
SKAB と時系列基盤モデルで産業センサーの異常検知を試してみた
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
以前の記事時系列基盤モデルを DGX Spark で動かして比べてみたでは、Chronos-2 と TimesFM 2.5 の予測精度・レイテンシ・コンテキストスケーリングを ETTh1 ベンチで比べました。記事の終盤で「製造業の PLC データに時系列基盤モデルを乗せたら異常検知が動くか」という話を 1 段落だけ触れていたのですが、ここを実データで掘り下げてみたい、というのが今回の動機です。
題材には SKAB(Skoltech Anomaly Benchmark) を選びました。産業用ポンプ系の testbed で記録された 8 sensor 時系列に、人手でラベル付けされたリアルな異常区間が含まれています。前回の異常検知シミュレーションでは Spike / Level shift / Noise burst を人工的に注入していましたが、今回は実機由来の異常パターンにモデルがどう反応するかを観察します。
検証は Chronos-2 (28M / 120M) と TimesFM 2.5 (200M) を DGX Spark 上で動かして、ROC AUC / F1 / FAR / MAR を 34 dataset 全体で取りました。
SKAB データセットの概要
SKAB は Skoltech (Skolkovo Institute of Science and Technology) が GitHub で公開しているオープンデータセットです。ライセンスは GPL-3.0、データ構造は次のとおりです。
- 34 個のラベル付き CSV ファイル(
valve1/16 個、valve2/4 個、other/14 個)+ 1 個のanomaly-free.csv - 各 CSV は 1 Hz サンプリングで約 1,000 行(約 16 分)、合計 37,401 行
- 8 sensor 列(振動加速度 ×2、電流、電圧、圧力、本体温度、流体温度、流量)+
anomalyラベル +changepointマーカー - 全体の異常率は 34.9%、changepoint は 129 件
参考までに valve1/0.csv の 8 sensor 時系列を眺めてみると、こんな形をしています。赤い帯がラベル付きの異常区間です。
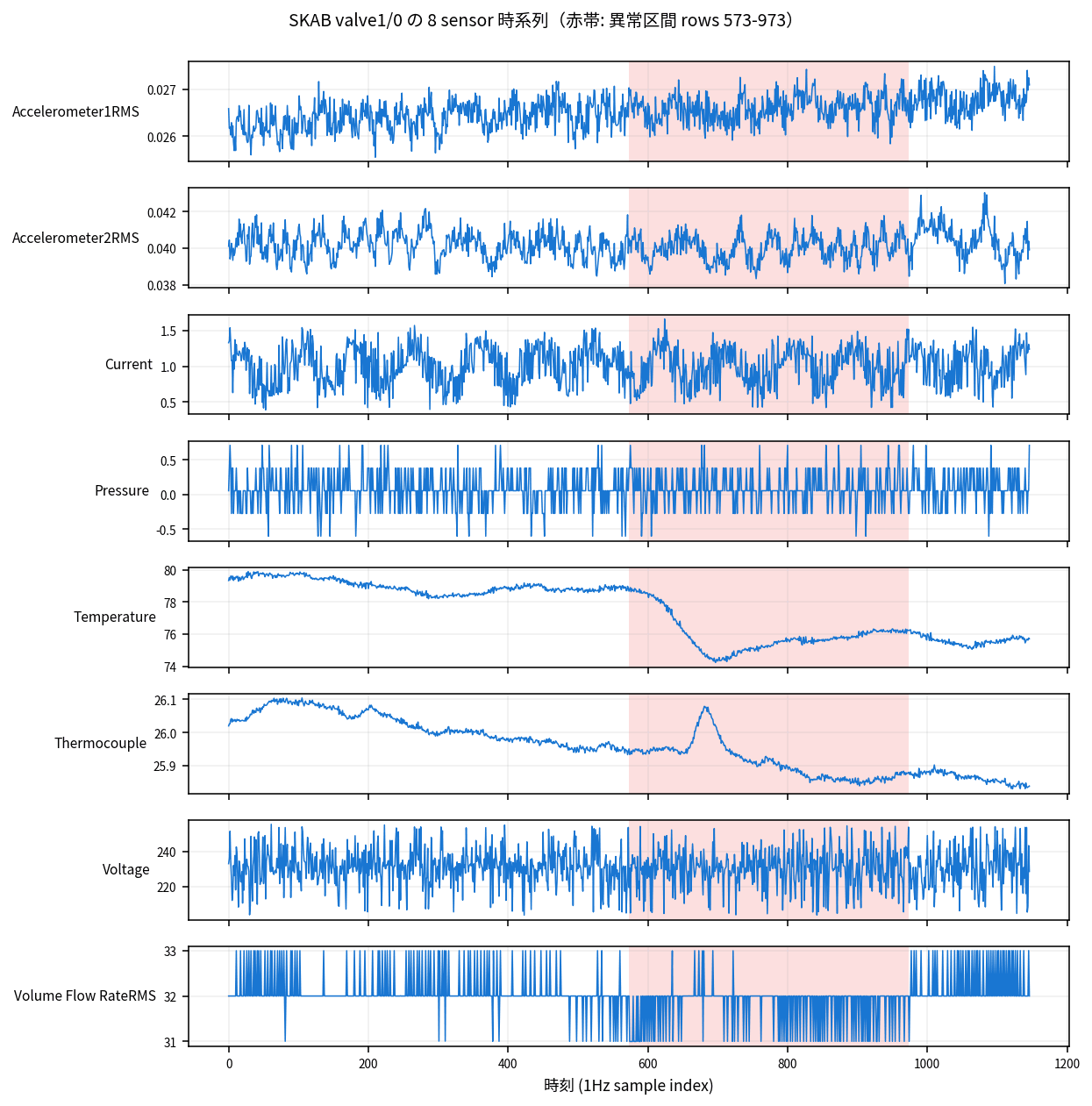
Voltage が ~230V スケール、Accelerometer が ~0.03 スケールと、sensor 間でスケールが 4 桁ほど違うのが分かります。後ほど触れますが、このスケール差をどう吸収するかが異常検知の精度に直結します。
異常区間(rows 573-974)では Temperature と Thermocouple がじわじわ上昇し、Volume Flow Rate が小刻みに荒れて、Voltage はほぼ平常という挙動になっています。「単一センサーだけ見ていても気づきにくい、複合的な挙動の変化」が SKAB の異常パターンとしてよく見られる構図です。
検証方針
異常検知の流れは次のように組みました。
- 各 dataset の異常を含まないセクション(先頭の
anomaly=0が連続する区間)から sensor 別の z-score スケーラを学習 sliding_windows(context_len=256, horizon=16, stride=16)で context と horizon を切り出し、horizon に対応する真値ラベルを「区間内に異常が 1 つでもあれば 1」として割り当てる- 各モデルで horizon 区間の予測値を出し、z-score 空間での残差を sensor 別に計算
- sensor 別の残差を
mean / max / pcaのいずれかで 1 つの異常スコアに集約 - ROC AUC でランキング能力を評価、best-F1 閾値で F1 / FAR / MAR を算出
評価指標を 4 つ並べたのは、製造業の異常検知では見逃し率(MAR)と誤警報率(FAR)のバランスが運用上のキモになるからです。F1 は両者を 1 つにまとめた値、ROC AUC は閾値非依存のランキング性能、と読みやすくなります。
z-score 正規化は Voltage 支配を吸収するために入れました。素の MSE のまま集約すると、Voltage の MSE だけが ~100 オーダー、他の sensor は ~0.01 オーダーで、Voltage 1 本に引っ張られて他の sensor の異常が見えなくなります。sensor 別に標準化することで、どの sensor の残差も同じスケールで議論できるようにしました。
検証の再現性を確保するため、np.random.seed(0) と torch.manual_seed(0) を固定し、各セルを 2 回独立に実行して AUC の standard deviation を取りました。閾値 0.05 を超えた dataset には 3 回目を追加する設計です。結果としては全 4 セル × 34 dataset で std > 0.05 は 0 件で、Chronos-2 系も TimesFM 2.5 もどちらのモデルも結果が非常に安定していました。
検証パイプライン全体像
データ取り込みから集約・評価までを 1 枚にまとめると次のような流れです。
Chronos-2 の異常検知
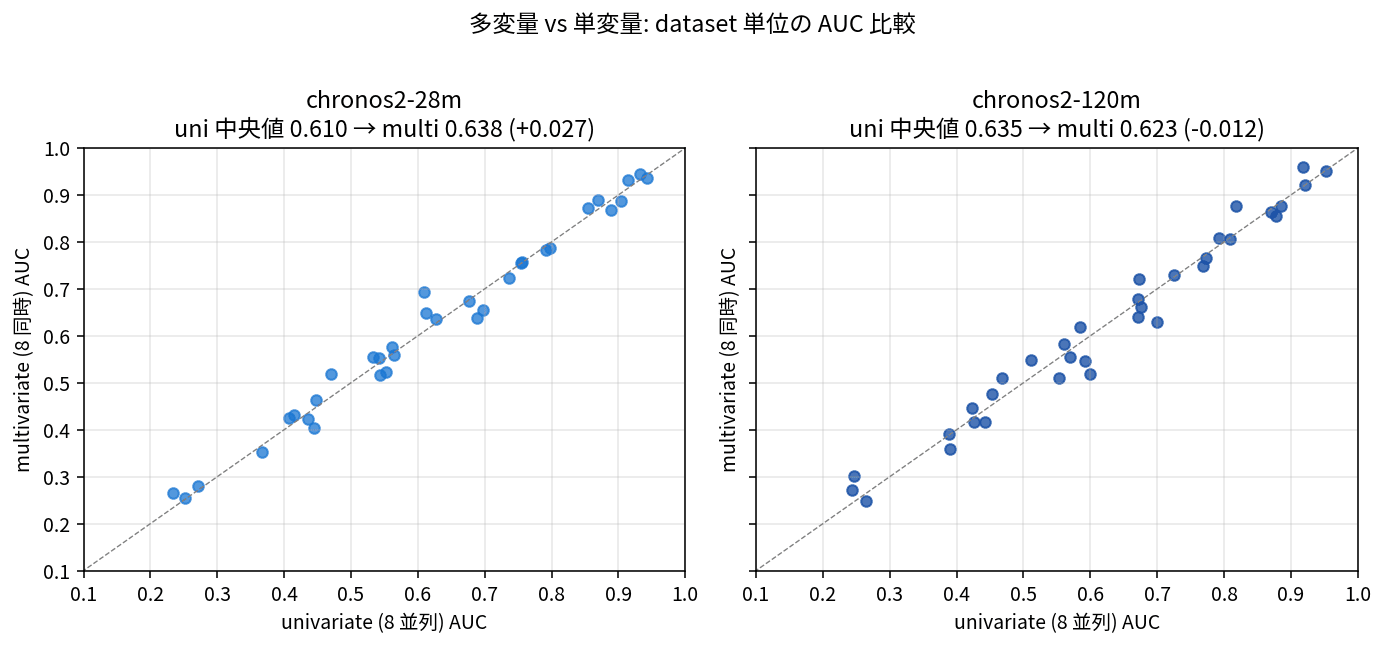
Chronos-2 は AWS が pipeline.predict_quantiles((1, n_var, ctx)) の形で 1 度に複数 sensor の予測を返してくれます。8 sensor をまとめて投げる「多変量モード」と、1 sensor ずつ 8 回投げる「単変量 8 並列モード」で、レイテンシと精度がどう変わるかを 34 dataset 全体で取りました。
| モデル × モード | AUC 中央値 | min | max | warm レイテンシ | GPU メモリ |
|---|---|---|---|---|---|
| 28M univariate | 0.6103 | 0.234 | 0.942 | 3.7 ms / sensor | 86 MB |
| 28M multivariate | 0.6376 | 0.255 | 0.945 | 4.1 ms / 8 sensor | 88 MB |
| 120M univariate | 0.6351 | 0.244 | 0.952 | 6.5 ms / sensor | 260 MB |
| 120M multivariate | 0.6234 | 0.247 | 0.960 | 7.3 ms / 8 sensor | 264 MB |
数字を眺めて目を引くのは、28M で多変量化すると AUC が +2.7 ポイント上がる一方、120M では -1.2 ポイント軽くデグレすることです。前回の ETTh1 ベンチでも「120M は多変量化で OT MASE が -7%」と出ていたので傾向としては整合し、容量に余裕のある 120M は単変量で十分、容量の小さい 28M は cross-channel attention で底上げされる、という構図に見えます。
レイテンシ側はもっと明確です。1 window あたり 8 sensor を処理する場合、28M では単変量 8 並列が 30 ms だったところ多変量化で 4.1 ms に、120M でも 52 ms から 7.3 ms に短縮され、どちらも約 7 倍の高速化です。1 forward pass で 8 sensor の予測を返す仕組みがそのまま効いてくるので、多変量化はノーコストどころかむしろプラスとなりそうです。
PLC スキャンサイクル予算(典型的には 100 ms 〜 1 秒)に対して、Chronos-2 28M multivariate の 4.1 ms は 25 倍以上の余裕があります。GPU メモリも 88 MB 程度なので、Jetson Orin Nano クラスのエッジ機器でも余裕で載るサイズです。34 dataset のうち 18 dataset で 28M multivariate が 120M multivariate を上回っており、エッジ展開を視野に入れる場合に 28M を切り捨てる理由はなさそうです。
TimesFM 2.5 の異常検知
TimesFM 2.5 の forecast(inputs=[1Darray]) は 1D 入力のリストを受け取る univariate-only な API です。多変量を扱う場合、8 sensor を独立に予測した残差を後段で 1 つに集約することになります。集約方法を mean / max / pca の 3 戦略で比較しました。
| 集約戦略 | AUC 中央値 | min | max | 想定が当たる場面 |
|---|---|---|---|---|
| mean | 0.7723 | 0.328 | 0.898 | 全 sensor が均等に異常を示す状況 |
| max | 0.6923 | 0.364 | 0.830 | 単一 sensor の突発スパイクが主因の状況 |
| pca | 0.5538 | 0.216 | 0.875 | 周期的な相関構造が壊れる状況(理論上) |
数字で見ると、mean が他を一段引き離して中央値 0.77 と頭一つ抜けています。max は単一 sensor の突発スパイクを捉えるのは得意ですが、ノイズに弱いという弱点が出ました。pca は理論としては「通常の相関構造から逸脱する方向の異常」を狙えるはずですが、SKAB の dataset サイズ(1 dataset あたり 30-60 window 程度)では第 1 主成分の推定が不安定になりやすく、max よりさらに低い AUC に沈みました。
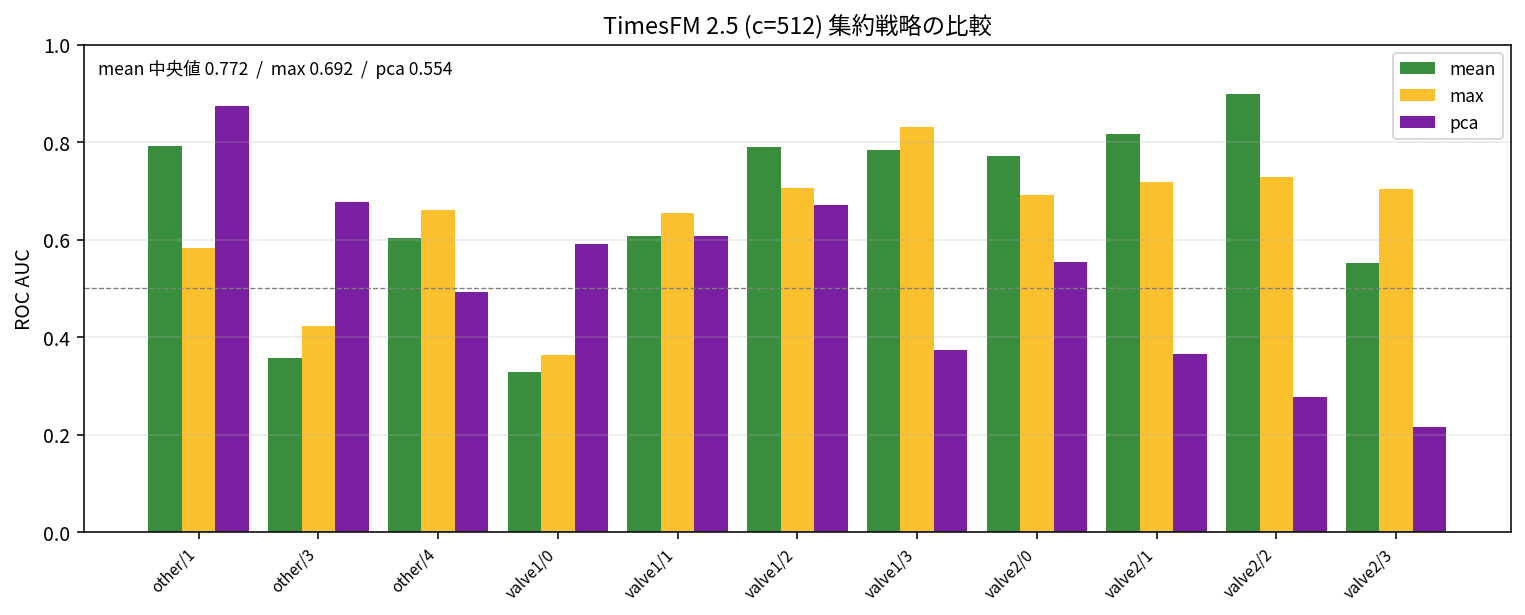
ただし dataset 別の分布を見ると、other/1 では pca = 0.875 で 3 戦略中トップ、other/3 でも pca = 0.678 と健闘するケースがあります。平均では mean が圧勝、個別には他の戦略が刺さるパターンもあるという、製造業の異常検知でよくあるケースバイケースの構図です。
次に気になるのが、過去にどれだけ遡って参照するかという context スケーリングです。SKAB の 1 dataset は約 1,000 行(約 16 分)。TimesFM 2.5 の context を 128(約 2 分)と 512(約 8 分)で動かして比較しました。前回の親記事で c=15,360 まで伸ばすと MASE が 30% 改善したので「異常検知でも長 context が常に有利なはず」と予想していたのですが、結論から言うとそう単純ではなかったです。
| context | AUC 中央値 (mean 集約) | std | 評価可能 dataset 数 |
|---|---|---|---|
| c=128 | 0.6822 | 0.162 | 12 |
| c=512 | 0.7723 | 0.182 | 11 |
全体では c=512 が +0.06 ほど勝つのですが、dataset 別では逆転している組が出てきます。
| dataset | c=128 | c=512 | Δ | 解釈 |
|---|---|---|---|---|
| valve1/0 | 0.5426 | 0.3284 | -0.214 | 短 context が有利 |
| valve2/3 | 0.7324 | 0.5520 | -0.180 | 短 context が有利 |
| other/1 | 0.4231 | 0.7917 | +0.369 | 長 context が必須 |
| valve1/2 | 0.6523 | 0.7902 | +0.138 | 長 context が有利 |
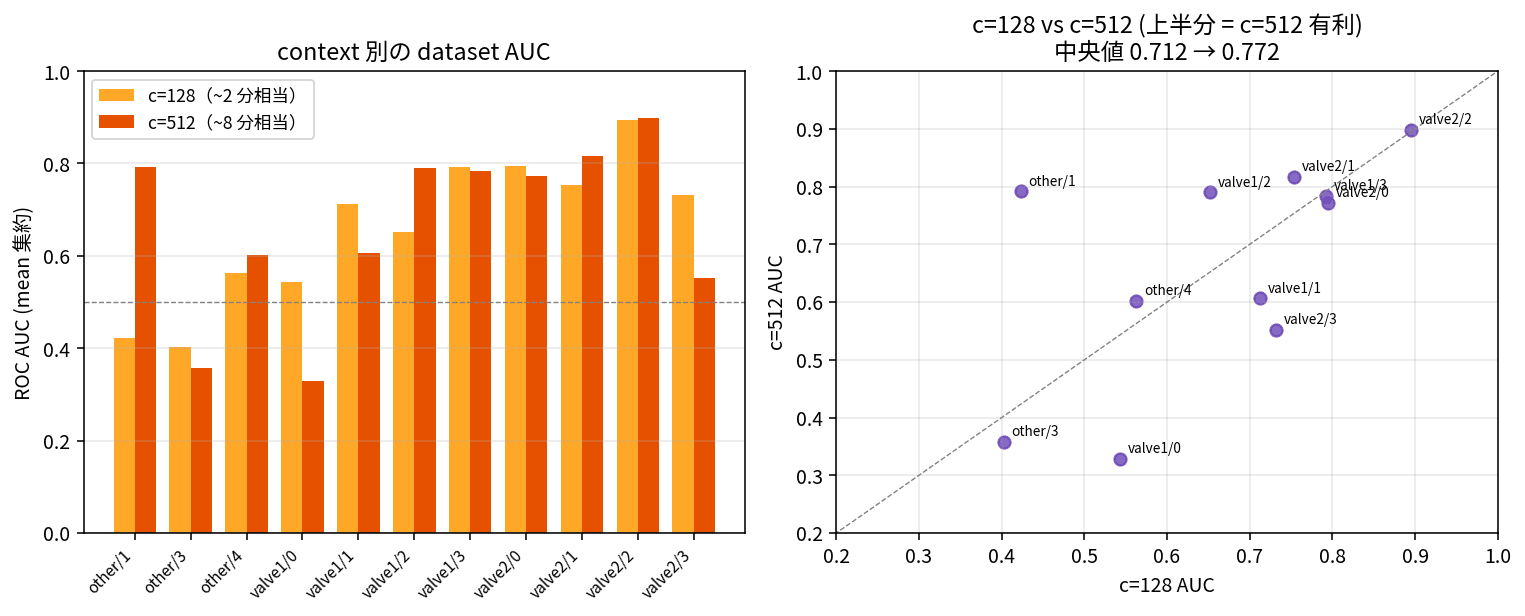
製造業の文脈で読み替えると、突発的なバルブ詰まりや急峻なシフトのような瞬間異常には短い context が向きます。一方で運転サイクルの乱れや周期性の崩れのような長期 trend 系の異常には長 context が必須で、c=128 では「いつもこんなもの」として見逃されてしまいます。短 context と長 context のモデルを並走させて両方の異常スコアを併用するアンサンブル運用が自然な選択肢として浮かびます。
なお c=2048 も試したのですが、SKAB の最長 dataset でも 1,328 行で context + horizon ≤ T の制約に届かず、全 dataset 評価不能でした。SKAB のスケールでは c=128 と c=512 の比較が現実的な範囲です。
3 モデルの使い分け
ここまで Chronos-2 と TimesFM 2.5 を個別に見てきましたが、改めて同じ 11 dataset サブセットで並べておきます。TimesFM 側は推論コストの都合で 12 dataset サンプリング(other/2 は positive label が出ず除外)にしていたので、Chronos-2 側もこの 11 dataset に絞って AUC 中央値を取り直しました。
| セル | AUC 中央値 | std | min | max | warm レイテンシ | GPU メモリ |
|---|---|---|---|---|---|---|
| chronos2-28m univariate | 0.5648 | 0.196 | 0.251 | 0.942 | 3.7 ms / sensor | 86 MB |
| chronos2-28m multivariate | 0.5602 | 0.191 | 0.255 | 0.937 | 4.1 ms / 8 sensor | 88 MB |
| chronos2-120m univariate | 0.5926 | 0.192 | 0.244 | 0.921 | 6.5 ms / sensor | 260 MB |
| chronos2-120m multivariate | 0.5557 | 0.189 | 0.272 | 0.921 | 7.3 ms / 8 sensor | 264 MB |
| TimesFM 2.5 mean (c=512) | 0.7723 | 0.182 | 0.328 | 0.898 | 229 ms / sensor | 944 MB |
| TimesFM 2.5 max (c=512) | 0.6923 | 0.131 | 0.364 | 0.830 | 同上 | 同上 |
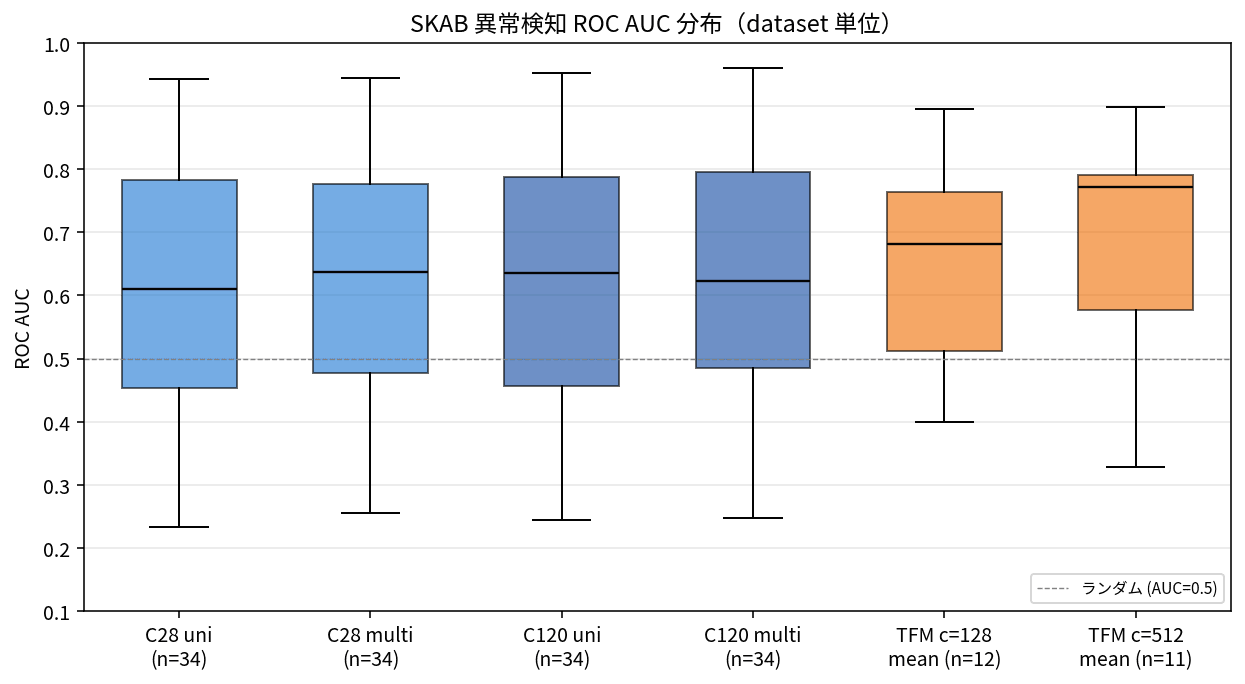
TimesFM 2.5 mean が Chronos-2 各モデルを AUC で +18〜22 ポイント上回る という結果になりました(相対比較では +30〜39%)。ただし dataset 別に追いかけると、両モデルは異常の捉え方がだいぶ違います。
| dataset | C28 multi | C120 multi | TFM mean | パターン |
|---|---|---|---|---|
| valve2/1 | 0.43 | 0.42 | 0.82 | TimesFM が拾う hard ケース |
| valve2/3 | 0.26 | 0.27 | 0.55 | 同上 |
| valve1/0 | 0.52 | 0.56 | 0.33 | Chronos-2 のみが拾う |
| other/4 | 0.79 | 0.81 | 0.60 | 同上 |
| valve2/2 | 0.94 | 0.92 | 0.90 | 両モデル得意 |
ざっくりまとめると、TimesFM は Chronos-2 が全滅する hard ケース(valve2/1, valve2/3)で AUC を 2 倍前後に持ち上げる一方、TimesFM が落ちる valve1/0 や other/4 では Chronos-2 が中位以上をキープしています。「長期 trend 系の異常は TimesFM、短期 spike 系の異常は Chronos-2」という仮説と矛盾しない結果で、両モデルを並べたアンサンブルが次の一手として見えてきます。
レイテンシ側で見ると景色は別物になります。
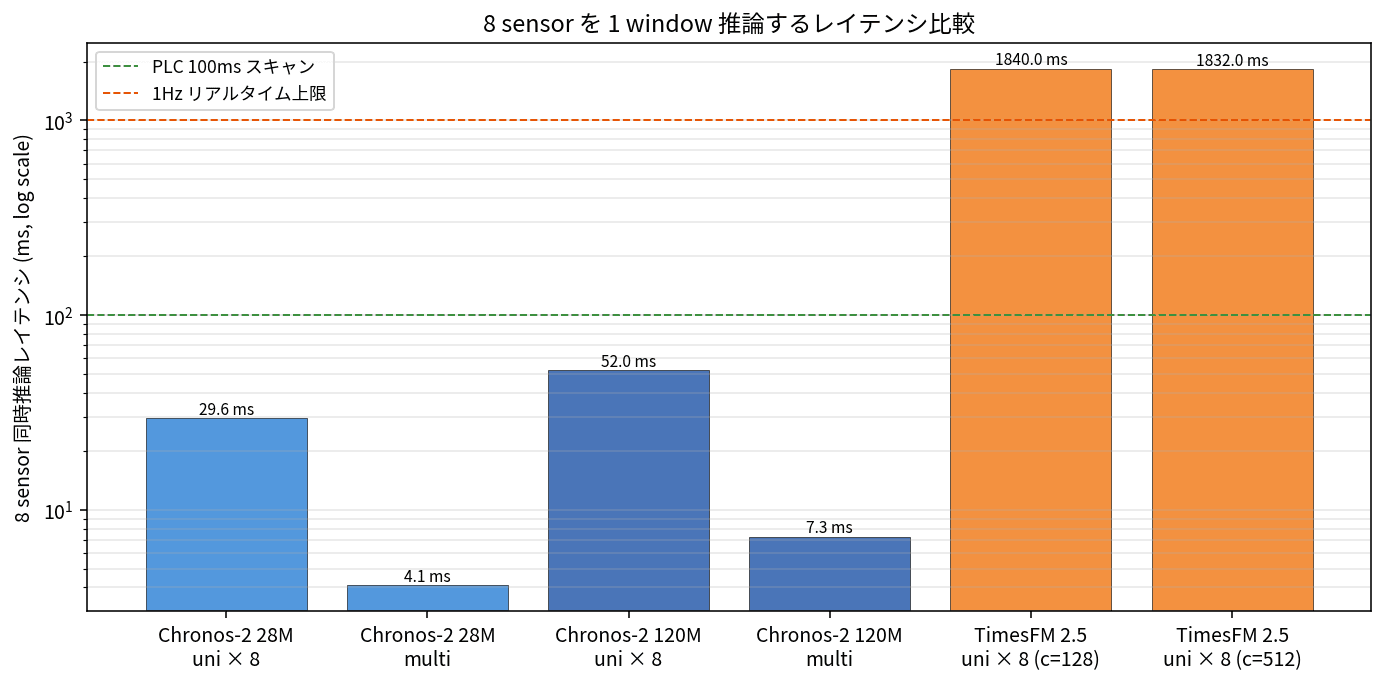
Chronos-2 28M multivariate (4.1 ms) と TimesFM 2.5 (約 1,832 ms) の差は約 450 倍。TimesFM は精度では勝つのですが、PLC スキャンサイクル予算 100 ms には収まらず、1 Hz のリアルタイム判定(1,000 ms 上限)にも届きません。
ここから読み取れる使い分けの目安は次のような形になります。
| シナリオ | 推奨 |
|---|---|
| エッジ展開(PLC 直結 IPC、Jetson 等)+ リアルタイム判定 | Chronos-2 28M multivariate(4 ms / 88 MB) |
| 工場サーバ(複数ラインを集約) + 中精度 | Chronos-2 120M(uni or multi) |
| サーバ集約 + 精度最優先(バッチ判定 OK) | TimesFM 2.5 mean (c=512)(229 ms / 944 MB) |
| 両方の異常タイプを取りこぼしたくない | Chronos-2 28M multi + TimesFM 2.5 mean のアンサンブル |
製造業の現場では、エッジで一次判定して怪しいものだけサーバ側で再評価する 2 段判定が常套手段なので、Chronos-2 28M をエッジに、TimesFM 2.5 を集約層に置く構成が自然な落としどころになりそうです。
検出例
数字だけだとイメージが湧きにくいので、具体的に valve1/4(AUC 0.87 の dataset)で Chronos-2 28M multivariate がどう検知しているかを見ておきます。
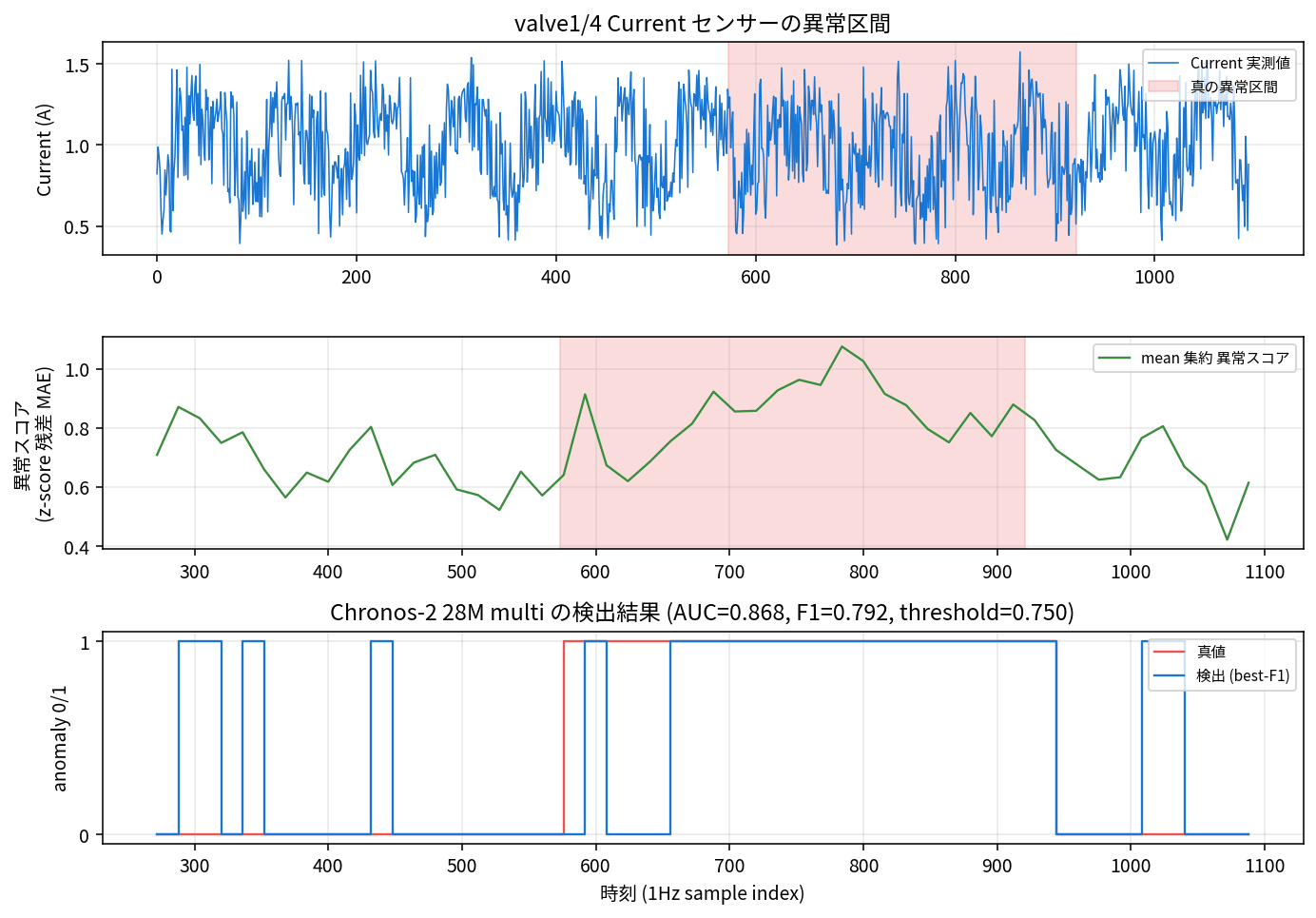
上段が Current センサーの生信号(赤帯が真の異常区間)、中段が mean 集約した window 別の異常スコア、下段が best-F1 閾値での 0/1 検出結果と真値の重ね合わせです。AUC 0.868 / F1 0.792 / threshold 0.750 という、製造業の異常検知としては悪くない数字が出ています。
注目すべきは、異常スコアが真の異常区間(rows 600 〜 950 あたり)でしっかり山を作っている一方で、それ以前の正常区間でも 0.5 付近の小さな山がいくつか出ている点です。ノイズが乗った正常状態でも偽陽性をゼロには抑えにくいのが現実で、best-F1 で閾値を最適化しても FAR は 3.4%、MAR は 30.4% という値になっています。安全側に倒すなら閾値を下げて FAR を増やし、MAR を抑える調整が必要、というあたりがこのまま PoC から本番へつなぐ際の論点になります。
PLC リアルタイム連携の組み方
実機の PLC を用意せずに「PLC → 時系列モデル」のループを再現する手段として、OpenPLC(オープンソース PLC エミュレータ)と Node-RED の組み合わせがあります。SKAB の CSV を Modbus TCP 経由で stream して、Chronos-2 で異常スコアを返す、という構成は次のような形になります。
レイテンシ予算は、PLC スキャン (1 Hz, 1,000 ms) → InfluxDB 書き込み + 直近 window 取り出し (5-20 ms) → Chronos-2 28M multivariate 推論 (4 ms) → 閾値判定 + 通知 (1-5 ms) で、推論パイプライン全体が 10-30 ms で回ります。スキャンが 100 ms に上がっても Chronos-2 28M なら問題なし、TimesFM 2.5 (1,832 ms) では間に合わない計算です。
実装上は、InfluxDB から毎回 256 行取り出すよりも Node-RED 側で deque を維持する方が低レイテンシで済むこと、anomaly-free セクションから学習した z-score スケーラは事前保存して推論時は適用のみにすること、Chronos-2 の多変量入力は (1, n_var, ctx) の 3D tensor を期待することの 3 点を押さえれば、本記事で測った 4 ms に近いレイテンシで運用できます。
SCADA / MES と組み合わせた 3 層構成
実際の製造業の工場では、PLC の上に SCADA、その上に MES が乗る階層構造になっており、時系列基盤モデルをどの層に置くかはライン規模で変わります。小規模なら PLC 直結のエッジ推論、中規模なら SCADA がデータ集約してモデルに渡し HMI に異常スコアを返す形、大規模なら SCADA タグと MES 工程指示を組み合わせた多変量予測を MES に戻して工程ロット単位の品質トレーサビリティに使う、という階段になります。
ここで 3 モデル使い分けの目安を当てはめると、3 層構成が自然に組めます。
L1 で即時警報、L2 で両モデルアンサンブルによる詳細評価、L3 で日次・ロット単位のロールアップ分析、と役割が綺麗に分かれます。前回の親記事章 7 で紹介した Cognite × NVIDIA × Celanese の事例も L2 / L3 で NV-Tesseract が活躍する構図と読めるので、本記事の Chronos-2 / TimesFM 2.5 と組み合わせて読むと製造業 AI スタックの全体像が見えやすくなりますね。
まとめ
SKAB という実機由来の異常データに対して、Chronos-2 と TimesFM 2.5 が「使えるか」「どう使い分けるか」を 34 dataset 全体で評価して見えてきたのは、おおまかに次のような点でした。
- 多変量化はノーコストどころか得。Chronos-2 28M で多変量化すると AUC が +2.7 ポイント上がり、レイテンシは約 7 倍速になります
- モデルで異常タイプの得意不得意がはっきり分かれる。TimesFM 2.5 mean が AUC 中央値 0.77 で総合首位ながら、Chronos-2 が得意な valve1/0 などでは TimesFM が落ちる、という補完関係でした
- context スケーリングは「長ければ良い」ではなく、TimesFM 2.5 で c=128 / c=512 を切り替えると dataset によって ±0.37 の幅で逆転します
- PLC スキャンサイクル予算と精度要件を天秤にかけると、エッジ 28M / サーバ 120M + TimesFM の 3 層構成が現実解で、エッジ層には Chronos-2 28M multivariate (4 ms / 88 MB) がそのまま使えます
NV-Tesseract(評価ライセンス段階)が手元で動かせるようになったら L2 / L3 層での TimesFM 2.5 との対比を改めて取りたいところです。Cognite × NVIDIA × Celanese の事例の 4 sensor 状態予測と、本記事の 8 sensor 異常検知をつないで読むと、製造業 AI スタックの 2026 年版が見えてくるかなと思っています。










