
Gemma 4 に 12B が追加されたので DGX Spark で日本語性能・音声入力・MTP まで試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
Gemma 4 に新しいサイズ「12B」が追加されました。これまで Gemma 4 は E2B / E4B という小型と、26B-A4B(MoE)/ 31B(Dense)という大型の組み合わせで、ちょうど真ん中が空いていました。今回の 12B はその間を埋める中量級で、Google も「E4B と 26B MoE の橋渡し」と位置づけています。
自分はこれまで Gemma 4 を 2 回ほど DGX Spark で触ってきました。1 本目は全サイズを日本語とマルチモーダルでベンチマークした記事、2 本目はMTP(Multi-Token Prediction)で生成を高速化した記事です。せっかく物差しが手元にあるので、新顔の 12B を同じ土俵に乗せて「どのあたりに座るのか」を確かめてみました。
12B には注目したい新しさが 3 つあります。256K トークンのコンテキスト、中量級では初の音声入力(native audio)、そして MTP 用の drafter が最初から付いてくること。さらに公式によると 16GB のメモリでも動くとのことで、手軽さも魅力です。今回はテキストの日本語性能から、新機能の音声入力、MTP の高速化まで、ひととおり DGX Spark の実機で測ってみました。
先に結論をお伝えしておくと、12B の日本語常識テストのスコアは E4B とほぼ並びました。テキストだけ見ると中量級のうまみは出にくいのですが、そのぶん音声まで 1 つのモデルで扱える点と、16GB で動く手軽さが 12B の見どころかなと思っています。
Gemma 4 12B はどんなモデルなのか
まず Gemma 4 ファミリーの中での 12B の位置を整理しておきます。
| サイズ | 種別 | 特徴 |
|---|---|---|
| E2B(2.3B) | Dense | 最小、エッジ向け |
| E4B(4.5B) | Dense | 小型、ローカル実用 |
| 12B | Dense | 新顔・中量級・音声入力対応 |
| 26B-A4B | MoE(Active 3.8B) | 中〜大型、効率重視 |
| 31B | Dense | 最大、最高精度 |
12B で個人的に面白いと思ったのが、アーキテクチャが encoder-free になっている点です。これまでのマルチモーダルモデルは、画像や音声を専用のエンコーダーで一度ベクトルに変換してから言語モデルに渡す構成が一般的でした。Gemma 4 12B は画像も音声も、軽量な埋め込み層を通して LLM 本体に直接流し込みます。画像側は 35M パラメータの埋め込み層が、これまでの画像エンコーダー 27 層分を置き換えていて、48×48 ピクセルのパッチを 1 回の行列積で投影します。音声側は、16kHz の波形を 40ms ごとのフレーム(640 個の数値)に切って線形変換するだけ、という思い切った設計です。画像も音声もテキストも同じ重みを共有するので、ファインチューニングもまとめて 1 つで済みます。
公式が出している主なベンチマークはこちらです。
| ベンチマーク | スコア |
|---|---|
| MMLU Pro | 77.2 |
| AIME 2026(ツールなし) | 77.5 |
| LiveCodeBench v6 | 72.0 |
| GPQA Diamond | 78.8 |
| MMMU Pro(画像) | 69.1 |
| CoVoST(音声) | 38.5 |
| MRCR v2(ロングコンテキスト) | 43.4 |
検証環境とつまずきどころ
12B を動かそうとして、いきなりつまずきました。検証を始めた時点では、手元の安定版(transformers と vLLM の正式リリース版)はこんなエラーで止まりました。
model type `gemma4_unified` but Transformers does not recognize this architecture
12B の encoder-free アーキは社内コード名で gemma4_unified という新しい型になっていて、当時の安定版はまだ知らなかったのです。そのため検証時は、Google の案内どおり transformers を GitHub の main から、vLLM を nightly から入れて進めました。
検証はテキストと画像、音声の精度を transformers 直叩きで、MTP の速度を vLLM で、という二刀流にしました。新しく venv を作って transformers を入れたところ、AutoModelForMultimodalLM で 12B が bfloat16 で読み込めました。以下のつまずきは検証当時のものですが、原因と回避策は今でも参考になるはずなので残しておきます。
12B を transformers で動かすまでにハマった 3 点
- torchvision が要る: 12B の画像処理が
torchvision.transforms.v2に依存しているので、入れていないとModuleNotFoundError: No module named 'torchvision'で止まります。 - 音声データセットのデコード: 評価用に FLEURS を
datasetsで読むとTo support decoding audio data, please install 'torchcodec'と言われます。torchcodec は ffmpeg まわりの依存が増えるので、自分はAudio(decode=False)で生バイトを取り出して soundfile で読む形にして回避しました。 - vLLM の flashinfer sampler が JIT ビルドする: vLLM nightly で 12B をサービングしようとしたら
FileNotFoundError: 'ninja'で起動に失敗しました。flashinfer がサンプリング用カーネルをその場でコンパイルしようとして、ビルドツールが PATH 上に見つからないのが原因です。VLLM_USE_FLASHINFER_SAMPLER=0で JIT 自体を回避し、念のため venv と CUDA を PATH に通したら立ち上がりました。これは nightly を使う以上は当面ついて回りそうなので、MTP を vLLM で試す方は頭の隅に置いておくとよいかもしれません。
テキストは E4B とほぼ並ぶ — 日本語常識テスト
最初はテキストです。1 本目の記事と同じ JCommonsenseQA(日本語常識推論、leemeng/jcommonsenseqa-v1.1)で、同じ 3-shot・同じシード・1,116 問という条件をそろえました。前回の数値はバックエンドが違ったので、比較サイズ(E2B / E4B / 31B)も今回まとめて transformers で測り直し、12B と同じ土俵に乗せています。
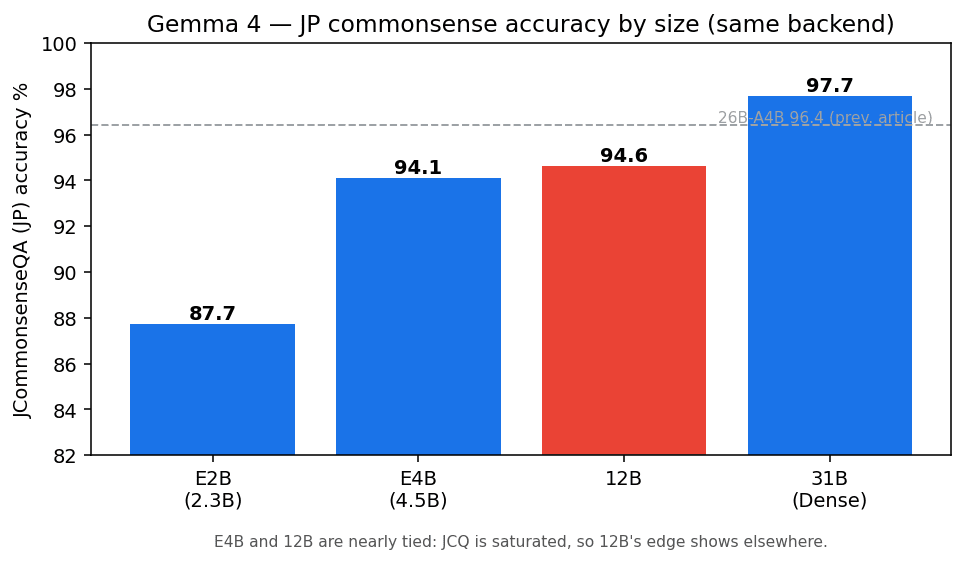
| サイズ | JCQ 正解率 | 1 問あたり中央値 |
|---|---|---|
| E2B | 87.7% | 0.08 秒 |
| E4B | 94.1% | 0.15 秒 |
| 12B | 94.6% | 0.32 秒 |
| 31B | 97.7% | 4.84 秒 |
12B は 94.6% で、E4B の 94.1% とほとんど差がありませんでした。31B の 97.7% には 3 ポイントほど届きません。1 本目の記事で測った 26B-A4B が 96.4% だったので、ざっくり E4B ≈ 12B < 26B < 31B という並びです。
「E4B と 26B の橋渡し」と聞くと、ちょうど中間あたりのスコアを期待してしまいますが、これは 12B が弱いというより、JCommonsenseQA が E4B の時点ですでに 94% まで来ていて、天井に近いからだと考えています。日本語の常識推論という土俵では、中量級にしたうまみが点数に表れにくいわけです。
つまり 12B の価値は、テキストの常識テストではなく別のところにあります。次の画像と音声を見ていきましょう。
画像は大学レベルで真価が問われる — JMMMU
画像は JMMMU を使いました。MMMU の日本語版で、大学レベルの図表問題を 28 分野から集めたものです。公式が出している MMMU Pro(画像)69.1 は英語なので、こちらは日本語で 300 問を解かせてみました。
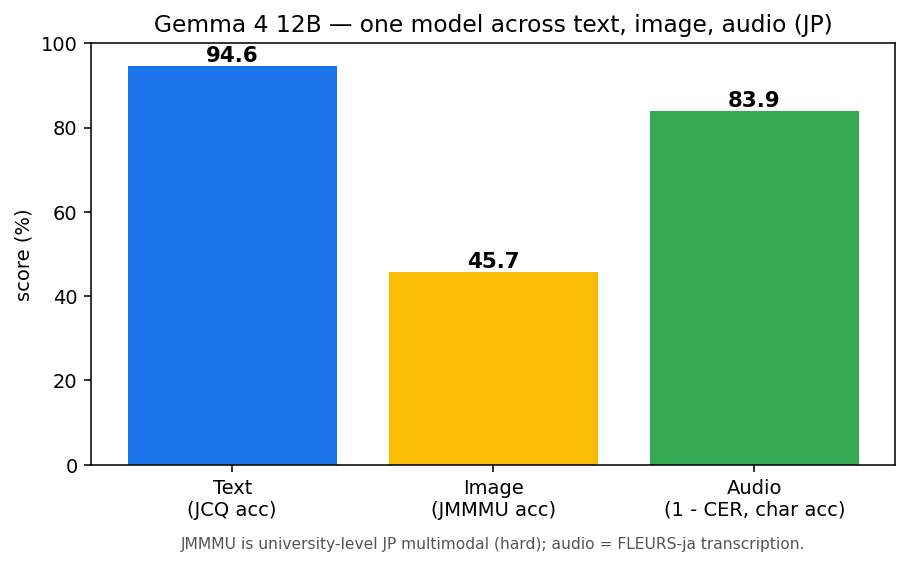
12B の正解率は 45.7% でした。数字だけ見ると物足りなく感じるかもしれませんが、JMMMU は人間でも分野によっては苦戦するくらい難しいベンチマークです。分野ごとに見ると傾向がはっきり出ました。
| 得意な分野 | 正解率 | 苦手な分野 | 正解率 |
|---|---|---|---|
| コンピューターサイエンス | 0.75 | 機械工学 | 0.00 |
| 心理学 | 0.75 | 建築・工学 | 0.00 |
| 世界史 | 0.71 | エネルギー | 0.00 |
| 農業 | 0.70 | 数学 | 0.20 |
文章主体の分野は手堅く解ける一方、図面や回路、力学のように図そのものを精密に読む工学系はほぼ歯が立ちませんでした。このあたりは中量級モデルの限界が素直に出る部分かなと思います。製造業の図面解析のような用途では、まだ過度な期待は禁物ですね。
新機能の目玉、音声入力を日本語で試す
ここが今回いちばん試したかったところです。12B は中量級として初めて音声入力に対応しました。
仕組みはさきほど触れたとおりで、専用の音声エンコーダーを置かず、16kHz の波形を 40ms フレームに切って LLM に直接渡します。transformers ではメッセージに音声の配列を渡すだけで、画像と同じ感覚で書けました。
content = [
{"type": "audio", "audio": arr}, # 16kHz の numpy 配列
{"type": "text", "text": "この音声を日本語で正確に書き起こしてください。"},
]
FLEURS の日本語音声 100 件を書き起こして、文字誤り率(CER)で評価しました。結果は中央値で 16.1%、平均で 23.1% です。平均が中央値より高いのは、一部の難しい音声がスコアを引っ張っているためで、代表的な品質は中央値の 16% あたりと見るのが妥当です。
公式のモデルカードにも FLEURS の CER が載っていて、そちらは 6.9% です。ただしこれは中国語を除く多言語の平均値で、自分が測ったのは日本語だけという違いがあります。日本語は漢字や同音異義語があって CER 評価では難しめの言語なので、多言語平均より数字が大きくなるのは自然かなと思います。その差し引きで見ると、日本語単体で中央値 16% は悪くない出来です。
数字だけだと分かりにくいので、実際の書き起こしを 1 つ載せます。
正解: インターネットで 敵対的環境コース について検索すると おそらく現地企業の住所が出てくるでしょう
12B : インターネットで 適体的な環境公社 について検索すると、おそらく現地企業の住所が出てくるでしょう
「敵対的環境コース」が「適体的な環境公社」になっている以外は、ほぼ正確に書き起こせています。同音異義語で取り違えるあたりは、音響モデルというより言語モデルらしい間違い方で、見ていて面白いですね。
なお公式によると、12B の音声は単なる書き起こしだけでなく、話者分離(誰が話したかの区別)や動画の理解にも対応するとしています。今回は日本語の書き起こしに絞って試しましたが、用途の幅は思ったより広そうです。
FLEURS のようなクリーンな読み上げ音声であれば、専用の音声認識モデル(Whisper など)は日本語の CER が一桁台に収まります。精度だけで張り合うと 12B は一歩譲ります。ただ、ここで大事なのは、テキストも画像も音声も 1 つのモデルでまとめて扱えるという統合性です。文字起こしした内容をそのまま要約したり、画像と音声を一度に渡して質問したり、といった使い方が 1 モデルで完結します。
MTP で生成が約 2.8 倍速くなる
最後は速度です。12B には MTP 用の drafter(google/gemma-4-12B-it-assistant)が最初から付いてきます。2 本目の記事でやった speculative decoding を、そのまま 12B に当てられるわけです。
vLLM nightly で、drafter なしの baseline と、drafter ありの MTP(投機トークン数 4)を同じ条件で長文生成させて比べました。
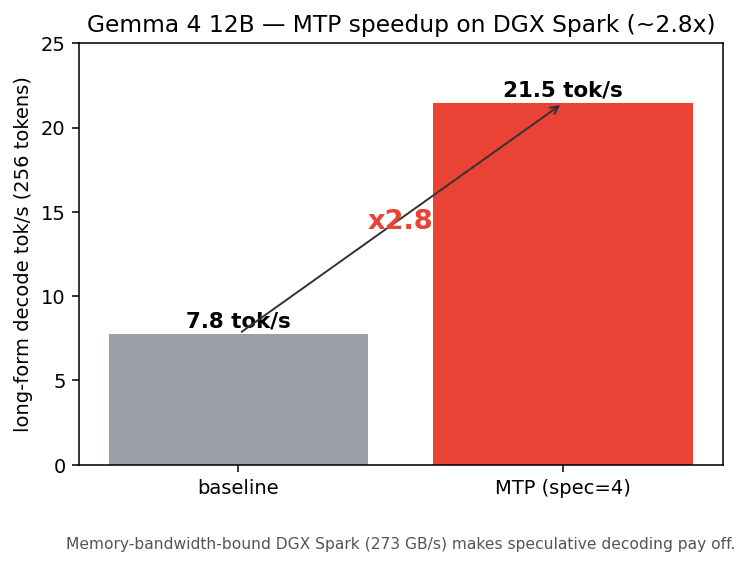
| 条件 | 長文の生成速度 |
|---|---|
| baseline | 7.7 tok/s |
| MTP(spec=4) | 21.5 tok/s |
256 トークンの長文生成で、7.7 tok/s から 21.5 tok/s へ、約 2.8 倍に伸びました。出力そのものは baseline と変わらないので、品質を落とさずに速くなっています。
ひとつ補足しておくと、今回の baseline は前述の ninja 問題を避けるために flashinfer のサンプラーを無効にして測っているため、絶対的な tok/s は控えめに出ています。倍率はこの baseline の測り方にも左右されるので、2 本目で測った E4B(2.1 倍、baseline 18.5 tok/s)と数字を並べて優劣を語れるものではありません。あくまで「12B でも長文生成では MTP がしっかり効く」という確認として見ていただければと思います。
なぜこれだけ効くかというと、DGX Spark のメモリ帯域が 273GB/s と、データセンター向け GPU に比べてかなり控えめだからです。1 トークンずつ生成すると毎回モデルの重みをメモリから読み直すことになり、この帯域がボトルネックになります。MTP は drafter が先に複数トークンを下書きして本体がまとめて検証するので、重みの読み直し回数が減り、帯域の制約をうまくかわせます。帯域が細い DGX Spark のような環境ほど効果が大きくなる、という印象です。
16GB で動く中量級という立ち位置
ここまでの結果を踏まえて、12B をどう使うかを考えてみます。
テキストの日本語常識という土俵では、12B は E4B とほぼ並びました。なので「日本語のテキスト処理だけなら、より軽い E4B でも足りる」場面は多そうです。一方で 12B は音声入力という、E4B や 26B にはない武器を中量級で持っています。テキスト・画像・音声をまたぐ用途を 1 モデルで回したいなら、12B が現実的な選択肢になります。
そして 16GB で動くという手軽さも見逃せません。31B は精度こそ高いものの、今回の検証でも 1 問あたり中央値で 4.8 秒かかり、生成も重いモデルでした。手元のマシンでマルチモーダルを気軽に回す、という日常使いの目線では、12B のサイズ感はちょうどよいバランスだなと感じています。
| こんなとき | おすすめ |
|---|---|
| 日本語テキストを軽く速く | E4B |
| 音声まで 1 モデルで扱いたい | 12B |
| とにかく精度を優先 | 31B / 26B-A4B |
まとめ
日本語の常識テストでは E4B とほぼ並び、テキストだけ見ると中量級のうまみは控えめでした。そのぶん、中量級では初の音声入力を実機で確かめられたのが収穫です。日本語の書き起こしが文字誤り率の中央値 16% で実用域に入っていて、テキスト・画像・音声を 1 モデルで扱える統合性が 12B らしさだと感じました。MTP を当てれば生成も約 2.8 倍に速くなり、16GB で動く手軽さと合わせて、日常使いのマルチモーダルモデルとしてバランスのよい選択肢だと思います。
参考リンク
- Google Blog: Introducing Gemma 4 12B
- Google Developers Blog: Gemma 4 12B — The Developer Guide
- HuggingFace: google/gemma-4-12B-it
- HuggingFace: google/gemma-4-12B-it-assistant(MTP drafter)
- vLLM Recipes: Gemma 4 12B-it
- JCommonsenseQA v1.1
- JMMMU(日本語版 MMMU)
- FLEURS
- 過去記事: Gemma 4 を DGX Spark で動かして日本語とマルチモーダルをベンチマークしてみた
- 過去記事: Gemma 4 MTP を DGX Spark で動かして日本語生成の高速化を実測してみた










