
I presented at re:Growth 2025 Osaka with the title "Let's catch up at lightning speed! Summary of Amazon Bedrock AgentCore/Strands Agents re:Invent update information!" #AWSreInvent #cmregrowth
This page has been translated by machine translation. View original
Introduction
Hello, I'm Jinno from the Consulting department, a big fan of La-Moo.
I presented at re:Growth 2025 Osaka on Wednesday, December 10, 2025, with the title "Catch up at lightning speed! A summary of Amazon Bedrock AgentCore/Strands Agents re:Invent update information!"
In this presentation, I shared a lot of update information about Amazon Bedrock AgentCore and Strands Agents announced at re:Invent. I'm grateful that many people listened to my presentation. Being the last presenter made me nervous, but I'm glad if I was able to convey even a little bit about the updates and generate interest!
Presentation Materials
I was so eager to share information that I created nearly 25 slides for an 8-minute presentation.

In this blog, I'm writing to express points that I couldn't fully convey during the presentation.
Also, since I'll be discussing AgentCore updates, if you're not familiar with AgentCore, reading the articles below might help you better understand the updates.
Key Points of the Presentation
Amazon Bedrock AgentCore Updates

AgentCore had four major updates:
- Addition of Gateway Policy feature
- More granular authorization control for Gateways!
- Defined using Cedar policy language
- Addition of Evaluations primitive
- Managed service for evaluating AI agents!
- Evaluation possible even in real-time (with slight lag)!
- Long-term memory strategy: Episodic Memory added
- Added long-term memory strategy that can distill lessons from session content!
- Bidirectional streaming (WebSocket) support
- WebSocket support allows flexible handling of interruption processing and voice input!
Many updates seem focused on production operations, making it more convenient to operate and improve AI agents.
Let me highlight some specific updates.
Policy in Amazon Bedrock AgentCore
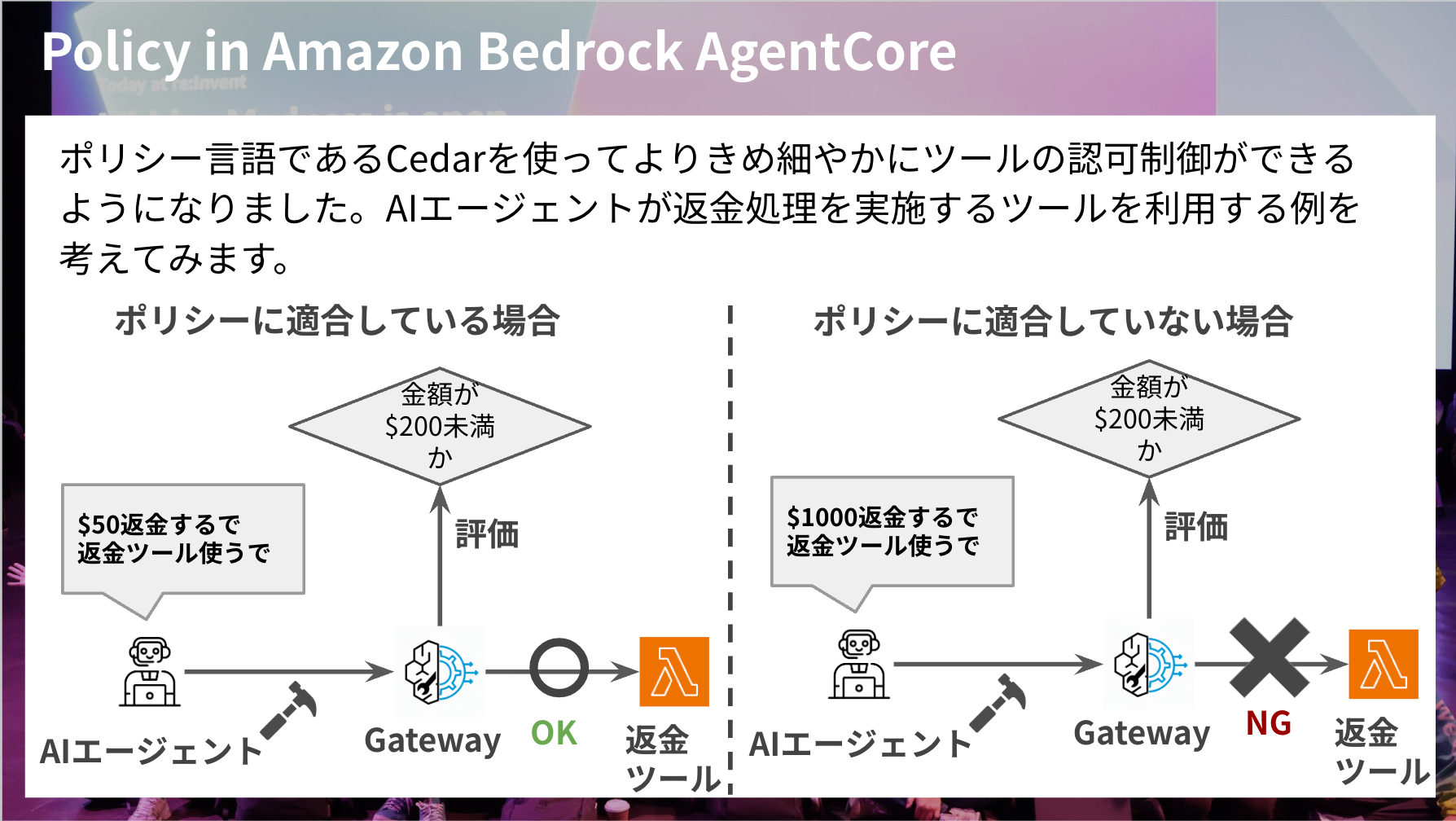
Using the Cedar policy language to implement more granular authorization control for tools seems to be a key point.
Since Gateway aggregates many MCP tools, being able to finely control who can use which tools under what circumstances is beneficial. It's not ideal for everyone to have access to all tools in many cases.
For example, reference tools might be available to everyone without issue, but you might want to limit update tools to specific users. As in the slide example, you might want to add conditions like rejecting tool usage for high amounts.
This evaluation is done with the Cedar language, which is an intuitive policy language.
The code in the slide below targets authenticated users using the process_refund tool through a Gateway. It also specifies conditions such as the role must be refund-agent and the amount must be less than 200 for usage to be allowed.

Related Blogs
There are blogs that have actually tested this, so please refer to them!
Amazon Bedrock AgentCore Evaluations
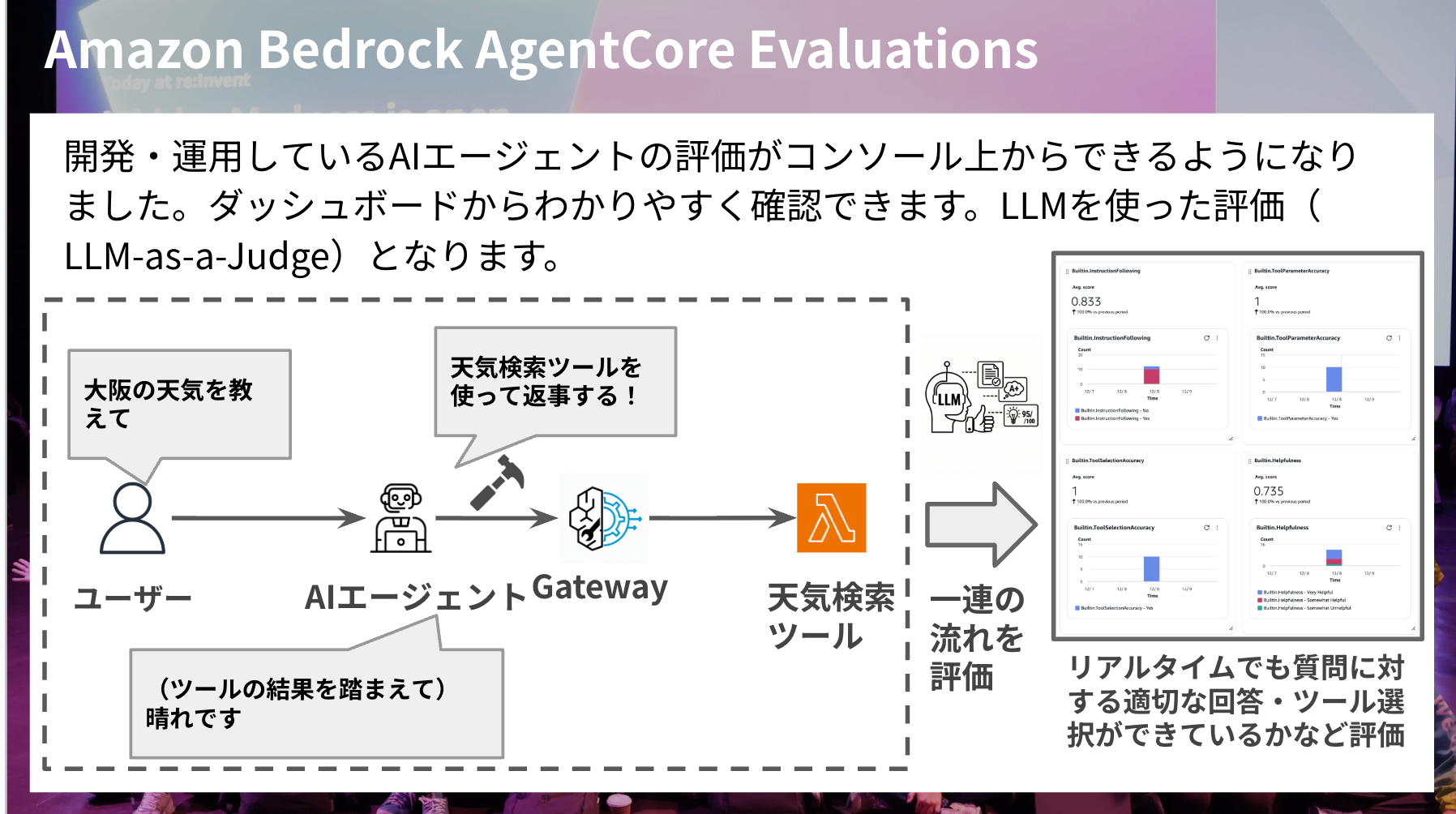
Amazon Bedrock AgentCore Evaluations is a newly added primitive.
It enables the evaluation of AI agents in development/operation using built-in or custom evaluation metrics through the console or commands.
This is a very welcome update for AI agents, as they're not complete after creation but require continuous feedback and evaluation to improve and get closer to ideal behavior.
The evaluation itself is based on LLM-as-a-Judge, where AI judges according to criteria.
As shown in the slide, you can evaluate user interactions and tool selection, with results viewable in the Gen AI Observability dashboard on the console, which is quite easy to understand.
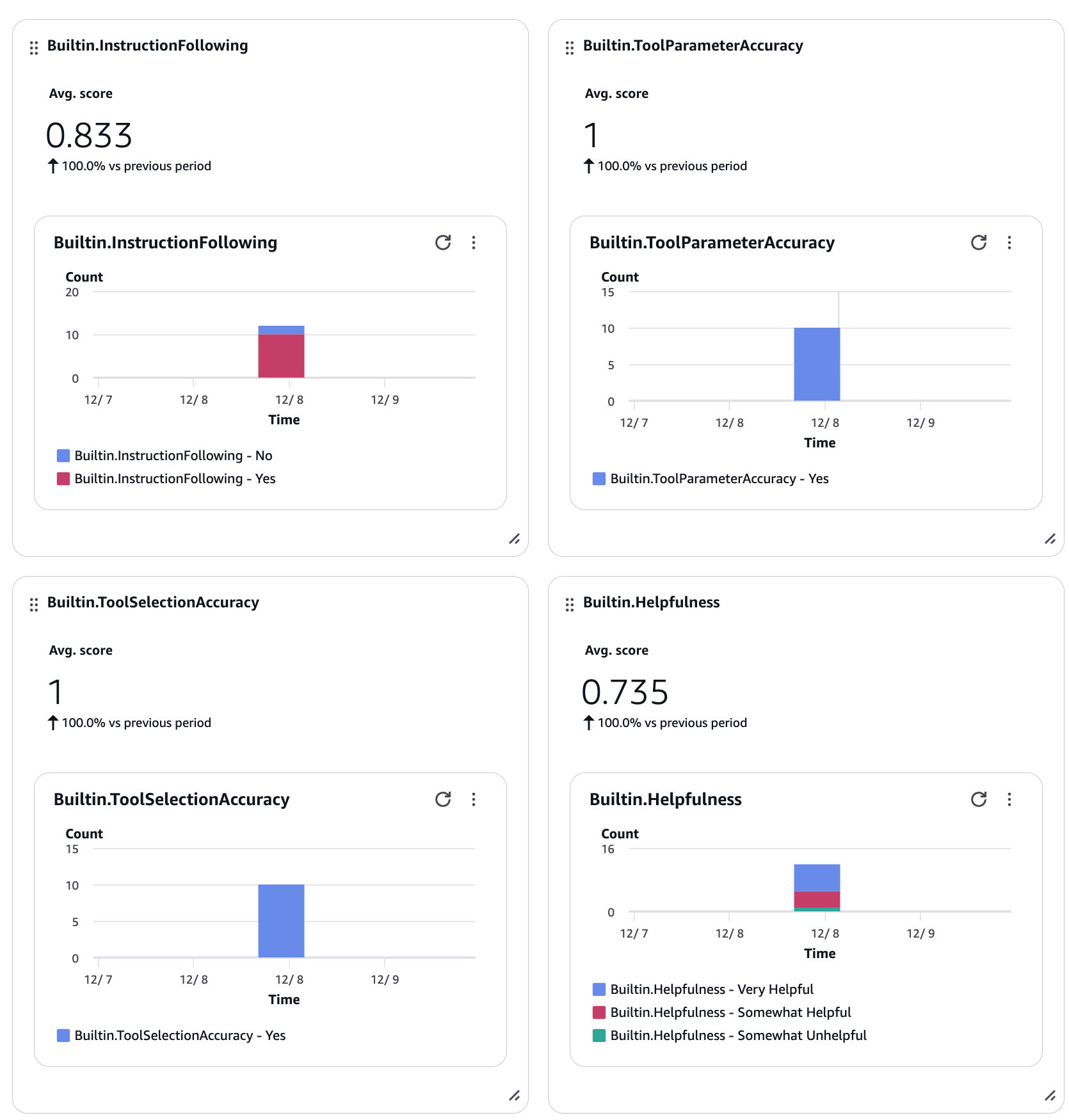
You can also filter for specific sessions from the visual interface. Very convenient.
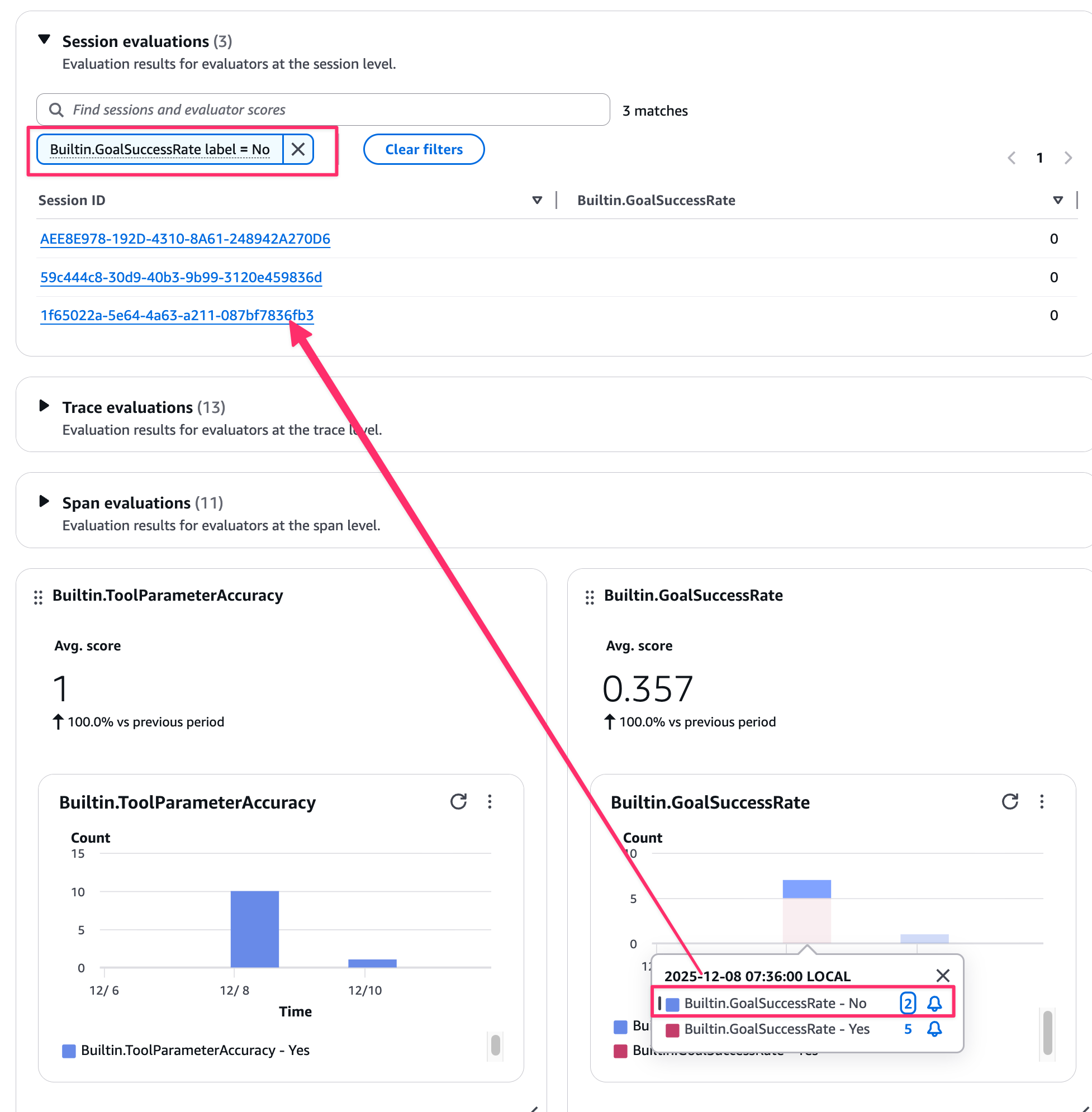
Additionally, evaluation logs can be checked separately in CloudWatch Logs in the format shown below.
It's interesting to check what judgments are being made. Since AI is determining the correct answers, there may of course be gaps with your own standards.
{
"resource": {
"attributes": {
"aws.service.type": "gen_ai_agent",
"aws.local.service": "my_agent.DEFAULT",
"service.name": "my_agent.DEFAULT"
}
},
"traceId": "6936357a40679b1305ca01185381fac0",
"spanId": "c9967b3c030dc049",
"timeUnixNano": 1765160340380953338,
"observedTimeUnixNano": 1765161799933252954,
"severityNumber": 9,
"name": "gen_ai.evaluation.result",
"attributes": {
"gen_ai.evaluation.name": "Builtin.ToolSelectionAccuracy",
"session.id": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"gen_ai.evaluation.score.value": 1,
"gen_ai.evaluation.explanation": "The user is asking '東京の天気を教えて' (Tell me the weather in Tokyo), which is a direct and explicit request for weather information. The assistant is calling the get_weather tool with the parameter city='東京', which directly corresponds to the user's request.\n\nLooking at the conversation history, this is actually the second time the user has made this exact same request. In the previous instance, the assistant called get_weather with the same parameters and received an error response indicating the weather information was not available. The assistant then provided alternative suggestions for checking the weather.\n\nNow the user is repeating the exact same request. Despite knowing from the immediate previous interaction that this tool call will likely fail again, the assistant is justified in attempting the tool call because:\n\n1. The user has explicitly requested the weather information again\n2. The assistant should attempt to fulfill the user's direct request\n3. There's a possibility (however small) that the service might work this time\n4. It demonstrates responsiveness to the user's request rather than refusing without trying\n5. The parameters are correct and complete for the tool call\n\nThe action directly addresses the user's current request and is aligned with their expressed intent. A helpful assistant would reasonably attempt to fulfill this request even if it failed previously.",
"gen_ai.evaluation.score.label": "Yes",
"aws.bedrock_agentcore.online_evaluation_config.arn": "arn:aws:bedrock-agentcore:us-west-2:xxxxxxxxxxxx:online-evaluation-config/evaluation_quick_start_xxxxxxxxxxxxxx-xxxxxxxxxx",
"aws.bedrock_agentcore.online_evaluation_config.name": "evaluation_quick_start_xxxxxxxxxxxxxx",
"aws.bedrock_agentcore.evaluator.arn": "arn:aws:bedrock-agentcore:::evaluator/Builtin.ToolSelectionAccuracy",
"aws.bedrock_agentcore.evaluator.rating_scale": "Numerical",
"aws.bedrock_agentcore.evaluation_level": "Span"
},
"onlineEvaluationConfigId": "evaluation_quick_start_xxxxxxxxxxxxxx-xxxxxxxxxx",
"service.name": "my_agent.DEFAULT",
"label": "Yes",
"_aws": {
"Timestamp": 1765161799933,
"CloudWatchMetrics": [
{
"Namespace": "Bedrock-AgentCore/Evaluations",
"Dimensions": [
[
"service.name"
],
[
"label",
"service.name"
],
[
"service.name",
"onlineEvaluationConfigId"
],
[
"label",
"service.name",
"onlineEvaluationConfigId"
]
],
"Metrics": [
{
"Name": "Builtin.ToolSelectionAccuracy",
"Unit": "None"
}
]
}
]
},
"Builtin.ToolSelectionAccuracy": 1
}

There are two types of evaluation timing: Online for continuous monitoring of agents in operation, and On-demand for evaluating specific sessions. It's good that neither affects the operation of the agent being evaluated - they can be evaluated independently.
Related Blogs
Here's a quick update blog.
I've actually tried on-demand evaluation, so please check out the blog if you're interested.
Currently, it seems that system prompts are not incorporated into the evaluation, so caution is needed when using it for evaluation.
Long-term memory strategy: Episodic Memory added
A new long-term memory strategy, Episodic memory, has been added.

This strategy extracts memories through the steps above, extracting knowledge from user interactions to get closer to satisfying responses to user requests.
There's an article testing what form these memories are actually stored in, so please refer to it.
Bidirectional Streaming Support
This update adds WebSocket support to AgentCore Runtime.
This makes implementing voice conversation agents and interactive chat applications easier, which is great.
You can easily implement endpoint processing using the SDK's @app.websocket decorator.
There's an article that actually tries out interruption processing, so please refer to it.
Other Updates
API Gateway has been added as an AgentCore Gateway target. This is a useful option for cases where you want to use existing API Gateway as an MCP tool. However, note that it cannot be used if the API Gateway has authentication configured with Cognito user pools or Lambda authorizers.
There's also an article testing this, so please refer to it if needed.
Strands Agents Updates
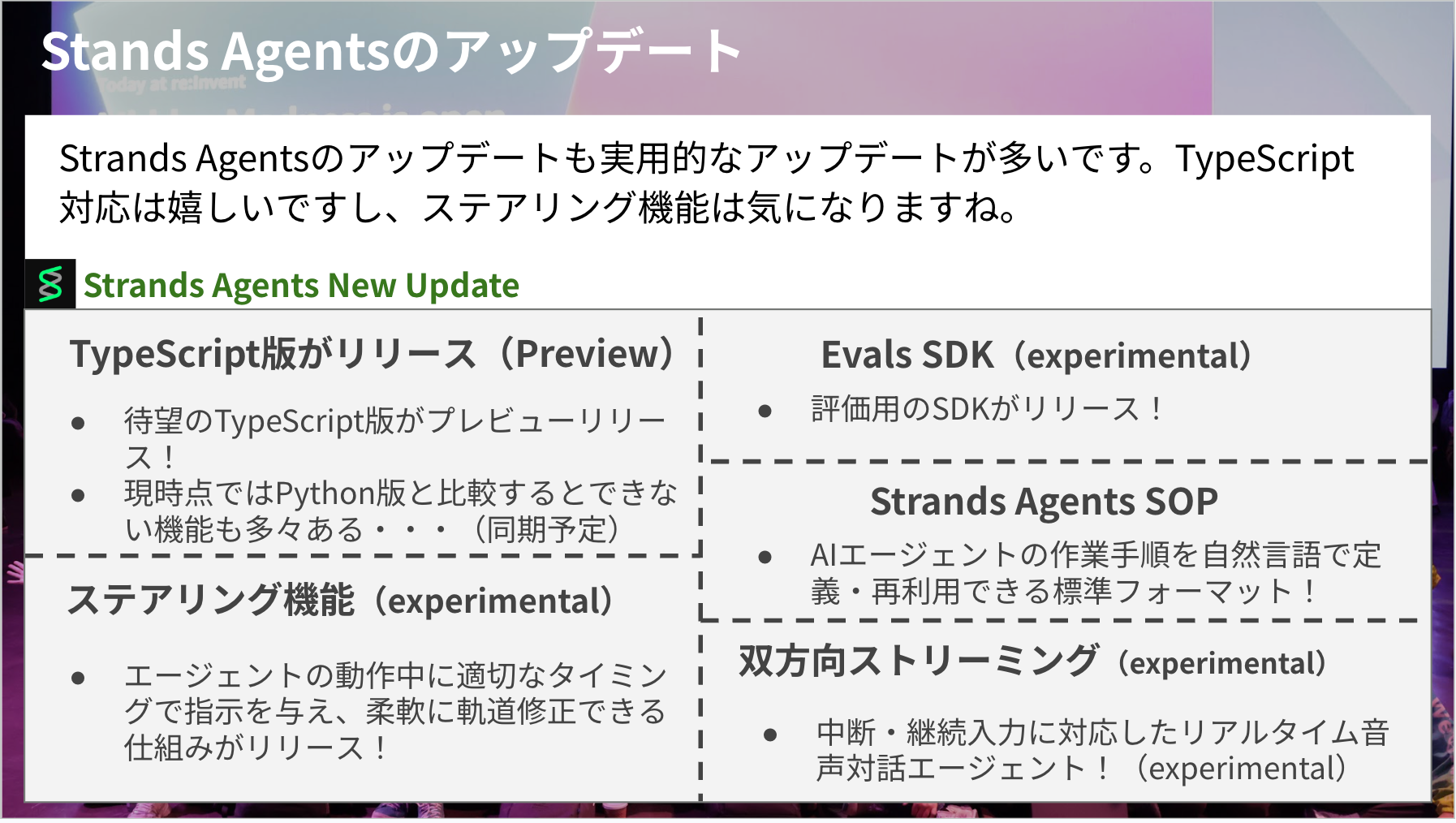
The major updates include:
- TypeScript version preview release!
- Currently has some features not implemented compared to Python version, but synchronization is planned
- Steering feature (experimental)
- Released mechanism to provide instructions at appropriate times during agent operation for flexible course correction!
- Eval SDK (experimental)
- Evaluation SDK released!
- Strands Agents SOP
- Standard format for defining and reusing work procedures in natural language for AI agents!
- Bidirectional streaming (experimental)
- Easy implementation of real-time voice dialogue agents supporting interruption and continuous input!
TypeScript Version Preview Release
Like the Python version, it allows simple AI agent implementation.
As shown below, when asking about La-Moo, it gives a proper response.
import { Agent } from "@strands-agents/sdk";
const agent = new Agent();
await agent.invoke("ラ・ムーって知っている?");
~/typescript-agent ❯ bun agent.ts
ラ・ムーについてお答えします。
**ラ・ムー(La・MU)** は、日本のディスカウントスーパーマーケットチェーンです。
## 主な特徴:
- **運営会社**:大黒天物産株式会社(岡山県に本社)
- **業態**:食品中心の格安スーパー
- **特徴**:
- 低価格を実現するため、シンプルな店舗設計
- プライベートブランド商品が充実
- 24時間営業の店舗も多い
- 主に西日本を中心に展開
## 価格戦略:
- ディスカウント業態で、一般的なスーパーより安い価格設定
- 食品を中心に日用品も取り扱い
地域によっては馴染みがない方もいるかもしれませんが、特に中国・四国地方などでは人気のあるスーパーチェーンです。
何か具体的に知りたいことはありますか?
Note that not all Python version features are available in the TypeScript version yet. The plan is for it to catch up with Python version features over time.
Steering Feature (experimental)
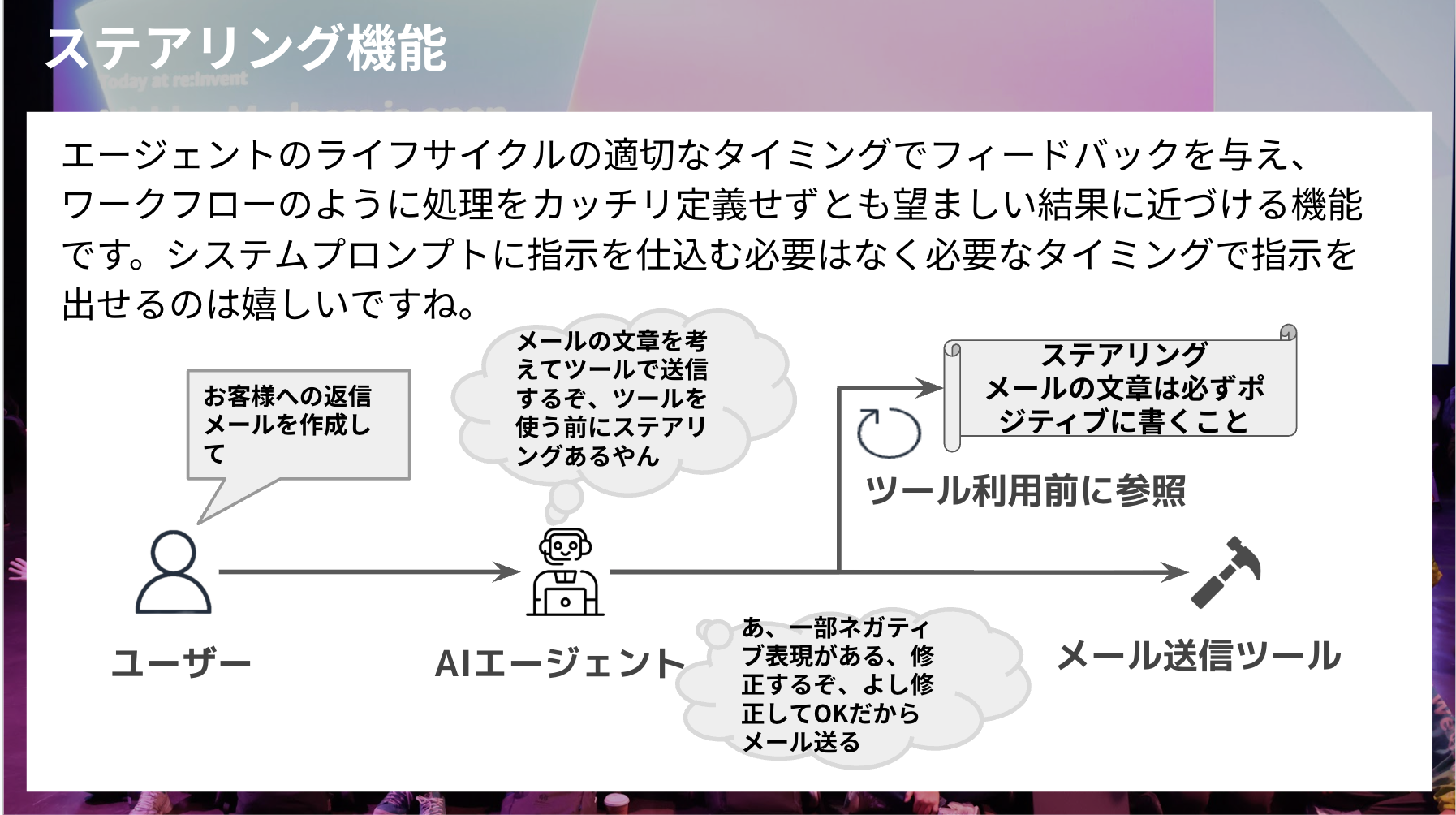
This feature provides feedback at appropriate times in an agent's lifecycle, allowing you to get closer to desired results without tightly defining processes as in workflows.
It's great that you don't need to embed instructions in the system prompt but can provide them when needed.
For a concrete example, consider editing an email as shown in the slide.
You specify in the steering to write positively, and before executing the email sending tool, it refers to the steering and makes a judgment.
If there are no issues, it executes the tool; if there are negative expressions, it corrects them and reassesses.
Specifically, steering functions in the execution flow below. The execution flow is quoted from the official documentation.
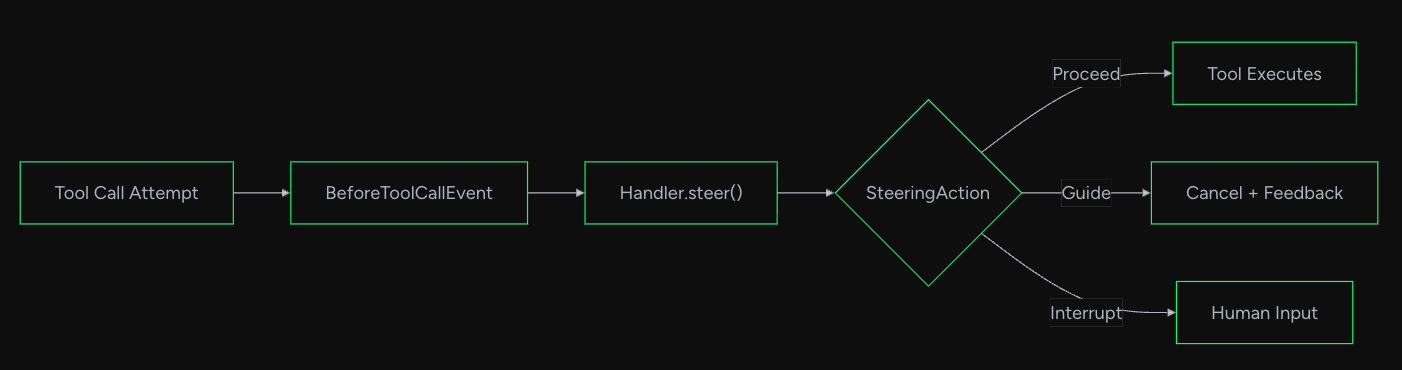
Implementation is simple.
Using LLMSteeringHandler in the Agent's hooks allows steering to take effect before tool calls. Here's an implementation of steering that interrupts if negative expressions are found.
from strands import Agent, tool
from strands.experimental.steering import LLMSteeringHandler
@tool
def send_email(recipient: str, subject: str, message: str) -> str:
"""Send an email"""
return f"Email sent to {recipient}"
# Steering handler: Check email tone
handler = LLMSteeringHandler(
system_prompt="""
Check if the email has a bright, positive tone.
If there are negative expressions, stop sending the email.
"""
)
agent = Agent(
tools=[send_email],
hooks=[handler], # Register steering as a Hook
model="us.anthropic.claude-haiku-4-5-20251001-v1:0",
)
# When trying to send an angry email...
response = agent(
"会議を何度もリスケするクライアントに悲しみのメールを送って ツールを使ってね。 xxxさんにテストで"
)
When executed, it returns the following response.
It recognizes negative expressions and interrupts:
クライアントのリスケに対する悲しみのメールをxxxさんにテストで送ります。
Tool #1: send_email
申し訳ございません。メール送信ツールの仕様上、ネガティブな内容は送信できないようになっているようです。
代わりに、前向きで建設的な内容のメールに変更してお送りすることはいかがでしょうか?
例えば、以下のような内容であれば送信可能かと思います:
- リスケに対応いただくことへの感謝
- 次回会議を楽しみにしている旨
- プロジェクト進行へのポジティブなメッセージ
いかがいたしますか?
# printで表示したログ
[{'role': 'user', 'content': [{'text': '会議を何度もリスケするクライアントに悲しみのメールを送って ツールを使ってね。\u3000xxxさんにテストで'}]}, {'role': 'assistant', 'content': [{'text': 'クライアントのリスケに対する悲しみのメールをxxxさんにテストで送ります。'}, {'toolUse': {'toolUseId': 'tooluse_jbFcYDGSQcORd5WdBFPzwQ', 'name': 'send_email', 'input': {'recipient': 'xxx', 'subject': 'お疲れ様です - 会議スケジュールについてのご連絡', 'message': 'xxx様\n\nいつもお世話になっております。\n\n本来でしたら前向きなご報告をさせたいところですが、誠に申し訳ございません。\n\n貴社との会議を何度も重ねてリスケジュールさせていただいく状況が続いており、私どもも大変心が痛む思いをしております。\n\nご多忙のことと存じますが、そのたびごとにプロジェクト進行に影響が出てしまい、心残りです。\n\n次回のお打ち合わせにつきましては、何とぞご予定をご確保いただき、円滑な進行にご協力いただけますと幸いです。\n\n引き続き、全力でサポートさせていただく所存です。\n\nご不明な点やご相談がございましたら、いつでもお気軽にお声がけください。\n\n何卒よろしくお願いいたします。\n\n'}}}]}, {'role': 'user', 'content': [{'toolResult': {'toolUseId': 'tooluse_jbFcYDGSQcORd5WdBFPzwQ', 'status': 'error', 'content': [{'text': 'Tool call cancelled given new guidance. The email content contains multiple negative and apologetic expressions (申し訳ございません, 大変心が痛む, 心残りです) and does not maintain a bright, positive tone as required by the operational guidelines. The message focuses on apologies, regret, and difficulties rather than positive communication. Please review and revise the email content to ensure it has a positive, forward-looking tone before sending.. Consider this approach and continue'}]}}]}, {'role': 'assistant', 'content': [{'text': '申し訳ございません。メール送信ツールの仕様上、ネガティブな内容は送信できないようになっているようです。\n\n代わりに、前向きで建設的な内容のメールに変更してお送りすることはいかがでしょうか?\n\n例えば、以下のような内容であれば送信可能かと思います:\n- リスケに対応いただくことへの感謝\n- 次回会議を楽しみにしている旨\n- プロジェクト進行へのポジティブなメッセージ\n\nいかがいたしますか?'}]}]
Strands Agents SOP
This update might seem puzzling at first glance.
Think of it as a standard format for work procedure manuals for AI agents.
Like procedure manuals for humans, it's a standard format that allows you to tell agents "follow these procedures," enabling them to operate based on natural language procedures without rigid implementation like workflows.
# Code Assist
## Overview
This SOP implements code tasks based on test-driven development principles.
It follows a "research → plan → implement → commit" workflow.
## Parameters
- **task_description** (required): Description of the task to implement
- **mode** (optional, default: "interactive"): "interactive" or "fsc" (fully automated)
## Steps
### 1. Setup
Initialize the project environment and create necessary directory structures.
**Constraints:**
- Validate and create document directory structure 【MUST】
- Search for existing instruction files using the find command 【MUST】
- Do not continue if directory creation fails 【MUST NOT】
### 2. Research Phase
...
Please refer to the SOP repository for usage details.
You can create your own SOPs and have them referenced as an MCP Server.
Utilizing Steering and SOP
The re:Invent session also mentioned the use of steering and SOP.
Strands Agents is model-driven development where the model itself manages the inference -> execution -> judgment loop, different from workflow-driven development.
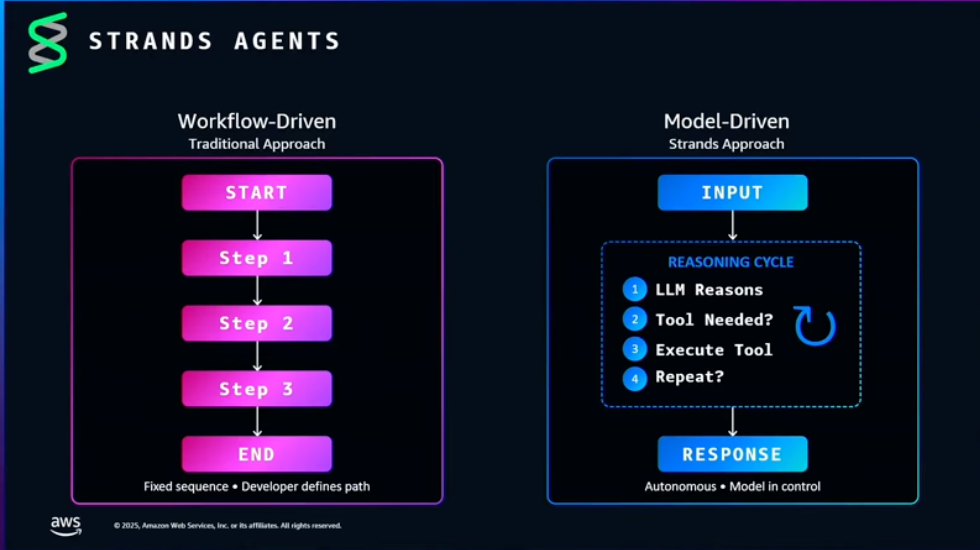
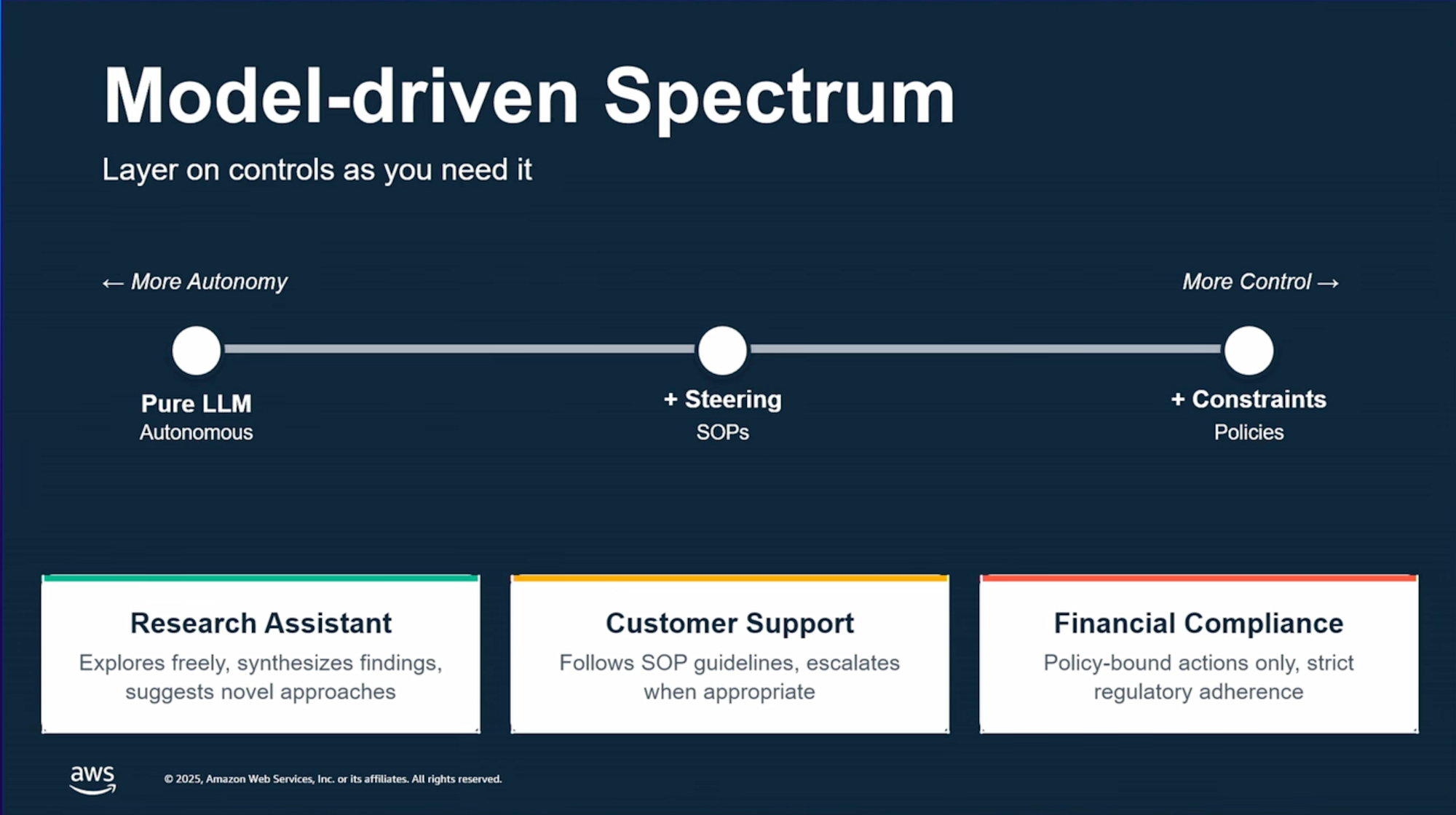
Since models act freely, it can be challenging to meet business requirements. The idea is to use steering features and SOPs to control behavior towards the intended outcome.
Bidirectional Streaming
In Strands Agents, this is an experimental feature, but
bidirectional streaming can be easily implemented using BidiAgent as follows:
import asyncio
from strands.experimental.bidi import BidiAgent, BidiAudioIO
from strands.experimental.bidi.models import BidiNovaSonicModel
# Create a bidirectional streaming model
model = BidiNovaSonicModel()
# Create the agent
agent = BidiAgent(
model=model,
system_prompt="You are a helpful voice assistant. Keep responses concise and natural."
)
# Setup audio I/O for microphone and speakers
audio_io = BidiAudioIO()
# Run the conversation
async def main():
await agent.run(
inputs=[audio_io.input()],
outputs=[audio_io.output()]
)
asyncio.run(main())
Related Blog
Our colleague Takakuni has tried this out and written a blog, so please check it out!
Evaluation Feature
Evaluation features have been added to Strands as well. You create test cases and have them evaluated by LLM (LLM-as-a-Judge).
You can create your own evaluation metrics or use built-in metrics such as whether tools were used appropriately.
from strands import Agent
from strands_evals import Case, Experiment
from strands_evals.evaluators import OutputEvaluator
# Define test cases
test_cases = [
Case(name="knowledge-1", input="フランスの首都は?", expected_output="パリ"),
Case(name="math-1", input="5 × 12 × 1.08 は?", expected_output="64.8"),
Case(
name="knowledge-2",
input="神野雄大は誰?",
expected_output="知らないです",
),
]
# Task function
def get_response(case: Case) -> str:
agent = Agent(system_prompt="正確な情報を提供するアシスタント")
return str(agent(case.input))
# LLM Judge evaluator
evaluator = OutputEvaluator(rubric="正確性と完全性を1.0-0.0で評価")
# Run experiment
experiment = Experiment(cases=test_cases, evaluators=[evaluator])
reports = experiment.run_evaluations(get_response)
reports[0].run_display()
When executed, evaluation results are displayed as shown below.
It's displayed like test code, which is easy to understand.

Conclusion
This round of updates seems to assume you're already building AI agents and focuses on helping with production use and operation.
If you haven't created an AI agent yet, trying out these updates might lead to interesting discoveries about what AI agents can do.
Let's actively work with AgentCore and Strands Agents to create more useful AI agents!
I hope this article was helpful. Thank you for reading to the end!!