
I tried NVIDIA Nemotron 3 Ultra
This page has been translated by machine translation. View original
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
The Nemotron 3 family from NVIDIA has gained its top-tier member, Ultra. At a size of 550B, it was released on June 4, 2026.
Up until now, I've been working through the Nemotron series on DGX Spark, starting from the smaller models. I was able to run locally everything from the small model I tried Japanese fine-tuning on up to the 120B-class Super, but this time Ultra is a completely different scale. Naturally, even just the weights don't fit in the DGX Spark's 128GB...
Nemotron 3 is publicly available through NVIDIA's own free API, so even models you can't run locally can be called through a browser. In this article, I'll confirm what kind of environment Ultra requires, verify it using that free API, and finally organize "which one to use and how" including Nano and Super.
What kind of model is Nemotron 3 Ultra
It's a MoE with 550B total parameters and 55B active per token. The architecture is called LatentMoE, a hybrid configuration combining Mamba-2, Transformer, and MoE.
What NVIDIA is aiming for with this model is long-running agents. Their technical blog described it as "single-turn chatbots evolving into long-running agents." An agent makes plans, calls tools, spawns sub-agents, and continuously feeds that history and reasoning back into the model. The longer the task, the more tokens swell from this back-and-forth, and the greater the drift between cost and goal. Ultra felt designed to overcome that with efficiency. NVIDIA's intended use cases are also agents that run for hours — complex coding, long-duration research, and automation of internal workflows.
The division of roles in the hybrid architecture was personally the interesting part. Mamba layers efficiently handle long contexts, while Transformer layers take on the role of "accurately recalling specific facts from within a large context." Additionally, MTP (Multi-Token Prediction) predicts multiple tokens at once to increase throughput for long outputs. Combined with NVFP4 quantization, inference throughput is said to be up to 5x faster and operational costs when running agents up to 30% lower compared to other open models of the same class. It's efficiency that pays off the longer you run.
One important note here. Ultra is text-only. Since Nano Omni in the same family is multimodal, you might assume images are supported, but Ultra accepts neither images nor audio. The highlights are the 1M token long context and reasoning capability. The license is OpenMDW 1.1, and commercial use is permitted.
In official benchmarks, the numbers include 91% on PinchBench measuring agent productivity, 82% on IFBench for instruction following, and 95% on Ruler's 1M context. The fact that even with NVFP4 the degradation from BF16 is at most 2-3 points, and in some cases it actually exceeds BF16, is reassuring for those of us planning to use the quantized version as our baseline.
Specs required to run Ultra
With 550B parameters, you can probably imagine it won't fit on DGX Spark, so let's look at what kind of environment is actually assumed.
Even with NVFP4 quantization, the weight size is approximately 335GB. The minimum configuration NVIDIA lists is 4x B200 in a single node, or 8x H100 80GB. With GB200 or GB300, it starts from 4 cards. That's over 600GB of VRAM, so this is a model that assumes data center-class GPUs. The weights alone are 2.6x the DGX Spark's 128GB, so they're simply in a different league.
| Model | Size | Running requirement |
|---|---|---|
| Nemotron 3 Nano | 30B-A3B | Easily on DGX Spark |
| Nemotron 3 Super | 120B-A12B | Ceiling of DGX Spark (official deployment guide exists) |
| Nemotron 3 Ultra | 550B-A55B | 4×B200 or similar, servers with 600GB+ VRAM |
DGX Spark can run up to Super class. Ultra is a step above that, requiring a multi-GPU server to run.
However, this barrier is also the flip side of Ultra's unique appeal. Ultra has all its weights, training data, and recipes publicly available, so as long as you can prepare a server of this class, you can run a 550B frontier model entirely in your own environment. You can use it freely without worrying about per-token metering, and additional training and customization on internal data is unrestricted. While cloud APIs are convenient, data you input is passed to external parties. On the other hand, if you can operate it confined within your own or your country's data centers, even fields where confidential information cannot go outside — manufacturing, healthcare, government — can use a top-tier model with confidence. Running it while keeping data under your own control — what's called Sovereign AI. I've been writing about a size that can't be run locally, but flipped around, it means that once you have the hardware, you can keep it in your own hands, and I think that's quite significant.
So where do you run it
If local is out of the question, you have no choice but to borrow somewhere that someone else is running it. Nemotron 3 Ultra was made available through quite a wide array of channels simultaneously with its release.
| Channel | Cost | Notes |
|---|---|---|
| build.nvidia.com API | Free (rate limits only) | OpenAI compatible. Used here |
| Nous Portal (Hermes Agent) | Free for 2 weeks (6/4–6/18) | Nebius partnership. Just select nvidia/nemotron-3-ultra:free |
| NVIDIA NIM container | NVIDIA AI Enterprise (90-day free evaluation) | Deploy to your own environment |
| OpenRouter | Free tier available | Provider-dependent |
| Together AI | $0.60 input / $3.60 output per 1M tokens | OpenAI compatible |
| Various cloud providers | Each provider's pricing | NVIDIA mentions SageMaker JumpStart, Google Cloud, and Microsoft Foundry |
In NVIDIA's technical blog, cloud providers including SageMaker JumpStart, Google Cloud, Microsoft Foundry, and Oracle Cloud were mentioned as distribution channels. However, I couldn't track down individual Ultra pages in each provider's catalog myself, so here I'll use the most accessible option: the free API at build.nvidia.com.
There's one more interesting channel for agent use cases. Nous Research, the developer of Hermes Agent, has joined NVIDIA's Nemotron Coalition and partnered with Nebius to open up Nemotron 3 Ultra for free on Nous Portal for 2 weeks (June 4–18). With Hermes Agent, whether on Desktop or CLI, you can call it just by selecting nvidia/nemotron-3-ultra:free as the model. I previously wrote an article about running Hermes Agent on DGX Spark's OpenShell with NemoHermes, and now you can run 550B directly from Hermes. Being able to immediately try Ultra, designed for long-running agents, from an agent execution platform seems like a natural fit.
Trying it out with the free API at build.nvidia.com
The API is OpenAI compatible, so you can call it just by replacing the base URL and model ID with the openai client.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=os.environ["NVIDIA_API_KEY"],
)
resp = client.chat.completions.create(
model="nvidia/nemotron-3-ultra-550b-a55b",
messages=[{"role": "user", "content": "あなたのモデル名と開発元を1文で答えてください。"}],
max_tokens=256,
temperature=0.2,
extra_body={"chat_template_kwargs": {"enable_thinking": False}},
)
print(resp.choices[0].message.content)
This returns "I am Nemotron 3 Ultra, a language model developed by NVIDIA researchers." The response took less than a second. A 550B model, callable from my own MacBook in just a few lines.
The interesting part is the behavior in reasoning mode. When you set enable_thinking to True, the thinking content is returned separately in a field called reasoning_content. For example, when I posed the classic question "Lotus leaves double every day and cover a pond on day 48. On which day is it half covered?", the reasoning_content field contained this:
If it doubles every day, then one day prior to being full,
it must have been half full. So, Day 47.
And the response body returned "Day 47" in Japanese. In this case, it processed its thinking in English and switched to Japanese only for the final answer. A very fitting behavior for a multilingual model.
Comparing Nano, Super, and Ultra on the same playing field
Since I can call Nano (30B-A3B) and Super (120B-A12B) through the same API, I lined up all three generations on Japanese reasoning problems. I started with 8 basic problems involving inclusion-exclusion principle and crane-and-tortoise problems, but all 3 models solved them without difficulty, showing no differentiation at all.
So I remeasured with 8 somewhat more challenging problems — inclusion-exclusion with larger numbers, combinations, and counting perfect squares and perfect cubes. Here are the results.
| Model | Correct (8 hard problems) | Average latency |
|---|---|---|
| Nemotron 3 Nano (30B-A3B) | 7/8 | ~4 seconds |
| Nemotron 3 Super (120B-A12B) | 7/8 | ~16 seconds |
| Nemotron 3 Ultra (550B-A55B) | 7/8 | ~17 seconds |
The one question dropped was one where my own phrasing of "how many common solutions are there" could also be read as "the number of solutions," and all 3 models answered in the same way. Effectively, it was a perfect score across the board.
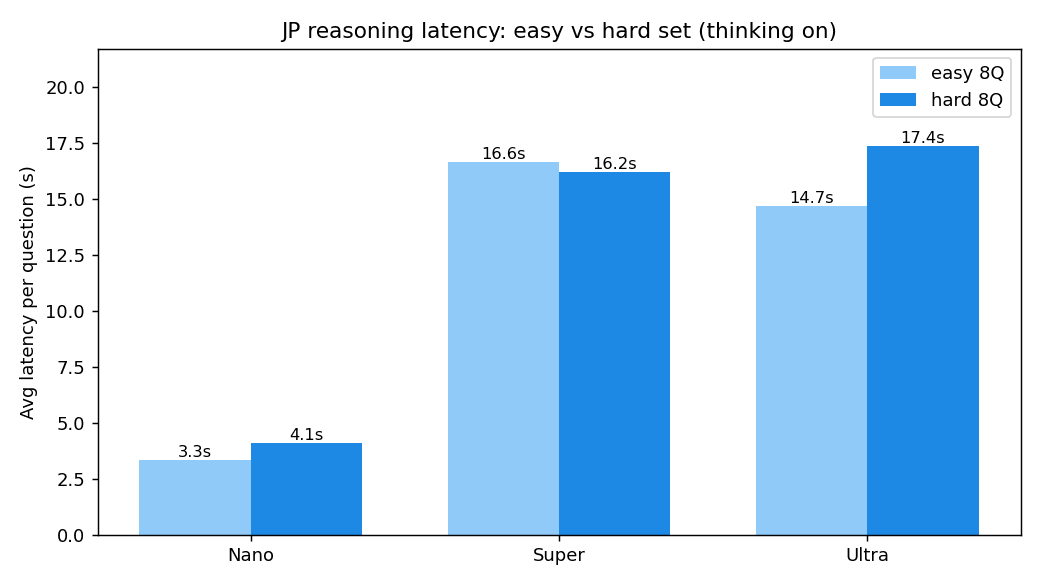
Average latency per question for the easy 8 and hard 8 question sets. In both sets, Nano was fastest, with time increasing as model size grows.
Ultra's true strength is long context
Its true strength lies in long context. I ran needle-in-haystack tests by embedding a single passphrase somewhere in a long Japanese text and asking for it at the end, varying the position of the passphrase (beginning, middle, end) and the text length (approximately 6,000 to 600,000 tokens).
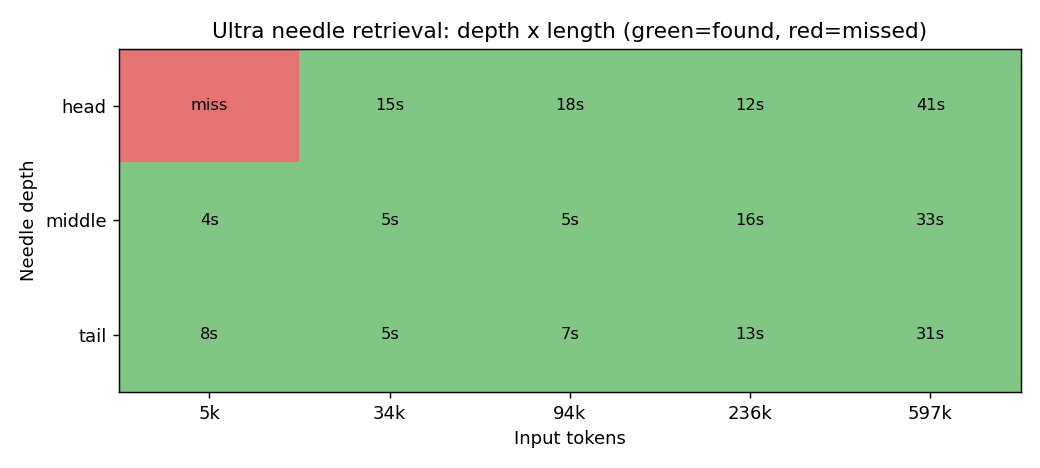
Results of testing whether the passphrase could be retrieved at the beginning, middle, and end positions across 5 different lengths. Green indicates success, and the number in each cell is the response time in seconds.
The result was success in 14 out of 15 cells. Even in long text of about 600,000 tokens, it accurately extracts the passphrase in about 35 seconds regardless of whether it's at the beginning, middle, or end. The one miss — "near the beginning × approximately 6,000 tokens" — was consistently retrieved when retested, so it was just noise. When I pushed further to aim for exactly 1M, I got an upper limit error, confirming that inputs can use up to approximately 1 million tokens. While many hosts cap the default at 256K, the API catalog version allows the full 1M from the start.
On the quality side, NVIDIA has published their own data. On the 1M version of Ruler, which tests extracting target information from long texts, Ultra scores 95%. This aligns with my hands-on experience of straightforward retrieval up to 600,000 tokens, and that capacity and stable extraction should prove valuable for agents running with histories of hundreds of thousands of tokens. Score details are in the technical blog linked at the beginning of the article.
What is Ultra designed for
After working with it this far, what I sensed is that Ultra is not "a bigger version of Nano or Super" — its positioning is fundamentally different. Nano and Super are everyday models that run locally on DGX Spark, and as we saw this time, even 30B-class handles basic Japanese reasoning just fine. The everyday intelligence level is already sufficient with small models.
What Ultra takes on is beyond that. At 550B, it doesn't fit locally and assumes data center-class GPUs. Its aim is placed on autonomous agents that handle complex coding, long-duration research, and automation of internal workflows while running continuously for hours. Carrying long context and chains of tool calls, running to completion without losing sight of the goal. That's the playing field it's designed for.
Viewed from this positioning, the numbers from the verification make sense. The 1M long context showed the capability to retrieve a passphrase from 600,000 tokens away, whether at the beginning or the end. Inference is said to be up to 5x faster and agent operational costs up to 30% lower compared to other open models of the same class. That efficiency that pays off the longer you run is designed for long-running agents where tokens balloon. Furthermore, since weights, data, and recipes are all publicly available, as long as you have the hardware, you can run it confined within your own data center. No concern about token billing, no confidential data going outside, keeping the top-tier class under your own control. That's Ultra's strength.
Summary
Having worked through the Nemotron 3 series from Nano on DGX Spark, Ultra pushed me past the local ceiling. What I learned is that Ultra is not "the biggest model that can't run locally" — it's "a model for running long-duration autonomous agents continuously, faster, cheaper, and under your own control." Now that small models are sufficient for basic intelligence, Ultra's role is to withstand token explosion and keep running without stopping. Even if you can't run it locally, you can try it immediately through the free API. If you're interested, start by accessing 550B from build.nvidia.com.
Reference Links
- Nemotron 3 Ultra model card (Hugging Face): https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4
- NVIDIA technical blog: https://developer.nvidia.com/blog/nvidia-nemotron-3-ultra-powers-faster-more-efficient-reasoning-for-long-running-agents/
- Ultra page on build.nvidia.com: https://build.nvidia.com/nvidia/nemotron-3-ultra-550b-a55b
- Nemotron 3 Super DGX Spark deployment guide: https://docs.nvidia.com/nemotron/nightly/usage-cookbook/Nemotron-3-Super/SparkDeploymentGuide/README.html
