
Gemma 4 MTP を DGX Spark で動かして日本語生成の高速化を実測してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
先日の Gemma 4 ベンチマーク記事 の続編です。Google が 2026-05-05 に発表した Gemma 4 MTP(Multi-Token Prediction)を DGX Spark で動かしてみました。
ざっくり言うと MTP は、本体モデルとは別に「次のトークンを先回りして予測する軽量な下書き役」を用意して、本体モデルがまとめて検証することで生成を速くする仕組みです。この種の技術は speculative decoding(投機的デコーディング)と呼ばれていて、Gemma 4 では本体(target)と下書き役(drafter)のペアモデルが Google から公式に配布されているのがポイントです。
Google の公式ブログでは「最大 3 倍の高速化」と謳っていますが、個人的に気になったのは「DGX Spark でも動くのか」「日本語タスクでも効果が出るのか」「メモリ帯域の差が結果にどう響くのか」という 3 点でした。
実は MTP リリース直後の 5/6 時点では、vLLM nightly が Gemma 4 の multimodal モデルへの speculative decoding に未対応で、起動すらできませんでした。一度は保留にしたのですが、翌日にマージされた PR #41745 で Gemma 4 MTP が正式サポートされ、5/7 朝に最新 nightly を pull したら一気に動くようになりました。
この記事では、vLLM nightly で全 4 モデル(E2B / E4B / 26B-A4B / 31B)の MTP 動作確認、JCQ(短文)と長文生成の両方でレイテンシ計測、そして「日本語タスクで受け入れ率が下がるのでは」という仮説の実機検証までを一気通貫で紹介します。結論を先に書くと、長文生成では最大 2.1 倍まで速くなり、品質劣化はゼロでした。一方で短文では効かず、26B MoE では逆に遅くなる場面もありました。
Gemma 4 MTP の仕組み
speculative decoding 自体は新しい技術ではなく、vLLM では DeepSeek が同じ系統の実装を先にリリースしていました。Gemma 4 MTP の特徴は、本体モデル(target)とペアになる下書き役(drafter)を Google が *-it-assistant という名前で別ファイルとして公式配布しているところです。
2 つほど補足しておきます。
1 つ目は drafter のサイズです。drafter は target とトークナイザー(文章をトークンに切り分けるルール)を揃え、本体側の埋め込み層もそのまま借りる構造になっています。drafter が独自に持つのはわずか 4 層と、出力候補を絞り込んで軽くした予測層だけ。E2B 用の drafter gemma-4-E2B-it-assistant は 182 MB で、target 9.6 GB に対して 2 % 弱の追加コストで済みます。
2 つ目は画像対応モデルへの工夫です。Gemma 4 は全モデルが画像入力対応(multimodal)で、本来 vLLM の speculative decoding は multimodal モデルを弾く仕様でした。PR #41745 では、drafter 側だけ画像/音声入力を切り捨ててテキスト専用モデルとして扱い、target は multimodal のまま動かす形でこの制約を回避しています。これによって、画像入りのリクエストでも MTP が効くようになっているわけですね。実際にログには次のように出力されます。
WARNING [llm_base_proposer.py:1375] Draft model does not support multimodal inputs, falling back to text-only mode
INFO [llm_base_proposer.py:1487] Detected MTP model. Sharing target model embedding weights with the draft model.
INFO [gemma4_mtp.py:536] Gemma4 MTP: centroids masking enabled (num_centroids=2048, top_k=32, active_tokens=4096/262144)
3 行目の centroids masking は、drafter が次のトークンを予測するときの候補を、本来の 26 万トークンから約 4,000 トークンに絞り込む工夫です。ほぼ確実に出てこないトークンを計算対象から外してしまうことで、drafter の動きを軽くしています。Gemma 4 MTP は、こういう細かいところまでしっかり最適化が入っていますね。地味に効いてくる工夫だなと感じます。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | DGX Spark(GB10、SM121、aarch64) |
| メモリ | 128 GB LPDDR5X 統合メモリ(帯域 273 GB/s) |
| vLLM | 0.20.2rc1.dev99+g9c0812ffd(nightly、cu130 wheel) |
| PyTorch | 2.11.0+cu130 |
| transformers | 5.8.0 |
| accelerate | 1.13.0 |
vLLM nightly はこんな手順でインストールしています。uv の --torch-backend=cu130 指定がないと依存解決で詰まる点だけ注意です。
uv pip install --pre --upgrade vllm \
--extra-index-url https://wheels.vllm.ai/nightly \
--torch-backend=cu130
検証対象は Gemma 4 全 4 モデルと、それぞれの drafter です。
| target | 量子化 | drafter | drafter サイズ |
|---|---|---|---|
google/gemma-4-E2B-it |
BF16 | google/gemma-4-E2B-it-assistant |
182 MB |
google/gemma-4-E4B-it |
BF16 | google/gemma-4-E4B-it-assistant |
182 MB |
nvidia/Gemma-4-26B-A4B-NVFP4 |
NVFP4 | google/gemma-4-26B-A4B-it-assistant |
832 MB |
nvidia/Gemma-4-31B-IT-NVFP4 |
NVFP4 | google/gemma-4-31B-it-assistant |
927 MB |
今回 26B-A4B と 31B は NVFP4 量子化版を使っています。drafter は target と同じ tokenizer を使うため、どのモデルでも 200 MB から 1 GB 弱の追加で済みます。
vLLM での MTP セットアップ
実際の起動コマンドは次のとおりです。E2B + drafter で MTP を有効化する例です。
vllm serve google/gemma-4-E2B-it \
--host 0.0.0.0 --port 8001 \
--served-model-name gemma4-e2b \
--max-model-len 8192 --max-num-seqs 4 \
--gpu-memory-utilization 0.5 \
--enforce-eager \
--max-num-batched-tokens 4096 \
--speculative-config '{"method":"mtp","num_speculative_tokens":2,"model":"google/gemma-4-E2B-it-assistant"}'
drafter は gemma4_assistant という model_type で配布されていて、vLLM 内部で gemma4_mtp に自動 rewrite される仕組みです。指定する model はあくまで drafter のリポジトリで、target は通常の gemma-4-E2B-it を渡します。
結果 1: モデル別の長文での高速化倍率
ベンチマークは「200 字程度の解説文を生成」というプロンプトを 12 回繰り返し実行し、初回(モデルが温まるまで遅くなりやすいので除外)を除いた 2 回目から 12 回目までの平均で評価しています。条件は temperature=0(出力のばらつきをなくす設定)、max_tokens=256(生成する最大トークン数)、シングルクライアント(同時リクエストなし)です。
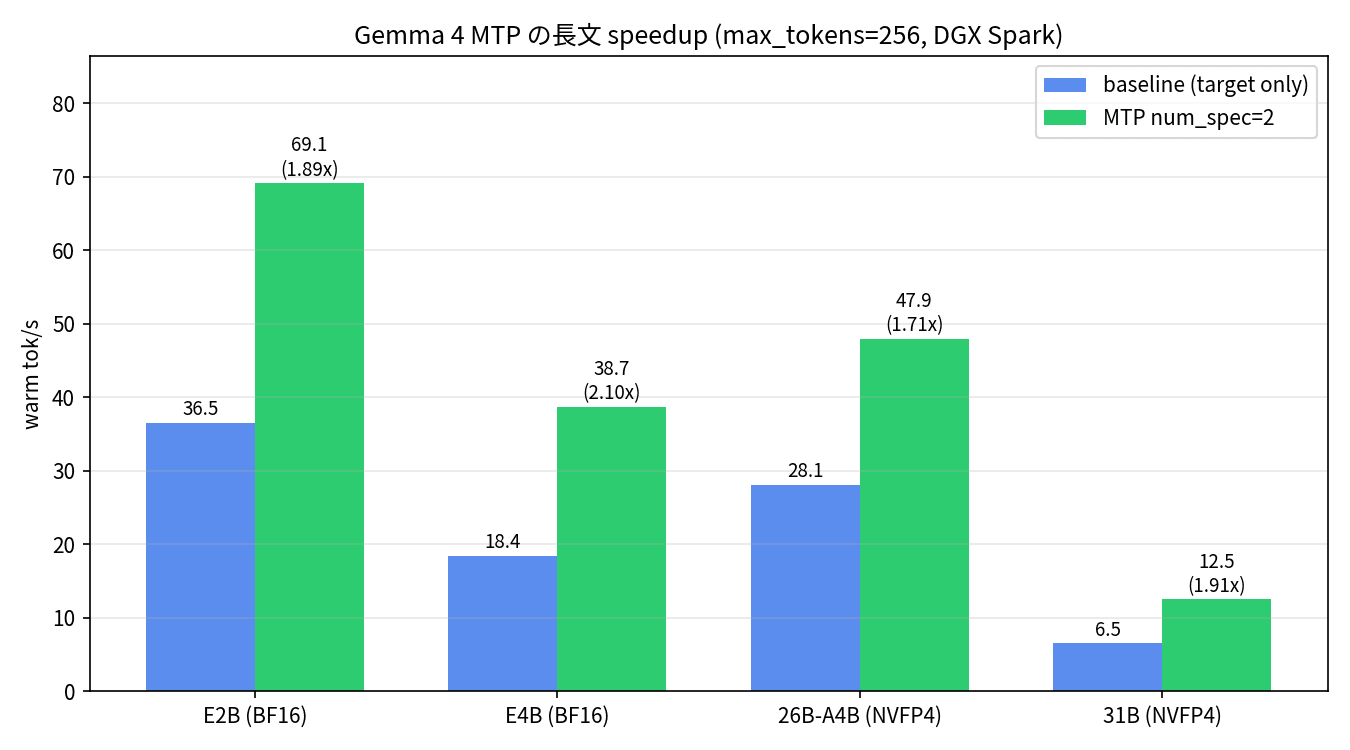
| モデル | baseline tok/s | MTP tok/s | 高速化倍率 | 受け入れ率 |
|---|---|---|---|---|
| E2B (BF16) | 36.5 | 69.1 | 1.89x | 38.8% |
| E4B (BF16) | 18.5 | 38.7 | 2.10x | 44.6% |
| 26B-A4B (NVFP4) | 28.1 | 47.9 | 1.71x | 54.9% |
| 31B (NVFP4) | 6.5 | 12.5 | 1.91x | 54.8% |
全モデルで 1.7〜2.1 倍の高速化倍率(speedup、ベースラインに対する高速化の比)が確認できました。E4B が最も伸びている(2.10x)のは、target と drafter のサイズバランスがちょうど効きやすい帯域だったのかなと思っています。31B も 1.91x 出ていて、絶対値こそ 12.5 tok/s と地味ですが、NVFP4 marlin の重い compute path でもしっかり効いている印象です。
受け入れ率(acceptance rate、drafter が予測したトークンのうち target がそのまま採用した割合)はモデルサイズに比例して 38% から 55% まで上がっています。target が大きく強いほど drafter の予測も当たりやすい、という直感どおりの関係に落ちているのが個人的には面白いところですね。
結果 2: 短文(JCQ)では MTP が効かない
実は同じ条件で、日本語常識推論ベンチマーク JCommonsenseQA(200 問、3-shot 形式で例示を渡す、max_tokens=8)でも測定しています。こちらは選択肢のラベル 1 文字(A〜E)だけ返せばよい、極端に短い応答のタスクです。
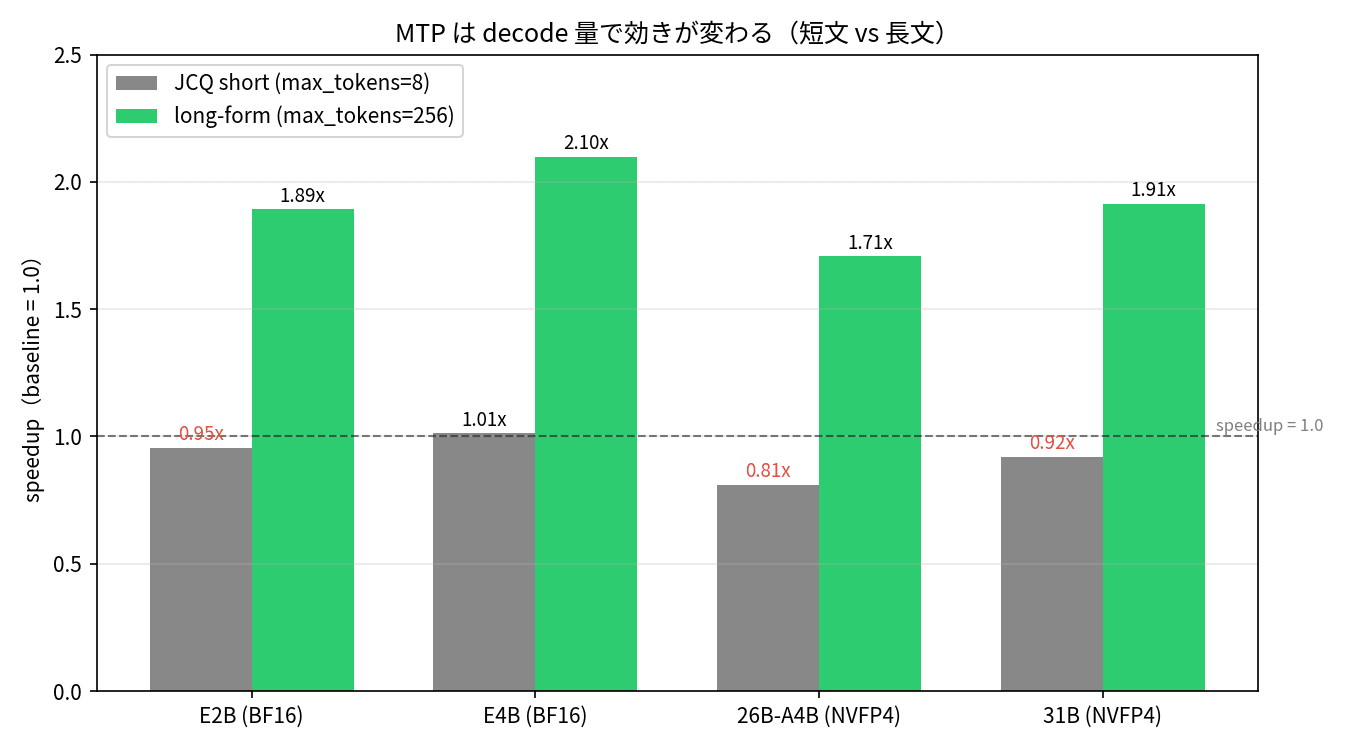
| モデル | 短文での高速化倍率 | 長文での高速化倍率 |
|---|---|---|
| E2B | 0.96x | 1.89x |
| E4B | 1.01x | 2.10x |
| 26B-A4B (MoE) | 0.81x(減速) | 1.71x(逆転) |
| 31B | 0.92x | 1.91x |
短文では全モデルでほぼ等速、26B-A4B にいたっては 19% ほど遅くなっています。drafter を毎回動かすコストが、生成トークンが少ないと回収しきれないためですね。MTP の公式ドキュメントにも「MoE(Mixture of Experts、専門家モデルを動的に切り替える方式)は batch_size=1 で高速化が効きにくい」という注意書きがあり、まさにそれが目の前で再現された格好です。
裏返すと、MTP は生成するトークン数が多いタスクでこそ効く最適化だということがはっきりわかります。チャット応答やコード生成、要約のような数百〜数千トークンを生成する用途では大きな効果が出ますが、選択肢を 1 つ返すような分類タスクで MTP を有効化するのはむしろ逆効果です。本番運用では「タスクの長さを見て MTP を on/off する」設計がいりそうですね。
26B-A4B が短文で 0.81x → 長文で 1.71x にひっくり返るのが、視覚的にも一番わかりやすい結果ですね。
結果 3: 品質劣化はゼロ
高速化と引き換えに精度が落ちては元も子もないので、JCQ 200 問の正答率で品質を確認しています。
| モデル | baseline accuracy | MTP accuracy | 差分 |
|---|---|---|---|
| E2B (BF16) | 87.5% | 88.0% | +0.5pt |
| E4B (BF16) | 93.0% | 93.0% | 0.0pt |
| 26B-A4B (NVFP4) | 97.5% | 97.0% | -0.5pt |
| 31B (NVFP4) | 98.0% | 98.0% | 0.0pt |
差分は ±0.5pt 以内で、200 問換算ではどれも 1 問差という範囲です。MTP は理論的には品質を保証する仕組みで、drafter が間違ったトークンを予測しても target 側がそれを拒否するため、最終的に出てくる文章は MTP を使わないときと同じになります。
結果 4: 日本語と英語、受け入れ率はほぼ同じ
「日本語特有のトークン分割(Gemma 4 で使われている SentencePiece という方式は、漢字 1 文字を単独のトークンにしたり 2 文字結合したりとパターンが多い)が drafter の予測を難しくして、受け入れ率が下がっているのでは?」という仮説を、英語プロンプトの同条件 12 回で検証しました。
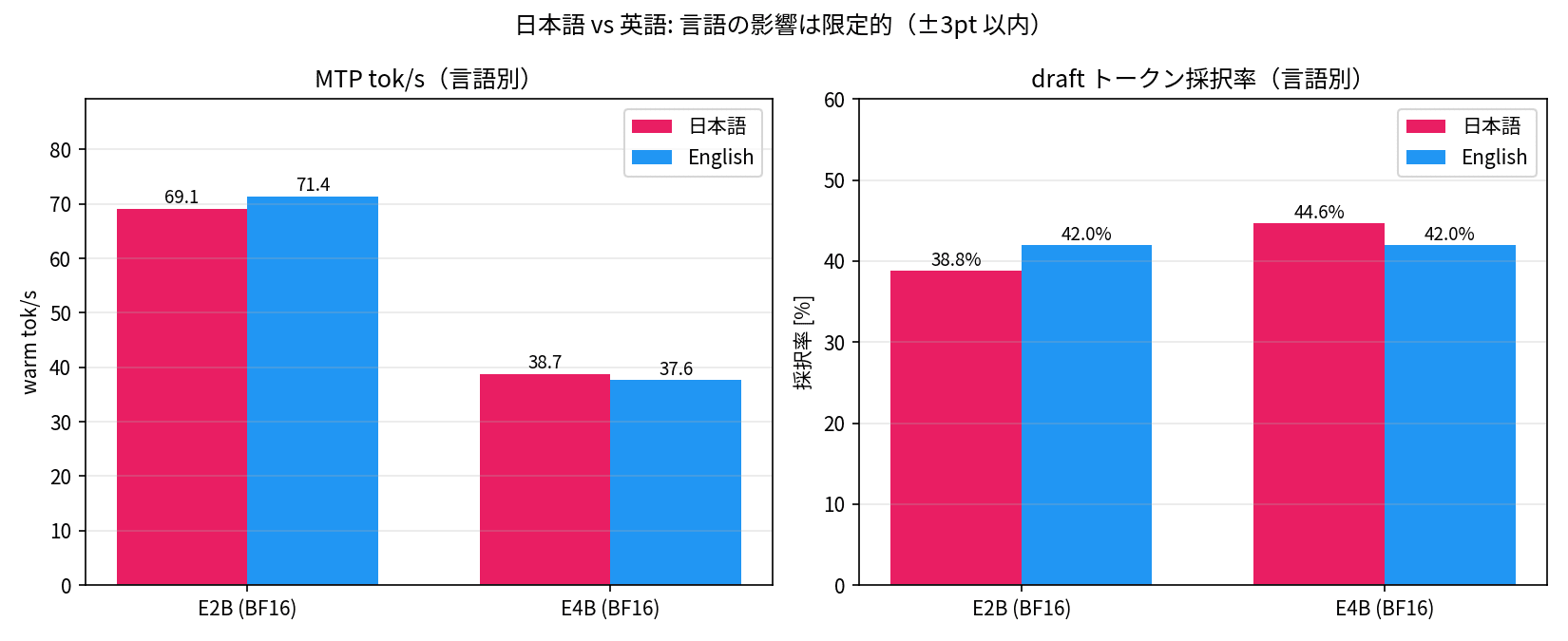
| モデル | 言語 | tok/s | 受け入れ率 | 出力 tok/round |
|---|---|---|---|---|
| E2B | 日本語 | 69.1 | 38.8% | 116.6 |
| E2B | 英語 | 71.4 | 42.0% | 165.2 |
| E4B | 日本語 | 38.7 | 44.6% | 117.5 |
| E4B | 英語 | 37.6 | 42.0% | 164.8 |
E2B では英語の方が +3.2pt 受け入れ率が高い一方、E4B では逆に -2.6pt 低くなりました。一貫した方向性がなく、言語による有意な差は見つからなかったというのが率直な結果です。tok/s もほぼ同等で、日本語タスクで MTP が苦戦しているわけではないようです。
面白いのは出力トークン数の方で、英語は同じ「200 字 / 150 words」という指定でも約 41% 多くなっています。日本語と英語ではトークンの作られ方が違って、ざっくり「英語 1 単語 ≒ 1〜2 トークン、日本語 1 文字 ≒ 1〜2 トークン」になるのが一般的です。同じ字数でもトークン数は変わるので、生成テキストの分量を比べる場合は文字数や単語数ではなくトークン数で揃えた方が公平になります。
そうなると、高速化倍率の上限を決めているのは別の要素だと考えるのが自然になります。
結果 5: メモリ帯域が真のボトルネック
speculative decoding が速くなる理屈は、「target が 1 回の処理で複数トークン分をまとめて検証することで、メモリ帯域を効率よく使う」点にあります。LLM 推論の 1 トークン生成は、毎回モデルの重み(数十 GB)をメモリから読み出してくる作業がボトルネックです。1 トークン処理しても N トークン処理しても、この読み出しコストはほぼ同じ。なので 1 回の処理で返せるトークン数が増えるほど、見かけの生成速度が上がる仕組みになります。
ところが DGX Spark のメモリ帯域は構造的に低く、それが高速化倍率の上限を決めています。
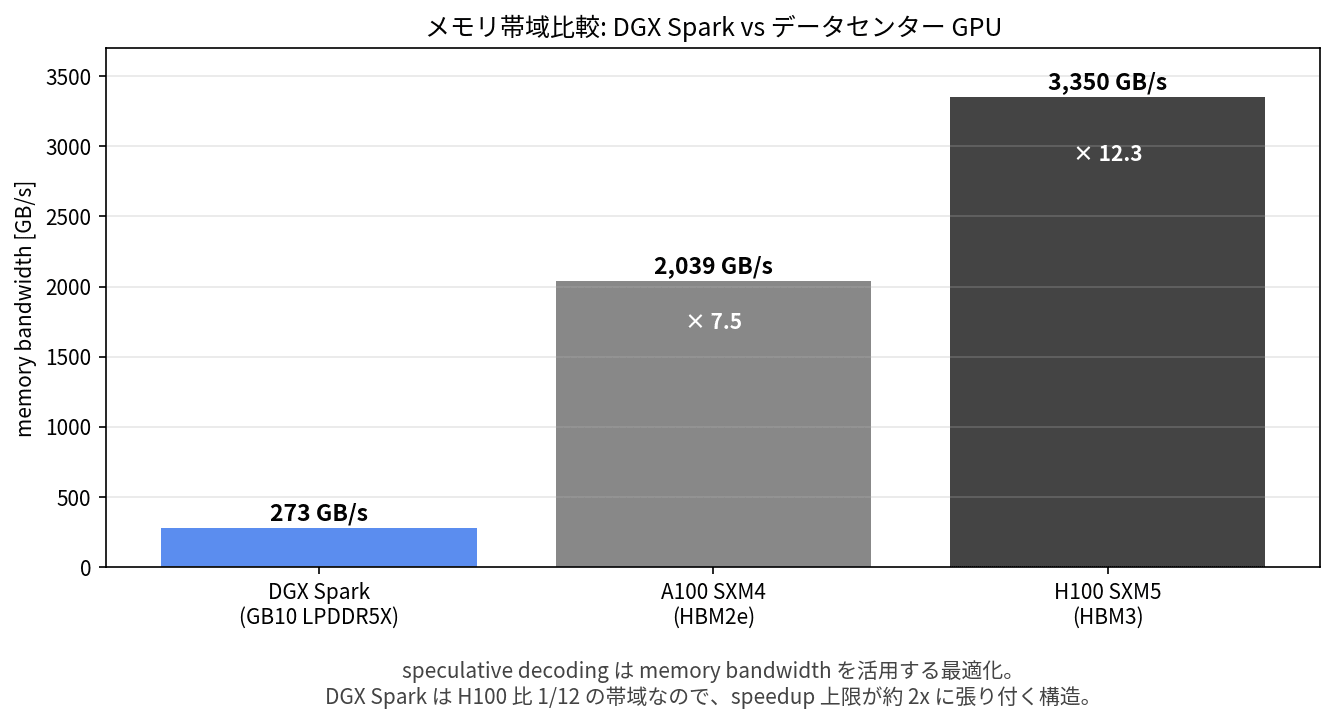
| ハードウェア | メモリ帯域 | DGX Spark 比 |
|---|---|---|
| DGX Spark GB10 (LPDDR5X) | 273 GB/s | 1.0x |
| A100 SXM4 (HBM2e) | 2,039 GB/s | 7.5x |
| H100 SXM5 (HBM3) | 3,350 GB/s | 12.3x |
H100 比で 1/12 の帯域しかないので、高速化倍率の上限が約 2 倍に張り付くのは構造的に妥当です。Google blog の「最大 3 倍」は H100 で動かしたときの値と考えるのが自然で、DGX Spark で 1.7〜2.1 倍出ているのはむしろ健闘していると言えるかもしれません。
つまり DGX Spark での MTP の高速化倍率は、おおまかに以下の関係で決まる構図になります。
最終 高速化倍率 ≈ min(
1 + 受け入れ率 × 先読みトークン数, # MTP の理論上限
メモリ帯域の比率, # 帯域からくる頭打ち
計算側の効率 # NVFP4 marlin など
)
受け入れ率 40〜55% × 先読みトークン数 2 だと理論上は 1.8〜2.1 倍が上限ですが、E2B / E4B の BF16 ではほぼその上限で動いていて、26B-A4B / 31B の NVFP4 では計算側のロスが少し効いています。実測データがきれいにこの式に乗ってくるあたり、speculative decoding の挙動が DGX Spark でも素直に再現できているのかなと思っています。
ここまでの結果
| モデル | 量子化 | vLLM 起動 | 長文での高速化倍率 | 受け入れ率 | 品質劣化 |
|---|---|---|---|---|---|
| E2B | BF16 | ✓ 動作 | 1.89x (69.1 tok/s) | 38.8% | なし (±0.5pt) |
| E4B | BF16 | ✓ 動作 | 2.10x (38.7 tok/s) | 44.6% | なし (±0.5pt) |
| 26B-A4B | NVFP4 | ✓ 動作 | 1.71x (47.9 tok/s) | 54.9% | なし (±0.5pt) |
| 31B | NVFP4 | ✓ 動作 | 1.91x (12.5 tok/s) | 54.8% | なし (±0.5pt) |
全モデルが起動し、長文タスクでは全モデルでしっかり高速化が効きます。短文や生成トークンが少ないタスクでは効果が出ない、または MoE モデルでは逆に遅くなることがあるので、実運用ではタスクの種類に応じて MTP の on/off を切り替えるか、別エンドポイントとして用意するのが現実的だと思います。
まとめ
DGX Spark で Gemma 4 MTP を試して、PR #41745 マージ翌日の鮮度で全 4 モデルの動作確認と性能評価ができました。要点をまとめると、以下のとおりです。
- 長文生成では 1.7〜2.1 倍まで高速化(max_tokens=256、ウォームアップ後)。E4B が最大の 2.10 倍
- 短文(JCQ、max_tokens=8)では効かず、26B MoE では 19% ほど遅くなる。MTP は生成トークン数で効きが変わる
- 品質劣化はゼロ(JCQ 200 問の正解率で ±0.5pt 以内)。MTP は理論的に品質が保証される仕組みなので当然ではあるものの、数字で確認できると安心材料
- 日本語と英語の受け入れ率差は ±3pt 程度で限定的。日本語だから MTP が不利、という構図ではない
- DGX Spark のメモリ帯域 273 GB/s(H100 比 1/12)が高速化倍率の上限を決めている。Google blog の「最大 3 倍」は H100 で動かしたときの値で、DGX Spark で 2 倍級は構造的な天井
DGX Spark で Gemma 4 を使っている方には、長文タスク用に MTP を有効化するのをおすすめしたいところです。E4B BF16 が 18 → 39 tok/s に上がるだけでも体感は大きく変わります。短文タスクとは切り分けて運用するのが、現時点での落としどころかなと思います。
NVFP4 系の絶対値は Marlin 経由のぶん控えめですが、それでも 26B-A4B が long で 47.9 tok/s、31B が 12.5 tok/s 出るので、DGX Spark のメモリ余裕(128 GB UMA)と組み合わせれば、ローカルで安心して長文生成タスクに使える実用レベルに届いている印象です。Google が PR を 1 日でマージし、その翌日に DGX Spark で動かせるところまで来ているのは、エコシステムの動きの速さを感じる結果でした。










