
Chronos-2 で PLC 風時系列データを予測し、Nemotron で保全コメントを生成してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
今回は、Amazon Chronos-2 と DGX Spark 上のローカル LLM(Nemotron 3 Nano 30B-A3B-NVFP4)を組み合わせて、PLC 風データに対する次のような流れを 1 本のリファレンス実装にしてみます。
- 自作の PLC 風シミュレータで電流・温度・振動・周囲温度を 1Hz で 72 時間分作る
- Chronos-2 で多変量予測を流し、残差から異常スコアを計算する
- 高スコアの window を抽出して、ローカル LLM に「保全コメント」を日本語で書かせる
実機 PLC なしで 0 → 1 のハンズオンを通せる構成にしつつ、章末の「本番拡張マッピング」では各コンポーネントを実環境のサービス(AWS IoT SiteWise / Timestream / SageMaker / Bedrock など)に置き換える対応関係を示します。
なお、本記事のスコープは Chronos-2 単独で 0 → 1 のハンズオンと LLM 連携までです。実機 PLC との接続経路や TimesFM 2.5 など他の時系列基盤モデルとの比較は対象外で、それぞれ別の記事で深掘りする予定です。
検証はすべて DGX Spark(128GB)1 台で完結します。
検証構成
検証構成は次のとおりです。
各ブロックはそのまま AWS IoT SiteWise(PLC データ収集)→ Timestream / TimescaleDB(時系列 DB)→ SageMaker Endpoint(時系列モデル)→ Bedrock / 同 LLM(解釈レイヤ)に置き換えできるので、本番予兆保全のリファレンス実装を想定しています。
PLC 風シミュレータの設計思想
今回は PLC 風シミュレータを用意して検証しています。
- 読者が自分の手元で同じ系列を再現できる(PLC 実機がないと進めない記事だと、読み終わっても何も動かせなくて寂しいですね)
- 劣化や突発スパイクのタイミングをこちらで思いどおりに動かせるので、Chronos-2 が何を拾って何を見逃しているかが切り分けやすい
- 「正常区間 → 劣化進行 → 突発異常」の物語を 72 時間に圧縮できる
実機 PLC(OPC UA / Modbus TCP / MQTT)との接続経路は本記事のスコープ外として、シミュレータが PLC 役を演じるイメージで進めます。
設計は次の 6 ブロック構成にしました。
FactoryState 運転モード / シフト / 周囲温度
LoadGenerator 昼夜 + 正弦 + ノイズ + 切替ディップ
EquipmentPhysics 負荷 → 電流 → 温度 → 振動の連鎖
SensorGenerator ガウスノイズ + 稀なドロップアウト
FailureInjector 線形劣化 + 非線形加速 + 突発スパイク
StreamPublisher CSV 書き出し + 直近 window の deque
ポイントは EquipmentPhysics で「負荷 → 電流 → 温度 → 振動」を多変量の因果として作り込んだところです。Chronos-2 のように共変量を扱える時系列基盤モデルは、こうしたセンサ間の相関を活かして予測精度を上げてくるはずなので、現場と同じ性質のデータを与えたい狙いがあります。
シミュレータ実装
EquipmentPhysics は「過学習させないシンプルな線形 + 摩耗依存」を狙いました。Chronos-2 が context から丸暗記して未来を当ててしまわないように、式は素直に保ちます。電流・温度・振動は次のような形で計算しました。
current = line_speed * 0.10 + 2.0 * wear # 摩耗で電流増
bearing_temp = ambient + load * 0.30 + current * 0.20 # 負荷 + 電流で昇温
vibration = 1.0 + 0.5 * wear # 摩耗で振動上昇
FailureInjector は線形劣化(wear_per_step = 5e-6 / step)に加えて、wear が 1.0 を超えると進行が 2.5 倍に加速する後半領域を入れました。突発スパイクは確率 0.0008 / step で発生し、5 ステップ持続したあと自然に収束する状態機械にしてあります。
72 時間(259,200 行)を 1 Hz で生成すると、出力はこのようになりました。
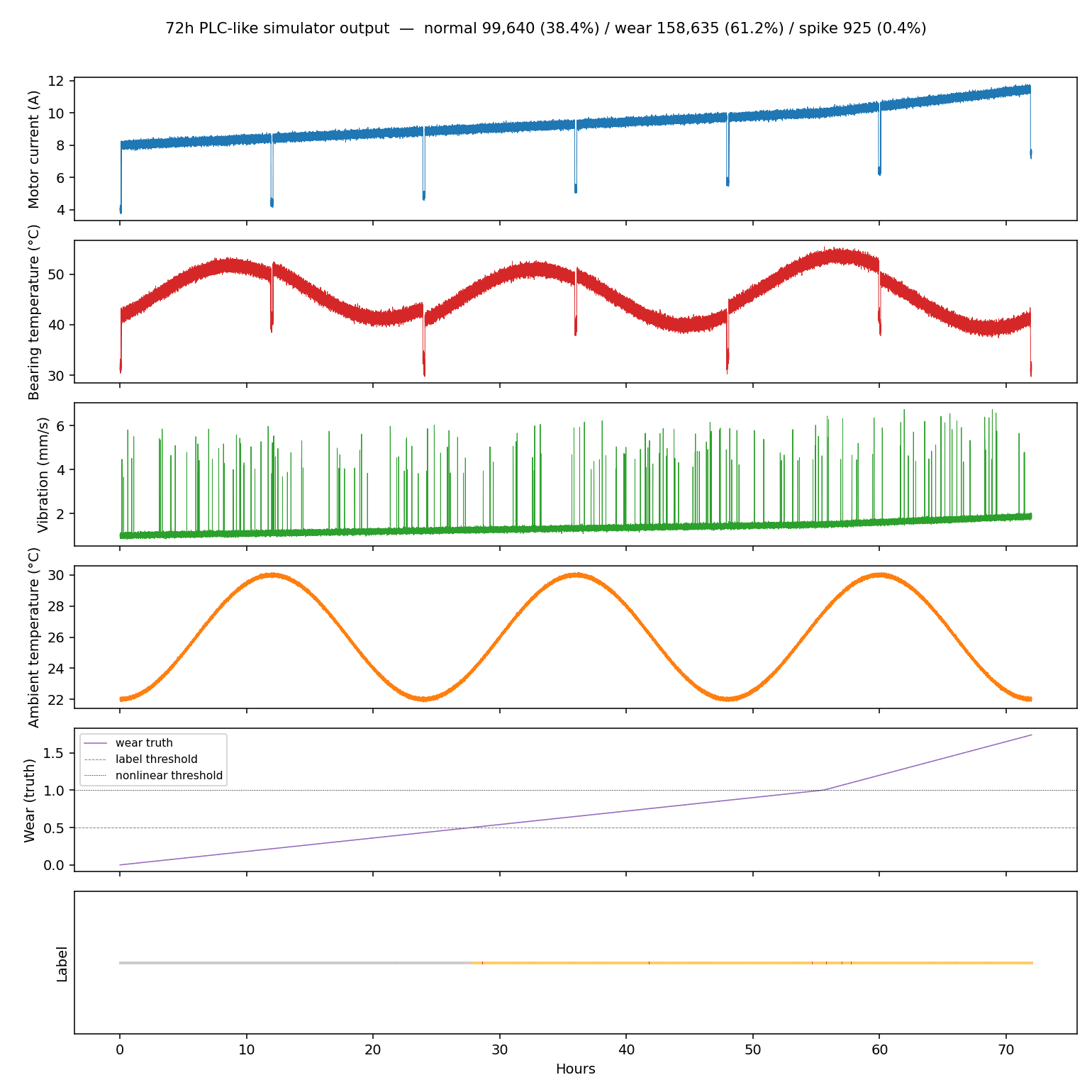
電流・温度・振動はすべて時間と共に底上げされていきます。温度は周囲温度の 24 時間サイクルが上乗せされて正弦的に揺れますね。振動は突発スパイクのときに 5 〜 6 mm/s まで跳ね上がっているのが見えます。wear(真値)は 28 時間付近で 0.5(ラベル切替閾値)を超え、56 時間付近で 1.0(非線形閾値)を通って加速し、72 時間時点で約 1.8 まで進みました。
ラベル分布は次のようになっています。
| ラベル | 件数 | 比率 |
|---|---|---|
| normal | 99,640 | 38.4% |
| wear | 158,635 | 61.2% |
| spike | 925 | 0.4% |
Chronos-2 で予測
Chronos-2 はゼロショットで多変量時系列を予測できる基盤モデルで、predict_quantiles((1, n_var, ctx)) の 3D テンソル入力で全センサを同時に予測できます。本記事では最小限のラッパを自前で書きました。
from chronos import BaseChronosPipeline
pipeline = BaseChronosPipeline.from_pretrained(
"autogluon/chronos-2-small", # 28M
device_map="cuda",
dtype=torch.bfloat16,
)
# X: (T, V) = (3600, 4) 3600 行 × 4 センサ
ctx = torch.tensor(X.T[None, :, :], dtype=torch.float32) # (1, V, T)
quantiles_list, _ = pipeline.predict_quantiles(
ctx,
prediction_length=16,
quantile_levels=[0.1, 0.5, 0.9],
)
preds = quantiles_list[0].cpu().numpy()[:, :, 1].T # (h, V) median
DGX Spark で 72 時間分(16,177 ウィンドウ、ctx=256 / h=16 / stride=16)を流したところ、次のレイテンシになりました。数値は spike-only モードでの測定値で、wear+spike モードでもレイテンシはほぼ同じです。
| モデル | パラメータ | レイテンシ p50 | p95 | wall (16,177 win) |
|---|---|---|---|---|
Chronos-2 28M (autogluon/chronos-2-small) |
28M | 4.07 ms | 4.16 ms | 66.3 s |
Chronos-2 120M (amazon/chronos-2) |
120M | 7.06 ms | 7.29 ms | 114.9 s |
28M は 1 ウィンドウあたり約 4 ms で、典型的な PLC スキャンサイクル(100 ms 〜 1 秒)の中に余裕で収まります。120M は約 1.7 倍ですが、それでも 10 ms を切るので準リアルタイム監視の予算には十分入りますね。
予測曲線を 1 つの window で重ねるとこんな感じです。
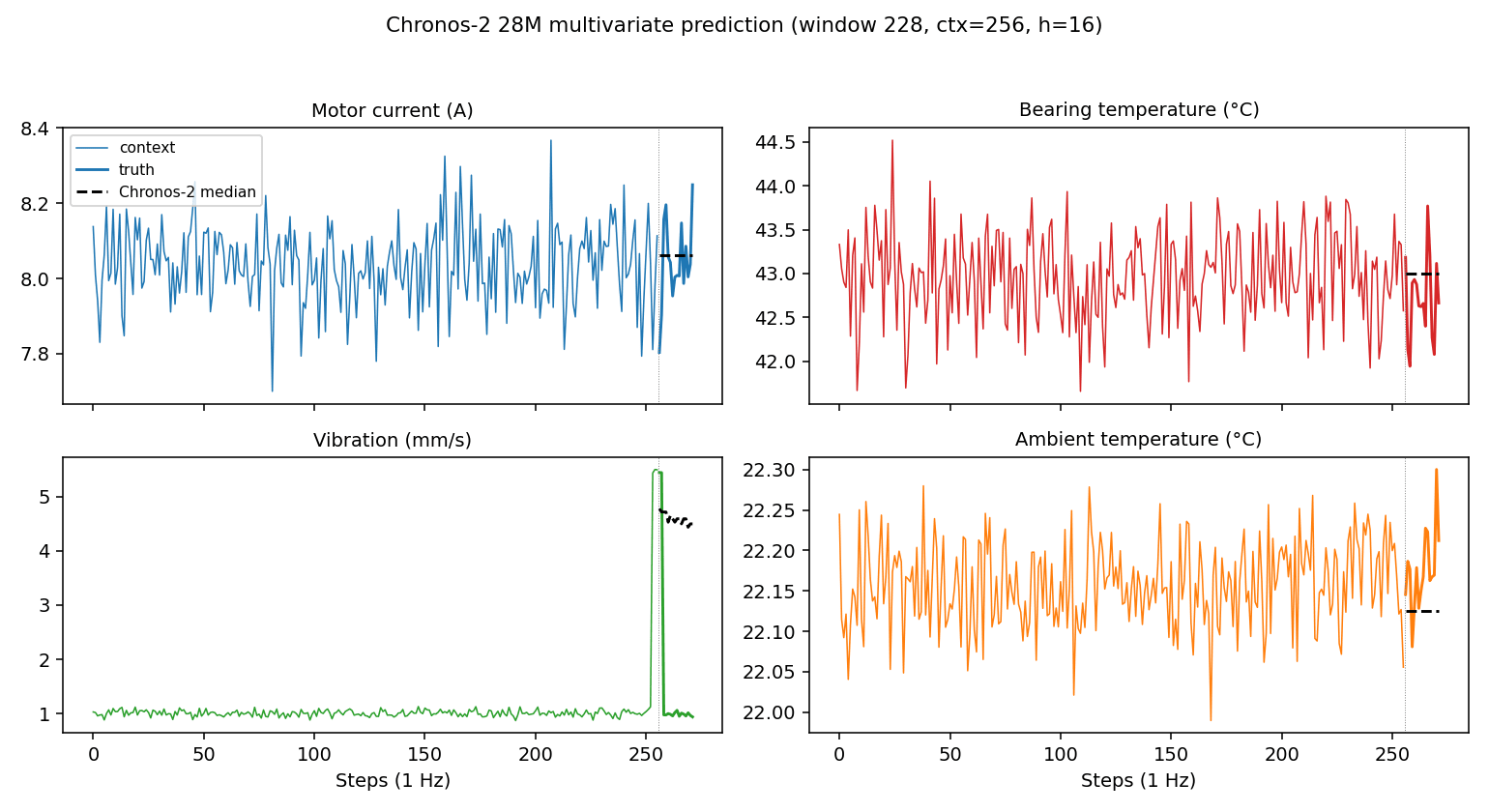
電流・温度・振動・周囲温度の 4 チャネルすべてで、median 予測が緩やかに延長線として伸びていく形になっています。Chronos-2 は context の方向性を素直に伸ばす癖があるので、緩やかな drift はそのまま予測値に反映されます。
異常スコアと閾値
予測と実測のずれを残差として、z-score 空間で per-sensor 残差にしてから集約します。z-score の基準は最初の 6 時間(劣化前の正常区間)から fit します。
diff = (pred - truth) / std # (N, h, V)
per_sensor = np.mean(np.abs(diff), axis=1) # (N, V)
score_mean = per_sensor.mean(axis=1) # 集約 (N,)
集約戦略は mean / max / pca の 3 種類を試しました。mean は全センサの残差を平均するので安定重視、max は 1 センサの外れ値に敏感、pca は per-sensor 残差の主成分方向に射影してセンサ間の相関構造の崩れを拾います。
ここで一度、検証の方針を整理させてください。Chronos-2 は時系列の続きを素直に予測する基盤モデルなので、緩やかに進む劣化(wear)は「これまでの流れの延長」として予測値にそのまま反映してしまいます。結果、予測と実測の残差は劣化中も小さいまま、突発スパイクのときだけ大きく跳ねる、という挙動になります。
これを踏まえずに「wear + spike を両方とも陽性ラベル」にして AUC を測ると、28M も 120M もほぼランダムな 0.51 になりました。残差ベースで wear を拾うのは Chronos-2 単独だと難しいわけですね。緩やかな drift の検出は移動平均などの別レイヤに任せて、本記事では Chronos-2 が得意な突発スパイクに絞って話を進めます。
[metrics:mean] AUC=0.51 F1=0.56 FAR=0.49 MAR=0.49
[metrics: max] AUC=0.51 F1=0.55 FAR=0.51 MAR=0.50
[metrics: pca] AUC=0.52 F1=0.56 FAR=0.49 MAR=0.49
そこで「spike だけを陽性ラベル」にすると、結果は一気に変わります。
| モデル | ラベル | AUC (best) | F1 | FAR | MAR |
|---|---|---|---|---|---|
| 28M | wear + spike | 0.517 (pca) | 0.56 | 0.49 | 0.49 |
| 28M | spike-only | 0.999 (pca) | 0.83 | 0.006 | 0.000 |
| 120M | wear + spike | 0.518 (pca) | 0.56 | 0.49 | 0.49 |
| 120M | spike-only | 0.994 (mean) | 0.75 | 0.007 | 0.11 |
28M は spike-only モードで MAR=0.000、つまり 232 件のスパイクをひとつも見逃しませんでした。120M も AUC=0.99 とほぼ同等ですが、F1 が 0.83 → 0.75 に下がり、MAR が 0.11 まで上昇しています。
本記事のシミュレータと spike-only ラベルの組み合わせでは より大きなモデルが必ずしも異常検知に有利ではない という結果になりました。120M は spike 直前の微弱な揺らぎを context から拾いすぎて、次に来るスパイクを予測の延長で当ててしまうために残差が立ちにくくなる、と説明できそうです。多変量化のメリットとパラメータ規模・残差ベース検出の相性については、別途公開データセットでの検証記事で深掘りする予定です。
異常スコアと閾値の関係を時系列で示すとこうなります。
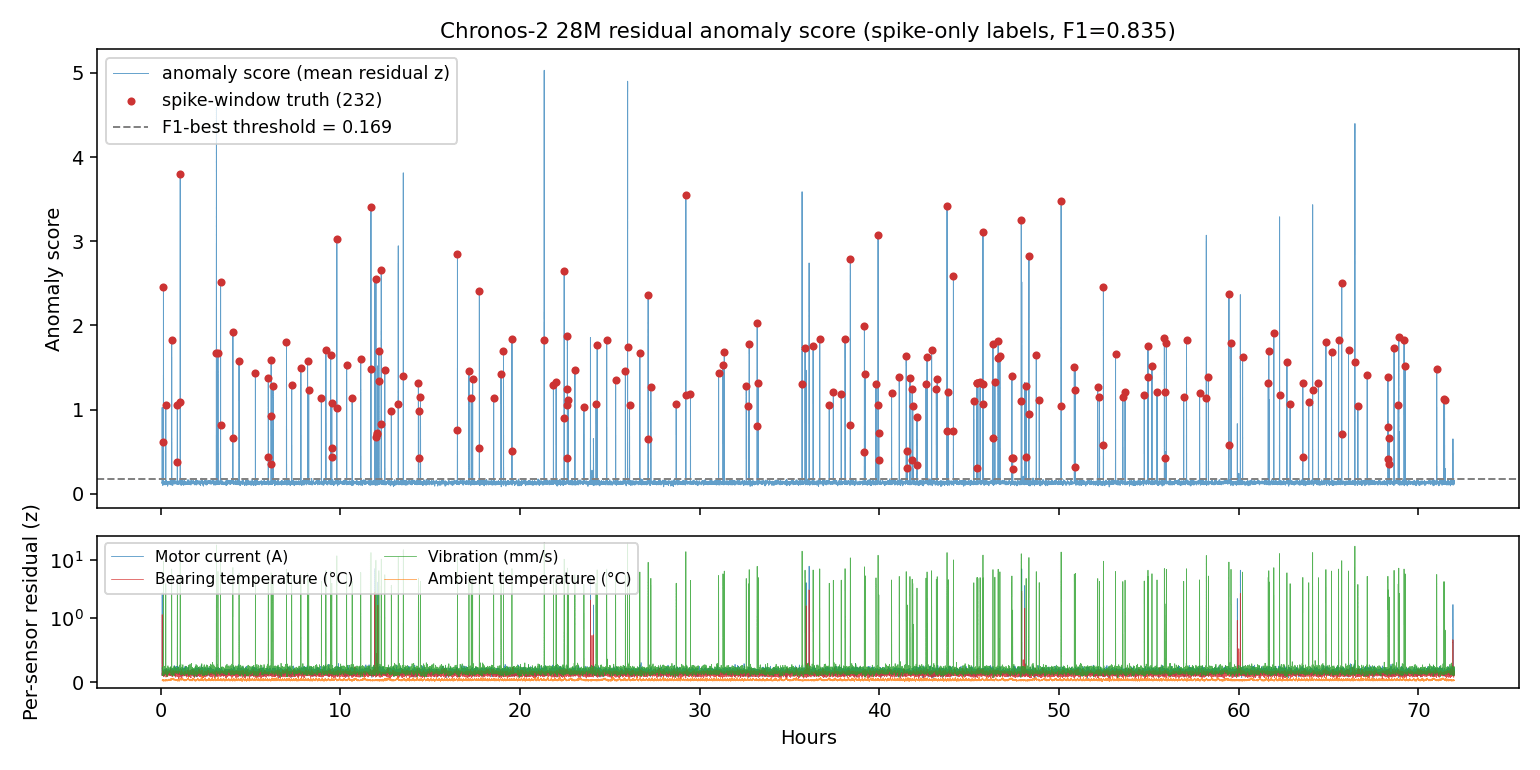
スパイクが発生するタイミングだけ、スコアが急に立ち上がっているのが見えます。緩やかな wear の進行は背景のままで、スコアにはほとんど現れません。これが Chronos-2 の 突発には強いが、drift には弱い という性格をはっきり示している図ですね。
ここから先、現場で本当に拾いたい劣化(数日かけて静かに進行するもの)を捕まえたいなら、Chronos-2 単独ではなく、別レイヤとして「z-score の絶対値が時間と共にじわじわ上がっているか」を見るような移動平均ベースの監視を並走させたいところです。突発に強いモデルと、ゆっくりした変化に強い手法は、本来の用途が違うものとして使い分けるのが現実的かなと思っています。
Nemotron LLM で保全コメント生成
異常スコアと残差が手に入ったら、これを LLM に渡して人間が読める保全コメントにしてもらいます。DGX Spark 単機で完結させたいので、ローカル LLM として Nemotron 3 Nano 30B-A3B-NVFP4 を vLLM で起動しました。Active 3B の MoE なので推論は速く、NVFP4 量子化で 18GB 程度に収まります。
vllm serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 \
--host 0.0.0.0 --port 8001 \
--served-model-name nemotron-3-nano-nvfp4-local \
--max-model-len 8192 \
--max-num-seqs 4 \
--gpu-memory-utilization 0.5 \
--enforce-eager \
--moe-backend flashinfer_cutlass \
--trust-remote-code
NVFP4 量子化には --moe-backend flashinfer_cutlass が必須で、ここを忘れると Nemotron 3 系の MoE 部分でロードに失敗します。--enforce-eager は CUDA graph capture を切ってロードを安定させるオプションですね。
プロンプトは次のように組みました。
SYSTEM = (
"あなたは産業設備の保全エンジニアです。"
"時系列モデルによる異常スコアとセンサー値を見て、"
"現場で参考になる短い保全コメント(1〜2文)を返してください。"
"推測ではなく、観測された数値だけを根拠にしてください。"
"実在しない過去事例や根拠のない確定的表現(必ず故障する等)は避けてください。"
)
ユーザーメッセージには JSON で観測情報を渡します。注意点として per_sensor_residual_zscore は z-score(無次元)の異常度、recent_sensor_values は物理単位(A / °C / mm/s)の生センサ値で、両者は別物として扱う必要があります。
{
"window_index": 228,
"anomaly_score_mean_zscore": 3.7965,
"per_sensor_residual_zscore": {
"motor_current_a": 0.1805,
"bearing_temp_c": 0.1083,
"vibration_mm_s": 14.8165,
"ambient_temp_c": 0.0809
},
"recent_sensor_values": {
"motor_current_a": 8.1126,
"bearing_temp_c": 42.5778,
"vibration_mm_s": 5.4951,
"ambient_temp_c": 22.4882
},
"scaler_baseline_anomaly_free_6h": {
"motor_current_a": { "mean": 8.0515, "std": 0.4946 },
"vibration_mm_s": { "mean": 1.0383, "std": 0.218 }
}
}
温度 0.2、Nemotron の thinking モードは OFF(理由は次章で詳しく触れます)、max_tokens=200 で 6 ウィンドウ(真陽性 3 + 偽陽性 3)に投げると、こんな出力が返ってきました。
真陽性(spike)の例
[window 228] anomaly_score=3.80 / vibration residual z=14.82
異常スコアが 3.7965 と高く、特に振動が 14.8 mm/s と
基準値(平均 1.04 ± 0.22)を大幅に上回っているため、
保守対象が示唆されます。
ただし、モータ電流 8.11 A やベアリング温度 42.58 °C は
規格上の平均値付近に収まっており、異常の根拠は振動データに
限られます。
[window 6557] anomaly_score=3.54 / vibration residual z=13.80
異常スコアの平均Zスコアが3.54と高く、振動が平均の
約22.5倍(4.98 mm/s)に上昇しています。
モータ電流や軸受温度は通常範囲内ですが、振動の異常が
顕著です。
「振動が原因」と特定しつつ、他のセンサが正常であることまで言及している点で、保全担当者がそのまま読んで状況把握できる文章になっていますね。
偽陽性(false alarm)の例
[window 5828] label=0 (正常) / anomaly_score=4.90 / vibration residual z=19.28
直近の振動が平均値(1.04 mm/s)から大幅に上昇し、
残差Zスコアが約19.3と異常に高いです。
一方、モータ電流やベアリング温度、周囲温度は平均値付近に
収まっており、特に異常なしと判断できます。
これが本記事で一番面白い応答です。Chronos-2 はスコア 4.90 で「異常」と判断しているのに、Nemotron は他のセンサが正常であることを根拠に「特に異常なしと判断できます」と書いてきました。現場の保全担当者が複数の証拠を組み合わせて判断するのと同じ流れですね。
応答品質と注意点
ここまでは温度 0.2 でほぼ安定した出力でしたが、温度 0.7 で 3 回繰り返し(同じ window × 3 リクエスト)にすると、明らかなブレが出ます。
失敗パターン 1: z-score と物理単位の混同
[window 4784, rep 1] T=0.7
振動が平均値を大幅に上回る(約19.8 mm/s)ため、
異常が検出されています。
実際の振動値は 5.8 mm/s で、19.8 は z-score 残差です。LLM がプロンプト内の per_sensor_residual_zscore: 19.8 と recent_sensor_values: 5.82 を混同して「19.8 mm/s」と書いてしまいました。
失敗パターン 2: 同じ window で主因センサが食い違う
[window 228, rep 1]
モータ電流(8.11A)とベアリング温度(42.58℃)が、
過去6時間の正常データに比べて異常スコアが高く(3.79)
外れ値として検出されています。
[window 228, rep 2]
振動は平均 1.04 mm/s と比べ、今回 5.50 mm/s と
著しく高く、残差‑Z スコア 14.8 が異常スコアの主因と
なっています。
実際は振動だけが異常で、モータ電流と温度はほぼ正常範囲内です。rep 1 は誤読、rep 2 は正答。同じ入力に対する 2 つの応答がまったく違う主因を指摘してきます。
失敗パターン 3: 論理矛盾
[window 5828, rep 0] T=0.7
異常スコア(Zスコア平均 4.9)と振動の残差(約 19.3)が
目立ち、特に振動が平均値を大きく上回っている異常傾向が
観測されました。
ただし、振動の直近の測定値(約 5.8 mm/s)は基準値の
平均(約 1.0)を大きく上回っていないため、現在の異常スコアは
過去の残差に基づくものであり、即時的な故障リスクを
示すものではないことを留意してください。
5.8 mm/s は基準 1.0 mm/s の約 5.6 倍で、明確に「大きく上回っている」値です。LLM は数値を引用しながら、それを正しく比較できていません。
緩和策
温度 0.2 + thinking モード OFF で運用すると、これらの失敗はかなり減ります。
max_tokens を 200 に置いたのは「1〜2 文の日本語保全コメント」想定で、実測 completion_tokens も 80〜150 に収まっているからですね。過剰生成によるレイテンシ増を避けたい意図もあります。
それでも残るハルシネーション(特に z-score と物理単位の混同)に対しては、プロンプト側で「z-score は無次元、recent_sensor_values は物理単位」と明記したり、リトリーバル拡張で「過去の同センサのリファレンス値」を添えるなどの工夫が要りそうです。
ローカル LLM ならではの利点は 3 つあります。ネットワーク断時もオフラインで保全コメントが返せること、レイテンシ 2〜4 秒は分単位の判定ループに十分間に合うこと、そして機微なセンサデータをクラウドに送らずに済むので、データ持ち出し制約のある現場でも採用しやすいことですね。
本番拡張マッピング
ここまでで DGX Spark 1 台で動く最小構成のリファレンス実装ができました。本番の予兆保全に持っていく場合、各コンポーネントを実環境のサービスに置き換えるイメージを表にすると次のとおりです。本記事内では検証していない参考対応関係なので、その点はご了承ください。
| 最小構成(本記事、DGX Spark 単機) | 本番拡張(AWS) | 本番拡張(Azure / オンプレ) |
|---|---|---|
| 自作 PLC 風シミュレータ | 実機 PLC + OPC UA / Modbus TCP / MQTT | 同左 + Azure IoT Hub |
| CSV / deque で直近 window | AWS IoT SiteWise / Timestream | InfluxDB / TimescaleDB / Azure Data Explorer |
| Chronos-2 ローカル単機推論 | SageMaker Endpoint / Bedrock Marketplace | Azure ML Endpoint / オンプレ Triton |
| Nemotron Nano 30B-A3B-NVFP4 ローカル | Bedrock Claude / Nova、または同 Nemotron をクラウド推論 | Azure OpenAI / オンプレ vLLM |
| matplotlib タイムライン | Amazon Managed Grafana / QuickSight | Azure Managed Grafana / Power BI |
| 単一ノード | IoT Greengrass エッジ + AWS クラウド集約 | Azure IoT Edge + Azure ML |
| 手動プロンプト | Bedrock Agent / MCP Server 統合 | Azure AI Agent Service |
実機 PLC へつなぐときの収集経路(OPC UA / Modbus TCP / MQTT / 時系列 DB 選定)は本記事のスコープ外として、あくまで「シミュレータが PLC 役を演じている」前提で、Chronos-2 + LLM の組み合わせ部分にフォーカスしました。
まとめと今後
DGX Spark 1 台で「PLC 風データ生成 → Chronos-2 多変量予測 → 残差スコアリング → ローカル LLM が日本語の保全コメント」までを 1 本のリファレンス実装としてつないでみました。検証中に出てきた主な発見はこのあたりですね。
- Chronos-2 は突発スパイクに非常に強い(spike-only AUC=0.999、MAR=0.000)
- 緩やかな drift は予測モデルが「予測の延長」として吸収してしまい、残差ベースでは検出困難(AUC≈0.51)
- より大きなモデルが必ずしも異常検知に有利ではない(28M F1=0.83 vs 120M F1=0.75)
- ローカル LLM の保全コメントは温度 0.2 + thinking OFF でかなり安定するが、z-score と物理単位の混同や主因の食い違いが温度 0.7 で目立つ
検証はすべて DGX Spark(128GB)1 台で完結しました。検証コードは himorishige/dgx-spark-blog/chronos2-plc-sim/ に置いてあります。手元の DGX Spark や任意の CUDA 対応 GPU で uv sync && python run_simulation.py --hours 72 && python predict_pipeline.py --model chronos2-28m --positive-kinds spike && python comment_pipeline.py の流れで同じ結果を再現できる構成にしてあります。
今後試したいこととしては、次のあたりを考えています。
- AWS IoT SiteWise + Timestream にデータ収集側を載せ替え
- SageMaker Endpoint で Chronos-2 を回して、Lambda 経由で Bedrock Claude に保全コメントを書かせる
- MCP Server で Claude Code から呼び出せるようにして、開発エージェントが直接シミュレータを叩く構成
- Cosmos Reason(画像・映像理解モデル)との階層化、いわゆる三層 Physical AI 構成の検討
- Grafana ダッシュボードに異常スコアと LLM コメントを並べる
今回の検証で確信したのは「Chronos-2 で突発を拾い、ゆっくりした劣化は別の手法で見守る」という棲み分けが現場では現実的だということですね。1 つのモデルですべてを片付けようとせず、得意領域を活かして組み合わせる発想が、時系列基盤モデルを実プロジェクトに持ち込むときの土台になりそうです。
Chronos-2 を 0 → 1 で触ってみたい方、ローカル LLM で「現場の言葉」を返すパイプラインを試したい方の出発点として役に立てば嬉しいです。











