
I ran Nemotron-Labs-Diffusion on DGX Spark and actually measured tri-mode generation
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
In May 2026, NVIDIA released a new model family called "Nemotron-Labs-Diffusion." Since the name contains "diffusion," some of you might have thought this was about image generation, but this is actually a "diffusion language model" that generates text. Grasping this point first will make the rest of this article easier to read.
The LLMs we typically use write text one token at a time from left to right. Since the next token can't be determined until the previous one is decided, generation is inherently sequential. Diffusion language models change this. They generate multiple tokens in parallel in block units, and fill in uncertain parts in later steps.
What makes Nemotron-Labs-Diffusion interesting is that a single model can switch between three decoding modes (AR / Diffusion / Linear Self-Speculation). NVIDIA calls this tri-mode. Both autoregressive (AR) and diffusion coexist within the same checkpoint, not as separate models.
Reading through the released information, the three things I personally found most curious were:
- Do all three modes run smoothly in the local DGX Spark environment?
- What does the diffusion mode's "generate in parallel and fill in later" behavior actually look like when you run it?
- What happens to the numbers the official documentation cites—"2.7x vs AR" and "6× tokens per forward"—with a plain run without quantization?
So I loaded the 8B model of Nemotron-Labs-Diffusion onto a DGX Spark and measured all three modes. To give the conclusion upfront: all three modes ran on the DGX Spark. In terms of speed, Linear Self-Speculation was 1.75 to 1.98x faster compared to AR. However, the flashy numbers put forward officially come with conditions, and when generating longform content in BF16 without quantization, a different picture emerges. I'll cover those differences as well.
As a related note, I previously wrote an article about measuring speculative decoding on a DGX Spark using Gemma 4 MTP. Gemma 4 MTP uses a separate draft model, whereas this time's Linear Self-Speculation is self-contained within a single model — but they share the same skeleton of "quickly producing a draft that the main model then verifies." Reading them together should help you grasp the positioning of diffusion language models.
What is Nemotron-Labs-Diffusion's tri-mode?
Model family and background
Nemotron-Labs-Diffusion comes in three sizes for text generation — 3B / 8B / 14B — each with a pretrain-only Base version and an instruction-tuned Instruct version. A VLM-8B that can also handle images is also available. This time, I focused on the instruction-tuned 8B (nvidia/Nemotron-Labs-Diffusion-8B).
The architecture is a straightforward Transformer, not a Mamba hybrid. According to the technical report, training started from the existing Ministral3-8B as a base, proceeding first with 1T tokens of continued pretraining using autoregression only, then 300B tokens of continued pretraining with a combined autoregressive and diffusion objective, and finally 45B tokens of instruction tuning. The license is the NVIDIA Nemotron Open Model License.
What's subtly important here is that training with both autoregressive and diffusion together does not degrade AR accuracy. The technical report states that compared to a model trained under the same conditions but without diffusion loss, the AR accuracy after joint training actually improved by 0.14–0.43%. The pleasing aspect of this design is that adding diffusion capability does not sacrifice autoregressive performance.
Three decoding modes
Let me organize the contents of tri-mode. For the same weights, three different generation methods are available by switching how attention is applied at inference time.
AR mode is conventional autoregressive decoding. One token is confirmed from left to right per forward pass. It calls ar_generate().
Diffusion mode divides the generation span into blocks of block_length tokens, masks everything in the block at first, and then gradually fills in positions with higher confidence. It calls generate() and accepts the diffusion-specific parameters block_length and threshold. threshold determines how many tokens to confirm at each step — higher means more cautious, lower means filling in more aggressively at once.
Linear Self-Speculation mode is self-speculative decoding combining diffusion and autoregression. The diffusion mode generates candidate tokens in parallel as a draft, which autoregression then verifies and confirms up to the correct point. The idea is the same as speculative decoding, but there's no need to separately prepare a small dedicated draft model — the same model's diffusion mode serves as the drafter. It calls linear_spec_generate().
In terms of not needing a separate weight file for the draft role, this is in a similar vein to DeepSeek's MTP, which embeds a dedicated drafting module directly into the main model. However, unlike DeepSeek which adds a dedicated module, Nemotron-Labs-Diffusion doesn't add even that — it directly reuses the diffusion mode it already has as the draft. Gemma 4 MTP mentioned earlier distributes a separate draft model, so aligning all three, you get "separate model," "built-in module," and "mode reuse," each with a slightly different source for the draft.
The three methods return both the generation result and nfe (number of forward evaluations — how many times the forward pass was run). If the same length of text can be produced with fewer forward passes, that means it's faster. In this article, I'll frequently use nfe and the derived metric tokens per forward (how many tokens are confirmed per forward pass) as speed indicators.
Verification environment
I used one DGX Spark for verification. The hardware and software configuration is as follows:
| Item | Details |
|---|---|
| Machine | NVIDIA DGX Spark (GB10, Blackwell SM121) |
| Memory | 128GB unified memory (UMA), bandwidth 273 GB/s |
| Architecture | aarch64 (ARM64) |
| Python | 3.13.13 (built with uv) |
| PyTorch | 2.12.0+cu130 |
| transformers | 5.9.0 |
| Model | nvidia/Nemotron-Labs-Diffusion-8B (BF16, approx. 16GB) |
The three tri-mode modes are switched with the custom methods ar_generate() / generate() / linear_spec_generate(). These are implemented in custom modeling (modeling_*.py) bundled with the model repository, and cannot be easily called from vLLM's standard serving functionality. This time I loaded the model from transformers with trust_remote_code=True and called the methods directly.
Setup and model loading
I create a virtual environment for verification using uv and install the required libraries. For PyTorch, I specify the cu130 build to match the CUDA 13 environment of DGX Spark.
cd ~/works/nemotron-labs-diffusion
uv venv --python 3.13 .venv
uv pip install --python .venv/bin/python \
torch 'transformers>=5.0' peft accelerate datasets \
--torch-backend=cu130
Loading the model follows the model card sample exactly, with trust_remote_code=True being mandatory — it's needed to load the custom modeling.
from transformers import AutoModel, AutoTokenizer
import torch
repo = "nvidia/Nemotron-Labs-Diffusion-8B"
tokenizer = AutoTokenizer.from_pretrained(repo, trust_remote_code=True)
model = AutoModel.from_pretrained(repo, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16).eval()
The three modes are called as follows. The process up to applying the chat template and creating prompt_ids is common to all.
history = [{"role": "user", "content": "Please explain a diffusion language model in one sentence."}]
text = tokenizer.apply_chat_template(history, tokenize=False, add_generation_prompt=True)
prompt_ids = tokenizer(text, return_tensors="pt").input_ids.cuda()
eos = tokenizer.eos_token_id
# AR mode
out_ids, nfe = model.ar_generate(prompt_ids, max_new_tokens=512)
# Diffusion mode
out_ids, nfe = model.generate(
prompt_ids, max_new_tokens=512, block_length=32, threshold=0.9, eos_token_id=eos,
)
# Linear Self-Speculation mode
out_ids, nfe = model.linear_spec_generate(
prompt_ids, max_new_tokens=512, block_length=32, eos_token_id=eos,
)
A LoRA adapter (linear_spec_lora) is bundled in the model repository to further extend acceptance in Linear Self-Speculation. When using this, you attach it with PeftModel and then call the method from the unwrapped base model side.
from peft import PeftModel
model = PeftModel.from_pretrained(model, repo, subfolder="linear_spec_lora").eval()
base = model.model # Call linear_spec_generate after unwrapping
out_ids, nfe = base.linear_spec_generate(
prompt_ids, max_new_tokens=512, block_length=32, eos_token_id=eos,
)
In practice, of this straightforward procedure, the diffusion mode and Linear Self-Speculation mode initially stop with an exception in transformers 5.9. The cause and workaround are explained together in the "Potential pitfalls on DGX Spark" section. For now, I'll just note that "inserting one shim makes all three modes work."
Measuring the speed of all three tri-mode modes
Here's the main part. I ran the same set of 12 longform prompts (requests for explanations on technical topics, mixed Japanese and English) through 4 configurations and took the average excluding warmup. Generation used max_new_tokens=512 and greedy decoding at temperature 0.
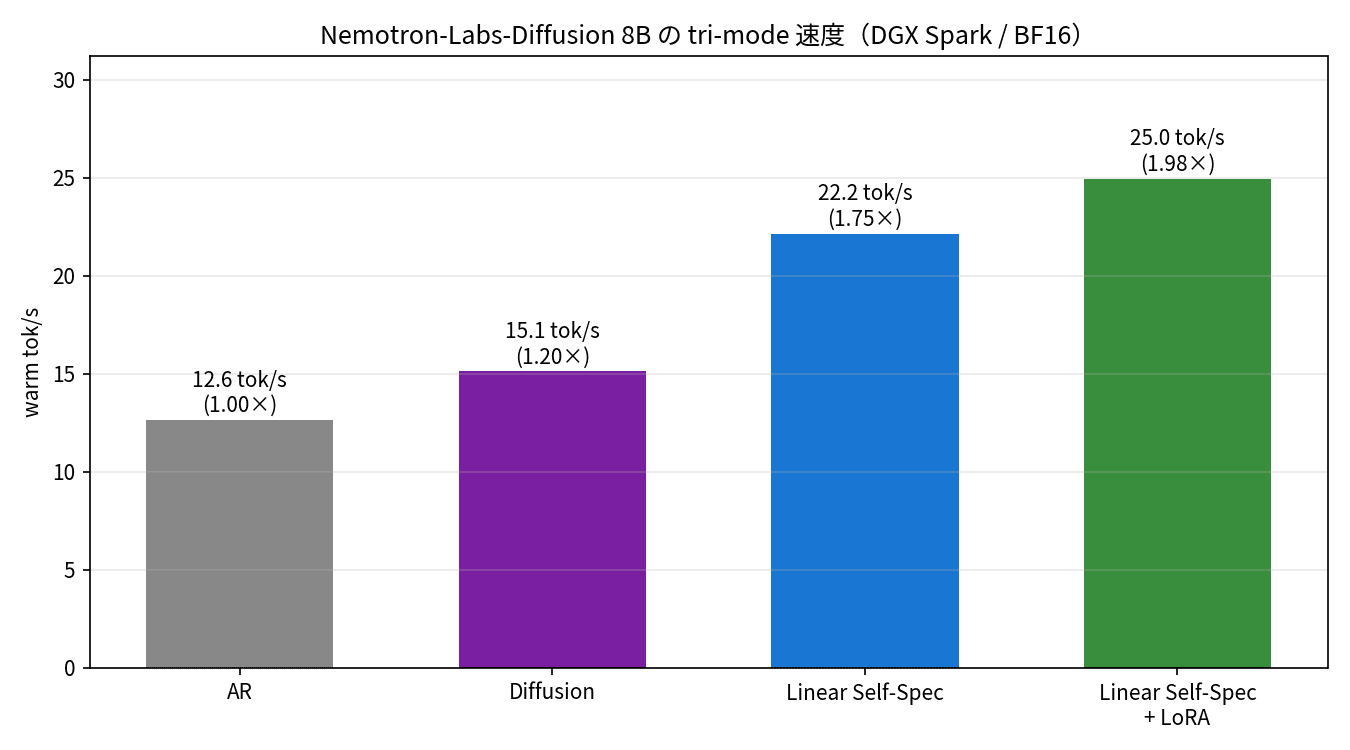
Warm tok/s for 4 configurations. Using AR as the baseline, Diffusion is 1.20x, Linear Self-Speculation is 1.75x, and with LoRA it's 1.98x. All use the same 8B model with the same weights, only switching the decoding method.
The numerical results are as follows:
| Configuration | tok/s | vs AR | tokens/forward | mean nfe |
|---|---|---|---|---|
| AR (baseline) | 12.6 | 1.00x | 1.00 | 512 |
| Diffusion | 15.1 | 1.20x | 1.23 | 420 |
| Linear Self-Spec | 22.2 | 1.75x | 1.81 | 287 |
| Linear Self-Spec + LoRA | 25.0 | 1.98x | 2.08 | 252 |
It forms a clean staircase. What I want to highlight are tokens/forward and nfe. AR confirms 1 token per forward, so it runs 512 forward passes to produce 512 tokens. Linear Self-Speculation + LoRA confirms an average of 2.08 tokens per forward, producing roughly the same length of text in just 252 forward passes. Halving the number of forward passes directly translates into the speed difference.
Let me also clarify the relationship with the official numbers. The technical report includes actual measurements on DGX Spark, showing that the 8B diffusion mode achieves 77.5 tok/s with FP8 quantization (3.14x vs AR) and 112.5 tok/s with INT4 quantization (2.69x vs AR). My own measurements here look considerably lower, but this is because I'm running plain BF16 without quantization, directly from transformers without going through inference engine optimizations. Absolute values can change considerably with the runtime and quantization. What I wanted to see in this article is not those values, but the relative speed difference between AR and diffusion-based approaches under the same conditions. In that sense, the result of Linear Self-Speculation at 1.75–1.98x straightforwardly reflects the structural advantage of diffusion language models.
I also checked measurement variance. AR consistently stayed within 12.6–12.7 tok/s across all 12 prompts, with virtually no measurement noise. The tokens/forward staircase (AR 1.00 → Diffusion 1.23 → Linear Spec 1.81 → +LoRA 2.08) also reproduced stably.
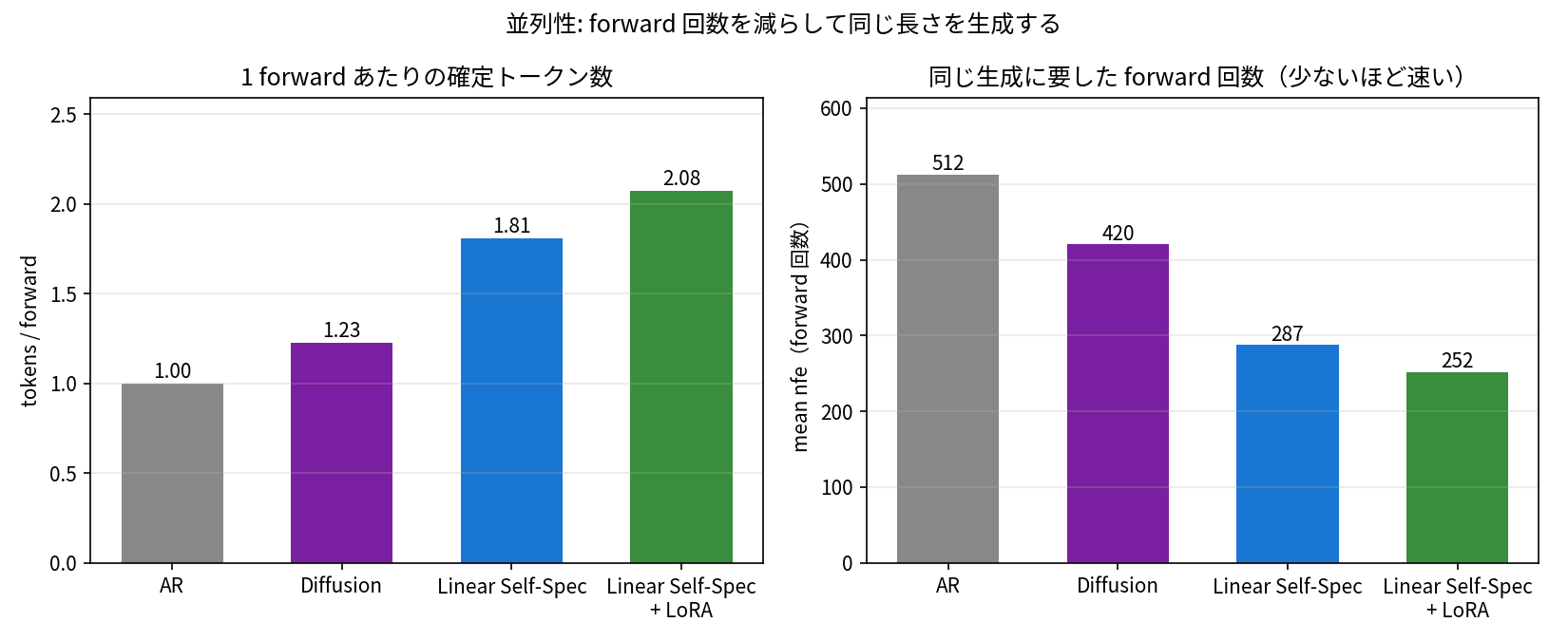
Left shows tokens per forward, right shows the number of forward passes required for the same generation. Diffusion-based approaches confirm more tokens per forward pass, reducing the total number of forward passes accordingly.
All three modes ran on DGX Spark, and the quality of the output text was comparable to AR. Here is a summary table of operability:
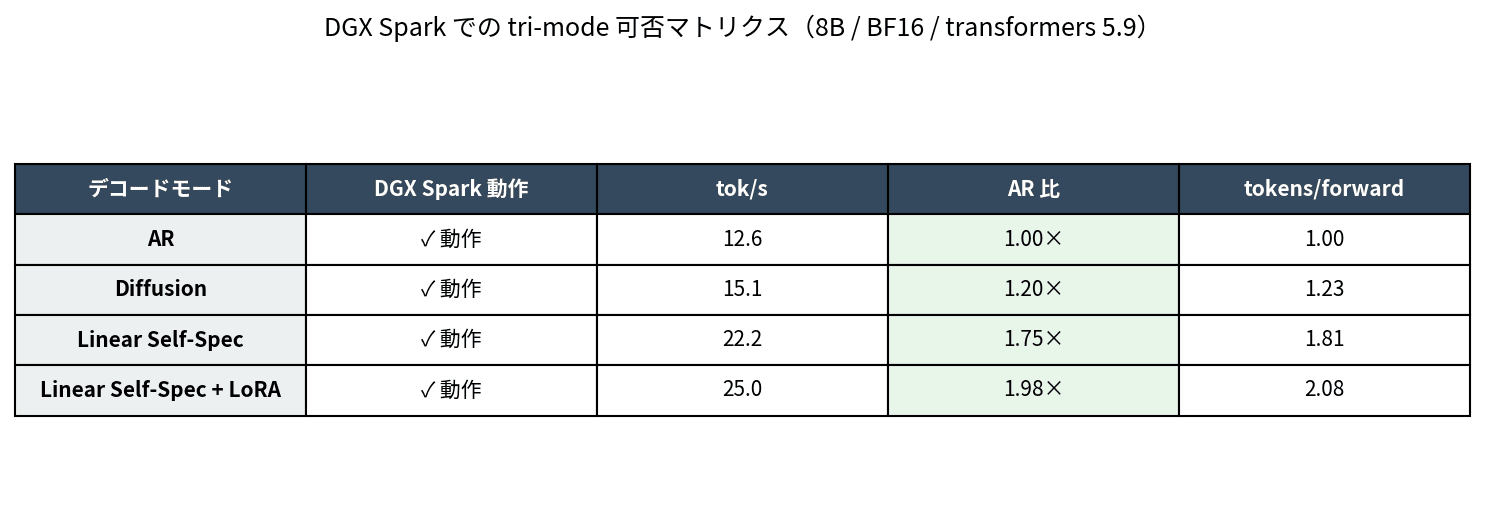
tri-mode operability with 8B / BF16 / transformers 5.9. All three modes worked, with Linear Self-Speculation being the fastest.
Visualizing the parallel generation of diffusion mode
The speed is clear. But in what order does diffusion mode actually fill in tokens? This is the part I personally wanted to see most.
The generate() of diffusion mode internally repeats a process for each block: "among positions still masked, confirm those with higher confidence." So I recorded "which positions are still masked" and "which positions were confirmed at this step" each time this confirmation process is called, and traced how one block fills in.
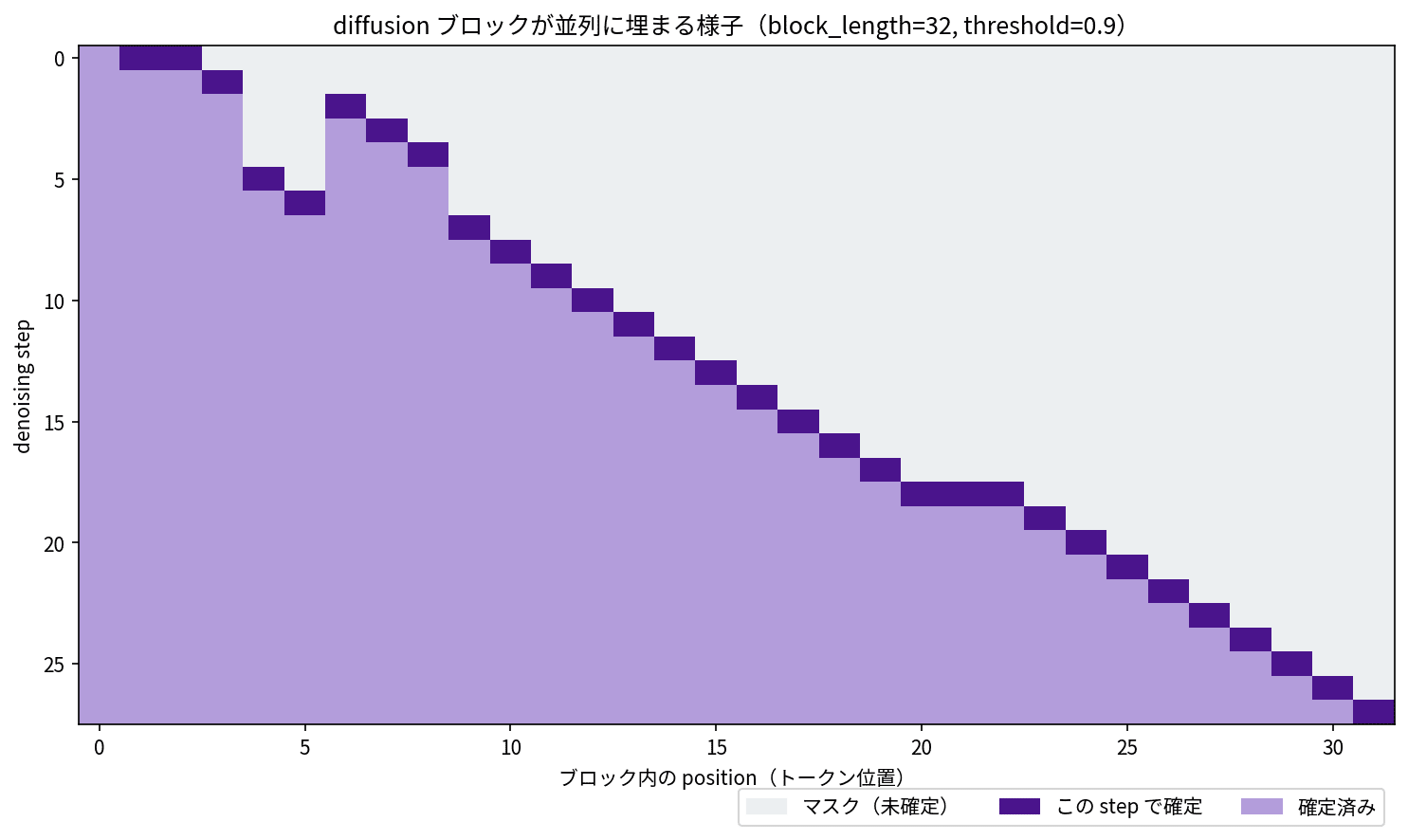
How a block with block_length=32 fills in across denoising steps. Horizontal axis is the token position within the block, vertical axis is the step. Dark purple indicates positions confirmed at that step, light purple indicates already confirmed, gray indicates masked. With threshold=0.9, mainly 1 token is confirmed per step, but in the first step multiple positions are confirmed simultaneously.
Looking at the heatmap, you can see multiple positions confirmed simultaneously in the first step of the block, and then positions filling in one by one from the most confident afterward. Since threshold=0.9 is a cautious setting, most steps confirm one token at a time. Still, unlike autoregression which must always proceed left to right as "position 0 → 1 → 2…", the difference is that it fills in from the most confident positions first.
The next figure shows the order in which positions within a block were confirmed.
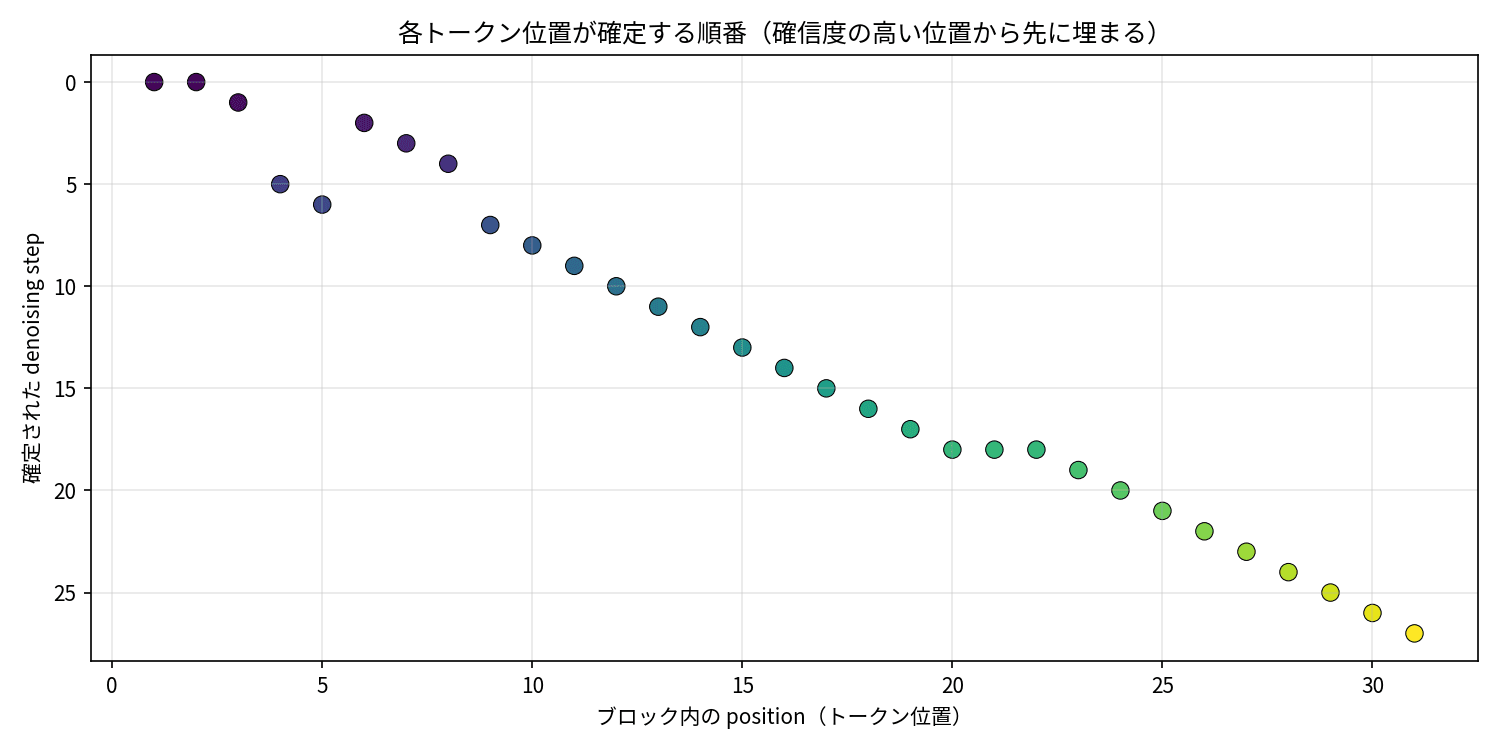
At which denoising step (vertical axis) each token position (horizontal axis) within the block was confirmed. Rather than left-to-right, positions fill in non-sequentially from the most confident positions.
There is one thing I want to state precisely here. In NVIDIA's explanation, one feature of diffusion language models is described as "never permanently committing tokens, able to revise as they go." Within the scope of tracing the internals of generate() on the 8B model, once a position was confirmed, it did not become a mask target again in the remaining steps of that block — in that sense, confirmation itself was irreversible. The essential difference from autoregression is less about "revision" and more about the fact that the order of confirmation is not fixed (left to right) but follows confidence, and multiple positions can be confirmed simultaneously in one step. This is what feels most natural given the actual behavior on the machine. This parallelism is what leads to the reduction in forward pass count seen earlier.
Sweeping threshold and block_length
Diffusion mode has two adjustment knobs: threshold and block_length. I did a grid check to see how speed and quality change as these are varied. Threshold was tested at 4 values — 0.7 / 0.8 / 0.9 / 0.95 — and block_length at 3 values — 8 / 16 / 32 — for a total of 12 combinations run across 8 longform prompts.
I struggled a bit with the quality metric. I initially tried to measure using the accuracy on a multiple-choice QA benchmark (JCommonsenseQA), but since answers are a single character, changing threshold barely moved the results and it wasn't useful as an indicator. In the end, I used the repetition rate of the output (duplicate rate of the same 4-gram) as a proxy for quality. The technical report also notes that diffusion mode limits generation length to avoid repetition and hallucination, and repetition is a typical failure mode when diffusion mode breaks down.
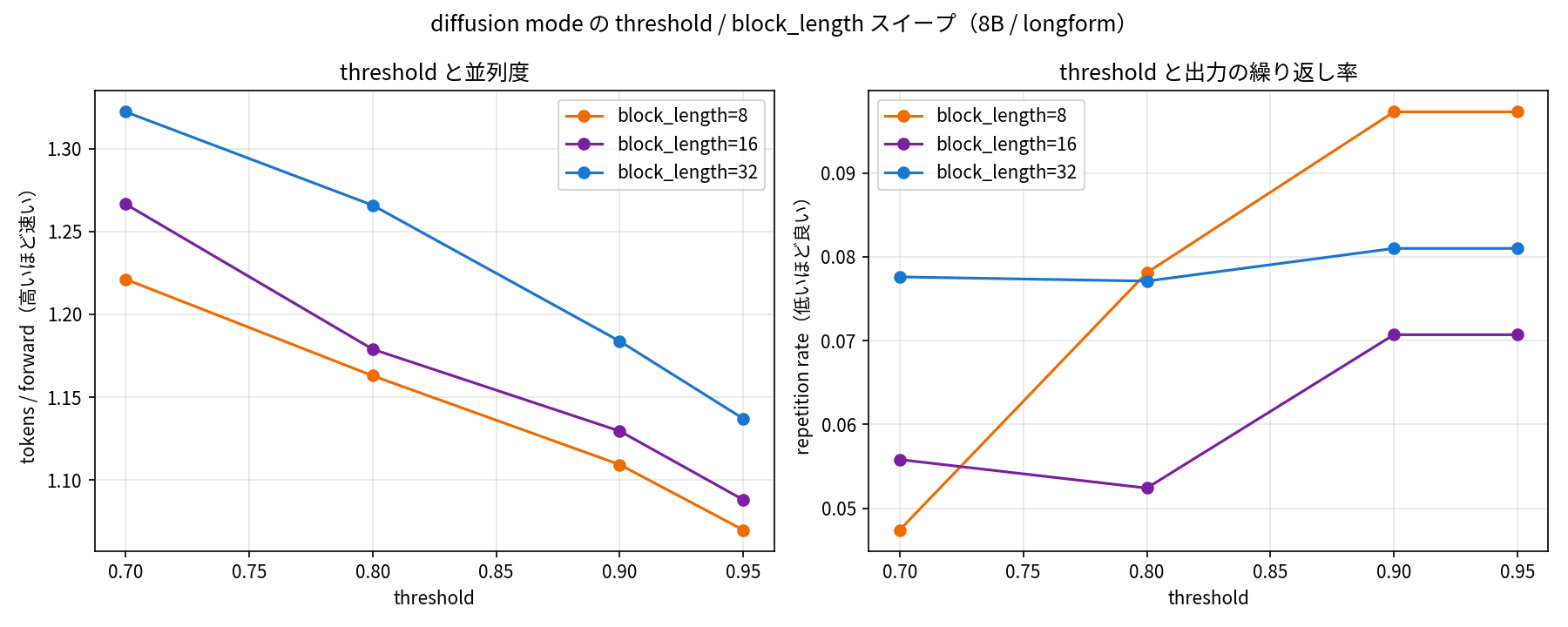
Left shows threshold vs. parallelism (tokens per forward), right shows threshold vs. repetition rate. Lowering threshold increases parallelism and speeds things up. Repetition rate is actually lower on the lower threshold side.
The results were simple. Lowering threshold consistently speeds things up. With block_length=32, tokens per forward increases from 1.14 to 1.32 when reducing threshold from 0.95 to 0.70, reducing the total number of forward passes accordingly.
What was surprising was the quality side. I expected that confirming more at once by lowering threshold would be sloppy and increase repetition — but in practice it was the opposite. The repetition rate was actually lower at lower threshold values, with a slight tendency toward more repetition at threshold 0.9 or 0.95. The values themselves were also low at 0.05–0.10, not at a level where the text breaks down.
The technical report describes threshold as "a knob that determines the tradeoff between speed and token error rate." However, at least within the scope of running this longform explanation task with 8B BF16, I found no compelling reason to set threshold high. There was also a tendency for the influence of threshold to diminish as block_length increased, so in practice starting with a somewhat larger block_length and a lower threshold seems natural. Since this will vary by task and model size, it seems best to sweep it once for your own use case.
Potential pitfalls on DGX Spark
The biggest headache during verification was the incompatibility between transformers 5.9 and the bundled custom modeling. The Nemotron-Labs-Diffusion model repository includes a Python file called modeling_ministral.py, which is executed when loading with trust_remote_code=True. However, this file calls create_causal_mask() with slightly older argument names (input_embeds= and cache_position=), and since transformers 5.9.0 changed these argument names, it stops with a TypeError. Diffusion mode and Linear Self-Speculation mode go through this code path (AR mode uses a different path and was not affected).
Directly modifying files in the Hugging Face cache means tampering with what is under the library's management, which I wanted to avoid. This time, I prepared a shim on my script side that thinly wraps the mask generation function in transformers.masking_utils to absorb the old argument names. By applying this wrap before from_pretrained() loads the custom modeling, it works without touching any dependency code or the cache.
def apply_transformers_compat() -> None:
import transformers.masking_utils as mu
def _wrap(fn):
def wrapped(*args, **kwargs):
if "input_embeds" in kwargs and "inputs_embeds" not in kwargs:
kwargs["inputs_embeds"] = kwargs.pop("input_embeds")
kwargs.pop("cache_position", None)
return fn(*args, **kwargs)
return wrapped
for name in ("create_causal_mask", "create_sliding_window_causal_mask"):
setattr(mu, name, _wrap(getattr(mu, name)))
When running a freshly released model with the latest transformers, version mismatches like this come up fairly often. Since it's the kind of thing that becomes unnecessary once the custom modeling side is updated, I think it's best to treat the shim as a temporary workaround and keep it self-contained within your own script without touching any dependency code.
Incidentally, the model card doesn't state the context length, but looking at config.json, max_position_embeddings is 262144 (256K). This is helpful to keep in mind when planning to feed in long text locally.
Summary
I ran the 8B model of Nemotron-Labs-Diffusion on DGX Spark and measured all three tri-modes. Here's a summary of what I found:
- All three modes — AR / Diffusion / Linear Self-Speculation — worked in the BF16 environment on DGX Spark (with one shim needed for transformers 5.9)
- In terms of speed, Linear Self-Speculation was 1.75x vs AR, and 1.98x with LoRA. Self-speculation, where diffusion generates a draft in parallel and autoregression verifies it, was the most effective in a plain configuration
- Diffusion mode fills in from the most confident positions. Confirmation itself is irreversible, and the key difference from autoregression lies in "parallelism and confirmation order" rather than "revision"
- Lowering threshold speeds things up, and the repetition rate actually decreases too. For this task, no reason was found to set threshold high
- The official figures of "6× tokens per forward" and "2.7x vs AR with INT4" include quantization and runtime, and with BF16 longform without quantization, tokens per forward was 1.2–2.1 and speedup was just under 2x
Diffusion language models clearly showed a direction where self-speculation speeds things up straightforwardly without needing a separate draft model. They also seem well-suited to environments like DGX Spark that run locally on a single node. There's still much I haven't tried — quantized versions, the VLM version, behavior with longer contexts — so I hope to cover the rest in a separate article.
Reference links
Technical report and public resources for Nemotron-Labs-Diffusion:
Related article measuring speculative decoding on DGX Spark:
