super-120b-a12b:free |
0.00 |
| 4 | GPT-OSS 120B High | openai/gpt-oss-120b |
0.43 |
| 5 | Qwen 3.5 35B | qwen/qwen3.5-35b-a3b |
1.30 |
| 6 | Qwen 3.5 122B | qwen/qwen3.5-122b-a10b |
2.08 |
| 7 | GPT-5.2 High | openai/gpt-5.2 |
14.00 |
| 8 | GPT-5.4 High | openai/gpt-5.4 |
15.00 |
| 9 | Claude Opus 4.6 High | anthropic/claude-opus-4-6 |
25.78 |
A 9-tier setup spanning roughly an order of magnitude in output unit price, from Nemotron 3 Super (free tier) to Opus 4.6 at the top. A few reasoning models in the mix have reasoning_effort: high or enable_thinking: true in their config, so thinking tokens will add a bit to the actual cost—worth keeping in mind.
To see the playground UI, spin up the Standalone Server:
model-router serve --config configs/v1-9models-qwen08b.yaml --port 8100
Opening http://localhost:8100 shows a UI where you can submit questions and see the routing decision, each model's confidence, and cost estimates all at once. If you just want to check the default pool contents, hitting /api/models is the fastest route.
Mixing Claude and GPT into the Pool via OpenRouter
To connect all the way through to actual calls, you need one OpenRouter API key. The default pool is set up assuming OpenRouter prefixes, so just exporting the key gets you Claude / GPT / Gemini / DeepSeek and more lined up in the pool.
export OPENROUTER_API_KEY=your-key
model-router serve --config configs/v1-9models-qwen08b.yaml --port 8100
Submitting "What is 2 + 2?" in the UI with default tolerance=0.05 gives you something like this:
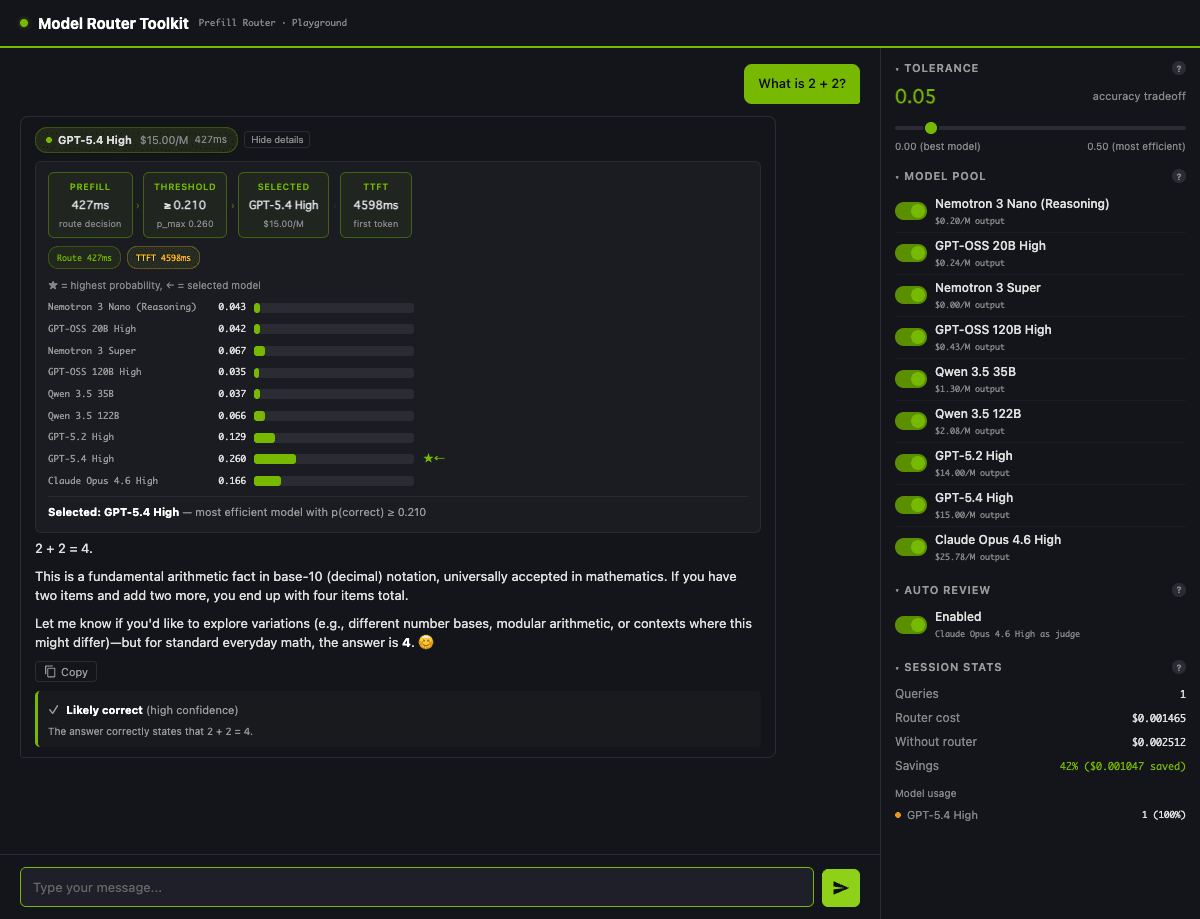
GPT-5.4 was the only model exceeding threshold 0.210, so it was selected. The "confidence absolute values hug low even for light questions" behavior I described earlier (0.035–0.260) shows up with the same numbers in the UI.
A natural question here is "which model actually gets called with the default tolerance?" I tried 20 questions of varying character at 5 tolerance levels (0.00 / 0.05 / 0.10 / 0.15 / 0.20). Pulling just the routing decision from /v1/route, the selected_model distribution shifted like this:
| tolerance | claude-opus | gpt-5-4 | gpt-5-2 | qwen-3-5-122b | nemotron-3-super | nemotron-3-nano |
|---|---|---|---|---|---|---|
| 0.00 | 6 questions | 14 questions | 0 questions | 0 questions | 0 questions | 0 questions |
| 0.05 | 0 questions | 14 questions | 4 questions | 0 questions | 0 questions | 2 questions |
| 0.10 | 0 questions | 3 questions | 12 questions | 1 question | 0 questions | 4 questions |
| 0.15 | 0 questions | 1 question | 2 questions | 1 question | 2 questions | 14 questions |
| 0.20 | 0 questions | 0 questions | 1 question | 1 question | 0 questions | 18 questions |
Even in maximum-quality mode at tolerance = 0, only the 6 questions judged as hard were routed to Claude Opus, while the remaining 14 concentrated on gpt-5-4. Moving tolerance from 0.05 to 0.20 shows a continuous descent of gpt-5-4 → gpt-5-2 → nemotron-3-nano, until at 0.20 nearly everything is handled by Nemotron.
Tracking this for a single question in the UI makes the intuition concrete. The same "What is 2 + 2?" submitted at tol=0.05 picks GPT-5.4 ($15/M output); re-submitted at tol=0.20, the threshold drops to 0.060 and it switches to Nemotron 3 Super ($0/M output), the cheapest tier.
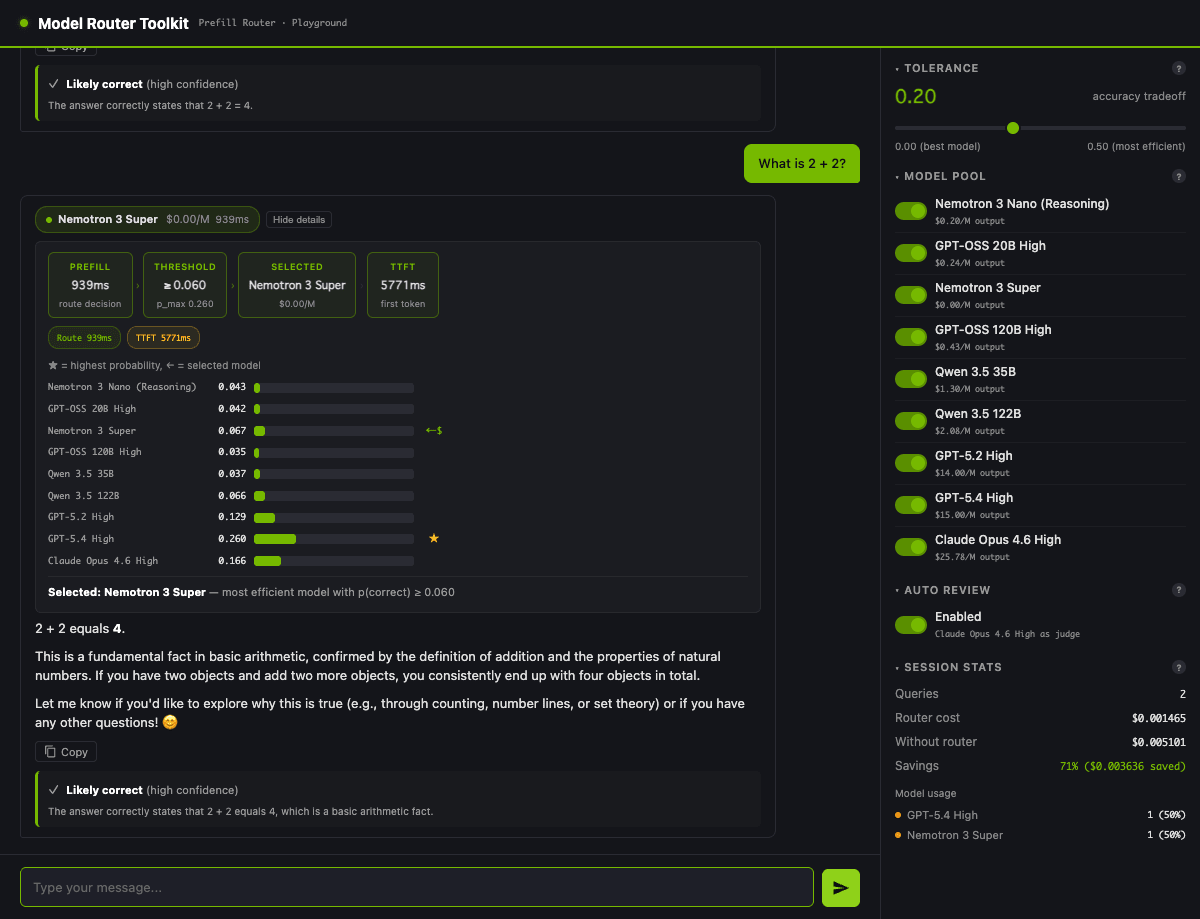
Session Stats savings going from 42% to 71% shows the effect of moving tolerance by one step. The movement seen in the 20-question sweep is perceptible even when tracking a single question.
At this point, some readers might wonder "wouldn't LiteLLM alone be sufficient?" LiteLLM does have automatic routing built in—the AutoRouter added in 2025 offers a Semantic Router that routes based on embedding similarity to user-written examples, and a Complexity Router that classifies queries rule-based into 4 tiers from token count and keywords like step by step. Beyond that, traditional strategies like cost-based-routing, latency-based-routing, usage-based-routing-v2, and provider-budget-limiting cover different optimization axes. Honestly, if your goal is purely cost optimization or load balancing, LiteLLM alone gets you quite far.
Where v3 goes a step further is the ML-based approach that simultaneously estimates the probability of a correct answer for each candidate model. LiteLLM's Semantic Router requires hand-writing example prompts, and the Complexity Router uses rule-based English keyword detection, so Japanese-heavy prompts, math-heavy prompts, or unexpected question types fall back to default. v3 uses DeBERTa-v3 + MLP head to output P(correct) for all 9 models, then selects the cheapest above the tolerance-defined quality floor—preventing both "Opus called for a trivial question" and "Nano assigned to a hard math problem" simultaneously. The ability to run collect → train → evaluate on your own data to retrain the router to your question distribution is another v3 strength. That training story is something I plan to actually run through in Part 2.
In terms of roles: v3 decides which model to call via ML, and LiteLLM handles the actual calling as an abstraction layer plus guardrails and budget management. LiteLLM's virtual keys, provider-budget-limiting, and guardrails integrations with Aporia, Presidio, etc. are outside v3's scope, so in enterprise operations a two-layer approach combining both is actually the practical path. If "just reduce cost and latency" is the goal, LiteLLM alone is sufficient; when you want "protect quality while reducing cost based on question content" or "preserve routing decision rationale down to per-model confidence," that's when you add v3 on top.
Measuring Reduction Rates with a Persona of a Regular Opus User
This is probably the most important part for anyone considering organizational adoption: "how much does it actually save?" I set up a persona and measured it.
The persona: "a user who always calls Claude Opus." I prepared 5 questions of varying character—light chitchat, writing a code decorator, technical explanation, mathematical proof, philosophical question—and compared the total cost of sending all of them to Opus versus sending them through v3 routing (with the default pool as-is).
| Route | Total Cost | Reduction vs. All-Opus |
|---|---|---|
| All Opus 4.6 (baseline) | $0.0913 | — |
| Routing (tol=0.05) | $0.0193 | 78.8% |
| Routing (tol=0.10) | $0.0198 | 78.3% |
| Routing (tol=0.20) | $0.0014 | 98.5% |
What's interesting is that tol=0.05 and tol=0.10 land at nearly identical reduction rates (78.8% and 78.3%). With the default pool, mid-range tolerance routes concentrated onto gpt-5.2 / gpt-5.4-class cloud models, so moving tolerance by 0.05 barely changed which models got called.
Pushing to tol=0.20 concentrates nearly all 5 questions into nemotron-3-nano-reasoning (the cheapest slot in the pool), achieving 98.5% reduction vs. Opus. The Nemotron cloud call costs aren't literally zero, but they're essentially negligible compared to Opus.
Mapping this to the 5-person team estimate from the intro (165,000 requests/month × 1,500 output tokens): All-Opus runs ~$6,200/month; tol=0.10 routing comes in around $1,350/month; tol=0.20 comes in around $90/month. From there, the realistic use involves tuning "how aggressive to go while protecting quality."
Personally, getting these results with the default checkpoint labeled "Reference implementation only" was honestly more than I expected. That said, the lack of improvement from tol=0.05 to tol=0.10 leaves room for pool design. Let's see how the mid-range tolerance behaves with local model mixing in the next section.
Mixing DGX Spark Local Models into the Pool
This is where the difference from OpenRouter Auto / Fusion / Pareto and LLM Router v3 really shows up. Just write a local vLLM endpoint into the pool slot, and it becomes a routing candidate on equal footing with cloud models.
I started Nemotron 3 Nano 30B-A3B NVFP4-quantized on vLLM on DGX Spark with --gpu-memory-utilization 0.4, and created a single YAML in configs/ for tier design:
models:
- name: nemotron-3-nano-reasoning # replace slot 1 with local
api_base: http://localhost:8000/v1
api_key_env: LOCAL_KEY
model_name: nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
cost_per_m_input_tokens: 0
cost_per_m_output_tokens: 0
- name: gpt-5-2-high # replace slot 7 with Kimi K2.7 Code
api_base: https://openrouter.ai/api/v1
api_key_env: OPENROUTER_API_KEY
model_name: moonshotai/kimi-k2.7-code-20260612
# ...
- name: gpt-5-4-high # replace slot 8 with GLM 5.2
model_name: z-ai/glm-5.2-20260616
# ...
The slots stay the same as defaults, so the trained MLP's selection logic works as-is—only the actual call destinations change. Looking at the /v1/chat/completions response, the model field correctly records nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 and z-ai/glm-5.2-20260616—you can see in practice that "only the entity changes while the slot name stays the same."
The ability to design data sovereignty—sensitive light queries go local, externally-sharable ones go to emerging cloud models, hard problems only go to Opus—all from a single pool config YAML is what makes this a good fit for enterprise requirements. OpenRouter Auto and Pareto pools are closed within OpenRouter's own models, so this "on-prem + cloud mixed" setup is exclusively the domain of v3 (and self-hosted routers like it).
Running the same 5 questions from Chapter 7 against this mixed pool, the reduction rates shifted as follows:
| Route | Total Cost | Reduction vs. All-Opus |
|---|---|---|
| All Opus 4.6 (baseline) | $0.0859 | — |
| Routing (tol=0.05, mixed) | $0.0211 | 75.4% |
| Routing (tol=0.10, mixed) | $0.0110 | 87.2% |
| Routing (tol=0.20, mixed) | $0.0000 | 100% |
With the default pool in Chapter 7, both tol=0.05 and tol=0.10 plateaued around 78%. After switching to the mixed pool, tol=0.10 extended to 87.2%. Kimi K2.7 Code and GLM 5.2 took over medium-weight queries, shifting the calls that had concentrated on gpt-5.2 / gpt-5.4 toward cheaper emerging models. At tol=0.20, nearly everything consolidates onto local Nemotron and cloud-side cost becomes literally $0.
Latency is another concern, so I measured 2 questions—a light chitchat and a heavy philosophy question—3 times each (median values):
| Question | Claude Opus 4.6 | Local Nemotron |
|---|---|---|
| chitchat_ja (light) | 3.87 sec | 3.37 sec |
| philosophy (heavy) | 6.08 sec | 30.02 sec |
On the light side the results are nearly equivalent—local is actually slightly faster. But for the heavy side it flips, with Nemotron taking 5× longer. This is because while Opus returned around 138 tokens concisely for Discuss the Chinese Room argument in 100 words., Nemotron returned a long response of 1,600–2,100 tokens. The gap in "following the 100-word instruction constraint" translates directly into perceived latency—something worth keeping in mind when designing pools.
How to Audit Routing Decisions
When evaluating enterprise adoption, the question that always comes up is auditability of routing decisions. Whether you can trace "which question was routed to which model, and why" in logs is critical for compliance and post-incident analysis.
The RoutingResult v3 returns includes not just the selected model, but the full pool's confidences, cost estimates, and latency. Streaming this directly into an observability platform lets you detect incidents like "Opus was being called even for light questions" after the fact.
For Langfuse, calling router.route() inside langfuse.start_span() and adding selected_model and confidences to metadata is all it takes to enable filtering in the dashboard after the fact. Being able to view tolerance-level distributions, monthly cost drift, and per-persona Opus ratios speeds up operational decisions considerably.
Comparing to OpenRouter Auto: since Auto's NotDiamond decision rationale is a black box, "why was that model selected" cannot be reproduced after the fact. v3 can record P(correct) for all 9 models, so if enterprise requirements include an obligation to preserve routing decision rationale, that's a compelling reason to choose v3. Quietly very useful.
Going one step further, viewing logs over time reveals indicators for deciding when to retrain—routing drift, where the selected_model distribution for the same question set shifts over time, and cost drift, where the cost ratio per pool model diverges from initial projections. The operational aspects around this are something I plan to address in Part 2.
Calling from an App as an OpenAI-Compatible Endpoint
So far we've looked at the behavior of the routing service and auditing, but let me briefly touch on how to connect when actually calling from an app or agent.
The /v1/chat/completions exposed by v3's model-router serve is OpenAI-compatible. It receives the messages array as-is and returns a response in OpenAI style with { id, choices, model, usage }. For the model in the request, you simply specify the policy name written in the pool config (for the default checkpoint it's default, or whatever name you gave to a custom mixed pool you built), and internally MLP runs and forwards to the actual model.
curl -X POST http://<DGX_SPARK_IP>:8202/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "default",
"messages": [
{"role": "user", "content": "What is 2+2?"}
],
"tolerance": 0.10
}'
The model field in the response contains the actual routed destination (for example, nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 or anthropic/claude-opus-4-6). tolerance is a custom extension that v3 adds to the OpenAI-compatible API; if omitted, the default value is used.
For coding agents that use OpenAI-compatible clients like the OpenAI SDK, LiteLLM, or OpenCode, simply switching the BASE_URL to http://<DGX_SPARK_IP>:8202/v1 means your usual tools will go through the routing service as-is. The nice thing about being OpenAI-compatible is that the client doesn't need to be aware of what's running inside the pool — the router handles the dispatching behind the scenes.
One caveat: Claude Code sends requests to /v1/messages (Anthropic format), so pointing it directly at /v1/chat/completions won't work. You'll need to insert an Anthropic-compatible shim (such as LiteLLM proxy's passthrough feature) in between.
Summary
As model costs have risen and using different models for different purposes has become a realistic consideration when scaling within an organization, SaaS options like OpenRouter Auto / Fusion / Pareto are convenient, but when requirements include visibility into routing decision rationale, freezing the shortlist, mixing in on-premises models, and retraining on your own data, self-hosted NVIDIA LLM Router v3 becomes a candidate.
Running it on actual hardware, even with the default checkpoint alone, we saw 75–87% cost reduction assuming users exclusively on Opus. Pushing tolerance = 0.20 to consolidate onto local Nemotron gets you to 100%, meaning you can build a configuration where cloud API spending drops to $0. The fact that the balance between cost and quality shifts smoothly depending on how you set tolerance means you can advance incrementally in line with your organization's risk tolerance — which from an implementation perspective is what makes it practical.
That said, the default checkpoint has its limits: its behavior is governed by a pre-trained MLP based on slot order in a 9-model pool. Even if you add newer models (Claude Opus 4.8 / GPT-5.5 / Kimi K2.7 Code / DeepSeek V4 / Qwen 3.7 / GLM 5.2, etc.) to the pool, since those weren't in the training signal, there's no guarantee that the model best suited to your use case will be selected. To fundamentally address this, the option of creating your own checkpoint through the collect → train → evaluate training pipeline comes into play. At the 500-question scale, the estimate is $5–25 and half a day, so I think it's recoverable within a month from a persona's monthly savings.
Also, as the README explicitly states — "Reference implementation only. For production deployment, please fork this repository" — v3 is fundamentally meant to be forked and adapted to your own use case. During the verification for this article, I found several areas for improvement around the OpenAI-compatible endpoint, so in the follow-up Part 2, I'll apply minimal improvements to the serve code after forking, then move into the persona training section.
Despite saying "reference implementation only," v3 is quite fun to play with — the direction it's heading is genuinely interesting.
Reference Links
NVIDIA LLM Router
- NVIDIA-AI-Blueprints/llm-router (GitHub) — The repository containing the v3 branch covered in this article. Checking out
v3gives you the same environment as this article - LLM Router: Rethinking Routing with Prefill Activations (arXiv 2603.20895) — Paper on prefill-based routing that estimates P(correct) for each model from the encoder's hidden states
OpenRouter Routers
- OpenRouter Auto Router — NotDiamond-based automatic router callable via
openrouter/auto - OpenRouter Fusion Router — Quality-improvement type using multi-model deliberation + judge
- OpenRouter Pareto Router — Tier-based type using Artificial Analysis coding percentile
LiteLLM
- LiteLLM Routing — List of strategies including
cost-based-routing,latency-based-routing,usage-based-routing-v2, and others - LiteLLM Auto Routing — Documentation for AutoRouter (Semantic + Complexity) added in 2025-07
- aurelio-labs/semantic-router — Semantic routing library used internally by LiteLLM AutoRouter (Semantic)
