
A GitHub Action has been added to automatically evaluate LLM accuracy in CI with Langfuse
This page has been translated by machine translation. View original
This is Suenaga from the Retail App Co-Creation Division.
A GitHub Action called langfuse/experiment-action has been released by Langfuse, so I decided to try it out.
This time, I set up a CI that evaluates a small multimodal agent using the TypeScript SDK and Vercel AI SDK to call Claude and guess country names from images. I also configured prompts to be managed in Git and automatically reflected in Langfuse's prompts when merging to main.
The verification code used this time can be found here.
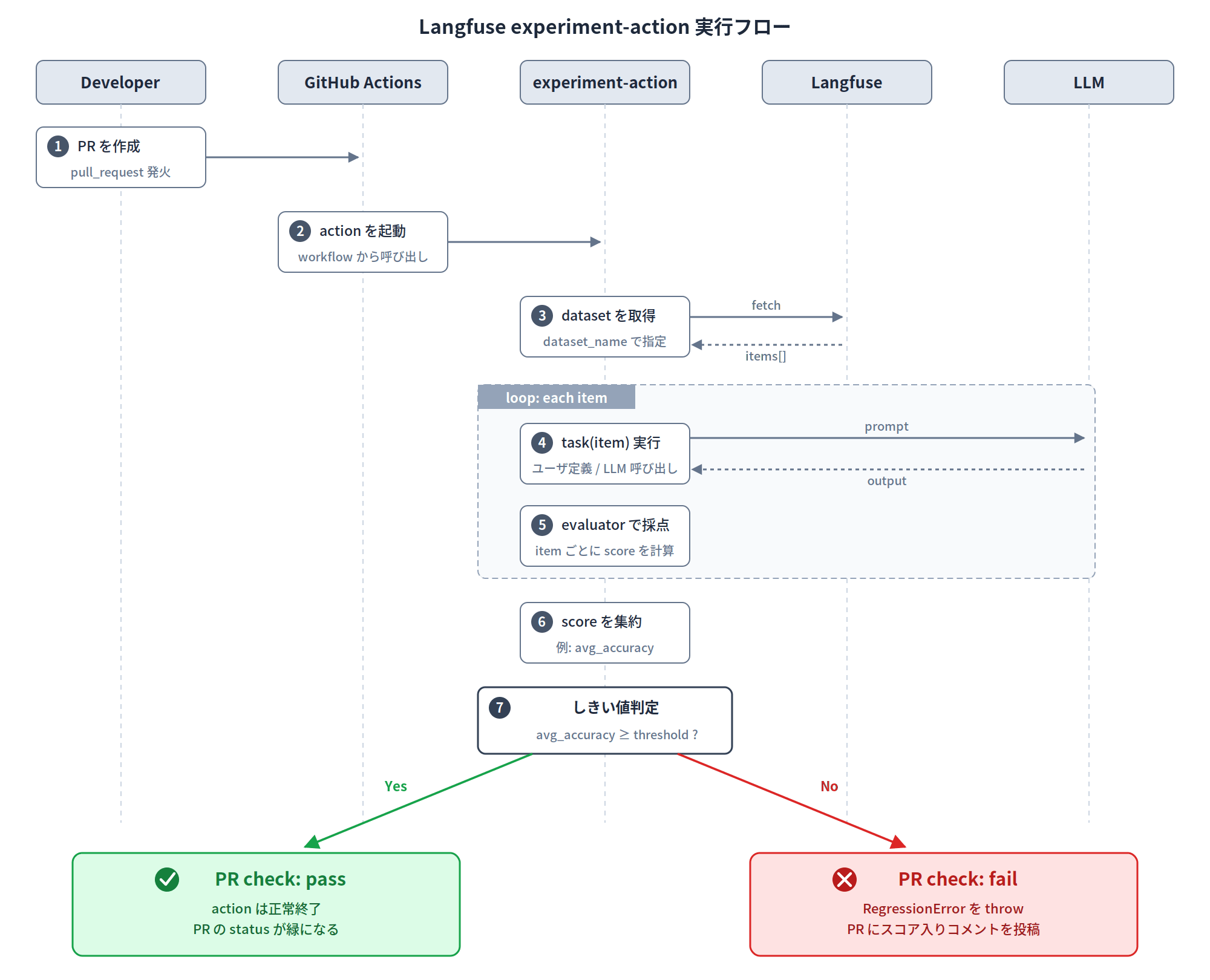
What experiment-action Can Do
The action takes care of the following all at once:
This context is created by the GitHub Action and handles the CI-specific setup for you:
- initializes the Langfuse SDK client from the action inputs
- loads the dataset items from
dataset_nameand appliesdataset_version- adds default metadata under
langfuse.*, such as commit SHA, branch, job URL, and actor.
So all you need to write on the user side is:
- The function to be evaluated (task)
- The scoring function (evaluator)
- The exception to throw when a threshold is breached (
RegressionError)
just these three things. The task is simply a function that receives each dataset item, calls the LLM, and returns the output. RegressionError is thrown according to your own threshold logic, and the action detects this and causes the CI to fail.
Actually Running It
The subject is a task of "passing 3 illustrations associated with Japan, America, and France, and having it answer the country name in one word."
The Dataset is created in advance from a TypeScript script. The input contains the relative path to the image, and the images themselves are placed in the repository.
// scripts/seed-dataset.ts
const items = [
{ input: { question: QUESTION, imagePath: "assets/japan.png" }, expectedOutput: "日本" },
{ input: { question: QUESTION, imagePath: "assets/usa.png" }, expectedOutput: "アメリカ" },
{ input: { question: QUESTION, imagePath: "assets/france.png" }, expectedOutput: "フランス" },
];
await langfuse.api.datasets.create({ name: "country-from-image-dataset" });
for (const item of items) {
await langfuse.api.datasetItems.create({
datasetName: "country-from-image-dataset",
...item,
});
}
The actual test images look like this.

Also, this is how they are displayed in the Langfuse UI.

Here is the function to be evaluated (task). It reads the image from a file, passes it to the LLM, and returns the returned text as output.
// experiments/support-agent-gate.ts
async function classifyCountry(input: { question: string; imagePath: string }) {
const [imageBytes, systemPrompt] = await Promise.all([
readFile(resolve(REPO_ROOT, input.imagePath)),
readFile(PROMPT_FILE, "utf-8"),
]);
const { text } = await generateText({
model: anthropic("claude-haiku-4-5-20251001"),
system: systemPrompt.trim(),
messages: [
{
role: "user",
content: [
{ type: "text", text: input.question },
{ type: "file", data: imageBytes, mediaType: "image/png" },
],
},
],
experimental_telemetry: { isEnabled: true },
});
return text.trim();
}
For scoring, I prepared two metrics: exact_match (exact match) and contains_expected (whether the expected value is included), and used the average of contains_expected (avg_accuracy) for the gate. If avg_accuracy falls below the threshold, a RegressionError is thrown and CI fails. Since there are only 3 questions this time, the threshold is set to 1.0, making it a strict setting where "missing even one question causes failure."
export async function experiment(context: RunnerContext) {
const result = await context.runExperiment({
name: "PR gate: country-from-image",
task: classifyTask,
evaluators: [exactMatch, containsExpected],
runEvaluators: [avgAccuracy],
});
const accuracy = result.runEvaluations.find(
(e) => e.name === "avg_accuracy",
)?.value;
if (typeof accuracy !== "number" || accuracy < THRESHOLD) {
throw new RegressionError({
result,
metric: "avg_accuracy",
value: typeof accuracy === "number" ? accuracy : 0,
threshold: THRESHOLD,
});
}
return result;
}
On the workflow side, all you need to do is call the action. The action tag is pinned with SHA to match the official README.
# .github/workflows/langfuse-experiment.yml (excerpt)
- uses: langfuse/experiment-action@887e7936bdf64a2197aa7dcfdc8a9e4afd85e229 # v1.0.3
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
with:
langfuse_public_key: ${{ secrets.LANGFUSE_PUBLIC_KEY }}
langfuse_secret_key: ${{ secrets.LANGFUSE_SECRET_KEY }}
langfuse_base_url: https://jp.cloud.langfuse.com
experiment_path: experiments/support-agent-gate.ts
dataset_name: country-from-image-dataset
github_token: ${{ github.token }}
When a PR is created, the workflow starts, and the scores and a link to the Langfuse experiment comparison view are posted to the PR like this.
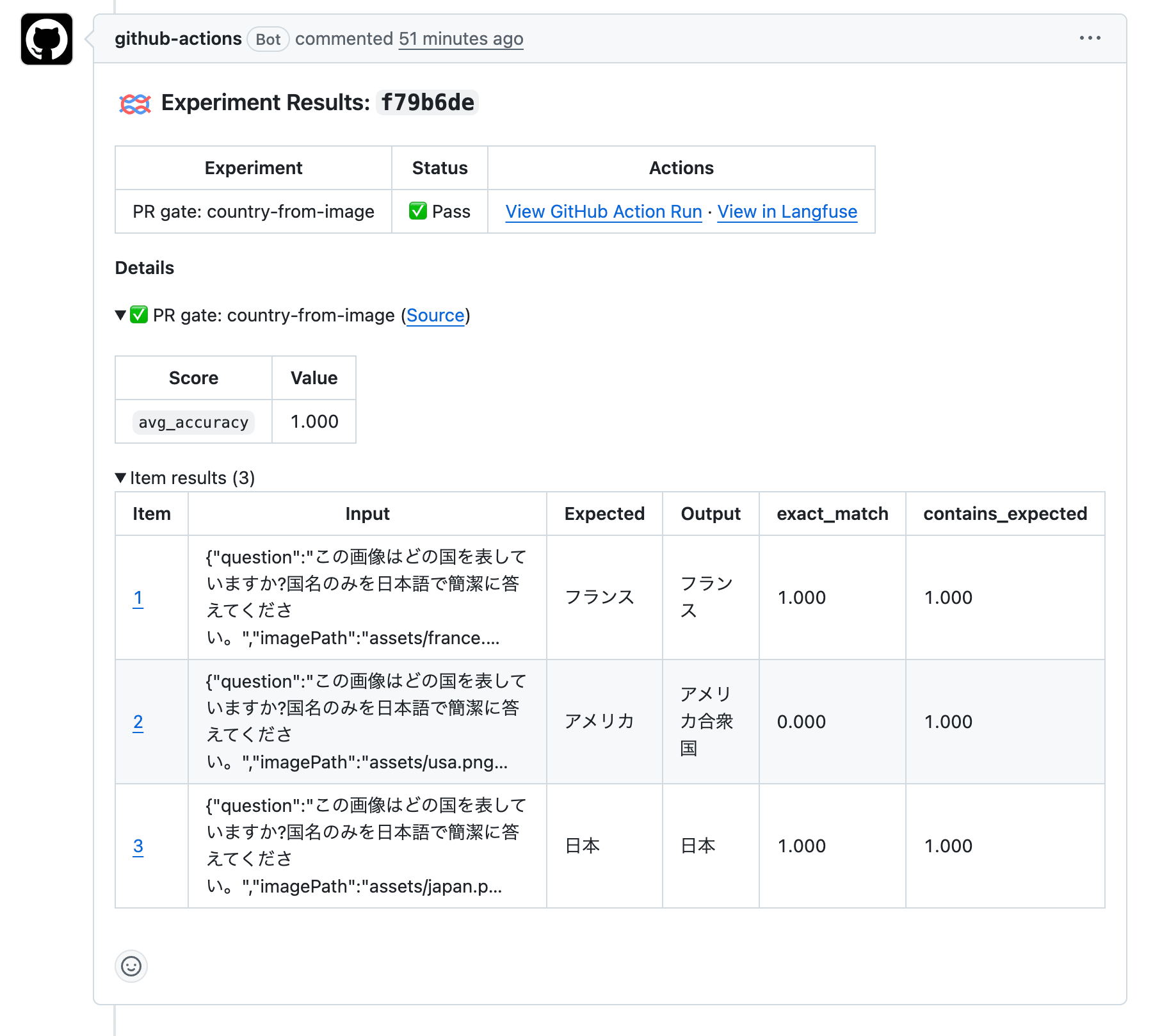
For example, for the American image this time, it returned "United States of America." The exact_match becomes 0, but since contains_expected is 1, avg_accuracy remains 1.0 and passes the gate. LLM output tends to have notation variations, so using only exact match as a metric can cause CI to fail unintentionally. I configured it to keep exact match for observation purposes while using partial match for the gate.
The actual PR can be checked here.
Managing Prompts in Git and Auto-Reflecting on Main Merge
Many people may already be doing this, but I also configured prompts to be managed in Git as prompts/country-classifier.md, so that when merged to main, they are automatically reflected in Langfuse's latest label.
The mechanism is simple: it just runs a script from the workflow on push to main that calls langfuse.prompt.create({ name, prompt: body, labels: ["latest"] }).
# .github/workflows/langfuse-prompt-promote.yml (excerpt)
on:
push:
branches: [main]
paths:
- "prompts/**"
jobs:
promote:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
- uses: pnpm/action-setup@v4
- uses: actions/setup-node@v6
with: { node-version: "24", cache: "pnpm" }
- run: pnpm install --frozen-lockfile
- env:
LANGFUSE_PUBLIC_KEY: ${{ secrets.LANGFUSE_PUBLIC_KEY }}
LANGFUSE_SECRET_KEY: ${{ secrets.LANGFUSE_SECRET_KEY }}
LANGFUSE_BASE_URL: https://jp.cloud.langfuse.com
run: pnpm tsx scripts/promote-prompt.ts
The task on the experiment-action side also reads the same prompts/country-classifier.md, so the CI on the PR runs evaluation with the "modified prompt" as-is, and after merging, Langfuse's latest version is switched.

In Closing
Being able to review accuracy in CI is something I think many people have been waiting for, so this is a welcome update. With the addition of the Japan region as well, there have been exciting updates recently and it's been fun to keep up with them.
See you 👋