
NVIDIA LLM Router で LLM の用途別使い分け環境を構築してみた(基礎編)
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
モデルの利用料金、ここ数か月でぐっと上がってきましたよね。。。Claude Opus 4.8 の output が 1M トークンで 25 ドル、GPT-5.5 や Gemini 3.1 Pro も同じ価格帯に並んできました。個人で触る分には Claude Code や Codex のサブスクリプションで吸収できる範囲ですが、組織でスケールしてくると「全部 Opus」では月次予算が厳しい話になってきます。
「軽い問い合わせにも Opus が呼ばれてしまっている気がする、とはいえ難問に小さいモデルを当てるのも怖い」というモヤモヤを抱えている方も多いのではないでしょうか。
そんなときに役立ちそうなのが LLM Router、つまり質問の内容を見てモデルを自動で切り替える仕組みです。OpenRouter の Auto Router のような機能もありますが、今回は自前で構築できる NVIDIA LLM Router v3 を DGX Spark 上で動かしてみました。API 経由のクラウドモデルだけでなく、DGX Spark の上で動かしているローカル LLM も同じ pool に混ぜてルーティングできるところまでが、本記事のスコープです。
モデルの使い分けが現実的な話になってきた背景
個人で軽く触る分には、サブスクリプションの中に押し込めば数千円で収まる話です。ただ、Claude Code や Codex を業務で常用するようになるとそうもいきません。1 ユーザーで 1 日 300 リクエスト、平均 output 1,500 トークンと置いただけで月 6,600 リクエスト、全 Opus 4.8 で月 250 ドル弱になります。Claude Code Max ($200 / 月) の天井をちょうど超えてくるあたりです。
これが 5 人のチームで、1 人あたりエージェントを常時走らせる使い方になると、もう一段スケールします。5 人 × 月 33,000 リクエスト × 平均 output 1,500 トークン(合計で月 165,000 リクエスト)の想定で並べてみました。
| 構成 | 単価 | 月次想定 |
|---|---|---|
| 全 Opus 4.8 | output $25 / 1M | 約 6,200 ドル |
| 全 Sonnet 4.6 | output $15 / 1M | 約 3,700 ドル |
| Opus 30% / Sonnet 50% / Haiku 20% の mix | 加重平均 $16 / 1M | 約 4,000 ドル |
数字は 2026 年現在の最新世代の Claude Opus 4.8 / Sonnet 4.6 / Haiku 4.5 の output 単価で揃えています(後述の v3 default pool には Opus 4.6 が同梱されていますが、価格帯と挙動は近似のため、月次試算には最新世代の単価を使っています)。
数字だけ見ると「Sonnet で十分では」となりがちなのですが、これは平均トークン数で揃えた話なので、実際は難問の output が伸びがちで Opus 比率が増えて、もう少し高くなる傾向です。逆に軽い質問はもっと短く、Haiku で十分なケースも多いはずです。「全部 Opus」と「全部 Sonnet」の間に、もう一段の使い分けが入り込む余地があります。
組織でこの使い分けを実装に落とすときに気にしておきたいのが、自分の場合は次の 3 点です。月次の予算が読める状態にしておきたいというコスト予測可能性、ルーティング判定の根拠と実際の呼び出しを全部ログに残しておきたいという監査性、そして機微な情報を含む質問はオンプレに、それ以外はクラウドにと境界を引きたいというデータ主権の話です。
組織にスケールしてくると、このあたりが一気に効いてきます。ここからが本題です。
ルータの選択肢を整理してみる
「ルータが欲しい」と思ったときに、まず候補に上がるのは OpenRouter です。openrouter/auto というモデルスラッグを指定するだけで、NotDiamond ベースのルータが prompt を見てモデルを選んでくれます。最近は Fusion Router や Pareto Router といった別系統の Router も追加されていて、選択肢が増えてきました。
NVIDIA LLM Router v3 と並べて整理してみると、こんな感じです。
| 観点 | OpenRouter Auto | OpenRouter Fusion | OpenRouter Pareto | NVIDIA LLM Router v3 |
|---|---|---|---|---|
| 目的 | コスト最適化 | 品質向上(複数モデル協議) | コーディング特化 | コスト最適化、self-host |
| 判定の中身 | NotDiamond(非公開) | judge model の比較 JSON | AA percentile(外部) | encoder + MLP で P(correct) 推定 |
| モデル pool | 運営更新の curated | 1–8 panel + 1 judge | tier 別 curated | self-host で再訓練可、オンプレ混在可 |
| コスト構造 | 単体モデル料金 | 4–5× 単体 | 単体モデル料金 | self-host 推論 + 単体モデル料金 |
| 自分のデータで再訓練 | できない | できない | できない | できる |
Fusion Router は「複数モデルで協議して判定」という別系統の機能で、コスト最適化ではなく品質向上に寄せています。1 リクエストで panel 3 モデル + judge 1 モデルが動くので、コストは単体の 4–5 倍です。Pareto Router は Artificial Analysis の coding percentile を使って min_coding_score で 3 段の tier から最安を選ぶ仕組みで、思想としては v3 の tolerance に近いところがあります。
ここで気になるのが、SaaS の OpenRouter で済むなら NVIDIA LLM Router v3 を自前で立てる意味はどこにあるのか、というところです。自分の整理では、ルーティング判定の根拠を可視化できる、shortlist を凍結して再現性を保てる、オンプレモデルを pool に混ぜられる、そして自分のデータで再訓練できる、この 4 点が分かれ目です。エンプラ要件で「routing 判定がブラックボックスだと監査が通らない」「機微な質問はオンプレに落としたい」という制約があるなら、v3 を fork して動かす方向も一つの選択肢になりそうです。
NVIDIA LLM Router v3 の今の位置づけ
NVIDIA LLM Router、リポジトリを訪ねるとブランチがいくつか並んでいて、最初は少し戸惑います。実は v1 から v2、v3 と世代を重ねていて、今動いているのは v3 ブランチです(リポジトリの説明を読む限り)。
各ブランチの最終コミット日はこんな状況です。
| ブランチ | 最新コミット | 実装の状況 |
|---|---|---|
main (v1) |
2026-04-29 | 2025-12-19 で実装停止、以降は Helm 例の更新のみ |
experimental (v2) |
2026-04-14 | 2025-12-31 で実装停止、以降は CI 設定のみ |
v3 |
2026-05-07 | 継続中、LiteLLM Proxy external sidecar hook 追加 |
v1 と v2 は実質メンテモードに入っていて、v3 が事実上の本命継続線です。default branch がまだ experimental のままなので「どれを見るのが正解?」と一瞬迷うのですが、README をたどると素直に v3 へ誘導されます。
その v3 の README、冒頭にこう書かれています。
Reference implementation only.
This branch is a reference implementation demonstrating prefill-based LLM routing.
For production deployment, please fork this repository.
「Reference implementation only」、つまり本番に持っていくなら fork して自分の責任で組み込んでください、という宣言です。Blueprint としての「production deploy 推奨」位置づけが v3 で剥がされているところは、利用者として見落としたくない情報です。逆に言うと、fork して自分のユースケースに当て込むことを前提にした作りになっているので、改変の余地は大きく取ってあります。
README には v1 / v2 / v3 の自己比較表もあります。v3 は v1 の proxying 機能を取り戻しつつ、v2 のマルチモーダル対応を切ってテキスト専用に絞った形です。pool には最安と最高で単価差 500 倍ほどある 9 モデルが並んでいて、学習済みの routing モデルもそのまま同梱されています。まずは動かして挙動を確かめてみるのが早そうです。
構造的に押さえておきたいのが、v3 は「どのモデルを呼ぶか」を判定するレイヤーで、「実際にモデルを呼ぶ」部分は OpenRouter や LiteLLM に任せる作りになっているところです。default pool のクラウドモデルは OpenRouter の prefix を前提に curated されているので、判定結果をそのまま OpenRouter 経由で呼べますし、既存の LiteLLM Proxy にルーティング判定を差し込むこともできます。次章で見ていく判定アルゴリズムは、この役割分担を前提にした「選ぶ側」の話になります。
どうやってモデルを選んでいるのか
v3 のルーティング判定は、おおまかに次の流れで動いています。
質問を Encoder(Qwen3.5-0.8B、GPU で 100ms、CPU でも 5 秒程度)に通して、質問の「意味ベクトル」にあたる hidden states を取り出します。これを PCA で次元削減してから、判定用の MLP(小さな多層ニューラルネット)に通すと、pool 内の各モデルについて「この質問に正解する確率」、P(correct) が出てきます。
ここで効いてくるのが tolerance というパラメータです。threshold = max(P) − tolerance で閾値を引いて、閾値を超えたモデルの中から最安を選びます。tolerance = 0 なら常に一番賢いモデルを選び、tolerance = 1.0 なら常に最安を選びます。default の 0.20 が、品質を落とさずにコストを下げるバランス点として置かれています。
README の例だと、こんな感じです。
P(correct): Cost:
nemotron-nano: 0.92 $0.05/M
gpt-oss-120b: 0.95 $0.43/M
claude-opus: 0.97 $25.78/M
tolerance = 0.20
→ threshold = 0.97 − 0.20 = 0.77
閾値を超えるモデル:
nemotron-nano ✓ → 最安なので選択
gpt-oss-120b ✓
claude-opus ✓
「軽い質問にも Opus を呼んでしまう」状態から抜け出すのは、まさにこの仕組みのおかげです。実機で "What is 2 + 2?" のような軽い質問を投げてみたところ、9 モデル全ての confidence が 0.03 〜 0.26 の範囲に低く張り付きました。P(correct) の絶対値は学習 judge との相対尺度なので、「足し算が 0.17」と見えるのは仕様です。比較する基準は同じ質問の中での相対値、と理解しておくと混乱しないかなと思っています。
実装は 4 レイヤー構造になっていて、Core が BaseRouter / PrefillRouter / PoolConfig / RoutingResult、Training が collect / train / evaluate の CLI、Adapters が LiteLLM Strategy や Standalone Server、LiteLLM Proxy、Sidecar など 6 種類、そして Plugins として NemoHermes の OpenClaw plugin が標準同梱されています。
まずは routing 判定だけ走らせてみる
ここからは実機で触ってみます。v3 の default pool は OpenRouter 経由でクラウドモデルを呼ぶ構成ですが、routing 判定そのものは encoder と checkpoint で完結するので、OpenRouter API キーを使わずに挙動の感触を掴めます。fork して checkout するところから順番に進めていきます。
git clone https://github.com/NVIDIA-AI-Blueprints/llm-router
cd llm-router
git checkout v3
git lfs install
git lfs pull
pip install -e '.[prefill,litellm]'
セットアップが終わったら、そのまま Python から呼んでみます。
from model_router_toolkit.config import load_config, build_router_from_config
config = load_config("configs/v1-9models-qwen08b.yaml")
router = build_router_from_config(config)
result = router.route("What is the capital of France?", tolerance=0.20)
print(f"Selected: {result.selected_model}")
print(f"Confidence: {result.selected_confidence:.3f}")
configs/v1-9models-qwen08b.yaml の v1- という prefix が紛らわしいのですが、これは「pool 構成バージョン v1」の意味で、router の v1 main branch とは無関係です。中身を覗くと 9 モデル pool が定義されていて、Nemotron nano から GPT-5、Claude Opus 4.6 までが並んでいます。Claude Opus も default で pool に含まれているので、OpenRouter API key を 1 つ通せばそのまま Anthropic ルーティングが成立する作りになっています。
| Slot | モデル | OpenRouter slug | output $/M |
|---|---|---|---|
| 1 | Nemotron 3 Nano (Reasoning) | nvidia/nemotron-3-nano-30b-a3b |
0.20 |
| 2 | GPT-OSS 20B High | openai/gpt-oss-20b |
0.25 |
| 3 | Nemotron 3 Super (free) | nvidia/nemotron-3-super-120b-a12b:free |
0.00 |
| 4 | GPT-OSS 120B High | openai/gpt-oss-120b |
0.43 |
| 5 | Qwen 3.5 35B | qwen/qwen3.5-35b-a3b |
1.30 |
| 6 | Qwen 3.5 122B | qwen/qwen3.5-122b-a10b |
2.08 |
| 7 | GPT-5.2 High | openai/gpt-5.2 |
14.00 |
| 8 | GPT-5.4 High | openai/gpt-5.4 |
15.00 |
| 9 | Claude Opus 4.6 High | anthropic/claude-opus-4-6 |
25.78 |
最安の Nemotron 3 Super(free tier)から最高単価の Opus 4.6 まで、output 単価で 1 桁の幅を取った 9 段構成です。reasoning 系(reasoning_effort: high や enable_thinking: true が config に書かれているモデル)が混ざっているので、軽量質問でも思考トークンが乗って実コストが少し膨らむ点だけ覚えておきたいところです。
playground UI を見たい場合は Standalone Server を立てます。
model-router serve --config configs/v1-9models-qwen08b.yaml --port 8100
http://localhost:8100 を開くと UI が出てきて、質問を投げると routing decision と各モデルの confidence、cost 見積もりが全部一覧で見られます。default pool の中身を確認するなら /api/models を叩くのが速いです。
OpenRouter 経由で Claude や GPT を pool に混ぜる
実際の呼び出しまでつなげるには OpenRouter API key を 1 つ用意します。default pool は OpenRouter の prefix を前提に組まれているので、key を export するだけで Claude / GPT / Gemini / DeepSeek あたりが pool に揃います。
export OPENROUTER_API_KEY=your-key
model-router serve --config configs/v1-9models-qwen08b.yaml --port 8100
UI で "What is 2 + 2?" を投げると、default の tolerance=0.05 でこんな画面になります。
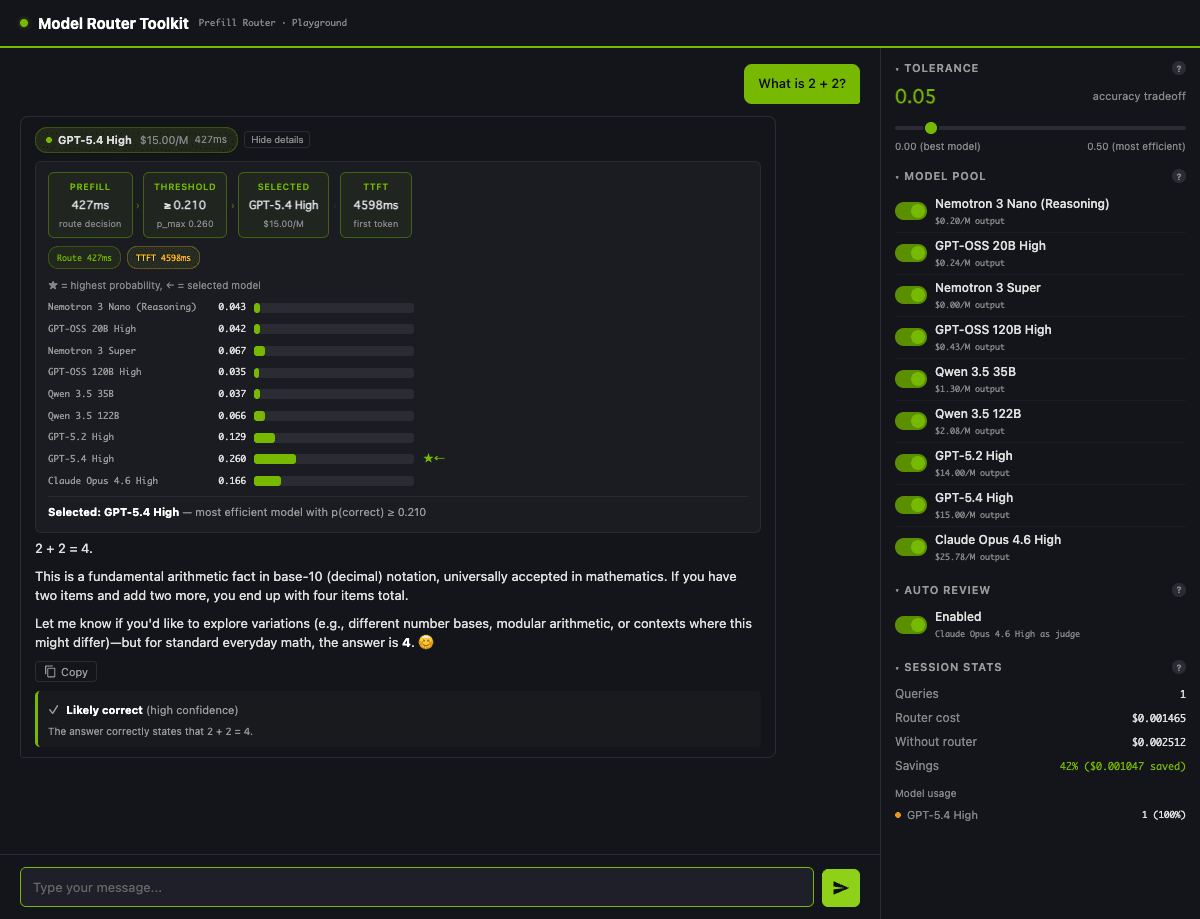
threshold 0.210 を超えたのが GPT-5.4 だけだったので、それが選ばれています。前章で書いた「軽い質問でも confidence の絶対値は低く張り付く」が、UI 上でも同じ数字感(0.035〜0.260)で確認できます。
ここで気になるのが「default の tolerance だと、結局どのモデルが呼ばれるのか」というところですよね。性質の違う 20 問を 5 段階の tolerance(0.00 / 0.05 / 0.10 / 0.15 / 0.20)で投げてみました。/v1/route でルーティング判定だけを取り出すと、selected_model の分布はこう動きました。
| tolerance | claude-opus | gpt-5-4 | gpt-5-2 | qwen-3-5-122b | nemotron-3-super | nemotron-3-nano |
|---|---|---|---|---|---|---|
| 0.00 | 6 問 | 14 問 | 0 問 | 0 問 | 0 問 | 0 問 |
| 0.05 | 0 問 | 14 問 | 4 問 | 0 問 | 0 問 | 2 問 |
| 0.10 | 0 問 | 3 問 | 12 問 | 1 問 | 0 問 | 4 問 |
| 0.15 | 0 問 | 1 問 | 2 問 | 1 問 | 2 問 | 14 問 |
| 0.20 | 0 問 | 0 問 | 1 問 | 1 問 | 0 問 | 18 問 |
tolerance = 0 の最高品質モードでも、難しいと判定された 6 問だけが Claude Opus に振られ、残り 14 問は gpt-5-4 に集中しました。tolerance を 0.05 から 0.20 へ動かしていくと、gpt-5-4 → gpt-5-2 → nemotron-3-nano という順に降りていって、0.20 ではほぼ Nemotron で処理される、というふうに連続的に動きます。
UI で同じ動きを 1 問だけ追ってみると、感覚としてつかみやすいです。同じ "What is 2 + 2?" を tol=0.05 で投げると GPT-5.4 ($15/M output) が選ばれ、tol=0.20 で投げ直すと threshold が 0.060 まで下がって、最安帯にいる Nemotron 3 Super ($0/M output) に振り替わります。
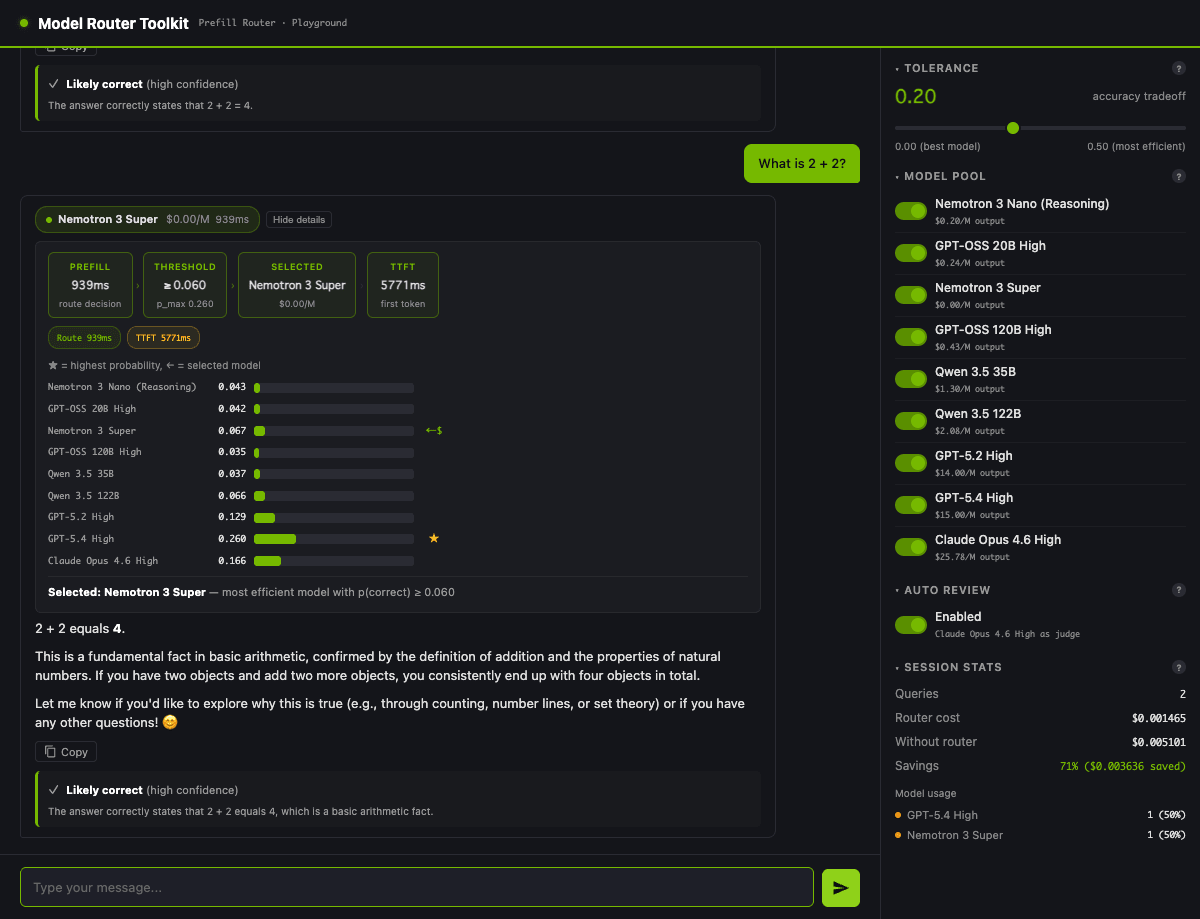
Session Stats の savings が 42% → 71% に伸びているのが、tolerance を 1 段動かした効果です。表で見た 20 問スイープの動きが、1 問だけ追っても実感として見えます。
ここで「LiteLLM だけでもいいのでは?」と気になる方もいると思います。実は LiteLLM にも自動 routing の仕組みは用意されていて、2025 年に追加された AutoRouter では、ユーザーが書いた例文との embedding 類似度で振り分ける Semantic Router と、トークン数や step by step などのキーワードからルールベースで 4 ティアに分類する Complexity Router が選べます。これに加えて従来の cost-based-routing、latency-based-routing、usage-based-routing-v2、provider-budget-limiting と、判定軸ごとに strategy が揃っています。コスト最適化や負荷分散だけが目的なら、LiteLLM 単独でもかなりのところまで届くというのが正直なところです。
v3 がそこからもう一段踏み込んでいるのが、各候補モデルの正解確率を ML で同時推定するアプローチです。LiteLLM 側の Semantic Router は例文を人手で書く必要があり、Complexity Router はルールベースの英語キーワード判定なので、日本語や数式が混じる prompt や、想定外の質問は default にフォールバックします。v3 は DeBERTa-v3 + MLP head で 9 モデル分の P(correct) を出して、tolerance で品質の床を担保したうえで最安を選ぶので、「軽い質問にも Opus を呼ぶ」「数学難問なのに Nano」を両方向で抑えられます。さらに自社データで collect → train → evaluate を回せば、自分たちの問い分布に合わせて再学習できるところも v3 側の強みです。この訓練側の話は Part 2 の訓練編で実際に動かしてみる予定です。
役割としては、v3 が「どのモデルを呼ぶか」を ML で決め、LiteLLM が「実際に呼ぶ」抽象化レイヤーとガードレール/予算管理を担う、という補完関係です。LiteLLM の virtual key、provider-budget-limiting、Aporia や Presidio などとの guardrails 統合は v3 の射程外なので、エンプラ運用ではむしろこの 2 層を重ねる構成が現実的です。「コストとレイテンシを抑えたいだけ」なら LiteLLM 単独でも十分組めますし、「質問内容に応じて品質を守りながらコスト削減したい」「routing 判定の根拠をモデル別 confidence まで残したい」となると v3 を上に積む、というのが整理かなと思っています。
ペルソナを普段 Opus をメインに利用しているユーザーにして削減率を測ってみる
ここからが、組織で導入を検討するときに一番気になるところだと思います。「結局いくら下がるのか」を、ペルソナを設定して実際に測ってみました。
ペルソナの設定は「いつも Claude Opus を呼んでいるユーザー」です。軽い chitchat、コードのデコレータ書き、技術解説、数学の証明、哲学的な問い、と性質の違う 5 問を用意して、Opus に全部投げた場合と、v3 ルーティング経由(default pool のまま)で投げた場合の合計コストを並べました。
| ルート | 合計コスト | All-Opus に対する削減率 |
|---|---|---|
| All Opus 4.6(基準) | $0.0913 | — |
| Routing(tol=0.05) | $0.0193 | 78.8% |
| Routing(tol=0.10) | $0.0198 | 78.3% |
| Routing(tol=0.20) | $0.0014 | 98.5% |
面白いのが、tol=0.05 と tol=0.10 がほぼ同じ削減率(78.8% と 78.3%)に落ち着いているところです。default pool だと中間 tolerance では gpt-5.2 / gpt-5.4 系のクラウドモデルに集中して振られるので、tol を 0.05 動かしても呼び出し先がほとんど変わらない、というのが内訳でした。
tol=0.20 まで上げると、5 問のほぼ全てが nemotron-3-nano-reasoning(pool の最安スロット)に集約されて、Opus 比で 98.5% 削減になります。Nemotron 側のクラウド呼び出し分はゼロにはなりませんが、Opus と比べれば実質ゼロに近い水準です。
冒頭の 5 人チーム想定(月 165,000 リクエスト × output 1,500 トークン)に当てはめてみると、All-Opus で月 6,200 ドル、tol=0.10 routing で月 1,350 ドル前後、tol=0.20 で月 90 ドル前後、と並びます。ここから「品質を落とさずどこまで攻めるか」のチューニングが入る、というのが現実的な使い方になりそうです。
「Reference implementation only」と書かれている default checkpoint のままでここまで来られるのは、個人的には正直予想以上でした。ただ、tol=0.05 と tol=0.10 で削減率が伸びていないところに pool 設計の余地が残っています。次章のローカル混在で、中間 tolerance がどう動くか見ていきましょう。
DGX Spark のローカルモデルを pool に混ぜる
OpenRouter の Auto / Fusion / Pareto と LLM Router v3 の違いが出てくるのはここからです。pool の slot にローカルで動かしている vLLM のエンドポイントを書き込むだけで、クラウドモデルと同じ土俵でルーティング対象に乗ります。
DGX Spark 上の vLLM で Nemotron 3 Nano 30B-A3B の NVFP4 量子化版を --gpu-memory-utilization 0.4 で起動しておいて、configs/ 配下に tier-design 用の YAML を 1 枚作ります。
models:
- name: nemotron-3-nano-reasoning # slot 1 をローカルに差し替え
api_base: http://localhost:8000/v1
api_key_env: LOCAL_KEY
model_name: nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4
cost_per_m_input_tokens: 0
cost_per_m_output_tokens: 0
- name: gpt-5-2-high # slot 7 を Kimi K2.7 Code に
api_base: https://openrouter.ai/api/v1
api_key_env: OPENROUTER_API_KEY
model_name: moonshotai/kimi-k2.7-code-20260612
# ...
- name: gpt-5-4-high # slot 8 を GLM 5.2 に
model_name: z-ai/glm-5.2-20260616
# ...
slot は default のままなので訓練済み MLP の selection logic はそのまま使えて、実際の呼び出し先だけが差し替わります。/v1/chat/completions のレスポンスを見ると、model フィールドにちゃんと nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 や z-ai/glm-5.2-20260616 が記録されていて、「同じ slot 名のまま実体だけが差し替わる」のが見て分かります。
機微な情報を含む軽い質問はローカルに落として、外部公開可なら新興クラウドモデル、難問だけ Opus へ、というデータ主権の設計が、pool config 1 枚で組めるところがエンプラ要件と相性のいいところだと思います。OpenRouter Auto や Pareto の pool は OpenRouter 内部のモデルに閉じているので、この「オンプレ + クラウド混在」は v3(と、v3 のような self-host 型のルータ)の独壇場です。
この混在 pool で章 7 と同じ 5 問を再度投げてみると、削減率がこう変わりました。
| ルート | 合計コスト | All-Opus に対する削減率 |
|---|---|---|
| All Opus 4.6(基準) | $0.0859 | — |
| Routing(tol=0.05、混在) | $0.0211 | 75.4% |
| Routing(tol=0.10、混在) | $0.0110 | 87.2% |
| Routing(tol=0.20、混在) | $0.0000 | 100% |
章 7 の default pool では tol=0.05 と tol=0.10 が両方とも 78% 台で頭打ちでしたが、混在 pool に組み替えると tol=0.10 が 87.2% まで伸びました。差し替えた Kimi K2.7 Code と GLM 5.2 が中量クエリ帯を受け持つようになって、gpt-5.2 / gpt-5.4 に集中していた呼び出しがコストの安い新興モデル側に流れた結果です。tol=0.20 ではほぼすべてローカル Nemotron に集約されて、クラウド側コストが文字通り 0 ドルになります。
レイテンシ面も気になるところなので、軽量な chitchat と重量な philosophy の 2 問で 3 回ずつ計測してみました(各中央値)。
| 質問 | Claude Opus 4.6 | ローカル Nemotron |
|---|---|---|
| chitchat_ja(軽量) | 3.87 秒 | 3.37 秒 |
| philosophy(重量) | 6.08 秒 | 30.02 秒 |
軽量側はほぼ同等、というかローカルがわずかに速いのですが、重量側では逆転して Nemotron の方が 5 倍遅くなりました。これは prompt の Discuss the Chinese Room argument in 100 words. に対して Opus が 138 トークン前後で簡潔に返したのに対し、Nemotron は 1,600 〜 2,100 トークンの長文を返したのが効いています。「instruction-following で 100 words 制約を守るか」の差が、そのまま体感レイテンシに出てくる、というのは pool 設計時に意識しておきたいポイントかなと思っています。
ルーティング判定をどう監査するか
エンプラ採用を検討するときに必ず聞かれるのが、ルーティング判定の監査性です。「どの質問が、なぜそのモデルに振られたのか」をログで追えるかどうかが、コンプライアンスや事故の事後分析で効いてきます。
v3 が返す RoutingResult には、選択されたモデルだけでなく、pool 全体の confidence、cost 見積もり、レイテンシまで全部入っています。これをそのまま観測基盤に流せば、「軽い質問にも Opus を呼んでしまっていた」のような事故も後から検出できます。
Langfuse 側に流すなら、langfuse.start_span() の中で router.route() を呼んで、selected_model と confidences を metadata に積むだけで、後からダッシュボードでフィルタできます。tolerance ごとの分布、月次の cost drift、ペルソナ別の Opus 比率、といった粒度で見られると運用判断が早くなります。
OpenRouter Auto との対比でいうと、Auto は NotDiamond の判定根拠がブラックボックスなので、「なぜそのモデルが選ばれたのか」は事後に再現できません。v3 は 9 モデル分の P(correct) を全部記録できるので、エンプラ要件で「routing 判定の根拠の保存義務」がある場合は、v3 を選ぶ動機がここで立ちます。地味にありがたいですね。
ここから一歩進めて、ログを時系列で眺めると「同じ質問群の selected_model 分布が時間経過で変わってきている」routing drift や、「pool model 別の cost 比率が当初想定からズレてきている」cost drift といった、再訓練のタイミングを判断する指標が見えてきます。このあたりの運用面は、続編の Part 2 で考え方を提示する予定です。
OpenAI 互換 endpoint としてアプリから呼ぶ
ここまで routing service の挙動と監査の話を見てきましたが、実際にアプリやエージェントから呼び出すときの繋ぎ方にも軽く触れておきます。
v3 の model-router serve が公開する /v1/chat/completions は OpenAI 互換です。messages 配列をそのまま受け取り、{ id, choices, model, usage } の OpenAI スタイルでレスポンスを返してくれます。リクエスト時の model は pool config に書いた policy 名(default checkpoint なら default、自分で組んだ混在 pool に別の名前を付けていればその名前)を指定するだけで、内部で MLP が走って実モデルへ転送されます。
curl -X POST http://<DGX_SPARK_IP>:8202/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "default",
"messages": [
{"role": "user", "content": "What is 2+2?"}
],
"tolerance": 0.10
}'
レスポンスの model フィールドには、ルーティングされた実際の呼び出し先(たとえば nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 や anthropic/claude-opus-4-6)が入ってきます。tolerance は v3 が OpenAI 互換に独自拡張しているパラメータで、付けなければデフォルト値が使われます。
OpenAI SDK や LiteLLM、OpenCode のような OpenAI 互換クライアントを採用しているコーディングエージェントなら、BASE_URL を http://<DGX_SPARK_IP>:8202/v1 に切り替えるだけで、ふだん使っているツールがそのまま routing service 経由になります。pool の中で何が動いているかは、クライアント側からは意識せず、ルータが裏で勝手に振り分けてくれる、というのが OpenAI 互換であることの嬉しいところですね。
ひとつ注意点があって、Claude Code は /v1/messages(Anthropic 形式)でリクエストを送るため、/v1/chat/completions をそのまま向けても繋がりません。Anthropic 互換のシム(LiteLLM proxy の passthrough 機能など)を挟む構成になります。
まとめ
モデルの値段が上がってきて、組織でスケールしたときに用途別の使い分けが現実的な話になってきました。SaaS の OpenRouter Auto / Fusion / Pareto は手軽ですが、ルーティング判定の根拠の可視化、shortlist の凍結、オンプレモデルの混在、自分のデータでの再訓練、というあたりが要件に入ってくると、self-host の NVIDIA LLM Router v3 が候補に上がります。
実機で動かしてみると、default checkpoint のままでも Opus 専属ユーザー想定で 75 〜 87% のコスト削減が出ました。tolerance = 0.20 まで上げてローカル Nemotron に集約すると 100%、つまりクラウド API への支払いが 0 ドルになる構成も作れます。tolerance の振り方でコストと品質のバランスが滑らかに変わるので、組織のリスク許容度に合わせて段階的に攻められるところが、実装視点では使い勝手のいいところでした。
ただ、default checkpoint には限界もあって、9 モデル pool の slot 順序ベースで訓練済みの MLP に挙動が支配されています。新興モデル群(Claude Opus 4.8 / GPT-5.5 / Kimi K2.7 Code / DeepSeek V4 / Qwen 3.7 / GLM 5.2 など)を pool に加えても、訓練時のシグナルにない以上、自分のユースケースで一番活きるモデルが選ばれているとは限りません。ここを本質的に解決するには、collect → train → evaluate の training pipeline で自分色のチェックポイントを作る、という選択肢が出てきます。500 質問規模なら 5 〜 25 ドルと半日で済む試算なので、ペルソナの月次削減で 1 か月以内に回収できる範囲かなと思っています。
それと、README が "Reference implementation only. For production deployment, please fork this repository" と明示している通り、v3 は「自分で fork して、自分のユースケースに合わせる」のが本来の使い方です。本記事の検証中も OpenAI 互換 endpoint まわりで改善ポイントがいくつか見つかったので、続編の Part 2 では fork 後の serve コードに最小限の改善を当ててから、ペルソナ訓練編に入っていきます。
Reference implementation only と言いつつ、ここまで遊べる v3、方向性としてはかなり面白いですね。
参考リンク
NVIDIA LLM Router
- NVIDIA-AI-Blueprints/llm-router (GitHub) — 本記事で扱った v3 ブランチを含むリポジトリ。
v3チェックアウトで本記事と同じ環境になります - LLM Router: Rethinking Routing with Prefill Activations (arXiv 2603.20895) — Encoder の hidden states から各モデルの P(correct) を推定する prefill-based routing の論文
OpenRouter の各種 Router
- OpenRouter Auto Router —
openrouter/autoで呼べる NotDiamond ベースの自動ルータ - OpenRouter Fusion Router — 複数モデルの協議+ judge による品質向上型
- OpenRouter Pareto Router — Artificial Analysis の coding percentile を使う tier 型
LiteLLM
- LiteLLM Routing —
cost-based-routinglatency-based-routingusage-based-routing-v2ほかの strategy 一覧 - LiteLLM Auto Routing — 2025-07 に追加された AutoRouter (Semantic + Complexity) のドキュメント
- aurelio-labs/semantic-router — LiteLLM AutoRouter (Semantic) が内部で使う semantic routing ライブラリ









