
NVIDIA Nemotron 3 Ultra を試してみた
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
NVIDIA の Nemotron 3 ファミリーに、最上位の Ultra が加わりました。550B というサイズで、2026 年 6 月 4 日に公開されています。
これまで、Nemotron シリーズを DGX Spark で小型のものから順に触ってきました。日本語ファインチューニングを試した小型モデルや、120B クラスの Super まではローカルで動かせたのですが、今回の Ultra はさすがにサイズが違います。当たり前ですが DGX Spark の 128GB には重みすら載りません。。。
Nemotron 3 は NVIDIA 自身が無料の API で公開していて、ローカルで動かせないモデルもブラウザ越しに叩けます。この記事では、Ultra にどれくらいの環境が要るのかを確認したうえで、その無料 API で実際に検証し、最後に Nano と Super も含めて「どれをどう使い分けるか」を整理してみます。
Nemotron 3 Ultra はどんなモデルか
総パラメータ 550B、トークンあたりの稼働は 55B の MoE です。アーキテクチャは LatentMoE と呼ばれていて、Mamba-2 と Transformer、それに MoE を組み合わせたハイブリッド構成になっています。
NVIDIA がこのモデルで狙っているのは、long-running agent です。技術ブログでは「シングルターンのチャットボットが long-running agent へ進化している」と表現していました。エージェントが計画を立て、ツールを呼び、サブエージェントを起動し、その履歴と推論を延々とモデルに戻し続ける。タスクが長くなるほど、このやり取りでトークンが膨らみ、コストとゴールのずれが増えていきます。Ultra はそこを効率で押し切る設計に感じました。NVIDIA が想定する使いどころも、複雑なコーディングや長時間のリサーチ、社内ワークフローの自動化といった、何時間も走り続けるエージェントです。
ハイブリッド構成の役割分担が、個人的には面白いところでした。Mamba 層が長いコンテキストを効率よくさばき、Transformer 層が「大きな文脈の中から特定の事実を正確に思い出す」役を担う、という分け方です。さらに MTP(Multi-Token Prediction)で複数トークンを一度に予測し、長い出力のスループットを上げています。NVFP4 量子化と合わせて、同クラスの他のオープンモデルと比べて推論スループットが最大 5 倍、エージェントを走らせたときの運用コストも最大 30% 下がるとしています。長く回すほど効いてくる効率ですね。
ここで一点注意があります。Ultra はテキスト専用です。同じファミリーの Nano Omni がマルチモーダルだったので画像も入ると思いがちですが、Ultra に画像や音声は入りません。見どころは 1M トークンのロングコンテキストと推論力のほうです。ライセンスは OpenMDW 1.1 で、商用利用も認められています。
公式ベンチマークでは、エージェント生産性を測る PinchBench で 91%、指示追従の IFBench で 82%、Ruler の 1M コンテキストで 95% といった数字が並びます。NVFP4 にしても BF16 から多くて 2〜3 ポイントの劣化で収まっていて、項目によってはむしろ上回るのも、量子化版を 提に使う側としては安心材料ですね。
Ultra を動かすのに必要なスペック
550B ともなると DGX Spark に載らないのは想像がつくと思うので、ここでは本来どれくらいの環境を想定しているのかを見ておきます。
NVFP4 量子化済みでも、重みのサイズはおよそ 335GB あります。NVIDIA が最小構成として挙げているのは、単一ノードで B200 が 4 枚、あるいは H100 80GB が 8 枚。GB200 や GB300 なら 4 枚からです。VRAM にして 600GB を超えるので、データセンター級の GPU を前提にしたモデルですね。DGX Spark の 128GB に対して重みだけで 2.6 倍あるので、そもそも土俵が違います。
| モデル | サイズ | 動かす目安 |
|---|---|---|
| Nemotron 3 Nano | 30B-A3B | DGX Spark で余裕 |
| Nemotron 3 Super | 120B-A12B | DGX Spark の天井(公式デプロイガイドあり) |
| Nemotron 3 Ultra | 550B-A55B | 4×B200 など、VRAM 600GB 超のサーバー |
DGX Spark で回せるのは Super クラスまで。Ultra はその一段上で、動かすなら複数 GPU のサーバーが要ります。
ただ、これはハードルであると同時に、Ultra ならではの魅力の裏返しでもあります。Ultra は重みも学習データもレシピもすべて公開されていて、このクラスのサーバーさえ用意できれば、550B のフロンティアモデルを丸ごと自前の環境で動かせます。トークンごとの従量課金を気にせず使い倒せて、社内データでの追加学習やカスタマイズも自由です。クラウド API は手軽な代わりに、入力したデータは外部へ渡ります。一方で、自社や自国のデータセンターに閉じて運用できれば、機密を外へ出せない製造や医療、行政の現場でも、最高峰クラスのモデルを安心して使えるわけです。データを自分たちの管理下に置いたまま動かす、いわゆるソブリン AI ですね。手元では動かせないサイズ、と書いてきましたが、裏を返せば、ハードさえ揃えれば自分たちの手の内に置けるという意味でもあって、そこはかなり大きいと感じています。
では、どこで動かすか
ローカルが無理なら、誰かが動かしているところを借りるしかありません。Nemotron 3 Ultra は公開と同時に、かなり広いチャネルで提供されました。
| 経路 | コスト | メモ |
|---|---|---|
| build.nvidia.com の API | 無料(レート制限のみ) | OpenAI 互換。今回はここを使用 |
| Nous Portal(Hermes Agent) | 2 週間無料(6/4〜6/18) | Nebius 提携。nvidia/nemotron-3-ultra:free を選ぶだけ |
| NVIDIA NIM コンテナ | NVIDIA AI Enterprise(90 日無料評価) | 自前環境にデプロイ |
| OpenRouter | 無料枠あり | プロバイダ依存 |
| Together AI | 100 万トークンあたり入力 $0.60・出力 $3.60 | OpenAI 互換 |
| クラウド各社 | 各社の料金 | NVIDIA は SageMaker JumpStart や Google Cloud、Microsoft Foundry を挙げています |
NVIDIA の技術ブログでは、SageMaker JumpStart や Google Cloud、Microsoft Foundry、Oracle Cloud といったクラウドも提供先として名前が挙がっていました。ただ各社のカタログで Ultra 単独のページまでは自分では追いきれなかったので、ここでは一番手軽な build.nvidia.com の無料 API を使います。
もう一つ、エージェント用途で面白い経路があります。Hermes Agent の開発元である Nous Research が NVIDIA の Nemotron Coalition に加わり、Nebius と組んで Nous Portal で Nemotron 3 Ultra を 2 週間無料(6 月 4 日〜18 日)で開放しています。Hermes Agent なら Desktop でも CLI でも、モデルに nvidia/nemotron-3-ultra:free を選ぶだけで呼び出せます。以前 NemoHermes で Hermes Agent を DGX Spark の OpenShell に載せた記事 を書きましたが、Hermes からそのまま 550B を動かせるわけですね。long-running agent 向けに設計された Ultra を、エージェントの実行基盤からすぐ試せるのは相性が良さそうです。
build.nvidia.com の無料 API で叩いてみる
API は OpenAI 互換なので、openai のクライアントでベース URL とモデル ID を差し替えるだけで叩けます。
import os
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=os.environ["NVIDIA_API_KEY"],
)
resp = client.chat.completions.create(
model="nvidia/nemotron-3-ultra-550b-a55b",
messages=[{"role": "user", "content": "あなたのモデル名と開発元を1文で答えてください。"}],
max_tokens=256,
temperature=0.2,
extra_body={"chat_template_kwargs": {"enable_thinking": False}},
)
print(resp.choices[0].message.content)
これで「私は NVIDIA の研究者たちによって開発された言語モデル Nemotron 3 Ultra です」と返ってきます。レスポンスは 1 秒もかかりませんでした。550B のモデルを、自分の MacBook から数行で叩けてしまうわけです。
面白いのが推論モードの挙動です。enable_thinking を True にすると、思考の中身が reasoning_content という別フィールドに分かれて返ります。たとえば「蓮の葉が毎日 2 倍に増えて 48 日目に池を覆う。半分になるのは何日目か」という古典的な問いを投げると、reasoning_content のほうにはこう入っていました。
If it doubles every day, then one day prior to being full,
it must have been half full. So, Day 47.
そして本文には「47 日目」と日本語で返ってきます。このときは思考を英語で進めて、最終回答だけ日本語に切り替えていました。多言語モデルらしい挙動でいいですね。
Nano と Super と Ultra を同じ土俵で比べる
せっかく同じ API で Nano(30B-A3B)も Super(120B-A12B)も叩けるので、日本語の推論問題で 3 世代を横並びにしてみました。最初は包除原理や鶴亀算といった基礎的な 8 問から始めたのですが、3 モデルとも危なげなく解いてしまい、まったく差がつきませんでした。
そこで、桁の大きい包除原理や組み合わせ、平方数と立方数の数え上げなど、もう少し歯ごたえのある 8 問で測り直してみました。結果がこちらです。
| モデル | 正答(難問 8 問) | 平均レイテンシ |
|---|---|---|
| Nemotron 3 Nano(30B-A3B) | 7/8 | 約 4 秒 |
| Nemotron 3 Super(120B-A12B) | 7/8 | 約 16 秒 |
| Nemotron 3 Ultra(550B-A55B) | 7/8 | 約 17 秒 |
落とした 1 問は「共通する解はいくつですか」という自分の設問が「解の個数」とも読めるもので、3 モデルとも同じ答え方をしただけでした。実質は横並びの満点です。
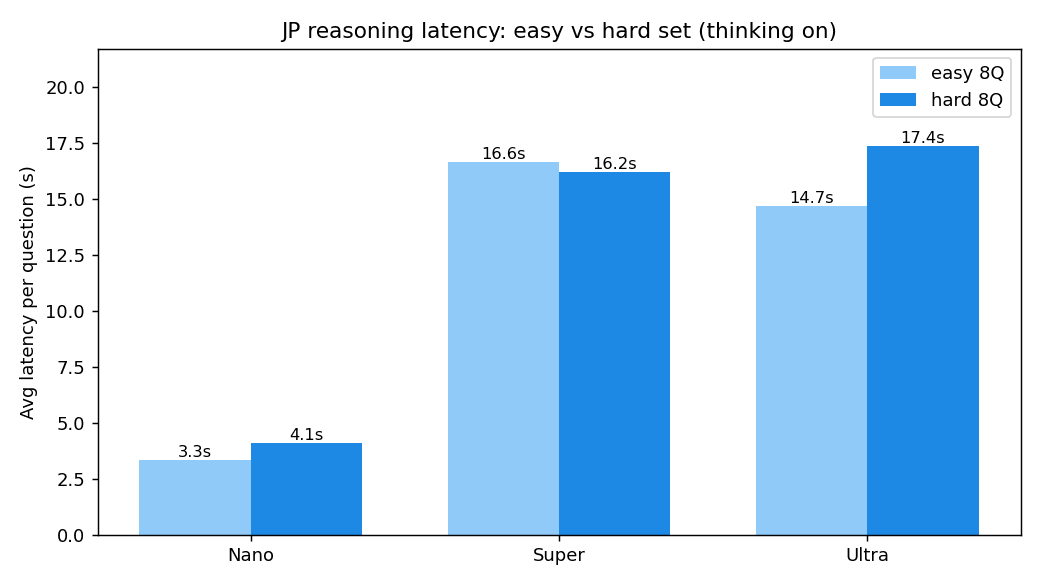
易しい 8 問と難しい 8 問の 1 問あたり平均レイテンシ。どちらのセットでも Nano が最も速く、サイズが上がるほど時間がかかる。
Ultra の本領はロングコンテキスト
本領はロングコンテキストのほうにあります。長い日本語テキストのどこかに合言葉を 1 つだけ埋め込み、末尾でそれを尋ねる needle-in-haystack を、合言葉の位置(先頭・中央・末尾)と文章の長さ(約 6 千〜60 万トークン)を変えながら試しました。
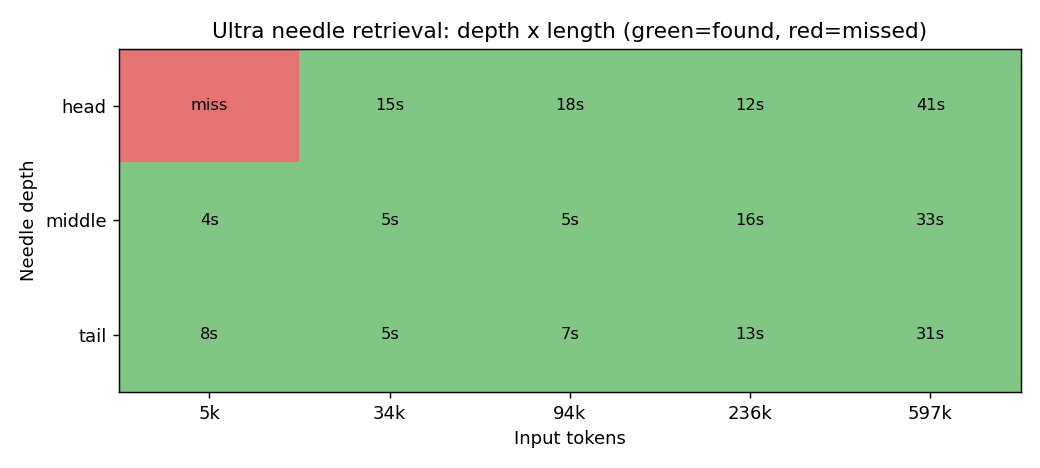
合言葉を先頭・中央・末尾に置き、5 つの長さで拾えるかを試した結果。緑が成功で、セルの数字は応答までの秒数。
結果は 15 マス中 14 マスで成功でした。約 60 万トークンの長文でも、合言葉が先頭・中央・末尾のどこにあっても 35 秒ほどで正確に抜き出してきます。唯一外した「先頭寄り × 約 6 千トークン」も、測り直すと毎回拾えたので揺れですね。さらに長くして 1M ちょうどを狙うと上限エラーになり、入力で約 100 万トークンまで使えることも分かりました。デフォルトが 256K に絞られたホストも多いなか、API カタログ版は最初から 1M がフルに使えます。
品質面は NVIDIA 自身が公開しています。長文から目的の情報を引き出す Ruler の 1M 版で、Ultra は 95% というスコアです。手元で 60 万トークンまで素直に拾えた体感とも合っていて、数十万トークンの履歴を抱えて走り続けるエージェントには、この容量と安定した抽出が効いてきそうです。スコアの詳細は記事冒頭の技術ブログに載っています。
Ultra は何のためのモデルか
ここまで触って感じたのは、Ultra は Nano や Super の「もっと大きい版」ではなく、立ち位置がそもそも違うということです。Nano や Super は DGX Spark に載せて手元で回す日常のモデルで、日本語の基礎的な推論なら今回見たとおり 30B クラスでも十分こなせます。普段使いの賢さは、もう小型でも足りる時代ですね。
Ultra が引き受けるのは、その先です。ローカルには載らず、データセンター級の GPU を前提にした 550B。狙いは、複雑なコーディングや長時間のリサーチ、社内ワークフローの自動化を、何時間も止まらず走り続ける自律エージェントに置かれています。長い文脈とツール呼び出しの連鎖を抱えたまま、ゴールを見失わずに走り切る。そのための土俵です。
この立ち位置で見ると、検証で出た数字が腑に落ちます。1M のロングコンテキストは、合言葉を先頭でも末尾でも 60 万トークンの彼方から拾える実力でした。同クラスの他のオープンモデルより推論は最大 5 倍速く、エージェントの運用コストは最大 30% 下がるとされています。長く回すほど効く効率は、トークンが膨れ上がる long-running agent のためのものですね。さらに重み・データ・レシピまで公開されているので、ハードさえあれば自社のデータセンターに閉じて動かせます。トークン課金を気にせず、機密も外に出さず、最高峰クラスを自分たちの管理下に置ける。これが Ultra の強みです。
まとめ
Nemotron 3 を Nano から順に DGX Spark で触ってきて、Ultra でローカルの天井を超えました。分かったのは、Ultra は「手元で動かせない一番大きいモデル」ではなく、「長時間の自律エージェントを、速く・安く・自社の管理下で走らせ続けるためのモデル」だということです。基礎的な賢さが小型でも足りるいま、Ultra が担うのはトークン爆発に耐えて止まらず走り続ける役どころですね。手元で動かせなくても、無料 API ですぐ試せます。気になった方は、まず build.nvidia.com から 550B に触れてみてください。
参考リンク
- Nemotron 3 Ultra モデルカード(Hugging Face): https://huggingface.co/nvidia/NVIDIA-Nemotron-3-Ultra-550B-A55B-NVFP4
- NVIDIA 技術ブログ: https://developer.nvidia.com/blog/nvidia-nemotron-3-ultra-powers-faster-more-efficient-reasoning-for-long-running-agents/
- build.nvidia.com の Ultra ページ: https://build.nvidia.com/nvidia/nemotron-3-ultra-550b-a55b
- Nemotron 3 Super の DGX Spark デプロイガイド: https://docs.nvidia.com/nemotron/nightly/usage-cookbook/Nemotron-3-Super/SparkDeploymentGuide/README.html








