
Nemotron-Labs-Diffusion を DGX Spark で動かして tri-mode 生成を実測してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
2026 年 5 月、NVIDIA が「Nemotron-Labs-Diffusion」という新しいモデルファミリーを公開しました。名前に diffusion とあるので画像生成の話かなと思った方もいるかもしれませんが、これはテキストを生成する「拡散言語モデル(diffusion language model)」です。最初にここを押さえておくと、この先の話が読みやすくなります。
ふだん使っている LLM は、文章を左から 1 トークンずつ順番に書いていきます。前のトークンが決まらないと次に進めないので、生成は本質的に逐次処理です。拡散言語モデルはここを変えます。複数のトークンをブロック単位でまとめて並列に生成し、確信が持てない部分は後のステップで埋め直す、という作り方をします。
Nemotron-Labs-Diffusion が面白いのは、ひとつのモデルで 3 つのデコード方式(AR / Diffusion / Linear Self-Speculation)を切り替えられるところです。NVIDIA はこれを tri-mode と呼んでいます。自己回帰(AR)も拡散も、別々のモデルではなく同じチェックポイントの中に同居しています。
公開された情報を読んでいて、個人的に気になったのは次の 3 点でした。
- DGX Spark のローカル環境で、3 つのモードはどれも素直に動くのか
- 拡散モードの「並列に生成して後から埋める」挙動は、実際に動かすとどう見えるのか
- 公式が出している「AR 比 2.7 倍」「6× tokens per forward」といった数字は、量子化なしの素の実行だとどうなるのか
ということで、Nemotron-Labs-Diffusion の 8B モデルを DGX Spark に載せて、3 モードを実測してみました。結論から先に書いておくと、3 モードとも DGX Spark で動きました。速度は Linear Self-Speculation が AR 比で 1.75〜1.98 倍。ただし公式が掲げる派手な数字は条件付きで、量子化なしの BF16 で longform を生成すると、また違った景色が見えてきます。その違いも含めて見ていきます。
なお、推論エンジンの speculative decoding を DGX Spark で実測した話としては、以前に Gemma 4 MTP の記事も書いています。Gemma 4 MTP は本体とは別に下書き役のモデルを用意する方式で、今回の Linear Self-Speculation は同じモデルだけで完結する方式という違いはありますが、「下書きを速く出して本体が検証する」という骨格は共通です。あわせて読むと拡散言語モデルの位置づけが掴みやすいと思います。
Nemotron-Labs-Diffusion の tri-mode とは
モデルファミリーと素性
Nemotron-Labs-Diffusion は、テキスト生成モデルが 3B / 8B / 14B の 3 サイズ、それぞれに事前学習だけの Base 版と指示チューニング済みの Instruct 版があります。さらに画像も扱える VLM-8B も用意されています。今回は指示チューニング済みの 8B(nvidia/Nemotron-Labs-Diffusion-8B)を対象にしました。
アーキテクチャは Mamba ハイブリッドではなく、素直な Transformer です。技術レポートによると、学習は既存の Ministral3-8B を起点に、まず自己回帰だけで 1T トークンの継続事前学習、続いて自己回帰と拡散を組み合わせた目的関数で 300B トークンの継続事前学習、最後に指示チューニングを 45B トークン、という流れで進めたとあります。ライセンスは NVIDIA Nemotron Open Model License です。
ここで地味に大事なのが、自己回帰と拡散を一緒に学習しても AR の精度が落ちないという点です。技術レポートでは、拡散の損失を入れずに同じ条件で学習したモデルと比べて、joint 学習後の AR 精度がむしろ 0.14〜0.43% 改善したと報告されています。拡散の能力を足すために自己回帰を犠牲にしてはいない、というのが設計のうれしいところですね。
3 つのデコードモード
tri-mode の中身を整理します。同じ重みに対して、推論時にアテンションの掛け方を切り替えることで 3 つの生成方式を使い分けます。
AR モードは従来どおりの自己回帰デコードです。1 回の forward で 1 トークンを左から順に確定します。ar_generate() を呼びます。
Diffusion モードは、生成する区間を block_length 個のブロックに区切り、ブロック内をいったん全部マスクしてから、確信度の高い位置を少しずつ埋めていきます。generate() を呼び、block_length と threshold という拡散特有のパラメータを渡します。threshold は「そのステップでどれだけのトークンを確定するか」を決めるもので、高いほど慎重に、低いほど一気に埋めます。
Linear Self-Speculation モードは、拡散と自己回帰を組み合わせた自己投機デコードです。拡散が候補トークンをまとめてドラフトとして並列生成し、それを自己回帰が検証して正しいところまでを確定します。speculative decoding と同じ発想ですが、ドラフト専用の小さなモデルを別に用意する必要がなく、同じモデルの拡散モードがドラフト役を兼ねます。linear_spec_generate() を呼びます。
下書き役のために別の重みファイルを持たないという点では、本体に下書き専用のモジュールを組み込む DeepSeek の MTP とも近い系統です。ただし DeepSeek が専用のモジュールを足しているのに対して、Nemotron-Labs-Diffusion はそのモジュールすら追加せず、もとから備えている拡散モードをそのまま下書きに流用しているところが違います。前述の Gemma 4 MTP は本体とは別の下書きモデルを配布する方式なので、3 つを並べると「別モデル」「内蔵モジュール」「モード流用」と、下書きの出どころが少しずつ違うことが見えてきますね。
3 つのメソッドは戻り値として生成結果のほかに nfe(number of forward evaluations、forward を何回回したか)を返します。同じ長さの文章をより少ない forward 回数で出せれば、それだけ速いということです。この記事では速度の指標として、この nfe と、そこから計算する tokens per forward(1 forward あたり何トークン確定したか)をたびたび使います。
検証環境
検証には DGX Spark を 1 台使いました。ハードウェアとソフトウェアの構成は次のとおりです。
| 項目 | 内容 |
|---|---|
| マシン | NVIDIA DGX Spark(GB10、Blackwell SM121) |
| メモリ | 128GB 統合メモリ(UMA)、帯域 273 GB/s |
| アーキテクチャ | aarch64(ARM64) |
| Python | 3.13.13(uv で構築) |
| PyTorch | 2.12.0+cu130 |
| transformers | 5.9.0 |
| モデル | nvidia/Nemotron-Labs-Diffusion-8B(BF16、約 16GB) |
tri-mode の 3 モードは ar_generate() / generate() / linear_spec_generate() という独自のメソッドで切り替えます。これらはモデルリポジトリに同梱された custom modeling(modeling_*.py)に実装されていて、vLLM の標準のサーブ機能からは素直に呼べません。今回は transformers から trust_remote_code=True でロードして直接メソッドを叩いています。
セットアップとモデルのロード
uv で検証用の仮想環境を作り、必要なライブラリを入れます。PyTorch は DGX Spark の CUDA 13 環境に合わせて cu130 のビルドを指定します。
cd ~/works/nemotron-labs-diffusion
uv venv --python 3.13 .venv
uv pip install --python .venv/bin/python \
torch 'transformers>=5.0' peft accelerate datasets \
--torch-backend=cu130
モデルのロードはモデルカードのサンプルどおりで、trust_remote_code=True が必須です。custom modeling を読み込むためですね。
from transformers import AutoModel, AutoTokenizer
import torch
repo = "nvidia/Nemotron-Labs-Diffusion-8B"
tokenizer = AutoTokenizer.from_pretrained(repo, trust_remote_code=True)
model = AutoModel.from_pretrained(repo, trust_remote_code=True)
model = model.cuda().to(torch.bfloat16).eval()
3 モードはそれぞれ次のように呼び分けます。チャットテンプレートを適用して prompt_ids を作るところまでは共通です。
history = [{"role": "user", "content": "拡散言語モデルを一文で説明してください。"}]
text = tokenizer.apply_chat_template(history, tokenize=False, add_generation_prompt=True)
prompt_ids = tokenizer(text, return_tensors="pt").input_ids.cuda()
eos = tokenizer.eos_token_id
# AR モード
out_ids, nfe = model.ar_generate(prompt_ids, max_new_tokens=512)
# Diffusion モード
out_ids, nfe = model.generate(
prompt_ids, max_new_tokens=512, block_length=32, threshold=0.9, eos_token_id=eos,
)
# Linear Self-Speculation モード
out_ids, nfe = model.linear_spec_generate(
prompt_ids, max_new_tokens=512, block_length=32, eos_token_id=eos,
)
Linear Self-Speculation には、採択をさらに伸ばす LoRA アダプタ(linear_spec_lora)がモデルリポジトリに同梱されています。これを使うときは PeftModel でアタッチしたあと、いったんラップを外したベースモデル側からメソッドを呼びます。
from peft import PeftModel
model = PeftModel.from_pretrained(model, repo, subfolder="linear_spec_lora").eval()
base = model.model # ラップを外してから linear_spec_generate を呼ぶ
out_ids, nfe = base.linear_spec_generate(
prompt_ids, max_new_tokens=512, block_length=32, eos_token_id=eos,
)
実は、この素直な手順のうち拡散モードと Linear Self-Speculation モードは、transformers 5.9 だと最初は例外で止まります。原因と回避策は「DGX Spark で詰まりやすいポイント」の章でまとめて説明します。ここでは「shim を 1 つ挟むと 3 モードとも動く」とだけ書いておきます。
tri-mode 3 モードの速度を実測する
ここからが本題です。同じ longform プロンプト 12 本(技術的な話題の解説を求めるもの、日本語と英語を混在)を 4 つの構成に通し、ウォームアップを除いた平均を取りました。生成は max_new_tokens=512、温度 0 の貪欲デコードです。
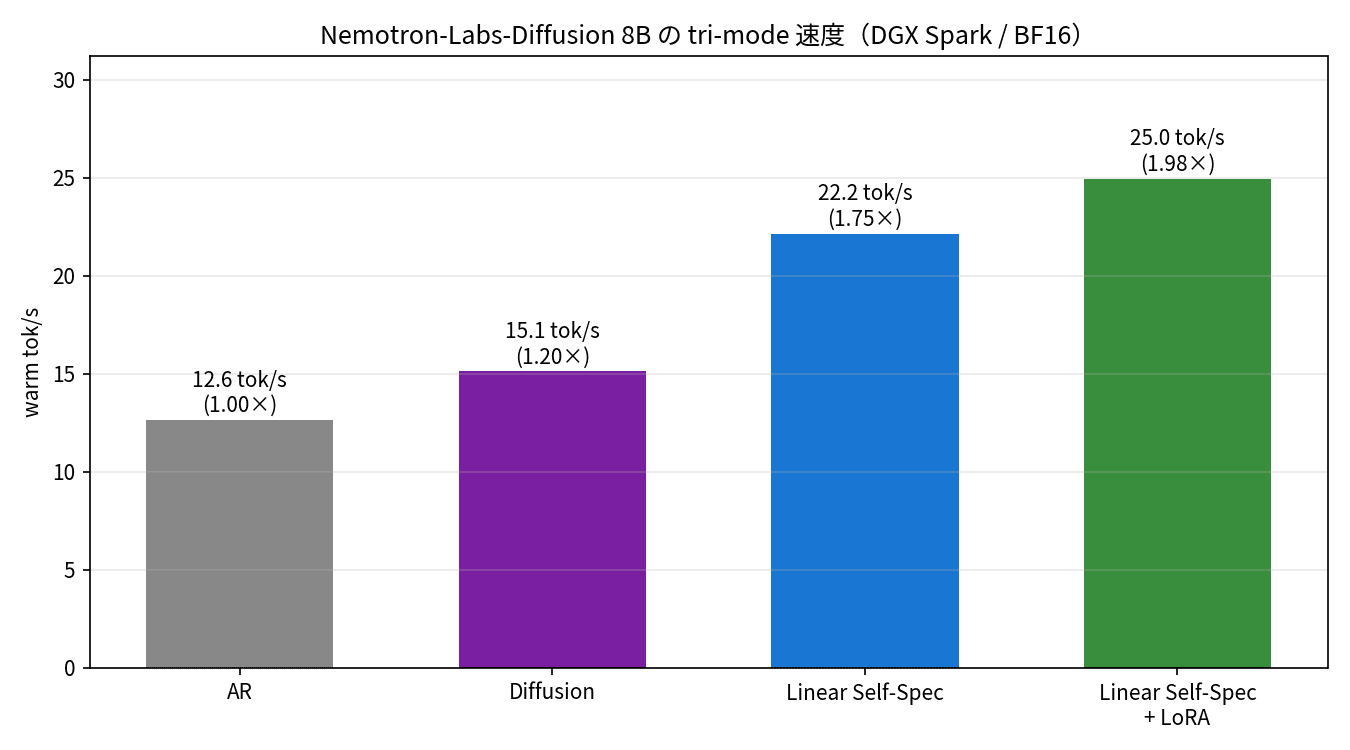
4 構成の warm tok/s。AR を基準に、Diffusion 1.20 倍、Linear Self-Speculation 1.75 倍、LoRA つきで 1.98 倍。すべて同じ 8B モデルの同じ重みで、デコード方式だけを切り替えている。
数値で並べると次のようになりました。
| 構成 | tok/s | AR 比 | tokens/forward | mean nfe |
|---|---|---|---|---|
| AR(基準) | 12.6 | 1.00 倍 | 1.00 | 512 |
| Diffusion | 15.1 | 1.20 倍 | 1.23 | 420 |
| Linear Self-Spec | 22.2 | 1.75 倍 | 1.81 | 287 |
| Linear Self-Spec + LoRA | 25.0 | 1.98 倍 | 2.08 | 252 |
きれいな階段になりました。注目したいのは tokens/forward と nfe です。AR は 1 forward で 1 トークンなので、512 トークンを出すのに 512 回 forward を回しています。Linear Self-Speculation + LoRA は 1 forward で平均 2.08 トークンを確定するので、ほぼ同じ長さの文章を 252 回の forward で出し切っています。forward の回数を半分に減らせているのが、そのまま速度差になっているわけですね。
ここで、公式の数字との関係を整理しておきます。技術レポートには DGX Spark での実測も載っていて、8B の拡散モードは FP8 量子化で 77.5 tok/s(AR 比 3.14 倍)、INT4 量子化で 112.5 tok/s(AR 比 2.69 倍)とあります。今回の自分の計測値はこれよりだいぶ低く見えますが、これは量子化なしの BF16 を、推論エンジンの最適化を通さず transformers から素で動かしているためです。絶対値はランタイムと量子化でいくらでも変わります。この記事で見たいのはそこではなく、同じ条件のまま AR と拡散系を並べたときの相対的な速度差です。その意味では、Linear Self-Speculation が 1.75〜1.98 倍という結果は、拡散言語モデルの構造的なうまみを素直に表していると思います。
計測のばらつきも見ておきました。AR は 12 本すべてで 12.6〜12.7 tok/s に収まっていて、計測ノイズはほぼありません。tokens/forward の階段(AR 1.00 → Diffusion 1.23 → Linear Spec 1.81 → +LoRA 2.08)も安定して再現しました。
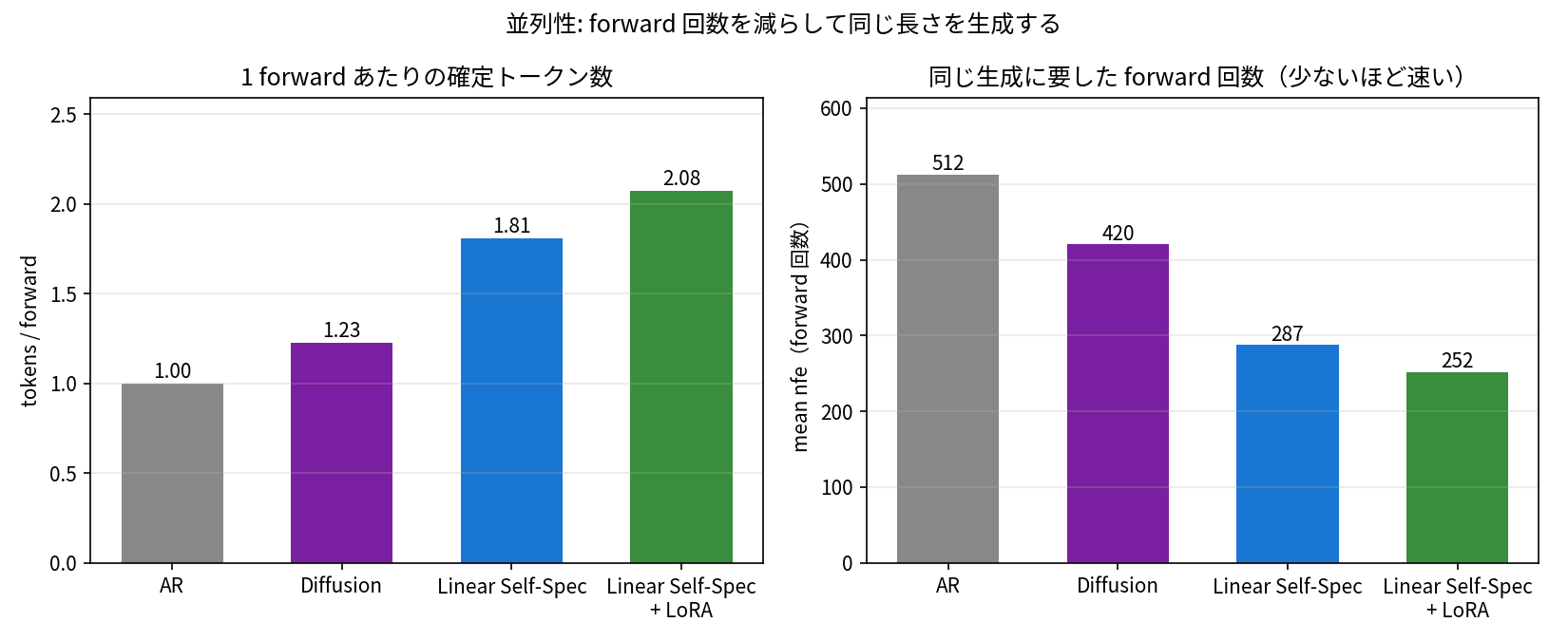
左が tokens per forward、右が同じ生成に要した forward 回数。拡散系は 1 回の forward でより多くのトークンを確定し、その分 forward の総数を減らしている。
3 つのモードはどれも DGX Spark で動き、出力の文章としての品質も AR と比べて遜色ありませんでした。可否を表にまとめておきます。
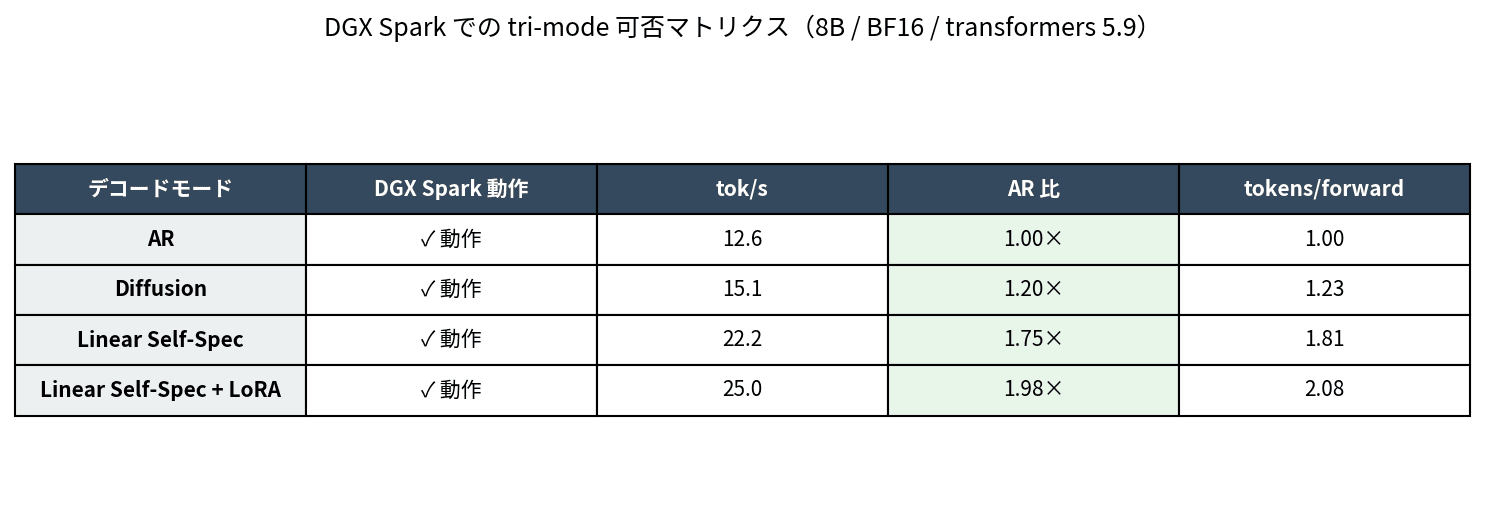
8B / BF16 / transformers 5.9 での tri-mode 動作可否。3 モードとも動作し、Linear Self-Speculation が最も速い。
拡散モードの並列生成を可視化してみる
速度が出るのは分かりました。では拡散モードは、実際にどういう順番でトークンを埋めているのでしょうか。ここが個人的に一番見たかったところです。
拡散モードの generate() は、内部でブロックごとに「まだマスクされている位置のうち、確信度の高いものを確定する」という処理を繰り返しています。そこで、この確定処理が呼ばれるたびに「どの位置がまだマスクか」「このステップでどの位置を確定したか」を記録するようにして、1 ブロックの埋まり方を追いかけてみました。
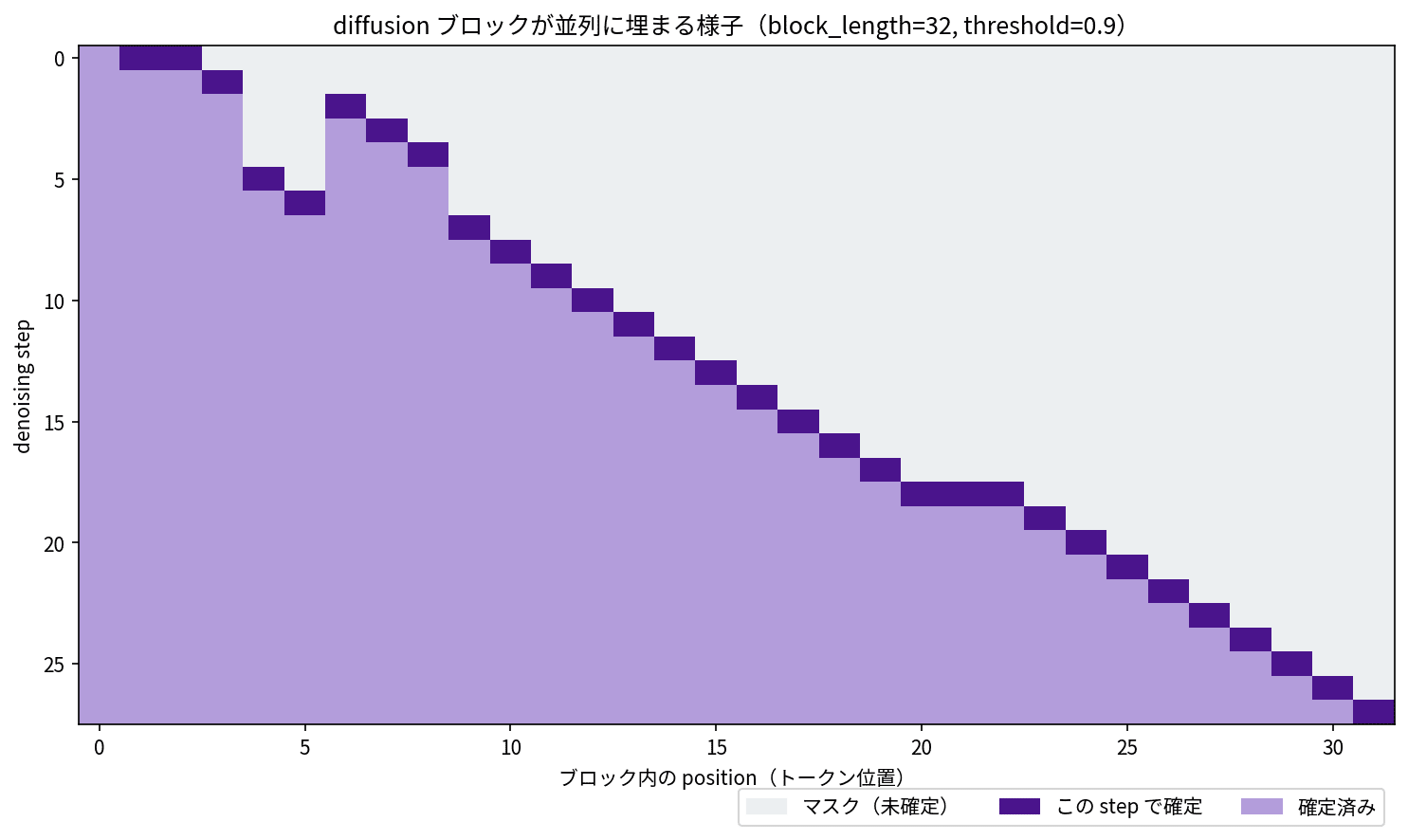
block_length=32 のブロックが denoising step を追って埋まっていく様子。横軸がブロック内のトークン位置、縦軸が step。濃い紫がそのステップで確定した位置、薄い紫が確定済み、グレーがマスク。threshold=0.9 では 1 ステップに確定するのは主に 1 トークンだが、最初のステップでは複数位置がまとめて確定している。
ヒートマップを見ると、ブロックの最初のステップで複数の位置がまとめて確定し、そのあとは確信度の高い位置から 1 つずつ埋まっていく様子が見えます。threshold=0.9 は慎重な設定なので、多くのステップで確定するのは 1 トークンずつです。それでも、自己回帰のように「位置 0 → 1 → 2…」と必ず左から進むのではなく、確信度の高い位置から先に埋めているところが違います。
もう 1 つ、ブロック内で位置がどの順番で確定したかを見たのが次の図です。
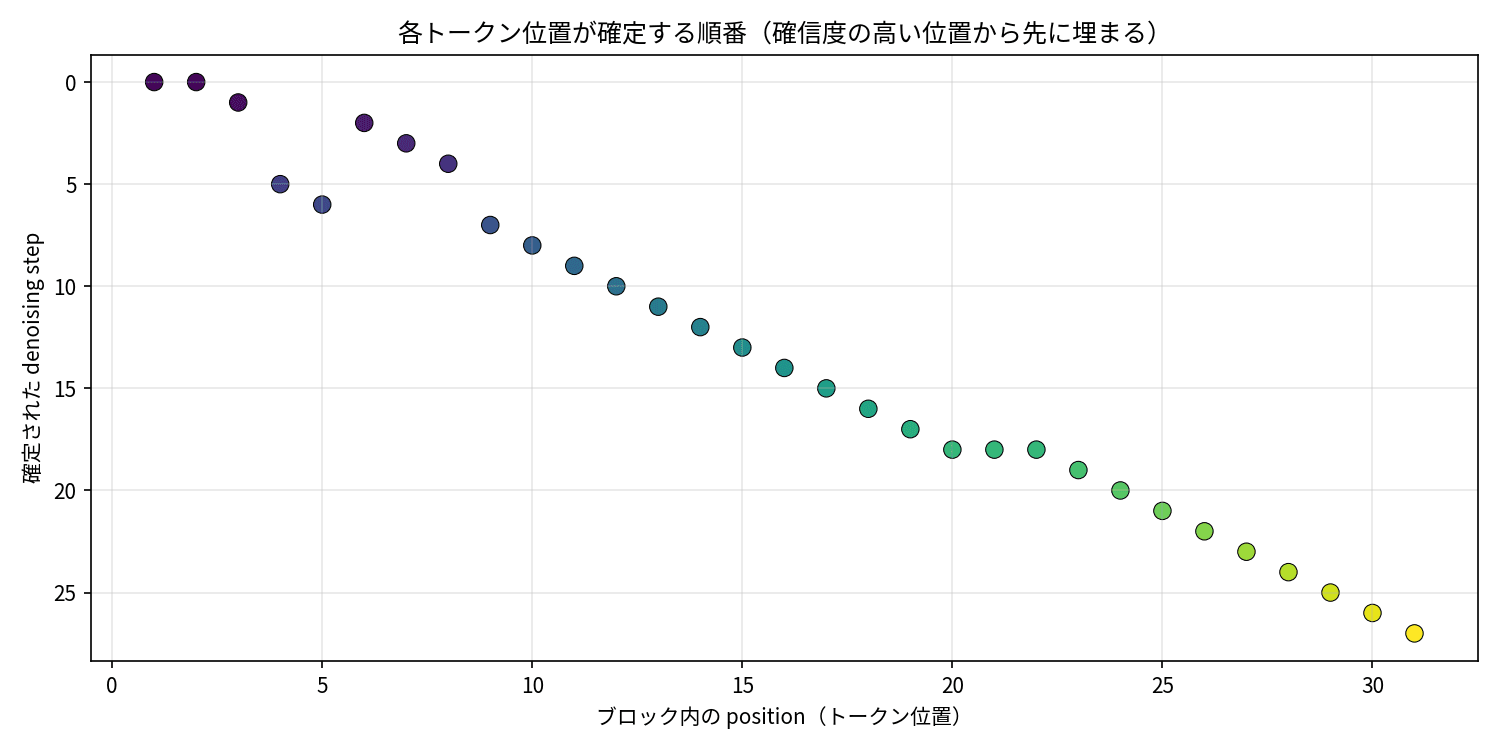
ブロック内の各トークン位置(横軸)が、どの denoising step(縦軸)で確定したか。左端と右端ではなく、確信度の高い位置から飛び飛びに埋まっていくのが分かる。
ここで 1 つ、正確に書いておきたいことがあります。NVIDIA の説明では拡散言語モデルの特徴として「トークンを永続的にコミットせず、生成しながら修正できる(revise as they go)」と紹介されています。今回 8B の generate() の中身を追った範囲では、いったん確定した位置はそのブロックの残りのステップで再びマスク対象になることはなく、その意味で確定そのものは不可逆でした。自己回帰との本質的な違いは「修正」というより、確定する順番が固定(左から)ではなく確信度順で、しかも 1 ステップで複数位置を同時に確定できるところにある、と捉えるのが実機の挙動には素直だと感じました。この並列性が、先ほど見た forward 回数の削減につながっています。
threshold と block_length を振ってみる
拡散モードには threshold と block_length という調整ノブがあります。これらを振ると速度と品質がどう動くのか、グリッドで確認しました。threshold は 0.7 / 0.8 / 0.9 / 0.95 の 4 通り、block_length は 8 / 16 / 32 の 3 通り、計 12 通りを longform プロンプト 8 本で回しています。
品質の指標には少し悩みました。最初は選択式の質問応答ベンチ(JCommonsenseQA)の正答率で測ろうとしたのですが、答えが記号 1 文字だと threshold をどう変えても結果がほぼ動かず、指標になりませんでした。最終的に、出力に含まれる繰り返し(同じ 4-gram の重複率)を品質の代理指標にしました。技術レポートも、拡散モードは繰り返しや hallucination を避けるために生成長を制限していると述べていて、繰り返しは拡散モードが崩れるときの典型的な失敗の形だからです。
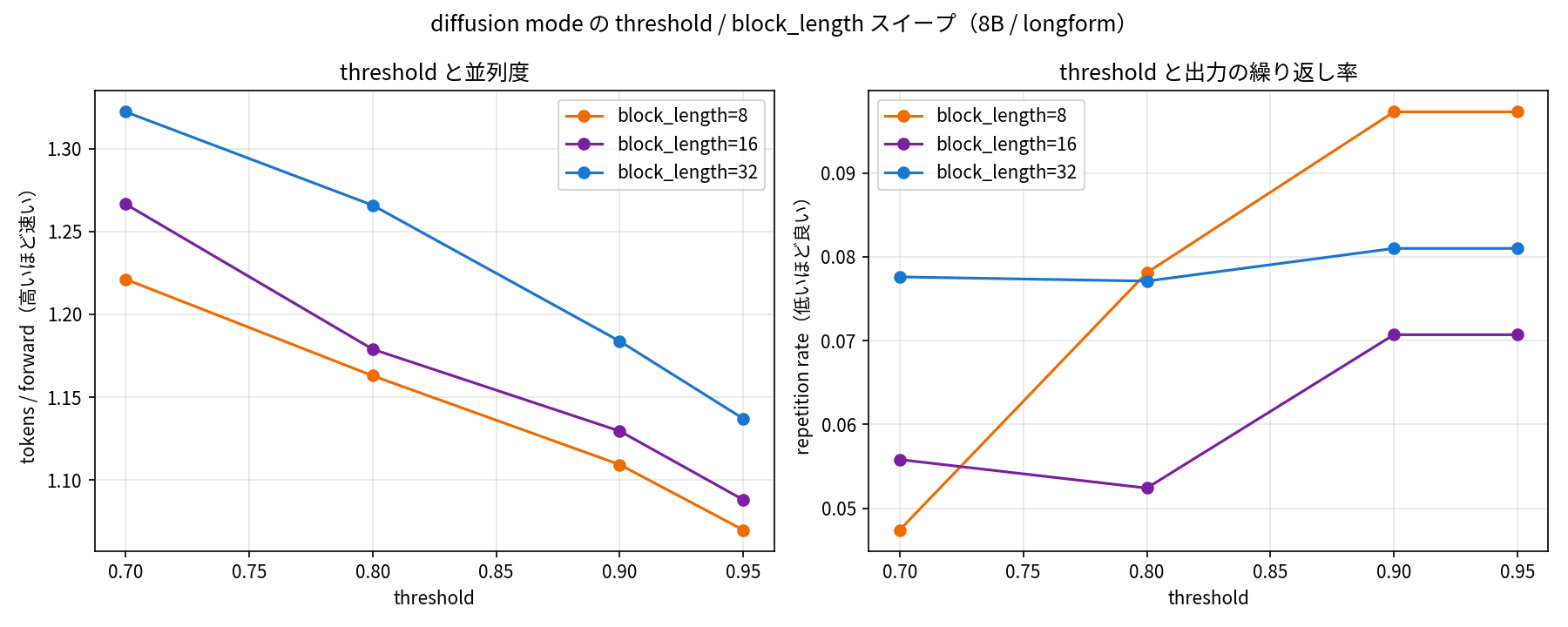
左が threshold と並列度(tokens per forward)、右が threshold と繰り返し率。threshold を下げると並列度が上がって速くなる。繰り返し率はむしろ低い threshold 側で小さい。
結果はシンプルでした。threshold を下げると一貫して速くなります。tokens per forward は block_length=32 で threshold を 0.95 から 0.70 に下げると 1.14 から 1.32 まで上がり、その分 forward の総数が減ります。
意外だったのは品質側です。threshold を下げると一気に確定する分だけ雑になり、繰り返しが増えるかと予想していたのですが、実機ではむしろ逆でした。繰り返し率は低い threshold 側のほうが小さく、threshold を 0.9 や 0.95 まで上げたほうがやや増える傾向すらありました。値そのものも 0.05〜0.10 と低く、文章として破綻するレベルではありません。
技術レポートは threshold を「速度とトークン誤り率のトレードオフを決めるノブ」と説明しています。ただ、少なくとも今回の longform 解説タスクを 8B の BF16 で動かした範囲では、threshold を高くする積極的な理由は見つかりませんでした。block_length を大きくすると threshold の影響そのものが薄れていく傾向もあり、実運用なら block_length をやや大きめに、threshold は低めから試すのが素直そうです。タスクやモデルサイズによって変わる部分なので、自分の用途で一度振ってみるのがよさそうですね。
DGX Spark で詰まりやすいポイント
検証中に一番手こずったのは、transformers 5.9 と同梱の custom modeling がかみ合わない問題です。Nemotron-Labs-Diffusion のモデルリポジトリには modeling_ministral.py という Python ファイルが同梱されていて、trust_remote_code=True でロードするとこれが実行されます。ところがこのファイルは、アテンションマスクを作る create_causal_mask() を少し古い引数名(input_embeds= や cache_position=)で呼んでいて、transformers 5.9.0 では引数名が変わっているため TypeError で止まります。拡散モードと Linear Self-Speculation モードがこの経路を通ります(AR モードは別経路なので影響を受けませんでした)。
Hugging Face のキャッシュにあるファイルを直接書き換えるのは、ライブラリ側の管理対象を勝手にいじることになるので避けたいところです。今回は、自分のスクリプト側で transformers.masking_utils のマスク生成関数を薄くラップし、古い引数名を吸収する shim を用意しました。from_pretrained() で custom modeling が読み込まれる前にこのラップを適用しておけば、依存コードもキャッシュも触らずに動きます。
def apply_transformers_compat() -> None:
import transformers.masking_utils as mu
def _wrap(fn):
def wrapped(*args, **kwargs):
if "input_embeds" in kwargs and "inputs_embeds" not in kwargs:
kwargs["inputs_embeds"] = kwargs.pop("input_embeds")
kwargs.pop("cache_position", None)
return fn(*args, **kwargs)
return wrapped
for name in ("create_causal_mask", "create_sliding_window_causal_mask"):
setattr(mu, name, _wrap(getattr(mu, name)))
リリース直後のモデルを最新の transformers で動かすと、この手のバージョン差はわりとよく踏みます。custom modeling 側が更新されれば不要になる類のものなので、shim は一時的な回避策と割り切って、依存コードには手を入れず自分のスクリプト内で完結させておくのが落ち着きます。
ちなみに、モデルカードには context length の記載がありませんが、config.json を見ると max_position_embeddings が 262144(256K)でした。手元で長文を流し込む前提を立てるときの参考になります。
まとめ
Nemotron-Labs-Diffusion の 8B を DGX Spark で動かして、tri-mode を実測してみました。分かったことを整理します。
- AR / Diffusion / Linear Self-Speculation の 3 モードは、DGX Spark の BF16 環境でどれも動いた(transformers 5.9 では shim を 1 つ挟む必要あり)
- 速度は Linear Self-Speculation が AR 比 1.75 倍、LoRA つきで 1.98 倍。拡散がドラフトを並列生成し自己回帰が検証する自己投機が、素の構成で一番効いた
- 拡散モードは確信度の高い位置から埋めていく。確定そのものは不可逆で、自己回帰との違いは「修正」よりも「並列性と確定順序」にある
- threshold を下げると速くなり、繰り返し率もむしろ下がる。今回のタスクでは threshold を高くする理由は見えなかった
- 公式が掲げる「6× tokens per forward」「INT4 で AR 比 2.7 倍」は量子化やランタイムを含む数字で、量子化なしの BF16 longform では tokens per forward 1.2〜2.1、speedup 2 倍弱だった
拡散言語モデルは、ドラフトモデルを別に持たなくても自己投機で素直に速くなる、という方向性がはっきり見えるモデルでした。DGX Spark のような単一ノードでローカルに動かす環境とも相性がよさそうです。量子化版や VLM 版、より長い文脈での挙動など、まだ試せていないところも多いので、続きはまた別の記事にできればと思っています。
参考リンク
Nemotron-Labs-Diffusion の技術レポートと公開リソースです。
speculative decoding を DGX Spark で実測した関連記事です。








