
I tried running NVIDIA VSS 3.2.0 GA on DGX Spark
This page has been translated by machine translation. View original
Introduction
Hello, I'm Morishige from Classmethod's Manufacturing Business Technology Department.
NVIDIA's VSS (Video Search and Summarization) was released as GA version 3.2.0 on June 16. This is the first General Availability release in the 3.X series.
To put it simply, VSS is a complete reference implementation for summarizing, searching, and performing alert detection on video using VLM (Vision Language Model). It consists of multiple microservices and agent workflows launched via Docker Compose or Helm. Previously it was in EA (Early Access), but with the GA release, I set up the full configuration of 3.2.0 on my local DGX Spark to verify everything hands-on, from the startup experience to the current state of new features.
DGX Spark is a compact AI workstation with a single GB10 (ARM64), featuring a unique architecture where the CPU and GPU share 128 GiB of Unified Memory. Since behavior differs from x86 + H100 / RTX PRO 6000 configurations in some areas, I'll add notes where relevant.
I've also written articles covering previous versions of VSS, so if you're considering migrating, feel free to check those out as well.
Overview of the 3.2.0 GA Release
First, let me summarize in a table what changed in the 3.2.0 GA release, covering NEW / CHANGED / FIXED / BREAKING from the release notes.
| Category | Main Topics |
|---|---|
| NEW | GitHub source release of all microservices and agent workflows (Apache-2.0 + MIT), Agent Skills (EA), NemoClaw + VSS (EA), RT-CV-3D (Sparse4D v2.2) + Auto Calibration, audio-enabled video understanding (Nemotron 3 Nano Omni) |
| CHANGED | /v1/generate_captions_alerts → /v1/generate_captions rename, Envoy/SDR routing removed from base profile, deploy structure migrated to developer-profiles/ + services/ include model |
| FIXED | HTTP 409 returned for duplicate stream/camera IDs (old behavior: silent overwrite), Riva ASR NIM removed from compose bundle |
| BREAKING | Items in the above CHANGED + FIXED that will break existing client code or compose configurations from previous versions |
The two changes that stood out most to me were "full source release" and "overhaul of the deploy structure." This article proceeds with hands-on verification built around these two changes.
Note that RT-CV-3D / Auto Calibration requires a multi-camera environment, so I won't go deep on that here. Audio-enabled video understanding (Nemotron 3 Nano Omni) also involves a significant change with Riva ASR NIM being swapped out, so I plan to cover that with hands-on verification in a separate article.
Overhaul of the Deploy Structure
The 3.2 deploy structure is a modular configuration connecting deploy/docker/{developer-profiles, industry-profiles, services}/ via includes. A startup script called dev-profile.sh auto-detects the GPU to determine HARDWARE_PROFILE and assembles the profile-specific compose.
The dashed lines show the services picked up by the base profile (agent / Cosmos-Reason2-8B / Nemotron-Nano-9B-v2 FP8 / ui · vios · infra). By following the dashed lines for alerts or lvs, you should be able to read what each different profile pulls in from the same diagram.
The GPU detection logic is around line 91 of dev-profile.sh:
case "${gpu_name}" in
*gb10*) echo "DGX-SPARK" ;;
...
esac
It auto-detects DGX-SPARK from the GPU name in nvidia-smi and writes HARDWARE_PROFILE=DGX-SPARK to generated.env. This means a DGX Spark with a GB10 will automatically land on the correct profile without any explicit configuration.
Incidentally, the design has HAProxy acting as an API Gateway on port 7777, and there's no separate vss-api-gateway image to be found. My impression is that in the 3.X series, HAProxy has settled into the role of both ingress and API Gateway.
Hands-on Points When Running on DGX Spark
From here, I'll organize what becomes visible when bringing up the base profile on a DGX Spark, covering three topics: LLM, Alert, and startup time.
The Local LLM Runs in a vLLM Container
When I used docker inspect to look inside the LLM container while the base profile was running, it turned out to be a plain vLLM container rather than a NIM.
$ docker inspect nvidia-nemotron-nano-9b-v2-fp8 --format '{{.Config.Image}}'
nvcr.io/nvidia/vllm:25.12.post1-py3
The actual startup command looks like this:
python3 -m vllm.entrypoints.openai.api_server \
--model nvidia/NVIDIA-Nemotron-Nano-9B-v2-FP8 \
--trust-remote-code \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.40 \
--port 8000 \
--mamba_ssm_cache_dtype float32 \
--enable-auto-tool-choice \
--tool-parser-plugin /opt/toolcall_parser/nemotron_toolcall_parser_no_streaming.py \
--tool-call-parser nemotron_json
The official compose (deploy/docker/services/nim/nvidia-nemotron-nano-9b-v2-fp8/compose.yml) even includes a comment like this:
# Nemotron-Nano-V2 and tool-parser (nemotron_toolcall_parser_no_streaming.py) require vLLM 25.12+; 25.10 does not support Nemotron.
Now you can read the "intent behind choosing vLLM 25.12+" directly from the VSS source. The Nemotron tool-call parser is also handled by an init container called nvidia-nemotron-nano-9b-v2-fp8-toolcall-init that fetches it from HuggingFace and places it in a volume, so there's no need to manually mount a tool parser yourself.
The official prerequisites still list "Fully local deployment for all agent workflows ... is planned for a future release" as a future plan, but given the existence of
hw-DGX-SPARK.envand the structure of the compose described above, the local LLM works fine in practice for the base profile at least. It's worth keeping in mind that the official stance of "Remote LLM only" and the implementation reality of "Local LLM is already set up to work" coexist here.
Alerts Are Consolidated into a Single vss-alert-verification
The container configuration for the alert workflow in 3.2 is consolidated as a single service within deploy/docker/services/alert/compose.yml.
services:
alert-bridge:
image: nvcr.io/nvidia/vss-core/vss-alert-verification:3.2.0
container_name: vss-alert-bridge
Interestingly, while the image name is vss-alert-verification, the container name is kept as vss-alert-bridge — a thoughtful choice that avoids breaking compose references or monitoring scripts that were migrated from previous versions.
Although it's a single service, it's designed to switch between the following four functional modes via environment variables:
| Environment Variable | Responsible Function |
|---|---|
ALWAYS_ON_RULES_CONFIG |
Rule configuration for Always-on alerts |
VLM_AS_VERIFIER_CONFIG_FILE |
Behavior configuration for VLM-as-Verifier |
VLM_AS_VERIFIER_ALERT_TYPE_CONFIG_FILE |
Alert type definitions for VLM-as-Verifier |
RTVI_VLM_BASE_URL / RTVI_VLM_MODEL_TO_USE |
Endpoint and model for Real-Time VLM |
The path to the VLM-as-Verifier configuration file (vlm-as-verifier/configs/config.yml) remains unchanged, so migrating settings from previous versions should be relatively straightforward.
Deployment Time for the Base Profile
I measured the time from executing dev-profile.sh up -p base -H DGX-SPARK ... until the health check passed through HAProxy, using time.
| Phase | Duration |
|---|---|
down existing cleanup |
~2 seconds |
| Image pull (vLLM + NIM suite) | ~55 seconds |
| Container startup cascade | ~13 minutes (dominated by VLM NIM compilation wait) |
| Total (measured) | 14 minutes 0 seconds |
The measured value includes about 5 minutes of port conflict recovery work that was specific to my environment during startup, so subtracting that gives a pure startup cascade of about 9 minutes, and a total of around 10 minutes as a representative figure. On a bare DGX Spark without Langfuse or similar running alongside, the value should be close to this.
The bottleneck is the TRT-LLM compilation time inside the NIM for the VLM (Cosmos-Reason2-8B, FP8 dynamic + KV8), which accounts for 8–9 minutes on a cold start. Setting NIM_DISABLE_CUDA_GRAPH=1 in hw-DGX-SPARK.env is likely a measure to shorten this cold start time even slightly.
The reason the image pull completed in 55 seconds is that layer cache from previously pulling different versions of vLLM and NIM images in past experiments was in effect. Starting from a completely clean environment, it's safer to budget an additional several minutes to 10 minutes or so.
API Behaviors Worth Knowing
For those migrating from previous versions or looking to reuse existing client code, here's a summary of places where API behavior has changed. All sources can be grepped in the GitHub repository at the v3.2.0 tag.
Caption Generation Endpoint
Stream caption generation is called via /v1/generate_captions.
curl -X POST http://localhost:7777/v1/generate_captions -d '{...}'
The actual route implementation is around line 1013 of services/video-summarization/src/via_server.py. Any code using the old name /v1/generate_captions_alerts will need to be migrated. Grepping the repository shows it has almost entirely disappeared:
$ grep -rn "generate_captions_alerts" services/ | wc -l
1
The single remaining instance is in the docstring of services/alert/alert-agent-web/app/api/realtime_schemas.py:218, where it references the old name as "Same as RTVI VLM generate_captions_alerts: ...". The rename is cleanly done at the API level.
Duplicate Stream / Camera IDs Are Rejected with 409
Sending the same stream ID / camera ID again will be rejected with HTTP 409 + DuplicateStreamId / DuplicateCameraId. Looking at the code:
# Near line 1265 of services/rtvi/rt-vlm/src/utils/asset_manager.py
if camera_id:
existing_asset_id = self._camera_id_map.get(camera_id)
if existing_asset_id and existing_asset_id in self._asset_map:
raise ServiceException(
f"Live stream with camera_id '{camera_id}' already exists",
"DuplicateCameraId",
409,
)
if stream_id:
asset_id = str(stream_id)
if asset_id in self._asset_map:
raise ServiceException(
f"Live stream with stream_id '{asset_id}' already exists",
"DuplicateStreamId",
409,
)
The same guard is in place on both the rt-vlm side and the rt-embed side. If you were assuming that sending the same ID would overwrite silently, you'll be surprised — it's worth adding 409 handling to be safe.
Same RTSP Is Treated as a Separate Independent Job
Calling /v1/generate_captions multiple times for the same RTSP URL will result in each call being treated as a separate job with its own independent request ID (UUID v4). The relevant logic in asset_manager.py generates a new UUID with str(uuid.uuid4()) if no stream_id is specified, so this is convenient if you want to run multiple separate processes against the same RTSP simultaneously.
Base Profile Routing Has No Envoy/SDR
In the base profile, the configuration connects directly to Stream Processing without going through Envoy + SDR routing. There's an explicit comment in dev-profile-base/.env:
# Direct streamprocessing (no SDR/Envoy/SDRC router on :10000)
The alerts / lvs / search profiles still have sdrc/<mode>/configs/*.yml.tmpl files, so only the base profile intentionally removes the routing layer. Be aware that configurations relying on custom Envoy filters/routes, Istio or Linkerd, or ENVOY_* environment variables will not work with the base profile.
DGX Spark's Official Position
The official prerequisites describe the DGX Spark's position as follows:
"AGX/IGX Thor and DGX Spark platforms currently support the listed remote-LLM configurations. Fully local deployment for all agent workflows (base, summarization, alerts, and search) is planned for a future release."
Officially it's Remote LLM only, but by combining hw-DGX-SPARK.env with the official vLLM compose, the Local LLM works just fine in practice for the base profile. The alerts / search profiles still require Remote LLM.
There's also an architecture dependency that remains: while VIOS-related images are unified into a single OCI image index for x86_64 / AGX Thor / DGX Spark, RTVI / RT-CV / RT-CV-3D require a separate SBSA-specific tag (*:3.2.0-sbsa). Since dev-profile.sh automatically writes RTVI_VLM_IMAGE_TAG=3.2.0-sbsa when it detects DGX-SPARK, you don't need to think about this explicitly.
Bonus: Locally Building services/agent and Swapping the Image
Since 3.2 brought "GitHub source release of all microservices and agent workflows," I wanted to experience that benefit firsthand on actual hardware.
Under services/agent/ in the repository is the full source for the VSS Agent, including the Dockerfile. The license is Apache 2.0.
$ head -1 services/agent/LICENSE.md
Apache License
Version 2.0, January 2004
Incidentally, the repository as a whole is dual-licensed under Apache 2.0 + MIT, with the top-level LICENSE explicitly stating: "Apache-2.0 applies to all code in the repository except the services/ui/ directory. MIT applies to the original code under the services/ui/ directory." Since this article covers services/agent, it falls under Apache 2.0.
Let's try building it ourselves and swapping it in instead of the official image.
Build Command
The Dockerfile is at services/agent/docker/Dockerfile, and the build context is the services/ directory.
docker build \
-f services/agent/docker/Dockerfile \
-t my-vss-agent:local \
services/
The build is multi-stage, with each stage playing the following role:
| Stage | Base | Role |
|---|---|---|
| builder | python:3.13-bookworm |
Resolves dependencies with uv, source-compiles pycairo for ARM64 |
| security-patches | debian:bookworm |
Patches libssl3 to CVE-fixed version |
| runtime | nvcr.io/nvidia/distroless/python:3.13-v3.1.7 |
Minimized with distroless |
| agent-runtime | Derived from runtime | ENTRYPOINT /vss-agent/.venv/bin/nat serve |
It's a production-grade build, even including FFmpeg source in the image for LGPL compliance (services/agent/3rdparty/ffmpeg/FFmpeg-n8.0.1.tar.gz, with verify_ffmpeg_tarball.py checking its presence and validity at build time). Budget 10–20 minutes for the build to be safe.
Pitfall: The URL in the security-patches Stage Goes Stale
Here I ran into "a classic pitfall of the open-source era." The security-patches stage in the Dockerfile uses wget to directly download libssl3 from the Debian security repo:
# v3.2.0 original (excerpt)
wget -O /patches/libssl3.deb http://security.debian.org/debian-security/pool/.../libssl3_3.0.19-1~deb12u2_arm64.deb
At the time of verification for this article, 3.0.19-1~deb12u2 had been removed from the current pool in Debian security, resulting in an HTTP 404. The most practical fix is to rewrite it to automatically fetch the current version while preserving the CVE fix intent.
- RUN apt-get update && \
- apt-get install -y --no-install-recommends wget ca-certificates && \
- mkdir -p /patches && \
- if [ "$TARGETARCH" = "amd64" ]; then \
- wget -O /patches/libssl3.deb http://security.debian.org/debian-security/pool/.../libssl3_3.0.19-1~deb12u2_amd64.deb; \
- elif [ "$TARGETARCH" = "arm64" ]; then \
- wget -O /patches/libssl3.deb http://security.debian.org/debian-security/pool/.../libssl3_3.0.19-1~deb12u2_arm64.deb; \
- fi && \
- cd /patches && \
- dpkg-deb -x libssl3.deb /patches/libssl3-extracted && \
- rm -rf /var/lib/apt/lists/*
+ RUN apt-get update && \
+ apt-get install -y --no-install-recommends ca-certificates && \
+ mkdir -p /patches && \
+ cd /patches && \
+ apt-get download libssl3 && \
+ mv libssl3_*.deb libssl3.deb && \
+ dpkg-deb -x libssl3.deb /patches/libssl3-extracted && \
+ rm -rf /var/lib/apt/lists/*
Using apt-get download libssl3 will automatically fetch the latest patched version currently in bookworm-security. It was a great lesson — "grateful for the source release" and "you need to be ready to deal with the aging of external dependencies" go hand in hand.
After the fix, the build completed in about 8 minutes on DGX Spark, with a final image size of 1.98 GB (including the distroless runtime). The official nvcr.io/nvidia/vss-core/vss-agent:3.2.0 image also shows as 1.98 GB in docker images. The fact that a locally built version from the Dockerfile matches the official image size exactly is clear evidence that the official image is reproducible from the Dockerfile.
Swapping the Image
The relevant line in deploy/docker/services/agent/compose.yml looks like this:
vss-agent:
# for release, change this to the versioned image from the registry
image: nvcr.io/nvidia/vss-core/vss-agent:${VSS_AGENT_VERSION}
As the comment explicitly says — "change this to the versioned image from the registry" — it's designed to be easy to swap. To replace it with my-vss-agent:local and restart only vss-agent:
# Edit the image: in compose.yml
sed -i 's|nvcr.io/nvidia/vss-core/vss-agent:.*|my-vss-agent:local|' \
deploy/docker/services/agent/compose.yml
# Move to deploy/docker and restart only the vss-agent container (leave dependencies as-is)
cd deploy/docker
docker compose --env-file developer-profiles/dev-profile-base/generated.env \
up -d --no-deps --force-recreate vss-agent
Without --no-deps, dependent services including vLLM / NIM / Phoenix will also be restarted, and you'll be waiting another 10 minutes. A subtly important flag.
To verify after startup, first check with docker inspect vss-agent that the image has been swapped:
$ docker inspect vss-agent --format '{{.Config.Image}}'
my-vss-agent:local
Confirm that the application layer responds by hitting /health directly:
$ curl -s http://localhost:8000/health
{"value":{"isAlive":true}}
The Web UI through HAProxy is also fine:
$ curl -s -o /dev/null -w "HTTP %{http_code}\n" http://localhost:7777/
HTTP 200
Once all of this passes, you should have a state where the Chat tab is running on code you built yourself. I actually opened the Chat tab, uploaded a sample video (the warehouse scene from services/alert/warmup/test.mp4), and sent "Summarize this video in 2-3 lines." The result is shown below.
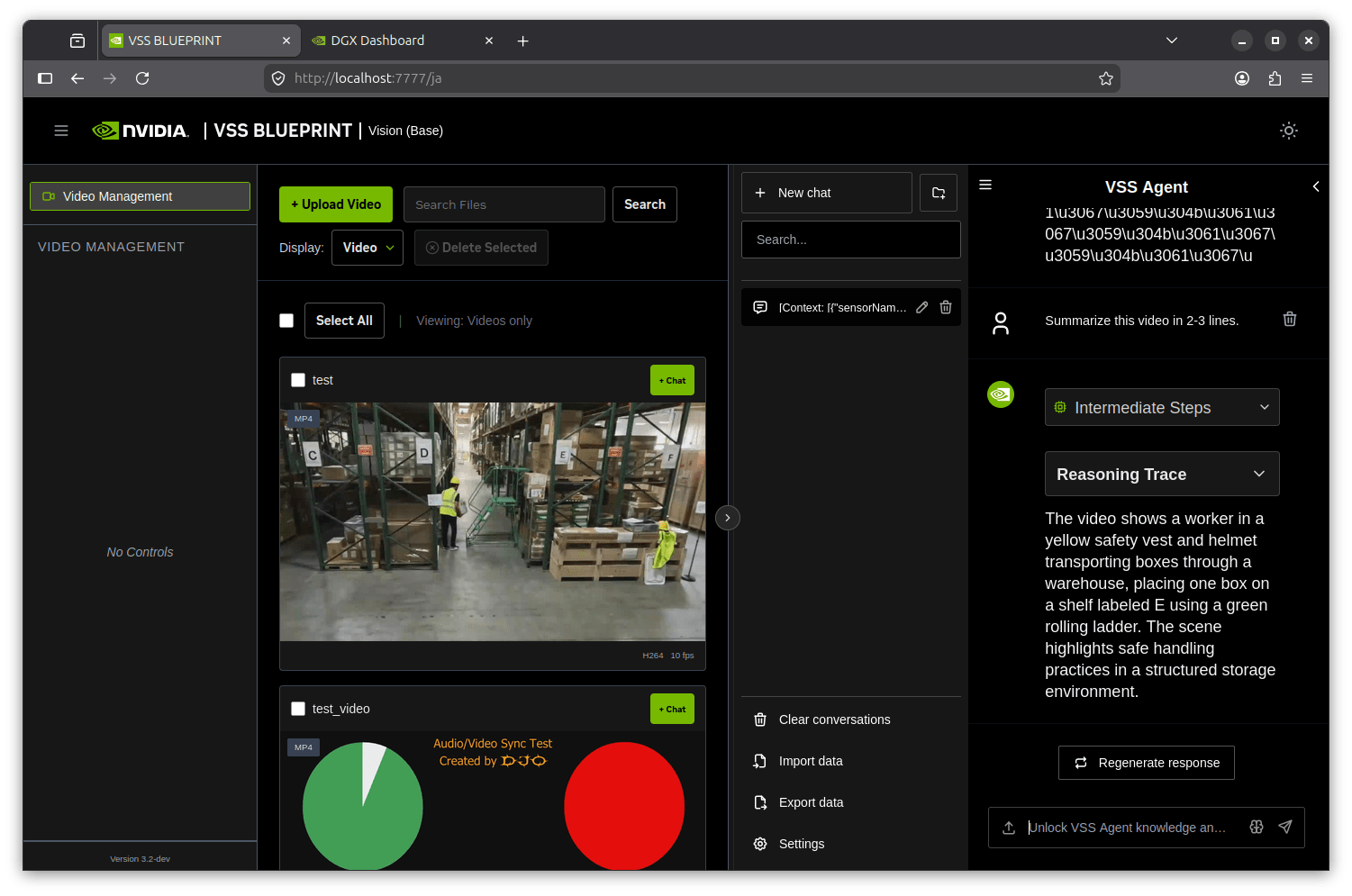
Opening the Reasoning Trace lets you follow the process by which the agent builds the summary based on VLM output. I think this single screenshot conveys that the locally built vss-agent — in a hybrid configuration with the official NIM VLM and local vLLM LLM — is properly communicating with the UI through the API Gateway.
Next Time
Finally, let me mention a service that quietly departed in 3.2.
Riva ASR NIM has been removed from docker-compose. It was incorporated for audio-enabled video understanding, but in 3.2 it exits with a comment # RIVA ASR is not yet supported, replaced by a design that performs audio understanding natively through Nemotron 3 Nano Omni VLM's audio path.
# .env sample (base profile + Omni)
VLM_NAME=Nemotron-Nano-V3-Omni-GA0420-FP8
RTVI_VLM_MODEL_TO_USE=vllm-compatible
VLM_MODEL_SUPPORTS_AUDIO=true
The audio understanding design change is a fairly significant topic, so next time I plan to chase that down on actual hardware.
Summary
Here's a rough summary of what became visible after bringing up VSS 3.2.0 GA on DGX Spark with the base profile:
| Aspect | Hands-on experience with 3.2 GA + DGX Spark |
|---|---|
| LLM | Official compose starts Nemotron-Nano-9B-v2 FP8 in a vLLM container. Tool-call parser is also auto-fetched by an init container |
| Alert | Single vss-alert-verification image switches between Always-on / VLM-as-Verifier / Real-Time via environment variables |
| Deploy time | ~9 minutes for a clean base profile startup cascade, ~10 minutes total (dominated by VLM NIM compilation wait) |
| API | Caption endpoint is /v1/generate_captions, duplicate IDs return 409, base profile has no Envoy/SDR |
| Source release | All microservices and Agent workflows published on GitHub under Apache-2.0 + MIT, Dockerfiles included |
While the official documentation says "DGX Spark is Remote LLM only," the base profile implementation has the Local LLM working as-is, making it fully self-contained for PoC and verification purposes. With the Dockerfile now public, it's become normal to build your own code, swap it in, and verify behavior directly.
Reference Links
- VSS docs (latest = 3.2.0)
- VSS 3.2.0 Release Notes
- VSS Prerequisites (hardware / profile / DGX Spark Remote LLM constraints)
- VSS Helm chart deployment guide
- GitHub: video-search-and-summarization v3.2.0 release
- GitHub: LICENSE (Apache-2.0 + MIT dual)
- GitHub: services/agent full source
- GitHub: deploy/docker (compose layout)
- GitHub: services/agent/docker/Dockerfile (the Dockerfile built in this article)
- HuggingFace: NVIDIA-Nemotron-Nano-9B-v2 (host of the tool parser)
- build.nvidia.com: VSS Blueprint card
- Previous article: VSS 3.1.0 EA and the current state of manufacturing VSS as seen at Hannover Messe
- First article: Trying out VSS 3.0.0 EA on DGX Spark
