
I tried anomaly detection for industrial sensors with SKAB and time series foundation models
This page has been translated by machine translation. View original
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Division.
In my previous article Comparing Time Series Foundation Models Running on DGX Spark, I compared Chronos-2 and TimesFM 2.5 in terms of prediction accuracy, latency, and context scaling on the ETTh1 benchmark. Near the end of that article, I briefly touched on the topic of "whether anomaly detection would work if time series foundation models were applied to manufacturing PLC data" in just one paragraph, and my motivation this time is to dig deeper into that with real data.
I chose SKAB (Skoltech Anomaly Benchmark) as the subject. It contains 8-sensor time series recorded on an industrial pump testbed, with manually labeled real anomaly intervals. In the previous anomaly detection simulation, I was artificially injecting Spike / Level shift / Noise burst patterns, but this time I observe how models react to anomaly patterns derived from actual equipment.
The validation ran Chronos-2 (28M / 120M) and TimesFM 2.5 (200M) on DGX Spark, measuring ROC AUC / F1 / FAR / MAR across all 34 datasets.
Overview of the SKAB Dataset
SKAB is an open dataset published on GitHub by Skoltech (Skolkovo Institute of Science and Technology). The license is GPL-3.0, and the data structure is as follows.
- 34 labeled CSV files (
valve1/16 files,valve2/4 files,other/14 files) + 1anomaly-free.csv - Each CSV has approximately 1,000 rows (about 16 minutes) at 1 Hz sampling, totaling 37,401 rows
- 8 sensor columns (vibration acceleration ×2, current, voltage, pressure, body temperature, fluid temperature, flow rate) +
anomalylabel +changepointmarker - Overall anomaly rate is 34.9%, with 129 changepoints
For reference, looking at the 8-sensor time series of valve1/0.csv, it looks like this. The red band indicates labeled anomaly intervals.
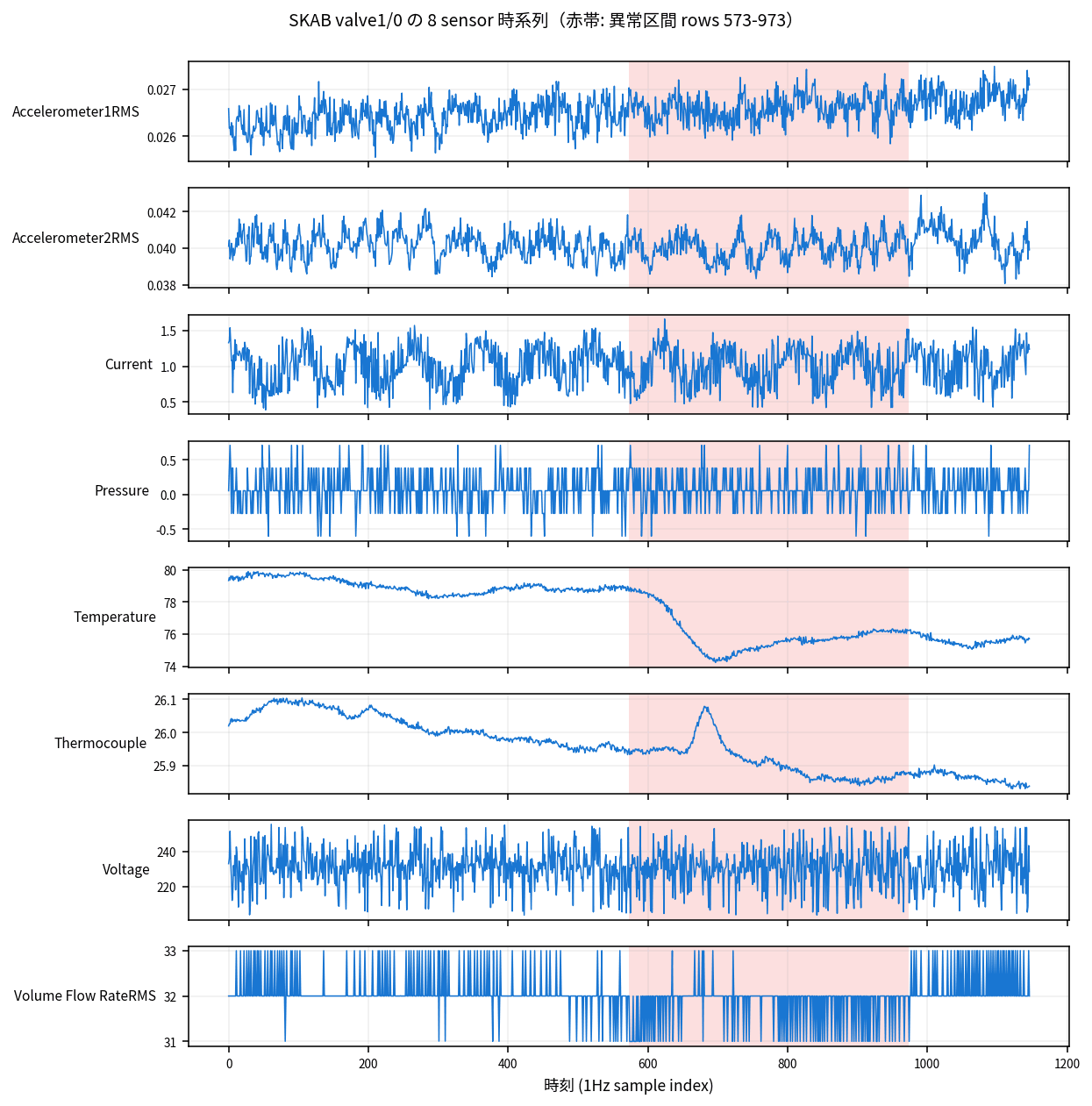
You can see that Voltage is on a ~230V scale and Accelerometer is on a ~0.03 scale, with about 4 orders of magnitude difference between sensors. As I'll touch on later, how to absorb this scale difference is directly linked to anomaly detection accuracy.
In the anomaly interval (rows 573-974), Temperature and Thermocouple gradually rise, Volume Flow Rate fluctuates irregularly, and Voltage remains nearly normal. "Complex behavioral changes that are hard to notice by looking at a single sensor alone" is a pattern commonly seen in SKAB anomalies.
Validation Approach
The anomaly detection flow was structured as follows.
- Learn per-sensor z-score scalers from the section without anomalies at the beginning of each dataset (the interval where leading
anomaly=0values are consecutive) - Use
sliding_windows(context_len=256, horizon=16, stride=16)to extract context and horizon, assigning true value labels corresponding to the horizon as "1 if there is at least one anomaly in the interval" - Generate horizon interval predictions with each model and compute per-sensor residuals in z-score space
- Aggregate per-sensor residuals into a single anomaly score using one of
mean / max / pca - Evaluate ranking ability with ROC AUC, and compute F1 / FAR / MAR at the best-F1 threshold
The reason for listing 4 evaluation metrics is that in manufacturing anomaly detection, the balance between miss rate (MAR) and false alarm rate (FAR) is the key to practical operation. F1 combines both into one value, and ROC AUC represents threshold-independent ranking performance, making them easy to interpret.
Z-score normalization was added to absorb Voltage dominance. If aggregating with raw MSE, only Voltage MSE would be on the ~100 order while other sensors are on the ~0.01 order, causing other sensor anomalies to be invisible when pulled by that single Voltage reading. By standardizing per sensor, residuals from any sensor can be discussed on the same scale.
To ensure reproducibility, np.random.seed(0) and torch.manual_seed(0) were fixed, and each cell was run twice independently to obtain the standard deviation of AUC. The design adds a third run for datasets exceeding a threshold of 0.05. As a result, std > 0.05 was 0 cases across all 4 cells × 34 datasets, and both Chronos-2 and TimesFM 2.5 showed very stable results.
Validation Pipeline Overview
The overall flow from data ingestion to aggregation and evaluation can be summarized in one diagram as follows.
Anomaly Detection with Chronos-2
Chronos-2 returns predictions for multiple sensors at once via AWS's pipeline.predict_quantiles((1, n_var, ctx)). I measured latency and accuracy across all 34 datasets for a "multivariate mode" that submits all 8 sensors at once versus a "univariate 8-parallel mode" that submits 1 sensor at a time 8 times.
| Model × Mode | AUC Median | min | max | Warm Latency | GPU Memory |
|---|---|---|---|---|---|
| 28M univariate | 0.6103 | 0.234 | 0.942 | 3.7 ms / sensor | 86 MB |
| 28M multivariate | 0.6376 | 0.255 | 0.945 | 4.1 ms / 8 sensor | 88 MB |
| 120M univariate | 0.6351 | 0.244 | 0.952 | 6.5 ms / sensor | 260 MB |
| 120M multivariate | 0.6234 | 0.247 | 0.960 | 7.3 ms / 8 sensor | 264 MB |
What stands out when looking at the numbers is that going multivariate with 28M raises AUC by +2.7 points, while 120M shows a slight regression of -1.2 points. In the previous ETTh1 benchmark, "120M shows -7% OT MASE with multivariate" was also observed, so this is consistent as a trend — suggesting that the capacity-rich 120M is sufficient univariate, while the smaller 28M benefits from cross-channel attention.
On the latency side, the picture is even clearer. When processing 8 sensors per window, going multivariate reduces 28M from 30 ms (8 parallel univariate) to 4.1 ms, and 120M from 52 ms to 7.3 ms — about a 7x speedup in both cases. The mechanism of returning predictions for all 8 sensors in a single forward pass pays off directly, making multivariate mode not just cost-neutral but actually a net positive.
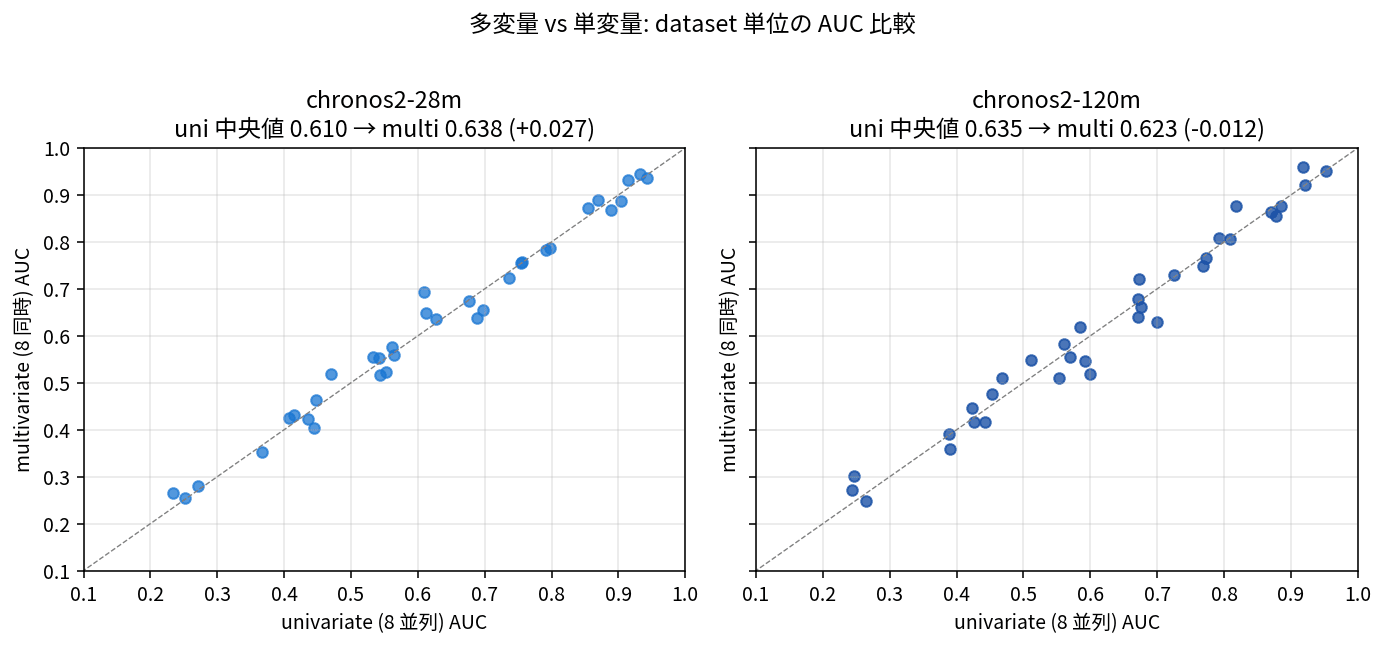
Against a PLC scan cycle budget (typically 100 ms to 1 second), the 4.1 ms of Chronos-2 28M multivariate offers more than 25x headroom. GPU memory is also around 88 MB, so it fits comfortably on edge devices at the level of Jetson Orin Nano. Among the 34 datasets, 28M multivariate outperforms 120M multivariate in 18 of them, so there seems to be no reason to dismiss 28M when considering edge deployment.
Anomaly Detection with TimesFM 2.5
TimesFM 2.5's forecast(inputs=[1Darray]) is a univariate-only API that takes a list of 1D inputs. For multivariate use, residuals from independently predicting 8 sensors must be aggregated downstream into a single score. I compared three aggregation strategies: mean / max / pca.
| Aggregation Strategy | AUC Median | min | max | Expected Use Case |
|---|---|---|---|---|
| mean | 0.7723 | 0.328 | 0.898 | Situations where all sensors show anomaly uniformly |
| max | 0.6923 | 0.364 | 0.830 | Situations where a single-sensor sudden spike is the main cause |
| pca | 0.5538 | 0.216 | 0.875 | Situations where periodic correlation structure breaks (theoretically) |
Looking at the numbers, mean pulls ahead by a clear margin with a median of 0.77, standing out from the rest. Max is good at capturing sudden spikes from a single sensor, but its weakness against noise showed. PCA theoretically targets "anomalies that deviate from the normal correlation structure," but with SKAB's dataset size (about 30-60 windows per dataset), the estimation of the first principal component tends to be unstable, resulting in even lower AUC than max.
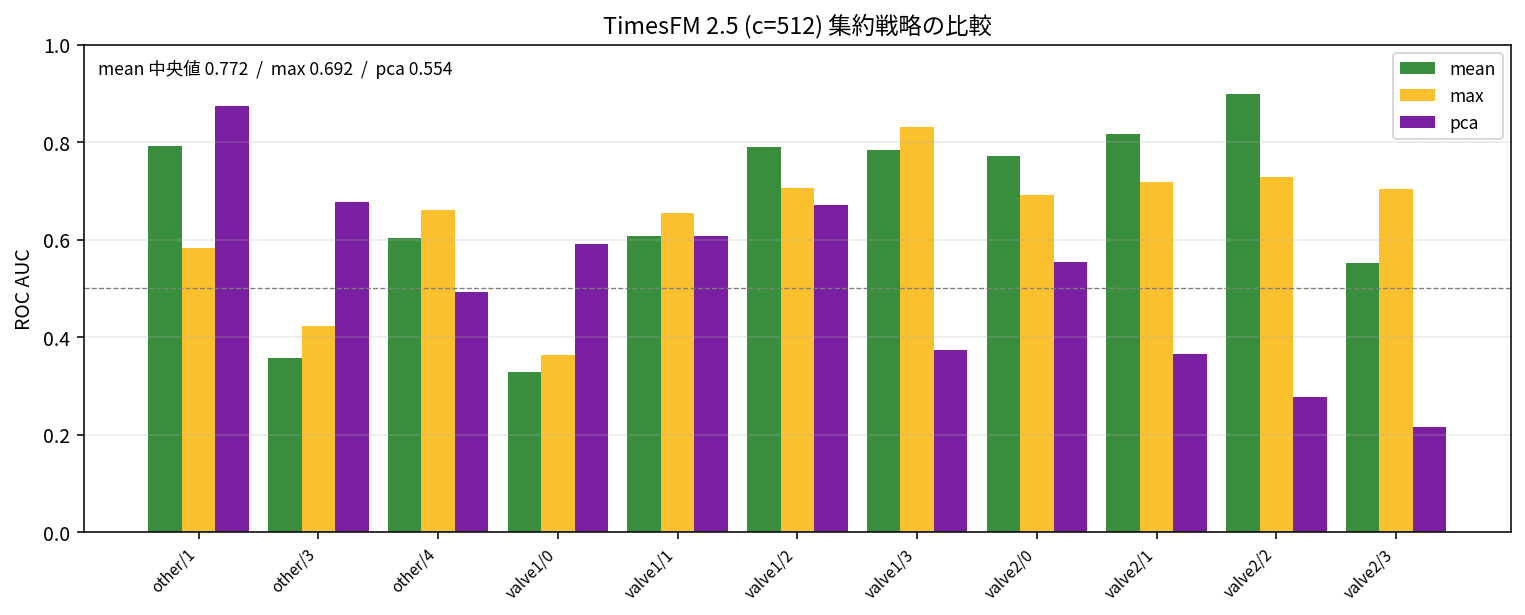
However, looking at the per-dataset distribution, pca tops all three strategies at 0.875 for other/1, and also performs reasonably well at 0.678 for other/3. The overall picture is mean winning decisively on average, while other strategies land better in specific cases — a case-by-case pattern common in manufacturing anomaly detection.
The next question is how far back to look, i.e., context scaling. A single SKAB dataset is about 1,000 rows (about 16 minutes). I compared TimesFM 2.5 running with context lengths of 128 (about 2 minutes) and 512 (about 8 minutes). In the previous parent article, extending to c=15,360 improved MASE by 30%, so I expected "longer context should always be better for anomaly detection too," but in short, it wasn't that simple.
| context | AUC Median (mean aggregation) | std | Number of evaluable datasets |
|---|---|---|---|
| c=128 | 0.6822 | 0.162 | 12 |
| c=512 | 0.7723 | 0.182 | 11 |
Overall, c=512 wins by about +0.06, but per-dataset reversals appear.
| dataset | c=128 | c=512 | Δ | Interpretation |
|---|---|---|---|---|
| valve1/0 | 0.5426 | 0.3284 | -0.214 | Short context is advantageous |
| valve2/3 | 0.7324 | 0.5520 | -0.180 | Short context is advantageous |
| other/1 | 0.4231 | 0.7917 | +0.369 | Long context is essential |
| valve1/2 | 0.6523 | 0.7902 | +0.138 | Long context is advantageous |
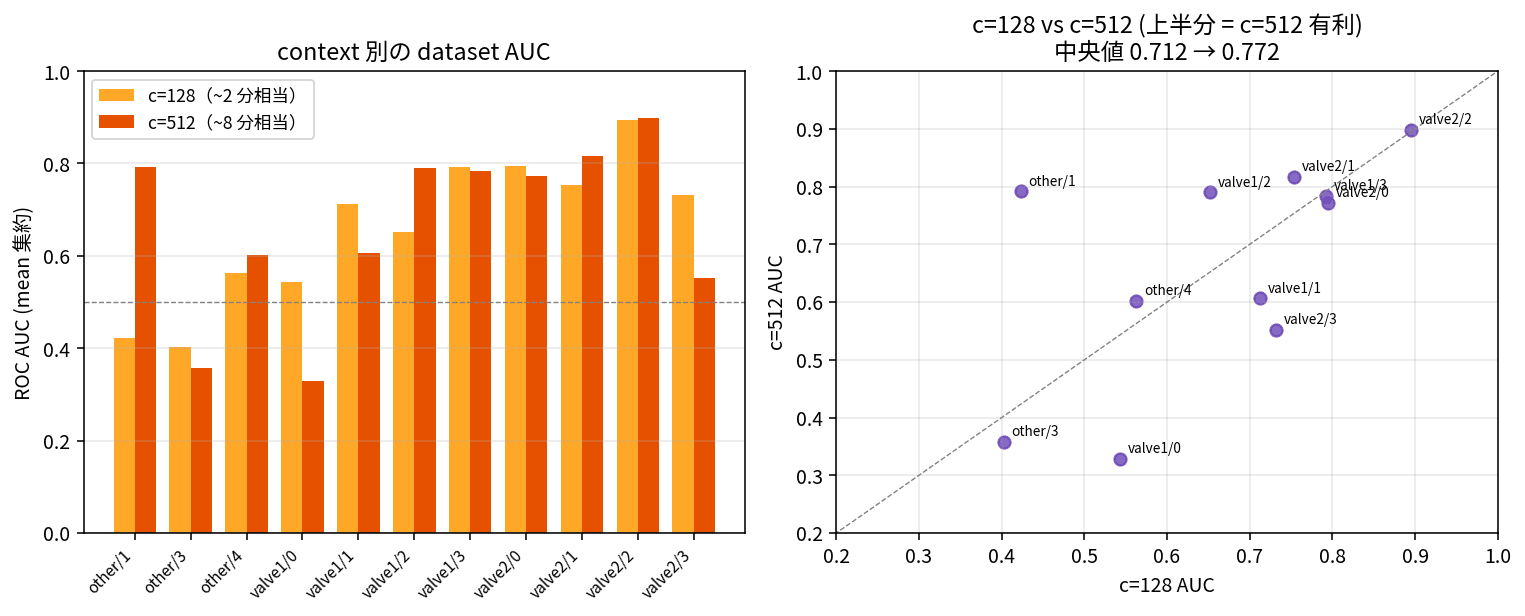
Translated into manufacturing context, short context is suitable for instantaneous anomalies like sudden valve clogging or sharp shifts. On the other hand, long context is essential for long-term trend anomalies like operational cycle disruptions or breakdowns of periodicity — these would be missed with c=128, dismissed as "just the usual." Running short-context and long-context models in parallel and combining both anomaly scores as an ensemble naturally emerges as an option.
I also tried c=2048, but even the longest SKAB dataset has only 1,328 rows, which doesn't satisfy the constraint context + horizon ≤ T, making all datasets unevaluable. At SKAB's scale, comparing c=128 and c=512 is the practical range.
Choosing Between the 3 Models
Having examined Chronos-2 and TimesFM 2.5 individually, let me now line them up on the same 11-dataset subset. Since the TimesFM side sampled 12 datasets due to inference cost constraints (other/2 was excluded as no positive labels appeared), I also recalculated AUC medians for Chronos-2 restricted to these 11 datasets.
| Cell | AUC Median | std | min | max | Warm Latency | GPU Memory |
|---|---|---|---|---|---|---|
| chronos2-28m univariate | 0.5648 | 0.196 | 0.251 | 0.942 | 3.7 ms / sensor | 86 MB |
| chronos2-28m multivariate | 0.5602 | 0.191 | 0.255 | 0.937 | 4.1 ms / 8 sensor | 88 MB |
| chronos2-120m univariate | 0.5926 | 0.192 | 0.244 | 0.921 | 6.5 ms / sensor | 260 MB |
| chronos2-120m multivariate | 0.5557 | 0.189 | 0.272 | 0.921 | 7.3 ms / 8 sensor | 264 MB |
| TimesFM 2.5 mean (c=512) | 0.7723 | 0.182 | 0.328 | 0.898 | 229 ms / sensor | 944 MB |
| TimesFM 2.5 max (c=512) | 0.6923 | 0.131 | 0.364 | 0.830 | Same as above | Same as above |
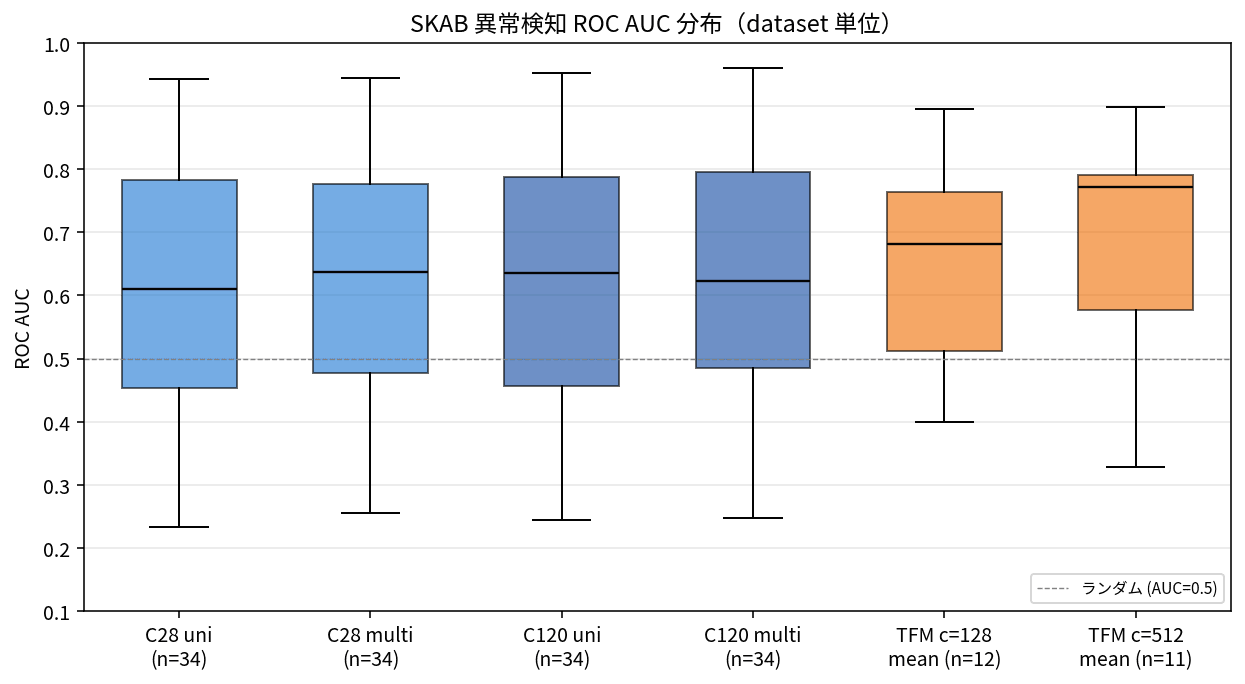
TimesFM 2.5 mean outperforms each Chronos-2 model by +18 to +22 AUC points (a relative improvement of +30 to +39%). However, tracking per-dataset results reveals that the two models differ considerably in how they capture anomalies.
| dataset | C28 multi | C120 multi | TFM mean | Pattern |
|---|---|---|---|---|
| valve2/1 | 0.43 | 0.42 | 0.82 | Hard case that TimesFM captures |
| valve2/3 | 0.26 | 0.27 | 0.55 | Same as above |
| valve1/0 | 0.52 | 0.56 | 0.33 | Only Chronos-2 captures |
| other/4 | 0.79 | 0.81 | 0.60 | Same as above |
| valve2/2 | 0.94 | 0.92 | 0.90 | Both models perform well |
To summarize broadly: TimesFM roughly doubles AUC on hard cases where Chronos-2 completely fails (valve2/1, valve2/3), while Chronos-2 maintains mid-range or better on cases where TimesFM drops like valve1/0 and other/4. The results are consistent with the hypothesis that "TimesFM handles long-term trend anomalies, Chronos-2 handles short-term spike anomalies," and an ensemble of both models emerges as the logical next step.
Looking at the latency side, the picture is completely different.
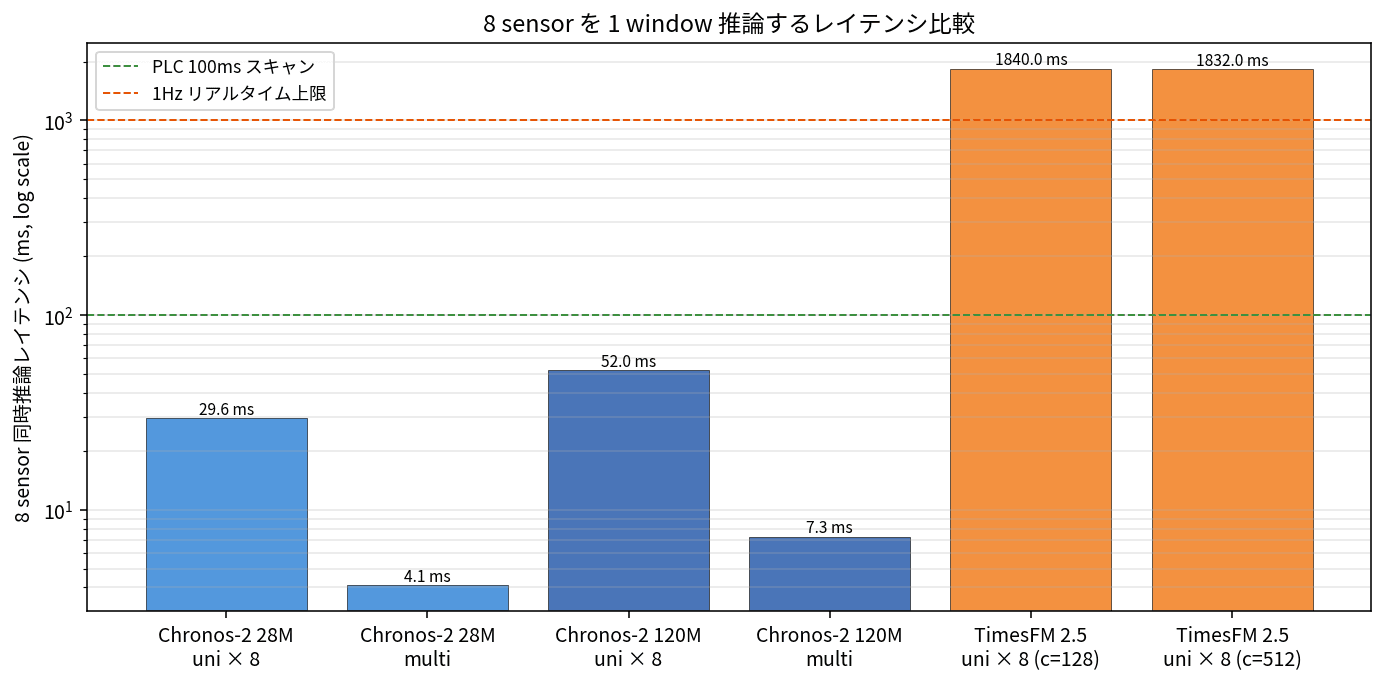
The gap between Chronos-2 28M multivariate (4.1 ms) and TimesFM 2.5 (approximately 1,832 ms) is about 450x. TimesFM wins on accuracy, but it doesn't fit within a PLC scan cycle budget of 100 ms, nor does it meet the 1 Hz real-time judgment limit (1,000 ms upper bound).
The usage guidelines that can be read from this are as follows.
| Scenario | Recommendation |
|---|---|
| Edge deployment (PLC-connected IPC, Jetson, etc.) + real-time judgment | Chronos-2 28M multivariate (4 ms / 88 MB) |
| Factory server (aggregating multiple lines) + medium accuracy | Chronos-2 120M (uni or multi) |
| Server aggregation + accuracy-first (batch judgment OK) | TimesFM 2.5 mean (c=512) (229 ms / 944 MB) |
| Don't want to miss either anomaly type | Ensemble of Chronos-2 28M multi + TimesFM 2.5 mean |
In manufacturing shop floors, a two-stage judgment that does primary judgment at the edge and re-evaluates only suspicious ones on the server side is a standard approach, so placing Chronos-2 28M at the edge and TimesFM 2.5 at the aggregation layer seems like a natural fit.
Detection Example
Numbers alone are hard to visualize, so let me look at how Chronos-2 28M multivariate detects anomalies specifically in valve1/4 (a dataset with AUC 0.87).
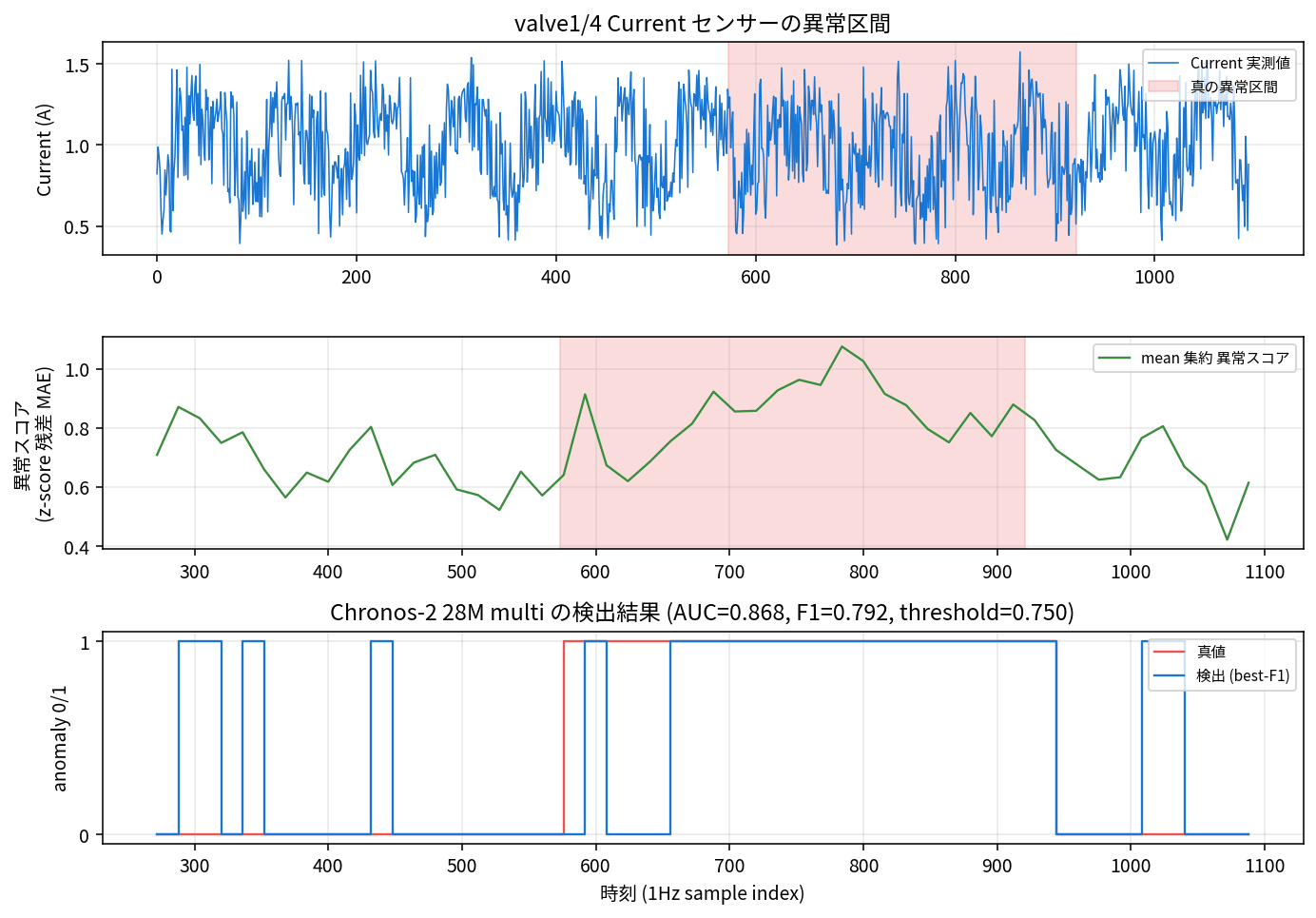
The top panel shows the raw Current sensor signal (red band = true anomaly interval), the middle shows the per-window anomaly score aggregated using mean, and the bottom shows the overlay of 0/1 detection results at the best-F1 threshold against the ground truth. The numbers — AUC 0.868 / F1 0.792 / threshold 0.750 — are respectable for manufacturing anomaly detection.
What's noteworthy is that while the anomaly score forms a clear peak in the true anomaly interval (around rows 600 to 950), several small peaks around 0.5 also appear in the normal interval before it. In reality, it's hard to completely suppress false positives even in noisy normal states, and even with threshold optimization at best-F1, FAR is 3.4% and MAR is 30.4%. If you want to err on the safe side, you'd lower the threshold to increase FAR while suppressing MAR — that trade-off is the discussion point when moving from PoC to production.
Setting Up PLC Real-Time Integration
As a way to reproduce the "PLC → time series model" loop without real PLC hardware, there's the combination of OpenPLC (an open-source PLC emulator) and Node-RED. A configuration that streams SKAB CSV via Modbus TCP and returns anomaly scores from Chronos-2 looks like this.
The latency budget is: PLC scan (1 Hz, 1,000 ms) → InfluxDB write + latest window retrieval (5-20 ms) → Chronos-2 28M multivariate inference (4 ms) → threshold judgment + notification (1-5 ms), with the entire inference pipeline running in 10-30 ms. Even if the scan interval goes up to 100 ms, Chronos-2 28M has no problem; TimesFM 2.5 (1,832 ms) wouldn't make it.
In terms of implementation, three key points to keep in mind to achieve latency close to the 4 ms measured in this article are: maintaining a deque on the Node-RED side is lower latency than fetching 256 rows from InfluxDB each time; the z-score scaler learned from the anomaly-free section should be pre-saved and only applied at inference time; and Chronos-2's multivariate input expects a 3D tensor of shape (1, n_var, ctx).
3-Layer Architecture Combined with SCADA / MES
In actual manufacturing plants, PLCs sit under SCADA, which sits under MES, forming a hierarchical structure, and which layer to place the time series foundation model in depends on the scale of the line. For small scale, it's edge inference directly connected to the PLC; for medium scale, SCADA aggregates data and passes it to the model, which returns anomaly scores to the HMI; for large scale, combining SCADA tags with MES process instructions for multivariate prediction and feeding it back to MES for quality traceability at the process lot level — it scales up in steps.
Applying the model usage guidelines here, a 3-layer architecture can be naturally organized.
The roles are cleanly separated: L1 for immediate alerts, L2 for detailed evaluation via ensemble of both models, and L3 for daily and lot-level rollup analysis. The Cognite × NVIDIA × Celanese case study introduced in Chapter 7 of the previous parent article can also be read as NV-Tesseract playing an active role at L2 / L3, so reading it alongside this article's Chronos-2 / TimesFM 2.5 should make the overall picture of the manufacturing AI stack for 2026 clearer.
Summary
Evaluating whether Chronos-2 and TimesFM 2.5 "work" and "how to use them" on SKAB's real-equipment-derived anomaly data across all 34 datasets revealed roughly the following points.
- Going multivariate is not just cost-neutral — it's a gain. With Chronos-2 28M, going multivariate raises AUC by +2.7 points and speeds up latency by about 7x.
- Models clearly differ in the types of anomalies they handle well. TimesFM 2.5 mean takes the overall lead with a median AUC of 0.77, yet Chronos-2 holds up on datasets it's good at like valve1/0 where TimesFM falls — a complementary relationship.
- Context scaling isn't "longer is better" — switching TimesFM 2.5 between c=128 and c=512 results in reversals with a spread of ±0.37 depending on the dataset.
- Balancing PLC scan cycle budget against accuracy requirements, a 3-layer configuration of edge 28M / server 120M + TimesFM is the practical solution, and the edge layer can directly use Chronos-2 28M multivariate (4 ms / 88 MB).
Once NV-Tesseract (currently at evaluation license stage) becomes available to run locally, I'd like to revisit the comparison with TimesFM 2.5 at the L2 / L3 layers. Reading the Cognite × NVIDIA × Celanese case study's 4-sensor state prediction together with this article's 8-sensor anomaly detection should give a clear picture of the 2026 version of the manufacturing AI stack.
