
NemoHermes で Hermes Agent を DGX Spark の OpenShell に載せてみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
先日の GTC Taipei で、NVIDIA はエンタープライズ向けに自律 AI エージェントを構築・運用するための Agent Toolkit を打ち出しました。基調講演で示された構成図では、エージェントのオーケストレーションを担う NemoClaw を中心に、その土台となるセキュアランタイムの OpenShell、ツールやスキルを提供する CUDA-X ライブラリ、そして Nemotron のオープンモデル群が、一枚の図としてまとめられていました。
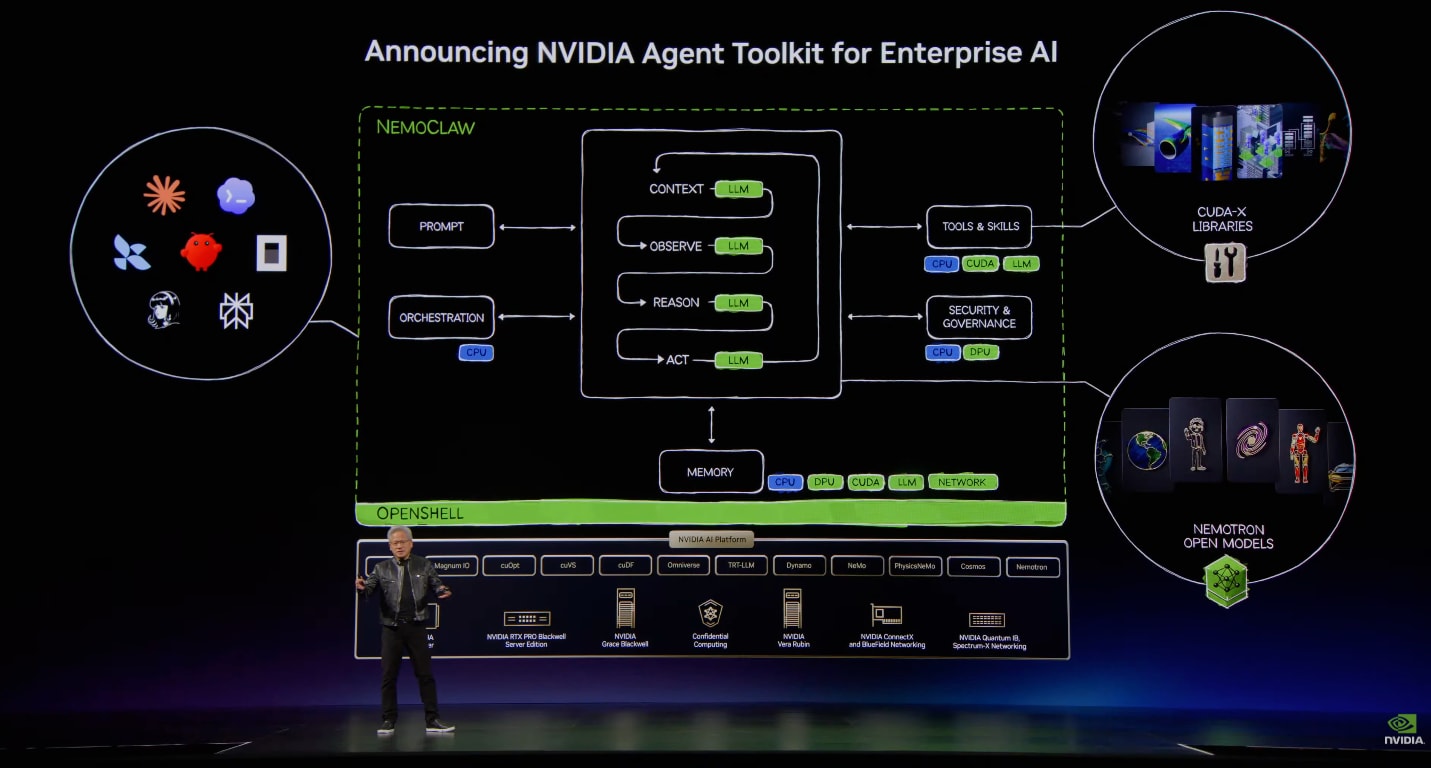
GTC Taipei 基調講演で示された NVIDIA Agent Toolkit の構成図
OpenClaw をはじめとするエージェントハーネスは、登場時の熱狂が少し落ち着いて、腰を据えて運用する安定期に入ってきた感があります。派手な新機能の競争から、長時間・高い権限で動くエージェントをいかに安全に動かすか、という地に足のついた関心に重心が移ってきた印象です。そんなタイミングで効いてくるのが、この NemoClaw と OpenShell です。今回はその実行基盤を、Hermes Agent を題材に手を動かしながら解剖していきます。Hermes はあくまで一例で、NemoClaw は OpenClaw など別のエージェントにも載せ替えられます。主役は「エージェントをどう包み、どう安全に走らせるか」のほうで、あえて NemoClaw / OpenShell を選ぶ人の判断材料になればと思っています。
NemoClaw / OpenShell と Hermes Agent の関係
OpenShell は、エージェントを安全に動かすためのセキュアランタイムです。sandbox による OS レベルの隔離、ファイルシステムやネットワークのポリシー適用、推論ルートの管理などを担当します。NemoClaw は、その OpenShell を使ってエージェントの導入・ポリシー・推論プロバイダー・メッセージング連携などをまとめて構成するレイヤーです。
そして Hermes Agent は、その sandbox の中で動かすエージェントハーネスの一つです。NemoClaw はデフォルトの OpenClaw のほか Hermes も選べて、エージェントに Hermes を選んだ構成が NemoHermes にあたります(nemohermes は「Hermes をあらかじめ選択した状態の nemoclaw」のエイリアス)。どのエージェントを載せても、外側の OpenShell と NemoClaw の仕組みは共通です。ここが「エージェント非依存の実行基盤」という今回の見どころになります。
Hermes を選ぶと、設定が /sandbox/.hermes 配下に書かれ、モデルの通信が inference.local 経由でルーティングされ、sandbox 内で Hermes のゲートウェイが起動して、ホストからはポート 8642 で OpenAI 互換 API にアクセスできるようになります。
なぜ OpenShell で包むのか
エージェントが強力になるほど、コードを書いたり、サブエージェントを生成したり、ローカルファイルにアクセスしたり、ツールを実行したりと、できることが増えていきます。Hermes もツール・スキル・メモリといった機能を持つので、まさにこの「強力なエージェント」に当てはまります。
便利な反面、ローカルファイルへのアクセスやネットワークの外向き通信、認証情報の扱いは慎重に管理したいところです。OpenShell は、こうしたエージェントの実行環境にファイルシステム・ネットワーク・プロセス・推論ルートのポリシーをかけて、エージェントを sandbox の内側に収めてくれます。GTC Taipei の基調講演でも、OpenShell サンドボックスの上でハーネスがモデルに接続するデモが示されていました。
検証環境
| 項目 | 値 |
|---|---|
| ハードウェア | NVIDIA DGX Spark(GB10) |
| メモリ | 128GB ユニファイドメモリ |
| OS | Ubuntu 24.04 LTS |
| Docker | 29.2.1 |
| OpenShell | 0.0.44 |
| Agent | Hermes Agent v2026.5.16 |
| 推論 | ローカル Ollama 経由 qwen3.6:35b(NemoClaw が自動構成) |
NemoHermes をインストールする
エージェントに Hermes を選ぶには、NEMOCLAW_AGENT=hermes を設定してからインストーラーを実行します。
export NEMOCLAW_AGENT=hermes
curl -fsSL https://www.nvidia.com/nemoclaw.sh | bash
この nemoclaw.sh は 160 行ほどの薄いブートストラップです。中身を読むと、GitHub の NVIDIA/NemoClaw を指定リリース(デフォルトは latest)で clone し、ダウンロードした本体をハッシュ検証してから scripts/install.sh を実行する作りになっていました。curl ... | bash という見た目ほど不透明ではなく、実体は GitHub 上の OSS です。
インストーラーはまず、サードパーティソフトウェアの取り扱いに関する同意を求めてきます。yes で進めると、ホストが DGX Spark であることを検出して、こんなメッセージが出ました。
[INFO] Detected DGX Spark.
Express install will configure managed local Ollama with model qwen3.6:35b.
It runs onboarding non-interactively, but still prompts for sudo when host setup needs it.
DGX Spark を検出すると Express install という非対話モードに入り、推論プロバイダーとして managed local Ollama を自動構成し、qwen3.6:35b を自動的に pull してくれます。
NEMOCLAW_NO_EXPRESS=1 を付けて実行すると Express install をスキップして対話モードになり、推論プロバイダーを自分で選べます。すでに立てている vLLM を使いたいなら、export NEMOCLAW_NO_EXPRESS=1 も加えてから実行します。
その後は 8 ステップの onboarding が非対話で流れていきます。途中、NVIDIA の CDI(Container Device Interface)デバイス仕様を生成するために sudo パスワードを求められます。これは OpenShell ゲートウェイが GPU を使えるようにするための設定で、Docker から nvidia.com/gpu デバイスを要求できるようにするものです。
[1/8] Preflight checks
✓ openshell CLI: openshell 0.0.44
✓ NVIDIA GPU detected (NVIDIA GB10, 124610 MB)
✓ Docker CDI GPU support detected (/var/run/cdi/nvidia.yaml)
[2/8] Starting OpenShell gateway … ✓ healthy
[3/8] Configuring inference provider … install-ollama / qwen3.6:35b (22.29 GB)
[4/8] Setting up inference provider … Route: inference.local / ollama-local
[5/8] Messaging channels … slack を検出
[6/8] Creating sandbox … build 174.1s
[7/8] Setting up Hermes Agent … ✓ gateway healthy
[8/8] Policy presets … balanced(npm/pypi/huggingface/brew/local-inference/slack)
sandbox イメージのビルドは 47 ステップで約 174 秒、全体では約 11 分(675 秒)で完了しました。初回はベースイメージの取得とビルドが入るので、それなりに待ち時間があります。完了すると ready の画面が出ます。
Hermes is ready
Sandbox: hermes
Model: qwen3.6:35b (Local Ollama)
Hermes Agent OpenAI-compatible API
Port 8642 must be forwarded before connecting.
http://127.0.0.1:8642/v1
Terminal:
nemohermes hermes connect
なお、自分の環境では SLACK_BOT_TOKEN がホストの環境変数に残っていたため、Express install がそれを検出して slack のポリシープリセットを自動で当てていました。意図しない連携が入らないよう、環境変数は事前に確認しておくとよいですね。
今回の Express install は、DGX Spark 向けに用意された非対話インストールでした。CI などでスクリプト化したい場合は、NEMOCLAW_NON_INTERACTIVE=1 や NEMOCLAW_SANDBOX_NAME、推論プロバイダー用の環境変数を明示的に渡す形でも実行できます。手元で挙動を固定したいときに便利そうです。
起動を確認する
ready になったので、まずヘルスチェックです。ポート 8642 は onboarding が自動でフォワードしてくれていました。
curl -sf http://127.0.0.1:8642/health
{ "status": "ok", "platform": "hermes-agent" }
nemoclaw list で sandbox の一覧を見ると、エージェントが Hermes になっていることが確認できます。sandbox を複数立てても、どれがどのエージェントかを名前で区別できるのはありがたいですね。
Sandboxes:
hermes *
agent: hermes model: qwen3.6:35b provider: ollama-local sandbox GPU
policies: slack, npm, pypi, huggingface, brew, local-inference
nemohermes hermes status では、推論バックエンド(Ollama)とその認証プロキシがどちらも healthy であること、sandbox が GPU を使えること、Hermes Agent のバージョンなどがまとめて見られます。
Sandbox: hermes
Model: qwen3.6:35b
Provider: ollama-local
Inference (ollama backend): healthy (http://127.0.0.1:11434/api/tags)
Inference (auth proxy): healthy (http://127.0.0.1:11435/api/tags)
Host GPU: yes
Sandbox GPU: enabled (auto)
OpenShell: 0.0.44 (docker)
Agent: Hermes Agent v2026.5.16
OpenAI 互換 API も叩いてみます。ローカルのフォワード経由なら認証なしで届きます。
curl -s http://127.0.0.1:8642/v1/models
{ "object": "list", "data": [{ "id": "hermes-agent", "object": "model", "owned_by": "hermes" }] }
公開されるモデル名は hermes-agent で、その裏で qwen3.6:35b にルーティングされます。実際にチャットを投げてみましょう。
curl -s http://127.0.0.1:8642/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"hermes-agent","messages":[{"role":"user","content":"あなたは何ですか?どこで動いていますか?2〜3文で。"}]}'
返ってきた応答がこちらです。
私はHermes Agent、Nous Researchによって開発されたAIアシスタントです。
現在はLinux環境のサンドボックス内(/sandbox上)で動作しており、
NemoClawによって管理されている環境で稼働しています。
Hermes が、自分は OpenShell sandbox の中で NemoClaw に管理されている、と正しく認識しているのが分かります。これは後で見る nemoclaw plugin が環境情報を渡しているためで、エージェントを sandbox に馴染ませる仕掛けが効いている一例です。対話的に使いたいときは nemohermes hermes connect で sandbox に入り hermes を起動します。
sandbox の中と GPU パススルー
sandbox の中身は openshell sandbox exec で覗けます。Hermes の設定ファイルを見てみます。
openshell sandbox exec -n hermes -- cat /sandbox/.hermes/config.yaml
model:
default: 'qwen3.6:35b'
provider: custom
base_url: 'https://inference.local/v1'
platform_toolsets:
api_server:
- web
- browser
- terminal
- file
- code_execution
- vision
- memory
- session_search
- delegation
- cronjob
platforms:
api_server:
enabled: true
extra:
port: 18642
host: 127.0.0.1
base_url が https://inference.local/v1 になっているのがポイントです。Hermes は sandbox の中からこの仮想的なエンドポイントに対してリクエストを投げ、OpenShell がそれをホスト側の推論バックエンド(今回は Ollama)へルーティングします。sandbox の中のエージェントは、実際のモデルがどこで動いているかを直接知らなくてよい構造になっています。
API のポートにも触れておくと、platforms.api_server の port: 18642 は sandbox 内部で待ち受けるポートで、これが onboarding のフォワードによってホスト側の 8642 番として見えています。先ほど curl で叩いた 127.0.0.1:8642 は、この内部の 18642 番につながっているわけですね。
ツールセットを見ると、ブラウザ操作・ターミナル・ファイル・コード実行・メモリ・サブエージェントへの委譲・cron など、エージェントとして一通りの機能が並んでいます。OpenShell で包む価値が出てくるのは、まさにこういう「何でもできる」エージェントを動かすときですね。
設定をもう少し見ると、plugins に nemoclaw が有効化されています。これは NemoClaw が Hermes に注入する専用プラグイン(バージョン 0.0.12、author は NVIDIA)で、hermes tools list にも 🔌 Nemoclaw として並びます。プラグインの定義を見ると、Hermes に公開しているツールは次の 3 つでした。
| ツール | 役割 |
|---|---|
nemoclaw_status |
sandbox の状態(モデル・プロバイダー・ヘルスなど)を収集して返す |
nemoclaw_info |
sandbox と NemoClaw 環境の情報を構造化 JSON で返す |
nemoclaw_reload_skills |
skill のキャッシュをクリアして再スキャンする(gateway の再起動なし) |
さらに、セッション開始時に走る on_session_start フックを持っていて、skill の自動再読み込みと、「自分は OpenShell sandbox の中で動いている」というランタイムコンテキストを Hermes のやり取りにそっと注入します。試しに Hermes へ「この環境で何ができる?」と聞くと nemoclaw_status や nemoclaw_info が呼ばれ、自分の置かれた状況を把握しにいきます。先ほど API 越しの応答で Hermes が自分の状況を言い当てたのは、このフックとツールのおかげですね。
公開ツールはこの 3 つですが、プラグインは内部でさらに、audio・browser・transcription・fal・firecrawl といった各種ツールを OpenShell の broker / プロキシ経由で動かすためのパッチも多数当てています。Hermes をそのまま走らせるのではなく、OpenShell sandbox の環境に馴染ませる接着剤の役割を担っているわけです。
逆に、スキルのほうは NemoClaw が手を加えていませんでした。sandbox に入っているスキル群(claude-code / llm-wiki / kanban-orchestrator など)は、Hermes Agent が標準で同梱しているものそのままです。NemoClaw のリポジトリを見てもユーザー sandbox 向けの独自スキルは見当たらず、NemoClaw が足しているのはスキルではなく、この nemoclaw プラグインと OpenShell のポリシーという形でした。エージェントの能力そのものは Hermes、それを安全に走らせる外側の枠が NemoClaw と OpenShell、と役割がきれいに分かれているのが見えてきます。
とはいえ、スキルを増やす道がないわけではありません。Hermes には標準で Skills Hub という仕組みがあり、hermes skills browse で一覧を眺めたり、hermes skills search <name> で検索したりできます。hermes skills search nvidia を引くと、GitHub の NVIDIA 公式 Skills Repo(NVIDIA/skills、説明は「AI agent skills published by NVIDIA」)が統合されているのが分かります。これは NVIDIA がプラットフォーム全体に向けて用意した検証済みスキルのカタログで、製品リポジトリから日次でミラーされ、コミュニティ投稿とは別物とされています。公開先は Hermes Skills Hub と Claude Code plugin marketplace の 2 か所とのこと。確認した時点で 130 以上のスキルがあり、領域はかなり広範です。
| 領域 | スキル例 | 用途 |
|---|---|---|
| cuOpt | cuopt-developer / cuopt-routing-api-python ほか |
組合せ最適化・配送ルーティング |
| cuDF / cuPyNumeric | accelerated-computing-cudf / cupynumeric-install |
GPU データ処理・移行 |
| CUDA-Q | cudaq-guide |
量子計算プログラミング |
| AI-Q | aiq-deploy / aiq-research |
エンタープライズ RAG・調査 |
| NeMo / Megatron Core | nemo-mbridge-perf-* / mcore-run-on-slurm ほか 30 種超 |
分散学習・推論最適化 |
| Nemotron | nemotron-speech / nemotron-customize |
音声・カスタマイズ |
| Omniverse | omniverse-usd-performance-tuning / omniverse-realtime-viewer |
USD・シーン・CAD 変換 |
| PhysicsNeMo / Physical AI | physicsnemo-discover / physical-ai-neural-reconstruction |
物理シミュレーション・世界モデル |
| DeepStream / VSS | deepstream-dev / vss-summarize-video ほか 15 種超 |
映像解析・検索・要約 |
| Holoscan / Dynamo / Earth2Studio | holoscan-setup / dynamo-router-starter / earth2studio-install |
エッジ・推論サービング・気象 |
| 医療(MONAI 系) | nv-segment-ct / dicom-series-to-volume ほか 15 種超 |
医用画像・臨床 ASR |
| 推論最適化 | tensorrt-llm |
TensorRT による最適化 |
CUDA-X 系から Omniverse、PhysicsNeMo、Megatron、DeepStream、VSS、さらには医療や気象まで、NVIDIA プラットフォームの使い方をエージェントに教えるスキルがそろっています。追加は hermes skills install NVIDIA/skills/skills/cudaq-guide のように識別子を指定し、hermes skills inspect <identifier> でプレビューもできます。NemoClaw が sandbox に焼き込むのはプラグインとポリシーまでで、スキルの拡張は Hermes 標準の Skills Hub に委ねる——その Skills Hub に NVIDIA 公式カタログが乗ってきた、という構図です。
他に気付いた点としては sandbox 内から GPU が使えるようになっていたことです。onboarding の最後に GPU パススルーの検証が走り、sandbox の中で nvidia-smi や CUDA の初期化が通ることが確認されています。
Verifying direct sandbox GPU access...
✓ GPU proof passed: nvidia-smi when available
✓ GPU proof passed: cuInit(0) via libcuda.so.1
OpenShell の隔離を確かめる
OpenShell のいちばんの売りはセキュリティ隔離なので、ネットワークの遮断を実際に確かめてみます。sandbox の中から、許可していないドメインへ接続を試みます。
openshell sandbox exec -n hermes -- \
curl -sS -m 8 -o /dev/null -w "code=%{http_code}\n" https://httpbin.org/get
curl: (56) CONNECT tunnel failed, response 403
きちんと弾かれました。sandbox の中のプロセスはすべて OpenShell の egress プロキシを経由するようになっていて(環境変数の https_proxy がプロキシを指していました)、onboarding で許可したドメイン以外への接続はプロキシが 403 で遮断します。エージェントが意図しない外部通信を行うリスクを、プロセスの外側から抑えてくれるわけですね。
OpenShell の隔離は層ごとに役割が分かれています。
| 層 | 保護対象 |
|---|---|
| ファイルシステム | 許可パス外の読み書きをブロック |
| ネットワーク | egress プロキシ経由で未許可の外部接続をブロック |
| プロセス | 権限昇格や危険な syscall をブロック |
| 推論 | モデル API 呼び出しを inference.local 経由の制御されたルートに限定 |
運用と、推論モデルの切り替え
sandbox の管理コマンドは一通りそろっています。
nemohermes hermes status
nemohermes hermes logs --follow
nemohermes hermes connect # sandbox に入って hermes CLI を対話的に使う
推論モデルやプロバイダーは、あとから差し替えられます。今回は Express install で Ollama になりましたが、たとえば自分で立てたローカルの vLLM や、クラウドの NVIDIA NIM に向け直すこともできます。
nemohermes inference set --model <model> --provider <provider> --sandbox hermes
このコマンドは OpenShell の推論ルートを更新し、sandbox 内の config.yaml の base_url などを書き換えてくれます。sandbox の作り直しや Hermes ゲートウェイの再起動は不要です。
ブラウザから使える Hermes の web ダッシュボードも用意されています。onboarding の前に NEMOCLAW_HERMES_DASHBOARD=1 を設定しておくと、ポート 9119 にダッシュボードが立ち上がります(NEMOCLAW_HERMES_DASHBOARD_PORT でポート変更、NEMOCLAW_HERMES_DASHBOARD_TUI=1 でブラウザ内 TUI タブも有効化できます)。今回の DGX Spark 向け Express install では立てていませんが、ローカルの管理 UI として使うものなので、共有・公開ネットワークに出すならアクセス制御を別途用意するのがよさそうです。
OpenShell を CLI で扱う(CLI コマンドと設定ファイル — クリックで展開)
ここまで nemohermes 経由で操作してきましたが、土台の OpenShell には独立した CLI があり、sandbox・推論ルート・ポリシー・ポート転送を直接さわれます。普段の運用で使いそうなものを挙げておきます。
推論ルートは openshell inference get で確認できます。
openshell inference get
Gateway inference:
Provider: ollama-local
Model: qwen3.6:35b
Timeout: 180s
別のプロバイダーやモデルに切り替えるなら openshell inference set です。--system を付けると、エージェントハーネス自身が使う system 用ルートをユーザー向けと分けて設定でき、--no-verify で起動前のエンドポイント検証を省けます。
openshell inference set --provider <provider> --model <model>
ポート転送は openshell forward で管理します。reboot やターミナル再起動で 8642 がつながらなくなったら、ここで張り直します。
openshell forward list
openshell forward start --background 8642 hermes
このほか、openshell settings get / set / delete でキー単位の設定を読み書きでき、openshell policy get -n hermes で現在のネットワーク・ファイルシステムポリシーを確認できます。プリセットの追加は nemohermes hermes policy-add <preset> です。
設定ファイルの所在も押さえておくと、挙動を追いやすくなります。
| 場所 | 内容 |
|---|---|
ホスト ~/.nemoclaw/sandboxes.json |
sandbox のメタ情報(名前・エージェント・モデルなど) |
ホスト ~/.nemoclaw/onboard-session.json |
onboarding セッションの状態 |
ホスト ~/.nemoclaw/source/ |
clone された NemoClaw 本体 |
sandbox /sandbox/.hermes/config.yaml |
Hermes 本体の設定(model / provider / toolsets / plugins) |
sandbox /sandbox/.hermes/.env |
Hermes の環境変数(認証情報など) |
推論ルートそのものは sandbox 内の config ではなく gateway 側が握っていて、inference set で更新すると /sandbox/.hermes/config.yaml の base_url などもあわせて書き換わる、という関係です。
ハマりどころ
DGX Spark で NemoHermes を動かすなかで気づいた点をまとめておきます。
最初の「事前に vLLM を立てておいたのに使われなかった」が、いちばんの落とし穴でした。DGX Spark では Express install が走り、Ollama を自動構成します。手元にすでに別の推論環境がある場合でも、Express install はそれを拾わずに Ollama 構成で進むので、別のバックエンドを使いたいなら onboarding 後に inference set で向け直すのが現実的です。
CDI デバイス仕様の生成で sudo パスワードを求められる点も、ドキュメントだけ読んでいると見落としがちです。これは GPU パススルーに必要な手順なので、避けては通れません。
ポート 8642 のフォワードは、reboot やターミナルの再起動で切れることがあります。つながらなくなったら、フォワードを張り直します。
Hermes Agent はツールやスキルの定義を含む大きめのコンテキストを前提にしているので、推論バックエンドのコンテキスト長にも余裕が要ります。今回の Ollama 構成では実行時のコンテキスト長が 262,144 トークンと十分でしたが、自前のバックエンドに差し替える場合は、ここが極端に小さくないかを確認しておくと安心です。
Hermes を最新版に上げるには(更新の制約と手順 — クリックで展開)
バージョンまわりにも癖があります。sandbox の Hermes は NemoClaw が配布する base image に焼き込まれているので、本家 Hermes の最新版とは少しズレることがあります。今回入ったのは v0.14.0 で、起動画面には「1 commit behind — uv pip install --upgrade hermes-agent で更新できる」と案内が出ていました。
ところが、この案内どおりにはいきません。uv pip install --upgrade を sandbox 内で実行しても、egress ポリシーが pypi への接続を遮断していて失敗します。面白いことに、ポリシーのプリセットでは pypi は有効になっているのですが、pypi.org への接続だけ通らず、同じく許可されている github.com は問題なく通る、という状態でした。許可リストに名前があっても、実際に egress プロキシを抜けられるかはドメイン次第のようです。
Hermes には hermes update という専用コマンドもあります。こちらで試すと、PyPI へのパッケージ解決と準備までは進みました(egress を抜けられたようです)。ところが今度は /opt/hermes/.venv への書き込みが Permission denied で弾かれます。
→ Running: /usr/local/bin/uv pip install --upgrade hermes-agent
Resolved 45 packages in 351ms
Prepared 15 packages in 312ms
error: failed to remove file `/opt/hermes/.venv/.../INSTALLER`: Permission denied (os error 13)
✗ Update failed
base image の Hermes は sandbox の中から書き換えられないように固定されていて、結局この経路でも更新できませんでした。そもそも sandbox は非 root ユーザー(uid=998)で動いていて sudo も入っておらず、/opt/hermes は root 所有です。egress・書き込み権限・非 root の三重で、sandbox の中からの更新は塞がれています。「再構築せずに中身だけ上げられないか」と試したくなるところですが、エージェントが自分の足場(ランタイム)を勝手に書き換えられないようにする、という OpenShell の隔離設計がここでも効いていて、基本的にはできない作りでした。
ではどう上げるか。素直なのは NemoClaw 自体を最新化してから sandbox を作り直す流れです。インストーラー(curl ... | bash)を叩き直すと最新の NemoClaw を取得し、その時点の Hermes を同梱した新しい base image に更新されます。そのうえで nemohermes sandbox rebuild を実行すれば、sandbox がその base image で作り直されます。名前は「作り直し」ですが、中身は workspace の状態(config・推論プロバイダー設定・ネットワークポリシー・メモリ・cron・認証情報など)を一度バックアップし、新しい image で sandbox を作り直してから復元する流れ(内部的には onboard --resume)なので、設定をやり直す必要はありません。心配なら snapshot create で事前に手動バックアップも取れます。一方で destroy は sandbox を永続ボリュームごと消す別物なので、ここは取り違えないようにしたいですね。逆に言えば、Hermes 単体の最新版がほしくても、NemoClaw 側が新しい base image を出すまでは sandbox の Hermes は上がりません。base image のビルド日(今回は 2026-05-29)と本家 Hermes のリリースタイミングがズレていると、こうした差が生まれます。どうしても最新の素の Hermes を触りたいときは、sandbox の外で別途動かすことになりそうです。
まとめ
DGX Spark 上で NemoHermes を使い、Hermes Agent を OpenShell sandbox の内側で動かすところまで一通り試してみました。
curl 一発のインストーラーが DGX Spark を検出して、Ollama と qwen3.6:35b の用意から sandbox の構築、Hermes ゲートウェイの起動までをまとめて面倒を見てくれたのは、ハンズオンとしてかなり手軽でした。ヘルスチェック、OpenAI 互換 API でのチャット、ネットワーク隔離の確認まで、おおむねスムーズに到達できました。GPU パススルーが sandbox 内まで効いているのも、ローカルで重いモデルを動かすうえでは心強いところですね。
中身を覗いてみると、役割分担がきれいに見えてきました。エージェントの能力そのもの、つまりスキルやツールは Hermes 標準のままで、NemoClaw が足しているのは nemoclaw プラグインと OpenShell のポリシーという外枠でした。そのエージェントは非 root で動き、自分のランタイムも外部通信も勝手にはいじれず、アップデートすら sandbox の中からはできません。一見すると窮屈ですが、これは「強力なエージェントを安全に走らせる」という狙いがそのまま形になったものだと感じました。能力は Hermes、それを安全に閉じ込める器が NemoClaw と OpenShell、という分担です。
ローカル推論と組み合わせて、エージェントを手元のハードウェアで安全に動かせるのは、DGX Spark との相性も良さそうです。
あらためて、あえて NemoClaw / OpenShell を選ぶ理由を整理すると、エージェントを sandbox で隔離して非 root で走らせる安全性、推論ルートを inference.local で一元的に制御できること、egress をポリシーで絞れること、base image でランタイムを固定して改ざんを防げること、あたりに集約されます。しかもそれらが OpenClaw でも Hermes でも同じように効く、エージェントを選ばない実行基盤である点が、いちばんの強みかなと思います。
参考リンク
公式ドキュメント
- NemoClaw Quickstart with Hermes
- NemoClaw Developer Guide
- NVIDIA OpenShell Developer Guide
- DGX Spark Playbooks - OpenShell
- Run Local AI Agents with Faster Models and Multi-Node Clustering on NVIDIA DGX Spark(NVIDIA 公式ブログ)
- Hermes Agent — Work with Skills









