
Since Gemma 4 added a 12B model, I tried testing Japanese language performance, voice input, and MTP on the DGX Spark
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
A new size "12B" has been added to Gemma 4. Until now, Gemma 4 consisted of small models (E2B / E4B) and large models (26B-A4B (MoE) / 31B (Dense)), leaving a gap right in the middle. The new 12B fills that gap as a mid-range model, and Google also positions it as a "bridge between E4B and 26B MoE."
I've previously worked with Gemma 4 on DGX Spark twice. The first article benchmarked all sizes in Japanese and multimodal, and the second covered speeding up generation with MTP (Multi-Token Prediction). Since I already have a measuring stick on hand, I decided to put the new 12B on the same playing field to see "where it stands."
There are three noteworthy new features in 12B: a 256K token context, native audio input (the first in the mid-range), and a built-in drafter for MTP. Additionally, according to the official announcement, it can run on just 16GB of memory, making it appealingly accessible. This time, I tested everything on actual DGX Spark hardware—from Japanese text performance to the new audio input feature and MTP speedups.
To give you the conclusion upfront: the 12B's score on the Japanese common sense test was roughly on par with E4B. Looking at text alone, the mid-range advantage doesn't stand out much, but I think the highlights of the 12B are its ability to handle audio with a single model and its ease of use running on 16GB.
What Kind of Model is Gemma 4 12B?
First, let me clarify where the 12B sits within the Gemma 4 family.
| Size | Type | Features |
|---|---|---|
| E2B (2.3B) | Dense | Smallest, edge-oriented |
| E4B (4.5B) | Dense | Small, practical for local use |
| 12B | Dense | New, mid-range, audio input support |
| 26B-A4B | MoE (Active 3.8B) | Medium to large, efficiency-focused |
| 31B | Dense | Largest, highest accuracy |
What I personally found interesting about the 12B is that its architecture is encoder-free. Until now, multimodal models typically converted images and audio into vectors using dedicated encoders before passing them to the language model. Gemma 4 12B feeds both images and audio directly into the LLM body through lightweight embedding layers. On the image side, a 35M-parameter embedding layer replaces what used to be 27 layers of image encoder, projecting 48×48 pixel patches with a single matrix multiplication. On the audio side, the design is boldly simple: 16kHz waveforms are cut into 40ms frames (640 values each) and passed through a linear transformation. Since images, audio, and text all share the same weights, fine-tuning can be done with a single pass covering all modalities.
Here are the main benchmarks released officially:
| Benchmark | Score |
|---|---|
| MMLU Pro | 77.2 |
| AIME 2026 (no tools) | 77.5 |
| LiveCodeBench v6 | 72.0 |
| GPQA Diamond | 78.8 |
| MMMU Pro (image) | 69.1 |
| CoVoST (audio) | 38.5 |
| MRCR v2 (long context) | 43.4 |
Testing Environment and Pitfalls
I ran into trouble right away when trying to run the 12B. At the time I started testing, the stable versions I had on hand (official releases of transformers and vLLM) stopped with this error:
model type `gemma4_unified` but Transformers does not recognize this architecture
The encoder-free architecture of the 12B uses an internal code name gemma4_unified as a new type, which the stable versions at the time didn't yet know. So I followed Google's guidance and installed transformers from the GitHub main branch and vLLM from nightly to proceed.
For testing, I used a two-pronged approach: hitting transformers directly for text, image, and audio accuracy, and using vLLM for MTP speed. After creating a new venv and installing transformers, I was able to load the 12B in bfloat16 using AutoModelForMultimodalLM. The following issues are from the time of testing, but the causes and workarounds are still useful references, so I'm leaving them in.
3 issues I ran into getting 12B working with transformers
- torchvision is required: The 12B's image processing depends on
torchvision.transforms.v2, so without it you'll getModuleNotFoundError: No module named 'torchvision'. - Decoding audio datasets: When loading FLEURS with
datasetsfor evaluation, you getTo support decoding audio data, please install 'torchcodec'. Since torchcodec adds ffmpeg-related dependencies, I worked around this by usingAudio(decode=False)to get the raw bytes and reading them with soundfile. - vLLM's flashinfer sampler does JIT builds: When I tried to serve 12B with vLLM nightly, it failed to start with
FileNotFoundError: 'ninja'. The cause was flashinfer trying to compile sampling kernels on the fly and not finding build tools in PATH. I avoided the JIT itself withVLLM_USE_FLASHINFER_SAMPLER=0, and also added the venv and CUDA to PATH to get it running. This seems like something that will come up for a while when using nightly, so those trying MTP with vLLM should keep it in mind.
Text Performance Nearly Matches E4B — Japanese Common Sense Test
First up is text. I used the same JCommonsenseQA (Japanese common sense reasoning, leemeng/jcommonsenseqa-v1.1) from the first article, with the same conditions: 3-shot, same seed, 1,116 questions. Since the previous numbers used a different backend, I re-measured the comparison sizes (E2B / E4B / 31B) with transformers this time to put them on the same playing field as the 12B.
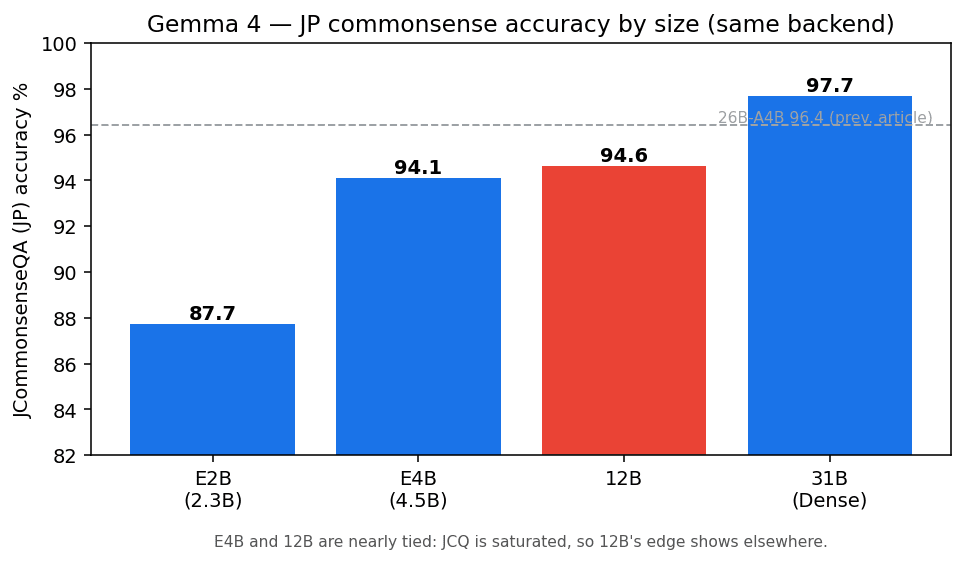
| Size | JCQ Accuracy | Median time per question |
|---|---|---|
| E2B | 87.7% | 0.08 sec |
| E4B | 94.1% | 0.15 sec |
| 12B | 94.6% | 0.32 sec |
| 31B | 97.7% | 4.84 sec |
The 12B scored 94.6%, barely different from E4B's 94.1%. It falls about 3 points short of 31B's 97.7%. The 26B-A4B measured in the first article was 96.4%, so roughly the ranking is E4B ≈ 12B < 26B < 31B.
Hearing "bridge between E4B and 26B" might lead you to expect a score somewhere in between, but this isn't because 12B is weak—it's because JCommonsenseQA already reaches 94% with E4B, close to a ceiling. In the domain of Japanese common sense reasoning, the benefit of going mid-range doesn't easily show up in scores.
In other words, the value of 12B lies elsewhere than text-based common sense tests. Let's look at image and audio next.
Images Challenge University-Level Comprehension — JMMMU
For images, I used JMMMU. It's the Japanese version of MMMU, collecting university-level chart and figure problems from 28 subject areas. The official MMMU Pro (image) score of 69.1 is in English, so I had the model solve 300 questions in Japanese.
The 12B achieved an accuracy of 45.7%. This might seem underwhelming at first glance, but JMMMU is a challenging benchmark that even humans can struggle with depending on the subject. Looking at performance by subject area, clear patterns emerged.
| Strong subjects | Accuracy | Weak subjects | Accuracy |
|---|---|---|---|
| Computer Science | 0.75 | Mechanical Engineering | 0.00 |
| Psychology | 0.75 | Architecture & Engineering | 0.00 |
| World History | 0.71 | Energy | 0.00 |
| Agriculture | 0.70 | Mathematics | 0.20 |
Text-heavy subjects were handled reliably, while engineering fields requiring precise reading of diagrams, circuits, and mechanics were nearly impossible. This is where the limits of a mid-range model show themselves honestly. For applications like manufacturing blueprint analysis, it's best not to have excessive expectations just yet.
Testing the Headlining New Feature: Audio Input in Japanese
This is what I most wanted to test this time. The 12B is the first mid-range model to support audio input.
As mentioned earlier, rather than using a dedicated audio encoder, 16kHz waveforms are cut into 40ms frames and fed directly into the LLM. In transformers, you simply pass an audio array in the message, writing it the same way as images.
content = [
{"type": "audio", "audio": arr}, # numpy array at 16kHz
{"type": "text", "text": "この音声を日本語で正確に書き起こしてください。"},
]
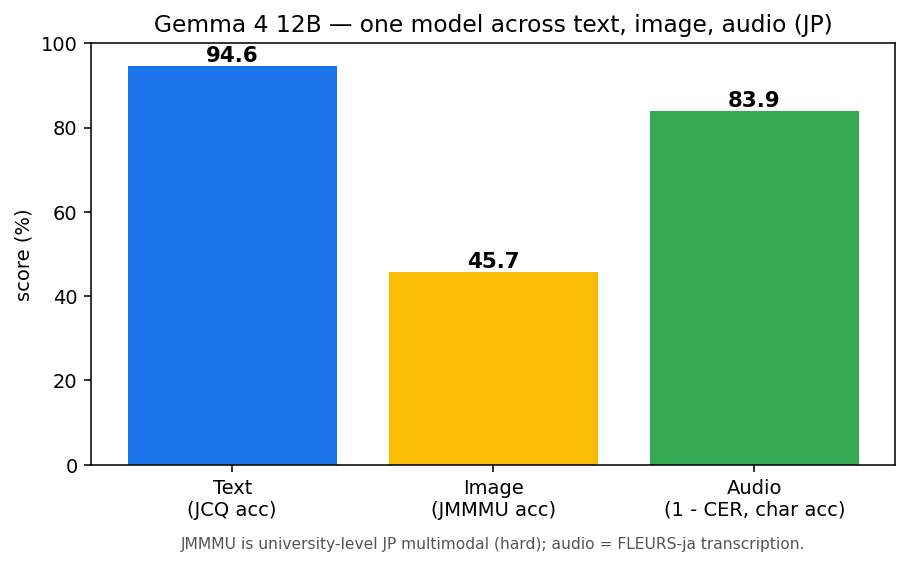
I transcribed 100 Japanese audio clips from FLEURS and evaluated using Character Error Rate (CER). The result was a median of 16.1% and an average of 23.1%. The higher average compared to median is because some difficult audio clips pulled the score up, so the representative quality is better viewed around the median 16%.
The official model card also shows FLEURS CER at 6.9%, but that's a multilingual average excluding Chinese, while I measured Japanese only. Japanese is a challenging language for CER evaluation due to kanji and homophones, so it's natural for the number to be larger than the multilingual average. Accounting for that, a median CER of 16% for Japanese alone is a reasonable result.
Numbers alone can be hard to grasp, so here's one actual transcription example:
Reference: インターネットで 敵対的環境コース について検索すると おそらく現地企業の住所が出てくるでしょう
12B output: インターネットで 適体的な環境公社 について検索すると、おそらく現地企業の住所が出てくるでしょう
Apart from "敵対的環境コース" becoming "適体的な環境公社," the transcription is nearly accurate. The type of error—confusing homophones—feels more like a language model mistake than an acoustic model one, which is interesting to observe.
According to the official documentation, the 12B's audio capabilities extend beyond simple transcription to speaker diarization (distinguishing who is speaking) and video understanding. This test focused on Japanese transcription, but the range of use cases appears broader than expected.
For clean read-aloud audio like FLEURS, dedicated speech recognition models (such as Whisper) achieve single-digit CER for Japanese. In terms of accuracy alone, 12B takes a step back. However, what matters here is the integration: the ability to handle text, images, and audio all with a single model. Summarizing transcribed content directly, or passing both images and audio together for a question—all of this works within one model.
MTP Speeds Up Generation by About 2.8x
Finally, let's look at speed. The 12B comes with a built-in MTP drafter (google/gemma-4-12B-it-assistant). That means the speculative decoding approach from the second article can be applied directly to 12B.
Using vLLM nightly, I compared baseline (no drafter) against MTP with the drafter (speculative tokens = 4) for long-form generation under the same conditions.
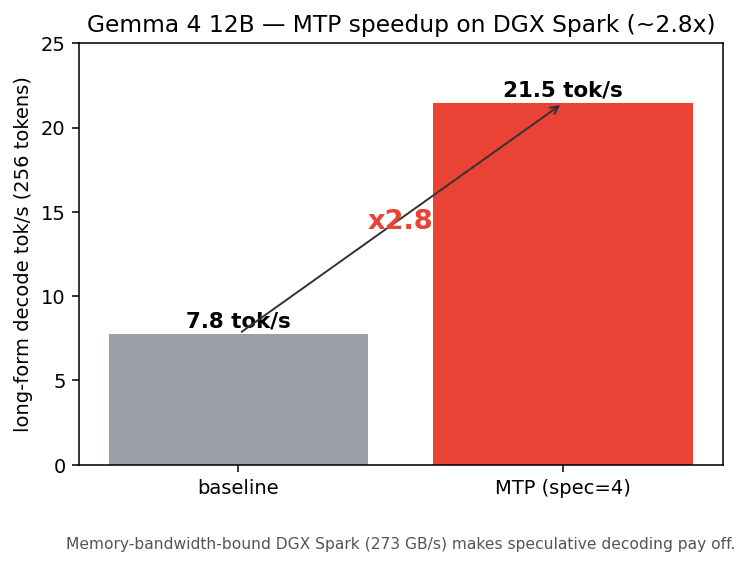
| Condition | Long-form generation speed |
|---|---|
| baseline | 7.7 tok/s |
| MTP (spec=4) | 21.5 tok/s |
For 256-token long-form generation, speed improved from 7.7 tok/s to 21.5 tok/s, approximately 2.8x faster. The output itself is identical to baseline, so quality is maintained while gaining speed.
One caveat: this baseline was measured with the flashinfer sampler disabled to avoid the ninja issue mentioned earlier, so the absolute tok/s numbers are on the conservative side. The multiplier also depends on how the baseline is measured, so it can't be directly compared to the E4B figures from the second article (2.1x, baseline 18.5 tok/s) to claim superiority. Please treat this as simply confirming that "MTP works well on 12B for long-form generation."
The reason it's this effective comes down to DGX Spark's memory bandwidth of 273GB/s, which is considerably modest compared to datacenter GPUs. Generating one token at a time means reloading the model weights from memory every time, and this bandwidth becomes the bottleneck. MTP has the drafter pre-generate multiple tokens that the main model then verifies in batch, reducing how often weights need to be reloaded and cleverly working around the bandwidth constraint. The impression is that the effect is larger in environments like DGX Spark where bandwidth is tight.
The Mid-Range That Runs on 16GB
Based on the results so far, let me consider how to use the 12B.
On the playing field of Japanese common sense text, the 12B nearly matched E4B. So there will be many situations where "E4B is sufficient for Japanese text processing alone." On the other hand, the 12B has a weapon that E4B and 26B lack—audio input—available at the mid-range level. If you want to handle cross-modal tasks spanning text, images, and audio with a single model, 12B becomes a realistic choice.
The accessibility of running on 16GB is also not to be overlooked. While the 31B offers high accuracy, our testing showed a median time of 4.8 seconds per question, making it a heavy model for generation too. From the perspective of casually running multimodal tasks on a personal machine, the 12B feels like just the right balance.
| Use case | Recommendation |
|---|---|
| Japanese text, light and fast | E4B |
| Want to handle audio with one model | 12B |
| Accuracy is the top priority | 31B / 26B-A4B |
Summary
In Japanese common sense testing, the 12B nearly matched E4B, and looking at text alone, the mid-range advantage was modest. That said, the real gain was being able to verify the audio input on actual hardware—the first for a mid-range model. Japanese transcription came in at a median CER of 16%, putting it in a practical range, and the integration of handling text, images, and audio with a single model felt like the defining characteristic of the 12B. With MTP applied, generation speeds up by about 2.8x, and combined with the accessibility of running on 16GB, I think it's a well-balanced option as an everyday multimodal model.
Reference Links
- Google Blog: Introducing Gemma 4 12B
- Google Developers Blog: Gemma 4 12B — The Developer Guide
- HuggingFace: google/gemma-4-12B-it
- HuggingFace: google/gemma-4-12B-it-assistant (MTP drafter)
- vLLM Recipes: Gemma 4 12B-it
- JCommonsenseQA v1.1
- JMMMU (Japanese version of MMMU)
- FLEURS
- Previous article: Benchmarking Gemma 4 on DGX Spark for Japanese and Multimodal
- Previous article: Measuring the speedup of Japanese generation with Gemma 4 MTP on DGX Spark
