
Langfuse で LLM の精度を CI で自動評価する GitHub Action が追加されました
リテールアプリ共創部の末永です。
Langfuse から langfuse/experiment-action という GitHub Action がリリースされましたので触ってみます。
今回は TypeScript SDK と Vercel AI SDK で Claude を呼び、画像から国名を当てる小さなマルチモーダルエージェントを評価する CI を組みました。あわせて prompt も Git で管理して、main マージ時に Langfuse の プロンプトに反映する設定も入れています。
なお、今回使用した検証コードは こちら から見れます。
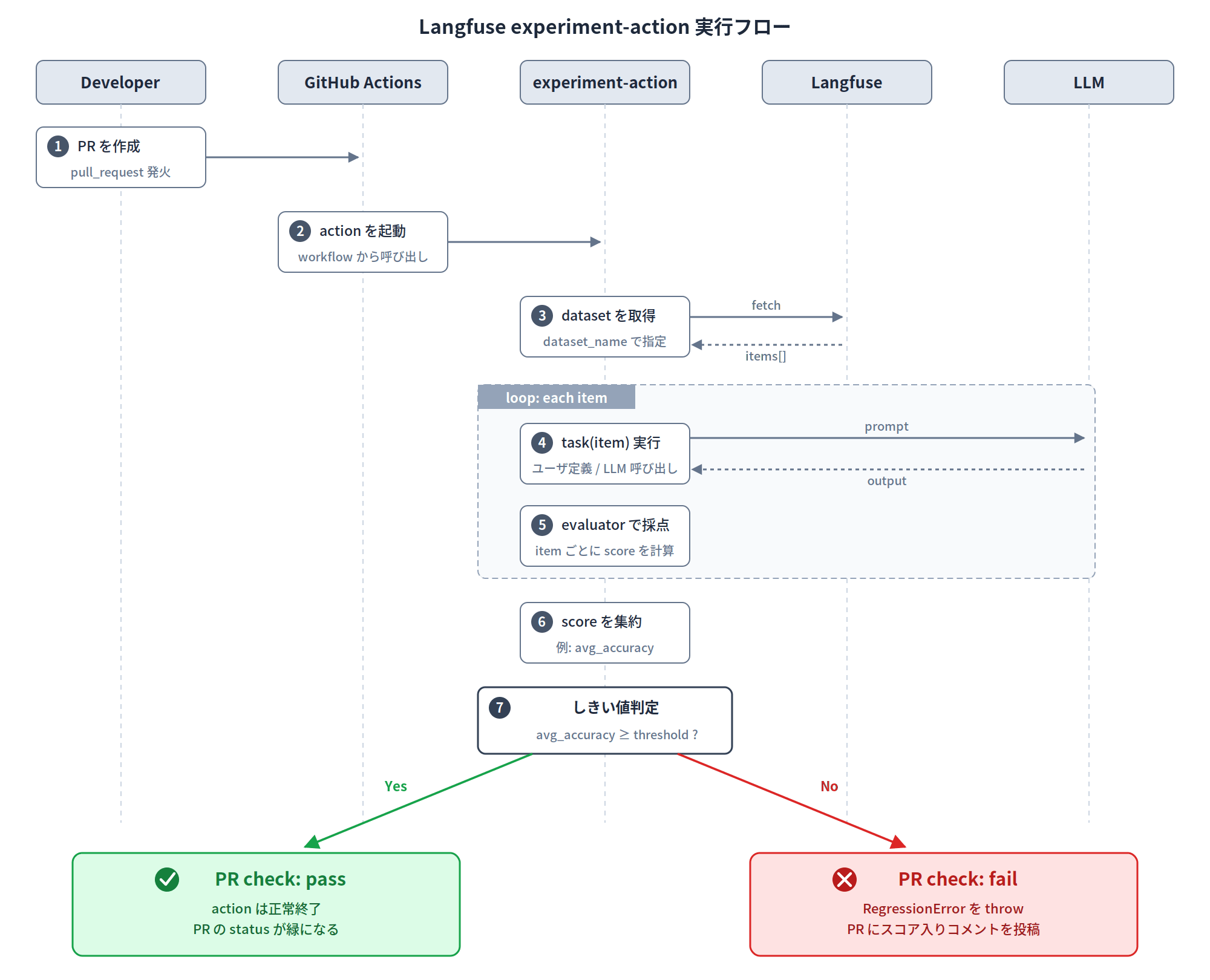
experiment-action でできること
action は次のことをまとめて面倒見てくれます。
This context is created by the GitHub Action and handles the CI-specific setup for you:
- initializes the Langfuse SDK client from the action inputs
- loads the dataset items from
dataset_nameand appliesdataset_version- adds default metadata under
langfuse.*, such as commit SHA, branch, job URL, and actor.(日本語訳)
このコンテキストは GitHub Action によって作成され、以下のような CI 固有のセットアップを自動で行います。
- アクションの入力(inputs)から Langfuse SDK クライアントを初期化する
dataset_nameからデータセットのアイテムをロードし、dataset_versionを適用する- コミット SHA、ブランチ、ジョブの URL、アクター(実行者)など、
langfuse.*配下にデフォルトのメタデータを追加する
なので利用側で書くのは、
- 評価対象の関数 (task)
- 採点関数 (evaluator)
- しきい値割れたら投げる例外 (
RegressionError)
の3つだけです。task は dataset の各 item を受け取って LLM を呼び、出力を返すだけの関数です。RegressionError は自分のしきい値ロジックに応じて投げるだけで、action 側がこれを検知して CI を失敗させてくれる仕組みになっています。
実際に動かしてみる
題材は「日本・アメリカ・フランスを連想させる3枚のイラストを渡して、国名を1単語で答えさせる」というタスクです。
Dataset は事前に TypeScript スクリプトから作っておきます。input には画像の相対パスを入れて、画像本体はリポジトリに置きました。
// scripts/seed-dataset.ts
const items = [
{ input: { question: QUESTION, imagePath: "assets/japan.png" }, expectedOutput: "日本" },
{ input: { question: QUESTION, imagePath: "assets/usa.png" }, expectedOutput: "アメリカ" },
{ input: { question: QUESTION, imagePath: "assets/france.png" }, expectedOutput: "フランス" },
];
await langfuse.api.datasets.create({ name: "country-from-image-dataset" });
for (const item of items) {
await langfuse.api.datasetItems.create({
datasetName: "country-from-image-dataset",
...item,
});
}
実際のテスト画像はこんな感じです。

また、Langfuse 上の UI ではこのように表示されています。

評価対象の関数 (task) はこちらです。画像をファイルから読み込んで LLM に投げ、返ってきたテキストを output として返しています。
// experiments/support-agent-gate.ts
async function classifyCountry(input: { question: string; imagePath: string }) {
const [imageBytes, systemPrompt] = await Promise.all([
readFile(resolve(REPO_ROOT, input.imagePath)),
readFile(PROMPT_FILE, "utf-8"),
]);
const { text } = await generateText({
model: anthropic("claude-haiku-4-5-20251001"),
system: systemPrompt.trim(),
messages: [
{
role: "user",
content: [
{ type: "text", text: input.question },
{ type: "file", data: imageBytes, mediaType: "image/png" },
],
},
],
experimental_telemetry: { isEnabled: true },
});
return text.trim();
}
採点には exact_match(完全一致)と contains_expected(期待値が含まれるか)の2つを用意して、ゲートには contains_expected の平均 (avg_accuracy) を使っています。avg_accuracy がしきい値を下回ったら RegressionError を投げて CI を落とします。今回は3問しかないのでしきい値を 1.0 にして、「1問でも外したら落ちる」という厳しめの設定にしてあります。
export async function experiment(context: RunnerContext) {
const result = await context.runExperiment({
name: "PR gate: country-from-image",
task: classifyTask,
evaluators: [exactMatch, containsExpected],
runEvaluators: [avgAccuracy],
});
const accuracy = result.runEvaluations.find(
(e) => e.name === "avg_accuracy",
)?.value;
if (typeof accuracy !== "number" || accuracy < THRESHOLD) {
throw new RegressionError({
result,
metric: "avg_accuracy",
value: typeof accuracy === "number" ? accuracy : 0,
threshold: THRESHOLD,
});
}
return result;
}
workflow 側は action を呼ぶだけです。action のタグは公式 README に合わせて SHA で pin しています。
# .github/workflows/langfuse-experiment.yml (抜粋)
- uses: langfuse/experiment-action@887e7936bdf64a2197aa7dcfdc8a9e4afd85e229 # v1.0.3
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
with:
langfuse_public_key: ${{ secrets.LANGFUSE_PUBLIC_KEY }}
langfuse_secret_key: ${{ secrets.LANGFUSE_SECRET_KEY }}
langfuse_base_url: https://jp.cloud.langfuse.com
experiment_path: experiments/support-agent-gate.ts
dataset_name: country-from-image-dataset
github_token: ${{ github.token }}
PR を作ると workflow が起動して、PR にこんな感じでスコアと Langfuse の experiment 比較ビューへのリンクが投稿されます。
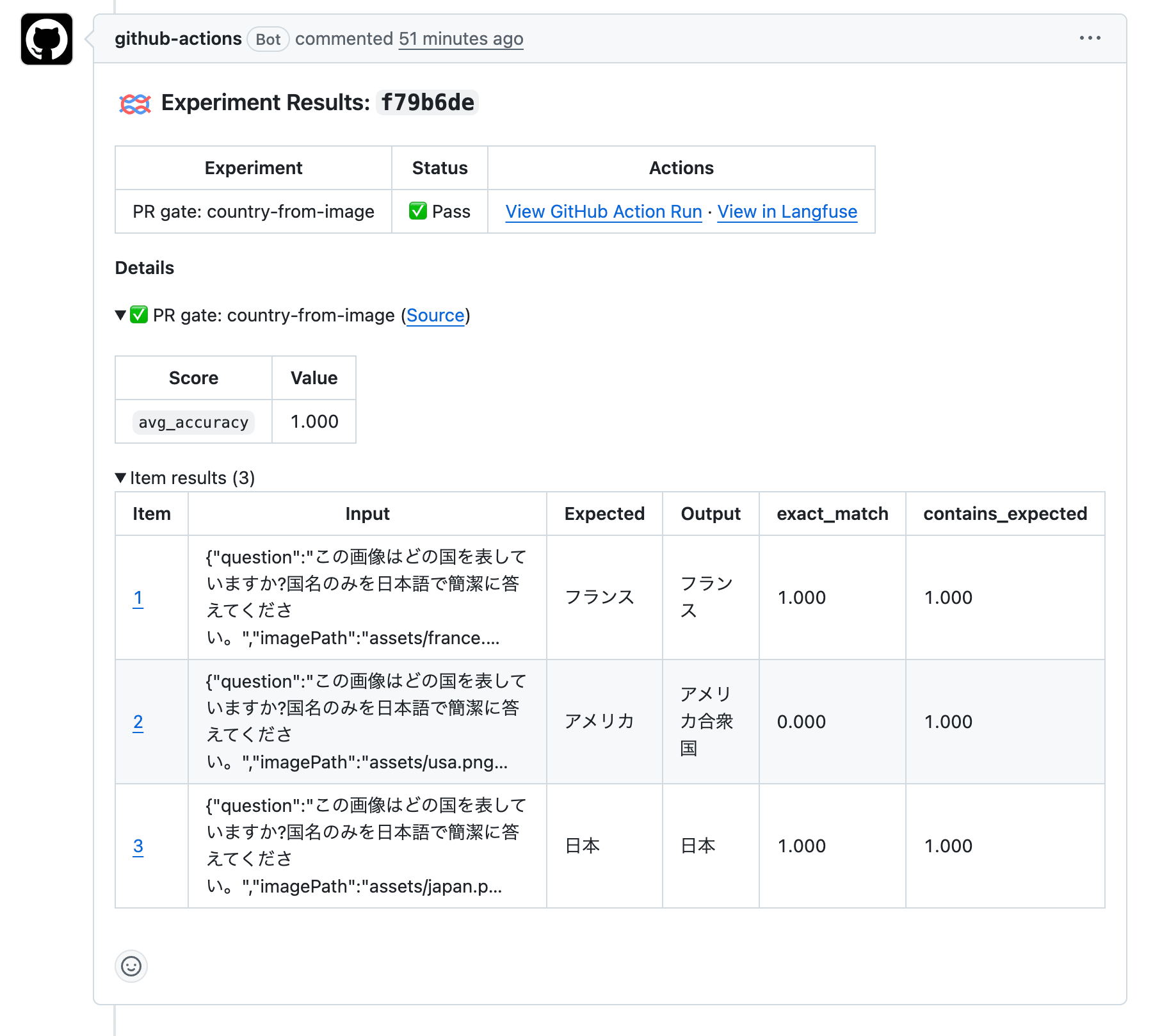
たとえば今回のアメリカの画像に対しては「アメリカ合衆国」と返ってきました。exact_match は 0 になりますが、contains_expected は 1 なので avg_accuracy は 1.0 のままでゲートを通っています。LLM の出力は表記揺れが起きやすいので、完全一致だけを指標として使うと CI が意図せず失敗になりがちです。完全一致は観測用に残しつつ、ゲートには部分一致を使う構成にしてみました。
実際の PR は こちらから確認できます。
prompt も Git で管理して main マージで自動反映する
ここはすでにやっている人も多そうですが、せっかくなので prompt も prompts/country-classifier.md として Git で管理して、main にマージしたら自動で Langfuse の latest ラベルに反映するようにしました。
仕組みは単純で、main への push で langfuse.prompt.create({ name, prompt: body, labels: ["latest"] }) を呼ぶスクリプトをワークフローから叩くだけです。
# .github/workflows/langfuse-prompt-promote.yml (抜粋)
on:
push:
branches: [main]
paths:
- "prompts/**"
jobs:
promote:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v6
- uses: pnpm/action-setup@v4
- uses: actions/setup-node@v6
with: { node-version: "24", cache: "pnpm" }
- run: pnpm install --frozen-lockfile
- env:
LANGFUSE_PUBLIC_KEY: ${{ secrets.LANGFUSE_PUBLIC_KEY }}
LANGFUSE_SECRET_KEY: ${{ secrets.LANGFUSE_SECRET_KEY }}
LANGFUSE_BASE_URL: https://jp.cloud.langfuse.com
run: pnpm tsx scripts/promote-prompt.ts
experiment-action 側の task も同じ prompts/country-classifier.md を読むようにしてあるので、PR の CI では「変更後の prompt」 でそのまま評価が走り、merge 後に Langfuse の latest バージョンが切り替わります。

最後に
CI で精度を見ながらレビューしたい、というのは結構待ち望まれていた話だと思うので、嬉しいアップデートです。日本リージョンの追加もあって、最近は熱いアップデートが続いていて追いかけていて楽しいですね。
では👋










