
I tried predicting PLC-style time series data with Chronos-2 and generating maintenance comments with Nemotron
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Division.
This time, I'm combining Amazon Chronos-2 with a local LLM on DGX Spark (Nemotron 3 Nano 30B-A3B-NVFP4) to create a single reference implementation for the following workflow on PLC-style data.
- Generate current, temperature, vibration, and ambient temperature at 1Hz for 72 hours using a custom PLC-style simulator
- Run multivariate predictions with Chronos-2 and calculate anomaly scores from residuals
- Extract high-score windows and have the local LLM write "maintenance comments" in Japanese
While making this a hands-on configuration that can go from 0 to 1 without actual PLC hardware, the "Production Expansion Mapping" section at the end of each chapter shows the correspondence for replacing each component with real-world services (AWS IoT SiteWise / Timestream / SageMaker / Bedrock, etc.).
Note that the scope of this article covers hands-on from 0 to 1 with Chronos-2 alone and LLM integration. Connection paths to actual PLCs and comparisons with other time series foundation models such as TimesFM 2.5 are out of scope, and I plan to explore each of those in separate articles.
All verification is completed on a single DGX Spark (128GB).
Verification Configuration
The verification configuration is as follows.
Each block can be replaced directly with AWS IoT SiteWise (PLC data collection) → Timestream / TimescaleDB (time series DB) → SageMaker Endpoint (time series model) → Bedrock / same LLM (interpretation layer), so this is intended as a reference implementation for production predictive maintenance.
Design Philosophy of the PLC-style Simulator
For this verification, I prepared a PLC-style simulator.
- Readers can reproduce the same series on their own machines (if an article requires actual PLC hardware to proceed, it would be disappointing to finish reading without being able to run anything)
- Since we can control the timing of degradation and sudden spikes as desired, it's easy to isolate what Chronos-2 detects and what it misses
- The narrative of "normal interval → degradation progression → sudden anomaly" can be compressed into 72 hours
The connection path to actual PLCs (OPC UA / Modbus TCP / MQTT) is outside the scope of this article, and I'll proceed with the image of the simulator playing the role of a PLC.
The design uses the following 6-block structure.
FactoryState Operation mode / Shift / Ambient temperature
LoadGenerator Day/night + sine + noise + switching dip
EquipmentPhysics Load → Current → Temperature → Vibration chain
SensorGenerator Gaussian noise + rare dropout
FailureInjector Linear degradation + nonlinear acceleration + sudden spikes
StreamPublisher CSV output + deque of recent windows
The key point is in EquipmentPhysics, where I carefully built "Load → Current → Temperature → Vibration" as a multivariate causal chain. Time series foundation models like Chronos-2 that can handle covariates should leverage such inter-sensor correlations to improve prediction accuracy, so the intent is to provide data with the same characteristics as real-world environments.
Simulator Implementation
EquipmentPhysics was designed to be "simple linear + wear-dependent without overfitting." The equations are kept straightforward so that Chronos-2 doesn't memorize the context and perfectly predict the future. Current, temperature, and vibration were calculated as follows.
current = line_speed * 0.10 + 2.0 * wear # Current increases with wear
bearing_temp = ambient + load * 0.30 + current * 0.20 # Temperature rises with load + current
vibration = 1.0 + 0.5 * wear # Vibration increases with wear
FailureInjector added a linear degradation (wear_per_step = 5e-6 / step) plus a second phase where progression accelerates 2.5x when wear exceeds 1.0. Sudden spikes occur at a probability of 0.0008/step and are implemented as a state machine that persists for 5 steps and then naturally converges.
When generating 72 hours (259,200 rows) at 1 Hz, the output looked like this.
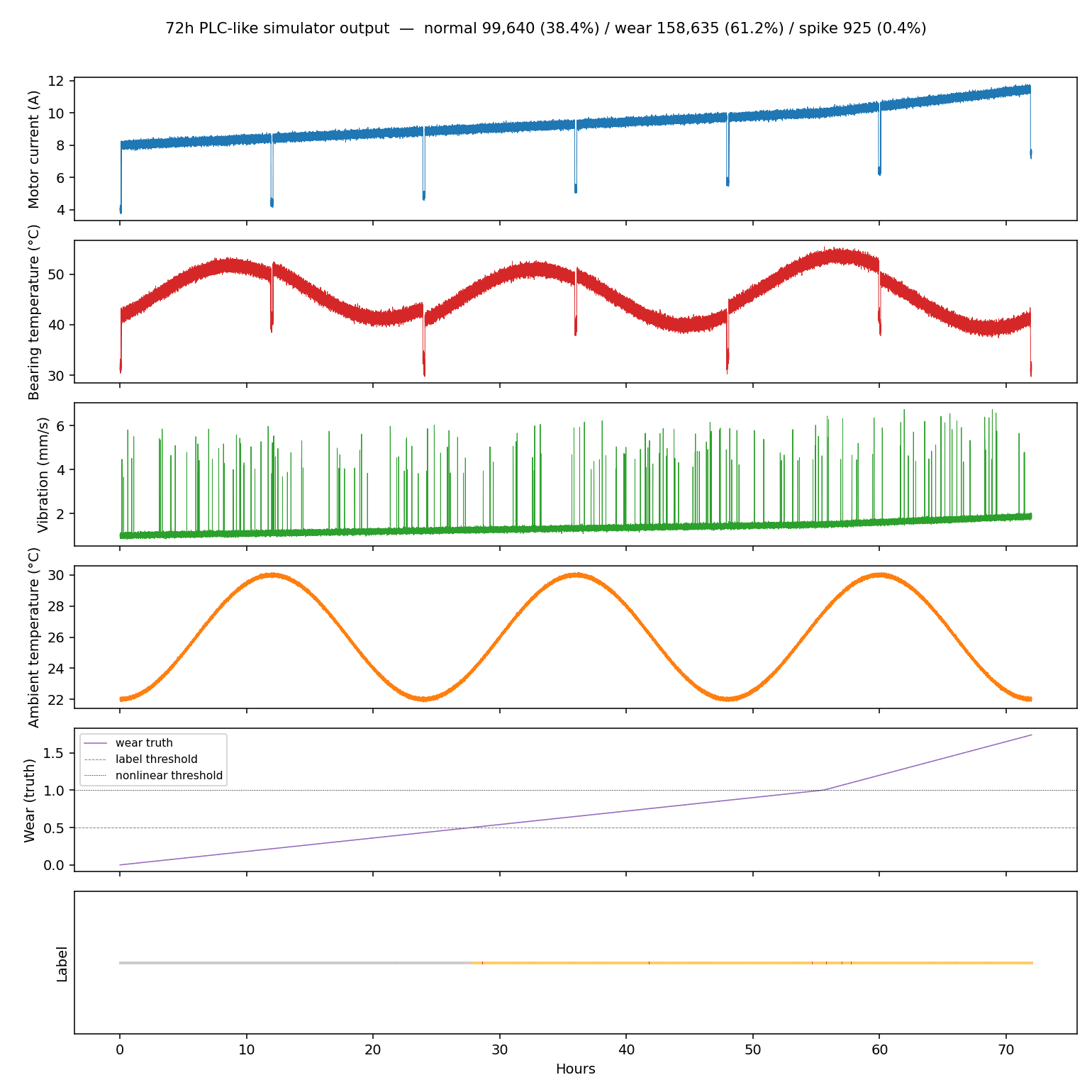
Current, temperature, and vibration all rise gradually over time. Temperature oscillates sinusoidally with a 24-hour ambient temperature cycle overlaid on top. You can see vibration jumping up to 5–6 mm/s during sudden spikes. The wear (ground truth) crosses 0.5 (label switching threshold) around 28 hours, passes through 1.0 (nonlinear threshold) around 56 hours and accelerates, reaching approximately 1.8 at the 72-hour mark.
The label distribution is as follows.
| Label | Count | Ratio |
|---|---|---|
| normal | 99,640 | 38.4% |
| wear | 158,635 | 61.2% |
| spike | 925 | 0.4% |
Prediction with Chronos-2
Chronos-2 is a foundation model that can predict multivariate time series in a zero-shot manner, accepting 3D tensor input of predict_quantiles((1, n_var, ctx)) to predict all sensors simultaneously. In this article, I wrote a minimal wrapper myself.
from chronos import BaseChronosPipeline
pipeline = BaseChronosPipeline.from_pretrained(
"autogluon/chronos-2-small", # 28M
device_map="cuda",
dtype=torch.bfloat16,
)
# X: (T, V) = (3600, 4) 3600 rows × 4 sensors
ctx = torch.tensor(X.T[None, :, :], dtype=torch.float32) # (1, V, T)
quantiles_list, _ = pipeline.predict_quantiles(
ctx,
prediction_length=16,
quantile_levels=[0.1, 0.5, 0.9],
)
preds = quantiles_list[0].cpu().numpy()[:, :, 1].T # (h, V) median
When running 72 hours worth of data (16,177 windows, ctx=256 / h=16 / stride=16) on DGX Spark, the following latencies were observed. The numbers are from measurements in spike-only mode, and latency is nearly the same in wear+spike mode.
| Model | Parameters | Latency p50 | p95 | wall (16,177 win) |
|---|---|---|---|---|
Chronos-2 28M (autogluon/chronos-2-small) |
28M | 4.07 ms | 4.16 ms | 66.3 s |
Chronos-2 120M (amazon/chronos-2) |
120M | 7.06 ms | 7.29 ms | 114.9 s |
The 28M model takes approximately 4 ms per window, which comfortably fits within a typical PLC scan cycle (100 ms to 1 second). The 120M model is about 1.7x slower, but still comes in under 10 ms, which is well within budget for near-real-time monitoring.
Overlaying the prediction curve for a single window looks like this.
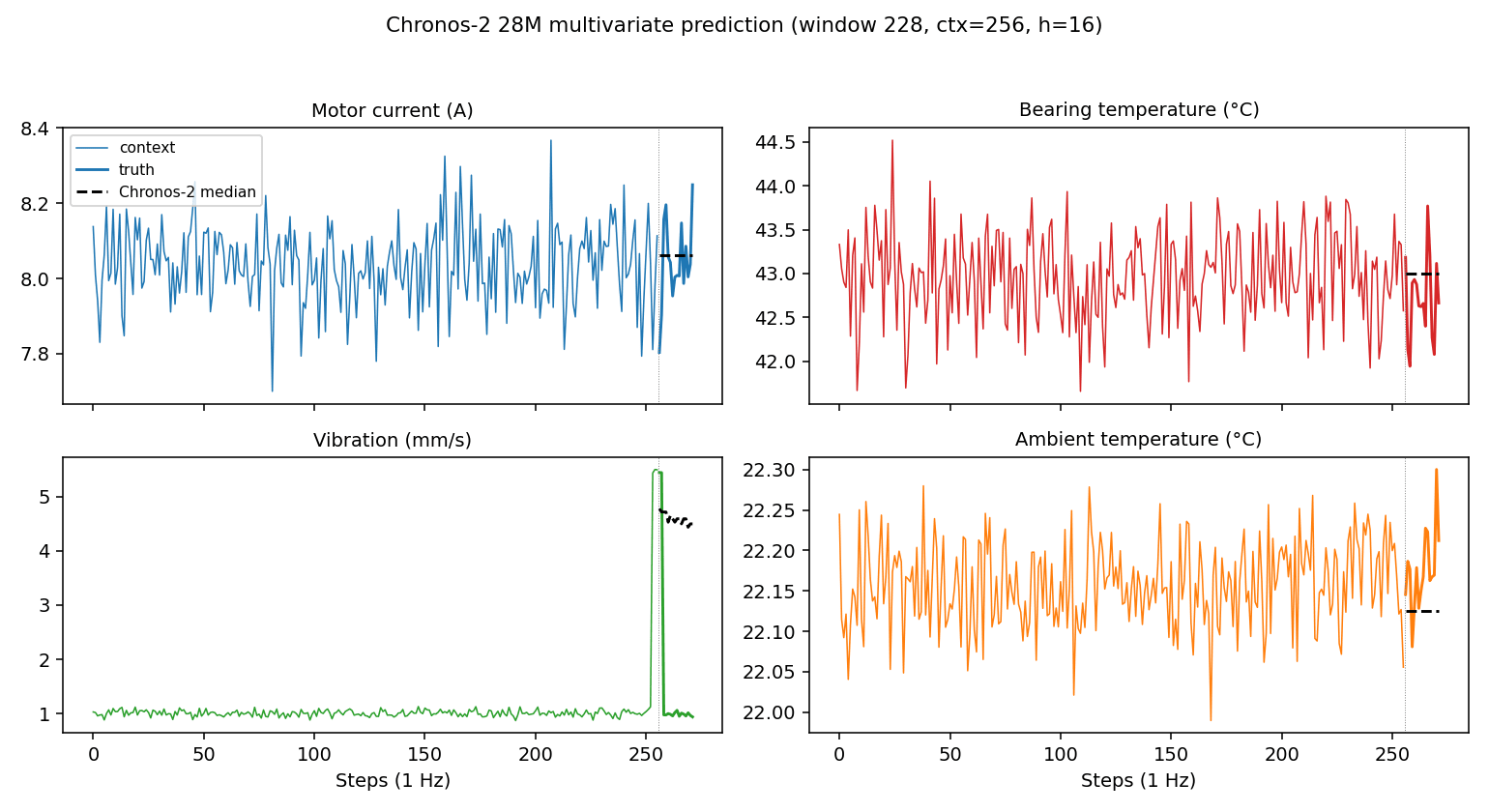
For all 4 channels — current, temperature, vibration, and ambient temperature — the median prediction extends gently as a continuation of the trend. Chronos-2 has a tendency to straightforwardly extend the direction of the context, so gradual drift is reflected as-is in the predicted values.
Anomaly Score and Threshold
The deviation between prediction and ground truth is treated as a residual, converted to per-sensor residuals in z-score space, and then aggregated. The z-score baseline is fit from the first 6 hours (the normal interval before degradation).
diff = (pred - truth) / std # (N, h, V)
per_sensor = np.mean(np.abs(diff), axis=1) # (N, V)
score_mean = per_sensor.mean(axis=1) # Aggregated (N,)
Three aggregation strategies were tested: mean, max, and pca. Mean averages the residuals across all sensors for stability, max is sensitive to outliers in any single sensor, and pca projects per-sensor residuals onto the principal component direction to capture breakdowns in the correlation structure between sensors.
Let me first clarify the verification approach. Chronos-2 is a foundation model that straightforwardly predicts the continuation of a time series, so gradual degradation (wear) gets reflected directly in the predicted values as "a continuation of the trend so far." As a result, residuals between prediction and ground truth remain small even during degradation, and only jump up significantly during sudden spikes.
Without accounting for this, measuring AUC with "wear + spike both as positive labels" resulted in near-random 0.51 for both 28M and 120M. This shows that detecting wear with residuals alone is difficult for Chronos-2 by itself. Rather than relying on Chronos-2 alone for gradual drift detection, I'll delegate that to a separate layer such as a moving average, and focus this article on sudden spikes where Chronos-2 excels.
[metrics:mean] AUC=0.51 F1=0.56 FAR=0.49 MAR=0.49
[metrics: max] AUC=0.51 F1=0.55 FAR=0.51 MAR=0.50
[metrics: pca] AUC=0.52 F1=0.56 FAR=0.49 MAR=0.49
When changing to "spike-only as the positive label," the results change dramatically.
| Model | Label | AUC (best) | F1 | FAR | MAR |
|---|---|---|---|---|---|
| 28M | wear + spike | 0.517 (pca) | 0.56 | 0.49 | 0.49 |
| 28M | spike-only | 0.999 (pca) | 0.83 | 0.006 | 0.000 |
| 120M | wear + spike | 0.518 (pca) | 0.56 | 0.49 | 0.49 |
| 120M | spike-only | 0.994 (mean) | 0.75 | 0.007 | 0.11 |
In spike-only mode, the 28M model achieved MAR=0.000, meaning it missed none of the 232 spikes. The 120M model also achieved a near-equivalent AUC=0.99, but F1 dropped from 0.83 to 0.75 and MAR rose to 0.11.
With the combination of this article's simulator and spike-only labels, a larger model is not necessarily advantageous for anomaly detection. A plausible explanation is that 120M picks up on the subtle fluctuations just before a spike from the context too well, effectively predicting the upcoming spike as an extension of the trend, making the residuals less prominent. The benefits of multivariatization and the compatibility of parameter scale with residual-based detection will be explored further in a separate verification article using publicly available datasets.
The relationship between anomaly scores and thresholds over time looks like this.
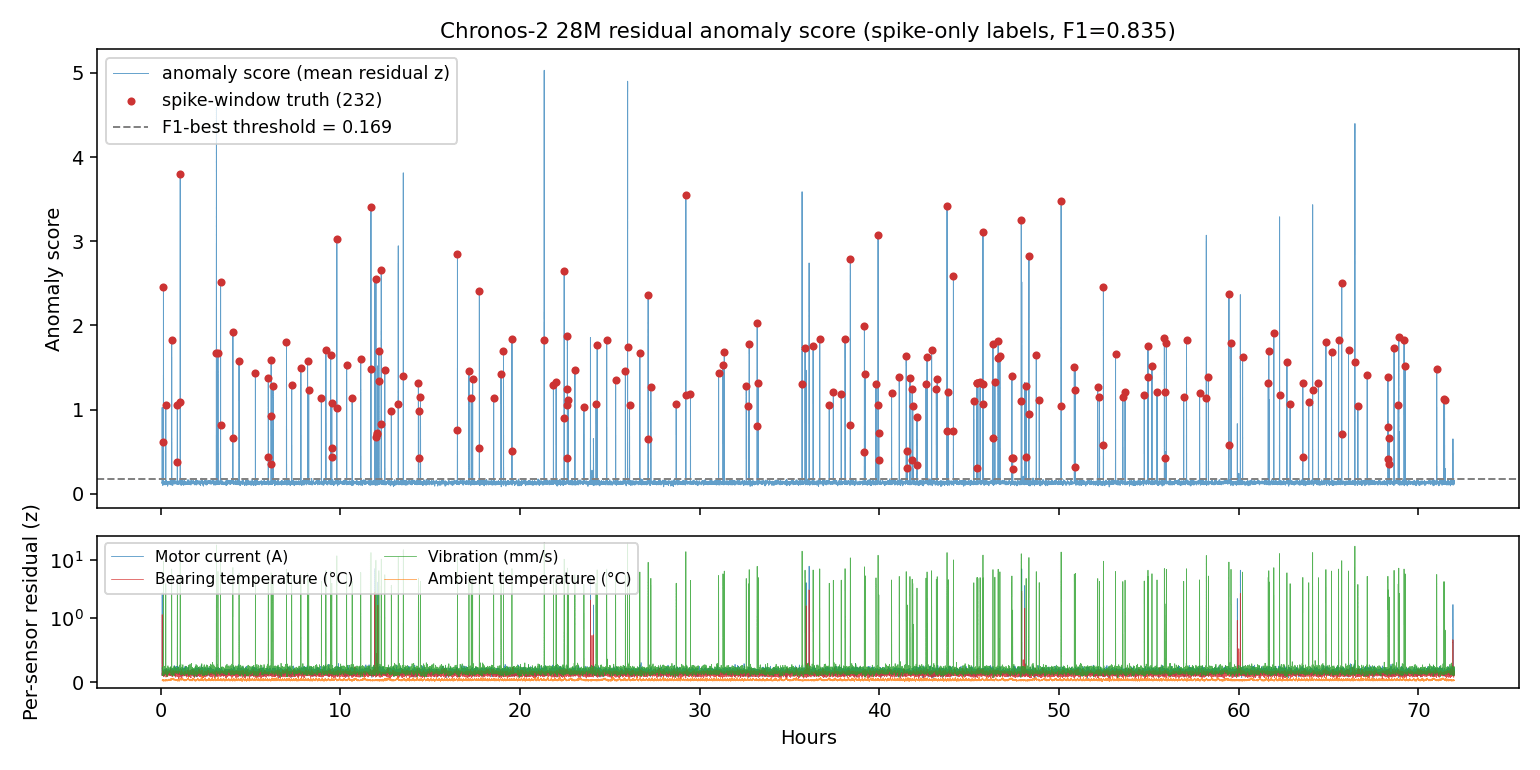
You can see the score spiking up sharply only at the moments when spikes occur. The gradual progression of wear remains in the background and barely appears in the score. This clearly illustrates Chronos-2's characteristic of being strong against sudden anomalies but weak against drift.
Going forward, if you want to actually catch the degradation that matters in the field (the kind that progresses quietly over several days), you'd want to run a moving-average-based monitoring layer alongside Chronos-2 that watches whether the absolute z-score value is gradually creeping upward over time. I think it's more practical to treat a model that's strong against sudden anomalies and a technique that's strong against slow changes as separate tools with different intended uses.
Maintenance Comment Generation with Nemotron LLM
Once we have the anomaly scores and residuals, we pass them to the LLM to turn them into human-readable maintenance comments. To keep everything self-contained on a single DGX Spark, I launched Nemotron 3 Nano 30B-A3B-NVFP4 as a local LLM via vLLM. As an Active 3B MoE, inference is fast, and NVFP4 quantization keeps it around 18GB.
vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 \
--host 0.0.0.0 --port 8001 \
--served-model-name nemotron-3-nano-nvfp4-local \
--max-model-len 8192 \
--max-num-seqs 4 \
--gpu-memory-utilization 0.5 \
--enforce-eager \
--moe-backend flashinfer_cutlass \
--trust-remote-code
--moe-backend flashinfer_cutlass is required for NVFP4 quantization — leaving this out causes load failures in the MoE portions of the Nemotron 3 series. --enforce-eager is an option that disables CUDA graph capture to stabilize loading.
The prompt was structured as follows.
SYSTEM = (
"You are a maintenance engineer for industrial equipment."
"Look at the anomaly scores and sensor values from the time series model,"
"and return a short maintenance comment (1-2 sentences) that would be useful on the shop floor."
"Base your comment only on observed values, not speculation."
"Avoid fabricated past cases or unsubstantiated definitive statements (e.g., 'will definitely fail')."
)
The observation data is passed as JSON in the user message. An important note: per_sensor_residual_zscore is a dimensionless anomaly score (z-score), while recent_sensor_values contains raw sensor values in physical units (A / °C / mm/s) — these two must be treated as distinct.
{
"window_index": 228,
"anomaly_score_mean_zscore": 3.7965,
"per_sensor_residual_zscore": {
"motor_current_a": 0.1805,
"bearing_temp_c": 0.1083,
"vibration_mm_s": 14.8165,
"ambient_temp_c": 0.0809
},
"recent_sensor_values": {
"motor_current_a": 8.1126,
"bearing_temp_c": 42.5778,
"vibration_mm_s": 5.4951,
"ambient_temp_c": 22.4882
},
"scaler_baseline_anomaly_free_6h": {
"motor_current_a": { "mean": 8.0515, "std": 0.4946 },
"vibration_mm_s": { "mean": 1.0383, "std": 0.218 }
}
}
With temperature 0.2, Nemotron's thinking mode OFF (reasons explained in the next section), and max_tokens=200, sending to 6 windows (3 true positives + 3 false positives) produced the following outputs.
True Positive (spike) Examples
[window 228] anomaly_score=3.80 / vibration residual z=14.82
The anomaly score is high at 3.7965, and in particular, vibration
at 14.8 mm/s significantly exceeds the reference value
(mean 1.04 ± 0.22), suggesting maintenance is warranted.
However, motor current at 8.11 A and bearing temperature at 42.58 °C
remain near their nominal averages, so the basis for anomaly
is limited to the vibration data.
[window 6557] anomaly_score=3.54 / vibration residual z=13.80
The mean anomaly score Z-score is high at 3.54, and vibration
has risen to approximately 22.5 times the mean (4.98 mm/s).
Motor current and bearing temperature are within normal range,
but the vibration anomaly is pronounced.
These comments identify vibration as the root cause while also noting that the other sensors are normal — making them immediately useful for a maintenance technician to understand the situation.
False Positive (false alarm) Example
[window 5828] label=0 (normal) / anomaly_score=4.90 / vibration residual z=19.28
The recent vibration has risen significantly from the mean value
(1.04 mm/s), and the residual Z-score of approximately 19.3 is
abnormally high.
On the other hand, motor current, bearing temperature, and ambient
temperature are all near their average values, and can be judged
to show no particular anomaly.
This is the most interesting response in the article. Chronos-2 judged this as "anomalous" with a score of 4.90, yet Nemotron concluded "no particular anomaly" based on the other sensors being normal. This mirrors the same process a human maintenance technician would use when combining multiple pieces of evidence to make a judgment.
Response Quality and Caveats
Up to this point, at temperature 0.2 the outputs were quite stable, but when running 3 repetitions at temperature 0.7 (same window × 3 requests), clear inconsistencies emerge.
Failure Pattern 1: Confusion of z-score and physical units
[window 4784, rep 1] T=0.7
Vibration significantly exceeds the mean value (approximately 19.8 mm/s),
so an anomaly has been detected.
The actual vibration value is 5.8 mm/s, and 19.8 is the z-score residual. The LLM confused per_sensor_residual_zscore: 19.8 with recent_sensor_values: 5.82 in the prompt and wrote "19.8 mm/s."
Failure Pattern 2: Conflicting root cause sensors for the same window
[window 228, rep 1]
Motor current (8.11A) and bearing temperature (42.58°C)
have a high anomaly score (3.79) compared to the normal data
from the past 6 hours and have been detected as outliers.
[window 228, rep 2]
Vibration is significantly high at 5.50 mm/s compared to the
mean of 1.04 mm/s, and a residual Z-score of 14.8 is the
primary driver of the anomaly score.
In reality, only vibration is anomalous, and motor current and temperature are within normal range. Rep 1 is incorrect, rep 2 is correct. Two responses to the same input point to completely different root causes.
Failure Pattern 3: Logical contradiction
[window 5828, rep 0] T=0.7
The anomaly score (Z-score average 4.9) and the vibration residual
(approximately 19.3) stand out, and in particular an anomalous trend
was observed where vibration significantly exceeds the mean value.
However, since the recent measured value of vibration (approximately
5.8 mm/s) is not significantly above the reference average
(approximately 1.0), please note that the current anomaly score is
based on past residuals and does not indicate an immediate risk of failure.
5.8 mm/s is approximately 5.6 times the reference of 1.0 mm/s — a value that is clearly "significantly above." The LLM quotes the numbers but fails to compare them correctly.
Mitigations
Running with temperature 0.2 + thinking mode OFF significantly reduces these failures.
max_tokens was set to 200 based on the intent of "1-2 sentence Japanese maintenance comments," and the measured completion_tokens indeed ranged from 80 to 150. This also helps avoid latency increases from excessive generation.
For the hallucinations that remain even then (particularly z-score vs. physical unit confusion), additional measures such as explicitly stating "z-score is dimensionless, recent_sensor_values are in physical units" in the prompt, or augmenting with retrieval to provide "reference values for the same sensor in the past," seem warranted.
There are three advantages unique to local LLM: it can return maintenance comments offline even when the network is down; latency of 2–4 seconds is well within the tolerance of decision loops on the order of minutes; and sensitive sensor data doesn't need to be sent to the cloud, making it easier to adopt in environments with data export restrictions.
Production Expansion Mapping
At this point, we have a minimal reference implementation running on a single DGX Spark. The table below shows how each component maps to real-world services when moving toward production predictive maintenance. Please note that these are reference mappings not verified within this article.
| Minimal configuration (this article, single DGX Spark) | Production expansion (AWS) | Production expansion (Azure / on-premises) |
|---|---|---|
| Custom PLC-style simulator | Actual PLC + OPC UA / Modbus TCP / MQTT | Same + Azure IoT Hub |
| CSV / deque for recent windows | AWS IoT SiteWise / Timestream | InfluxDB / TimescaleDB / Azure Data Explorer |
| Chronos-2 local single-machine inference | SageMaker Endpoint / Bedrock Marketplace | Azure ML Endpoint / on-premises Triton |
| Nemotron Nano 30B-A3B-NVFP4 local | Bedrock Claude / Nova, or same Nemotron running in cloud inference | Azure OpenAI / on-premises vLLM |
| matplotlib timeline | Amazon Managed Grafana / QuickSight | Azure Managed Grafana / Power BI |
| Single node | IoT Greengrass edge + AWS cloud aggregation | Azure IoT Edge + Azure ML |
| Manual prompt | Bedrock Agent / MCP Server integration | Azure AI Agent Service |
The collection path for connecting to actual PLCs (OPC UA / Modbus TCP / MQTT / time series DB selection) is outside the scope of this article, and I focused exclusively on the Chronos-2 + LLM combination under the assumption that "the simulator is playing the role of a PLC."
Summary and Next Steps
On a single DGX Spark, I connected "PLC-style data generation → Chronos-2 multivariate prediction → residual scoring → local LLM writing Japanese maintenance comments" into a single reference implementation. The main findings from the verification are as follows.
- Chronos-2 is extremely strong against sudden spikes (spike-only AUC=0.999, MAR=0.000)
- Gradual drift is absorbed by the prediction model as "an extension of the forecast," making it difficult to detect with residual-based methods (AUC≈0.51)
- A larger model is not necessarily advantageous for anomaly detection (28M F1=0.83 vs 120M F1=0.75)
- Local LLM maintenance comments are fairly stable at temperature 0.2 + thinking OFF, but confusion of z-score vs. physical units and conflicting root causes become noticeable at temperature 0.7
All verification was completed on a single DGX Spark (128GB). The verification code is available at himorishige/dgx-spark-blog/chronos2-plc-sim/. It is configured so that the same results can be reproduced on your own DGX Spark or any CUDA-compatible GPU with the flow uv sync && python run_simulation.py --hours 72 && python predict_pipeline.py --model chronos2-28m --positive-kinds spike && python comment_pipeline.py.
Future areas I'd like to explore include the following.
- Switching the data collection side to AWS IoT SiteWise + Timestream
- Running Chronos-2 on a SageMaker Endpoint and having Bedrock Claude write maintenance comments via Lambda
- Making it callable from Claude Code via an MCP Server, so that a development agent can directly invoke the simulator
- Investigating layered integration with Cosmos Reason (image/video understanding model), a so-called three-layer Physical AI architecture
- Placing anomaly scores and LLM comments side by side on a Grafana dashboard
What this verification confirmed is that "using Chronos-2 to catch sudden anomalies while relying on separate methods to monitor slow degradation" is a realistic division of responsibilities for real-world use. Rather than trying to handle everything with a single model, the idea of combining tools by leveraging their respective strengths seems like a solid foundation for bringing time series foundation models into real projects.
I hope this serves as a useful starting point for those who want to get hands-on with Chronos-2 from scratch, or for those who want to try building a pipeline that returns "field-relevant language" using a local LLM.

